Nemotron Elastic: Towards Efficient Many-in-One Reasoning LLMs
Abstract: Training a family of LLMs targeting multiple scales and deployment objectives is prohibitively expensive, requiring separate training runs for each different size. Recent work on model compression through pruning and knowledge distillation has reduced this cost; however, this process still incurs hundreds of billions of tokens worth of training cost per compressed model. In this paper, we present Nemotron Elastic, a framework for building reasoning-oriented LLMs, including hybrid Mamba-Attention architectures, that embed multiple nested submodels within a single parent model, each optimized for different deployment configurations and budgets. Each of these submodels shares weights with the parent model and can be extracted zero-shot during deployment without additional training or fine-tuning. We enable this functionality through an end-to-end trained router, tightly coupled to a two-stage training curriculum designed specifically for reasoning models. We additionally introduce group-aware SSM elastification that preserves Mamba's structural constraints, heterogeneous MLP elastification, normalized MSE-based layer importance for improved depth selection, and knowledge distillation enabling simultaneous multi-budget optimization. We apply Nemotron Elastic to the Nemotron Nano V2 12B model, simultaneously producing a 9B and a 6B model using only 110B training tokens; this results in over 360x cost reduction compared to training model families from scratch, and around 7x compared to SoTA compression techniques. Each of the nested models performs on par or better than the SoTA in accuracy. Moreover, unlike other compression methods, the nested capability of our approach allows having a many-in-one reasoning model that has constant deployment memory against the number of models in the family.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Nemotron Elastic, a “many-in-one” LLM built for reasoning. Instead of training separate models for different sizes (like small, medium, large), Nemotron Elastic trains one main model that contains several smaller models inside it—like nested dolls. These smaller models can be “pulled out” instantly during deployment without extra training, and each is tuned for different needs such as speed, memory, or accuracy. The goal is to make powerful reasoning models much cheaper and easier to deploy across many devices and use-cases.
Goals and Questions
The paper focuses on four easy-to-understand questions:
- Can we train one big reasoning model that already includes several smaller, well-optimized versions inside it?
- Can these “nested” models be extracted without retraining and still perform well on tough reasoning tasks?
- Can this approach dramatically cut training costs compared to training each model size separately?
- Can we make this system work with modern hybrid model designs (mixing Attention and Mamba), and keep performance strong on long, multi-step reasoning problems?
How It Works (Methods and Approach)
Think of Nemotron Elastic as a Swiss Army knife LLM: one tool that can switch modes to fit different situations. Here’s how the authors made that possible.
1) Nested models that share the same brain
- Instead of building new models from scratch, Nemotron Elastic builds smaller “submodels” inside the big one.
- All these models use the same “weights” (the learned knowledge), so switching between sizes doesn’t require retraining. It’s like choosing a smaller set of gears from the same machine when you need it to run faster or use less energy.
2) A “router” that decides which parts to use
- A small helper network called a router acts like a coach that chooses which parts of the main model should be active for a given budget (for example, a 6B-size model vs. a 12B model).
- During training, the router learns to pick the best combination of parts for different goals (speed, memory use, accuracy).
- It starts with “soft” choices and gradually makes sharper decisions, so it learns which components matter most.
3) Ranking what’s important (width and depth)
- The model has “width” (how many channels, neurons, or heads you use—like the number of lanes on a highway) and “depth” (how many layers—like floors in a building).
- The authors measure which channels, neurons, heads, and layers are most important by looking at activations and prediction changes. They keep the high-impact parts first when shrinking the model, so even the smaller versions stay smart.
4) Hybrid design: Attention + Mamba
- Attention is great at looking across the whole text and finding connections, but it needs big memory caches.
- Mamba (a state-space model) processes sequences very efficiently and scales well for long inputs.
- Nemotron Elastic supports both, and preserves Mamba’s special structure while being elastic—this is tricky and relatively new.
5) Knowledge distillation: learning from a teacher
- The system uses “knowledge distillation,” which is like a student learning from a teacher’s answers and confidence.
- A fixed, full-size teacher model helps the smaller nested models learn to behave like the full model, making them accurate without separate intensive training.
6) Two-stage training for reasoning (short, then long)
- Stage 1 (short context): All model sizes get equal practice on shorter sequences. This helps the router stabilize and explore good designs across sizes.
- Stage 2 (extended context): Training shifts to much longer sequences (up to ~49,000 tokens). More practice goes to the largest model to avoid performance drops as smaller models improve.
- Why long context? Real reasoning—math steps, code chains, explanations—often needs a long “thinking trace.” Training on long inputs teaches the model to handle complex, multi-step tasks.
7) Dynamic masking (turning parts on/off)
- The model uses simple masks (like on/off switches) to activate only the parts chosen by the router.
- This lets all sizes train together in one run without creating separate architectures, and makes deployment easy: you just slice out the chosen parts and the smaller model is ready instantly.
What They Found (Results)
Here are the main results and why they matter:
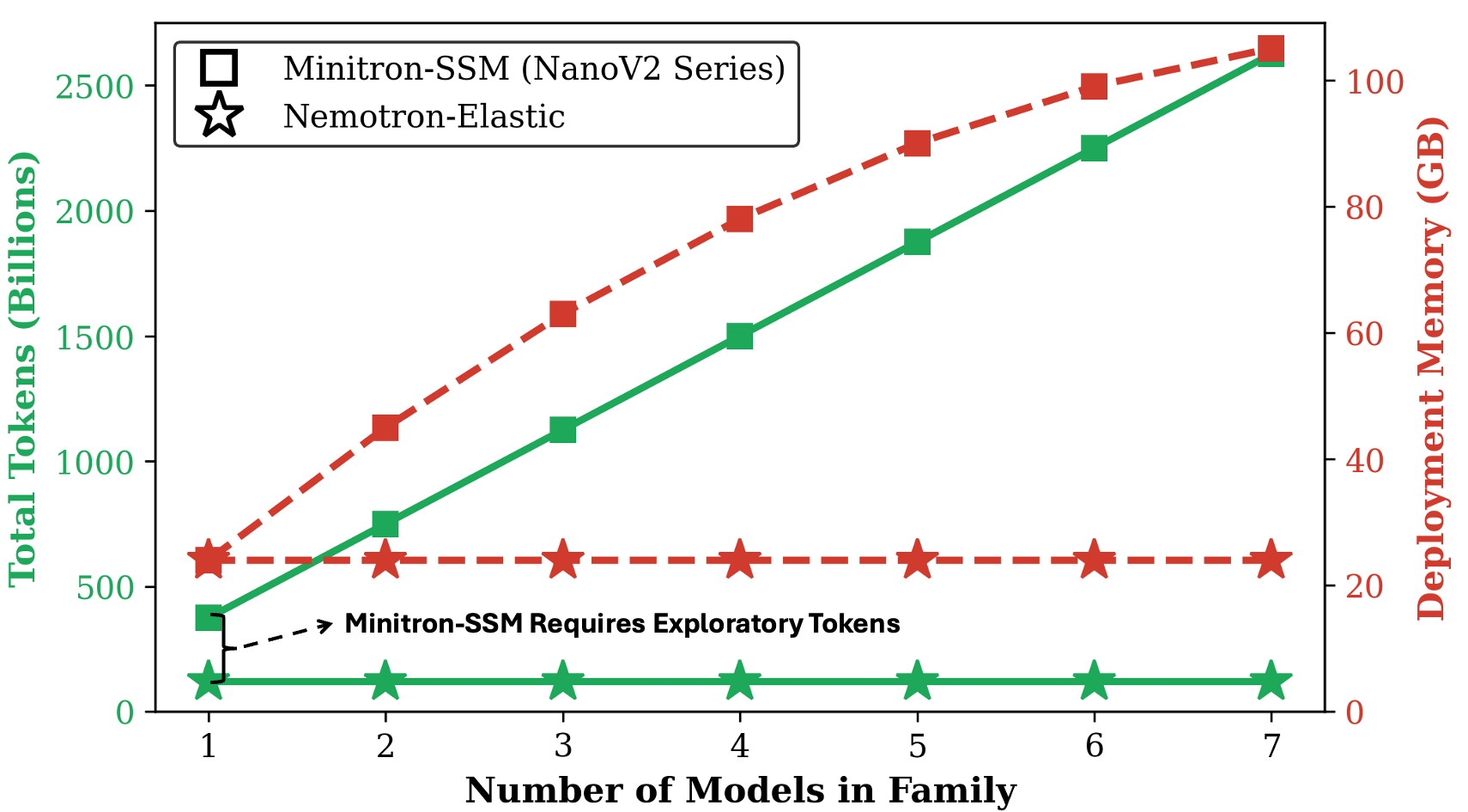
- Big cost savings: From one 12B model, the team produced 9B and 6B nested models using only about 110 billion training tokens.
- Compared to training each model size from scratch, this is roughly a 360× reduction in cost; compared to strong compression methods, it’s about 7× cheaper.
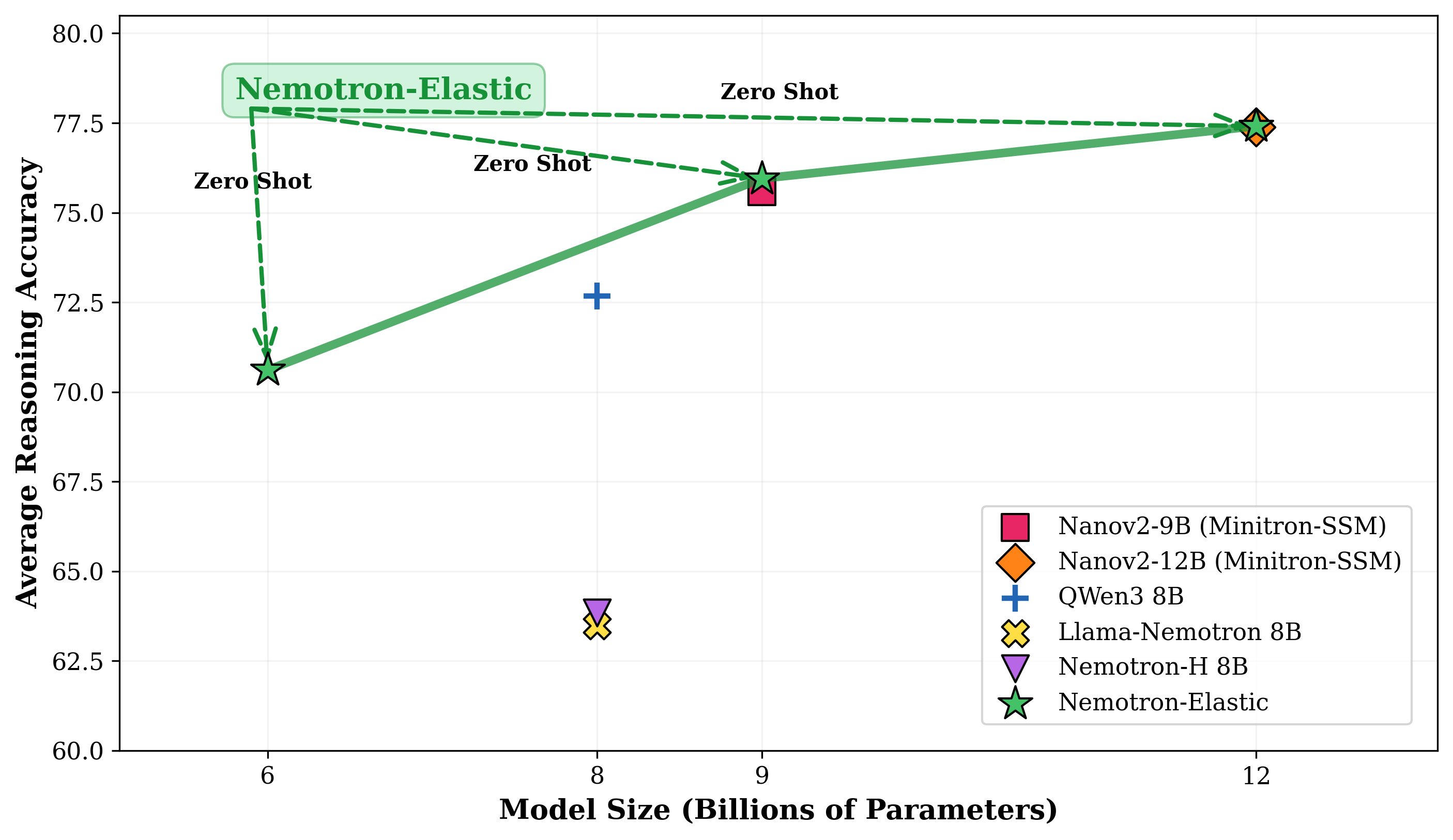
- Accuracy: The nested models perform on par or better than state-of-the-art compressed models on tough reasoning and math benchmarks (e.g., MATH-500, AIME-2024/2025, GPQA, LiveCodeBench v5, MMLU-Pro).
- Zero-shot extraction: After training, the 6B and 9B models can be extracted and used immediately without fine-tuning.
- Constant deployment memory: You can deploy the whole “many-in-one” model and still keep memory usage roughly constant, even if you have multiple nested models available. This is rare—other methods often scale memory linearly as you add model variants.
- Fast inference: Smaller nested models run faster while keeping strong accuracy, making them useful for devices or settings with limited resources.
- Hybrid support: The method works with hybrid Attention+Mamba designs and respects Mamba’s internal structure, which is important for efficiency.
Why It Matters (Implications and Impact)
This research could change how we build and use reasoning-focused AI models:
- Accessibility: Powerful reasoning models become more affordable to train and deploy, making them available to more teams and devices.
- Flexibility: One main model can serve many needs—fast responses on phones, high accuracy in data centers—without separate training runs.
- Efficiency: Training once and deploying many nested versions cuts time, money, and energy use.
- Better reasoning: By specifically training on extended contexts, the models are more capable of handling multi-step problems, like complicated math, programming tasks, and science questions.
- Future-ready: The approach supports modern hybrid designs and allows fine-grained, layer-by-layer adjustments, paving the way for smarter, more adaptable AI systems.
In short, Nemotron Elastic is like building a single brain that can flexibly become smaller or larger depending on the job, without losing its reasoning skills—and without the huge cost of training lots of separate models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Generalization across scales: The approach is only demonstrated on a 12B parent model with 6B and 9B submodels; it is unclear how elastification behaves for much larger models (e.g., 70B–405B) or for smaller (<6B) regimes, including stability, accuracy retention, and router behavior at scale.
- Breadth of architectures: Validation is limited to Nemotron Nano V2 with a specific hybrid Mamba–Attention design; it’s unknown how the framework transfers to other hybrid designs (e.g., different SSM variants), pure Transformer architectures, or MoE models.
- Router input is not task-aware: The router consumes only a one-hot budget indicator, not input/task features; the benefits and feasibility of per-input, difficulty-aware routing (dynamic budget selection conditioned on content) remain unexplored.
- Router objective and cost modeling: The resource loss uses a generic cost function but lacks concrete, validated mappings to real hardware metrics (latency, throughput, energy, memory including KV/Mamba caches). It’s unclear how accurate and portable the cost models are across GPUs, TPUs, and deployment stacks.
- Router stability and design: There are no ablations on router architecture (depth/width, activations), temperature annealing schedules, or training stability (mode collapse, gradient interference among budgets); robustness to hyperparameters (e.g., λ for router loss) is not characterized.
- Importance scoring sensitivity: Activation-based width importance and normalized MSE for depth are proposed without systematic comparisons to alternatives (Fisher information, Taylor/gradient metrics, SNIP/GRASP, Shapley, or curvature-based methods), nor sensitivity to calibration data choice and size.
- Depth elastification interactions: The iterative layer ablation method assumes independent layer effects; interactions among layers (synergies, order dependence, reordering) and the effect on residual pathways and normalization are not analyzed.
- Heterogeneous vs homogeneous elastification: The paper claims support for per-layer heterogeneous configurations but provides no quantitative comparison of benefits/costs versus homogeneous variants, nor guidelines for when heterogeneity is preferable.
- Extended-context training scope: While 49K tokens are used, there is no evaluation on longer contexts (e.g., 100K+, million-token streams) or memory-constrained long-context scenarios; the relationship between context length, router decisions, and reasoning accuracy is not empirically characterized.
- Long-context benchmarks: The evaluation focuses on math/code/reasoning (MATH-500, AIME, GPQA, LiveCodeBench, MMLU-Pro) and omits long-context benchmarks (e.g., LongBench, L-Eval, Needle-in-a-Haystack, Book QA) that would stress the claimed reasoning and extended context capabilities.
- Inference performance evidence: Claims of “significantly faster inference” and “constant deployment memory” lack detailed measurements (latency, throughput, VRAM, KV/Mamba cache sizes) across budgets and sequence lengths on real hardware.
- Scaling analysis granularity: The figure shows “constant cost” as family size grows but omits absolute costs and breakdowns (parameters, caches, activations); a comprehensive scaling study with end-to-end metrics per budget and sequence length is missing.
- Slicing reliability: Zero-shot extraction is claimed, but there is no analysis of distribution shift effects, calibration (e.g., layer norm/statistics drift), or whether small models require light finetuning for robustness across unseen tasks.
- KD teacher choice and strategy: The impact of teacher selection (frozen vs trainable, stronger external teacher, multi-teacher), KD temperature τ, and weighting with CE loss is not systematically evaluated; it’s unclear how these choices affect different budgets.
- Multi-budget sampling weights: Stage 2 uses non-uniform sampling but does not report the exact weight schedule nor an ablation of how different allocations affect full vs small model performance, stability, and fairness across budgets.
- Compute cost and reproducibility: Token count reductions are reported, but FLOPs, GPU-hours, cluster size, precision (FP8/FP16/BF16), optimizer settings, and training throughput are missing, limiting reproducibility and real cost assessment.
- Data transparency: The training corpus composition, data mixture for short vs extended-context phases, contamination controls for the evaluated benchmarks, and pre/post-instruction tuning details are not provided.
- Safety and alignment: Effects of elastification on safety, bias, hallucinations, and chain-of-thought disclosure are not studied; whether nested submodels preserve alignment properties is unknown.
- Compatibility with deployment techniques: Interactions with quantization, sparsity, speculative decoding, caching strategies, retrieval-augmented generation (RAG), and streaming inference are not evaluated; potential gains or conflicts are unclear.
- Unseen/continuous budgets: The framework only supports budgets in the training set; it is unknown whether models generalize to unseen or continuous budget targets (interpolation/extrapolation without retraining).
- Hybrid constraints theory: Group-aware SSM elastification is described procedurally but lacks theoretical guarantees that SSM invariants and stability are preserved; formal analysis and failure modes are not provided.
- Masking overhead and engineering: Training/inference overhead from dynamic masking and router invocation (vs sliced static models) is not quantified; best practices for runtime switching among budgets in production are not discussed.
- Per-layer component interplay: How the router jointly trades off Mamba vs attention capacity per layer for reasoning is not analyzed; guidelines for optimal hybrid composition at different budgets remain open.
- Benchmark breadth and OOD generalization: Beyond targeted reasoning/math/code tasks, evaluation on general NLP (summarization, QA, translation), multilingual settings, and out-of-distribution robustness is missing.
- Layer-importance calibration data: The procedure depends on a calibration dataset but does not specify its source, representativeness, or robustness to domain shift; the impact of mis-calibration on selected layers is unknown.
- Post-elastification instruction tuning/RLHF: Whether elastified submodels maintain or improve alignment and reasoning after SFT/RLHF, and how multi-budget training interacts with downstream tuning stages, is unexplored.
- Failure cases and diagnostics: The paper does not report failure modalities (e.g., router mis-selection, degraded small-model reasoning, instability under very long sequences) or provide diagnostic tools to detect/mitigate them.
Practical Applications
Immediate Applications
- Many-in-one model serving and tiered SLAs from a single checkpoint
- Sectors: software, cloud platforms, finance, customer support
- What: Deploy 6B/9B/12B variants from the same weights to meet different latency/cost/quality tiers per request without duplicating storage. Route requests to a budget that meets SLA constraints; extract submodels zero‑shot for specific endpoints.
- Tools/workflows: “Elastic LLM gateway” that maps SLA→budget; packaging scripts to slice submodels; autoscaling policies that select budgets based on queue latency.
- Assumptions/dependencies: Inference runtime must support loading one checkpoint and switching to pre-sliced submodels; cost models for each budget must be calibrated to hardware.
- Edge‑to‑cloud continuity using one consistent model family
- Sectors: mobile, IoT, robotics, healthcare
- What: Run 6B submodel on edge devices (on‑device summarization, task planning) and 12B in cloud for complex queries while keeping behavior aligned because all submodels share weights.
- Tools/workflows: Edge build with 6B slice + cloud escalation path; shared evaluation suite across budgets.
- Assumptions/dependencies: Mamba/attention support on target devices; available memory/compute for intended budget; long‑context may be truncated on edge.
- Rapid, low‑cost creation of model families for R&D and product teams
- Sectors: industry, academia, startups
- What: Train a 12B parent once and obtain 9B/6B variants with ~110B tokens—orders of magnitude cheaper than training each size separately; enables small labs to iterate on multiple sizes.
- Tools/workflows: Two‑stage curriculum (short‑context → extended‑context); KD pipeline with frozen teacher; importance scoring + router training.
- Assumptions/dependencies: Access to initial 12B model and long‑context training infrastructure; curated data for reasoning; high‑quality teacher for KD.
- Long‑context reasoning services with compute‑aware routing
- Sectors: legal, finance, enterprise search, software engineering
- What: Use 12B for 49k‑token chains of thought (e.g., contract/research report analysis, repo‑wide code tasks) and route simpler tasks to 6B/9B to save cost.
- Tools/workflows: Policy that selects budget based on input length/complexity; long‑context inference setup with reduced KV/Mamba cache pressure.
- Assumptions/dependencies: Long‑context inference stack (hybrid Mamba‑attention) and memory planning; domain‑specific evaluation.
- A/B testing and safe feature rollouts without retraining
- Sectors: software, MLOps
- What: Compare quality/latency across 6B vs 9B vs 12B variants of the same checkpoint; run canary rollouts by switching budgets, not models.
- Tools/workflows: Experiment management that logs budget choice; shared prompts and metrics across budgets.
- Assumptions/dependencies: Deterministic router‑driven slicing; monitoring to detect regressions per budget.
- Multi‑tenant hosting with constant storage footprint
- Sectors: cloud/MaaS providers, ISVs
- What: Host one elastic checkpoint and expose multiple “sizes” as SKUs without storing duplicate weights; constant deployment memory regardless of family size.
- Tools/workflows: SKU catalog bound to budget IDs; per‑tenant adapters/LoRAs over the shared base if needed.
- Assumptions/dependencies: If tenant‑specific fine‑tuning is required, use parameter‑efficient adapters to keep storage benefits.
- Hardware‑aware model sizing at deployment
- Sectors: DevOps, edge/cloud operations
- What: Map a node’s RAM/latency constraints to a supported budget (6B/9B/12B) using the router’s resource‑aware training; schedule jobs to the largest feasible submodel.
- Tools/workflows: Cost models (latency/memory) per budget; scheduler hooks that select budgets per host.
- Assumptions/dependencies: Router is trained on budget targets; cost modeling must reflect real hardware; input‑aware routing is not yet built‑in.
- Privacy‑preserving and compliant workflows via budget escalation
- Sectors: healthcare, government, regulated industries
- What: Run private or initial processing on a local 6B slice, escalate only pseudonymized or edge‑filtered cases to 12B in a secure zone for final reasoning.
- Tools/workflows: Data classification gates that choose budget; audit logs linking budgets to data classes.
- Assumptions/dependencies: Domain adaptation/fine‑tuning for regulated tasks; governance policies that define escalation criteria.
- Education and tutoring apps with adaptive compute
- Sectors: education, ed‑tech
- What: Provide step‑by‑step reasoning on low‑cost devices using 6B; switch to 9B/12B for more challenging problems (math, coding) to balance cost and quality.
- Tools/workflows: Difficulty estimators that select budget; offline mode defaults to smaller slice.
- Assumptions/dependencies: Safety and pedagogy fine‑tuning; robust difficulty heuristics.
- Developer assistants with task‑aware compute allocation
- Sectors: software engineering, DevTools
- What: Use 6B for autocomplete and linting; 12B for complex refactors, test generation, and multi‑file reasoning over long contexts.
- Tools/workflows: IDE plugin that picks budgets by task type and context length; repo‑wide analyzers leveraging long‑context training.
- Assumptions/dependencies: Code‑specialized instruction tuning; fast model switching or pre‑sliced endpoints.
Long‑Term Applications
- Input‑adaptive computation (dynamic width/depth by prompt difficulty)
- Sectors: all, especially latency‑sensitive apps
- What: Extend the router to be input‑conditioned, allocating more heads/layers for hard queries and fewer for easy ones at runtime.
- Assumptions/dependencies: Research on stable input‑aware routing; training signals and guardrails to prevent quality collapse.
- Serverless “elastic LLM” offerings with per‑token billing by budget
- Sectors: cloud platforms
- What: Integrate budget selection with schedulers so users pay for the actual compute tier used per request.
- Assumptions/dependencies: Provider support for tiered billing and telemetry; SLA‑compliant budget switching.
- Federated and on‑device continual learning across shared elastic backbones
- Sectors: mobile, IoT, healthcare
- What: Train or personalize smaller submodels on devices, aggregate into the shared 12B parent, and redistribute updated slices.
- Assumptions/dependencies: Privacy‑preserving aggregation; adapter‑based updates to avoid catastrophic interference.
- Real‑time autonomy with compute‑aware planning
- Sectors: robotics, drones, autonomous vehicles
- What: Run 6B for routine control and escalate to 12B for complex planning/explanations when slack is available.
- Assumptions/dependencies: Real‑time constraints, safety verification, and reliable latency predictability per budget.
- Energy‑aware scheduling and carbon‑optimal inference
- Sectors: data centers, sustainable computing
- What: Choose budgets based on renewable availability or carbon intensity—smaller submodels during peak grid load, larger when green energy is abundant.
- Assumptions/dependencies: Integration with energy telemetry; policies balancing QoS vs sustainability.
- Standardization and policy for cost‑ and carbon‑efficient AI procurement
- Sectors: public sector, enterprise IT governance
- What: Encourage or require elastic model families to minimize training and deployment footprints while meeting performance benchmarks.
- Assumptions/dependencies: Consensus benchmarks for quality across budgets; transparent reporting of token/energy savings.
- Cross‑architecture elastification (beyond hybrid Mamba‑attention)
- Sectors: AI research, model providers
- What: Generalize group‑aware elastification and depth ranking to pure transformers and other SSMs, producing universal many‑in‑one families.
- Assumptions/dependencies: Engineering for different layer types; validation on diverse tasks and scales.
- Tooling ecosystem and standards for “elastic slicing”
- Sectors: AI infrastructure (compilers, runtimes)
- What: First‑class support in ONNX/TensorRT/vLLM for exporting, optimizing, and serving budget slices with shared weights.
- Assumptions/dependencies: Vendor adoption; standard router/spec formats and compatibility with quantization/pruning passes.
- Multi‑domain hierarchical families in one checkpoint
- Sectors: finance, legal, healthcare, education
- What: One elastic checkpoint with domain‑specialized subnets (e.g., finance‑tuned 6B, legal‑tuned 9B) for consistent operations across organizations.
- Assumptions/dependencies: Multi‑domain data and adapter isolation to avoid negative transfer; governance for domain routing.
- Safety‑aware budget governance
- Sectors: regulated industries
- What: Policies tying budget escalation to risk levels (e.g., critical clinical decisions must use 12B with logging), backed by elastic infrastructure.
- Assumptions/dependencies: Calibrated risk models; audit trails and certification for each budget tier.
Glossary
- Activation-based importance scoring: A method that ranks model components by measuring their activation magnitudes during forward passes to guide pruning or selection. "We employ activation-based importance scoring to rank model components along each width dimension using layer activation magnitudes."
- Attention heads: Independent subcomponents in multi-head attention that process different parts or aspects of the input in parallel. "For each axisâembedding channels, Mamba heads, Mamba head channels, attention heads, and FFN intermediate neuronsâwe compute importance scores from forward propagation only, keeping this phase lightweight."
- Causal convolution: A convolution operation that ensures outputs at any time step depend only on current and past inputs, preserving sequence causality. "The intermediate activations , , and undergo causal convolution:"
- cross-entropy loss: A standard loss function for training probabilistic classifiers and LLMs by measuring the difference between predicted and true distributions. "The model can be trained using standard cross-entropy loss over the training corpus without external supervision:"
- Depth elastification: The process of making the number of layers adaptable by selecting which layers to retain based on importance, enabling elastic depth. "Depth elastification: We add depth reduction to elastification via iterative layer removal guided by normalized MSE to the full modelâs predictionsâresulting in more reliable layer ranking than single-shot or perplexity-based methods."
- Extended-context training: Training with long sequence lengths to improve a model’s ability to perform multi-step reasoning over extended inputs. "Extended-context training (with sequence length ) exposes all elastic variants to problems requiring longer inference chains, forcing the router to discover configurations that maintain coherence and performance across extended contexts."
- Feed-forward network (FFN): A per-layer MLP component in transformer-like architectures that applies non-linear transformations independently to each position. "For feed-forward network layers, we apply masking to both embedding and intermediate dimensions."
- Forward KL divergence: A distillation objective measuring how well the student distribution matches the teacher by computing KL(teacher || student). "The distillation loss using forward KL divergence is:"
- Gated RMSNorm: A normalization technique (RMSNorm) combined with a gating mechanism to modulate activations. "Followed by gated RMSNorm and output projection:"
- Group-aware masking: A masking strategy that respects structural group constraints (e.g., SSM head groups) to maintain valid computations during pruning. "For Mamba-2 components in the hybrid architecture, we apply group-aware masking following permutation-preserving constraints to maintain structural integrity of state-space computations."
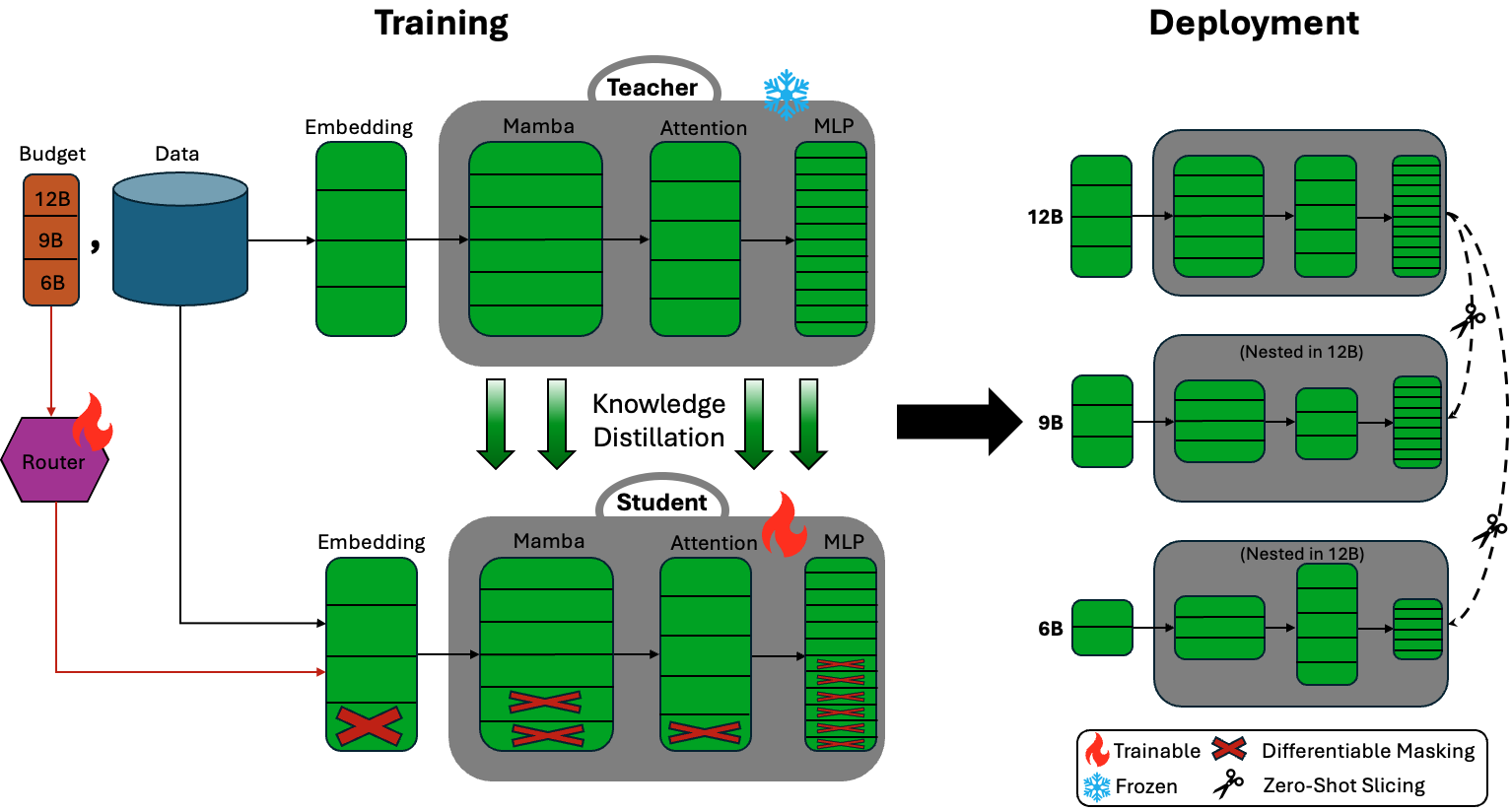
- Group-aware SSM elastification: Elastic resizing for SSM components that preserves group structure and constraints specific to state space models. "We additionally introduce group-aware SSM elastification that preserves Mamba's structural constraints, heterogeneous MLP elastification, normalized MSE-based layer importance for improved depth selection, and knowledge distillation enabling simultaneous multi-budget optimization."
- Gumbel-Softmax: A differentiable sampling technique that approximates discrete choices via continuous relaxations, enabling gradient-based learning over categorical variables. "The router outputs are passed through Gumbel-Softmax with temperature to produce soft probability distributions over configuration choices."
- Hybrid Mamba-Attention architectures: Models that combine attention layers with state space model layers (e.g., Mamba) to balance contextual reasoning and efficient sequence processing. "In this paper, we present Nemotron Elastic, a framework for building reasoning-oriented LLMs, including hybrid Mamba-Attention architectures, that embed multiple nested submodels within a single parent model, each optimized for different deployment configurations and budgets."
- Knowledge distillation: A training paradigm where a student model learns to mimic a teacher model’s output distribution to improve performance. "Knowledge Distillation (KD) improves model accuracy by transferring knowledge from a teacher model."
- KV cache: The cached key and value tensors used by attention mechanisms to speed up autoregressive inference. "These hybrid architectures, exemplified by models like Jamba, Zamba, and Nemotron-H, achieve superior efficiency through reduced KV cache requirements and linear-time sequence processing while maintaining competitive accuracy."
- Layer normalization: A normalization technique that standardizes activations across features within a layer to stabilize training. "This operator is applied to layer normalization outputs and all weight matrices interfacing with the embedding dimension."
- Leaky ReLU: An activation function similar to ReLU but allowing a small, non-zero gradient for negative inputs to prevent dead neurons. "Each router consists of two fully connected layers with leaky ReLU activation applied between them."
- Logits: Pre-softmax scores output by a model representing unnormalized log-probabilities over classes or tokens. "Let denote the student model's softmax-normalized logits at temperature , and denote the teacher's corresponding distribution."
- Mamba: A state space model architecture designed for efficient, linear-time sequence processing with strong long-context capabilities. "Concurrently, we observe two recent trends that are relevant to the above discussion: the first is the rise of hybrid models that combine attention mechanisms with State Space Models (SSMs) such as Mamba"
- Matryoshka-style nested networks: Architectures that embed multiple sub-networks inside a larger model such that smaller variants can be extracted without further training. "A promising alternative to model compression is elastic or Matryoshka-style nested networks"
- Mean squared error (MSE) normalization: Using MSE normalized by the full model’s output energy to compare layer importance across datasets. "Layer importance is estimated iteratively using normalized mean squared error (MSE) between the full model's predictions and predictions with specific layers removed."
- Minitron-SSM: A specific compression approach/model family used as a baseline for scaling and efficiency comparisons. "Right: Scaling analysis comparing Nemotron Elastic and Minitron-SSM as model family size grows."
- Nested weight-sharing architecture: An elastic design where all sub-model variants share the same parameters, enabling zero-shot extraction at different budgets. "We build upon a nested weight-sharing architecture that enables a single hybrid LLM to dynamically adapt across multiple resource constraints."
- Pareto-optimal configurations: Architecture choices that optimally balance trade-offs (e.g., accuracy vs. cost) with no configuration strictly better in all objectives. "This enables the router to autonomously search through the joint architecture space, balancing multiple objectives and discovering Pareto-optimal configurations."
- Residual skip connections: Pathways that bypass certain layers, allowing gradients to flow and outputs to be combined with identity mappings. "Layers with are bypassed through residual skip connections, maintaining gradient flow while reducing computation."
- RMSNorm: Root mean square normalization that scales activations based on their RMS, often used as a lighter alternative to LayerNorm. "y_{\text{pre} = \mathbf{W}_O \cdot \text{RMSNorm}(\tilde{y} \odot \text{silu}(z))"
- Router: A learned module that selects which components (layers, heads, channels) are active under given resource budgets using differentiable masking. "For each dynamic dimension , we introduce a dedicated router network that performs architecture search over the target configuration space."
- Silu: The Sigmoid Linear Unit activation function, often used to improve smoothness and performance over ReLU-like functions. "y_{\text{pre} = \mathbf{W}_O \cdot \text{RMSNorm}(\tilde{y} \odot \text{silu}(z))"
- State Space Models (SSMs): Sequence modeling architectures that represent dynamics via latent state transitions, enabling efficient long-context processing. "Concurrently, we observe two recent trends that are relevant to the above discussion: the first is the rise of hybrid models that combine attention mechanisms with State Space Models (SSMs) such as Mamba"
- Zero-shot: Performing a task (or extracting a sub-model) without any additional task-specific training or fine-tuning. "Each of these submodels shares weights with the parent model and can be extracted zero-shot during deployment without additional training or fine-tuning."
Collections
Sign up for free to add this paper to one or more collections.

