- The paper presents Express, a meta-procedure that converts unmasked attention into causal approximations using Thinformer with provable error guarantees.
- It introduces a custom I/O-aware Triton GPU kernel that accelerates long-context inference, achieving up to 82× speedup and reduced memory usage.
- Empirical evaluations show significant improvements in prefill, KV cache compression, and long-form decoding compared to prior state-of-the-art methods.
Express Language Modeling: Efficient Causal Attention via Unmasked Approximation Conversion
Overview and Motivation
The paper "Express Language Modeling" (2606.10944) presents Express, a meta-procedure for converting non-causal (unmasked) attention approximations into causal (masked) approximations with strong accuracy and resource guarantees. Express is instantiated with the Thinformer approximation, yielding Thinformer Express: an approach to causal attention with provable error rates and substantially reduced memory and computational requirements. The significance of this work lies in enabling efficient and accurate long-context inference for LLMs, addressing bottlenecks in four canonical resource-constrained scenarios: prefill, KV cache compression, memory-limited, and compute-limited long-form decoding.
Theoretical Foundations
Sub-Quadratic Thinning and Attention Approximation
Recent advances provide sub-quadratic approximations for unmasked attention, often by retaining a concise, weighted subset (coreset) of key-value pairs using thinning algorithms. Such methods, notably Thinformer, employ sub-Gaussian thinning tailored to preserve attention outputs for all queries with O(s)-sized coresets, where s is the desired cache size. However, causal attention—the backbone of language modeling inference—requires masking and streaming updates, which complicates coreset maintenance and approximation guarantees.
Express generalizes thinning by recursively applying a "halving" algorithm, tailored for offline coresets, and introduces a streaming variant that enables cache updates in causal order. Express maintains a dynamically thinned cache with bounded size and incremental updatability while controlling error propagation in the streaming setting. Notably, the sub-Gaussian concentration of error only grows logarithmically with the input sequence length, and both memory and compute remain decoupled from n (the total sequence length), scaling instead with the coreset size s.
For a sequence of length n, Express paired with Thinformer achieves an approximation error of O(log3/2(n)/s), O(s) cache memory, and O(s2log2(n)) compression overhead. These resource profiles markedly improve the scalability of causal attention relative to prior state-of-the-art methods.
Methodological Implementation
Thinformer Express is implemented with a custom I/O-aware Triton GPU kernel, significantly accelerating runtime relative to both the previous PyTorch Thinformer and FlashAttention 2. The system exploits tiling for optimal memory access, batch-level and row-parallelism, and avoids explicit kernel matrix materialization via index-based dereferencing.
Express's key phases include:
- Exact Phase: Initially, all input tokens are retained exactly up to cache size s.
- Thin Phase: Incoming tokens are batched and recursively thinned to s elements.
- Halve Phase: Once the cache exceeds s0, halving is used twice to reduce the cache, ensuring bounded memory.
This design guarantees that the attention cache never exceeds s1 entries, constraining GPU memory usage independently of context size.
Empirical Evaluation
Long-Context Prefill Acceleration
Express delivers up to s2 speedup over FlashAttention 2 at 512K tokens in the prefill phase with masked attention, outperforming both FlashAttention and HyperAttention in both runtime and runtime-perplexity tradeoffs in LongBench-E tasks.
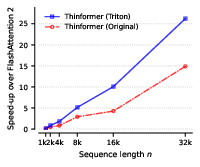
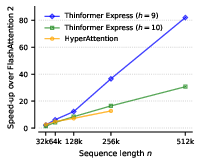
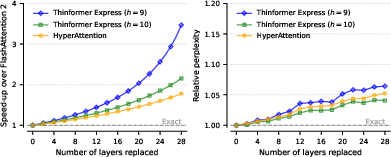
Figure 1: Express achieves substantial speedups in long-context prefill, especially on masked attention tasks, with resource usage and accuracy superior to HyperAttention.
KV Cache Compression
Express seamlessly integrates as a drop-in replacement for conventional key-value computation in leading cache compression pipelines (SnapKV, StreamingLLM, PyramidKV). This reduces overall runtime for long-context language understanding benchmarks, with no degradation in downstream accuracy.
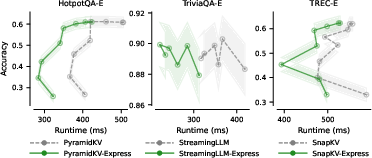
Figure 2: Across a spectrum of cache compression strategies, Express consistently accelerates attention without compromising accuracy across LongBench-E tasks.
On multi-step MATH-500 mathematical reasoning tasks, Express allows models to operate with only 61% of the conventional cache memory while retaining exact-attention-level accuracy. It also reduces computational cost per token, matching accuracy with just 56% of the compute time, thereby outperforming contemporary alternatives (StreamingLLM, SnapKV, ExpectedAttention, KeyDiff, Knorm) in both memory and compute constrained regimes.
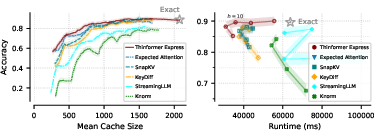
Figure 3: Express dominates state-of-the-art methods in both memory and compute efficiency on challenging long-form generation tasks, matching the accuracy of exact attention with reduced resources.
Comparison to Prior Work
Express's theoretical guarantees surpass those of BalanceKV and HyperAttention. Its error bounds are tighter in both magnitude and dependence on context size, value magnitudes, and the error inflation factor s3. While HyperAttention's error decays as s4 with s5 compute, Express decays as s6 for the same computational budget. Moreover, Express achieves a better value-matrix dependence and utilizes less peak memory and compute for similar or better accuracy guarantees.
Implications and Future Developments
Practical Impact
Express presents a robust framework for integrating high-quality unmasked attention approximations into the causal inference pipeline of LLMs without loss of theoretical guarantees or practical efficiency. This unblocks the use of advanced thinning methods in production-scale LLM deployments, especially for extremely long contexts on resource-constrained devices. Applications include efficient chat assistants, document processing, mathematical reasoning systems, and stream-processing LLM scenarios.
Theoretical and Methodological Extensions
Express is agnostic to the base halving algorithm: any new, higher-quality thinning method can potentially be plugged in to realize further efficiency or accuracy improvements. Further, the analytical results open avenues for hybrid compression strategies and compressed memory architectures leveraging causal streaming coresets in transformer inference.
Future developments may involve:
- Exploring alternative base thinning algorithms and kernels tailored for specific value distributions or data modalities.
- Extending the Triton implementation to support emerging GPU features (e.g., FP8, persistent kernels, TMAs), which were highlighted as promising by the authors.
- Broadening empirical evaluation to non-English languages, multimodal LLMs, and diverse domain tasks.
Conclusion
Express enables practical, theoretically principled, and resource-efficient causal attention approximation using sub-quadratic unmasked methods. Through the Thinformer Express instantiation, the approach demonstrates strictly improved performance and guarantees over existing work in multiple critical LLM inference regimes. The modular design, strong error control, and efficient engineering provide a foundation for scalable, deployable attention at unprecedented context lengths.