- The paper introduces a novel architecture that leverages adaptive chunking and learnable compression to controllably trade memory and compute for quality.
- It employs training with randomized chunk sizes, allowing a single model to dynamically adjust efficiency-quality trade-offs at test time without retraining.
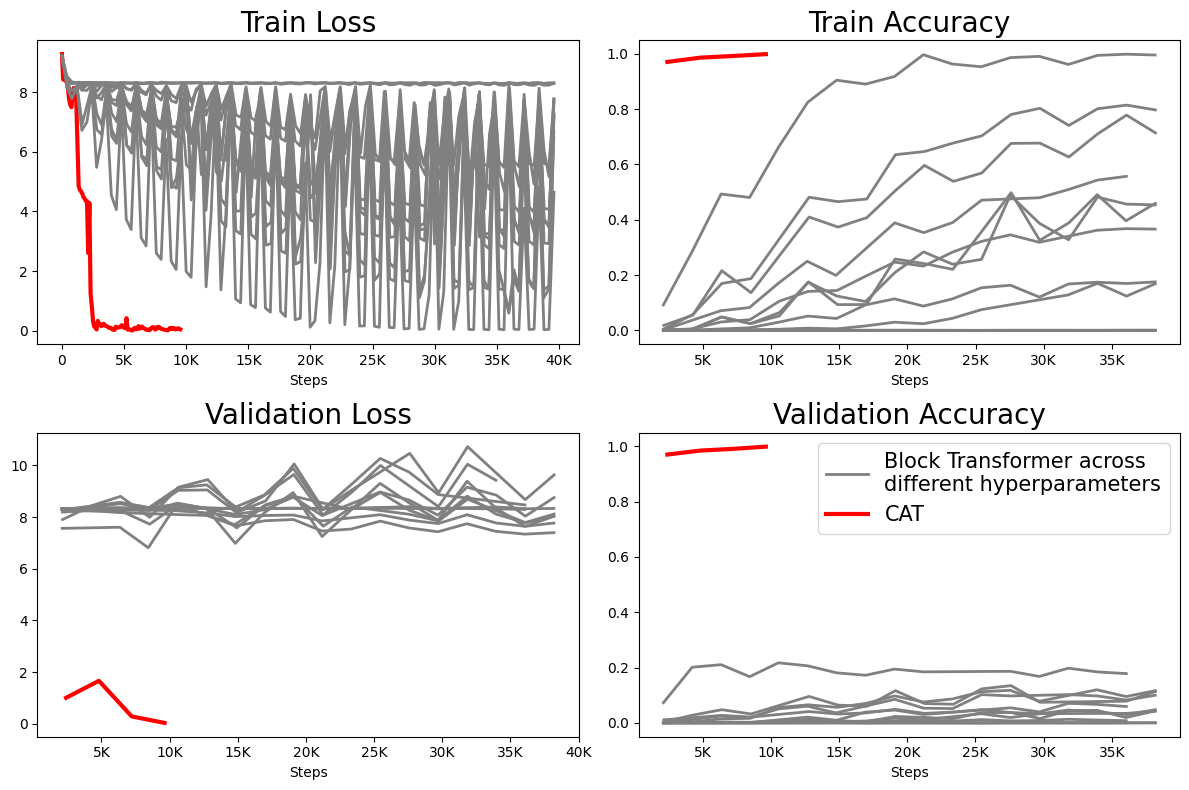
- Empirical results show that cat outperforms dense transformers in in-context recall and generation speed, achieving up to 3× faster throughput with lower memory usage.
Introduction and Motivation
The paper presents the Compress and Attend Transformer (cat), an architecture that addresses the quadratic computational and linear memory scaling of self-attention in dense transformers, particularly as applied to long-context LLMs. Unlike prior efficiency-focused architectures—such as sparse attention, sliding window methods, and linear recurrent mixers—which fix the quality-efficiency trade-off and often require heuristic design or complex recurrent update rules, cat leverages two fundamental concepts: dense attention and parallelizable compression. Cat provides a structured yet flexible mechanism to trade memory and compute for quality by chunking the sequence, compressing chunks with a learnable transformer-based compressor, and decoding with a dense transformer decoder that attends to compressed context. This yields adaptive control of efficiency/quality at test time, with a single model capable of spanning the quality-efficiency trade-off spectrum without retraining.
Notably, cat can be trained with multiple chunk sizes in a single run, unlocking post hoc test-time control. Empirical results show that cat achieves strong language modeling and reasoning performance, efficient scaling with model size, and superior in-context recall at memory-parity relative to other efficient or hybrid approaches. Intriguingly, in several practical regimes, cat even outperforms dense transformers in recall accuracy while using significantly less memory and offering increased throughput.
Figure 1: cat unlocks test-time control of quality-efficiency trade-offs, where a single adaptive cat model outperforms major efficient architectures on in-context recall across compute-memory budgets.
Architecture and Implementation Details
At the core of cat is a simple but effective abstraction:
- The token sequence x=(x1,x2,...,xN) is split into NC=⌈N/C⌉ chunks of C tokens each.
- Each chunk ci is compressed by a dense bidirectional transformer fθ into a fixed-sized vector fθ(ci)∈RDg.
- The decoder gθ (a causal dense transformer) autoregressively generates each token in chunk ci conditioned on previous tokens in the chunk and the compressed representations of all previous chunks {fθ(cj)}j<i.
This results in a recurrent, chunkwise context representation, yet all compression and decoding steps can be parallelized in training, sidestepping slow sequential computation present in earlier compressive or recurrent designs. Training employs a next-token prediction loss, with the architecture supporting efficient manipulation of chunk size both during and after training.
Efficient implementation is achieved via an augmented attention mask which interleaves compressed chunk representations among the tokens and restricts attention as needed to allow for key-value re-use and efficient quadratic compute (O(N2/C) as opposed to O(N2) in vanilla transformers), fully supported in frameworks like PyTorch using custom attention APIs such as FlexAttention. Generation is even more efficient, as past raw tokens can be discarded and only compressed chunk representations are kept in the attention cache, yielding direct memory savings up to the chunking factor C.
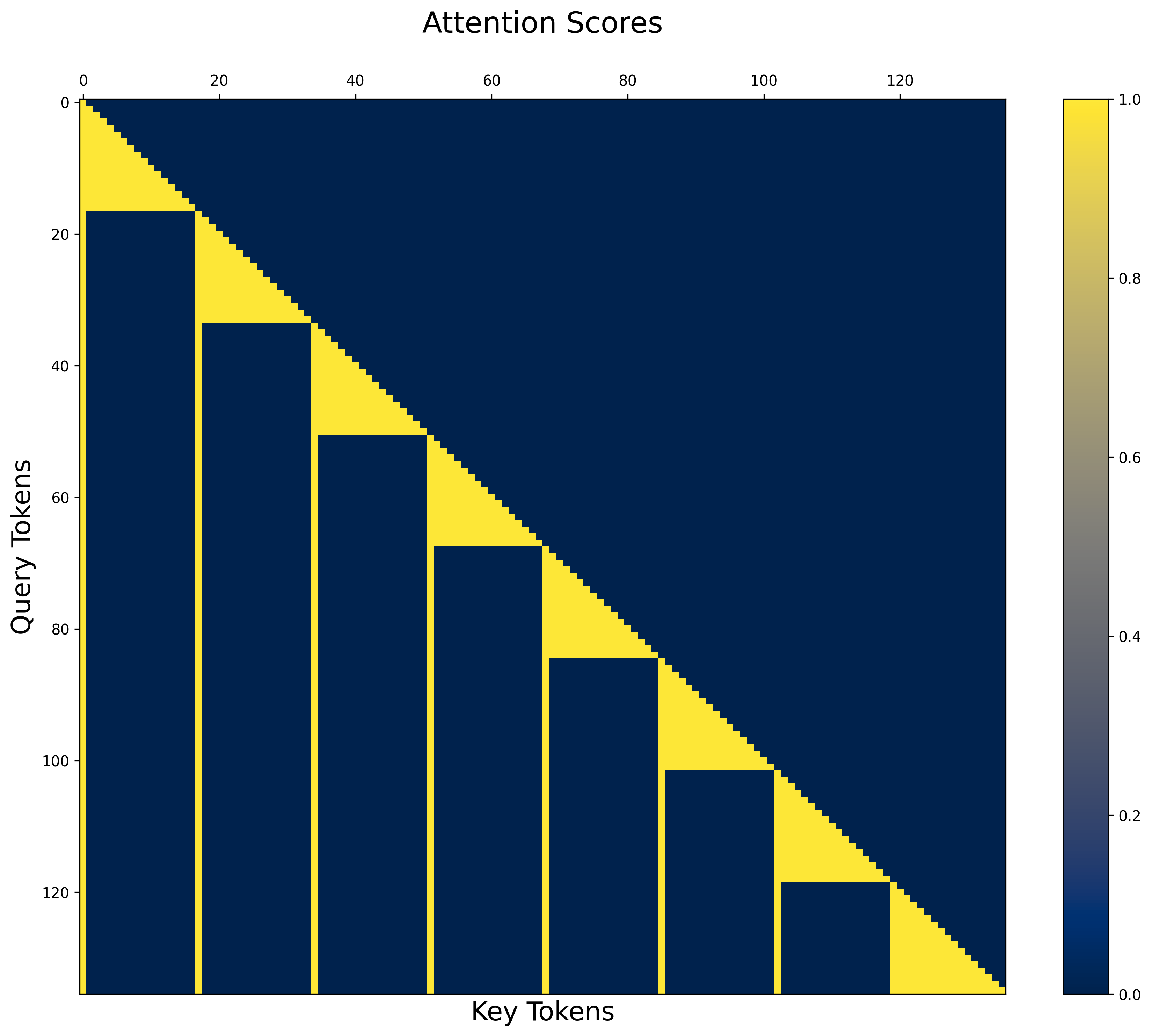
Figure 2: Sequence length is 128, and the attention mask shows chunk size C=16.
Pseudocode for both training and generation is provided in the appendix of the paper, demonstrating performant implementation feasible with standard deep learning libraries, without the need for custom CUDA/Triton kernels.
Adaptive Chunk Training for Test-Time Control
A critical practical innovation in cat is adaptive training: rather than fixing chunk size, cat can be trained via randomized sampling of chunk sizes (and corresponding indicator tokens signaling chunk size) at each iteration. This results in a single model which can be flexibly deployed at various efficiency-quality points by changing an indicator token and the chunking pattern at test time, with no retraining required. This stands in sharp contrast to prior methods which bind the quality-efficiency trade-off at train time, or require training and maintaining separate models for each operational regime.
Empirical Evaluation and Results
cat was benchmarked comprehensively against standard and efficient transformer baselines—Dense Transformer, Sparse Transformer, Linear (Mamba2), GatedDeltaNet (GDN), and hybrid architectures—across language modeling, common-sense reasoning, long-context understanding, in-context recall, and synthetic recall/needle-in-haystack tasks.
Key empirical findings:
- Language Modeling/Reasoning: All chunked cat variants (with chunk sizes C=4,8,16,32) match or outperform baselines on language modeling and reasoning, with cat-32 performing best on short sequence benchmarks; all cats outperform other efficient baselines on common-sense reasoning (see Table 1 in the paper).
- In-Context Recall and Long Contexts: cat's memory grows gracefully with sequence length, and it outperforms all efficient baselines, including dense and hybrid models, at similar or lower memory/computation, especially for moderate chunk sizes. At chunk sizes C=4,8 cat even exceeds dense transformer in in-context recall at 2×+ memory efficiency. For long context tasks, degradation with context length is slower in cat as compared to all other approaches.
- Generation Efficiency: cat generation throughput is $1.4$--3.2× higher than dense transformer, with $2.2$--9.5× lower memory usage as chunk size increases, despite increased total model parameters.
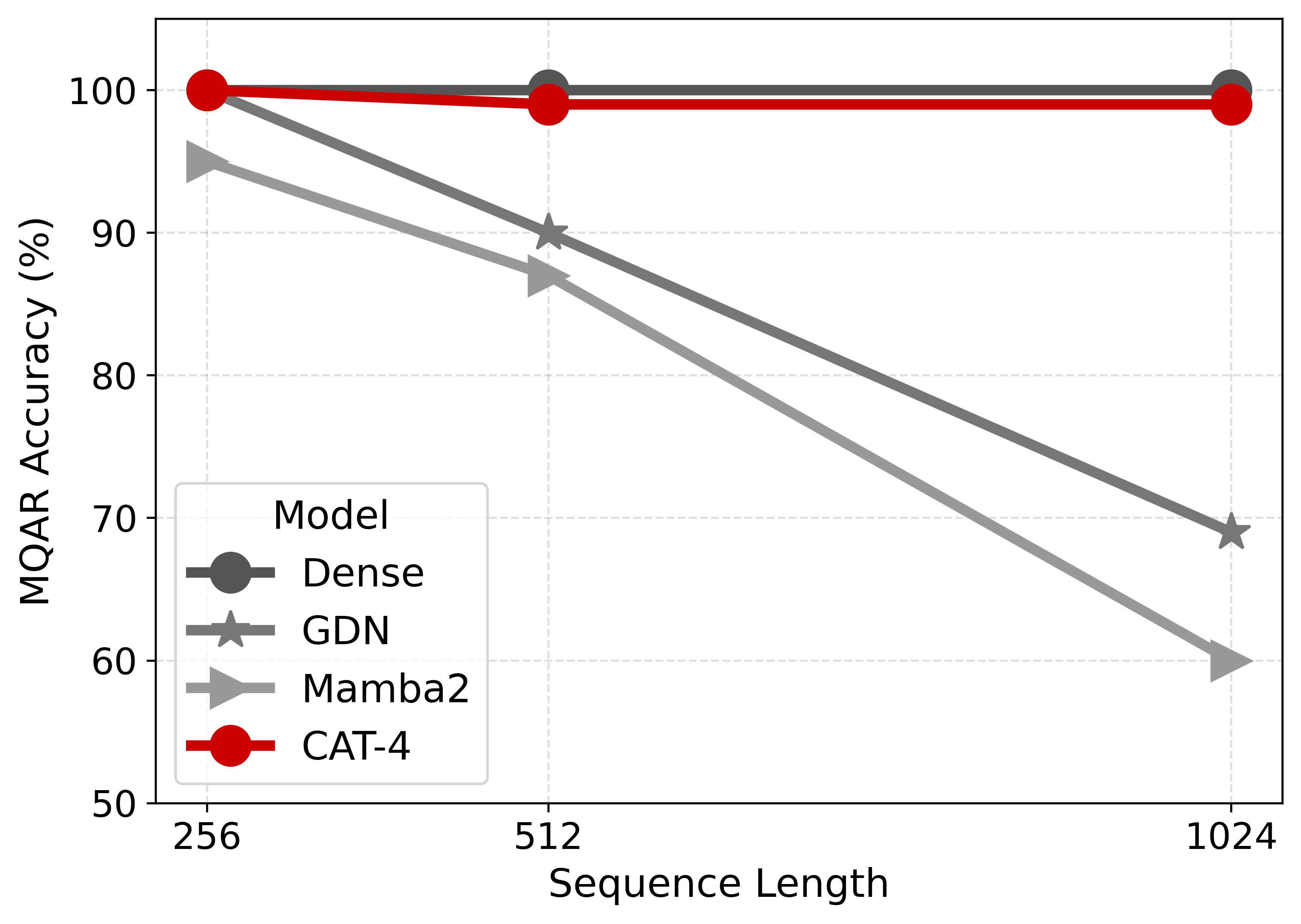
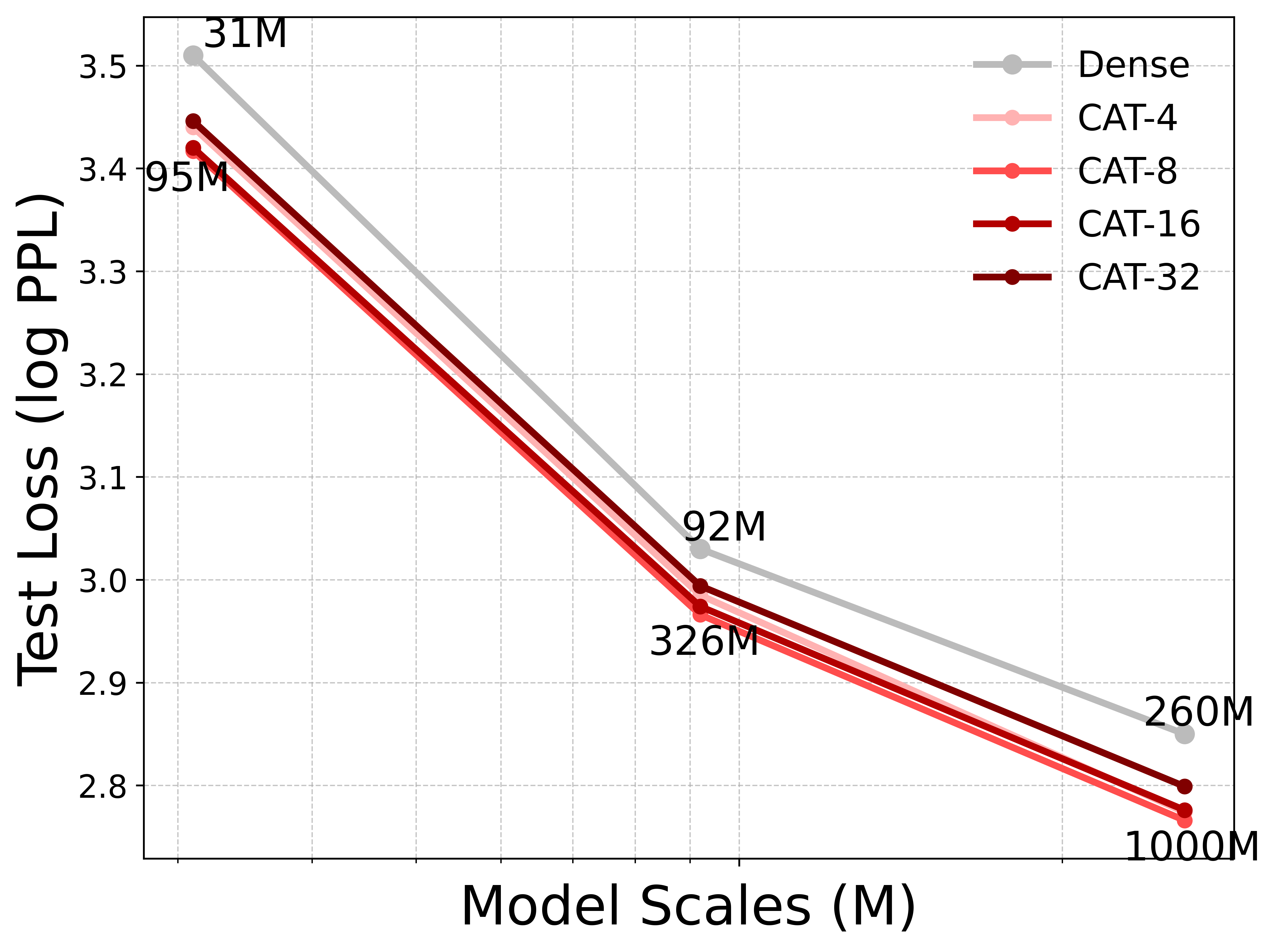
Figure 3: Left: On MQAR, cat outperforms baselines at long sequences, memory-matched. Right: cat scaling mirrors dense transformers, but is up to 3× faster and 9× more memory efficient.
- Scaling Behavior: Cat models scale similarly to dense transformers with respect to model size and training data, showing no adverse effect on loss curves or perplexity.
- Chunk Size Trade-off: cat acts as a controllable test-time knob; increasing chunk size improves efficiency at the cost of slight recall/perplexity degradation, allowing practitioners to select trade-offs appropriate to their deployment or application context.
cat is architecturally distinct from both block/chunk-based models (e.g., Block Transformer, MegaByte) and memory-efficient recurrent/linear attention mixers:
Implementation Considerations and Limitations
An efficient implementation of cat's custom attention mask is currently more expensive to compile than native FlashAttention, leading to somewhat increased training time (∼2.35× at $4096$ seq length), though inference/generation is fully efficient and scalable. Memory efficiency is especially pronounced at high batch sizes and long contexts, which are critical in applications such as code generation, multi-user LLM deployment, and large-scale RL rollouts.
cat requires users to select chunk size at test time, but this can be made adaptive (even data-driven) with further work, potentially unlocking true context- and task-based efficiency routing. Furthermore, cat can be integrated as a composable layer rather than a full architecture, enabling hybrid and modular designs.
A limit remains on how much information can be faithfully encoded in fixed-size chunk representations—as context length and chunk size rise, recall fidelity for extremely long targets may degrade unless the compressor/decoder is sufficiently expressive (which may increase parameters, but not FLOPs per generation step).
Future Directions
cat opens pathways for more adaptive, data-dependent allocation of compute/memory budgets, via techniques such as reinforcement learning-based budgeting or task-aware dynamic chunk sizing. The compressor and decoder modules can, in principle, use any sequence-mixing primitive, not limited to transformers. Integration with Grouped Query or Multi-Query Attention, further hardware-optimized attention kernels, and combination with post-hoc cache sparsification can push the memory and compute savings further. Large-scale pretraining and evaluation on industrial workloads will clarify the full potential and operational advantages, especially for extremely long-context applications.
Conclusion
The Compress and Attend Transformer (cat) provides a conceptually simple yet highly effective architecture for controllably efficient sequence modeling. By chunking and compressing sequences before dense attention-based decoding, cat enables a single model to operate efficiently across a variety of compute/memory regimes, delivering superior recall and matching language modeling quality observed in dense transformers, while drastically lowering resource requirements and increasing generation throughput. Cat thus offers both a new baseline for efficient, long-context LLMs and a flexible toolkit for balancing quality and efficiency at deployment time.