Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution
Abstract: Memory consumption of the Key-Value (KV) cache represents a major bottleneck for efficient LLM inference. While attention-score-based KV cache pruning shows promise, it faces critical practical limitations: attention scores from future tokens are unavailable during compression, and modern implementations like Flash Attention do not materialize the full attention matrix, making past scores inaccessible. To overcome these challenges, we introduce $\textbf{Expected Attention, a training-free compression method}$ that estimates KV pairs importance by predicting how future queries will attend to them. Our approach leverages the distributional properties of LLM activations to compute expected attention scores in closed form for each KV pair. These scores enable principled ranking and pruning of KV pairs with minimal impact on the residual stream, achieving effective compression without performance degradation. Importantly, our method operates seamlessly across both prefilling and decoding phases, consistently outperforming state-of-the-art baselines in both scenarios. Finally, $\textbf{we release KVPress, a comprehensive library to enable researchers to implement and benchmark KV cache compression methods, already including more than 20 techniques}$.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tackles a big practical problem when running LLMs: memory. LLMs keep a running “notebook” of past information called the KV cache so they can pay attention to earlier words as they generate new ones. But this notebook grows with every token and can eat up huge amounts of GPU memory.
The authors introduce a new, training-free way to shrink that notebook—called Expected Attention—by predicting which past pieces will matter most for future words, and safely throwing away the rest without hurting the model’s answers.
What questions are the authors trying to answer?
The paper focuses on three simple questions:
- Can we decide which saved pieces of context (KV pairs) a model will likely need later, even before those future words are generated?
- Can we do this without retraining the model or changing its architecture?
- Will this work both when the model is reading the long prompt (prefilling) and when it’s writing its answer one token at a time (decoding)?
How does the method work? (Everyday explanation)
Think of the model’s KV cache like a wall full of sticky notes:
- Each sticky note holds a small summary of one earlier token (a key and a value).
- When the model generates the next word, it shines a “spotlight” over the wall to pick the most relevant notes (attention).
- Over time, the wall fills up. If you never clean it, you run out of space (memory).
The challenge:
- We want to toss unimportant sticky notes to free up space.
- But we don’t know exactly which notes future words will look at, because the model hasn’t made those future queries yet.
- Also, modern fast attention code doesn’t save the full attention map, so we can’t just read it back to decide.
The idea: Expected Attention
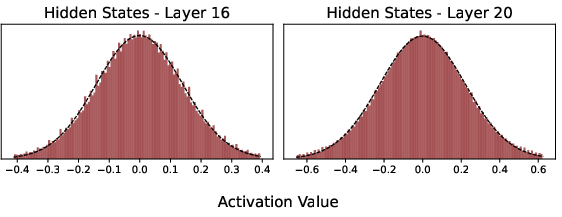
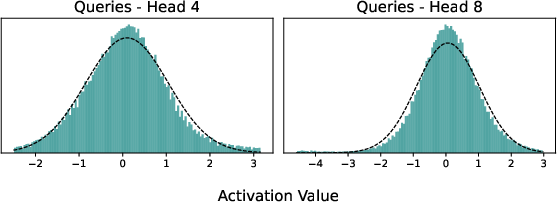
- The authors noticed that the model’s internal signals (its hidden states and queries) usually cluster around a “bell curve” pattern. That means we can estimate, on average, how much attention future queries will give to each existing sticky note—without knowing the exact future words.
- In plain terms: instead of asking “Will this note matter to the exact next word?”, they estimate “On average, over the next stretch of words, how much will this note be looked at?”
- They turn this estimate into an importance score for every sticky note and keep only the most important ones.
- They also consider that different “attention heads” (think of them as team members with different jobs) might need different amounts of memory, and they adapt the budgets per head.
Key points about the method:
- Training-free: no extra learning or fine-tuning needed.
- Works in both phases:
- Prefilling: when the model is reading and setting up the cache.
- Decoding: when the model is writing the answer step by step.
- Plug-and-play: no architecture changes; it uses statistics the model already produces.
What did they find, and why is it important?
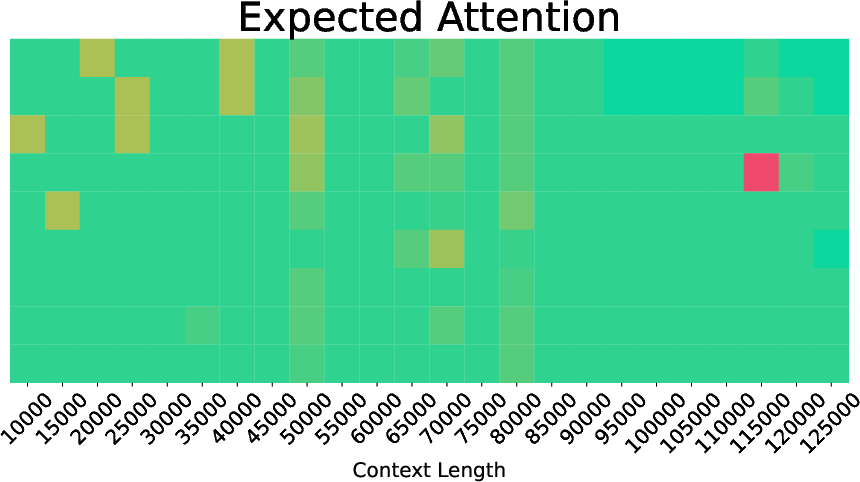
Across many tests and models (like Llama 3.1, Qwen 3, Gemma 3), Expected Attention shrinks the KV cache while keeping performance strong.
Highlights:
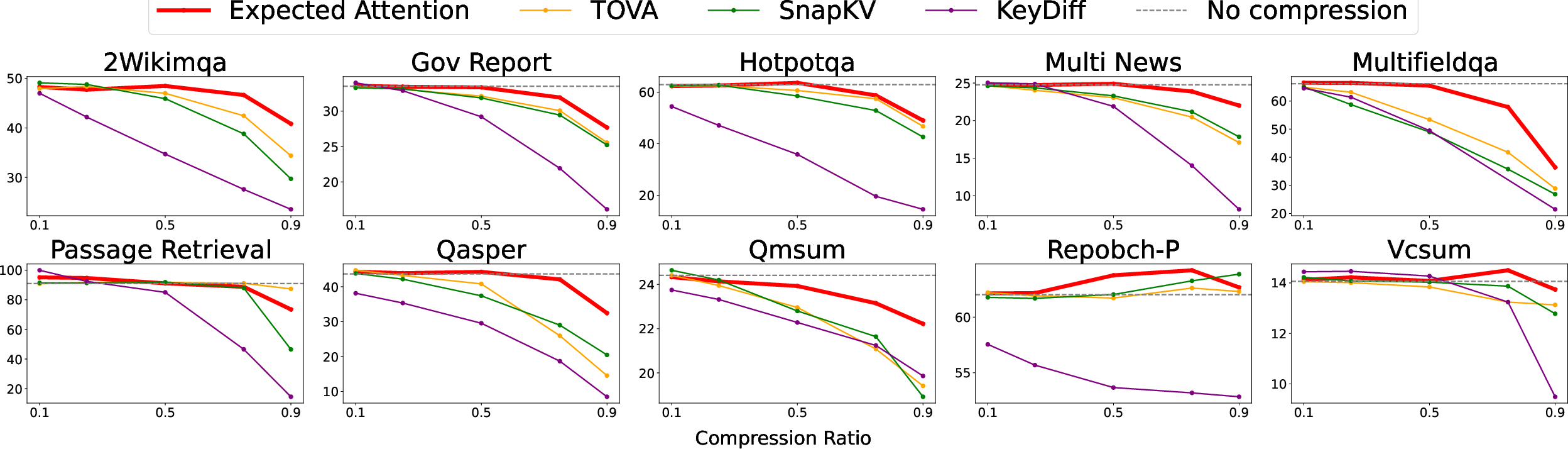
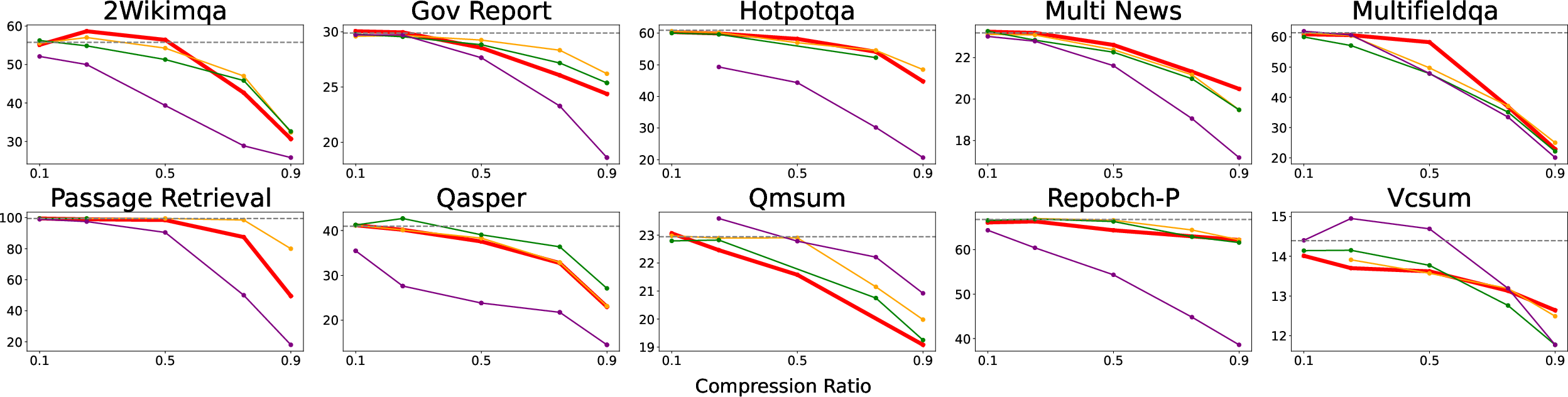
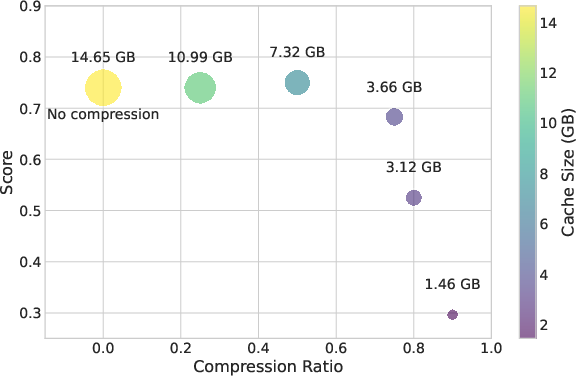
- Strong compression with minimal accuracy loss: The method can often remove around 50–60% of the cache while keeping results close to the original.
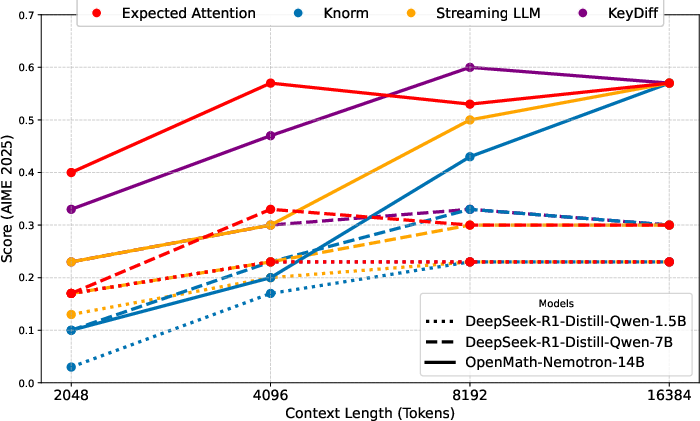
- Works broadly: It performs well on long-context reading tasks (LongBench, Ruler, Needle-in-a-Haystack) and on step-by-step reasoning/math tasks (AIME25, MATH-500).
- Prefilling and decoding: It reliably helps in both phases, which is crucial for real-world use.
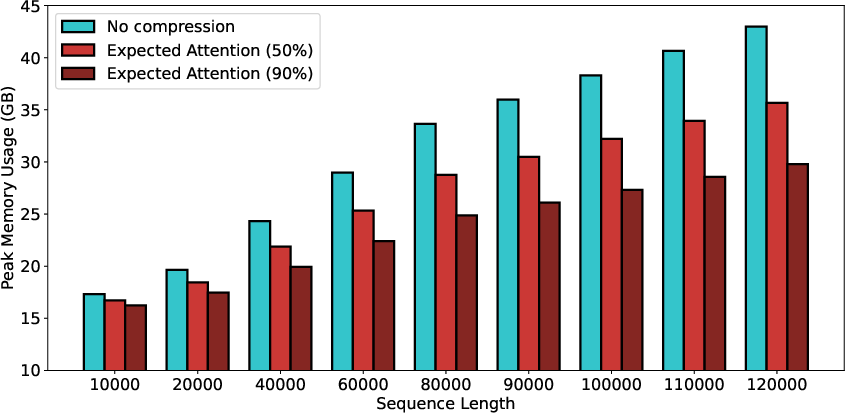
- Memory savings: At 50% compression, they show near-baseline performance on some tests with about half the memory. As the context gets longer, savings become even more valuable.
Why this matters:
- Many exciting LLM uses need huge contexts (like reading long documents, codebases, or video transcripts) or produce lots of reasoning steps. Memory quickly becomes a wall. By keeping only the most useful pieces, you can fit more context or serve more users on the same hardware.
What’s the bigger impact?
- Cheaper, longer, and more reliable LLM runs: You can handle longer inputs and longer reasoning traces on limited GPUs without retraining your model.
- Ready for today’s models: Since it doesn’t change the architecture or require training, you can apply it to existing checkpoints.
- Plays well with others: It’s compatible with other memory-saving ideas like quantization (storing numbers with fewer bits), so teams can combine techniques.
- Community tools: The authors released KVPress, a library with 20+ methods (including Expected Attention) and a public leaderboard to fairly compare approaches. This helps researchers and engineers develop and test new ideas faster.
Limitations and future directions
- Not a silver bullet: Some trainable approaches can still be stronger, but they require expensive extra training. Expected Attention trades a bit of peak performance for simplicity and practicality.
- Manual settings: You still choose how much to compress (the “ratio”), which might need tuning for different tasks.
- Prototype speed: The open-source code favors clarity over raw speed; a highly optimized version could be even faster.
Overall, this work shows a practical, theory-backed way to predict what future words will care about and keep only the most useful pieces of the past. That makes running large models on long contexts much more feasible in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains uncertain, missing, or unexplored, framed to guide follow-up research:
- Validity of Gaussian assumption for activations
- How robust is the method when hidden states/queries deviate from Gaussianity (e.g., heavy tails, multi-modality, anisotropy, layer/head-specific non-Gaussian behavior)?
- Are there layers/heads or tasks (code, math, vision tokens) where the Gaussian fit is systematically poor, and how does that affect compression accuracy?
- Covariance estimation under severe sample constraints
- In decoding, covariance is estimated from a 128-token buffer while the head dimension d is often comparable or larger; what is the impact of ill-conditioned or rank-deficient covariance estimates on scores?
- Do shrinkage/diagonal/low-rank covariance estimators improve stability/accuracy, and what is the best-in-class estimator for this use case?
- Averaging future RoPE matrices
- Averaging RoPE over T future positions yields a matrix that is not a rotation; what error does this introduce in practice, and can alternatives (e.g., sampling future positions, distribution over lengths, or analytic integration over rotations) reduce bias?
- How sensitive is performance to T (e.g., T=512), and should T adapt to anticipated remaining generation length or task?
- Approximating contribution without W_o
- The method replaces ||W_o v|| with ||v|| for efficiency; how much accuracy is lost per layer/head/model, and can cheaper surrogates (e.g., precomputed per-head scaling, low-rank W_o) recover most of the benefit?
- Head- and layer-adaptive budgeting
- What is the optimal policy for allocating per-head/per-layer budgets (beyond adopting AdaKV heuristics)? Can learned or online-adaptive budgets improve compression-accuracy trade-offs?
- Scoring frequency and scheduling
- What is the best compression schedule (e.g., pruning cadence, incremental updates, blockwise rescoring) for different workloads, and how does it affect latency/throughput and accuracy?
- Computational overhead and serving impact
- End-to-end latency/throughput overhead of computing mean/covariance, expected scores, and top-k selection is not reported; what is the real-world serving cost at scale, especially for million-token contexts?
- Can the scoring be fused into attention kernels (e.g., FlashAttention) or computed incrementally with negligible overhead?
- Theoretical guarantees
- Are there bounds relating expected attention to true future attention or to downstream loss degradation under the stated assumptions?
- Can we characterize worst-case errors when the distributional assumptions are violated?
- Interaction with QK normalization and attention variants
- How does the approach behave under QK-normalization, ALiBi, YaRN, linear/compound position encodings, or other attention variants?
- Does the expected-attention ranking remain stable across such modifications?
- Multi-turn and query-aware scenarios
- The prefilling evaluation assumes no access to user queries; can incorporating query-aware information when available further improve performance, and how should the method transition between query-agnostic and query-aware regimes in multi-turn dialogue?
- Task and modality generalization
- Robustness across languages, domains (code-heavy corpora), and modalities (vision tokens in VLMs) is untested; do query distributions remain well-modeled, and does pruning preserve cross-modal grounding?
- Large-scale model generalization
- Results focus on 8–14B models; do findings hold for 30B–70B+ models and MoE architectures, especially under extreme context lengths where KV cache dominates memory?
- Extremely high compression regimes
- What are the practical limits of compression (e.g., >90%) before catastrophic degradation, and can hybrid policies (e.g., combining sinks, recency, and expected attention) extend these limits?
- Safety-critical and generative quality effects
- Beyond retrieval/reasoning benchmarks, how does compression affect hallucination rates, faithfulness, instruction following, and long-form generation quality?
- Multi-head coordination
- The method ranks KV pairs per head; can cross-head coordination (e.g., joint selection to avoid redundant retention or accidental simultaneous deletion) improve retention of complementary information?
- Position/recency biases
- How does expected attention compare to explicit position-aware policies (e.g., sliding windows, sinks) across tasks, and can combined policies better capture both global importance and recency?
- Recovery/reconstruction of evicted context
- Methods like KV reconstruction (e.g., KVzip) can restore pruned context; can expected attention guide what to reconstruct or when to rehydrate evicted tokens?
- Online adaptation and drift
- Hidden-state/query statistics may drift within a document or across turns; can the method detect and adapt to non-stationarity (e.g., change-point detection, time-varying priors)?
- Hyperparameter sensitivity and auto-tuning
- Sensitivity to ε, T, buffer size, pruning ratio, and pruning cadence is not systematically studied; can we design automatic controllers to select compression ratios and estimator settings given latency/memory targets?
- Compatibility with quantization and other orthogonal methods
- Although orthogonal, no empirical study shows combined gains with KV quantization, sparse attention, or architectural long-context optimizations; what are best-practice stacks for cumulative savings?
- Memory fragmentation and allocator behavior
- Practical serving often suffers from fragmentation; does pruning policy interact with memory allocators (e.g., paged attention systems), and can scores inform compaction-friendly eviction?
- Error analysis by task type
- Which tasks fail under compression and why (e.g., multi-hop tracking vs. aggregation vs. needle retrieval)? Can task-aware priors or head/task specialization mitigate specific failure modes?
- Robustness under streaming constraints
- When outputs become highly peaky or repetitive during decoding, do the query statistics become degenerate and mislead pruning? Are safeguards needed (e.g., floor on recency, entropy-based checks)?
- Open-source reproducibility gaps
- The paper introduces KVPress but does not report cross-hardware reproducibility or sensitivity to implementation choices (hooks timing, precision, fused ops). What is the variability across backends and GPU architectures?
- Privacy/security implications
- Does selective retention alter exposure of sensitive content in long contexts? Are there adversarial prompts that manipulate statistics to force retention/deletion of specific tokens?
These points outline concrete avenues for empirical validation, theoretical analysis, system-level optimization, and broader applicability studies.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage Expected Attention and the KVPress library to reduce KV-cache memory while maintaining task quality.
- Memory-efficient LLM serving for long-context workloads (software/cloud)
- What: Halve or more the KV-cache footprint for chat, summarization, RAG, and code-assist services without retraining.
- How: Integrate Expected Attention as an eviction policy in inference stacks (e.g., adapt KVPress hooks within
transformers, prototype with Hugging Face, then port tovLLMorTensorRT-LLM). - Benefits: Higher user concurrency on the same GPU budget; lower latency and cost; compatibility with Flash Attention.
- Assumptions/Dependencies: Hidden states approximately Gaussian; instruction-tuned LLMs using RoPE; manual compression ratio tuning; modest accuracy loss at 50–60% KV reduction.
- Cost and energy savings in data centers (energy, software/cloud, sustainability)
- What: Reduce GPU count or raise throughput for long-context inference services.
- How: Deploy Expected Attention during both prefilling and decoding to constrain KV growth; add a runtime “compression ratio” slider in serving dashboards.
- Benefits: Lower energy per request; smaller capex/opex; greener operations.
- Assumptions/Dependencies: Workload tolerates small accuracy changes; standardized monitoring of energy and accuracy metrics.
- On-prem and edge deployment of long-context LLMs (healthcare, finance, manufacturing, public sector)
- What: Run million-token contexts on constrained hardware for private corpuses (EHRs, regulatory filings, SOPs).
- How: Enable KV eviction at prefill and decode; keep sink tokens or critical segments pinned while pruning the rest.
- Benefits: Privacy-preserving, local inference with extended context; reduced hardware requirements.
- Assumptions/Dependencies: Local GPU/accelerator availability; careful ratio selection for critical tasks.
- Legal discovery and compliance review at scale (legal, finance, public sector)
- What: Review and retrieve facts from large document sets without exceeding GPU memory.
- How: Use Expected Attention in the prefill pipeline; combine with RAG to preserve retrieved passages while compressing less-relevant context.
- Benefits: Faster turnaround on eDiscovery, audits, and filings; sustained retrieval performance under compression (demonstrated on NIAH/Ruler).
- Assumptions/Dependencies: PDFs/text normalized into token streams; retrieval workloads similar to benchmark characteristics.
- Large-repository code assistance and CI automation (software engineering)
- What: Analyze multi-repo codebases and long logs with limited GPUs.
- How: Apply Expected Attention during prefill of repository context; compress during long chain-of-thought decoding (reasoning models).
- Benefits: Longer context windows for static analysis, code review, and incident triage; reduced memory bottlenecks in CI pipelines.
- Assumptions/Dependencies: Stable performance on code tasks; head-adaptive compression tuned per model.
- Multi-round tutoring and LLM-powered learning platforms (education)
- What: Maintain long chat histories and multi-document lesson contexts without memory blowups.
- How: Evict lowest-contribution KV pairs; keep curriculum-critical tokens via head-adaptive retention.
- Benefits: Personalized tutoring with persistent context; improved device affordability for schools.
- Assumptions/Dependencies: Minor accuracy trade-offs acceptable; context content varies across lessons.
- Agentic workflows with extensive chain-of-thought (software/automation)
- What: Let task agents generate lengthy reasoning traces while staying within KV budgets.
- How: Budget KV per agent; compress every N steps during decoding as in the paper’s setup.
- Benefits: Stable math/reasoning performance at 2–4× compression (AIME25, MATH-500); better multi-agent scalability.
- Assumptions/Dependencies: Agents tolerate small degradation; buffer of recent hidden states available to compute statistics.
- Academic benchmarking and method development (academia)
- What: Reproduce, compare, and extend KV compression methods with a standardized framework.
- How: Use
KVPresshooks, the public leaderboard, and long-context suites (LongBench, Ruler, NIAH). - Benefits: Faster prototyping; fair comparisons across 20+ baselines; reproducible results.
- Assumptions/Dependencies: PyTorch/Hugging Face stack; acceptance of research-oriented (not fully optimized) runtime.
- Privacy-preserving local assistants for daily use (daily life, consumer devices)
- What: Longer conversations and larger document summaries on personal GPUs/NPUs.
- How: Enable Expected Attention-based pruning in desktop/server setups; adjust compression ratio per task.
- Benefits: Offline reading/summarization of books, emails, and meetings with extended context.
- Assumptions/Dependencies: Availability of local accelerators; potential need for future kernel optimizations for speed.
Long-Term Applications
These use cases require additional research, scaling, or engineering (e.g., optimized kernels, adaptive control policies, sector-specific safeguards).
- Production-grade CUDA kernels and engine integrations (software/cloud)
- What: High-performance, low-level implementations compatible with
FlashAttention,vLLM,TensorRT-LLM. - Outcome: Lower latency and overhead, enabling widespread commercial adoption.
- Assumptions/Dependencies: Dedicated kernel engineering; end-to-end profiling; API stability in serving frameworks.
- What: High-performance, low-level implementations compatible with
- Auto-tuning and adaptive compression policies (software/cloud, research)
- What: Dynamically choose compression ratios per task/user/session using signals like uncertainty, retrieval density, or latency SLAs.
- Product idea: “AutoKV” controller that balances accuracy and cost in real time.
- Assumptions/Dependencies: Reliable task-quality proxies; safe default policies; robust fallback mechanisms.
- Sector-specific safety and compliance policies (healthcare, finance, public sector)
- What: Policies that preserve critical tokens (diagnoses, legal citations, risk factors) while pruning others.
- Workflow: Annotate domain-critical spans; head-adaptive quotas per layer; combine with retrieval pinning.
- Assumptions/Dependencies: Domain ontologies; regulatory constraints; thorough validation on sector datasets.
- Hybrid trainable + Expected Attention compression (software/ML research)
- What: Lightweight fine-tuning to improve the Gaussian-based estimates or to learn better head budgets.
- Outcome: Higher accuracy at aggressive compression (8–12×) for sensitive tasks.
- Assumptions/Dependencies: Access to fine-tuning data; manageable compute budgets.
- Multimodal long-context compression (media, robotics, autonomous systems)
- What: Apply Expected Attention-like principles to video/audio transcripts and sensor logs for on-device planning.
- Outcome: Robots/assistants process long streams with constrained memory while retaining salient cues.
- Assumptions/Dependencies: Extension to multimodal attention blocks; validation under streaming conditions.
- Co-design with KV quantization (software/cloud, hardware)
- What: Combine eviction with per-layer/token precision reduction (e.g.,
KVQuant,KIVI) for maximal savings. - Product idea: “KVCompact” pipeline that orchestrates both strategies safely.
- Assumptions/Dependencies: Calibration to avoid compounding errors; model- and layer-specific tuning.
- What: Combine eviction with per-layer/token precision reduction (e.g.,
- Disaggregated prefill–decode services with slim cache transfer (cloud platforms)
- What: Compress caches before cross-node transfer to reduce network costs in split prefill/decoding architectures.
- Outcome: Lower bandwidth use; cost-effective distributed inference for million-token windows.
- Assumptions/Dependencies: Orchestration support; transfer protocol changes; compression-aware scheduling.
- Policy and sustainability reporting standards (policy, sustainability)
- What: Standard metrics/benchmarks for energy savings attributable to KV compression and long-context management.
- Outcome: Procurement guidelines encouraging memory-aware LLM deployments; public reporting of efficiency gains.
- Assumptions/Dependencies: Accepted measurement methodology; sector buy-in; independent audits.
- Meeting and knowledge management at extreme context lengths (enterprise, daily life)
- What: Persist and query months of transcripts, notes, and documents within practical memory budgets.
- Product idea: “Meeting Memory” that compresses non-critical KV while preserving action items and decisions.
- Assumptions/Dependencies: Reliable identification of critical spans; integration with organizational RAG and calendars.
Glossary
- AdaKV: A method for adaptive, head-specific KV cache compression in transformers. "Recognizing that different attention heads exhibit varying sensitivity to compression, recent methods such as AdaKV~\citep{adakv} and PyramidKV~\citep{pyramidkv} adopt head-specific compression strategies."
- Aime25: A benchmark of competition-level math problems for evaluating multi-step reasoning in LLMs. "We use the Aime25~\citep{yamada2025aiscientistv2workshoplevelautomated} and MATH-500~\citep{math500} datasets."
- Autoregressive generation: A token-by-token generation process where each new token depends on previously generated tokens. "During autoregressive generation, the KV cache stores key and value vectors for every processed token, enabling efficient attention computation."
- bfloat16: A 16-bit floating-point format commonly used to reduce memory and improve performance in deep learning. "All experiments are conducted on a single H100 GPU with bfloat16 precision for both model weights and KV cache."
- Decoding phase: The sequential token generation stage of LLM inference, using cached KV pairs and prior outputs. "The decoding phase sequentially generates tokens using the KV cache and previous logits, appending new key-value pairs iteratively~\citep{howtoscale, vllminternals}."
- Disaggregated architectures: Systems that split LLM inference between different hardware setups for prefill and decode to optimize performance. "This dichotomy has motivated disaggregated architectures that implement prefill and decoding on different hardware, at the cost of transferring the cache, further incentivising compression~\citep{disaggregated, step3}."
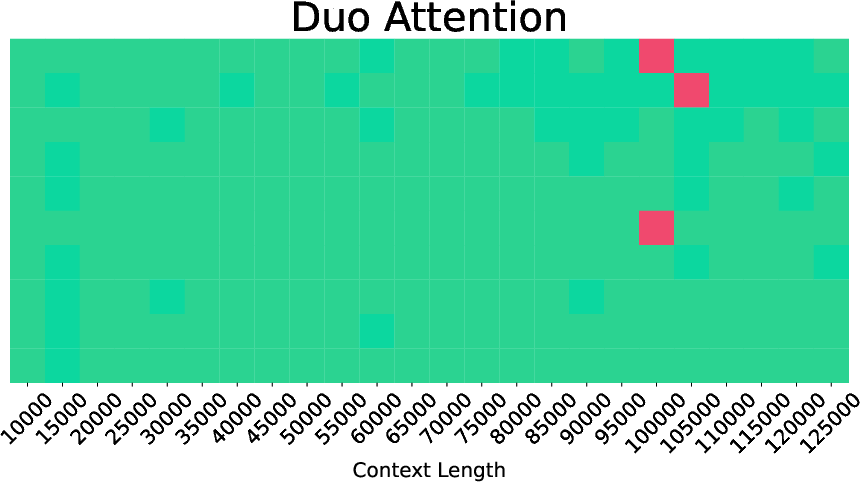
- DuoAttention: A trainable approach that learns compression masks for attention heads to enable efficient long-context inference. "DuoAttention~\citep{duoattention} takes a trainable approach, learning compression masks for each attention head."
- Expected Attention: A training-free method that estimates future attention weights from a distribution of future queries to rank and prune KV pairs. "To overcome these challenges, we introduce Expected Attention, a training-free compression method that estimates KV pairs importance by predicting how future queries will attend to them."
- Flash Attention: An optimized attention algorithm that computes attention without materializing the full matrix, reducing memory and IO costs. "modern implementations like Flash Attention do not materialize the full attention matrix, making past scores inaccessible."
- Gaussian distribution: A normal distribution assumed for LLM hidden states to analytically compute expected attention. "hidden states in modern LLMs loosely follow a Gaussian distribution ."
- Grouped Query Attention (GQA): A variant of attention where multiple queries share keys/values to reduce memory and computation. "noting that the following analysis naturally extends to multi-head attention, grouped query attention (GQA, \citealt{mqa}) and all their variants."
- Head-Adaptive Compression: A compression strategy that allocates different budgets per attention head based on importance. "Head-Adaptive Compression"
- Hugging Face transformers: A popular open-source library for building and running transformer-based models. "By natively integrating with Hugging Face transformers~\citep{transformers}, KVPress allows researchers to implement and test novel techniques rapidly and intuitively."
- KV cache: The memory of keys and values stored during inference to avoid recomputing attention projections. "A critical issue in deploying LLMs in such scenarios is the prohibitive memory consumption of the Key-Value (KV) cache~\citep{yaofu-long-context-challenge, kvreview, kvsurvey}."
- KV cache compression: Techniques that reduce the size or precision of the KV cache to lower memory usage. "We release KVPress, a comprehensive library to enable researchers to implement and benchmark KV cache compression methods, already including more than 20 techniques."
- KVPress: A PyTorch-based library for implementing and benchmarking KV cache compression methods. "We release KVPress, a comprehensive library to enable researchers to implement and benchmark KV cache compression methods, already including more than 20 techniques."
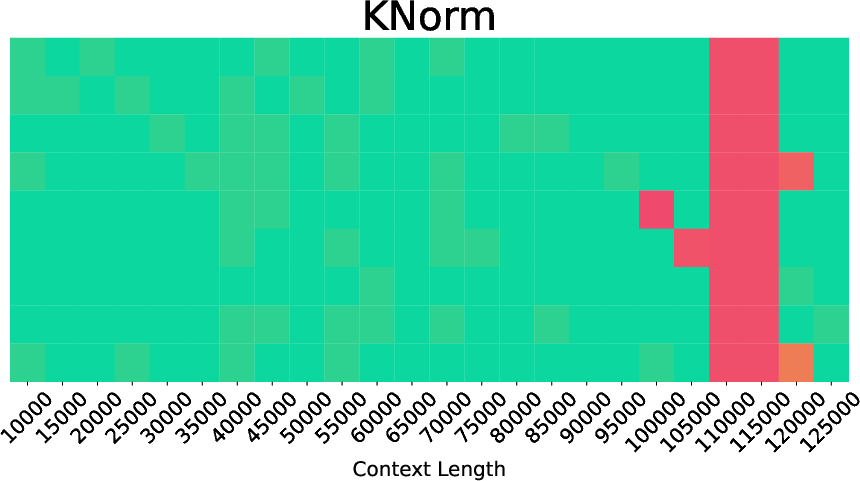
- L2 norm: The Euclidean norm used as a heuristic to rank or filter keys by magnitude. "KNorm~\citep{knorm} uses a simple approach by preserving keys with the lowest norm."
- LongBench: A benchmark suite for testing long-context understanding and generation across diverse tasks. "LongBench~\citep{longbench} tests long-context capabilities across diverse tasks."
- Logits: The pre-softmax output scores used to derive probabilities for next-token prediction. "The decoding phase sequentially generates tokens using the KV cache and previous logits, appending new key-value pairs iteratively~\citep{howtoscale, vllminternals}."
- Moment-generating function: A probabilistic tool used to compute expectations of exponential linear forms for Gaussian variables. "where the second equality follows from the moment-generating function of a Gaussian distribution."
- Multi-Head Latent Attention: A train-time modification that projects keys/values into a lower-dimensional latent space to shrink cache size. "Other architectural changes limited to the attention mechanism, such as multi-head latent attention~\citep{deepseekv2} or sliding window attention~\citep{mistral, gemma_2025}, reduce KV cache size but do not remove the attention bottleneck and are orthogonal to KV cache compression."
- Multi-head attention: An attention mechanism with multiple parallel heads to capture diverse relationships. "including feed forward networks and multi-head attention blocks."
- Needle in a Haystack: A long-context retrieval benchmark that evaluates whether a model can find a specific fact within distractors. "Needle in a Haystack~\citep{niah, lostinthemiddle}"
- Output projection matrix: The matrix W_o that maps attention head outputs back to the hidden state dimension. "and is the learnable output projection matrix."
- Prefilling phase: The parallel processing stage that encodes the entire prompt and fills the initial KV cache. "The prefilling phase processes the entire input prompt in parallel, computing key-value projections for the KV cache, a compute-bound operation requiring substantial floating-point operations."
- PyramidKV: A head-specific KV compression method based on pyramidal information funneling. "recent methods such as AdaKV~\citep{adakv} and PyramidKV~\citep{pyramidkv} adopt head-specific compression strategies."
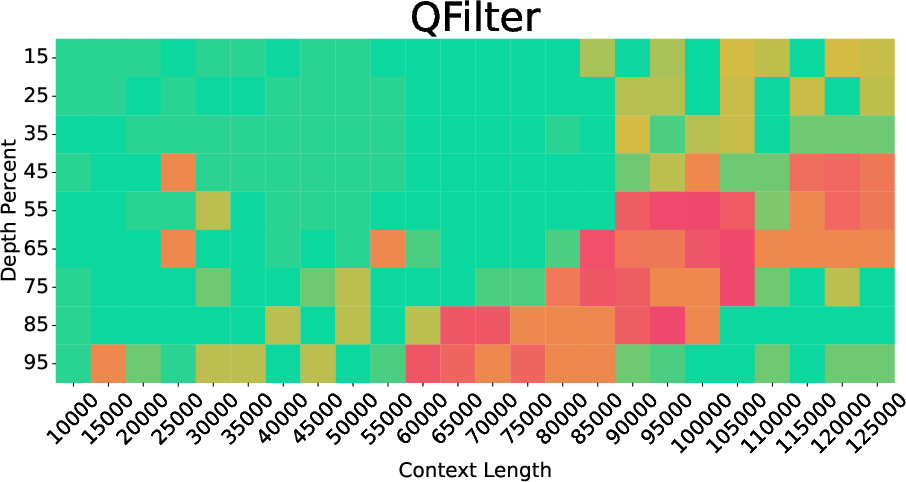
- Q-Filters: A compression approach leveraging the geometry of query-key spaces, often via SVD-based projections. "such as keys norm (KNorm~\citet{knorm}), token positions (StreamingLLM~\citet{streamingllm}, H2O~\citet{h2o}) or SVD projection (Q-Filters~\citet{qfilters})."
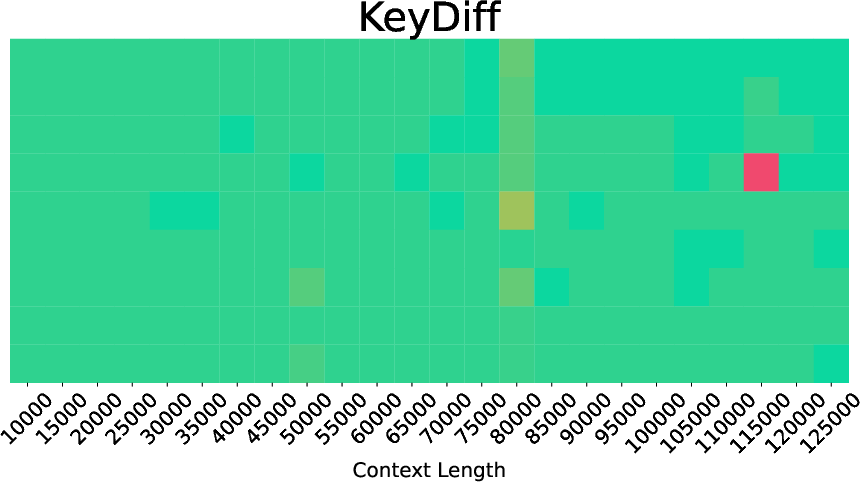
- QK normalization: A scaling or normalization applied to query-key interactions that can affect method performance across models. "While KeyDiff performs well on Llama3.1-8B, it struggles on Gemma3-12B and Qwen3-8B, potentially due to QK normalization~\citep{gemma_2025, qwen3}."
- Residual stream: The additive pathway in transformers where each block contributes vector updates to the hidden state. "The hidden states embedding represents the "residual stream,"~\citep{elhage2021mathematical} updated via vector additions by each transformer block."
- Rotary Position Embedding (RoPE): A positional encoding technique that rotates query/key vectors to encode relative positions. "where is the attention head dimension, is the Rotary Position Embedding (RoPE, \citealt{rope}) matrix at position "
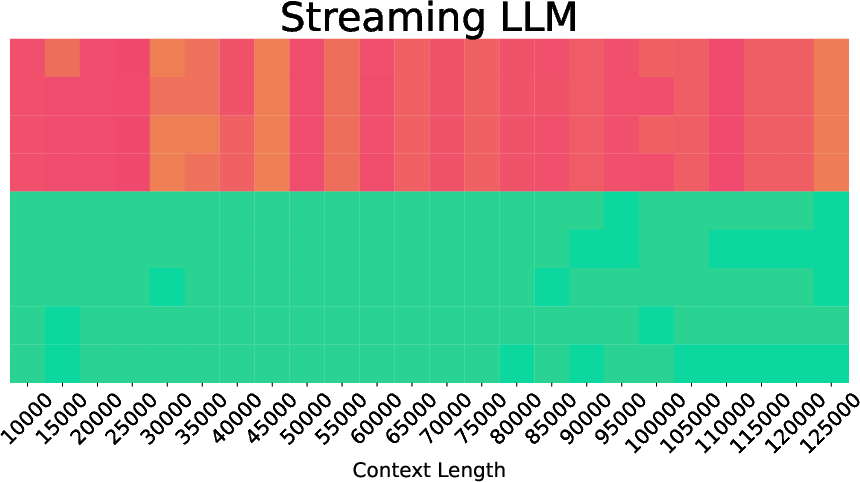
- Sink tokens: Special initial tokens kept throughout generation to stabilize attention during streaming. "StreamingLLM~\citep{streamingllm} maintains initial sink tokens throughout generation."
- Sliding window attention: An attention mechanism that restricts attention to a fixed-size window to reduce memory usage. "such as multi-head latent attention~\citep{deepseekv2} or sliding window attention~\citep{mistral, gemma_2025}, reduce KV cache size but do not remove the attention bottleneck and are orthogonal to KV cache compression."
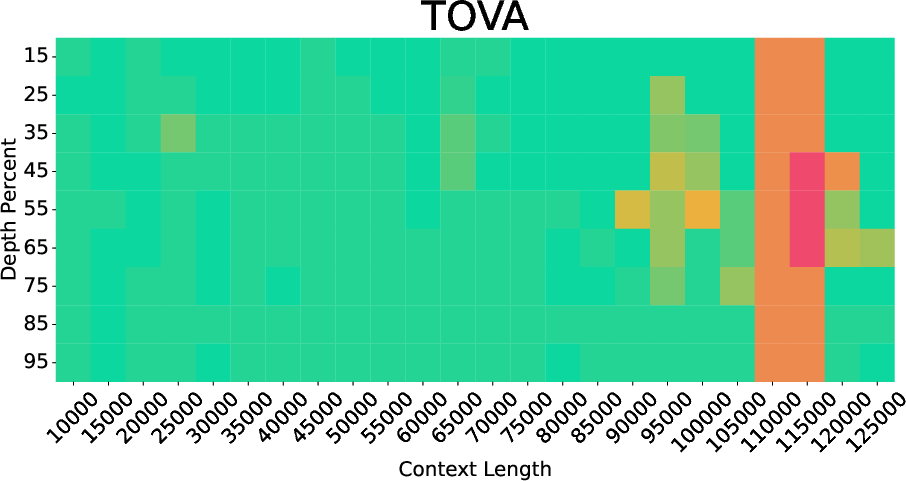
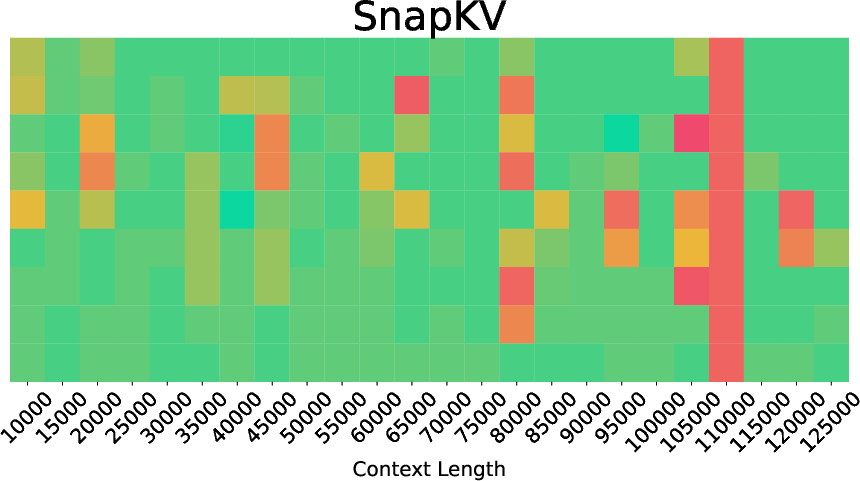
- SnapKV: A method that ranks KV pairs using attention scores from user queries for compression. "For prefilling, we evaluate attention-based approaches like SnapKV~\citep{snapkv} and TOVA~\citep{tova}, embedding-based KeyDiff~\citep{keydiff}, and the trainable DuoAttention~\citep{duoattention} when the checkpoint is available."
- Softmax: The normalization function that converts unnormalized attention scores into probabilities. "We then define the expected attention score by applying the softmax on our unnormalized expectation:"
- State Space Models: Sequence models with linear-time recurrence that reduce memory compared to transformers but may underperform on long contexts. "State Space Models offer a solution by reducing memory costs~\citep{ssm, mamba}, yet their inferior performance compared to transformers, especially on long context tasks, limits adoption~\citep{repeat, illusionof}."
- StreamingLLM: A streaming-friendly approach that preserves specific tokens during generation to manage KV cache growth. "StreamingLLM~\citep{streamingllm} maintains initial sink tokens throughout generation."
- TOVA: An attention-based compression baseline that uses query attention signals to rank KV importance. "For prefilling, we evaluate attention-based approaches like SnapKV~\citep{snapkv} and TOVA~\citep{tova}, embedding-based KeyDiff~\citep{keydiff}, and the trainable DuoAttention~\citep{duoattention} when the checkpoint is available."
- Unnormalized attention score: The exponential of scaled query-key dot products before softmax normalization. "and $z_{ti} = \exp\left( \frac{q_t^T k_i}{\sqrt{d} \right)$ represents the unnormalized attention score."
- vLLM: An inference system introducing efficient KV cache memory management for serving LLMs. "The first to investigate this and introduce efficient memory management for KV cache was vLLM~\citep{vllm}, soon followed by other approaches~\citep{vattention, minference} and frameworks~\citep{trtllm}."
Collections
Sign up for free to add this paper to one or more collections.