- The paper introduces a framework that decomposes exact self-attention into schedulable subproblems to prevent out-of-memory errors.
- It utilizes cyclic quorum set theory (CQS Divide) to partition the attention computation, ensuring each token interaction is computed exactly once.
- Empirical results demonstrate predictable memory scaling and effective scheduling for billion-token sequences on modern GPUs.
Stream-CQSA: Flexible Scheduling for Memory-Adaptive Attention
Introduction and Motivation
The scalability of long-context LLMs is critically limited by the quadratic memory cost of exact self-attention. This constraint is increasingly acute as context lengths approach millions or billions of tokens, rendering exact attention infeasible on contemporary hardware due to OOM failures. Existing solutions, such as FlashAttention and various approximate methods (sparse, low-rank, kernel-based), optimize internal implementation but fundamentally assume that the full Q, K, and V tensors can be resident in device memory. As such, these approaches become impractical when simply storing the collective QKV representations already suffices to exceed hardware limitations.
The present work introduces an alternative paradigm: Stream-CQSA, a memory-adaptive framework that removes the monolithic assumption and redefines exact attention as a collection of fully schedulable subsequence computations. The core insight is the decomposition of the attention problem via CQS Divide, a construction grounded in cyclic quorum set (CQS) theory. This enables guaranteed-exact coverage of the full sequence attention as the recomposition of smaller, independent attention computations, without any loss in fidelity or change in the underlying functional form.
CQS Divide: Combinatorial Decomposition of Attention
CQS Divide formulates the attention matrix as the union of fully covered pairwise interactions, partitioned into c subsequences derived from combinatorial designs—specifically, cyclic quorum sets, which connect to Steiner system S(2,l,c). The partitioning guarantees that every interaction is computed exactly once.
For l=3,c=7, the minimal non-trivial instantiation, the sequence is partitioned into seven chunks, and each subsequence aggregates QKV entries corresponding to three chunk indices in a fixed cyclic pattern (the interest set). Subsequence construction and masking rules ensure non-redundant computation:
- Subsequence Selection: Each subsequence selects tokens from three pre-specified chunks, cycling across all offsets.
- Masking: Structured chunk-level masking resolves overlaps, assigning each intra-chunk interaction exclusively to one subsequence to maintain exactness.
This operation is recursively applicable, allowing for arbitrary granularity of decomposition to fit any available device memory budget.
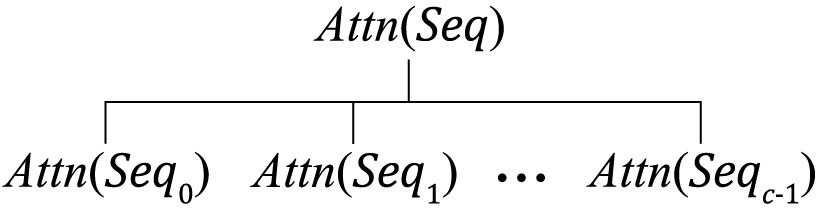
Figure 1: The CQS Divide process decomposes the full attention matrix into exactly covered, non-overlapping subproblems.
Stream CQSA Algorithmic Pipeline
Forward and Backward Passes
For each subsequence, attention is computed according to the CQS mask. The results (softmax numerator and denominator) are then scattered back to the global sequence coordinates and accumulated. Final normalization yields the exact attention outputs. The backward pass follows a congruent decomposition, computing gradients locally within each subsequence, and then scattering and accumulating these results analogously.
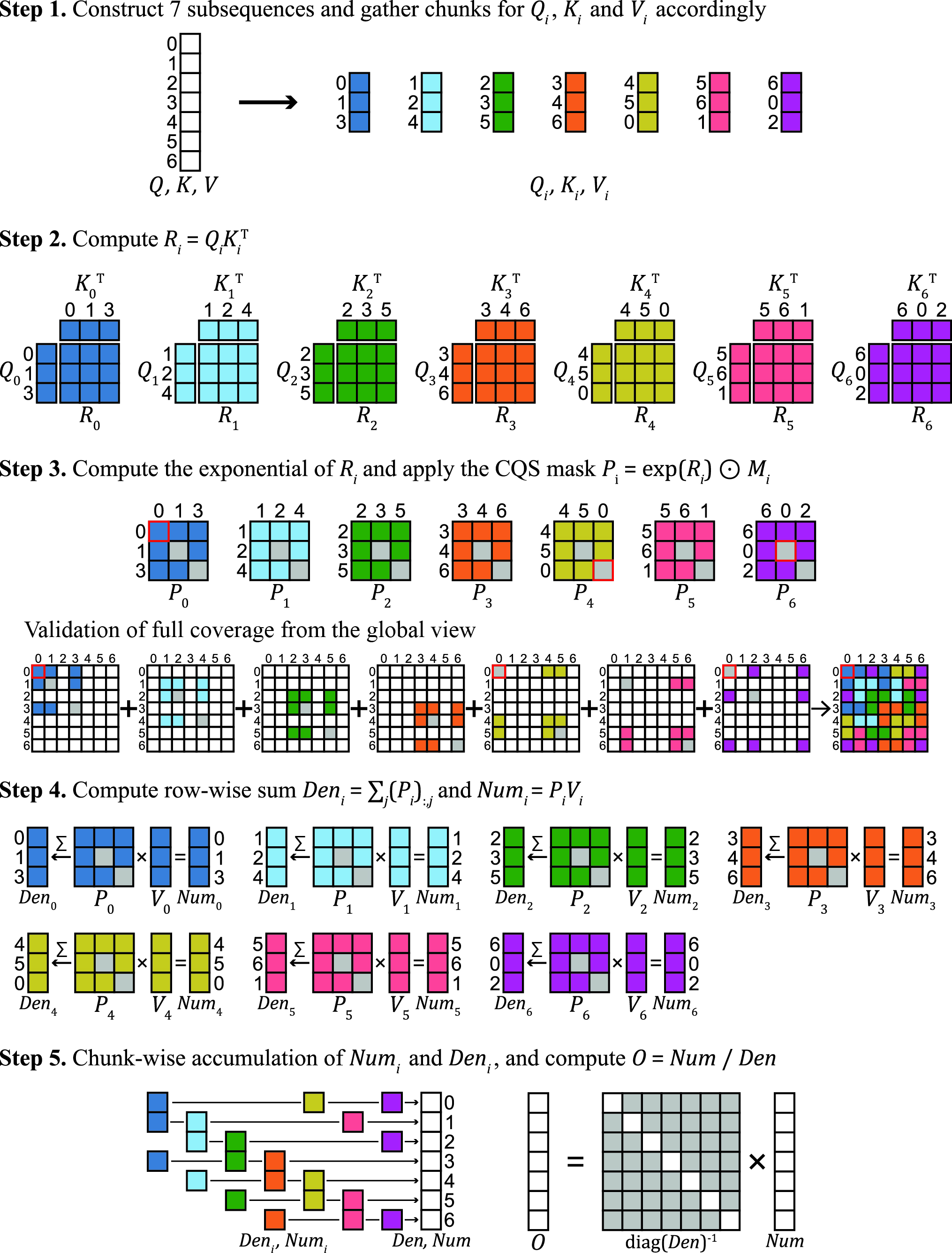
Figure 2: Illustration of the forward pass through CQSA with c=7 and a representative interest set, demonstrating token selection and coverage.
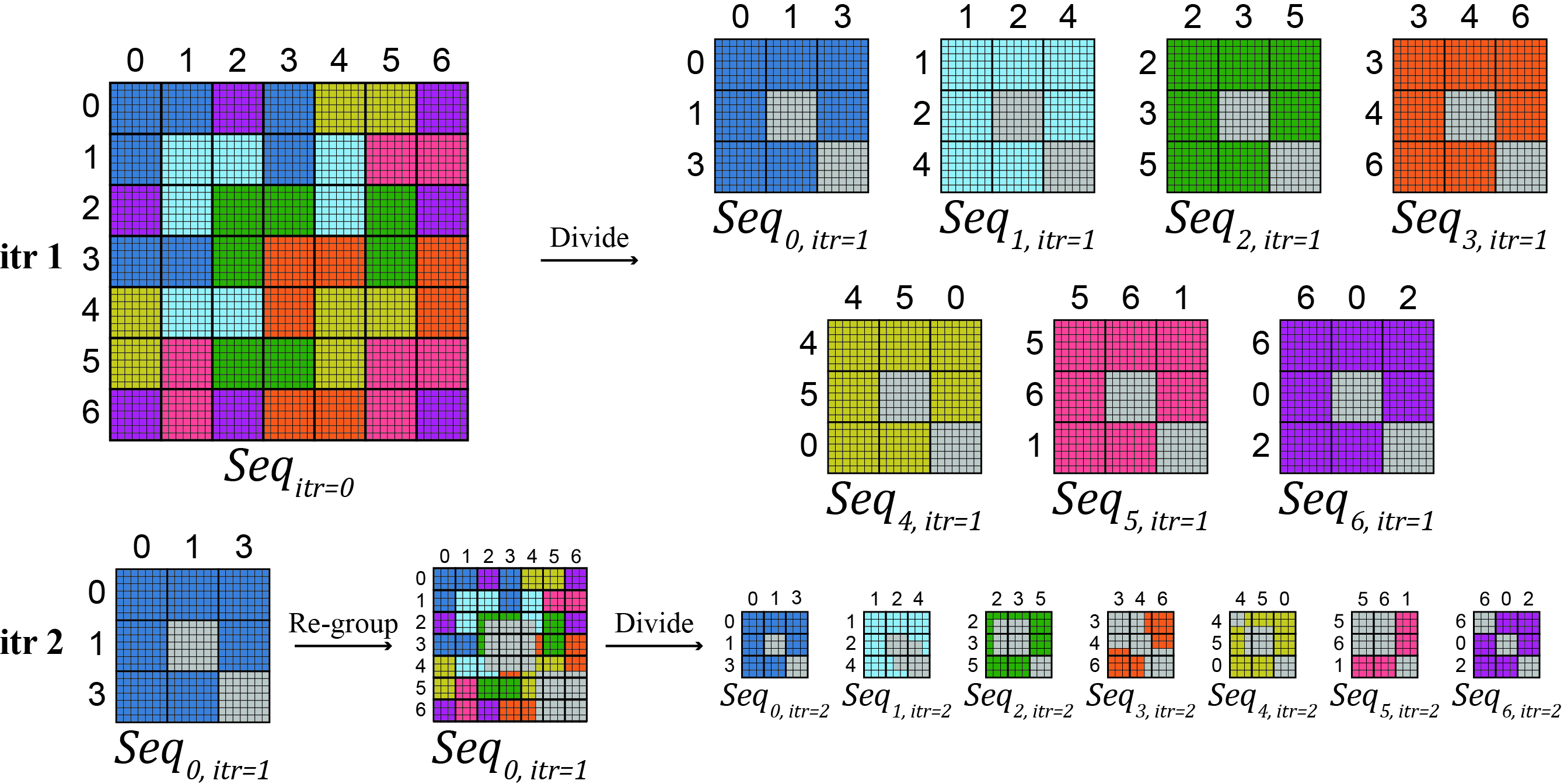
Figure 3: Visualization of masking strategy, showing how intra-chunk redundancies are removed and only the correct diagonal blocks are retained after subsequent divisions.
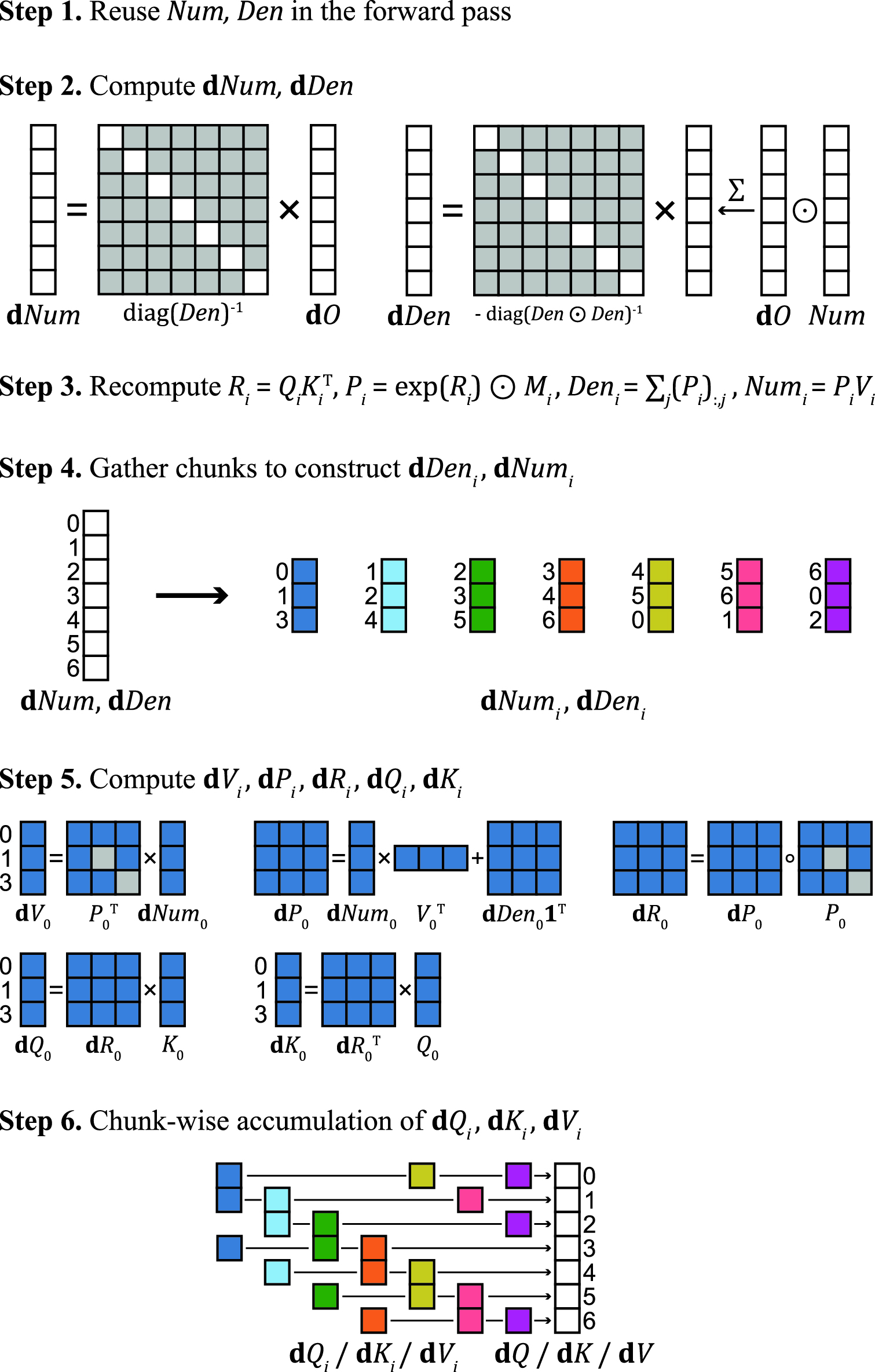
Figure 4: The backward pass for c=7; gradient accumulation and recomposition occur identically to the forward structure.
Memory and Parallel Scheduling
By iteratively applying CQS Divide, Stream-CQSA converts the original monolithic attention into a queue of independent, schedulable subtasks. The degree of decomposition is user-controlled; with each iterative division, the memory required per subproblem reduces by a constant factor. This enables the computation of exact attention for context sizes previously unattainable.
Scheduling strategies include:
- Uniform Scheduling: All subsequences are of the same size/division level.
- Hybrid Scheduling: Different subsequences are adaptively divided based on current memory utilization, allowing heterogeneous scheduling across available devices.
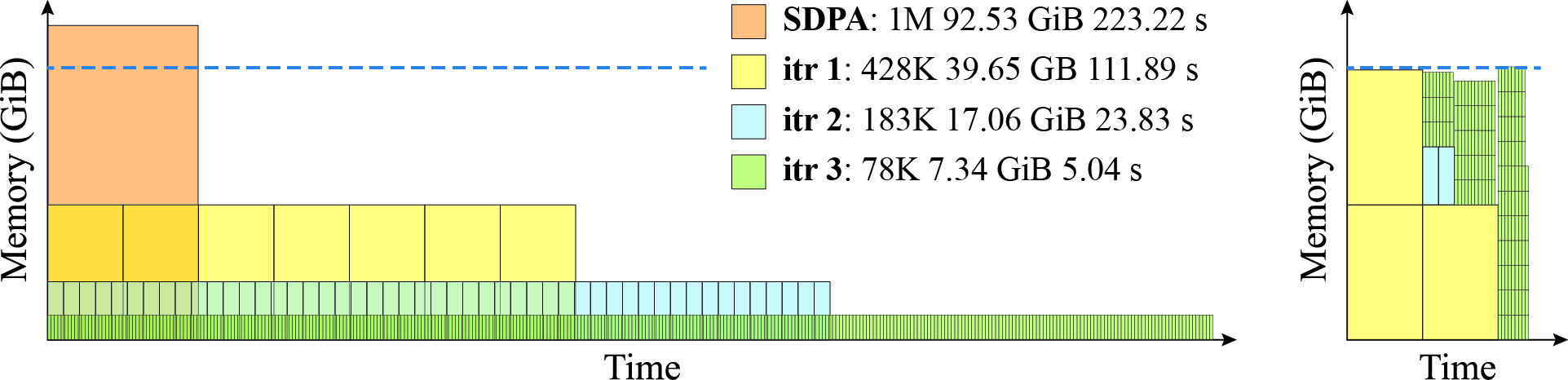
Figure 5: Comparison of workload management—uniform scheduling processes equal-sized subsequences while hybrid scheduling dynamically adapts granularity for improved hardware utilization.
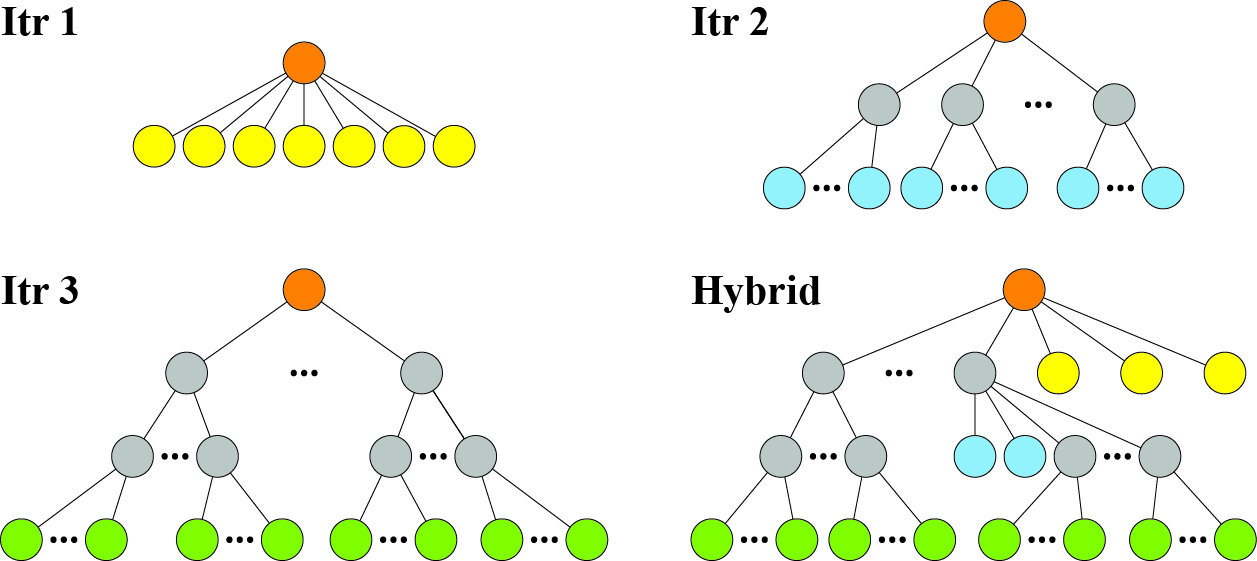
Figure 6: Tree structure visualization for the two scheduling regimes, indicating decomposition hierarchy and device mapping.
Empirical Evaluation
Comprehensive experiments on NVIDIA A100 (80 GiB) validate:
- Predictable, controllable memory scaling. Peak memory per subsequence is linearly reduced with each CQS Divide iteration, following the theoretical ratio K0.
- Run-time increases due to increased number of subproblems and additional data movement, but remains efficient relative to prior methods within practical bounds.
- Both forward and backward passes are supported, with backward requiring roughly K1 the memory and K2 the runtime of the forward pass. No OOMs occur at any tested configuration.
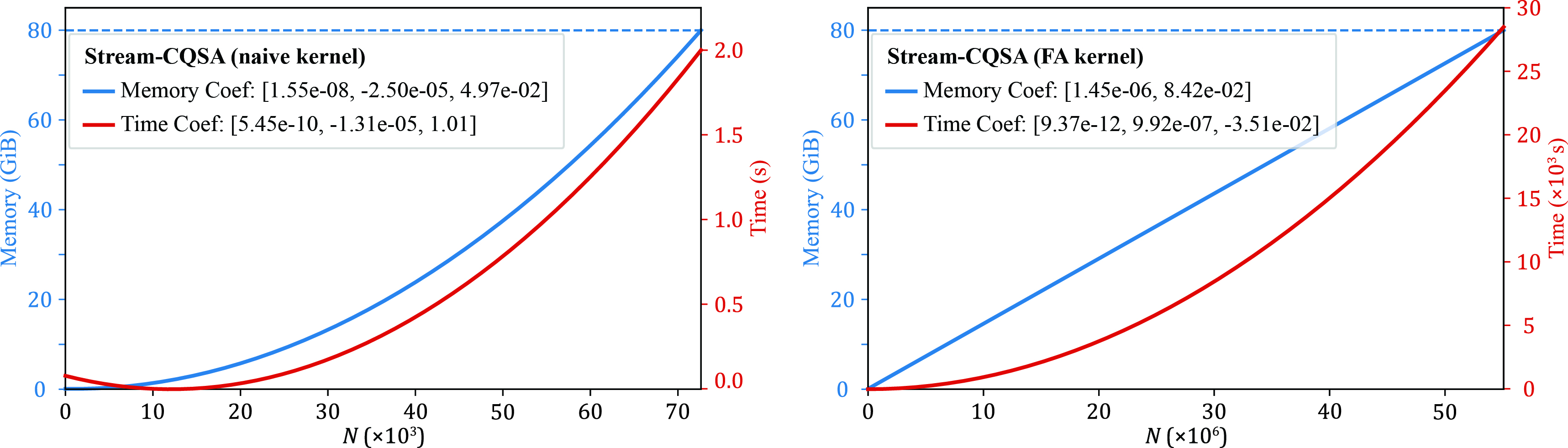
Figure 7: Benchmark comparing naïve Python and FlashAttention (FA) kernels; FA exhibits strict linear memory scaling and significantly reduced per-subsequence resource overhead.
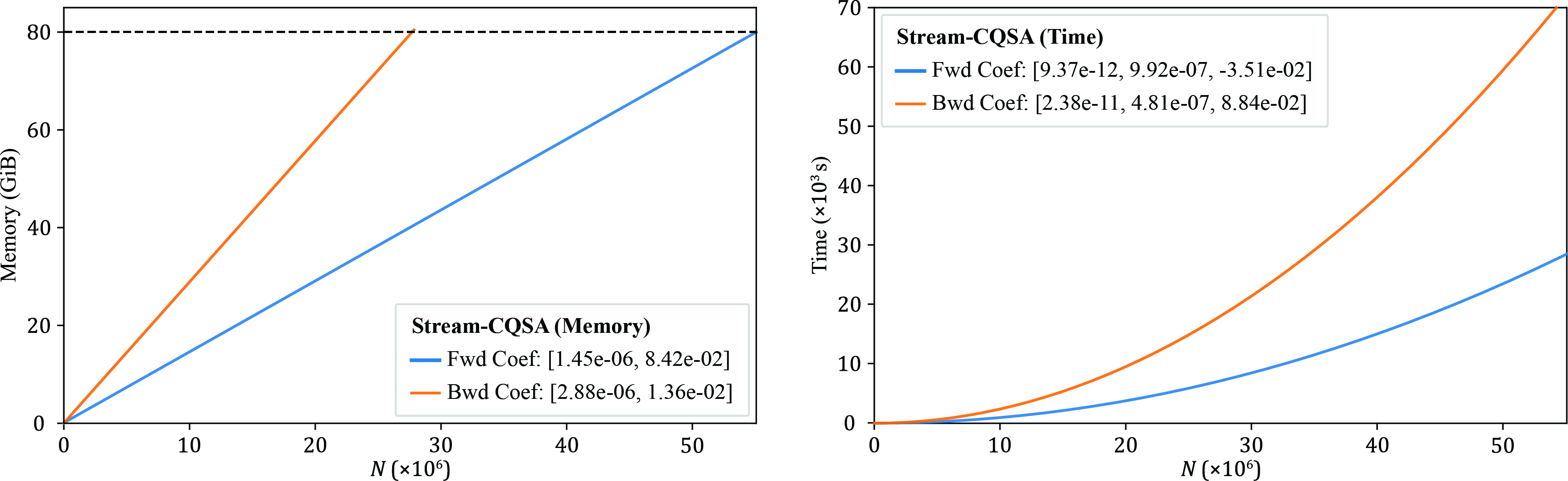
Figure 8: Head-to-head memory and runtime comparison for CQSA forward and backward—the backward pass is strictly more memory- and compute-intensive, dictating scheduler configuration.
Processing exact attention for billion-token sequences is demonstrated to be feasible in a single-GPU, streaming regime by sufficiently increasing divide granularity. Hybrid scheduling further improves resource exhaustion tolerance and overall throughput, with guardrails actively monitoring OOM events and dynamically tuning the decomposition.
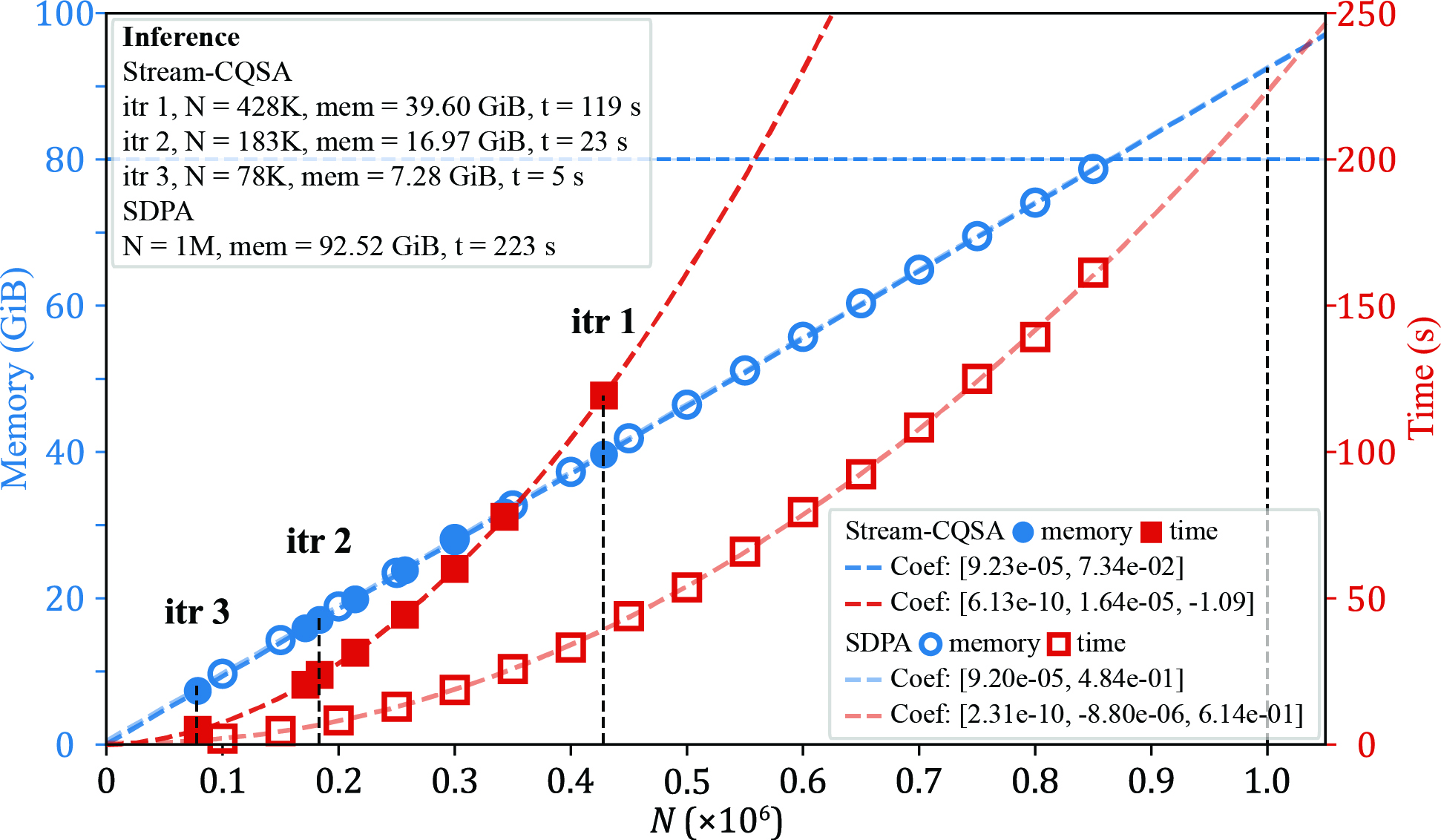
Figure 9: Extrapolated performance curves for baseline SDPA vs. Stream-CQSA demonstrate infeasibility for SDPA above K3K tokens, while Stream-CQSA scales predictably to multi-million tokens.
Implications and Future Directions
The primary implication is that exact, non-approximate long-context attention is now decoupled from device memory constraints; for any context length and hardware budget, Stream-CQSA guarantees a viable, exact computation procedure without loss. This decoupling is achieved solely by algorithmic partitioning and does not require architectural modification or kernel-level approximation, maintaining exact mathematical equivalence with standard attention.
The framework natively supports streaming, dynamic scheduling, and distributed execution, with the potential for pipeline-optimized dataflows across heterogeneous devices. Adoption of more parallelized attention kernels (e.g., future FA variants supporting multiple parallel subproblems) and communication-aware scheduling are recognized as the immediate next steps for improving runtime efficiency. Extension to plug-in arbitrary approximate attention kernels could further broaden applicability across contexts with even more extreme sequence lengths or stricter resource constraints.
Potential applications include long-context modeling for documents, code, or time series where input lengths exceed the capacity of any existing monolithic attention implementation. In large-scale distributed inference and training, Stream-CQSA enables flexible partitioning and scheduling over arbitrary device clusters, eliminating the bottleneck of inter-device communication for subsequence-local attention.
Conclusion
Stream-CQSA reframes full-sequence attention computation as a memory-adaptive, exactly decomposed set of independent tasks, grounded in combinatorial CQS design. This paradigm strictly removes memory-based execution barriers and enables exact long-context attention for sequences of arbitrary length. Remaining challenges are runtime optimization in the many-subproblem regime and integration with more advanced kernel backends and distributed infrastructure. The framework substantiates a systems-level shift in how full-attention is scheduled, executed, and parallelized for future LLM applications.

