- The paper introduces MAC-Attention, a match-amend-complete framework that reduces KV accesses by up to 99% without sacrificing accuracy.
- It decomposes attention into three stages, achieving 14.3x–46x speedups in inference for long-context large language models.
- The method is model-agnostic, integrating with existing kernels to deliver scalable, high-throughput performance improvements.
MAC-Attention: A Match-Amend-Complete Scheme for Fast and Accurate Attention Computation
Introduction and Motivation
Long-context inference in LLMs introduces a substantial I/O bottleneck due to the repeated streaming and processing of expanding KV caches. Prior acceleration paradigms—primarily aggressive KV compression and selection/eviction strategies—lower KV memory and bandwidth footprints but compromise access fidelity or restrict long-range dependencies, thereby degrading performance on tasks requiring delayed recall, long-form reasoning, or robust cross-document retrieval. The solution presented in "MAC-Attention: a Match-Amend-Complete Scheme for Fast and Accurate Attention Computation" (2604.00235) is a fidelity-preserving, model-agnostic approach that targets computational and I/O bottlenecks via semantic-level computation reuse within the canonical attention stack.
MAC-Attention: Algorithmic Structure
The MAC-Attention mechanism is driven by the observation that queries in generative decoding frequently demonstrate high self-similarity within a short horizon, particularly in long-form generation, multi-turn interaction, and systematic retrieval. MAC introduces an online per-request micro-pipeline, decomposed into three main algorithmic stages:
- Match: At each decode step, the pre-RoPE query vector is L2-compared within a constant-size, recent-horizon candidate ring. On a hit (when the L2 distance passes a dimension-aware threshold), a previously computed rectified attention summary is selected for reuse. Importantly, MAC matches in pre-RoPE space, not post-RoPE, significantly improving hit rates compared to phase-sensitive matching.
- Amend: To mitigate high-mass drift—arising from positional encoding sensitivity and local recency bias—a small prefix band (typically r∈[128,512] tokens) around the reuse boundary is recomputed, ensuring that tokens with the largest softmax contribution are freshly processed. This correction step effectively bounds approximation error.
- Complete: The rectified prefix summary is then merged with a newly computed tail via log-domain summation, yielding the attention output in an associative and numerically stable manner. On a match, compute complexity reduces to O(1) for the prefix, regardless of sequence length.
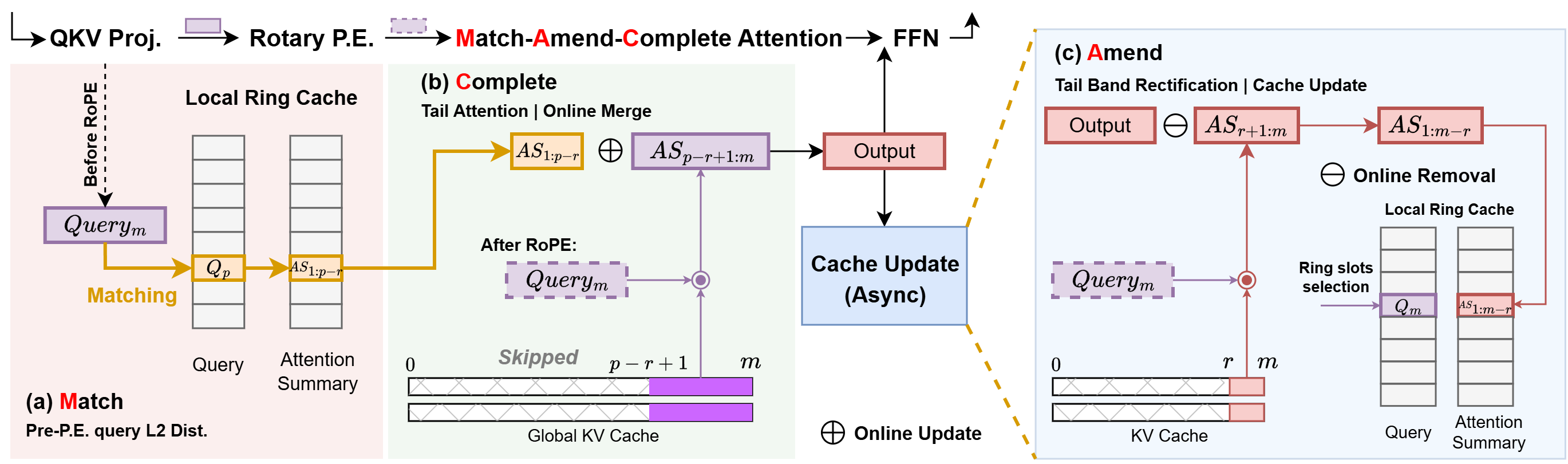
Figure 1: Schematic of MAC-Attention's Match-Amend-Complete pipeline, showing how computation is skipped for reused prefixes, only amending a band and completing with a tail merge.
This pipeline is composable with existing attention kernels (e.g., FlashAttention, FlashInfer), paged-KV memory managers, and architectures with grouped or multi-query attention.
Systems Design and Implementation
MAC-Attention is implemented via per-request ring buffers for both query and rectified summary caching, enabling O(1) insertions and bounded auxiliary memory (O(K) per sequence, with K≪L where L is the context length). Per-layer and per-head matching acceptances are highly variable, thus match thresholds and amendment spans can be layer-tuned for optimal reuse (Figure 2).

Figure 3: Decode-phase micro-pipeline—Match operates in parallel with subsequent amend/complete stages; kernels are load-balanced based on reuse span across query heads.
Systems-level efficiency is ensured by:
- Dense, single-pass matching kernels that exploit vectorized (bf16/fp16) reads with fp32 accumulation.
- Work flattening and CTA allocation proportional to rectification span, achieving near-perfect load balancing and mitigating overlapped IO-bound and compute-bound workloads.
- Auxiliary stream scheduling for off-path summary construction.
Auxiliary memory overhead is typically ≤5% of the KV cache at K=1024 and L=120K, scaling sub-linearly with context length.
Empirical Evaluation
Quality-Preserving Efficiency
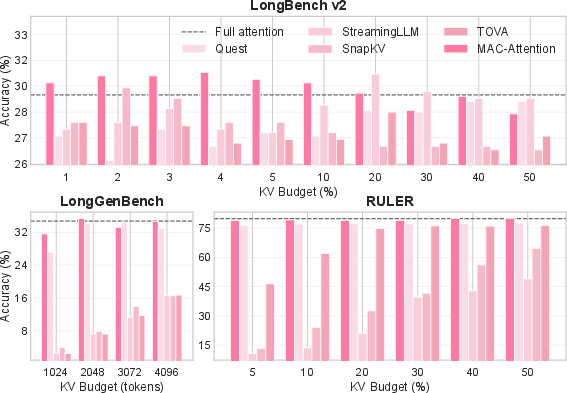
On LongBench v2 (120K), RULER (120K), and LongGenBench (16K), MAC:
Per-layer and per-head acceptance rates often exceed 99% (with proper thresholding), yielding near-constant-time prefix computation regardless of L (Figure 2), and dominating the “Full Attention” baseline for all context lengths under comparison.

Figure 5: MAC-Attention's batch-size-scaled speedup across increasing context lengths. Speedup correlates with KV skip ratio, peaking at 46x at 256K.
Fidelity and Error Analysis
Numerical analysis of the rectification strategy demonstrates that amending a narrow prefix band (O(1)0) drives the normed output error to near-zero, with error decay matching the cumulative mass outside the rectified interval (Figure 6). Sensitivity to layer depth and window size further enables layerwise match/adaptivity.
Figure 6: Layerwise heatmaps of rectification error versus reuse gap and band width—error drops rapidly as the band widens, with large gaps requiring slightly larger rectification.
Fine-grained latency profiling (Figure 7) confirms that the match kernel, amendment, and merging are fixed-cost components independent of O(1)1. Thus, for high-skip regimes (O(1)2), the overall MAC decode path is essentially flat in O(1)3, while baseline attention grows linearly.
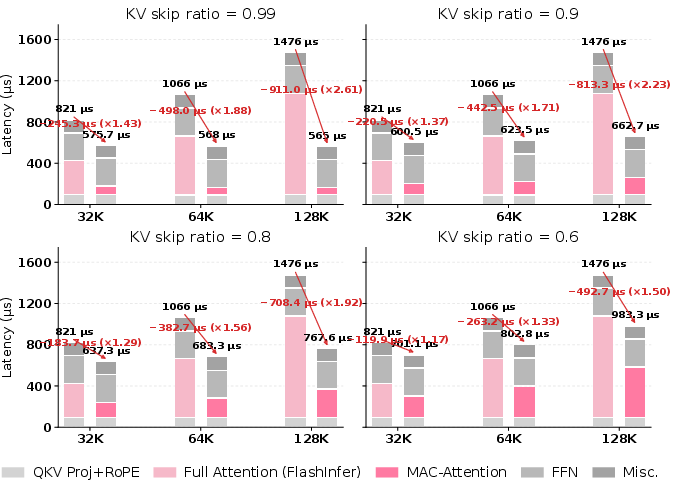
Figure 8: Full decode latency breakdown and MAC-Attention speedup—largest gains accrue in attention, with overall speedup bottlenecked by non-attention phases as predicted by Amdahl's law.
Generality: MoE Models and Robustness
Evaluation on MoE-backed architectures (e.g., Qwen3-30B-A3B-Instruct) demonstrates that semantic redundancy exploited by MAC is not diminished by conditional computation or expert partitioning. Hit/skip rates and accuracy are virtually unaffected, emphasizing the agnosticism to architectural specialization.
Relation to Prior Work
MAC-Attention is distinct from prior I/O and compute reduction strategies:
- Compression/Selection: Orthogonal to low-rank or quantization (e.g., PALU, LoRC) and selection/eviction (e.g., Quest, SnapKV), MAC does not discard or downsample context; all tokens remain accessible, and high-fidelity is approached asymptotically via local amendment.
- Structural/Stepwise Reuse: It is independent from prefix or request-pair caching (e.g., PromptCache, DeFT) and statistical partial recycling (e.g., Recycled Attention).
- Kernel-Accelerated: Composes natively with existing I/O-aware and paged-KV kernels, enhancing their wall-clock efficiency with no retraining or weight modification requirements.
Implications and Future Directions
Theoretical: MAC broadens the design space for sub-linear/deep-inference attention by amortizing compute and KV streaming costs in the temporal domain. It provides a rigorous, numerically stable route to O(1)4 decode complexity under strong match rates, while maintaining fallback to O(1)5 worst-case.
Practical: MAC is particularly suited for deployments requiring high-throughput, long-context serving on memory-bound hardware, as it is model-agnostic, training-free, and introduces negligible auxiliary compute/memory overhead.
Future trajectories include adaptive per-layer parameterization (e.g., learnable thresholds or dynamic band sizing), robust prefill integration (beyond decode), and hybrid schemes combining semantic reuse with lossy compression or token selection for even greater resource efficiency.
Conclusion
MAC-Attention establishes a new paradigm for accelerating long-context inference in LLMs: it leverages semantic-level temporal redundancy to amortize redundant compute and radically reduce memory traffic, all while preserving task fidelity and architectural compatibility. By introducing the Match-Amend-Complete pipeline, MAC achieves unprecedented end-to-end throughput improvements at true long context scales, without sacrificing accuracy or access. Its algorithmic simplicity, system robustness, and empirical superiority position it as a central component in the next generation of high-performance LLM serving stacks.
(2604.00235)