- The paper introduces a hierarchical two-level sparse attention that combines fast block-level filtering with precise token-level selection for efficient long-context inference.
- It achieves parity with full attention accuracy while delivering up to 4.0x speedups and significant throughput gains over conventional sparse methods.
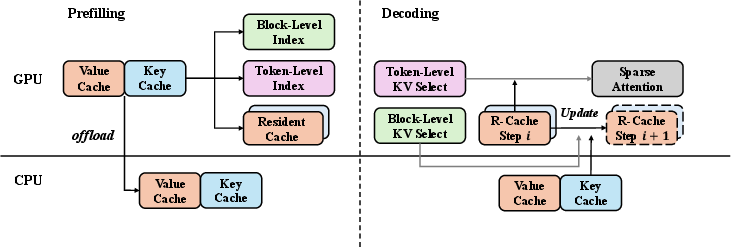
- The asynchronous KV cache offloading engine overlaps computation and memory transfer, reducing PCIe bandwidth demands and minimizing memory overhead.
AsyncTLS: Asynchronous Two-Level Sparse Attention for Efficient Long-Context LLM Inference
Introduction and Motivation
The quadratic complexity of self-attention and the linear growth of Key-Value (KV) cache memory fundamentally limit the scalability of LLMs in long-context inference. With sequence lengths expanding to 100k+ tokens, the memory footprint frequently exceeds GPU capacity, necessitating expensive transfers to CPU memory. Existing sparse attention methods typically operate at the token or block level—token-level sparsity offers higher fidelity but comes at substantial indexing and computation costs, while block-level sparsity enables efficient hardware utilization but sacrifices precision due to the inclusion of irrelevant tokens.
AsyncTLS introduces a hierarchical approach, combining fast block-level filtering with precise token-level selection and a specialized asynchronous KV cache offloading engine leveraging temporal locality, to address both computational and memory bottlenecks in long-context generative inference.
Hierarchical Two-Level Sparse Attention
AsyncTLS leverages hierarchical indices for KV blocks at two granularities:
- Block-Level Indexing: Coarse filtering via block importance scoring rapidly eliminates irrelevant sequence segments.
- Token-Level Indexing: Within retained blocks, fine-grained token selection provides precise contextual retrieval, preserving the accuracy benefits of high-resolution sparse attention.
This staged selection drastically limits the search space for fine-grained token selection, minimizing indexing overhead while retaining the critical tokens needed for model fidelity.
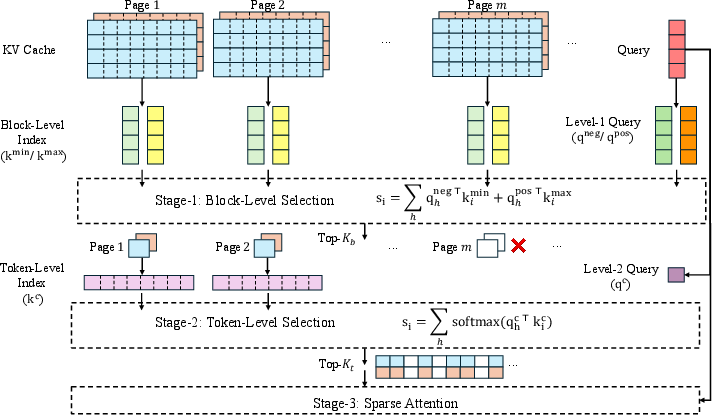
Figure 1: Illustration of hierarchical indices in AsyncTLS; block-level filtering precedes token-level selection for sparse attention computation.
Asynchronous KV Cache Offloading Engine
Beyond attention costs, long-context inference requires substantial KV cache storage. AsyncTLS integrates an asynchronous offloading pipeline:
Experimental Results and Numerical Findings
AsyncTLS is evaluated on Qwen3 (8B/14B) and GLM-4.7-Flash models across GQA and MLA architectures. The key findings:
- Accuracy: AsyncTLS achieves results indistinguishable from Full Attention (FA) under equivalent token budgets, outperforming block-level methods (Quest) and matching token-level approaches (DS/Double-Sparsity).
- Operator Speedups: Delivers 1.2×--10.0× operator speedups versus FA, with up to 4.0× improvements over token-level sparse attention.
- End-to-End Throughput: Achieves 1.3×--4.7× throughput gains on 48k–96k contexts compared to FA, supporting larger batch sizes without memory exhaustion.
Performance under varying token budgets demonstrates robust retention of accuracy; AsyncTLS consistently outperforms block-level sparse attention and aligns with token-level baselines across retrieval, summarization, and code completion tasks.
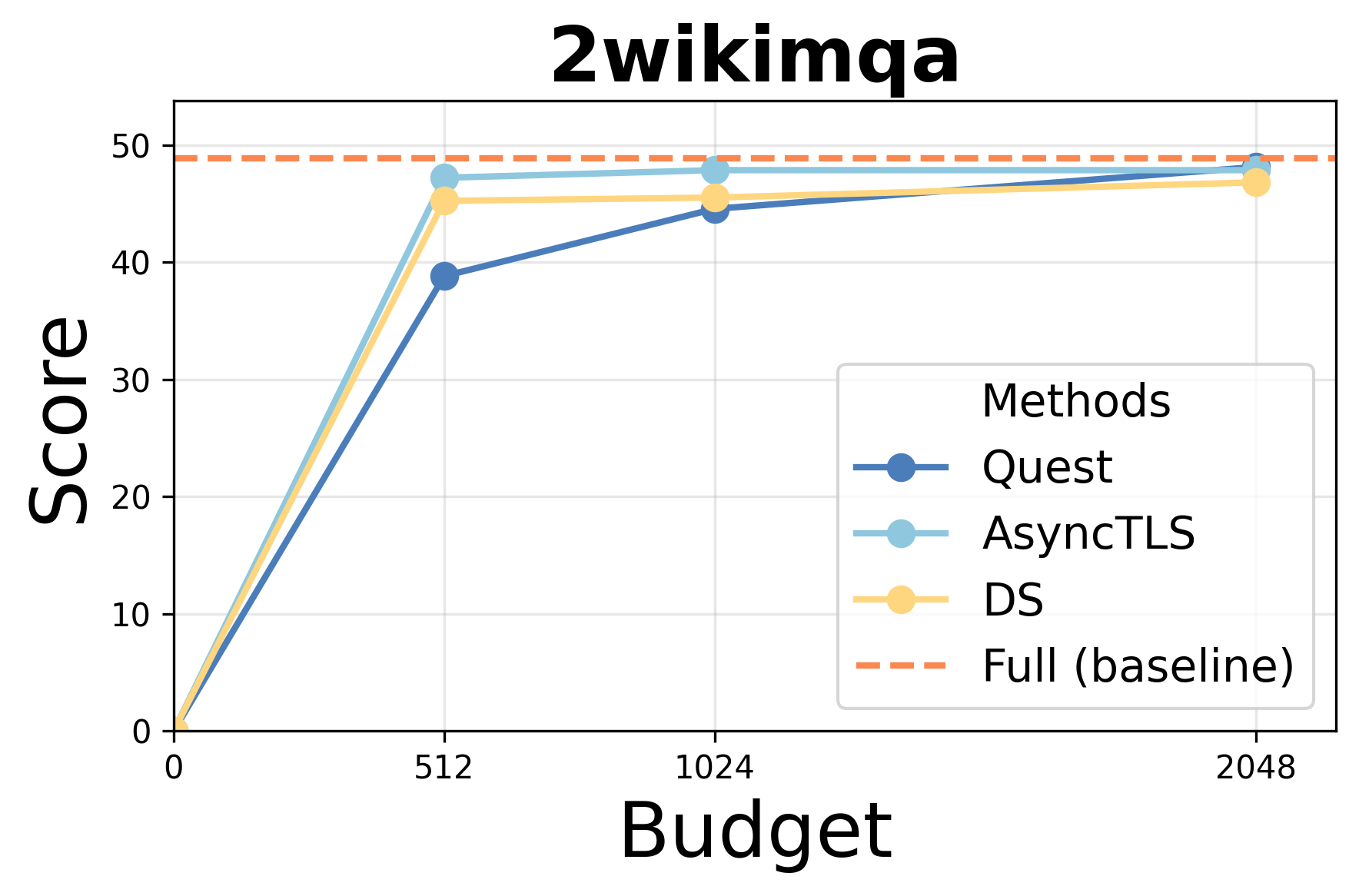
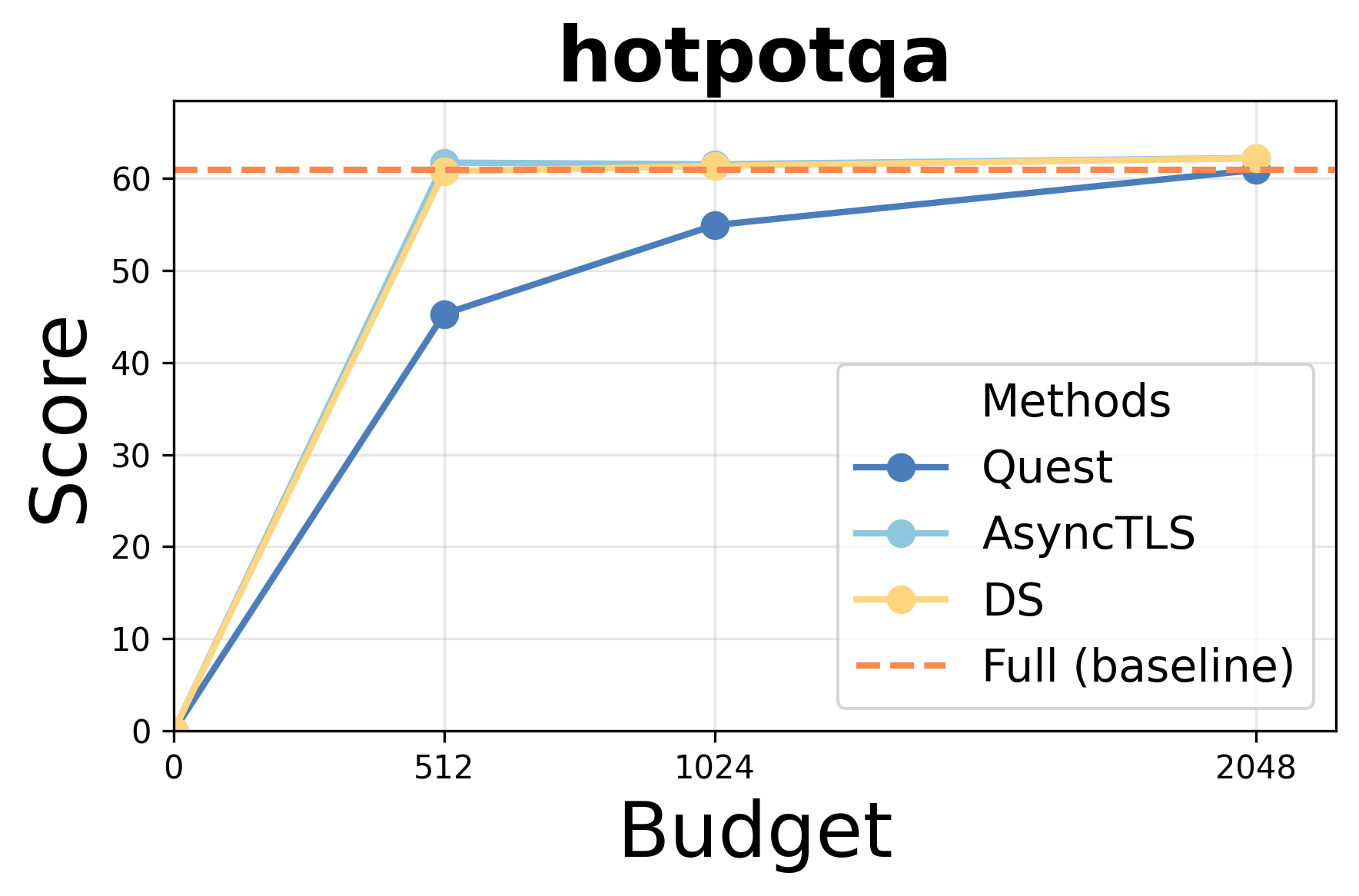
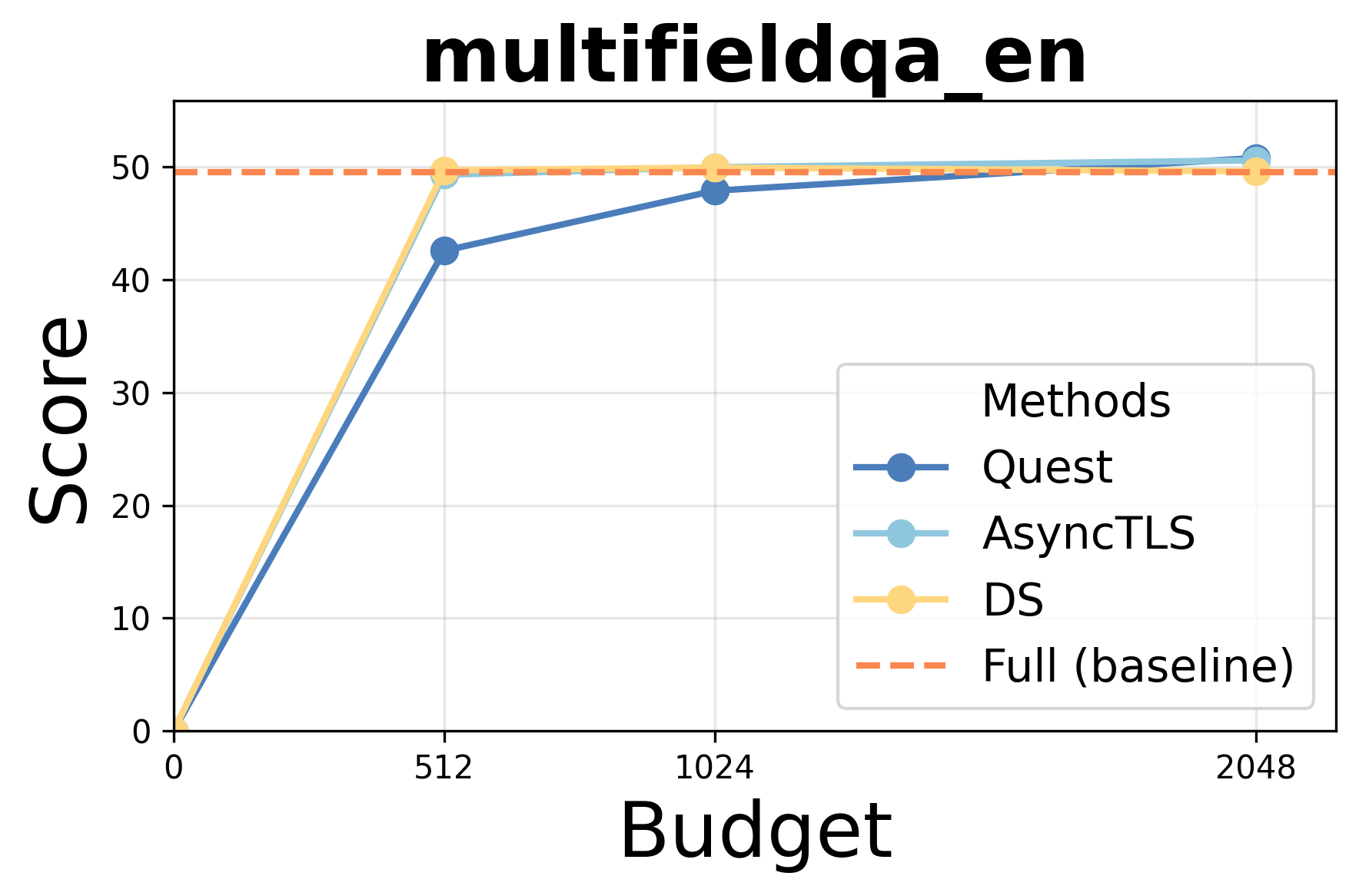
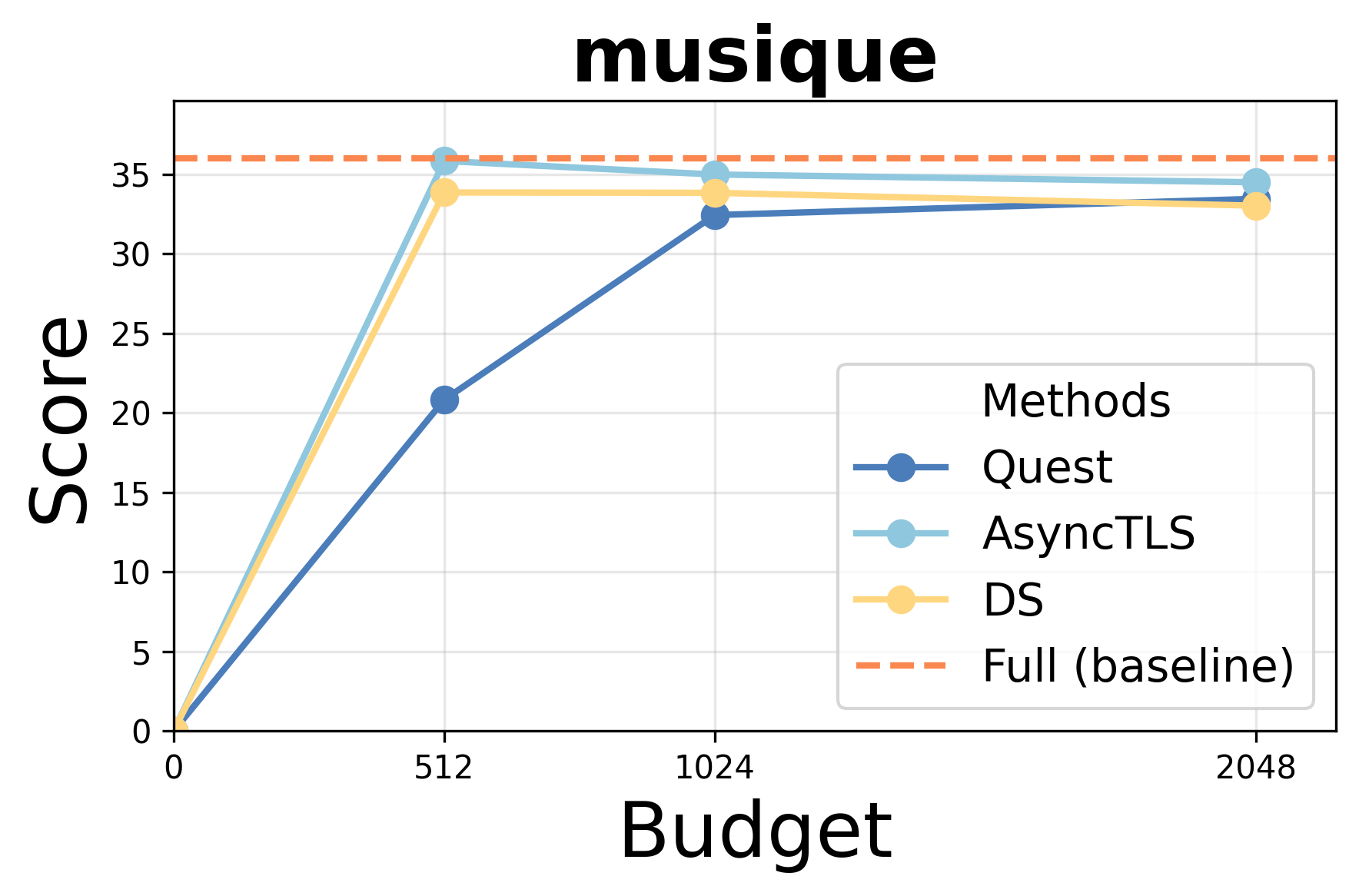
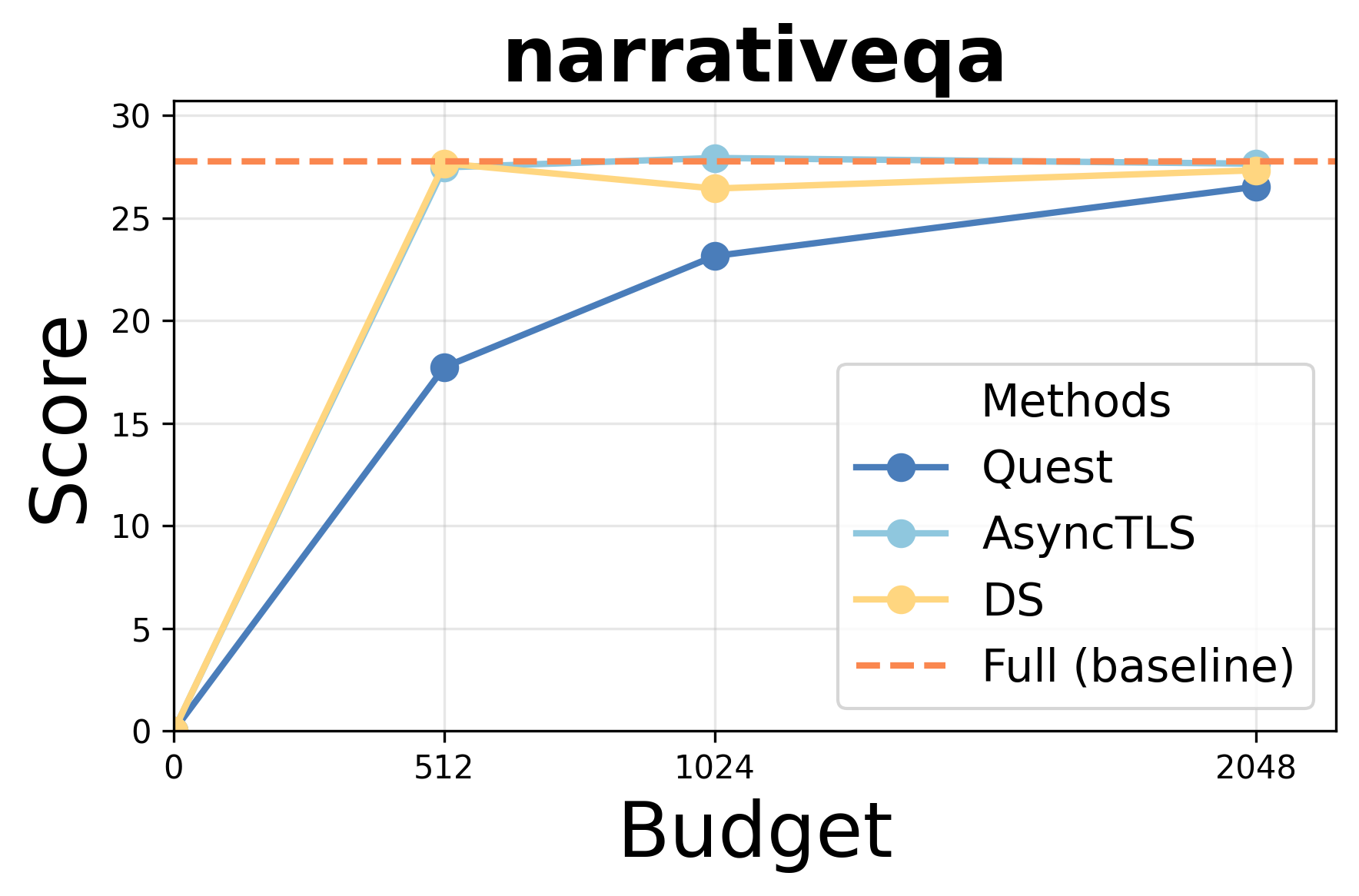
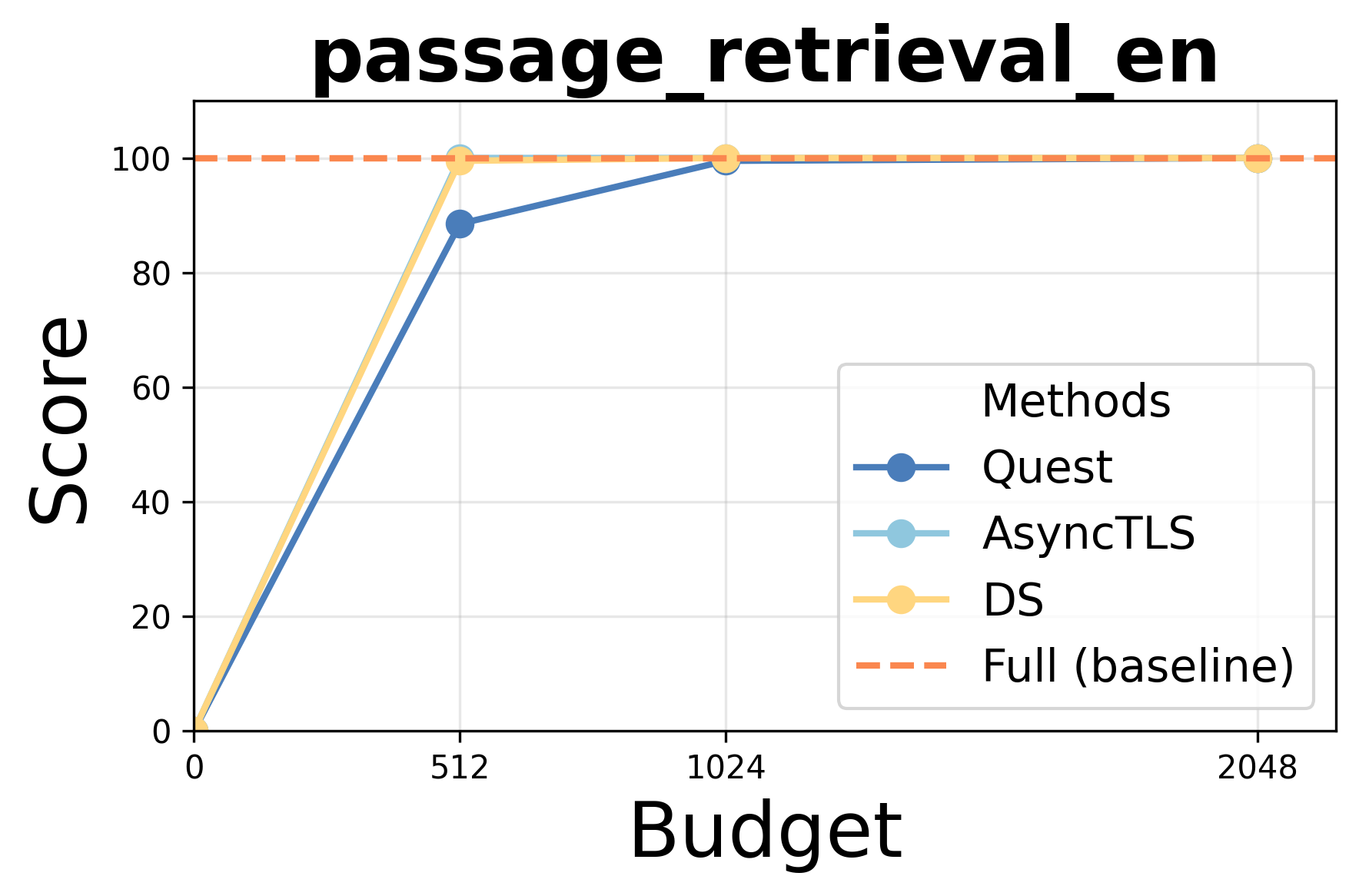
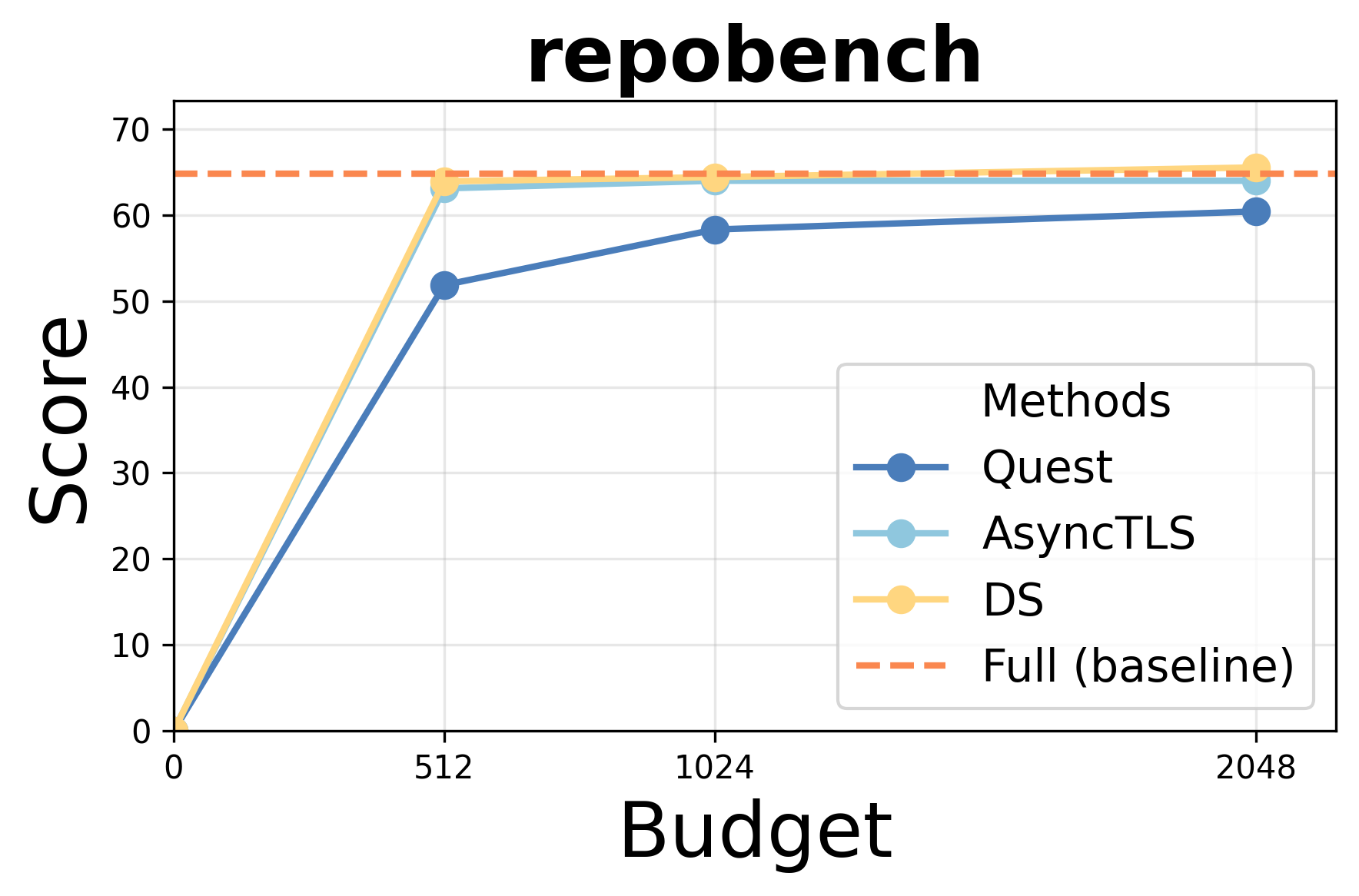
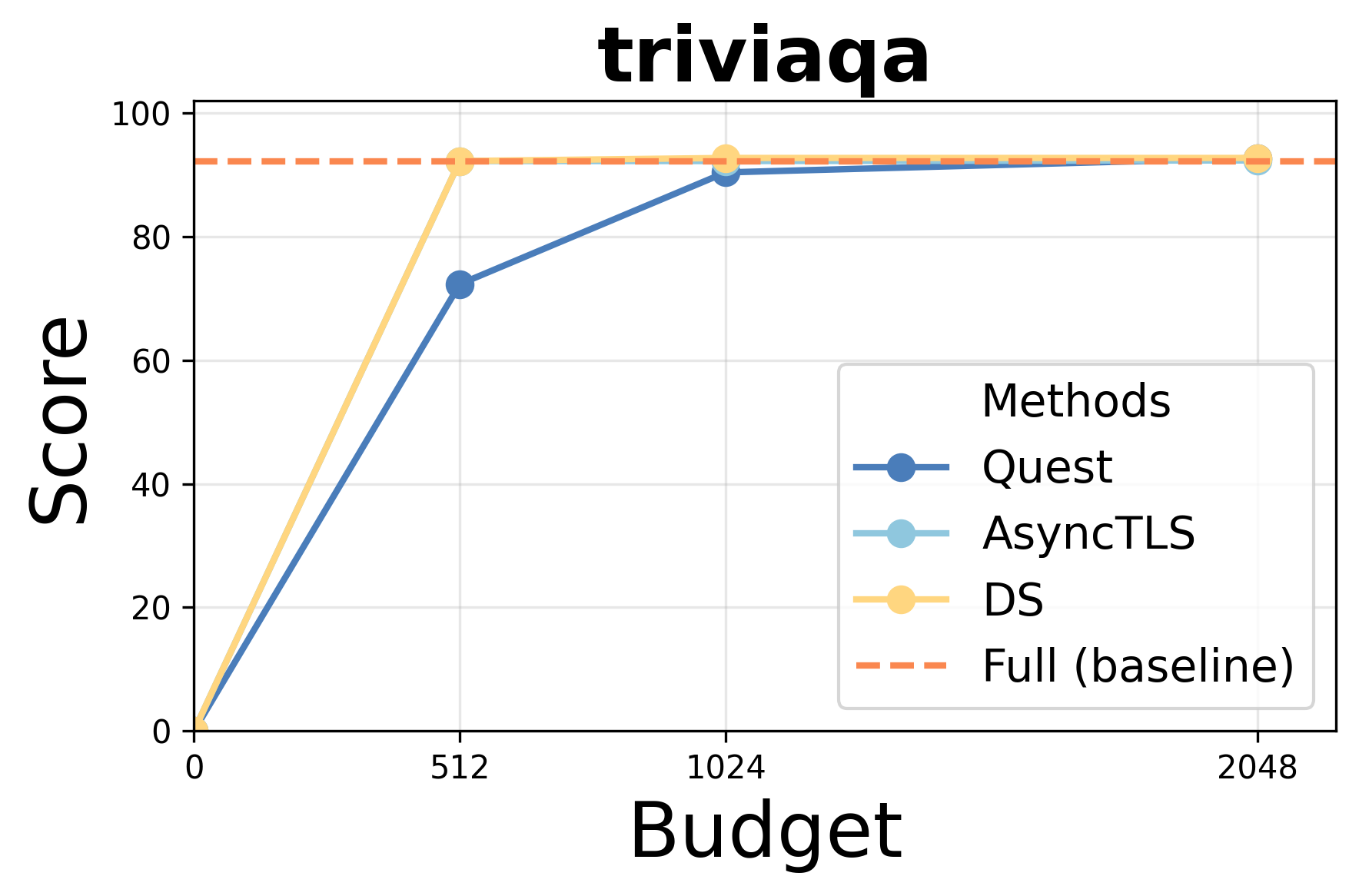
Figure 3: AsyncTLS maintains high task scores under token budget constraints for Qwen3-14B.
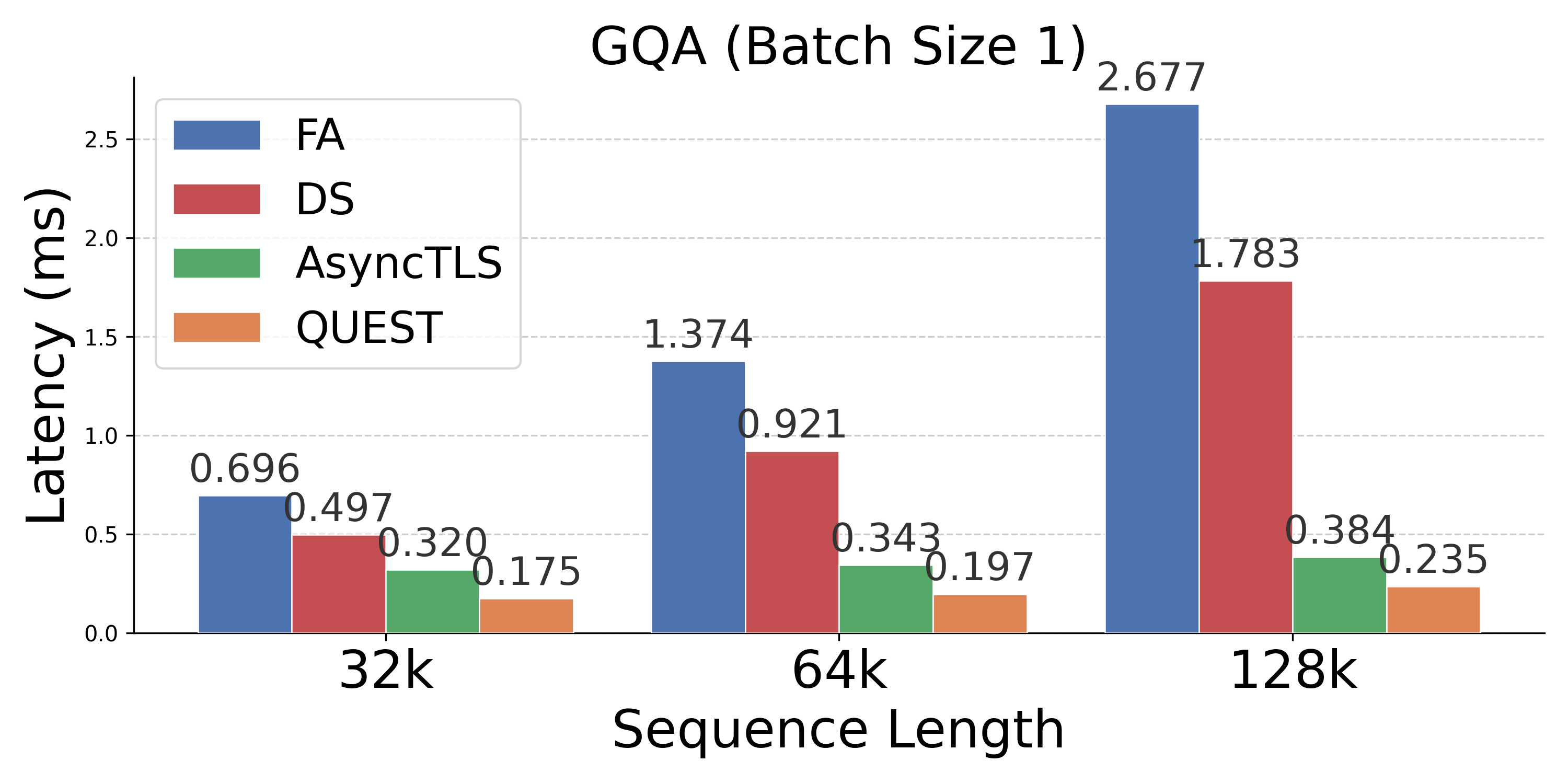
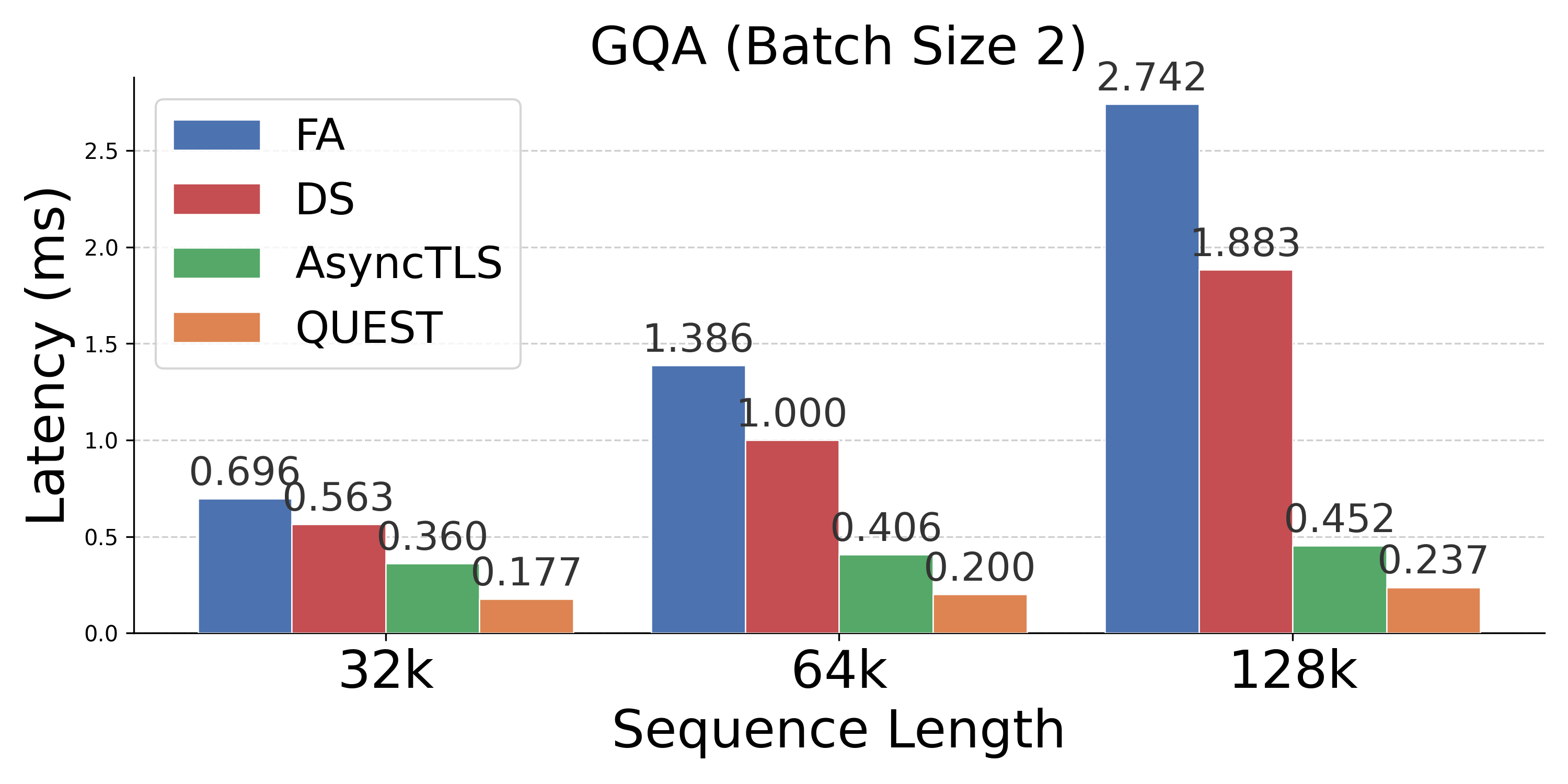
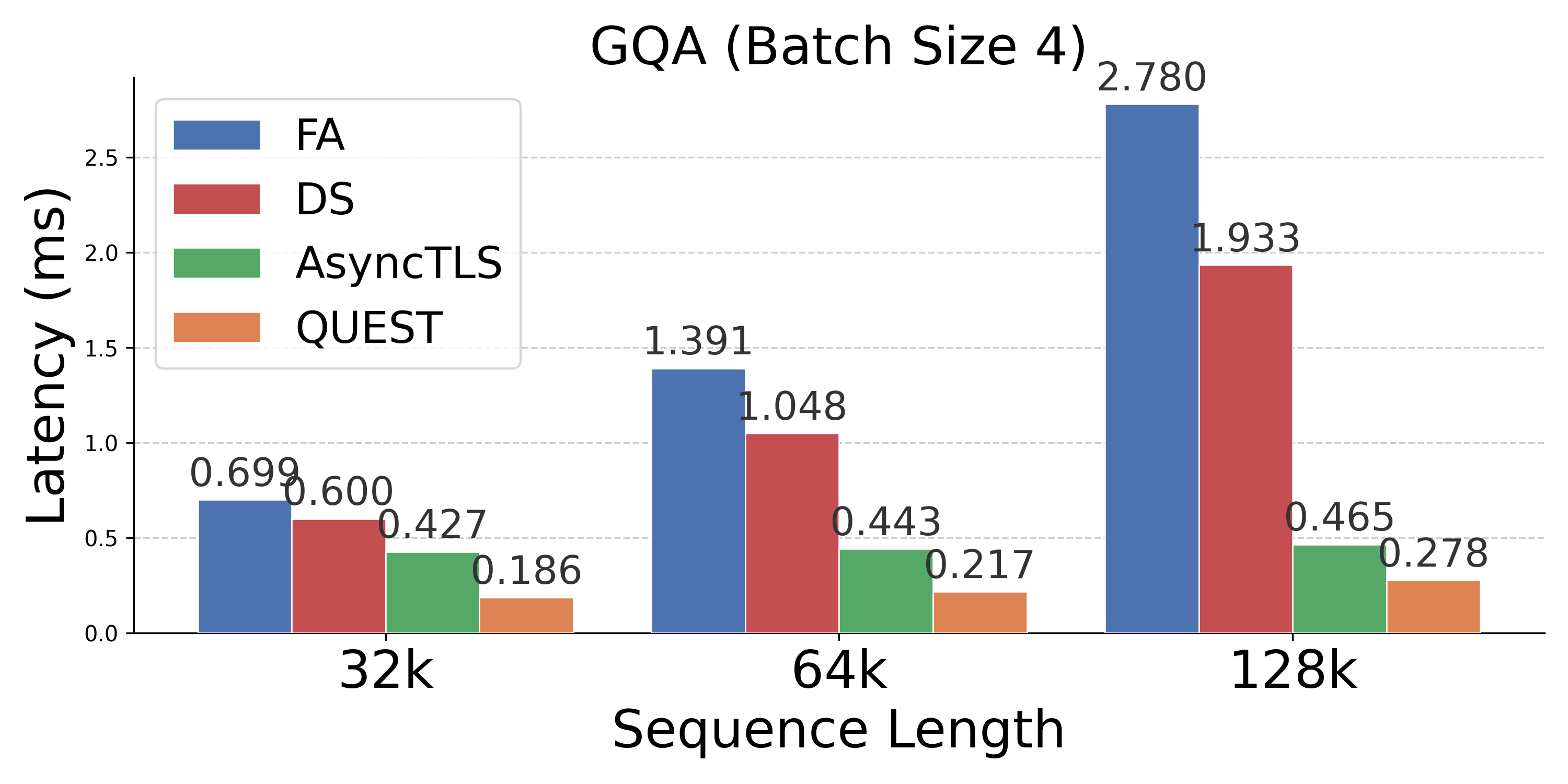
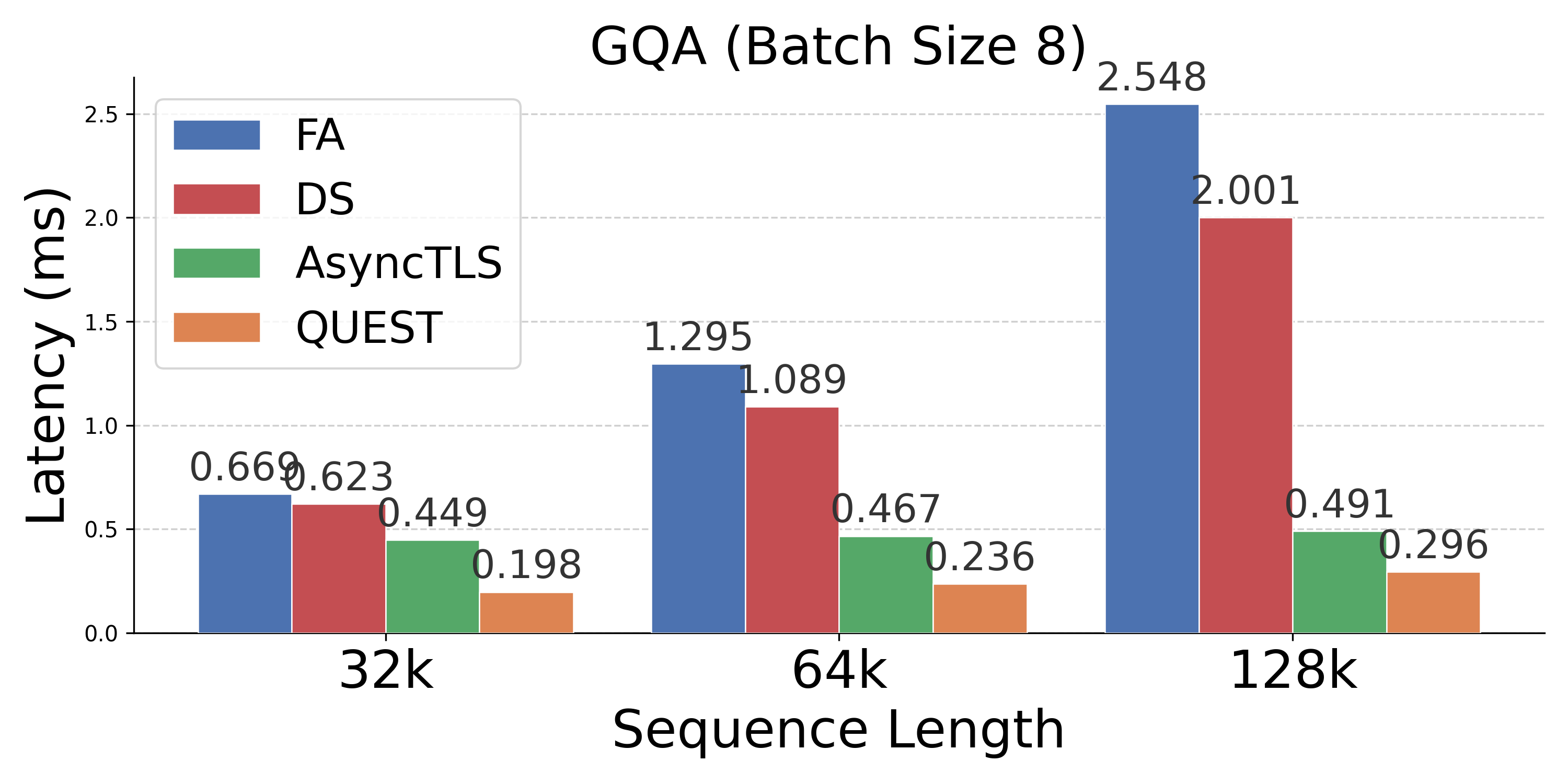
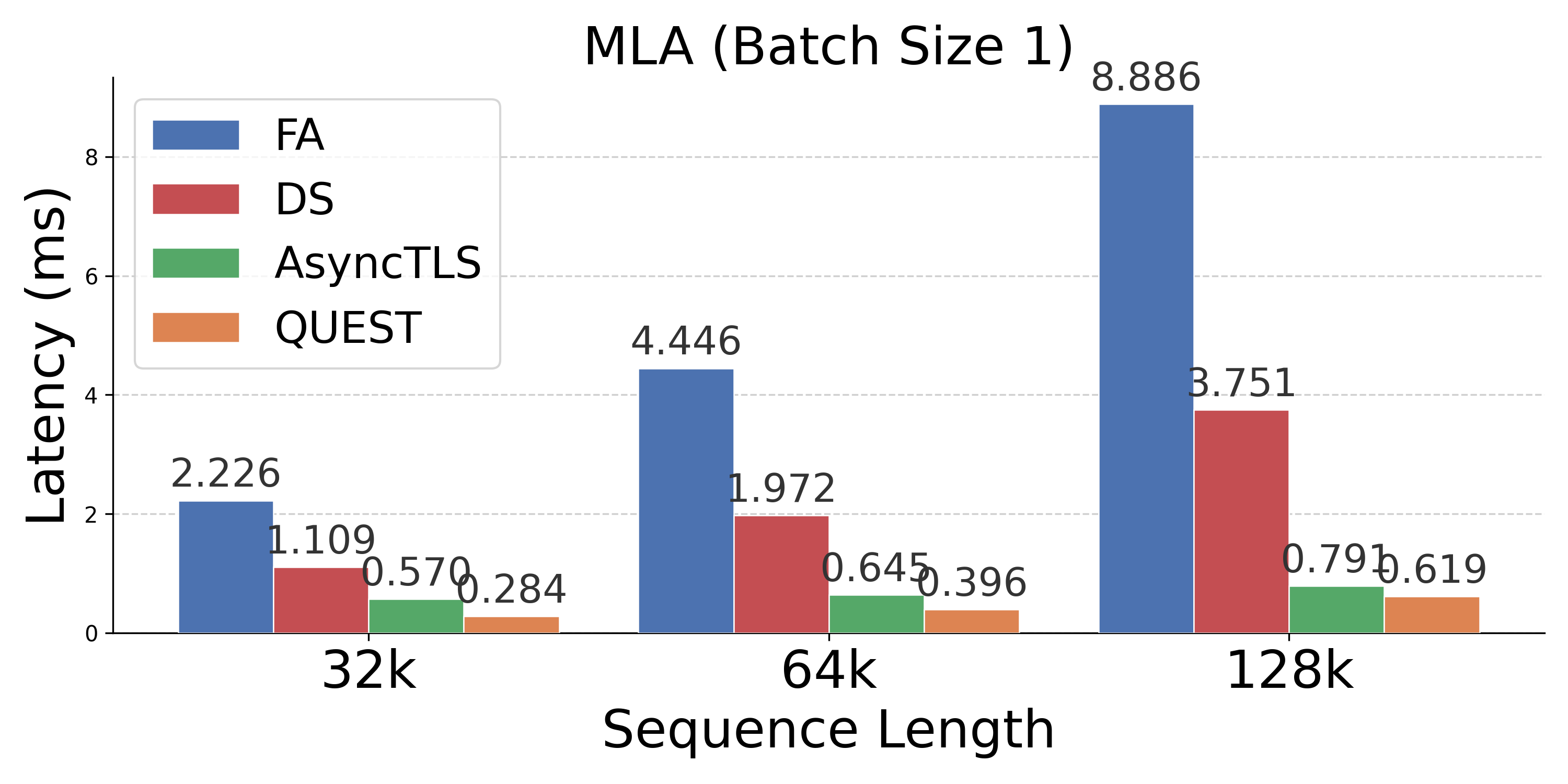
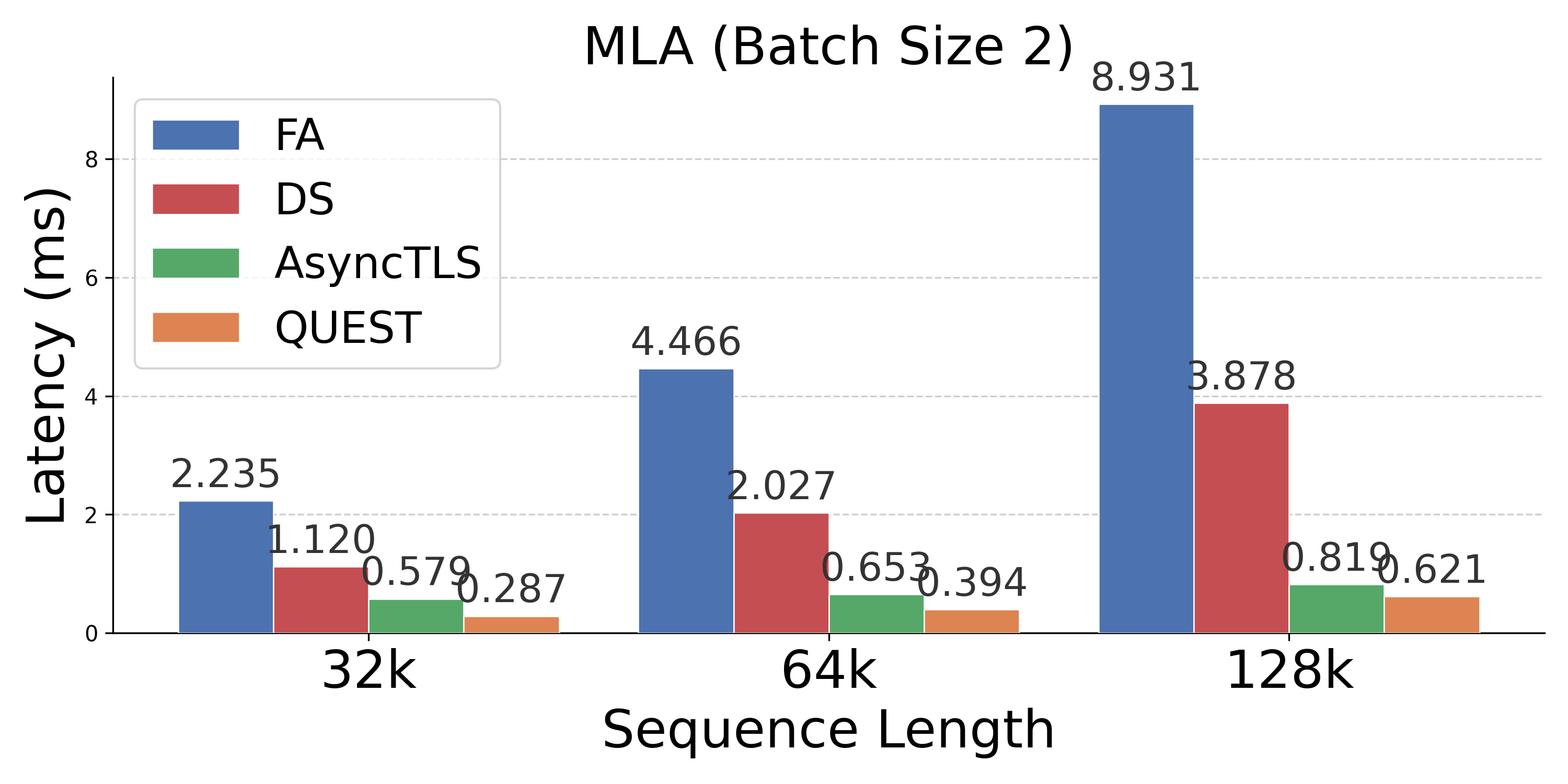
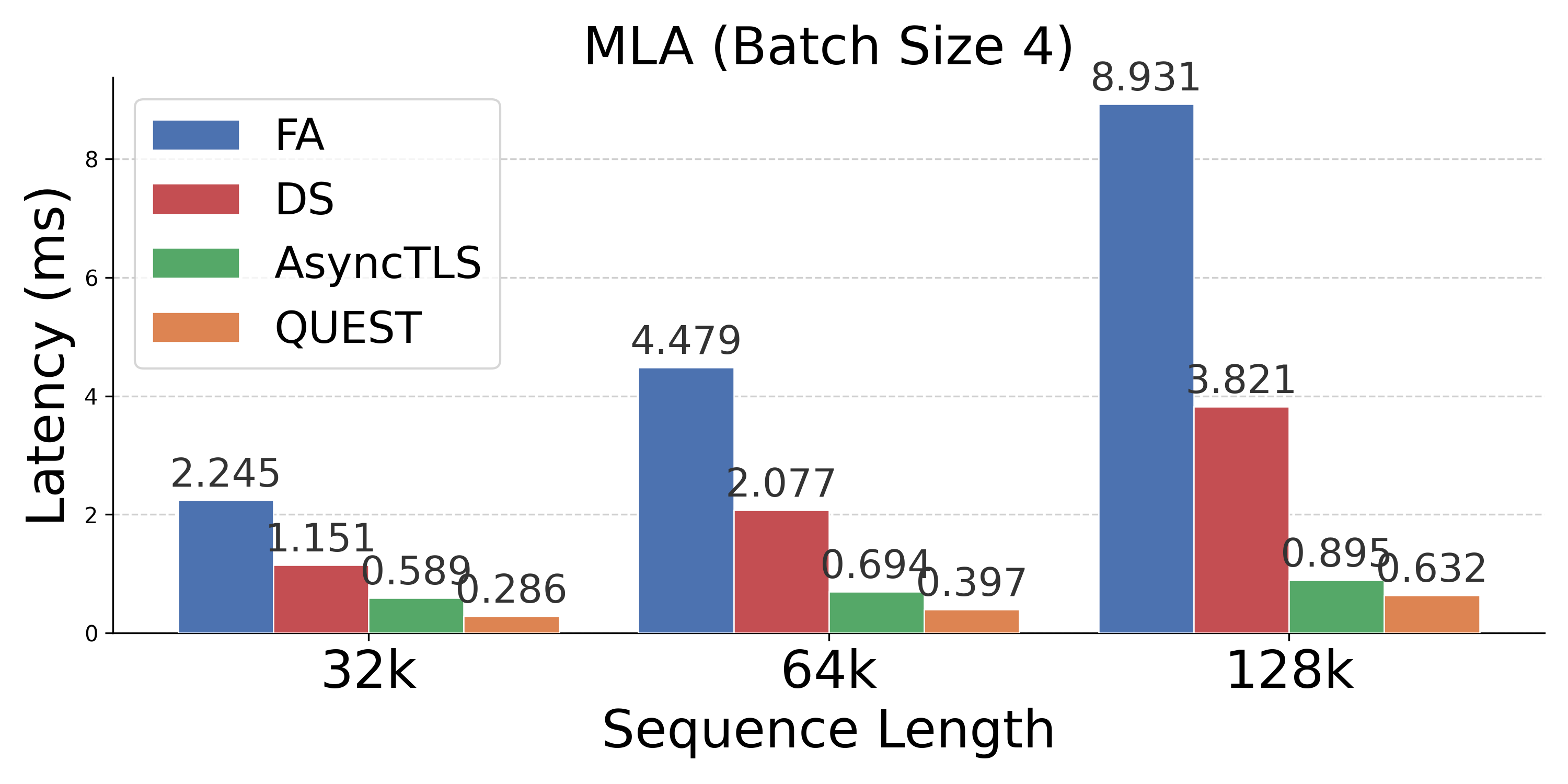
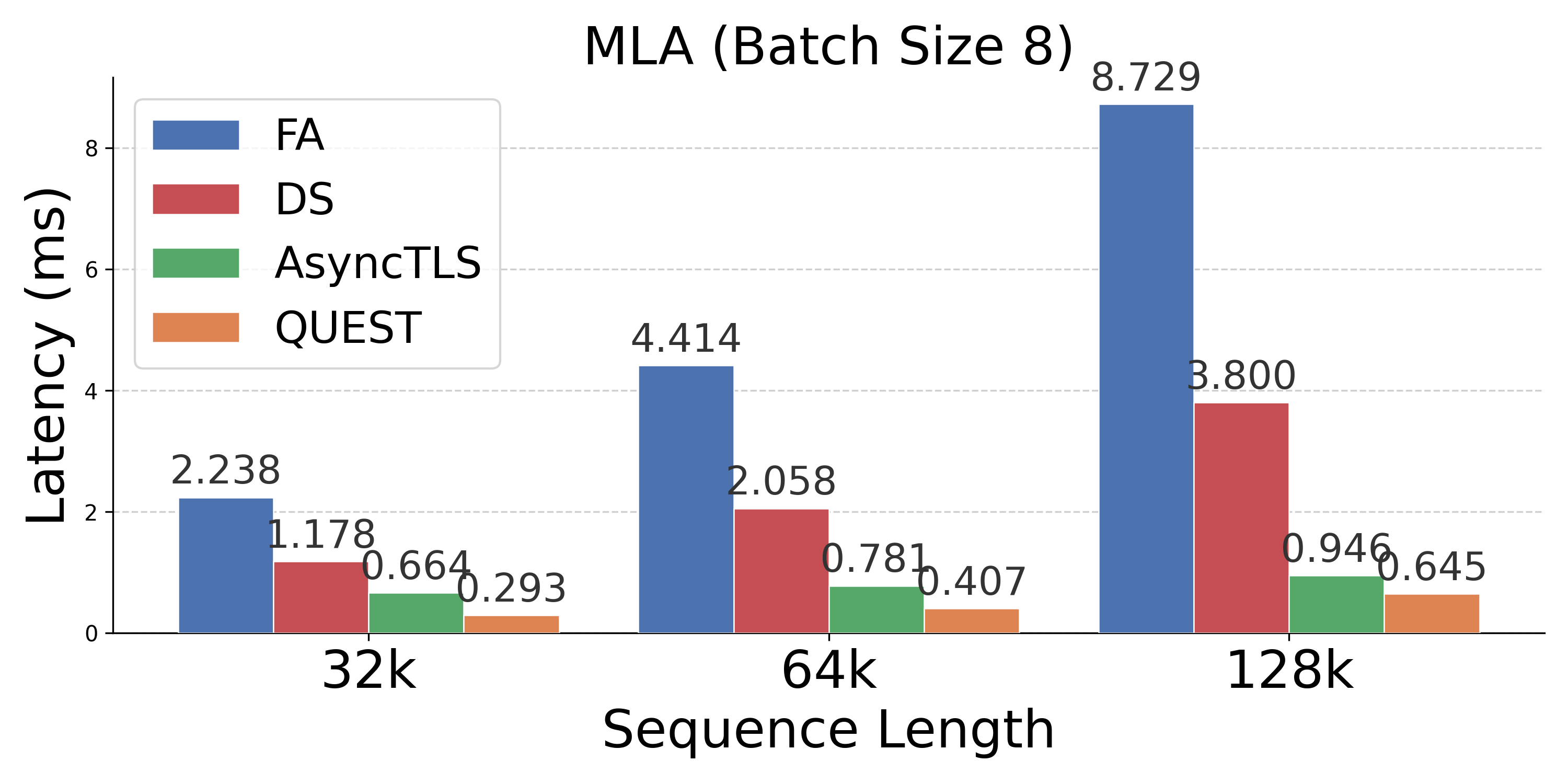
Figure 4: Latency comparison across attention mechanisms; AsyncTLS provides substantial gains at all batch sizes and sequence lengths.
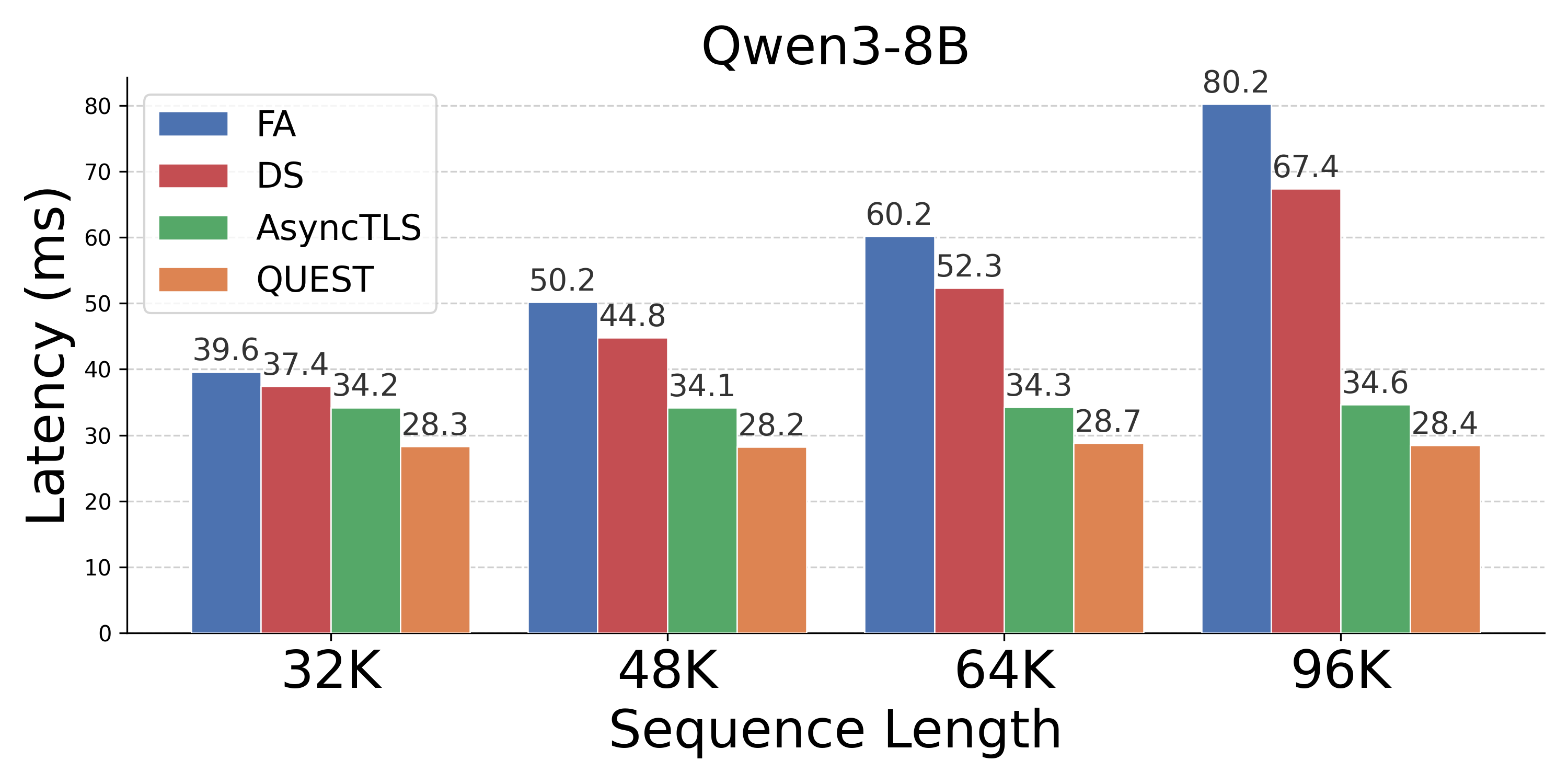
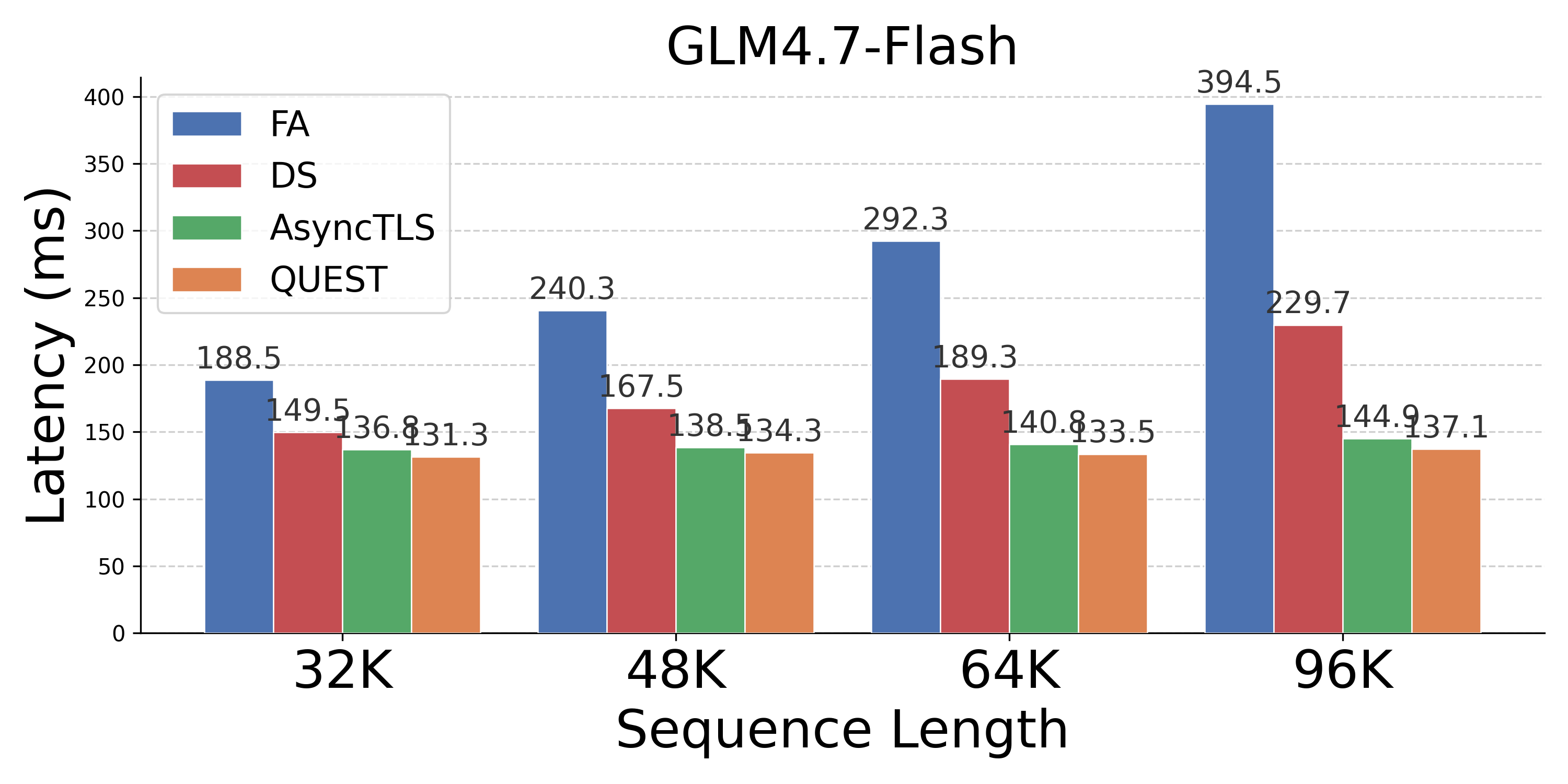
Figure 5: End-to-end latency; AsyncTLS significantly reduces inference times relative to FA, DS, and Quest.
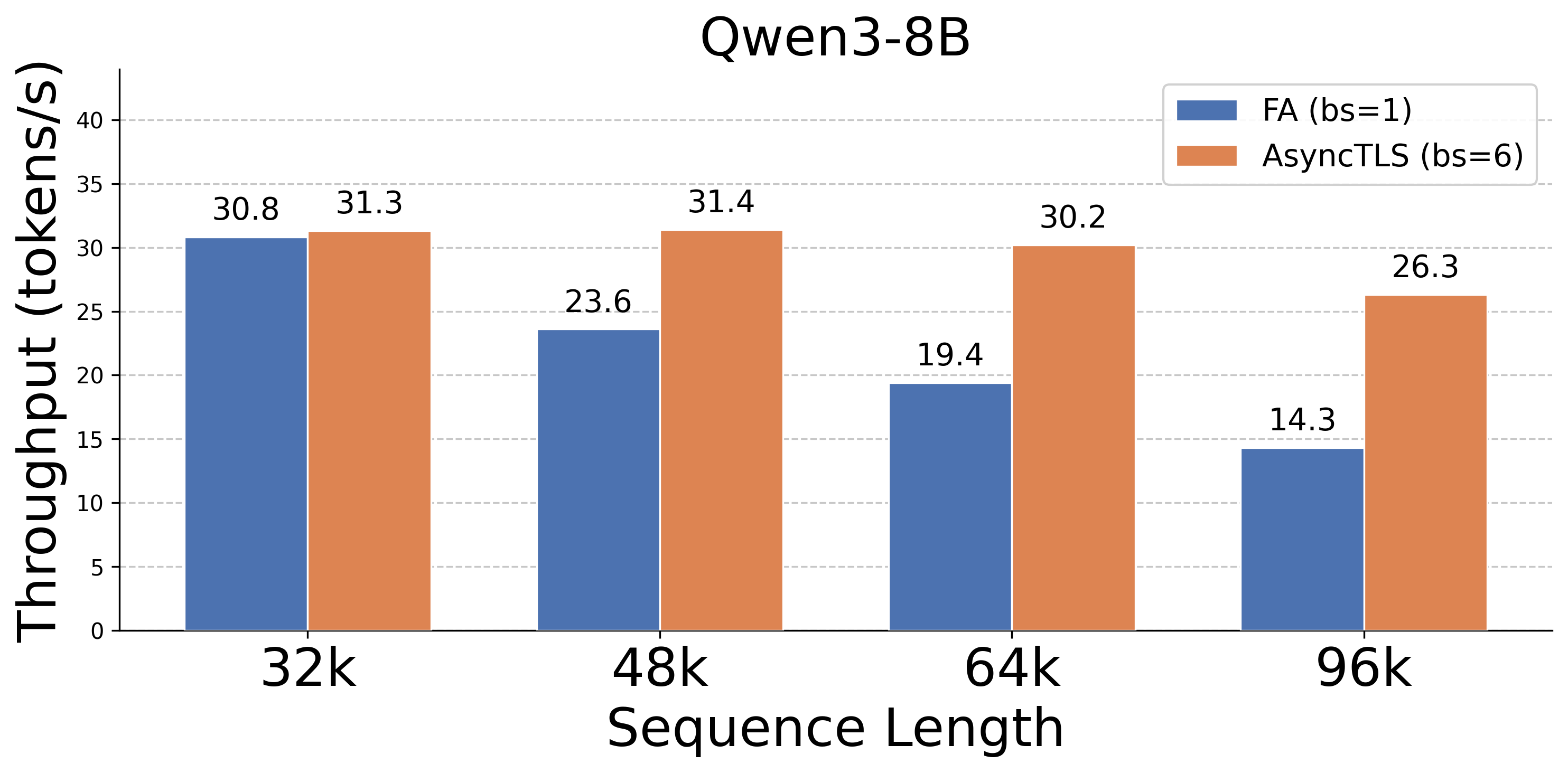
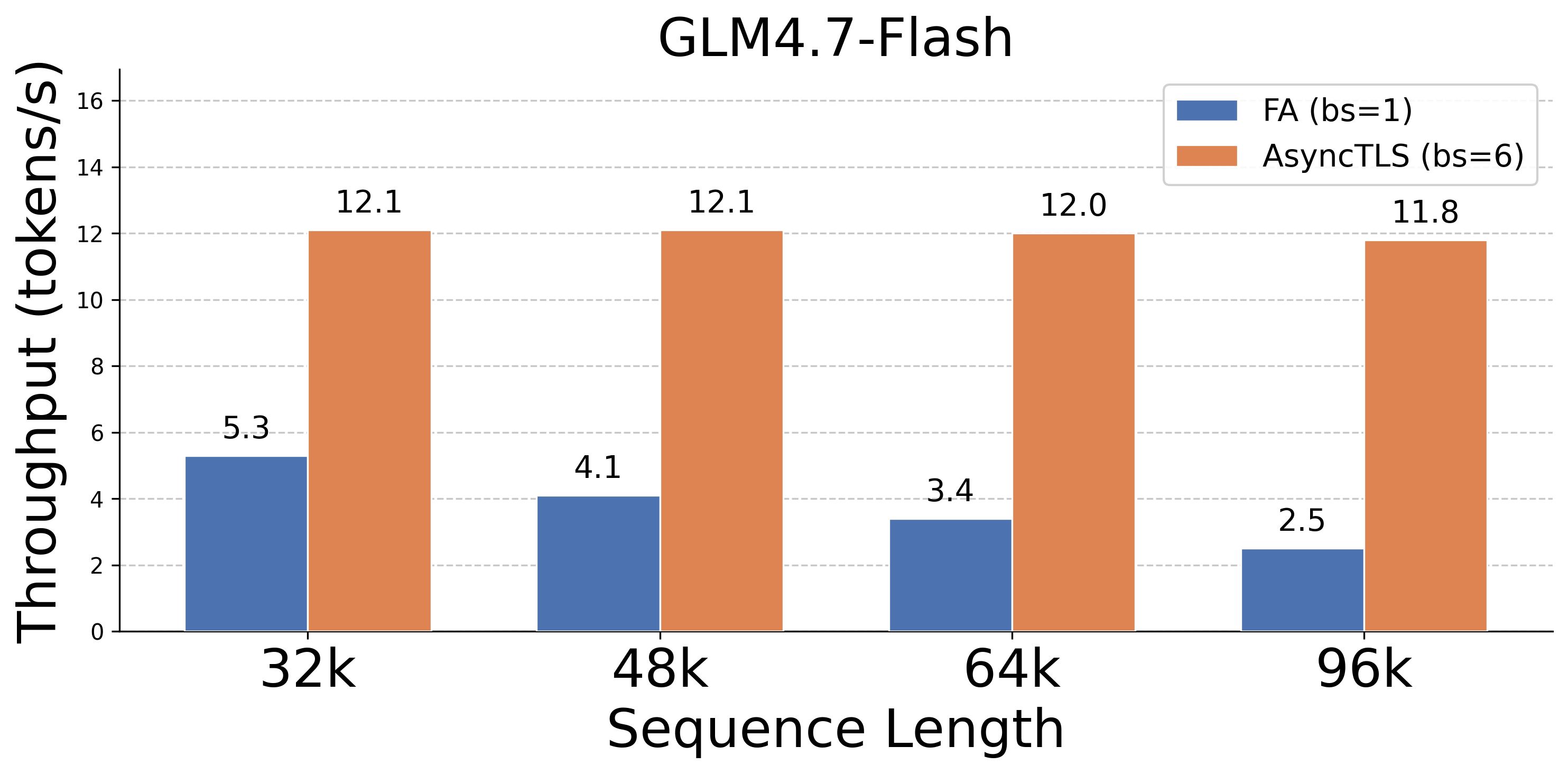
Figure 6: Throughput benchmarks; AsyncTLS enables high batch processing for long contexts.
Architectural and Practical Implications
AsyncTLS demonstrates hardware-agnostic compatibility (GQA, MLA), with no dependency on retraining or fine-tuning. Its hierarchical attention design and cache management pipeline make it suitable for production-scale LLM deployments where ultra-long context and efficient hardware utilization are essential. The asynchronous offloading engine directly addresses PCIe bottlenecks, supporting scalable inference with minimized memory overhead.
From a theoretical standpoint, the staged selection pipeline suggests a general strategy for balancing granularity and computational efficiency, applicable beyond Transformer-based attention. The exploitation of temporal locality in KV selection paves the way for further research into predictive cache management and pipeline optimization.
Future Directions
Potential future extensions include:
- Integration with learned adaptive selection strategies for block/token granularity rather than fixed heuristics.
- Hardware-specific kernel optimization to further maximize performance on emerging accelerator architectures.
- Combining hierarchical attention with other KV compression paradigms (e.g., latent or semantic clustering) for additional memory savings.
- Application to retrieval-augmented generation and streaming inference scenarios.
Conclusion
AsyncTLS introduces a training-free, hardware-efficient sparse attention architecture that reconciles the accuracy of fine-grained token-level selection with the efficiency of block-level processing. Its asynchronous KV cache offloading engine overlaps computation and memory transfer, exploiting temporal locality to minimize bandwidth requirements. Comprehensive experiments validate that AsyncTLS achieves parity with full attention accuracy while offering substantial operator speedups and throughput improvements for contexts up to 96k tokens. This work establishes a scalable foundation for practical long-context LLM deployment, and its principles are extensible to future developments in memory-efficient generative AI.