Compressed Convolutional Attention: Efficient Attention in a Compressed Latent Space
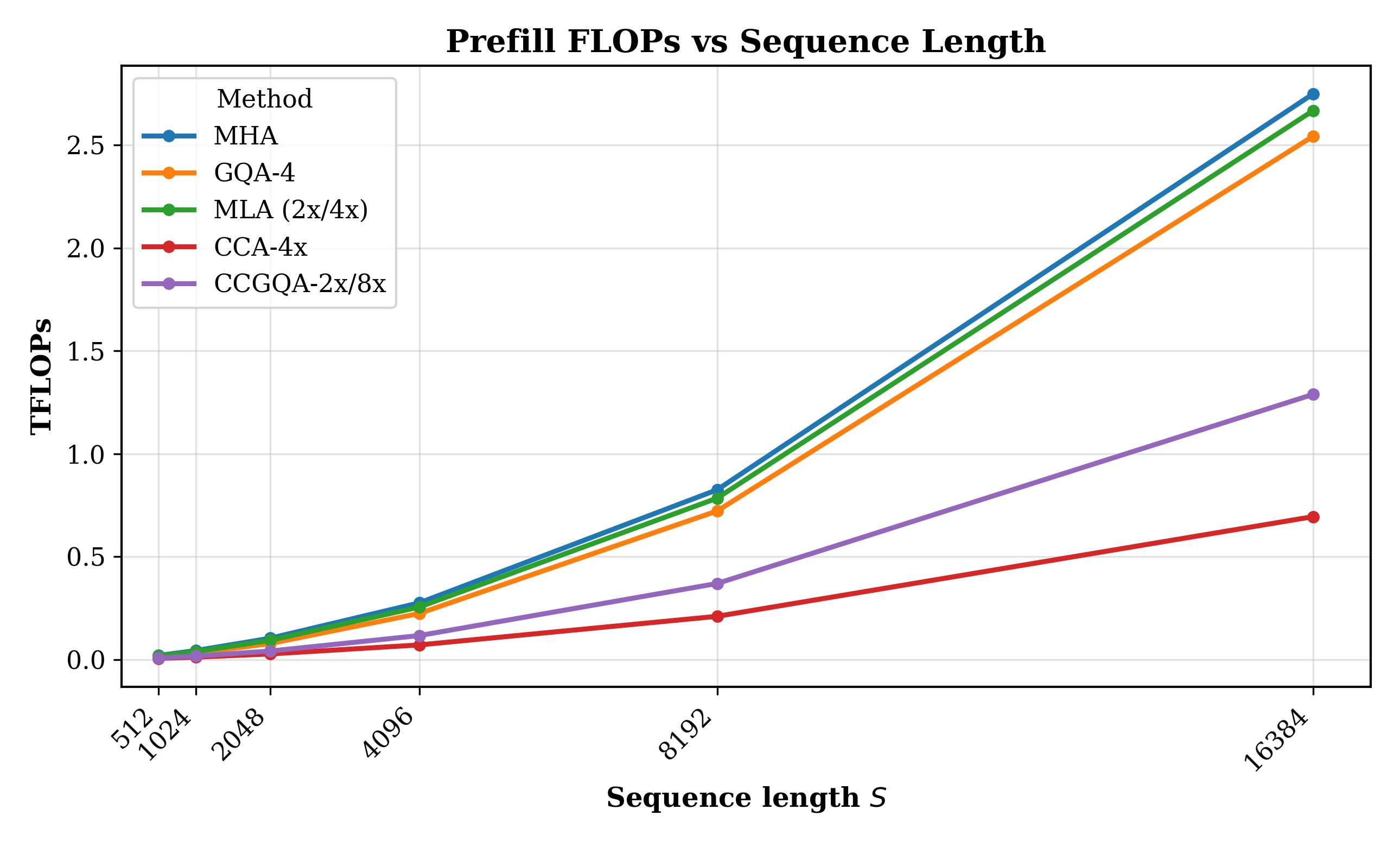
Abstract: Multi-headed Attention's (MHA) quadratic compute and linearly growing KV-cache make long-context transformers expensive to train and serve. Prior works such as Grouped Query Attention (GQA) and Multi-Latent Attention (MLA) shrink the cache, speeding decode, but leave compute, which determines prefill and training speed, largely unchanged. We introduce Compressed Convolutional Attention (CCA), a novel attention method which down-projects queries, keys, and values and performs the entire attention operation inside the shared latent space. This simple design dramatically cuts parameters, KV-cache, and FLOPs all at once by the desired compression factor. Because CCA is orthogonal to head-sharing, we combine the two to form Compressed Convolutional Grouped Query Attention (CCGQA), which further tightens the compute-bandwidth Pareto frontier so that users can tune compression toward either FLOP or memory limits without sacrificing quality. Experiments show that CCGQA consistently outperforms both GQA and MLA at equal KV-cache compression on dense and MoE models. Additionally, we show that CCGQA outperforms all other attention methods on MoE models with half the KV-cache of GQA and MLA, achieving an 8x KV-cache compression with no drop in performance compared to standard MHA. CCA and CCGQA also dramatically reduce the FLOP cost of attention which leads to substantially faster training and prefill than existing methods. On H100 GPUs, our fused CCA/CCGQA kernel reduces prefill latency by about 1.7x at a sequence length of 16k relative to MHA, and accelerates backward by about 1.3x.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a core part of how modern AI LLMs (like transformers) work: “attention.” Attention helps a model decide which earlier words in a sentence it should focus on when predicting the next word. The problem is that attention can be slow and use a lot of memory, especially when the model needs to look at very long texts.
The authors introduce a new way to do attention called Compressed Convolutional Attention (CCA). They also combine it with a popular technique called Grouped Query Attention to make Compressed Convolutional Grouped Query Attention (CCGQA). These methods make attention faster and lighter on memory while keeping (or even improving) model quality.
The big questions the paper asks
The paper explores simple, practical questions:
- Can we make attention much cheaper to run without hurting the model’s accuracy?
- Can we cut down the memory needed to store past information (the “KV-cache”) during generation?
- Can we do both at the same time—reduce compute and reduce memory—and still work well on long texts and complex tasks?
- How do these new methods compare to existing ones like Multi-Head Attention (MHA), Grouped Query Attention (GQA), and Multi-Latent Attention (MLA)?
How the new method works (in everyday terms)
Think of attention like a student looking back over notes to answer a question. The student keeps a “cache” of key points (K) and their details (V) from previous notes, and uses a question (Q) to find what’s relevant. Traditional attention stores and searches through a lot of high‑resolution notes, which is slow and memory‑heavy for long documents.
CCA does two big things:
- It shrinks the “resolution” of the notes before doing attention. In technical terms, it down-projects the queries (Q), keys (K), and values (V) into a smaller shared space and does all the attention there. This reduces both compute (fewer math operations) and memory (smaller cache).
- It gently “mixes” and improves the shrunk notes so the model doesn’t lose understanding. The paper adds three small, cheap tweaks that boost performance:
- Two tiny “convolution” steps on Q and K: like sliding a small window over the sequence and over the features to smooth and mix information. This helps the model keep useful patterns even after compression.
- A “q–k mean” skip connection: it shares some average info between Q and K so their relationship stays strong, like reminding the student how the question and the notes relate.
- A “value shift”: half of the value vectors come from the current token, half from the previous token. It’s like giving some heads a slightly delayed view, which can stabilize learning.
After attention in the compressed space, the result is expanded back to the model’s usual size.
CCGQA combines this compression with “grouping” of heads (like having multiple students share the same summarized notes). Doing both together lets you trade off compute and memory in flexible ways.
Helpful analogies for key terms:
- Attention: deciding which earlier words matter right now.
- KV-cache: the memory of past keys and values during generation—like a backpack of past notes the model keeps for reference.
- Compression: shrinking the size of those notes so they take less space and are faster to search, like storing lower‑resolution photos.
- Convolution: scanning with a small window to smooth and mix information, like reading line‑by‑line with a ruler to focus.
- RoPE (rotary position encoding): a way to keep track of “where” each token is in the sequence, similar to page numbers; CCA can apply this directly inside the compressed space.
What the experiments found and why it matters
Here are the main results:
- CCA and CCGQA reduce both compute (FLOPs) and memory (KV-cache) at the same time. Existing methods often only reduce memory or add overhead elsewhere.
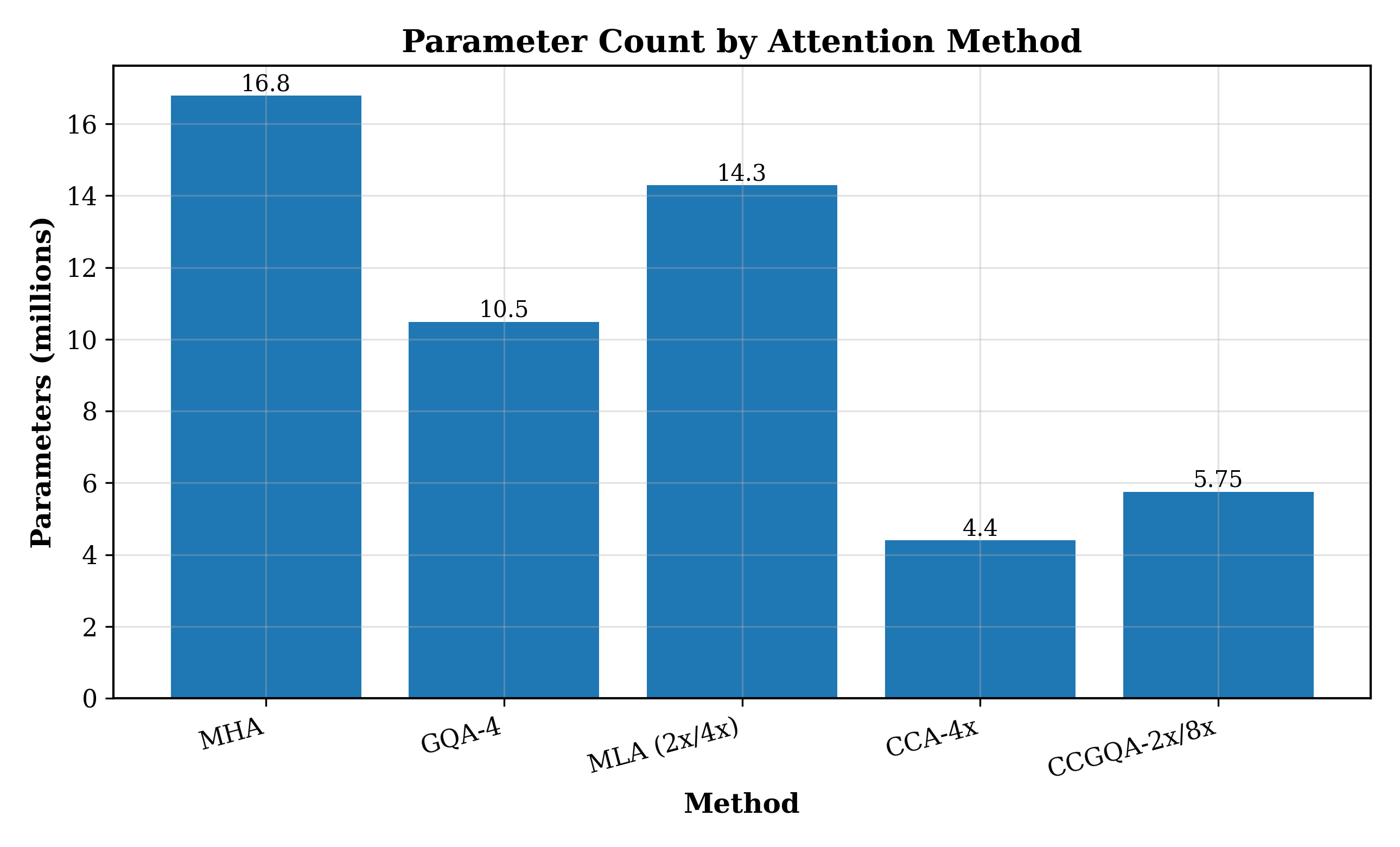
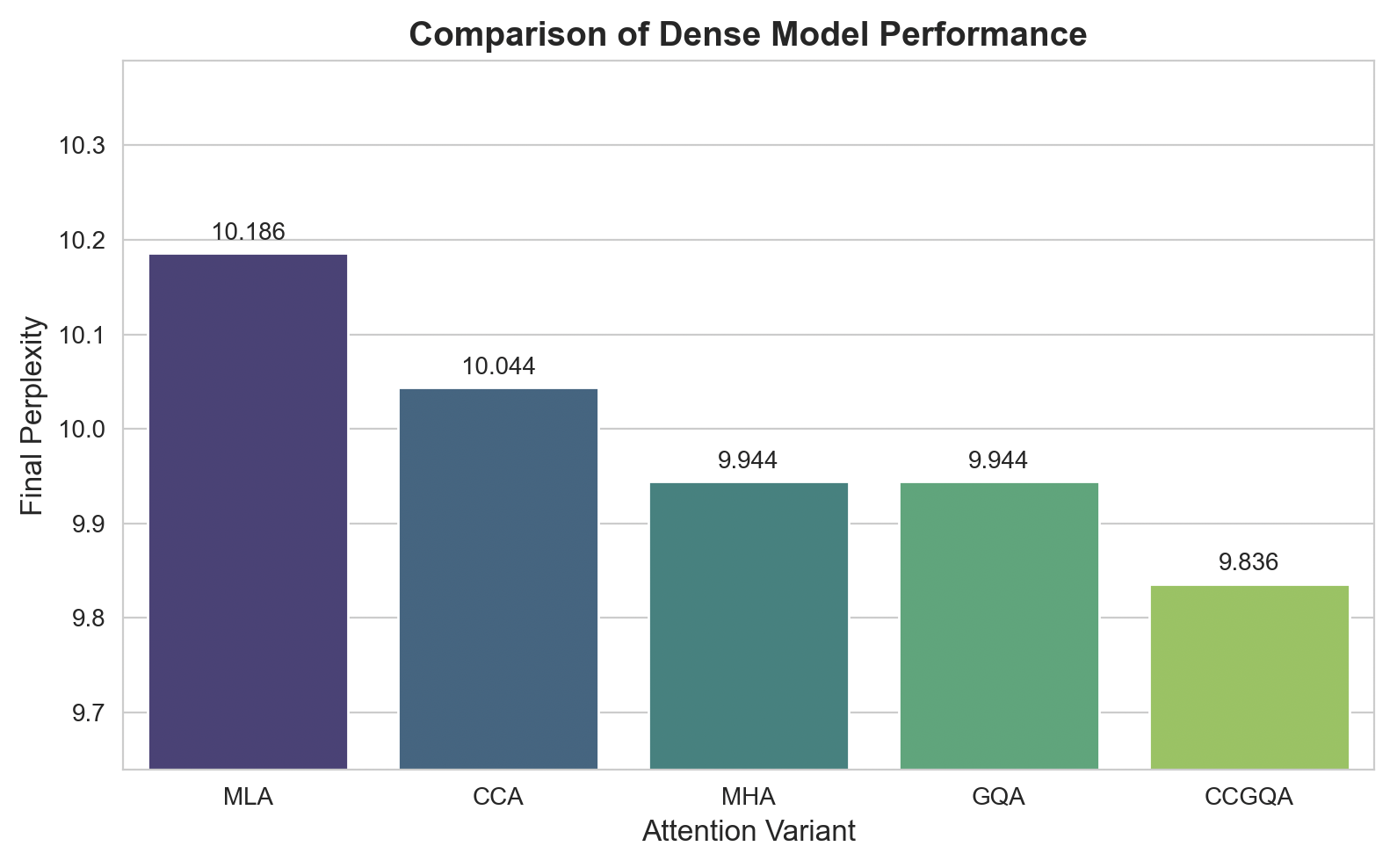
- At the same KV-cache compression, CCGQA consistently beats GQA and MLA on both dense models and MoE (Mixture-of-Experts) models.
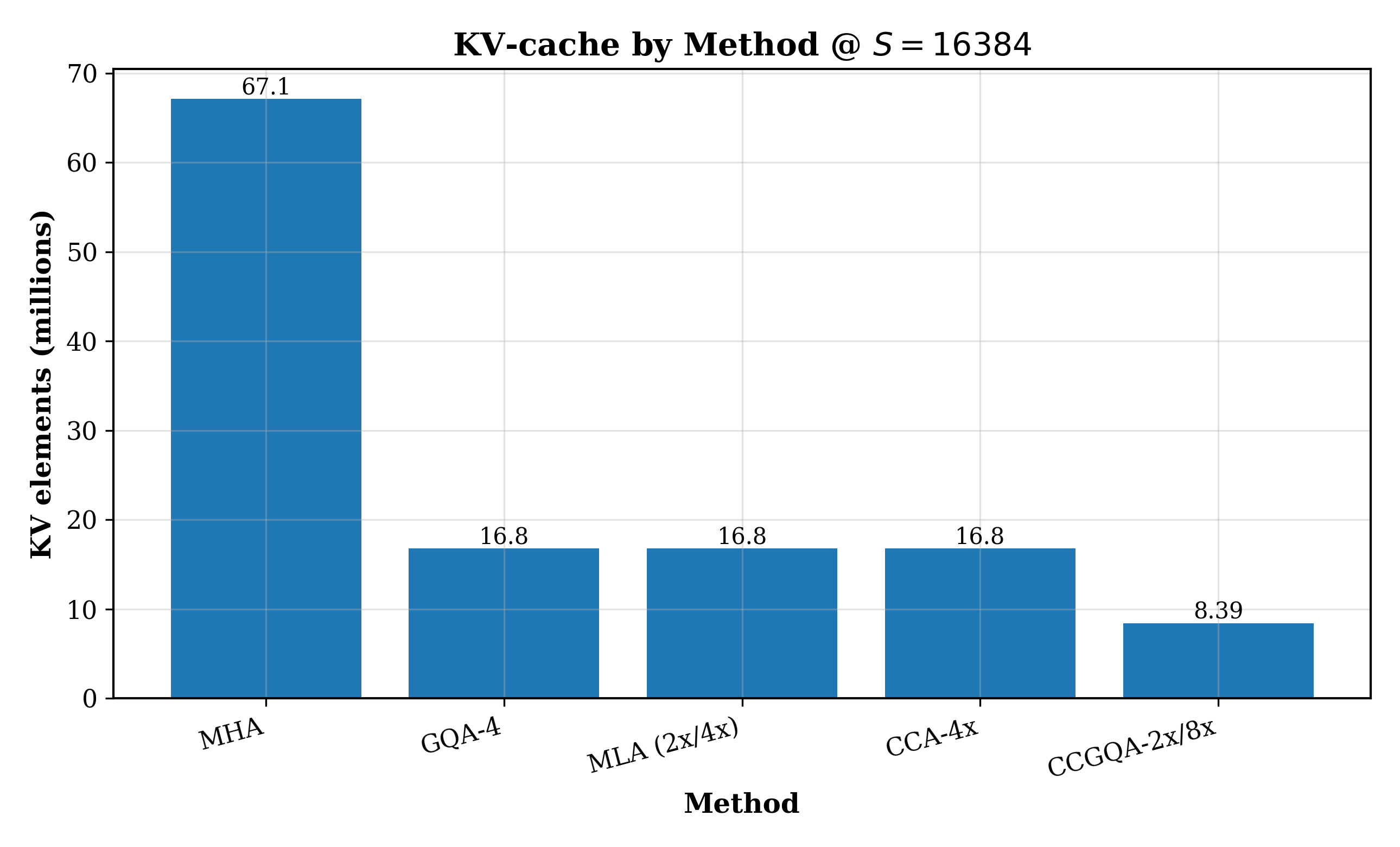
- On MoE models, CCGQA can use half the KV-cache that GQA and MLA need and still perform better—achieving about 8× KV-cache compression with no loss compared to standard attention (MHA).
- Speedups are substantial for long inputs:
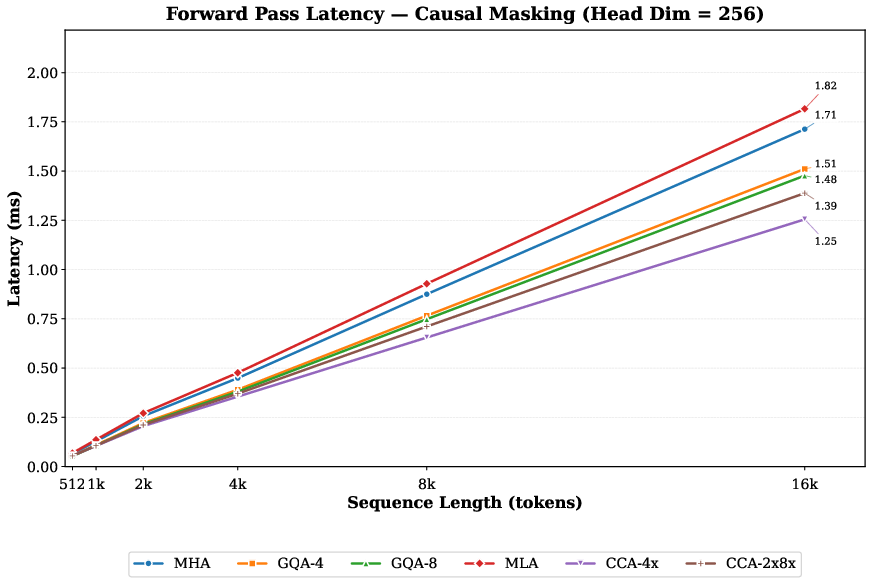
- On H100 GPUs at sequence length 16k, prefill (processing the input before generating) is about 1.6–1.7× faster than regular MHA.
- Backward pass during training is about 1.2–1.3× faster.
- The small tweaks (convolutions, q–k mean, value shift) make compressed attention work well in practice; removing them makes performance drop.
- Because CCA does attention entirely in the compressed space, it avoids extra complication with position encoding (RoPE) that MLA faces.
Why this matters: Long-context “reasoning models” often read thousands of tokens before answering. Cutting both memory and compute makes them cheaper and faster to train and serve, and enables longer contexts on the same hardware.
What this could mean going forward
- Better efficiency for long documents: Models can handle longer inputs faster and with less memory, which is useful for tasks like coding, legal analysis, and scientific papers.
- More flexibility: Because CCA and CCGQA let you tune compression separately for queries and keys/values, you can match your hardware limits—whether you’re constrained by compute or memory bandwidth—without sacrificing quality.
- Compatibility: CCA fits well with existing training and serving setups, and it can combine with head-sharing (GQA) or even future sequence-compressing tricks, making it a versatile building block.
- Faster research and deployment: Lower costs for training and inference mean quicker iteration cycles and more accessible long-context models.
In short, the paper shows a simple but effective idea: do attention in a smaller space, add just enough mixing to keep it smart, and combine it with sharing when helpful. That reduces both the time and memory attention needs—especially for long inputs—while keeping or improving model quality.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide future research and experimentation.
- Lack of compute-matched ablations: results are parameter- and KV-cache-matched, but not FLOPs/byte-matched; it remains unclear how CCA/CCGQA perform under strictly equal compute budgets versus MHA, GQA, and MLA during pretraining.
- Missing decode throughput measurements: the paper focuses on prefill latency; actual end-to-end autoregressive decode throughput (tokens/sec) and latency gains across batch sizes, context lengths, and KV-cache sizes are not reported.
- KV-cache system results deferred: empirical KV-cache bandwidth utilization, eviction policies, sharding overheads, and multi-device behavior are deferred to “follow-up work,” leaving uncertainty about real-world memory-bandwidth impacts in production inference.
- Limited scale: evaluations are confined to ~1B dense and ~350M-active/1.5B-total MoE; no evidence is provided for scaling beyond ~1–2B parameters (e.g., 7B–70B), where inductive biases and compression trade-offs can change.
- Narrow benchmarks: primarily perplexity and a small set of short-context tasks (HellaSwag, ARC, PiQA, Winogrande); no long-context evaluations (e.g., Needle-In-A-Haystack, BookSum), code-generation, math reasoning, or instruction-following tasks are reported.
- Length generalization untested: while CCA claims seamless RoPE integration, there are no systematic length-generalization studies (train vs. test context mismatch, e.g., 32k–128k) comparing MHA, GQA, MLA, CCA, and CCGQA.
- Compression frontier not mapped: only a few points are shown; a systematic sweep over compression factors and decoupled / (queries vs. keys/values), head counts, and group sizes is missing to establish the full Pareto frontier in accuracy vs. compute/memory.
- Convolution design not characterized: kernel sizes (
k_seq,k_ch), grouping strategies, and dilation choices are not systematically ablated; best practices for selecting these hyperparameters across layers and scales remain unknown. - Value-shift edge cases: the impact of using previous-token values on start-of-sequence handling, streaming inputs, and tasks that rely on immediate token information is not analyzed; optimal fraction of heads to shift and alternatives are unexplored.
- Mechanistic understanding of qk-mean and normalization: the paper reports gains but does not provide theoretical or mechanistic analyses (e.g., how qk-mean affects attention diagonality, induction head behavior, or gradient dynamics).
- Stability under extreme compression: failure modes, training instabilities, and quality degradation thresholds as grows (e.g., 16×–32×) are not characterized; guidance on safe operating regions is missing.
- Per-layer heterogeneity: whether compression and convolution settings should vary by layer depth (e.g., less compression early, more in middle layers) and the effects of per-layer adaptation are not explored.
- Robustness across data domains: performance is shown on Zyda2; transfer to varied domains (code, multilingual, scientific text, legal) and domain-shift robustness are not evaluated.
- Interaction with quantization: compatibility and accuracy under 8-bit/4-bit weight activation quantization, KV-cache quantization, and integer arithmetic kernels are not studied.
- Compatibility with sparse attention: how CCA interacts with block-sparse patterns, selective attention, or retrieval-augmented schemes (NSA, MoBA, DSA) is left as future work; joint sequence- and channel-compression remains unvalidated experimentally.
- Distributed training/inference details: while TP/CP feasibility is discussed qualitatively, quantitative measurements of collective overheads, halo sizes for causal convs, and scaling efficiency across multi-GPU nodes are not provided.
- Backward pass and memory profiling: only latency is reported; peak activation memory, optimizer-state memory, and end-to-end step time vs. sequence length (including checkpointing and recomputation) are missing.
- Effect on MoE routing and load-balancing: beyond parameter reallocation, there is no analysis of how compressed attention affects expert selection dynamics, routing stability, or load-balancing efficiency.
- Position embedding alternatives: claims that “any position embedding” can be integrated are not empirically validated; comparative results with ALiBi, learned positional embeddings, or NoPE across lengths are absent.
- Head specialization and expressivity: compressing the latent space likely alters head diversity and induction patterns; there is no study of how CCA impacts mechanistic interpretability or head specialization vs. MHA/GQA/MLA.
- Training hyperparameter sensitivity: missing ablations over learning rates, weight decay, normalization choices (pre/post-attention), dropout, and temperature parameter
βto assess stability and robustness. - Hardware generality: kernel benchmarks are only on H100 BF16; portability and performance on A100, consumer GPUs, or other accelerators (e.g., TPU) and different dtypes (FP8, INT8) are unknown.
- Implementation availability and reproducibility: while PyTorch snippets are mentioned, the fused kernels and full training recipes are not clearly open-sourced; reproducibility across frameworks and releases is uncertain.
- Start-to-end system trade-offs: practical guidance is missing on when to prefer CCA vs. CCGQA vs. MLA in different deployment regimes (memory-bound decode, compute-bound prefill, TP/CP topologies) with concrete, data-backed decision criteria.
- Interaction with offline KV compression: the paper suggests future exploration but provides no empirical results combining CCA’s compressed KV-cache with existing offline KV compression methods (e.g., clustering, lexico, lossless).
- Layer count vs. width trade-offs: how savings from attention compression should be reinvested (deeper networks vs. wider experts vs. larger feedforward) to maximize quality for a given budget is not studied.
- Error bounds and theory: there is no theoretical approximation analysis bounding attention quality loss under latent compression (e.g., projection error, rank constraints), leaving the limits of CCA’s expressivity unclear.
- Extreme group sizes in CCGQA: the accuracy/memory trade-offs as approaches MQA-like regimes within compressed latents are not characterized; when and why performance collapses is unknown.
- Data efficiency: whether CCA/CCGQA require more or less training tokens to achieve parity with MHA (sample complexity) is not investigated.
- Safety and robustness: adversarial or worst-case sequence behaviors (e.g., repetitive or degenerate prompts) and failure analyses under compression are not provided.
Practical Applications
Immediate Applications
The methods introduced—Compressed Convolutional Attention (CCA) and Compressed Convolutional Grouped Query Attention (CCGQA)—enable concrete, deployable improvements to long-context transformers by cutting parameters, KV-cache size, and FLOPs simultaneously. Below are specific, actionable uses.
- Cloud AI inference and LLM-as-a-service (software/AI infrastructure)
- Upgrade inference engines (e.g., vLLM, TensorRT-LLM, TGI) with CCA/CCGQA blocks and fused kernels to deliver 1.3–1.7× faster prefill for long prompts (e.g., 16k tokens), shrink KV-caches by up to 8× with no quality loss (MoE), and raise concurrency per GPU.
- Offer user-selectable “compression profiles” (e.g., C1=2 for queries, C2=8 for KV) to trade memory vs compute without retraining the serving stack.
- Dependencies: Availability of fused CUDA/Triton kernels; models must be pretrained/finetuned with CCA/CCGQA; best results currently demonstrated on H100-class GPUs; long-context training and RoPE-in-latent integration must be in the model.
- Faster, cheaper pretraining and finetuning (industry and academia)
- Replace MHA/GQA/MLA with CCA/CCGQA in training pipelines (PyTorch/JAX) to reduce attention FLOPs and accelerate forward (∼1.6–1.9× causal) and backward (∼1.2–1.3×) passes at long sequence lengths.
- Reinvest saved parameters and compute into MoE experts to improve quality at fixed total/active parameter budgets.
- Dependencies: Model retraining; kernel fusion for convolutions + attention; careful hyperparameter tuning (convolution kernel sizes, compression factors); benefits increase with sequence length.
- Long-context enterprise applications with lower TCO (healthcare, legal, finance, customer support, software engineering)
- Run longer contexts (128k–256k) on fewer GPUs for: contract review and e-discovery, EHR summarization, compliance/report analysis, call center transcripts, long meeting minutes, and large-repo code assistants.
- Reduce or eliminate costly context-parallelism (ring/tree) for many workloads by holding entire KV in-device at compressed widths.
- Dependencies: Models trained to handle long contexts; domain evaluation to validate quality; integration into existing RAG pipelines (retrieval chunking can be simplified with longer effective contexts).
- On-prem and small-footprint deployment (regulated industries and SMBs)
- Fit longer-context models on smaller VRAM cards (e.g., 24–48 GB) by shrinking KV-cache and attention parameters, enabling air-gapped inference and improved multi-tenant isolation.
- Combine with quantization and speculative decoding to further lower latency and memory.
- Dependencies: CCA-capable model checkpoints; kernel support for older GPUs; quantization-aware finetuning as needed.
- Distributed systems and parallelism simplification (cloud/platform teams)
- Reduce TP/CP communication by sharding the narrower latent (E/C) instead of full-width E; simplify context-parallel collectives by communicating compressed states.
- Integrate CCA into pipeline- and tensor-parallel schedules for better prefill-bound throughput.
- Dependencies: Framework support (NCCL collectives tuned for E/C widths); matching TP ranks to group counts for CCGQA; operator fusion.
- Cost and sustainability reporting (policy/ESG, procurement)
- Include CCA-driven FLOP and memory-movement reductions in model cards and emissions calculators to report lower energy-per-token for long-context workloads.
- Dependencies: Measurement protocols beyond raw FLOPs (include memory traffic); third-party verification.
- Research baselines and ablations (academia)
- Establish CCA/CCGQA as new baselines for long-context and MoE studies; ablate sequence/channel convolutions, q-k-mean, and value-shift to study inductive biases.
- Tools/Workflows: Release of CCA kernels, Hugging Face Transformers integration, benchmark suites (e.g., long-context retrieval/reasoning, MoE routing).
- Dependencies: Open-source implementations and checkpoints; reproducibility kits.
- Serving orchestration and scheduling (LLM platform ops)
- Adjust batching and admission control to exploit faster prefill for prompt-heavy traffic (e.g., RAG); dynamically swap between compression profiles (C1/C2) based on live memory headroom and latency SLOs.
- Dependencies: Telemetry for prompt vs generate ratios; autoscaling policies aware of KV-cache occupancy and compression.
- Security and multi-tenant hygiene (platform security)
- Smaller per-request KV-caches reduce memory pressure and simplify zeroization and isolation, decreasing cross-tenant leakage risk windows.
- Dependencies: Correct per-request memory isolation; no change to model data handling policies required.
Long-Term Applications
As the ecosystem matures and kernels, models, and tooling generalize, the following applications become increasingly feasible.
- On-device long-context assistants (consumer devices, education, software)
- Achieve laptop/phone-level 128k+ context with manageable KV and compute for personal knowledge management, offline tutoring, and IDE copilots that track entire project histories.
- Dependencies: CCA kernels on mobile NPUs/GPUs; thermal/power constraints; compact CCA-trained checkpoints; robust long-context training.
- Multimodal long-sequence models (media, autonomy, surveillance)
- Apply CCA to video/audio transformers to handle very long temporal sequences with 1/C FLOP scaling; convolutional mixing may align naturally with temporal locality.
- Products: Hours-long meeting/video summarizers, in-cabin monitoring, continuous compliance recording analysis.
- Dependencies: Extending CCA to multimodal fusion layers; large-scale multimodal training sets; latency-critical decoding paths.
- Hardware–software co-design for compressed attention (semiconductors)
- Build accelerators with fused conv–attention primitives and SRAM hierarchies sized for compressed latents (E/C), optimizing both compute and bandwidth.
- Dependencies: Standardization of CCA ops; stable adoption across frameworks; co-design with memory fabrics.
- Adaptive per-layer/per-runtime compression (inference engines)
- Auto-tune C1/C2 per layer or per request (e.g., higher compression in shallow layers or at longer prompts), or adapt at runtime based on prompt length and device telemetry.
- Tools: Controllers and schedulers that optimize the compute–bandwidth Pareto frontier on-the-fly.
- Dependencies: Research on stability/quality under dynamic compression; calibration procedures; guardrails for catastrophic degradation.
- Combining channel/cache compression with sequence selectivity (LLM providers)
- Integrate CCA with selective/blocked attention (e.g., NSA, MoBA, DSA) to reduce complexity in both channel (E) and sequence (S), enabling 1M+ token contexts at practical cost.
- Dependencies: Algorithmic integration; training curricula; evaluation of recall/precision trade-offs.
- Standardized KV-cache compression ecosystem (industry consortia, policy)
- Define interop formats, telemetry, and benchmarks for compressed KV-caches; include privacy-preserving cache handling and DP accounting for KV reuse.
- Dependencies: Engagement by MLCommons and standards groups; cross-vendor agreement on metrics.
- Federated/private long-context fine-tuning (healthcare, finance, public sector)
- Train on-device/on-prem with long proprietary logs (EHRs, trading books, case records) under privacy constraints thanks to reduced memory/compute demands.
- Dependencies: Policy approvals; privacy-preserving optimizers; secure aggregation.
- Energy-aware AI procurement and regulation (policy/ESG)
- Establish FLOP/byte efficiency thresholds for public-sector AI deployments; prefer compressed-attention models for long-context tasks to meet sustainability targets.
- Dependencies: Widely accepted efficiency metrics; audit frameworks and independent evaluations.
- Education-scale history-aware tutors (education tech)
- Maintain semester-long student histories within context to personalize feedback while running on institutional hardware.
- Dependencies: Safety/fairness studies; long-context pedagogical evaluation; IT integration.
- Developer platforms with full-repo context (software)
- Provide continuous code review and refactoring across entire codebases at low latency/cost by minimizing KV overhead and prefill time.
- Dependencies: Strong code-task performance with CCA; toolchain integration (LSPs, CI/CD); privacy of source code.
- Compliance and large-scale document workflows (legal/finance/government)
- Process millions of pages/contracts with longer uninterrupted contexts, reducing chunking errors and improving auditability at lower GPU-hour budgets.
- Dependencies: Domain adaptation; verifiable accuracy; workflow certification.
- Long-horizon planning and robotics (robotics, operations)
- Adapt CCA to decision/trajectory transformers to support longer temporal horizons with lower memory footprint and latency.
- Dependencies: Method transfer to control settings; real-time constraints; safety validation.
- Real-time translation/subtitling with discourse memory (media/live events)
- Maintain minute-scale context streams on edge devices, improving coherence and terminology consistency.
- Dependencies: Low-latency ASR integration; streaming attention with compressed KV; QoS guarantees.
Cross-cutting assumptions and dependencies
- Retraining/finetuning is typically required; CCA is not a drop-in replacement for MHA weights.
- Fused kernels are crucial; naive implementations can forfeit much of the theoretical gains due to extra ops (convolutions, q-k-mean, value-shift).
- Best empirical speedups shown on H100 with BF16; gains on older GPUs/CPUs/NPUs depend on kernel maturity.
- Inductive biases from conv mixing and value-shift improve small/mid-scale models; behavior at very large scales should be validated.
- Long-context benefits require training with appropriate context lengths and robust positional handling (RoPE-in-latent is supported).
- MoE configurations benefit disproportionately by reallocating saved attention parameters to experts; gating and routing remain standard.
Glossary
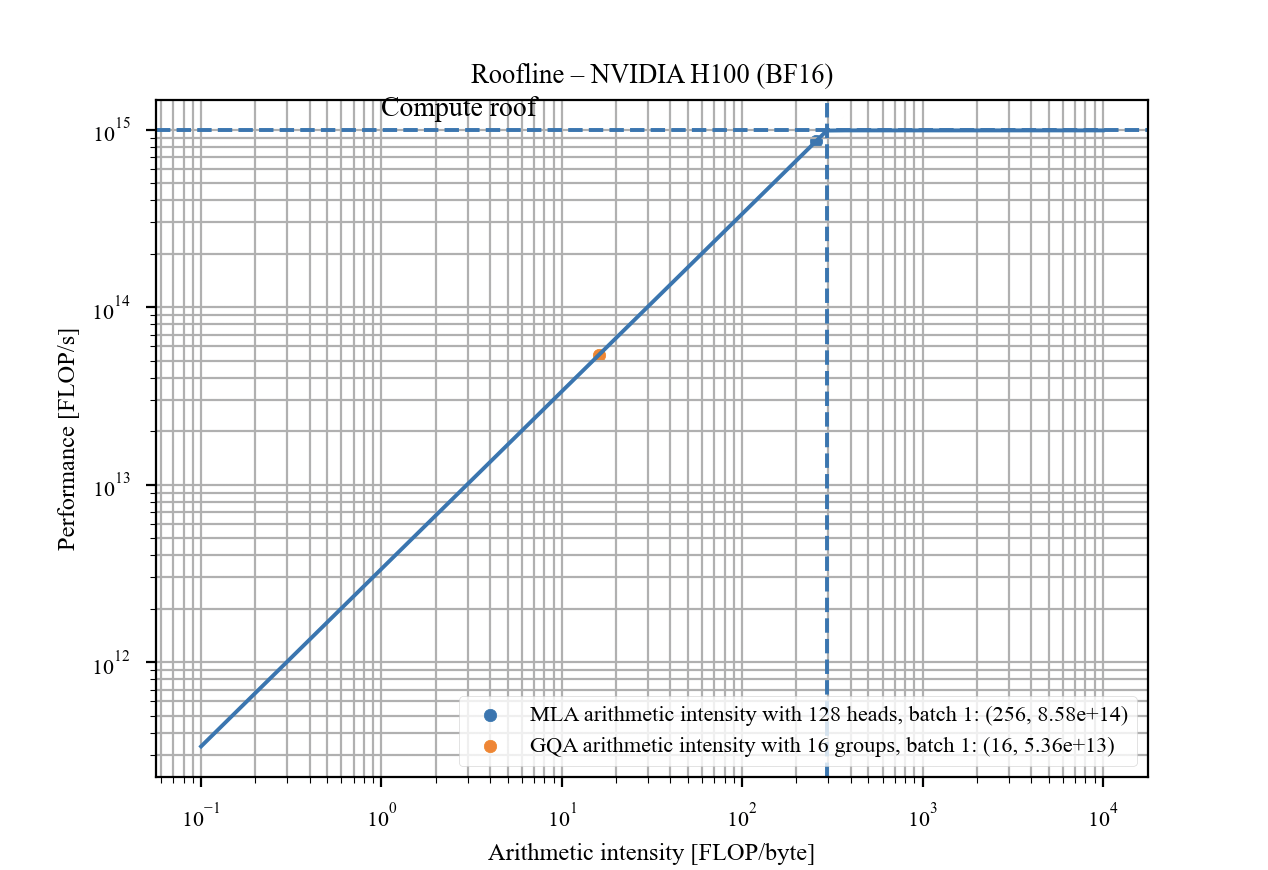
- Arithmetic intensity: Ratio of computation to memory movement; higher means more compute per byte moved, relevant to GPU efficiency. "Compressed Convolutional Attention (CCA) executes the entire attention operation in a compressed latent space, which significantly reduces both the arithmetic intensity and the data-movement requirements relative to competing methods such as MHA, GQA, and MLA."
- Autoregressive generation: Token-by-token generation where past outputs become future inputs. "Moreover, during autoregressive generation the KV-cache grows linearly with sequence length and hidden size, incurring huge memory-bandwidth costs that cannot be amortized across batches."
- BFLOAT16: A 16-bit floating-point format used for efficient training/inference on modern accelerators. "Performance of CCA versus competing attention methods with hidden dimension 2048 and BFLOAT16 on an H100 GPU"
- Canon layers: Convolutional mixing layers proposed to enhance expressivity across MLP and attention blocks. "In a similar vein, recently-proposed ``canon layers'' are convolutional mixing layers applied across MLP and attention layers"
- Causal convolution: Sequence convolution limited to past context to preserve causality in autoregressive models. "similar to how the causal convolution prior to the SSM in Mamba \citep{gu2023mamba} improves sequence mixing performance."
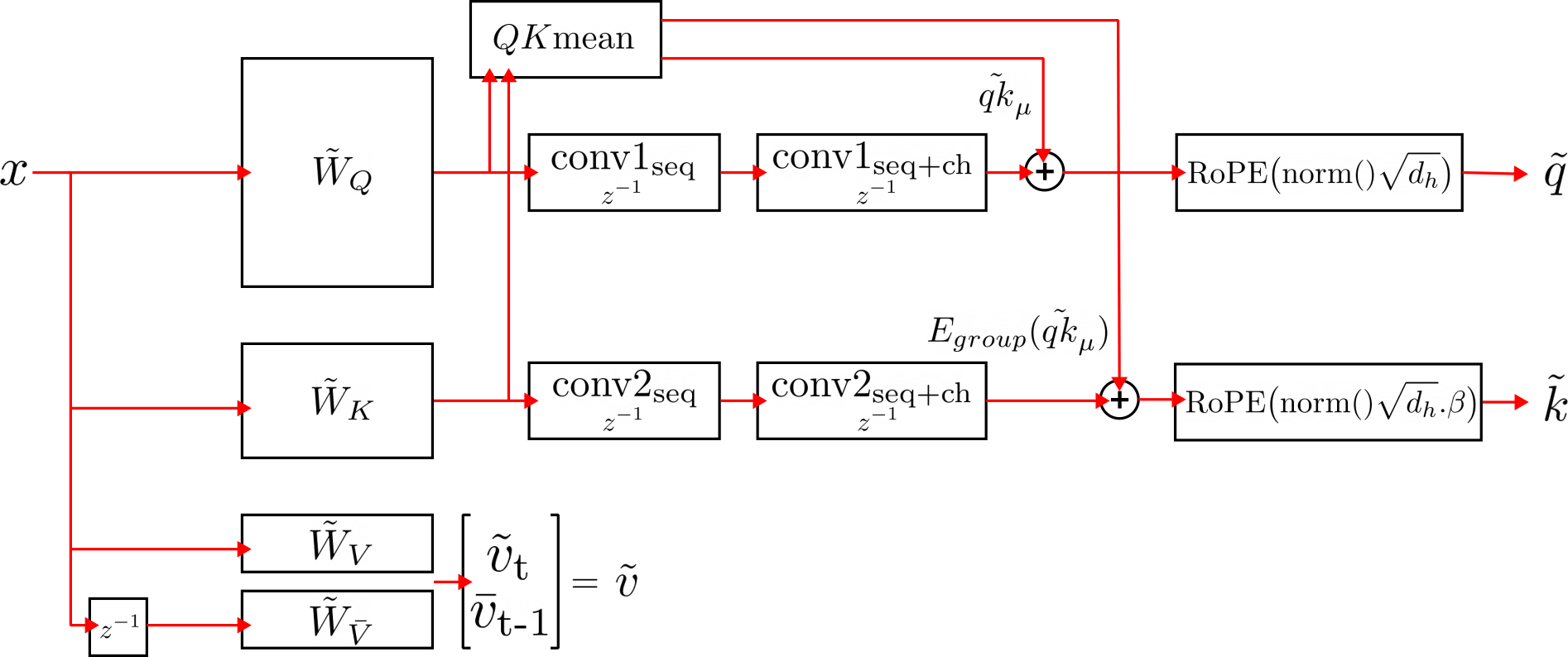
- Compressed Convolutional Attention (CCA): Attention performed entirely in a compressed latent space with added convolutional mixing and adjustments. "In this paper, we present Compressed Convolutional Attention (CCA), an elegant parameter- and compute- compression method, which removes the drawbacks of MLA and outperforms it in practice."
- Compressed Convolutional Grouped Query Attention (CCGQA): Combination of CCA with GQA-style head sharing to further reduce compute and KV-cache. "we find it is productive to combine them in a method we call Compressed Convolutional Grouped Query Attention (CCGQA) which applies a GQA-style K and V head sharing within the already compressed latent space."
- Convolutional mixing: Additional convolution operations across sequence and channel dimensions to enhance compressed Q/K expressivity. "We find that performing convolutional mixing across both the sequence and channel dimensions (within a head) for q and k can substantially improve the resulting performance of CCA."
- Context-parallelism: Distributing the KV-cache across devices to serve long contexts. "Serving models with KV-caches larger than a single GPU requires expensive context-parallelism approaches like Ring or Tree Attention"
- Decoding: Inference phase where the model generates tokens conditioned on past outputs. "During decoding, however, MLA possesses an ‘MQA-mode’ which merges the up-projections for the shared-KV cache into the query up-projection and output projection."
- Down-projection: Linear mapping from a high-dimensional space to a lower-dimensional latent to compress representations. "The compression is done with linear down-projections, such as $\tilde{W}_{DKV} \in \mathcal{R}^{E \times \tilde{e}$"
- Flash Attention: Kernel family for fast and memory-efficient attention via online softmax and tiling. "prior to performing standard Flash Attention on the compressed latents."
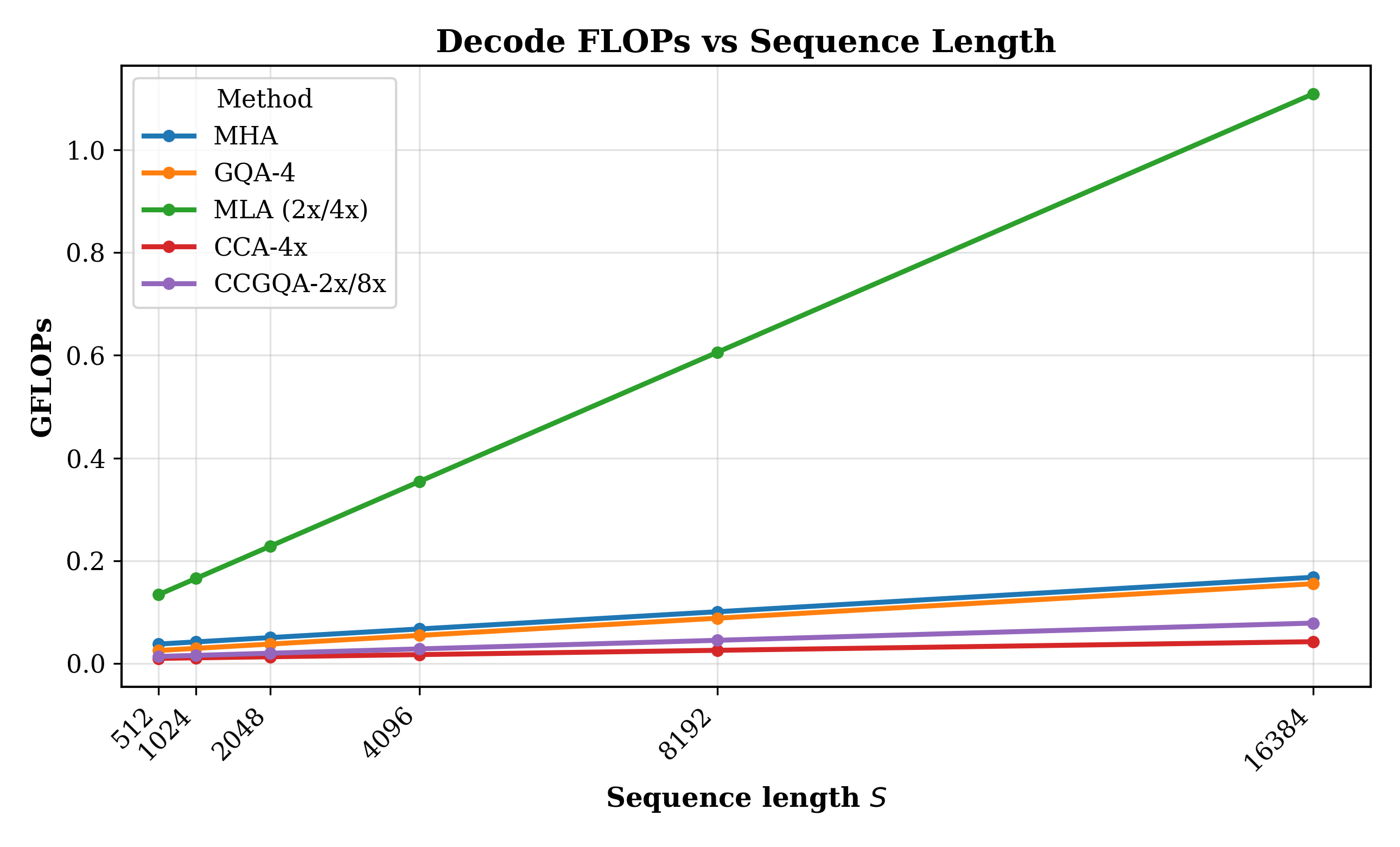
- FLOPs: Floating-point operations; measure of computational cost. "Prefill FLOPs vs sequence length"
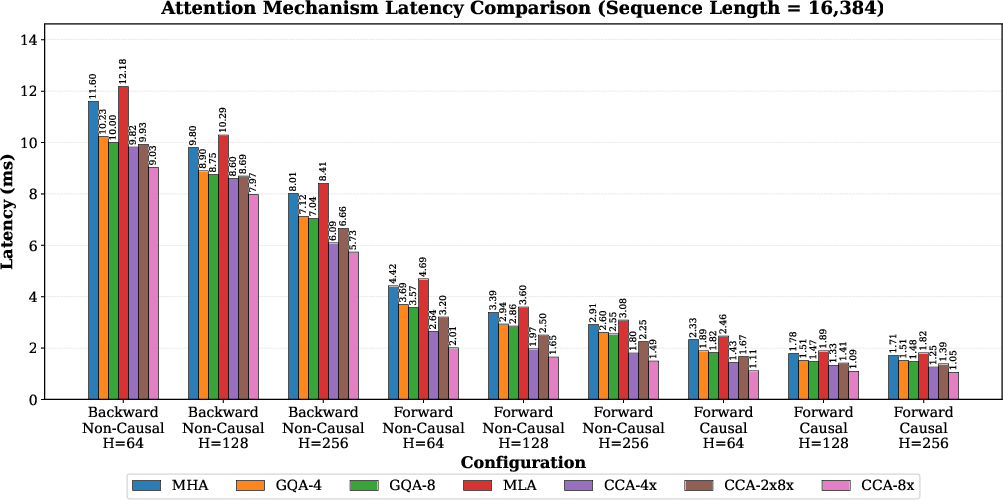
- Forward-causal: Causal attention computation in the forward pass (prefill). "while forward-causal shows gains."
- Grouped Query Attention (GQA): Parameter-sharing across K/V heads to shrink KV-cache while keeping attention primitive. "GQA has seen significant recent adoption for LLM pretraining being used in \cite{jiang2023mistral,touvron2023llama,abdin2024phi} and results in significant improvement in inference speed."
- Head-sharing: Sharing parameters among multiple attention heads to reduce memory and bandwidth. "Because CCA is orthogonal to head-sharing, we combine the two to form Compressed Convolutional Grouped Query Attention (CCGQA), which further tightens the computeâbandwidth Pareto frontier"
- Inductive bias: Architectural bias that guides learning toward certain functions or structures. "This induces a measure of inductive bias into CCA which is less present in MLA and GQA and may mean that CCA outperforms at small scales while the benefits lessen at larger scales."
- KV-cache: Stored keys and values across sequence positions used for efficient autoregressive attention. "Multi-headed Attention's (MHA) quadratic compute and linearly growing KV-cache make long-context transformers expensive to train and serve."
- L2 normalization: Scaling vectors to unit L2 norm to stabilize attention logits. "Given the compressed latent vectors , we then perform Q, K L2 normalization and scale by the square-root of the head dimension"
- Latent halo: Extra tokens kept around to support convolutional operations at sequence edges. "Unlike MLA, CCA applies RoPE directly in the latent and only needs a constant-size latent halo for the causal convolutions and one-token value-shift"
- Latent space: Lower-dimensional shared representation where compressed Q/K/V live. "We introduce Compressed Convolutional Attention (CCA), a novel attention method which down-projects queries, keys, and values and performs the entire attention operation inside the shared latent space."
- Multi-Head Attention (MHA): Classical attention with multiple independent heads for expressivity. "Multi-headed Attention's (MHA) quadratic compute and linearly growing KV-cache make long-context transformers expensive to train and serve."
- Multi-Latent Attention (MLA): Attention variant that stores a shared compressed KV latent and up-projects to full dimension for computation. "Recently, another attention variant named Multi-Latent Attention (MLA) \citep{deepseekv3} took a different approach by learning to directly compress the K and V projections needed for the KV-cache."
- Multi-Query Attention (MQA): Attention with shared K/V across all heads to reduce KV-cache size. "Multi-query attention (MQA) \citep{shazeer2019fast}, and grouped query attention (GQA) \citep{ainslie2023gqa} keep the core self-attention primitive and reduce the KV-cache requirements by parameter-sharing across K and V heads."
- Mixture of Experts (MoE): Architecture with multiple expert modules where a subset is activated per input. "Experiments show that CCGQA consistently outperforms both GQA and MLA at equal KV-cache compression on dense and MoE models."
- Memory-bandwidth-bound: Performance limited by data movement rather than computation. "During decoding, however, MLA possesses an ‘MQA-mode’ ... This significantly reduces the memory bandwidth-required during decoding."
- NoPE: No positional embeddings; a setting where positional encodings are absent or handled differently. "In the NoPE \citep{wang2024lengthgeneralizationcausaltransformers} setting, MLA is advantageous as one can amortize all up-projections at test time and transform into MQA"
- Online softmax: Softmax computed incrementally during tiled attention to avoid large intermediate buffers. "We have designed an H100 GPU kernel to fuse the convolution with an online softmax in the style of the flash attention series of kernels \citep{dao2023flashattention2}."
- Pareto frontier: Trade-off curve where improving one metric worsens another; here compute vs bandwidth. "Compressed Convolutional Grouped Query Attention (CCGQA), which further tightens the computeâbandwidth Pareto frontier so that users can tune compression toward either FLOP or memory limits without sacrificing quality."
- Prefill: The initial attention pass over input tokens before any decoding steps. "Prefill performance is especially important during long-context workloads where the vast majority of tokens are inputs to the model rather than generated."
- Residual stream: The main sequence of embeddings passed through transformer layers to which outputs are added. "Classical multi-head attention (MHA) operates on the input embedding coming from the residual stream in a transformer"
- Ring Attention: A context-parallelism scheme distributing KV across devices in a ring topology. "Serving models with KV-caches larger than a single GPU requires expensive context-parallelism approaches like Ring or Tree Attention"
- RoPE (Rotary Positional Embeddings): Positional encoding scheme that rotates Q/K vectors to encode position. "RoPE \citep{su2023rotary}, which cannot operate directly on the compressed cache, so MLA must keep a separate key RoPE cache shared across heads."
- State-space models (SSMs): Sequence models with constant-size states used to replace or augment attention. "This led to the proposal of hybrid architectures ... which combine both SSMs and attention, and can achieve the best of both worlds."
- Tensor-parallel: Splitting model tensors across devices to parallelize computation. "While being parameter efficient, MQA is not entirely advantageous in multi-device inference in tensor-parallel settings, as each device would receive a copy of the shared KV latent before performing attention"
- Token-shift: Technique where some heads attend to previous tokens to enforce temporal bias. "RWKV \citep{peng2023rwkv} use a similar approach (which they call token-shift); which they find improves performance of their RNN-based sequence mixer."
- Temperature scaling (β): Learnable scaling of key vectors to adjust attention sharpness. "multiply the key by a learnable temperature parameter "
- Tree Attention: A context-parallelism method using tree-structured communication. "Serving models with KV-caches larger than a single GPU requires expensive context-parallelism approaches like Ring or Tree Attention"
- Up-projection: Linear mapping from compressed latent back to the full dimensionality. "the K and V heads are generated using separate up-projection matrices of shape "
- Value-shift: Operation where half of value heads use previous-token embeddings to add temporal bias. "Finally, for the value projection, we introduce an operation referred to as value-shift."
- QK-mean: Operation adding the mean of pre/post-convolution Q/K to each other as a residual for stability. "Next, we perform the q-k-mean operation, which adds the mean of the values of q and k pre and post convolution to the convolved values."
- QK-norm: Combined normalization of queries and keys to control attention score distribution. "Geometrically, this increases the sparsity of the attention diagonal when combined with QK-norm."
Collections
Sign up for free to add this paper to one or more collections.

