Trajectory Geometry of Transformer Representations Across Layers
Abstract: Understanding how transformer representations evolve across layers, not merely what they encode, remains an open problem in mechanistic interpretability. We recast the transformer forward pass as a discrete population trajectory through a high-dimensional representation manifold, drawing on geometric tools from computational neuroscience. Rather than probing for pre-specified features, we characterize trajectory geometry using five metrics computed directly in the ambient space: trajectory length, curvature, a semantic convergence index, layerwise cosine similarity, and representational stability. Across three model families (GPT-2, TinyLlama, Qwen2.5) and five controlled prompt families, we report four findings. First, semantically related prompts converge significantly in middle-to-late layers (peak CI 0.41--0.58, p<0.001, Mann-Whitney U), consistent with attractor-like dynamics. Second, reasoning tasks produce trajectories of greater curvature than lexical variations (0.71--0.83 rad vs. 0.27--0.31 rad), suggesting curvature encodes computational complexity. Third, ambiguous tokens exhibit trajectory bifurcation with up to 5.6x representational separation by the final layer, absent in unambiguous controls. Fourth, layerwise cosine similarity reveals a universal three-phase structure: encoding, elaboration, and output preparation, consistent across all three architectures. All four effects vanish under shuffled-layer and random-embedding controls. We release a fully open-source, model-agnostic pipeline and argue that trajectory geometry constitutes a principled, probe-free lens for mechanistic interpretability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “Trajectory Geometry of Transformer Representations Across Layers”
What is this paper about?
This paper studies how a transformer (a kind of AI that reads and writes text) changes its internal “thoughts” step by step from the input to the output. Instead of asking “what does a layer know?”, the authors ask “how do the model’s internal states move and change across layers?” They treat these changes like a path (a trajectory) moving through a very high‑dimensional space and measure the shape of that path.
What questions did the researchers ask?
The team focused on four simple questions:
- Do prompts with similar meaning gradually move closer together inside the model as they pass through layers?
- Do harder tasks (like multi‑step reasoning) cause the model’s internal path to bend and twist more than easy tasks (like small wording changes)?
- When a word is ambiguous (like “bank”: river bank vs. money bank), does the model’s internal path split into two different directions as context clarifies the meaning?
- Is there a repeatable “three‑phase” pattern in how layers process information (for example: first encode, then think, then prepare to answer)?
How did they study it? (Methods explained simply)
They ran three open models locally (GPT‑2 Small, TinyLlama‑1.1B, Qwen2.5‑1.5B) on five groups of short prompts designed to test meaning, wording changes, analogies, multi‑step reasoning, and ambiguity.
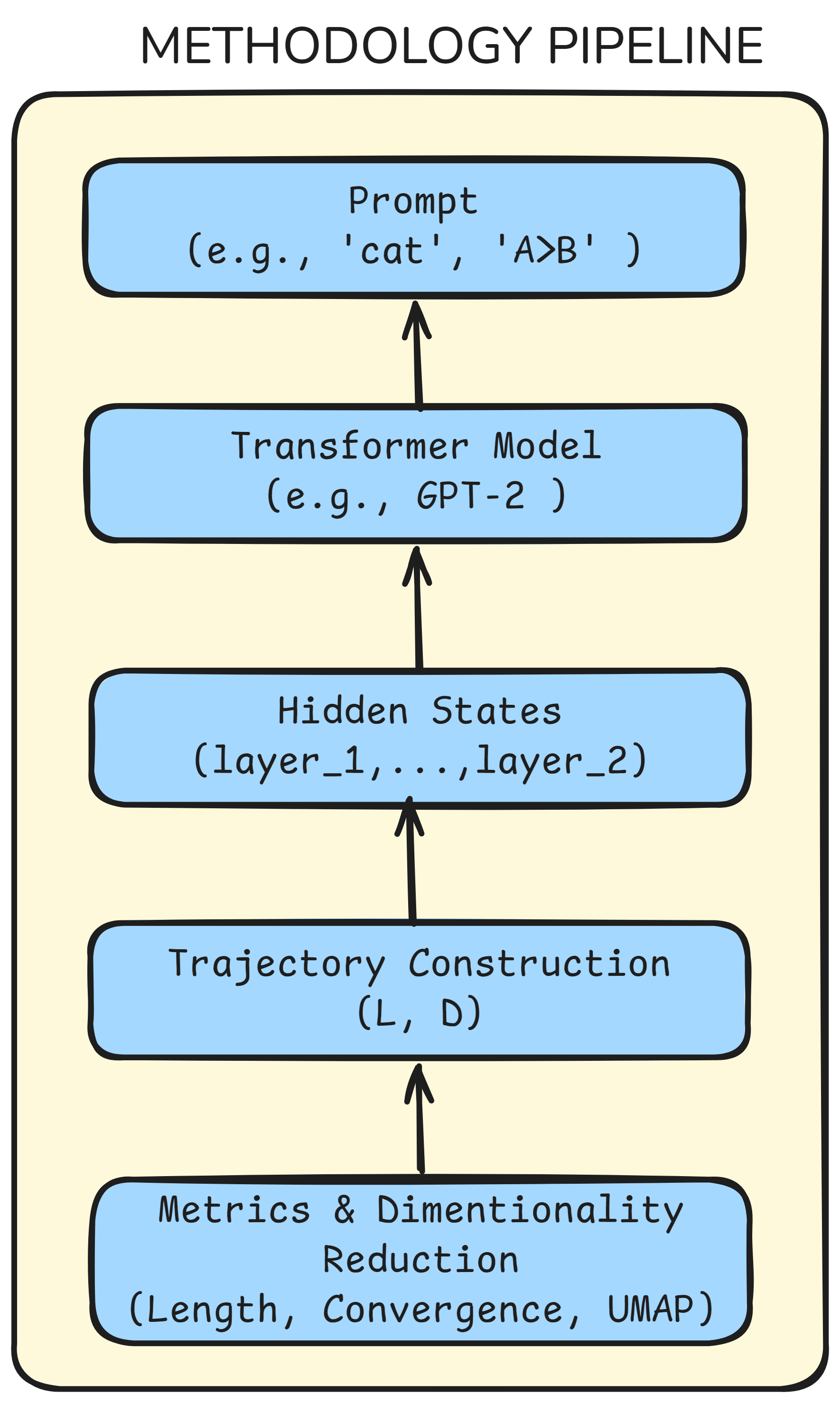
At each layer, a transformer creates a hidden representation (you can think of this as an internal summary). For each prompt, they:
- Collected the hidden representation at every layer.
- Averaged across the tokens in the prompt to get one vector per layer (like taking the “overall” internal summary at that step).
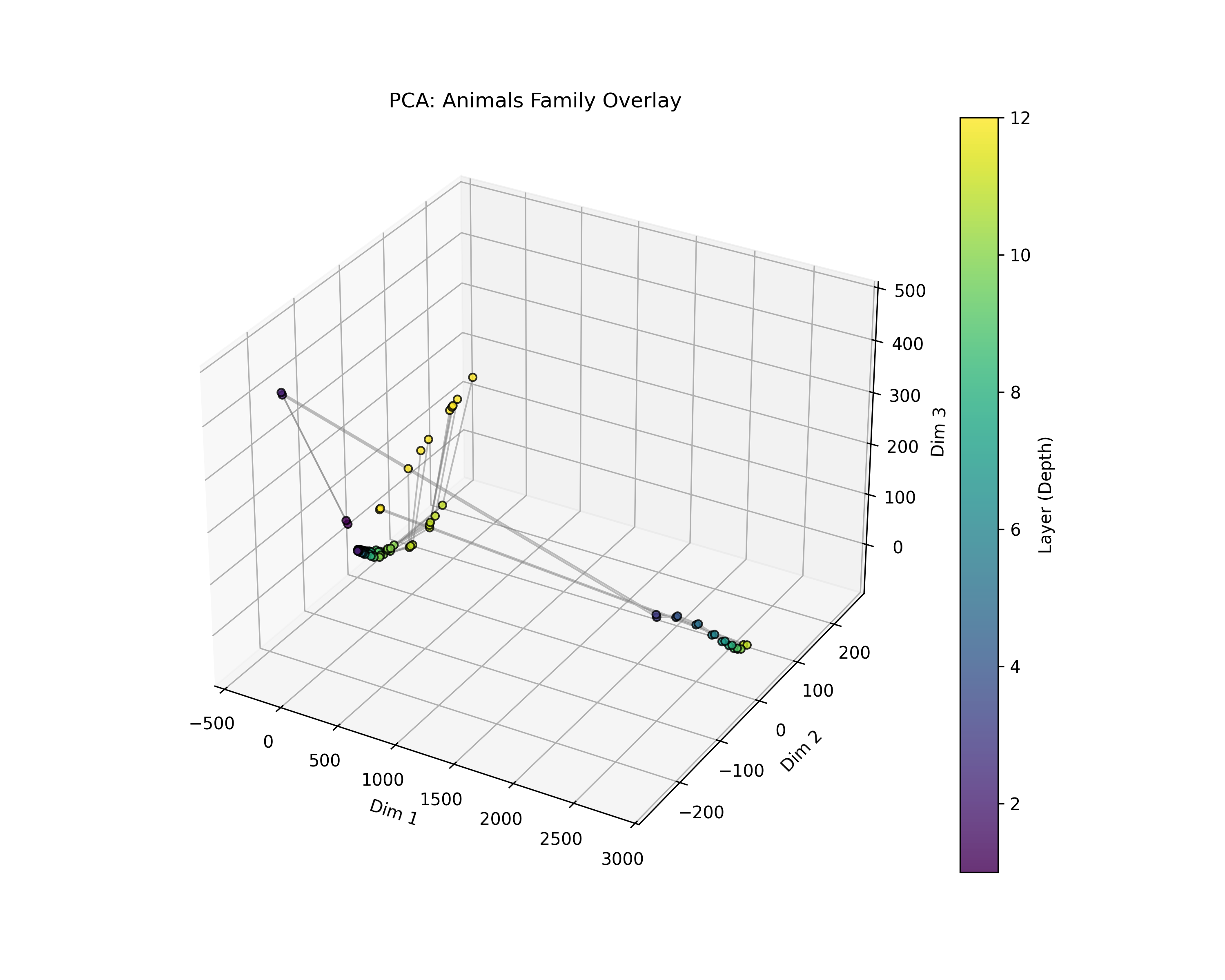
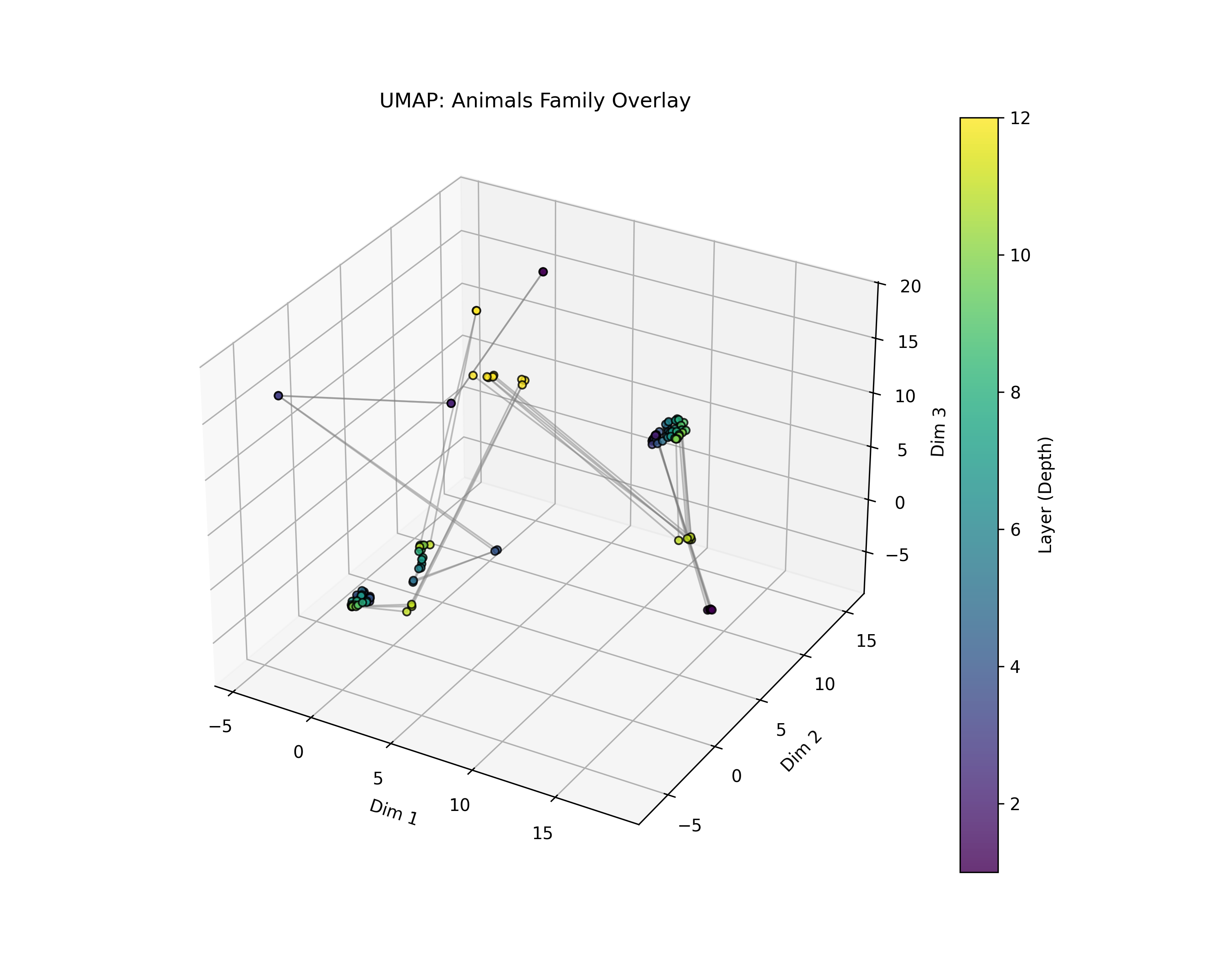
- Treated the sequence of these vectors across layers as a path through space.
They then measured five simple geometric properties of these paths, using everyday analogies:
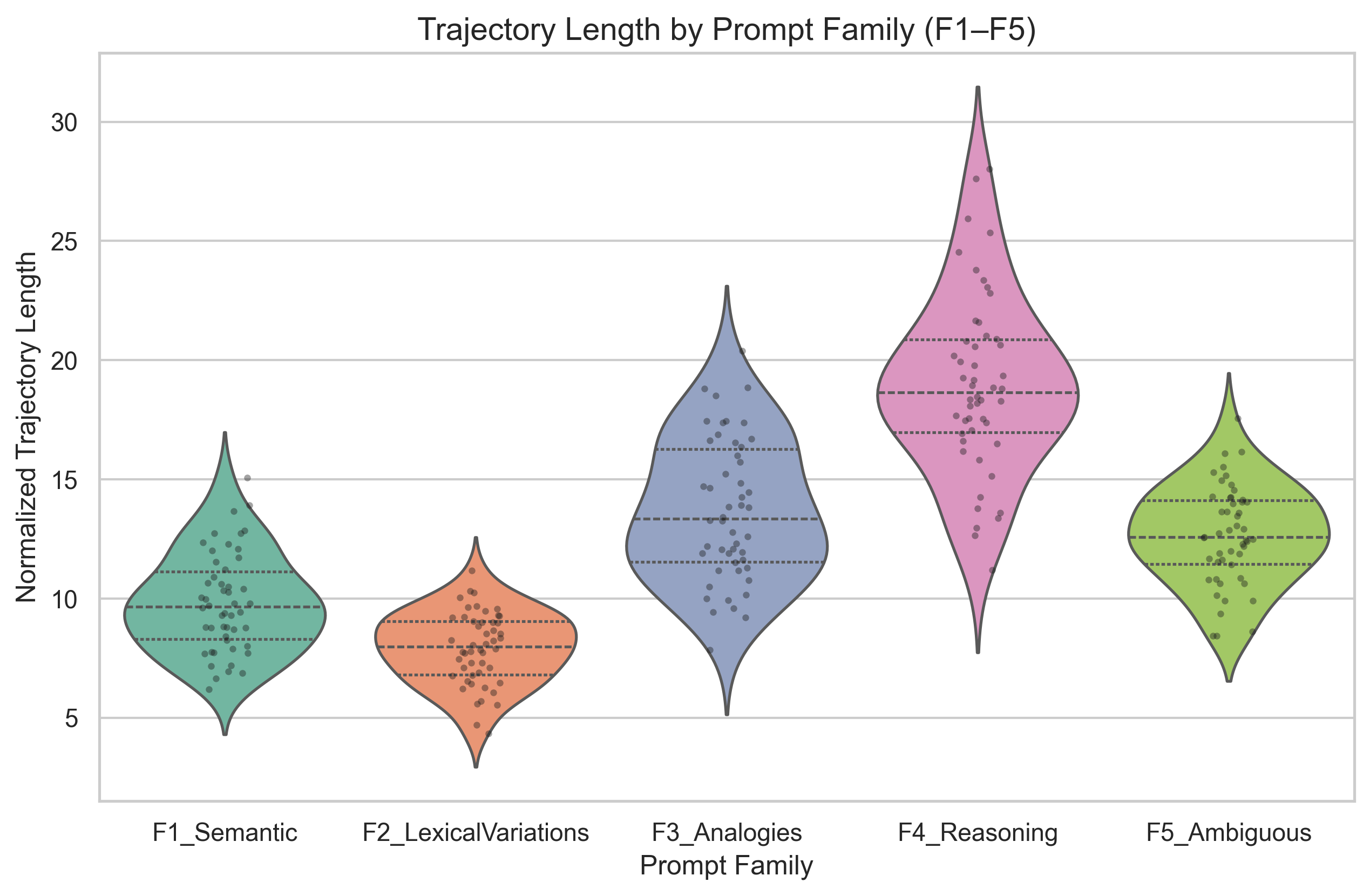
- Trajectory length: How far the path travels from start to finish. Longer = bigger change in the model’s internal state.
- Curvature: How much the path turns, like how curvy a road is. Higher curvature = more complex internal processing.
- Semantic convergence index: How much prompts with the same meaning cluster together compared to different meanings. Higher = stronger “clumping” by meaning.
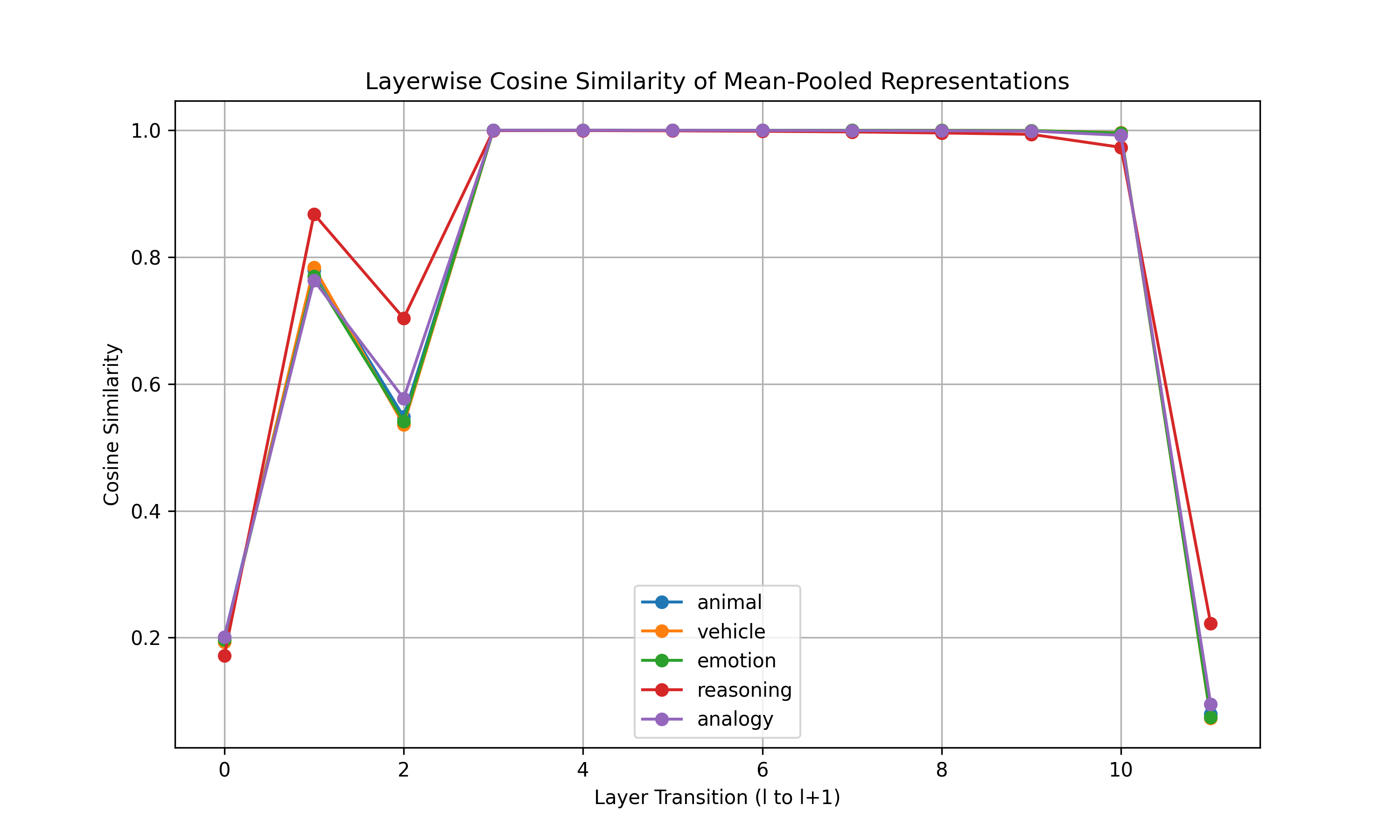
- Layer‑to‑layer cosine similarity: How similar the internal summary is between one layer and the next. Drops mark big shifts in computation.
- Representational stability: If you tweak the wording a little (like “cat” vs. “a cat”), how similar do the internal summaries stay? Higher = the model is ignoring surface details and focusing on meaning.
They also did careful checks to make sure the patterns were real and not just flukes:
- Shuffled the labels (meanings) to see if the “clumping” disappears (it did).
- Used a randomly initialized model (no training) to see if the structure vanishes (it did).
- Shuffled the order of layers to see if the depth‑wise trends break (they did).
- Used different visualization methods to check that pictures weren’t tricking them (the measured effects did not depend on pictures).
Finally, they used standard statistical tests to confirm the results weren’t due to chance.
What did they find, and why does it matter?
Here are the four main findings, with why they’re important:
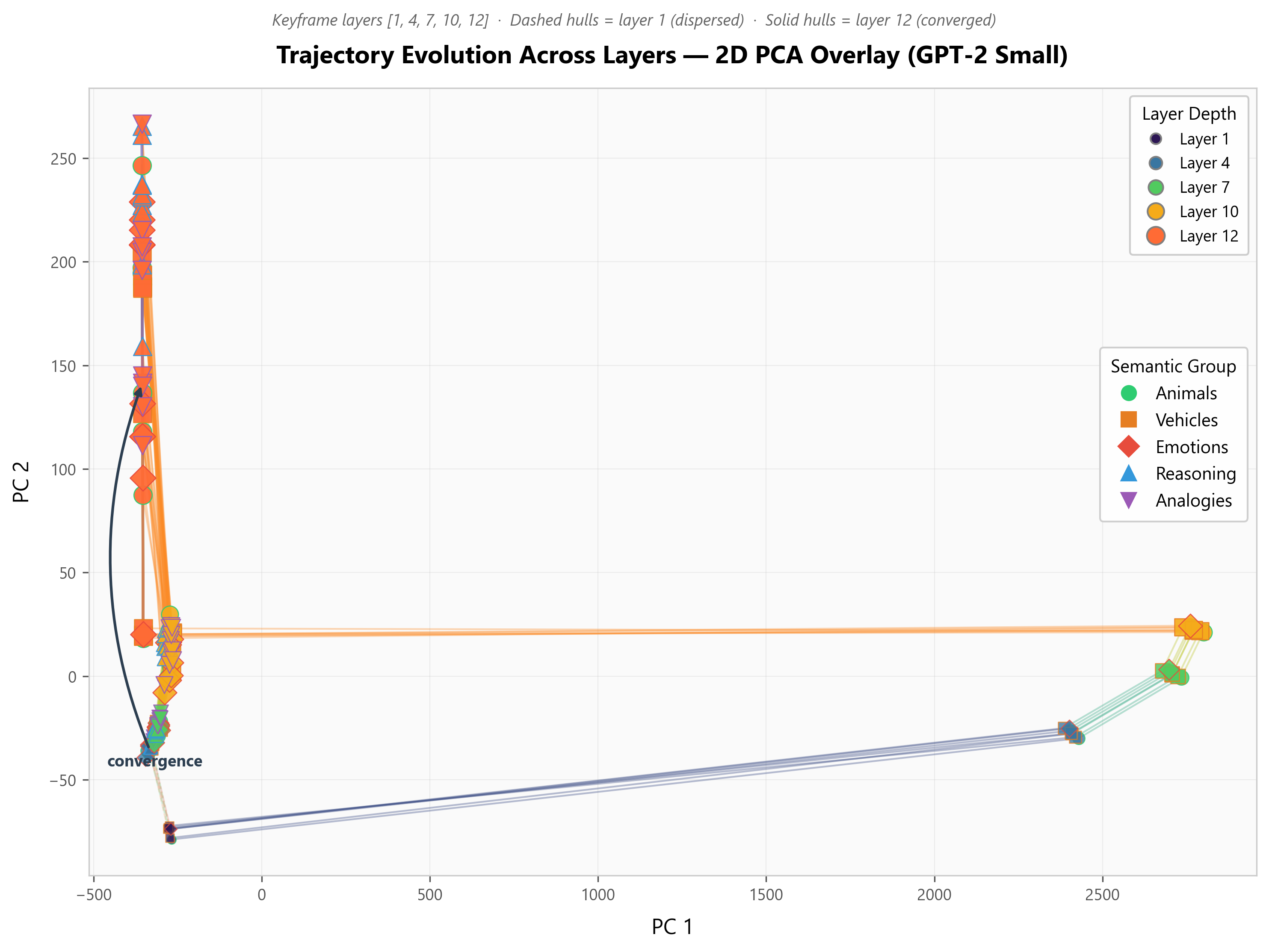
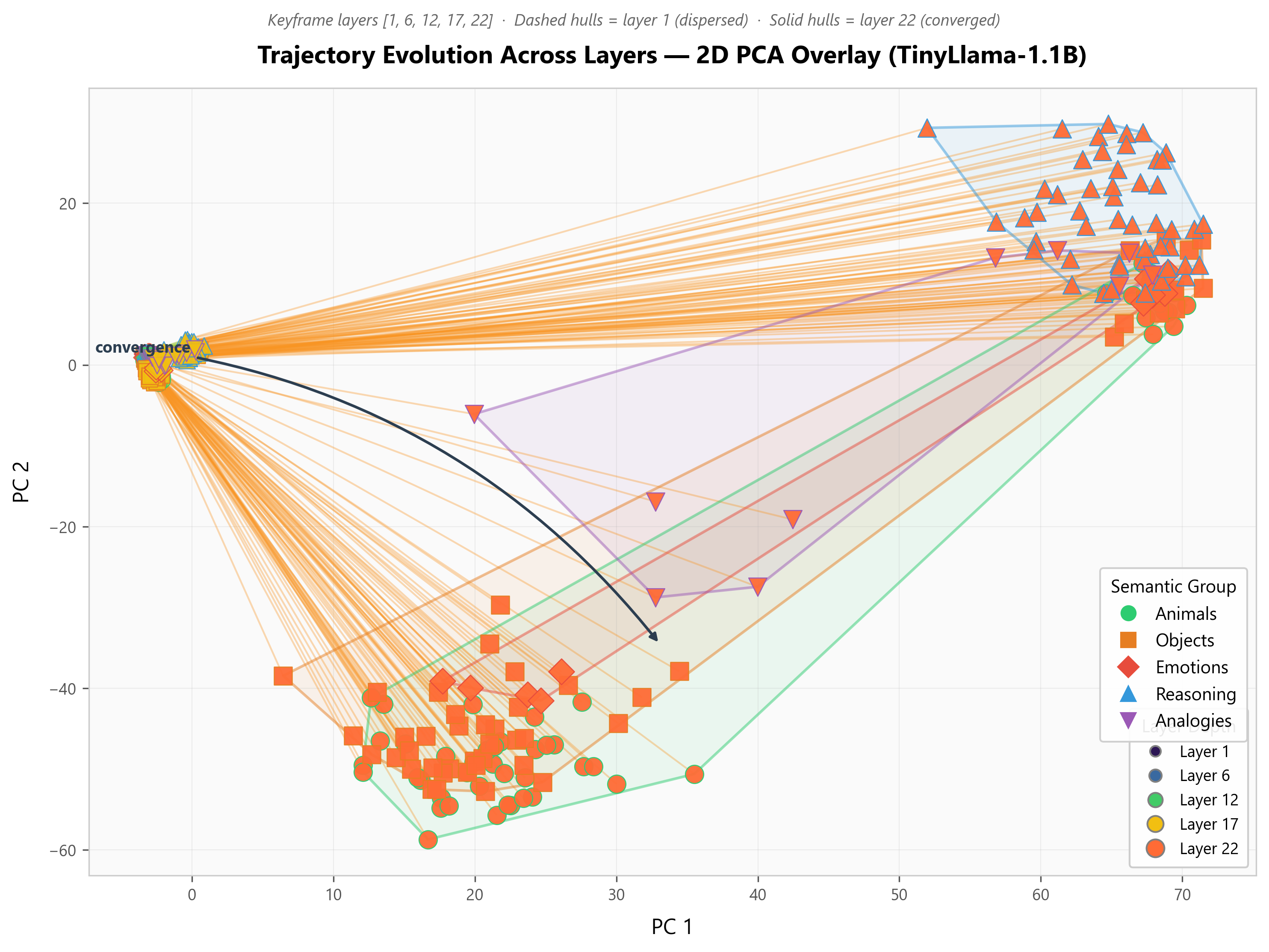
- Semantically similar prompts converge in the middle‑to‑late layers
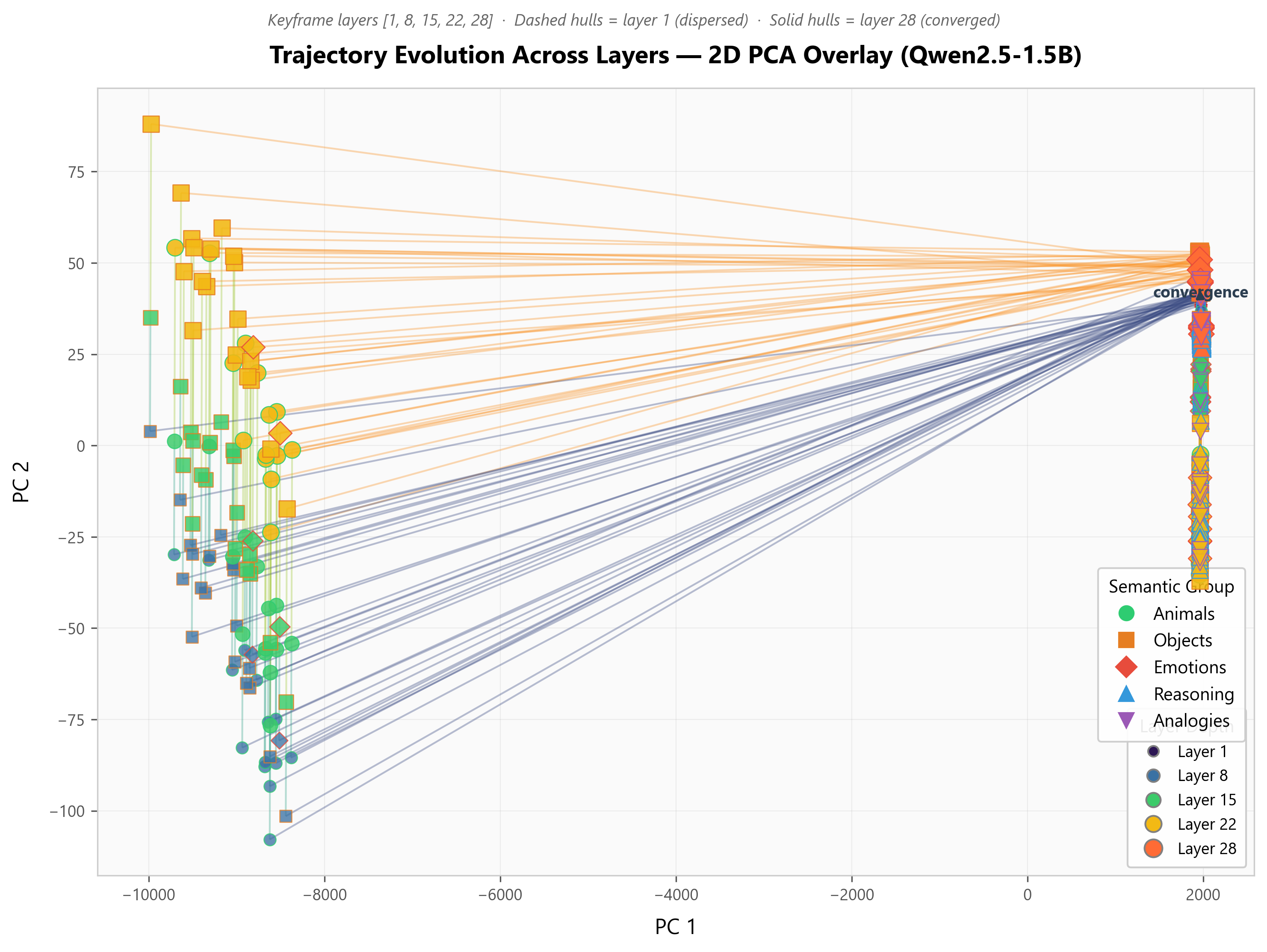
- What they saw: Prompts with related meanings move closer together as they pass through the network, peaking in later layers. The “convergence index” reached about 0.41–0.58 (bigger is stronger).
- Why it matters: This looks like the model being pulled into “attractor” regions—think valleys in a landscape—where meanings live. It suggests transformers naturally organize meaning as they process text.
- Harder tasks bend the path more
- What they saw: Multi‑step reasoning and analogies produced paths with higher curvature (about 0.71–0.83 radians) than simple wording changes (about 0.27–0.31).
- Why it matters: Curvature seems to reflect how much “thinking” the model does. This could become a quick, training‑free way to flag when a prompt requires complex reasoning.
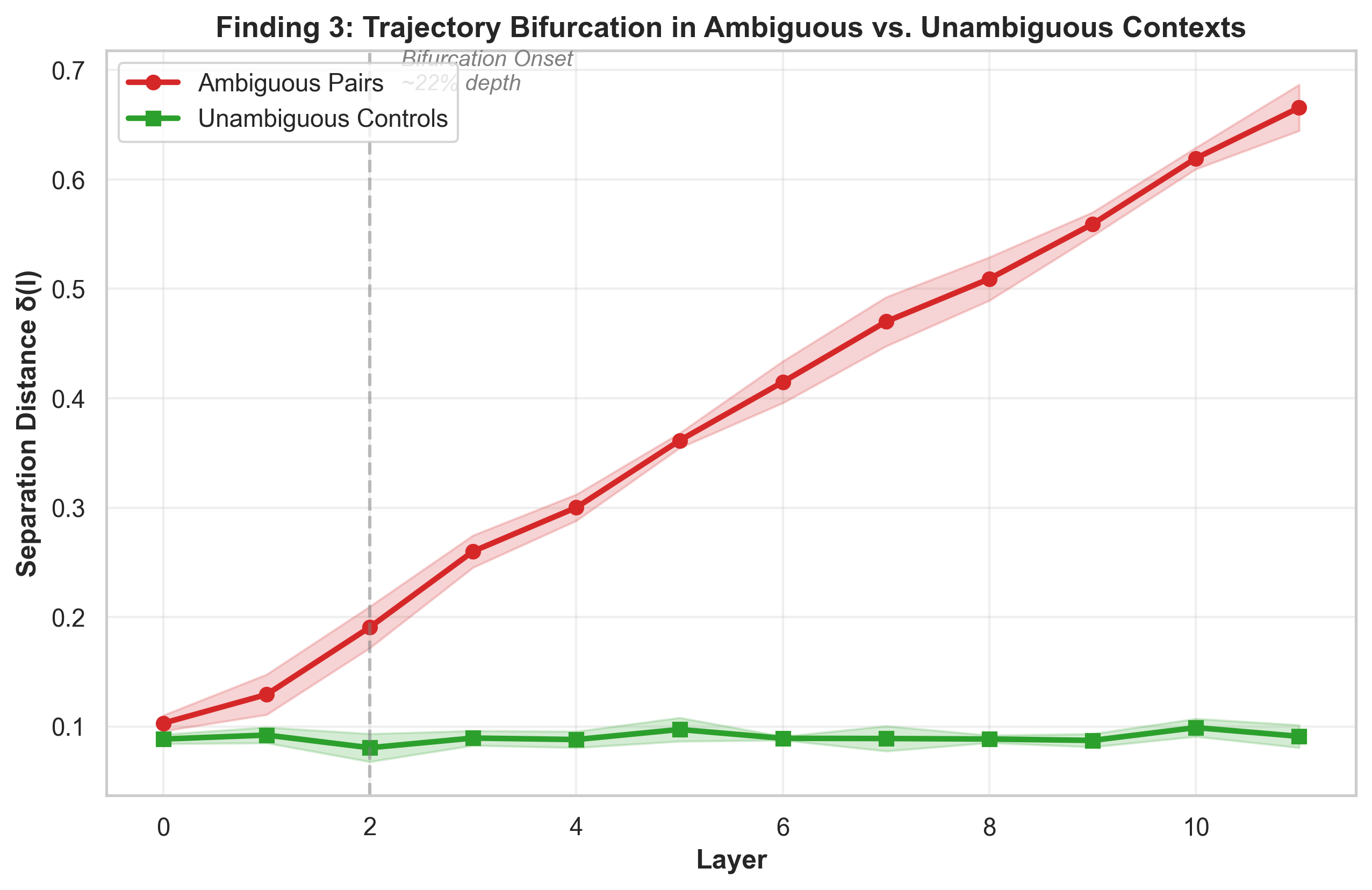
- Ambiguous words split into different paths as context resolves the meaning
- What they saw: For words like “bank,” the two meanings start close together in early layers but then split apart, ending up about 5 times more separated by the final layer. This “bifurcation” reliably begins about 20–25% into the layers.
- Why it matters: The model doesn’t instantly decide the meaning—it gradually commits as it reads more context. Knowing when that commitment starts could help with targeted edits or steering.
- A universal three‑phase processing pattern appears across models
- What they saw: Layer‑to‑layer similarity shows three phases:
- Phase I (early): Encoding—fast changes as the model picks up basic structure.
- Phase II (middle): Elaboration—more stable processing where meaning is built and refined.
- Phase III (late): Output preparation—adjusting representations to prepare the final words.
- Why it matters: This gives a simple map of “where” different kinds of computation happen, which is useful for interpretability and safe intervention.
All these effects disappeared under the control tests, which strengthens the conclusion that they reflect what the trained models actually learned.
So what’s the bigger picture?
- For understanding: Looking at the shape of the model’s internal path (its trajectory) gives a “probe‑free” window into how it thinks over time, not just what any single layer knows.
- For practice:
- If you want to edit meaning, focus on the middle “elaboration” phase.
- If you need to steer ambiguity, intervene around the 20–25% layer mark, before the model fully commits.
- Curvature could serve as a quick difficulty gauge for inputs that need deeper reasoning.
- For future research: The study suggests a bridge between AI and neuroscience ideas about population activity and attractors. Next steps include testing bigger and different model types and doing causal experiments (like activation patching) to see if changing the path shape also changes behavior.
In short, the paper shows that transformers don’t just store information layer by layer—they follow organized, meaningful paths through their internal space, and the shape of those paths tells us a lot about what kind of thinking they’re doing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper that future researchers could concretely address.
- Universality across model classes and scales: Validate whether the reported three-phase structure, semantic convergence, curvature patterns, and bifurcation onset persist in larger models (e.g., 7B–70B+), encoder-only (BERT/RoBERTa) and encoder–decoder (T5) architectures, and instruction-tuned/chat models.
- Token-level vs. sequence-level dynamics: Replace or complement mean-pooling with token-level trajectories to uncover position-specific and syntactic dynamics (e.g., subject–verb agreement, coreference), and quantify how aggregation choices (mean-pool, last-token, attention-pool) alter trajectory geometry.
- Prompt diversity and ecological validity: Expand beyond the controlled 150-prompt set to diverse, longer, noisy, and multilingual corpora; test whether curvature and convergence generalize to real-world inputs, long-context reasoning, and domain-specific text.
- Curvature–performance linkage: Establish whether trajectory curvature correlates with task difficulty and model correctness by pairing prompts with ground-truth labels and measuring accuracy, calibration, and error modes.
- Causal validation of geometry–behavior claims: Use activation patching, representation editing, and component ablations at phase boundaries and bifurcation onset to test whether manipulating trajectory geometry causally changes outputs.
- Layer-resolved component attribution: Decompose contributions of attention heads, MLPs, and residual connections to trajectory segments (e.g., which heads increase curvature or drive semantic convergence) via per-component ablation or masking.
- Attractor claims and stability analysis: Move beyond empirical convergence indices to test for true attractor dynamics by analyzing local Jacobians/eigenvalues, iterative application of blocks, or energy/flow-field interpretations of residual streams.
- Coordinate-free characterization: Mitigate coordinate dependence by incorporating topological data analysis (e.g., persistent homology, Betti numbers) and Riemannian/affine-invariant metrics to confirm that reported effects are not artifacts of Euclidean embeddings.
- Metric robustness and alternatives: Systematically compare Euclidean vs. cosine distances, ratio vs. difference formulations for CI, normalization choices (L2-normalization, LayerNorm-whitened spaces), and alternative geometric descriptors (torsion, geodesic curvature, Frenet frames).
- Sensitivity to architectural hyperparameters: Probe the influence of RoPE vs. absolute positional embeddings, LayerNorm placement (pre/post), feed-forward activation functions, width/depth scaling, and residual scaling on phase boundaries and curvature profiles.
- Training-stage dynamics: Track trajectory geometry during pretraining or fine-tuning (checkpoints across training) to see when the three-phase structure, convergence, and curvature emerge, and whether they predict downstream generalization.
- Tokenization and segmentation effects: Quantify how different tokenizers (BPE, sentencepiece), byte-level vs. word-level units, and subword segmentation impact trajectory geometry and disambiguation onset.
- Decoding strategy and context growth: Assess whether geometry depends on decoding (greedy vs. sampled), incremental context addition, and continuation length, especially for multi-step reasoning prompts.
- Ambiguity coverage and typology: Scale F5 beyond 15 pairs to a broader taxonomy of ambiguity (polysemy, homonymy, metaphor, pronoun/coreference, scope ambiguity), and test whether onset depth varies by ambiguity type and context richness.
- Phase boundary precision and variability: Quantify the variance of phase boundaries across prompts and models, and derive scaling laws or predictors (e.g., depth-proportional constants) that could forecast boundaries in unseen architectures.
- Interactions with anisotropy and norm drift: Examine how residual stream anisotropy and layer-wise norm changes affect distance-based metrics; evaluate geometry in whitened/normalized spaces and under norm-preserving transformations.
- Relationship to known circuits: Directly link trajectory segments to identified mechanisms (e.g., induction heads, key–value retrieval) via targeted ablations and measure resulting changes in SIM(l), CI(l), and curvature.
- Task-localization and intervention targeting: Test the practical utility of the phase map for representation engineering by applying edits/interventions in Phase II (semantic) vs. Phase III (output preparation) and measuring controllability and side effects.
- Generalization across languages and modalities: Extend the framework to multilingual models and multimodal transformers (vision–language) to test claims aligned with the Platonic Representation Hypothesis regarding shared trajectory geometry.
- Statistical power and reliability: Increase prompt family sizes, run multi-seed replications, and compare nonparametric tests with parametric alternatives to ensure robust effect size estimation and control for multiple comparisons.
- Visualization–metric alignment: Although metrics are computed in ambient space, verify that visualization choices (global PCA + UMAP) do not subtly bias qualitative interpretations by cross-validating with other global embeddings and stress tests.
- Formal definition consistency: Resolve and document equation specification issues (e.g., CI and SIM bracket/normalization details), and publish precise implementation references to prevent ambiguity in reproductions.
- Downstream utility of geometric signals: Explore real-time applications (difficulty estimation, uncertainty flagging) by using curvature/stability profiles as inference-time signals, and evaluate trade-offs in latency and reliability.
- Limits of probe-free interpretability: Determine where trajectory geometry suffices and where feature-specific probes remain necessary, creating guidelines for combining geometry with mechanistic and probing approaches.
Practical Applications
Immediate Applications
The paper introduces probe-free geometric metrics (trajectory length, curvature, semantic convergence index, layerwise cosine similarity, representational stability) and a model-agnostic pipeline. These enable actionable workflows today when you have access to hidden states (open-weight or instrumented models).
Industry (LLMOps, software, safety)
- Geometry-based model health monitoring and regression testing
- Use case: Track CI(l), SIM(l), mean curvature, and STAB(l) on a fixed prompt suite across releases to detect regressions, data drift, or unintended changes to reasoning behavior.
- Sectors: Software, MLOps, Safety.
- Tools/workflows: CI job that computes metrics on every model build; Threshold alerts for “phase boundaries” shifting or curvature spikes.
- Assumptions/dependencies: Access to output_hidden_states; stable prompt suite; acceptance thresholds defined by historical baselines.
- Inference-time complexity routing
- Use case: If early-layer curvature exceeds a threshold, route the request to a slower “reasoning” path (chain-of-thought, tool-use, search) or a larger model; otherwise use fast path.
- Sectors: Software, Finance (query answering), Customer support, Education (tutoring).
- Tools/workflows: “ComplexityRouter”: microservice that inspects first K layers’ metrics before deciding execution path.
- Assumptions/dependencies: Low-latency access to early hidden states; calibrated curvature thresholds on in-domain data.
- Phase-aware representation editing and steering
- Use case: Apply ROME/activation-patching-like edits in Phase II (elaboration) to adjust semantic content; confine output-format interventions to Phase III (output preparation).
- Sectors: Safety, Content moderation, Enterprise customization.
- Tools/workflows: “PhaseEdit” runbook: identify phase boundaries via SIM(l); perform edits only in relevant layer ranges.
- Assumptions/dependencies: Editing methods (e.g., ROME) available; internal model access; careful A/B testing to avoid side effects.
- Ambiguity management via bifurcation-aware prompting
- Use case: Detect ambiguous inputs by shallow-layer near-zero separation and rising bifurcation; proactively inject clarifying context before the ~20–25% depth “commitment” point.
- Sectors: Customer support, Legal QA, Healthcare NLP.
- Tools/workflows: “Disambiguate-early” prompt middleware that adds clarifying clauses when bifurcation onset is detected; flag for human review if separation grows abnormally.
- Assumptions/dependencies: Real-time access to layerwise representations; tuned ambiguity thresholds on domain data.
- Early-exit and pruning candidates by geometric identity layers
- Use case: Identify layers with near-zero incremental displacement and high SIM(l) to design early-exit policies or prune near-identity layers for cost savings.
- Sectors: Software, Energy efficiency, Edge deployment.
- Tools/workflows: “GeoPrune” report highlighting layers with low step-length and high SIM(l); integrate with distillation.
- Assumptions/dependencies: Careful accuracy audits post-pruning; may be model- and domain-dependent.
- Safety and red-teaming triage
- Use case: Use stability STAB(l) to surface prompts where small lexical changes cause large representation shifts (fragility); monitor abnormally high CI(l) for undesired attractor convergence (e.g., unsafe content).
- Sectors: Safety, Trust & Safety ops.
- Tools/workflows: “GeometryGuard” dashboard with fragility and attractor alerts; attach to red-team campaigns.
- Assumptions/dependencies: Curated risky prompt families; thresholds need tuning to reduce false positives.
- Vendor-neutral benchmarking and audits
- Use case: Compare models via geometry profiles (phase boundaries, peak CI, curvature rank across task families) without training probes.
- Sectors: Procurement, Policy, Enterprise evaluation.
- Tools/workflows: Public “TrajectoryLens” report included in model cards; side-by-side plots for multiple vendors.
- Assumptions/dependencies: Vendors must expose hidden states or provide metric APIs; standardized prompt suites.
Academia (interpretability, training, evaluation)
- Probe-free task difficulty estimation for benchmarking
- Use case: Use mean curvature and trajectory length as unsupervised difficulty signals, correlating them with accuracy to design better benchmarks.
- Tools/workflows: Add curvature columns to benchmark leaderboards; analyze error vs curvature.
- Assumptions/dependencies: Validation on broader datasets to confirm monotonicity with difficulty.
- Hypothesis generation for mechanistic studies
- Use case: Localize experiments (e.g., induction heads, retrieval) to the “computational inflection zone” where curvature peaks and SIM drops.
- Tools/workflows: Drive activation patching, causal tracing to layers flagged by geometry.
- Assumptions/dependencies: Access to intervention tools; replicability across seeds/models.
- Dataset design and curation
- Use case: Use CI(l) to verify that semantic categories compress as intended; detect mislabeled or heterogeneous items.
- Tools/workflows: Data pruning using per-layer CI and STAB diagnostics.
- Assumptions/dependencies: Reasonable semantic family definitions; compute budget to scan datasets.
Policy and Governance
- Lightweight interpretability disclosures
- Use case: Require geometry summaries (phase boundaries, peak CI, curvature profiles on public suites) in model documentation for transparency.
- Tools/workflows: Template annex to model cards with standard plots and metrics.
- Assumptions/dependencies: Agreement on public prompt suites; auditors’ access to compute metrics.
Daily Life (practitioner tips)
- Prompting heuristics informed by geometry
- Use case: Add clarifying context early to reduce ambiguity (pre-bifurcation); request “think step-by-step” when the task is likely high-curvature (multi-step reasoning).
- Tools/workflows: Prompt linting plugin warning about potential ambiguity; suggest disambiguators.
- Assumptions/dependencies: Heuristics calibrated on typical user tasks.
- Cost-performance tuning
- Use case: Choose short, unambiguous prompts for routine queries (lower curvature), and enable reasoning tools only for complex tasks (higher curvature).
- Tools/workflows: Simple “complexity toggle” in chat interfaces.
- Assumptions/dependencies: UI wiring to different inference paths.
Long-Term Applications
These require further research, scaling, or broader ecosystem changes (e.g., closed-weight access, larger models, causal validation).
Industry (productization, architecture, efficiency)
- Causally validated, geometry-guided controllers
- Use case: Train controllers that adjust decoding strategy, tool invocation, or search depth based on learned mappings from early-layer geometry to error risk.
- Sectors: Software, Finance, Healthcare compliance.
- Dependencies: Causal links between geometry and failure modes; large-scale online A/B testing.
- Geometry-regularized training objectives
- Use case: Add loss terms that target desirable geometry (e.g., stable Phase II, calibrated curvature for reasoning tasks) to improve robustness and reduce hallucinations.
- Sectors: Foundation model training.
- Dependencies: Demonstrating that shaping trajectory geometry improves downstream accuracy/safety; compute for ablations.
- Dynamic-depth and compute-allocation policies driven by phase detection
- Use case: Learn early-stop criteria when SIM(l) stabilizes; allocate extra depth when curvature suggests ongoing elaboration.
- Sectors: Energy, Edge/On-device AI.
- Dependencies: Reliable phase detection across domains; hardware/SDK support for elastic depth.
- Geometry-preserving compression and distillation
- Use case: Distill students to match teachers’ trajectory geometry (not just logits), preserving reasoning behavior.
- Sectors: Model compression.
- Dependencies: Empirical evidence that geometry matching yields better faithfulness than standard distillation; alignment of student capacity.
- Security and provenance via geometry fingerprints
- Use case: Identify model lineages or tampering by matching characteristic phase boundaries and CI/curvature profiles.
- Sectors: Security, IP protection.
- Dependencies: Robustness of fingerprints across domains and prompts; adversarial resistance analysis.
Academia (science, methods)
- Token-level and structure-aware trajectory analysis
- Use case: Move beyond mean pooling to study position-wise trajectories, syntax trees, and cross-token interactions.
- Dependencies: Memory-efficient extraction; scalable visualization; new metrics.
- Topological data analysis (TDA) of representation manifolds
- Use case: Use persistent homology to identify attractors and phase transitions in a coordinate-free way.
- Dependencies: Method development for high-dimensional, layer-indexed data; linking Betti numbers to computation.
- Cross-modal and cross-architecture generalization
- Use case: Test whether three-phase structure, bifurcation depth, and curvature-complexity relations hold for encoders, encoder-decoder models, and multimodal systems.
- Dependencies: Access to diverse models; standardized suites across modalities.
- Geometry-informed curricula and data synthesis
- Use case: Generate training data that induces target curvature profiles (e.g., scaffolded reasoning), potentially accelerating capability growth.
- Dependencies: Data generation pipelines; closed-loop training experiments.
- Causal mechanistic validation
- Use case: Use activation patching and representation surgery at phase boundaries and bifurcation onsets to test causal claims.
- Dependencies: Tooling for scalable intervention; agreement on causal benchmarks.
Policy and Governance
- Standards for geometry-based interpretability audits
- Use case: Establish certification protocols where models must report geometry metrics over regulated task suites (e.g., medical, legal).
- Dependencies: Multistakeholder consensus; regulator capacity; privacy-compliant test sets.
- Risk-sensitive deployment rules
- Use case: Mandate human oversight when high-curvature signals indicate complex or ambiguous reasoning in high-stakes contexts.
- Dependencies: Proven predictive value of curvature for error risk; auditing infrastructure.
Daily Life and Education
- Adaptive tutoring systems guided by complexity signals
- Use case: Detect when a learner’s query demands multi-step reasoning (high curvature) and automatically scaffold explanations.
- Dependencies: Controlled studies linking geometry to learning outcomes; alignment with pedagogy.
- Accessibility and assistive tech
- Use case: For users with cognitive load constraints, rephrase or structure queries to minimize unnecessary curvature while preserving intent.
- Dependencies: Personalization models; evaluation frameworks for cognitive effort.
Notes on Assumptions and Dependencies
- Internal access: Most applications assume access to hidden states or vendor-provided metric APIs. Closed black-box APIs limit feasibility.
- Generalization: Findings were validated on small-to-mid models (≤1.5B), English prompts, and controlled families; verification on larger, multilingual, and domain-specific settings is needed.
- Metric design choices: Mean pooling vs token-level trajectories may affect sensitivity; thresholds require domain calibration.
- Causality: Current signals are correlational; intervention-based validation is needed before safety-critical gating or policy mandates.
- Overheads: Computing metrics increases latency and cost; production use must balance inspection depth (layers, prompts) against SLA constraints.
Glossary
- Activation patching: An intervention technique that edits or replaces internal activations to test causal effects on model behavior. "Causal claims require activation patching or representation surgery experiments"
- Ambient space: The full high-dimensional vector space in which representations reside and metrics are computed. "All geometric metrics are computed directly in the full ambient representation space "
- Attractor basins: Regions in representation space toward which trajectories converge, reflecting stable semantic states. "semantic convergence into attractor basins"
- Attractor-like dynamics: System behavior where trajectories move toward stable points or regions, analogous to attractors in dynamical systems. "consistent with attractor-like dynamics."
- Benjamini-Hochberg FDR correction: A multiple hypothesis testing procedure controlling the false discovery rate. "Benjamini-Hochberg FDR correction at "
- Betti numbers: Topological invariants counting connected components, holes, and higher-dimensional voids of a space. "compute intrinsic manifold properties such as Betti numbers"
- Bootstrap confidence intervals: Nonparametric uncertainty estimates derived from resampling the data. "Confidence intervals are 95\% bootstrap CIs with resamples."
- Centered Kernel Alignment (CKA): A similarity measure for comparing representational spaces across layers or models. "Centered Kernel Alignment (CKA) provides a principled measure of representational similarity"
- Cohen's d: A standardized effect size quantifying the magnitude of differences between groups. "Effect sizes are reported as Cohen's computed on rank-transformed values."
- Computational inflection zone: A depth range where curvature peaks and significant representational changes concentrate. "We term this the computational inflection zone"
- Decoder-only transformer: A transformer architecture consisting solely of decoder blocks for autoregressive generation. "three open-weight decoder-only transformer models"
- Dynamical systems lens: An analytical perspective that models network computation as trajectories governed by underlying dynamics. "Several works have analyzed deep networks through a dynamical systems lens."
- Geodesic: The shortest path between two points in a space; here used as a metaphor for straight-line evolution in representation space. "near-geodesic (straight-line) evolution."
- Induction heads: Attention heads that implement an algorithm for copying or continuing patterns, implicated in in-context learning. "align with layer ranges implicated in induction head formation"
- Key-value retrieval mechanism: A view of MLP layers as retrieving and promoting concepts via learned key-value pairs. "via a key-value retrieval mechanism."
- Layerwise cosine similarity: The cosine similarity between consecutive layer representations, indicating directional changes across depth. "Layerwise cosine similarity reveals a universal three-phase computational structure"
- Logit lens: A method projecting intermediate hidden states into vocabulary logits to inspect early predictions. "The logit lens extends this by projecting intermediate representations directly into vocabulary space"
- Mann-Whitney U test: A nonparametric statistical test for comparing two independent samples. "All metric comparisons are evaluated using the two-sided Mann-Whitney U test"
- Neural collapse: A training-phase phenomenon where last-layer representations collapse to class means with aligned classifier weights. "Recent work on neural collapse shows that last-layer representations collapse to class means at convergence"
- Neural manifold: A low-dimensional surface embedded in high-dimensional neural activity space on which population trajectories lie. "a low-dimensional neural manifold largely invariant to task conditions."
- Persistent homology: A tool from topological data analysis that tracks the birth and death of homological features across scales. "specifically persistent homology"
- Platonic Representation Hypothesis: The proposal that diverse models converge toward a shared statistical model of reality in representation space. "The Platonic Representation Hypothesis proposes that models trained on different data and objectives converge toward a shared statistical model of reality."
- Representational Similarity Analysis (RSA): A method comparing representational geometries via (dis)similarity matrices across conditions or models. "Representational Similarity Analysis (RSA), originating in systems neuroscience"
- Representational stability: A metric quantifying invariance of representations to small lexical perturbations of the input. "Representational Stability:"
- Representation surgery: Interventions that edit internal representations to test causal structure-function relationships. "activation patching or representation surgery experiments"
- Residual stream: The running sum of layer outputs in a transformer through which information flows across depth. "the transformer residual stream implements something analogous to a learned vector field"
- RoPE (Rotary Position Embeddings): A positional encoding technique that injects relative position information via rotations in embedding space. "RoPE based"
- Semantic Convergence Index: A metric measuring within-category clustering relative to between-category separation across layers. "Semantic Convergence Index:"
- Singular Vector Canonical Correlation Analysis (SVCCA): A technique to compare neural representations by aligning subspaces via singular vectors and CCA. "used SVCCA to show that representations in deep networks stabilize from the bottom up during training."
- Spearman correlation (ρ): A rank-based correlation coefficient assessing monotonic association. "Spearman across models"
- Superposition: The encoding of multiple features in overlapping directions within a shared representational space. "superposition as a mechanism by which a single neuron encodes multiple features"
- t-SNE (t-distributed Stochastic Neighbor Embedding): A nonlinear dimensionality reduction method for visualization of high-dimensional data. "t-SNE"
- Topological data analysis (TDA): A suite of methods using topology to characterize the shape of data. "topological data analysis"
- Trajectory bifurcation: A split of representation trajectories into distinct paths corresponding to different interpretations. "trajectory bifurcation"
- Trajectory curvature: The turning angle of successive representational displacements across layers, summarizing path nonlinearity. "Mean trajectory curvature"
- UMAP (Uniform Manifold Approximation and Projection): A nonlinear dimensionality reduction technique preserving manifold structure for visualization. "UMAP"
- Vector field: A field assigning a direction of change to each point in space; here, a learned flow over representations across layers. "implements something analogous to a learned vector field"
Collections
Sign up for free to add this paper to one or more collections.