Hedge-Bench: Benchmarking Agents on Hard, Realistic Tasks Pertaining to Financial Reasoning
Abstract: AI agents can increasingly handle the mechanical tasks of financial analysis: retrieving documents, calculating formulas, updating spreadsheets. The harder, more valuable challenge is reasoning through the open-ended questions that define expert Analyst work. Existing benchmarks do not capture this class of problem, and those that attempt to evaluate open-ended reasoning rely on model-judged outputs that introduce noise and circularity. We present Hedge-Bench 1.0: a benchmark of 102 actual, on-the-job tasks grounded in the explicit reasoning traces of professional hedge fund analysts working with relevant information sources. This approach enables deterministic grading against verified expert steps. Frontier models and agents score below 16\% on the benchmark. We publish the dataset and evaluation harness at github.com/Trata-Inc/trata-hedge-bench.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Hedge-Bench, explained simply
Overview: What is this paper about?
This paper introduces Hedge-Bench, a new way to test AI “agents” (smart programs) on tough, realistic finance tasks—the kind of open-ended thinking senior analysts at investment firms do. Instead of asking AI to spit out a single number or fact, Hedge-Bench checks whether the AI can read real documents, ask the right questions, back up claims with evidence, weigh pros and cons, and write a clear argument—just like a human expert would.
The authors also built Hedge-Bench 1.0, a set of 102 challenging tasks made from real conversations between two professional hedge fund analysts. They then tested several top AI models to see how well they handled these tasks.
Goals and questions: What were the researchers trying to find out?
They wanted to know:
- Can today’s AI agents do the high-level, open-ended reasoning that expert finance analysts do?
- Can they choose the right documents to read, make the right calculations, and build a convincing, evidence-based argument?
- How well do the best AI models perform on these realistic tasks?
- Where do they fail, and why?
How Hedge-Bench works: Methods in everyday language
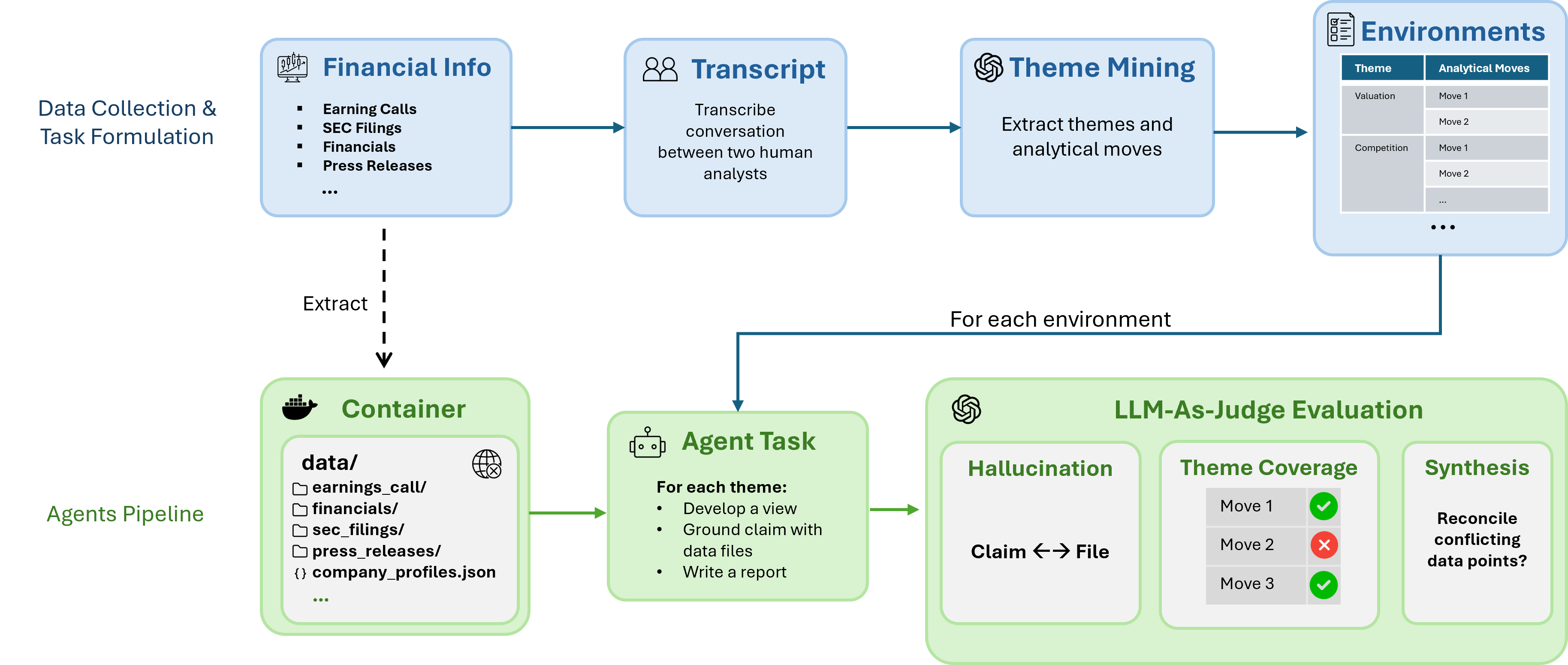
Think of each task like a serious school project set inside a “locked” digital room:
- The AI gets a private workspace (a “Docker container,” like a sealed classroom) filled with the exact documents a real analyst would use: company filings (10-K/10-Q), earnings calls, press releases, news, competitor info, and industry reports.
- The AI is given an open-ended prompt such as “Figure out whether this company has a strong competitive position and how that affects its valuation.”
- The AI must read the files, reason step by step, and write a full answer with inline citations to the provided documents (like footnotes). If it claims a number or event, it must point to the file it came from.
To score the AI fairly, the authors use a detailed checklist called a rubric:
- The rubric is broken into “themes” (big questions an analyst would consider, like valuation or risks).
- Each theme has “required moves” (specific points the AI should make, such as comparing certain financial metrics or explaining why a technology is hard to copy).
- The AI gets credit when it makes these moves and backs them with the supplied documents.
Because the answers are long essays (not one-word replies), another AI model acts as the grader (“LLM-as-a-judge”). It checks three things:
- Grounding: Did the AI’s facts truly come from the cited files, or were any made up (a “hallucination”)?
- Coverage: How many of the rubric’s required moves did the AI correctly make and support?
- Synthesis: Did the AI pull together conflicting facts into a clear, unified conclusion, instead of just listing pros and cons?
Scoring:
- “Dense score” (0–4): partial credit based on how many themes were covered, with the top score requiring a real synthesis.
- “Pass@1”: the chance the AI gets a perfect 4/4 in a single try (think: how often it totally nails it on first attempt).
What models did they test?
- They ran 8 leading models, trying each task around eight times, and averaged the results.
Here are a few simple explanations of important terms used in the paper:
- Agent: An AI that reads, uses tools, and writes an answer.
- Docker container: A sealed computer workspace so everyone is tested fairly on the same files.
- Rubric: A detailed checklist of what a strong answer should cover.
- Required move: A specific point the answer should make and support with evidence.
- Hallucination: When the AI makes up a fact or cites something that isn’t in the provided files.
- Pass@1: The chance of a perfect score on one attempt.
- Trajectory length and tool use: Roughly, how many steps and file/tool lookups the AI did while working.
Main results: What did they find, and why does it matter?
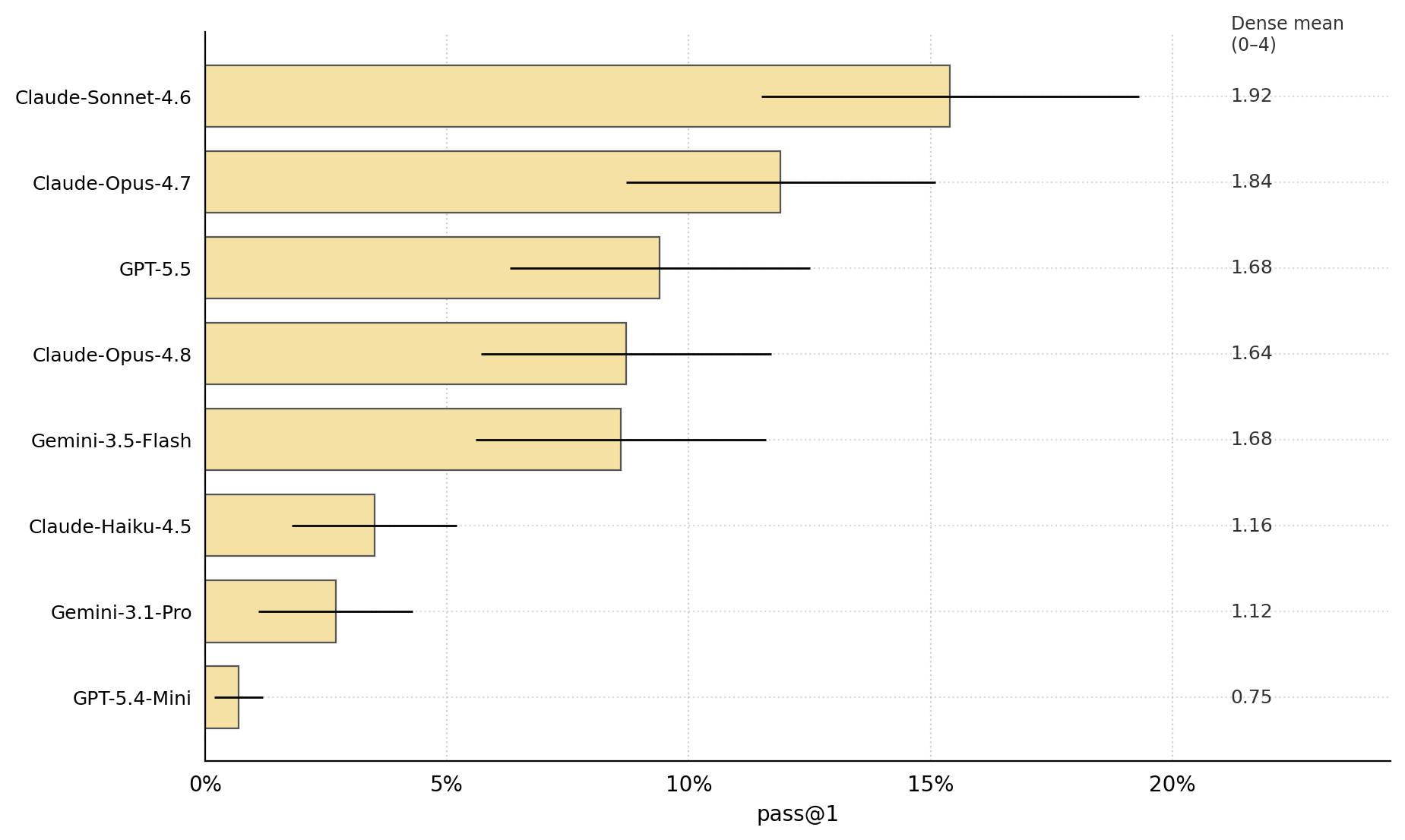
- These tasks are hard. Even the best model got a perfect score only a bit over 15% of the time. On average, the top model covered fewer than half of the possible rubric points. In short, we are far from AI that consistently reasons like a senior analyst.
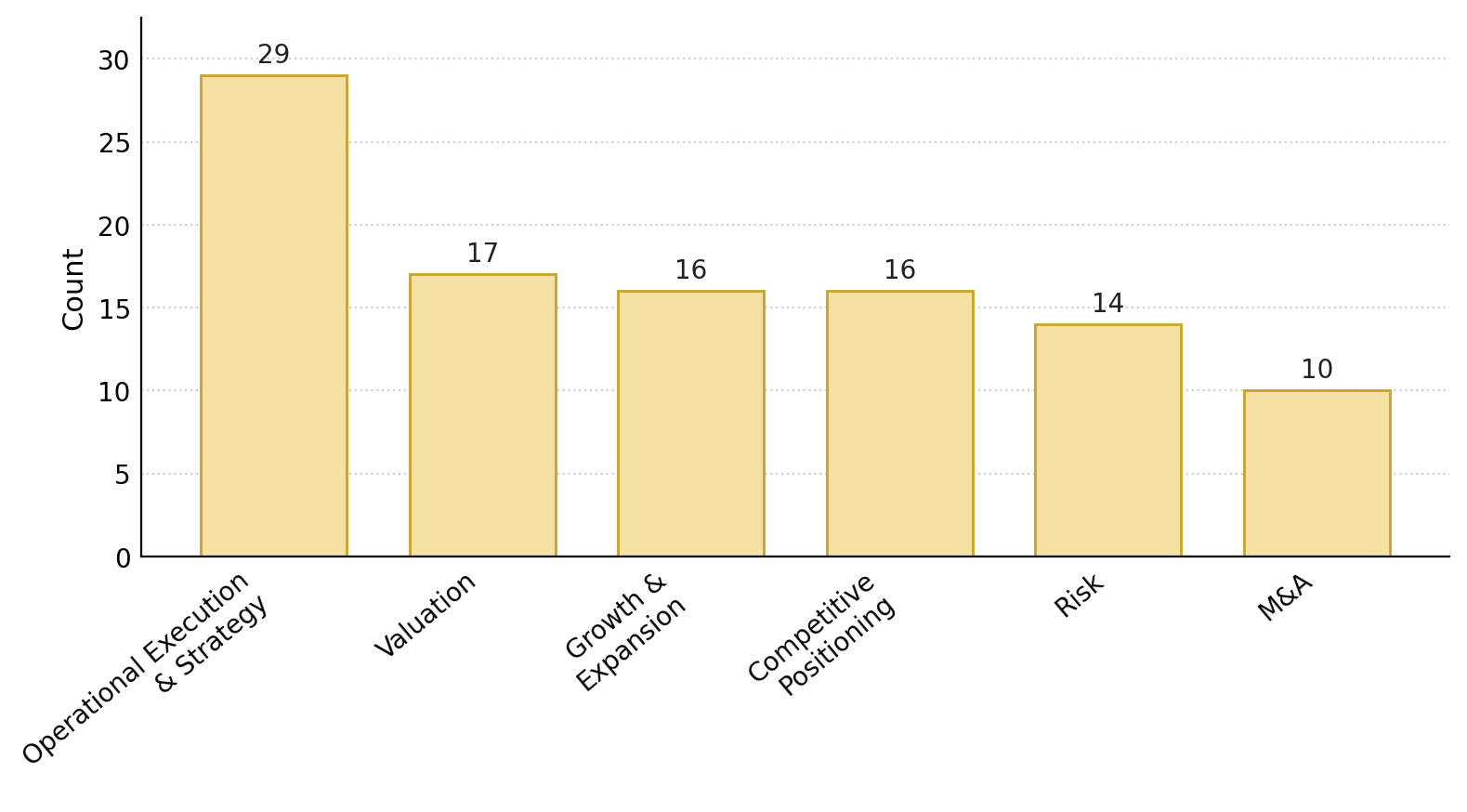
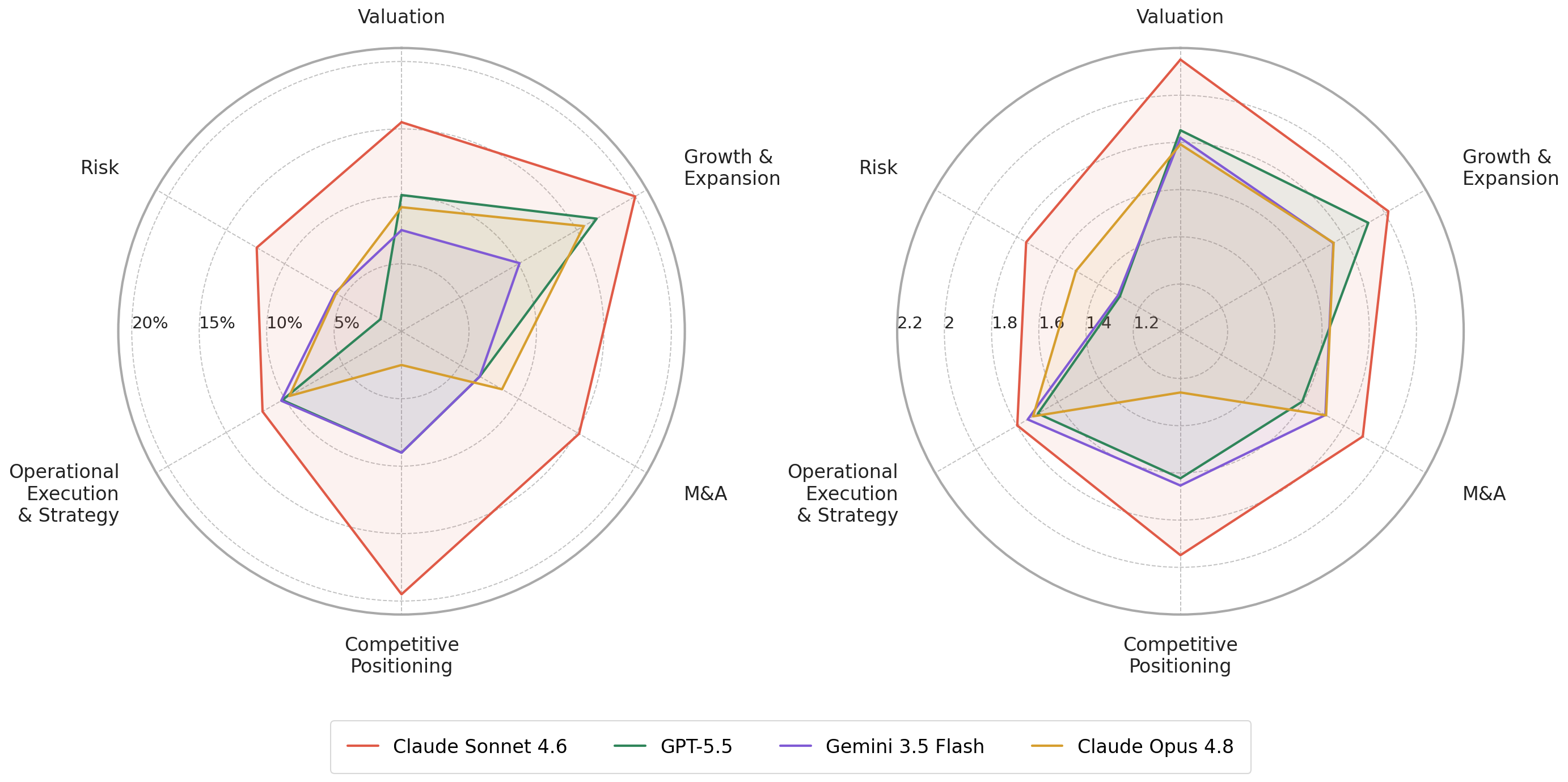
- Some categories are easier than others:
- Easiest: Valuation (clear numbers and data to anchor reasoning).
- Hardest: Risk and judgment-heavy topics (forward-looking, interpretive thinking).
- Doing more research generally helps—but only up to a point:
- Models that naturally explore more (read more files, take more steps) tend to score higher overall.
- But within a single model, taking many more steps often just means the task was hard; extra steps don’t always boost the score.
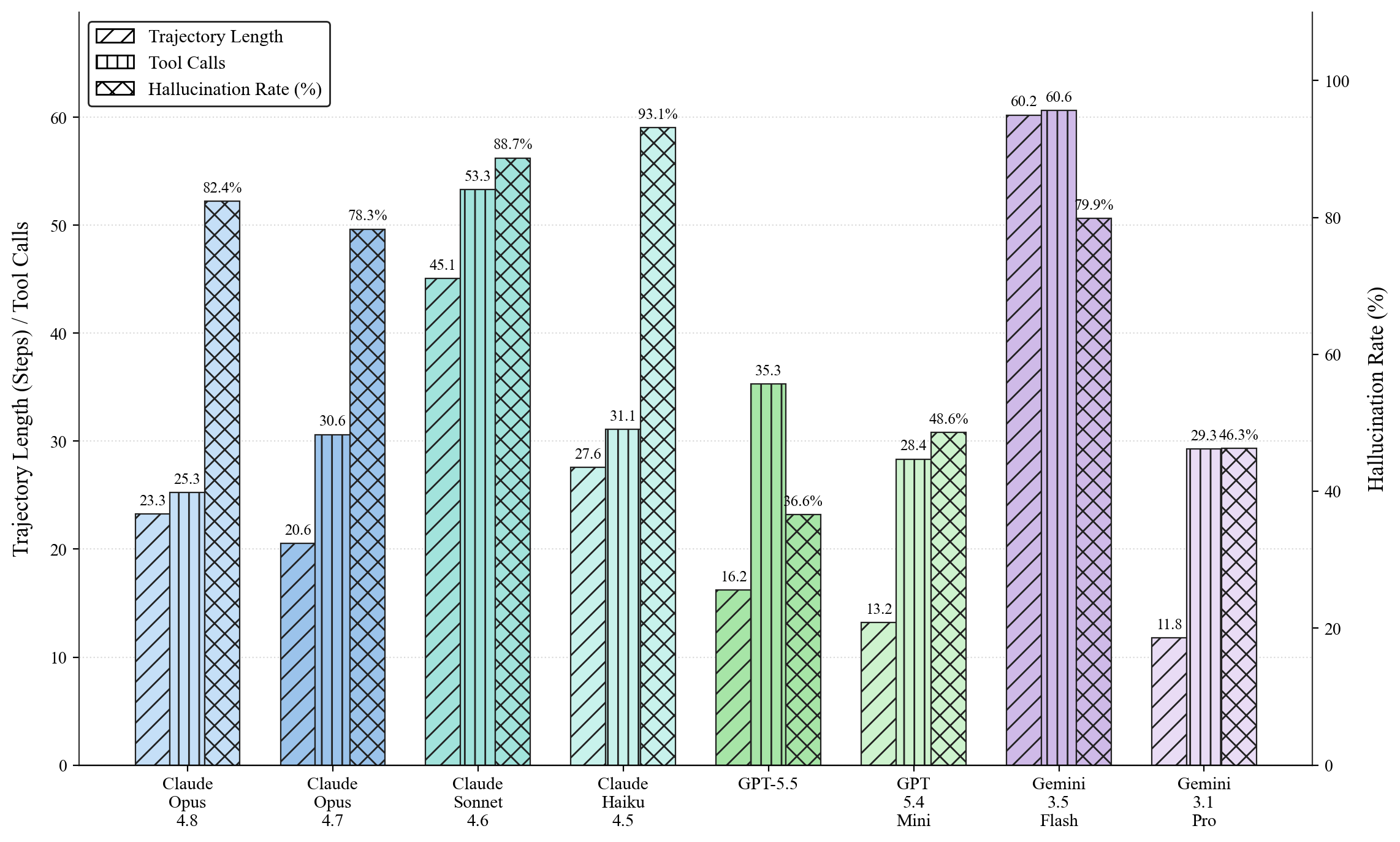
- Quality vs. reliability tradeoff:
- The highest-scoring models also hallucinated a lot (for example, around 89% of trials for one top model included at least one made-up claim). That’s a big problem for real finance use, where wrong facts can be costly.
- One model stood out as a better balance: it had strong scores but much lower hallucination rates compared to the very top scorer, making it more “deployable” in practice.
- Sometimes the AI added new insights:
- The researchers saw cases where the AI connected extra dots beyond the rubric (for instance, linking physics-based advantages to long-term regulatory protection). That’s a hint that, with better training and guardrails, AI could contribute fresh ideas at scale.
Why this is important
Real finance work isn’t about plugging numbers into a formula. It’s about judgment: choosing what matters, weighing conflicting evidence, and explaining a clear view. This benchmark shows that current AIs are improving but still struggle with that higher-level thinking. It also shows that forcing the AI to cite its sources and grading its reasoning steps—rather than just final answers—is a better way to test real-world usefulness.
What this could mean next: Impact and future directions
- Trust and safety first: Before professionals can rely on AI in finance, the AI must stop making things up. Reducing hallucinations is a must.
- Train for process, not just answers: Teaching models to follow expert-like reasoning steps—and grading them on those steps—should push the field forward.
- Better datasets: Using real expert conversations to build tasks and rubrics helps models learn what pros actually do on the job.
- Smarter evaluation tools: Improved judging, better grounding checks, and human validation loops will make scores more reliable.
- Ongoing progress: As new models are released, Hedge-Bench can keep raising the bar with fresh, harder tasks so that AI reasoning keeps getting closer to expert human performance.
In short, Hedge-Bench shows how far we still have to go for trustworthy, expert-level financial reasoning—and offers a strong roadmap for getting there.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, consolidated list of the paper’s open issues, framed to be concrete and actionable for future work.
- Representativeness of tasks: Only 102 tasks were selected from 5,112 via internal difficulty judgments and two reviewers; provide transparent, pre-registered sampling, stratification (sector, market-cap, geography, time), and release per-task metadata to assess selection bias and coverage.
- Human baseline and variability: No human-analyst baselines under the same constraints; measure human pass@1/dense scores, inter-analyst agreement on moves/themes, and variance across firms/strategies to calibrate the human–model gap.
- Single LLM judge reliance: Grading depends on one judge (Gemini-3.1-Pro); run cross-judge audits (e.g., GPT, Claude, open-source judges), report agreement statistics, and quantify judge-induced ranking shifts.
- Vendor/style bias in judging: The judge is from a model family also being evaluated; test for bias by blinding model identity, using multi-judge ensembles, and measuring whether specific stylistic patterns are favored.
- Rubric generation drift: Rubrics are produced by a single LLM pass and verified only against the data folder (not transcript spans); implement the proposed v2 pipeline (stepwise generation, transcript-span grounding, human validation, disagreement-triggered re-review) and quantify drift rates before/after.
- Hallucination detection fidelity: The grounding check uses inline citations and an LLM; build a gold subset with human claim–evidence annotations to estimate precision/recall of hallucination flags, and test robustness to “citation spamming” and near-miss source matches.
- Off-rubric insight credit: Off-rubric but correct/novel reasoning is not rewarded; add a secondary “novel insight” score with human adjudication or a dynamic rubric expansion process and report its reliability.
- Closed-document pool realism: Agents are restricted to a curated, containerized corpus; assess performance with live retrieval (EDGAR, press releases, news, industry reports) and paywalled data to better mirror analyst workflows.
- Adversarial/noisy sources: Corpora lack adversarial or low-quality documents; introduce controlled noise, conflicting narratives, and prompt-injection content to test robustness and mitigation strategies.
- Temporal and forecasting validity: Tasks are anchored to transcript dates, but forward-looking reasoning is central; evaluate whether rubric-aligned answers predict ex-post outcomes (events, KPIs, returns), and quantify calibration over varying horizons.
- Link to economic outcomes: Validate construct validity by correlating dense/pass scores with subsequent excess returns or realized event outcomes on a subset of tasks.
- Tooling transparency and ablations: The exact toolset and permissions (e.g., spreadsheet, plotting, Python, APIs) are not systematically varied; run tool-ablation studies and measure the marginal utility of each tool class.
- Agent scaffolding and decoding controls: The agent architecture, prompts, and decoding settings (temperature/top-p) for each model are under-specified; standardize scaffolds, control seeds, and conduct prompt/decoding sensitivity analyses.
- Metric design breadth: Beyond pass@1 and dense score, report pass@k, best-of-n, sample-efficiency curves, compute- and cost-normalized metrics ($/perfect pass), and reliability-aware scores that penalize output-level hallucinations.
- Uncertainty quantification: Error bars capture only task-sampling uncertainty; add run-to-run variance (bootstrap across trials/seeds) and report confidence intervals for dense and pass@k per model.
- Parsing/grade failure impact: Unparsable judge outputs zero entire runs; quantify the incidence, root causes, and bias across models, and implement robust parsing/retry policies with pre-specified fallbacks.
- Scoring rule sensitivity: The theme threshold τ and move credit rules are unvalidated; perform sensitivity analyses to τ and tainting rules, and publish model ranking stability under metric variants.
- Rewarding synthesis: The synthesis check is a binary gate; evaluate its reliability, define clear operational criteria, and test whether minimal phrasing can game synthesis credit.
- Data/code availability: The benchmark relies on proprietary traces; specify access terms, release scoring code and judge prompts, and provide a public or synthetic subset for replication.
- Multimodality gaps: Many filings include figures/charts/PDF tables; extend tasks, tools, and judging to images, scanned PDFs, and spreadsheet manipulation with verifiable cell-level grounding.
- Human-in-the-loop evaluation: Realistic analyst workflows are collaborative; run user studies where analysts use agents as copilots, measuring time saved, error rates, and decision quality.
- Trajectory budget causality: Observed plateaus in returns to longer trajectories are correlational; run controlled interventions varying step/tool budgets and test adaptive stopping policies.
- Train/test leakage and learning: No assessment of finetuning on part of the corpus and testing on held-out tasks; define standard train/validation/test splits and evaluate generalization and overfitting risks.
- Failure-mode taxonomy release: The paper mentions a taxonomy but does not detail it; publish the taxonomy, definitions, and labeled examples to guide targeted method development.
- Sector/region/language scope: Coverage across industries, geographies, and languages is unclear; include non-U.S. regimes, multilingual filings, and sector-balanced suites to test cross-domain generalization.
- Portfolio-level reasoning: Tasks emphasize single-company analysis; add position sizing, hedging, scenario analysis, and cross-holding constraints to capture portfolio construction reasoning.
- Baseline comparators: No non-LLM baselines (keyword templates, financial heuristics); include such baselines to contextualize LLM gains and isolate the value of reasoning vs retrieval.
- Item difficulty calibration: Per-task difficulty/discrimination is not modeled; apply item response theory to calibrate tasks and create ability-scaled reporting.
- Privacy/ethics of transcripts: Provide detailed consent, anonymization, redaction, and audit procedures for proprietary analyst conversations, and publish an ethics statement covering data governance.
Practical Applications
Immediate Applications
- Finance: vendor selection and model gating for research agents
- What: Use Hedge-Bench-style pass@1, dense scores, hallucination rates, and per-category performance to choose and govern LLMs/agents for investment research.
- Tools/workflows: Deploy a procurement dashboard that runs candidate models in a containerized task harness (e.g., Harbor/Terminus) against a fixed environment set; set category-specific thresholds (e.g., higher thresholds for Risk and M&A tasks, where failure costs are higher).
- Assumptions/dependencies: Access to Hedge-Bench-like tasks or equivalent internal task bank; licensing for models; reproducible containers with time-bounded corpora.
- Finance: grounded memo checker for research and compliance
- What: Enforce inline citations and run a grounding check to flag unsupported facts in analyst notes, investment memos, and marketing materials.
- Tools/products: “Grounded Memo Checker” plugin for Google Docs/Word/Notion that extracts factual claims and verifies them against cited filings/press releases; taints unsupported moves.
- Assumptions/dependencies: Document collection/management with canonical source-of-truth links; acceptance by legal/compliance; reliable claim extraction and matching.
- Finance: analyst training and assessment gym
- What: Convert theme/move rubrics into case-based exercises for new hires; auto-grade reasoning coverage and synthesis quality.
- Tools/workflows: Training portal with Dockerized environments, rubric-based grading, feedback on missed/tainted moves, and synthesis prompts for reconciliation practice.
- Assumptions/dependencies: Availability of licensed tasks or internally curated analogs; LLM-as-judge configured for concept-match grading.
- Finance: workflow policies to reduce hallucination risk
- What: Institute operating rules reflecting paper findings—require inline citations for all figures/entities, reject ungrounded claims, and route high-judgment items to human oversight.
- Tools/workflows: “Reliability gates” in research pipelines; automatic rejection/triage when tainted moves exceed a threshold; dual-pass verification for Risk/M&A content.
- Assumptions/dependencies: Organizational buy-in; integration with content management and review systems.
- Finance/Software: cost–quality optimization using step budgets
- What: Apply the observed performance plateau around 15–25 steps to set default agent budgets that capture most quality with lower cost/latency.
- Tools/workflows: “Adaptive Budgeter” that caps steps and tunes parallel tool-calls; monitors marginal gains by step to auto-halt.
- Assumptions/dependencies: Similar task complexity profiles; ability to meter and control agent step/tool-call counts.
- Cross-sector (legal, healthcare, policy analysis): process-based grading for open-ended tasks
- What: Adopt the theme/move rubric + LLM-as-a-judge approach to grade argumentation quality rather than just final answers for long-form reasoning in other domains.
- Tools/workflows: Domain-specific rubrics; inline-citation enforcement; grounding, coverage, and synthesis checks.
- Assumptions/dependencies: Access to domain SMEs to craft/validate rubrics; curated, time-bounded source corpora; governance for sensitive data (especially in healthcare/legal).
- Academia/ML research: evaluation of agent architectures and tool-use strategies
- What: Use Hedge-Bench-style metrics to study the impact of trajectory length, tool-call strategies, and grounding constraints on reasoning quality and reliability.
- Tools/workflows: Benchmark harness with macro-averaged dense and pass@1 metrics; ablations on tool use vs. depth; tainted-move analysis to diagnose hallucination patterns.
- Assumptions/dependencies: Reproducible environments and grading; access to multiple model families for fair comparisons.
- Policy/Regulation: internal audit standard for AI-generated financial content
- What: Create an internal supervisory standard requiring citations and grounded claims for AI-assisted disclosures or client communications.
- Tools/workflows: “Compliance pre-review bot” that runs grounding/synthesis checks; audit logs linking each claim to evidence.
- Assumptions/dependencies: Regulator tolerance for LLM-as-a-judge-assisted workflows; human-in-the-loop oversight; robust logs for audit trails.
- Daily life (retail investors): browser extension that flags unsupported claims in finance articles
- What: Consumer tool that highlights numbers/entities in articles and checks for linked primary sources (filings, press releases); warns if no sources are present.
- Tools/products: Browser extension with lightweight claim detection and source lookup; scoring badge for “evidence coverage.”
- Assumptions/dependencies: Access to public filings/news APIs; simplified grading (no proprietary rubrics); careful UI to prevent overclaiming accuracy.
- Software/Knowledge management: containerized, date-bounded analysis sandboxes
- What: Package document pools tied to a cutoff date to avoid leakage and enable reproducible reasoning experiments across teams.
- Tools/workflows: Docker-based corpora bundles; standardized mounting and provenance metadata; versioned environments for A/B tests.
- Assumptions/dependencies: Document ingestion pipelines; storage/governance for dated snapshots.
Long-Term Applications
- Finance: expert-aligned preference and process models for research agents
- What: Train agents to match expert analysts’ reasoning trajectories (not just answers), using process-level supervision and rubrics.
- Tools/products: Process RL / preference modeling from action-move traces; “Analyst-aligned Research Copilot” that plans, cites, and synthesizes like experts.
- Assumptions/dependencies: Scalable, licensed reasoning trace datasets; safety/ethics reviews; robust generalization across firms/sectors.
- Finance: autonomous thesis-generation with explicit reconciliation
- What: Agents that autonomously decompose open-ended prompts, run analyses, and produce theses with grounded synthesis of conflicting evidence.
- Tools/workflows: Multi-tool agents integrated with financial data providers; synthesis-aware planners; continuous evaluation against Hedge-Bench-like suites.
- Assumptions/dependencies: Lower hallucination rates or stronger verification; deeper tool integration (models, data vendors, simulators); human oversight for high-stakes outputs.
- Cross-industry: standardized process-level benchmarks for professional services
- What: Extend the Hedge-Bench methodology to legal briefs, medical case reviews, policy memos, and scientific literature surveys.
- Tools/products: Domain-specific “ProcessBench” families; publicly auditable rubrics; sector-grade harnesses.
- Assumptions/dependencies: SME availability; regulatory/privacy constraints; interoperable document provenance standards.
- Policy/Regulation: certification regimes for AI research tools
- What: Third-party certification that AI systems meet process-level grounding and synthesis standards before deployment in regulated finance.
- Tools/workflows: Accredited benchmarks with pass/fail thresholds and category-specific minimums; public scorecards and audit artifacts.
- Assumptions/dependencies: Regulatory alignment; consensus on acceptable LLM-judge reliability; periodic re-certification to track model drift.
- Data/IP markets: licensed marketplaces for high-fidelity expert reasoning traces
- What: Scalable acquisition and licensing of expert debates/transcripts to train and benchmark domain agents.
- Tools/products: Data marketplaces with consented, anonymized traces; quality tiers; provenance and compensation frameworks.
- Assumptions/dependencies: Legal/IP frameworks, privacy safeguards, standardization of annotation/rubric formats.
- Multi-agent systems for adversarial debate and consensus synthesis
- What: Agents that stage pro/con debates and converge via rubric-driven synthesis, improving judgment-heavy categories like Risk and M&A.
- Tools/workflows: Debate orchestrators; synthesis judges that reward reconciliations; adaptive reruns when tainted moves appear.
- Assumptions/dependencies: Reliable arbitration mechanisms; cost controls for multi-agent runs; empirical validation of debate gains.
- Dynamic reliability management and “hallucination insurance”
- What: Run-time policies that detect tainted moves and automatically add verification steps, invoke retrieval/quant checks, or escalate to humans.
- Tools/workflows: Claim-level provenance trackers; adaptive verification chains; risk-weighted routing (e.g., more checks for forward-looking judgments).
- Assumptions/dependencies: Mature claim verification ecosystems; integration with internal data warehouses; acceptable latency/cost budgets.
- Education: adaptive tutors for finance and business reasoning
- What: Case-based learning systems that grade process and provide targeted feedback on missed analytical moves and weak synthesis.
- Tools/products: “Analyst Coach” with rubric-aligned hints; programmatic curricula that adjust difficulty by coverage metrics.
- Assumptions/dependencies: Institutional access to case materials; fairness/assessment policies; localized content for different markets.
- Tooling: generalized “action-move rubric builder” from SME conversations
- What: Semi-automated pipeline that converts SME interviews into themes and required moves, grounded in source corpora, with human verification gates.
- Tools/workflows: Transcript mining; move extraction with cross-model disagreement flags; per-move evidence linkage.
- Assumptions/dependencies: High-quality SME inputs; scalable human-in-the-loop verification; robust version control for rubrics.
- Agent ops: budget-aware planning and telemetry standards
- What: Platform-level controls to set step/tool budgets, log grounded coverage, and manage quality-cost trade-offs across deployments.
- Tools/workflows: “AgentOps” dashboards with pass@1/dense metrics by task category; budget policies learned from historical plateau points.
- Assumptions/dependencies: Standardized telemetry across model vendors; privacy-compliant logging; cultural acceptance of metered agent behavior.
Notes on feasibility and dependencies across applications:
- LLM-as-a-judge reliability: Grading quality depends on judge robustness; production systems need fallback judges, schema validations, and human audits to mitigate grading defects.
- Rubric quality: v1 single-pass rubric generation can drift from transcripts; productionization should adopt the paper’s v2 remedy (step-wise generation, per-move transcript grounding, human validation, and disagreement-based re-reviews).
- Data governance: Time-bounded, containerized corpora improve reproducibility and reduce leakage but require disciplined document pipelines and storage.
- Model drift and variance: Periodic re-benchmarks are necessary as models evolve; macro-averaging and confidence intervals should be standard reporting.
- Legal/compliance: Use of expert traces and generated analyses must respect licensing, privacy, and regulatory boundaries; high-stakes outputs require human oversight.
Glossary
- 95% confidence interval: A statistical range that likely contains the true value of an estimated metric with 95% confidence. "Error bars show the 95% confidence interval for task-sampling uncertainty across environments."
- action moves: Discrete, checkable sub-claims the rubric expects within each theme to demonstrate reasoning. "each theme is further divided into four to five sub-themes representing action moves."
- agentic effort: The extent of an agent’s active exploration during a task, often proxied by steps and tool use. "The better predictor is agentic effort (i.e. trajectory length, tool use), shown in Fig. \ref{fig:trajectory_hallucination}."
- answer-keyed questions: Tasks graded by matching a pre-specified answer rather than evaluating reasoning. "it still terminates in answer-keyed questions and grades factual correctness rather than argumentation."
- binary events: Outcomes with two possible states that materially affect decisions or valuation. "binary events like litigation outcomes."
- coverage check: A grading step that evaluates which required moves in each theme the answer satisfies. "The second task is a coverage check."
- dealbreaker gating: A scoring rule where certain critical errors cause failure regardless of other performance. "Vals AI's FAB v2 has a severity-weighted partial credit scoring mechanism with dealbreaker gating."
- dense score: A fine-grained multi-point score reflecting breadth and depth of rubric coverage. "Dense mean score: the fine-grained score per model on a scale or (averaged across all environments and all attempts)."
- deterministic grading criteria: Evaluation rules designed to produce unambiguous, reproducible grading outcomes. "deterministic grading criteria derived from explicit reasoning traces jointly created by two hedge fund Analysts"
- Docker container: An isolated execution environment packaging code, data, and tools for a task. "the agent must complete in the Docker container."
- frontier models: The most advanced LLMs available, representing the capability frontier. "frontier models and agents resolve less than 16\% of tasks"
- GLP-1: A class of metabolic drugs (glucagon-like peptide-1 receptor agonists) that can alter consumer behavior and demand. "because of GLP-1"
- gold span: The annotated ground-truth text snippet used as the target in QA datasets. "pairs each item with a gold span, number, or reasoning program"
- ground truth: The authoritative reference used to evaluate model outputs. "Pairing experts in ground truth construction provides structural quality checks"
- groundability: How readily claims can be supported by the provided source documents. "The gradient tracks groundability: Valuation, Growth, and Operational topics are data-anchored"
- grounding check: A verification step that flags claims not supported by the cited sources. "The first task is a grounding check."
- Harbor harness: The execution framework used to run tasks specified in the Harbor format. "are run using the Harbor harness."
- Harbor task format: A specification for packaging interactive tasks and their resources. "Tasks are specified using the Harbor task format"
- hallucination rate: The frequency with which a model produces unsupported or fabricated claims. "Trials are also tracked for trajectory length, tool usage, and hallucination rate."
- inline-cite: To include in-text citations pointing to specific source files for each claim. "Critically, the agent must inline-cite the specific source file backing every claim;"
- ITU allocation: Spectrum assignment by the International Telecommunication Union that governs exclusive usage rights. "L-band carries a primary, exclusive ITU allocation, which is in turn what walls competitors off from regulated safety services"
- judgment-heavy: Requiring forward-looking or subjective assessment rather than purely data-anchored analysis. "Risk, Competitive Positioning, and M{paper_content}A are judgment-heavy and forward-looking."
- L-band spectrum: A 1–2 GHz radio frequency band valued for reliability and penetration in adverse conditions. "Identifies L-band's specific resilience to environmental interference such as heavy cloud cover, storms, and dense foliage."
- LLM-as-a-Judge: Using a LLM to evaluate and score outputs against a rubric. "LLM-as-a-Judge"
- low-variance estimator: An estimator designed to have minimal sampling variability. "the standard low-variance estimator of pass@1,"
- macro-averaging: Averaging metrics within each environment, then averaging equally across environments. "computed by macro-averaging: we first average the dense scores of the valid trials within each environment, then average those per-environment means across all 102 environments,"
- macro dense mean: The macro-averaged mean of dense scores across environments. "Claude-Sonnet-4.6 leads on rubric performance (macro dense mean 1.92/4.0, the only pass@1 above 15\%;"
- mission-critical: Denoting reliability required for essential, safety-sensitive operations. "Contrasts Iridium's `mission-critical' reliability for voice and low-bandwidth data against the vulnerability of high-frequency broadband."
- multiple compression: A decline in a valuation multiple (e.g., P/E), often reducing a firm’s market valuation. "includes concepts like multiple compression and expansion, downside protection,"
- multiple expansion: An increase in a valuation multiple, boosting a firm’s market valuation. "includes concepts like multiple compression and expansion, downside protection,"
- normalized earnings power: A firm’s sustainable earnings level adjusted for one-offs and cyclicality. "assessing normalized earnings power,"
- pass@1: The probability that a single attempt achieves a perfect score. "Pass@1: the probability a single model attempt scores a perfect 4.0/4.0 in a given environment"
- Pearson r: The Pearson correlation coefficient measuring linear association between two variables. "Pearson , ."
- preference model: A model trained to reflect expert judgments or choices rather than objective labels. "Hedge-Bench is deliberately geared towards building a preference model that reflects the actions expert analysts actually take."
- required moves: Lettered sub-requirements under a theme representing specific claims the answer must make. "each theme decomposes into lettered required moves, the specific claims or arguments an answer must make to demonstrate it reasoned through the theme."
- rubric-based scoring: Grading outputs using a structured rubric of themes and moves. "Rubric-based scoring"
- safety services: Regulated communications services (e.g., aviation/maritime) reserved for safety-critical use. "Competitors are walled off from safety services"
- severity-weighted partial credit: A scoring scheme that allocates partial credit based on the seriousness of errors. "has a severity-weighted partial credit scoring mechanism"
- sparse pass/fail signal: A binary indicator of whether a perfect rubric score was achieved. "From the dense score we derive a sparse pass/fail signal:"
- sum-of-the-parts analyses: Valuation by summing individually valued business segments or assets. "sum-of-the-parts analyses"
- synthesis check: An evaluation step that looks for reconciliation of conflicting evidence into a unified conclusion. "The third task is a synthesis check,"
- tainting: Marking a move as invalid because its support relies on hallucinated or unverifiable facts. "Here is where hallucinations are penalized through tainting."
- task-sampling uncertainty: Variability in reported metrics due to which tasks are included in the benchmark sample. "task-sampling uncertainty across environments."
- technical moat: A durable competitive advantage arising from technological or physical properties. "Technical Moat of L-Band Spectrum in Austere Environments"
- tool call: An invocation of an external tool by the agent during a run. "The trajectory length, tool-call counts, and hallucination rate for each model."
- trajectory length: The number of steps or actions an agent takes in a task attempt. "Trials are also tracked for trajectory length, tool usage, and hallucination rate."
- unit economics: Per-unit revenue, cost, and margin characteristics that drive business viability. "with superior unit economics"
- valuation multiples: Ratios (e.g., P/E, EV/EBITDA) used to compare and value companies. "computing valuation multiples"
Collections
Sign up for free to add this paper to one or more collections.

