Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Abstract: AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper introduces Terminal-Bench 2.0, a big, carefully designed “report card” for AI helpers that use a computer’s terminal. The terminal is the text-only window where you type commands to do powerful things (like installing software, searching files, running programs). The goal is to see how well today’s top AI models can handle tough, realistic computer tasks that skilled people do at work.
What questions the researchers asked
They wanted to know:
- Can AI agents actually complete hard, real-world computer tasks from start to finish, not just answer questions?
- Which AI models and agent setups do the best?
- What kinds of mistakes do these AIs make, and why?
- How can we fairly and repeatably test these abilities as AIs get better?
How the benchmark works (with plain-language examples)
Think of Terminal-Bench like an obstacle course for AI on a computer. Each task is a self-contained “level” inside a safe, controlled computer-in-a-box.
Key pieces of each task:
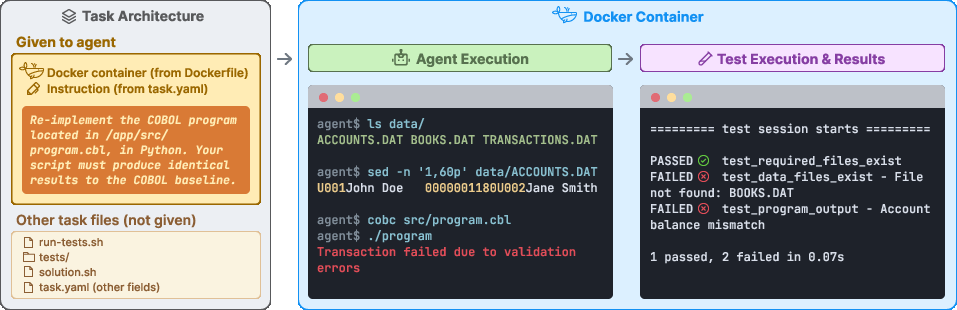
- An instruction: what needs to be done (for example, “fix this program,” “train this model,” or “rewrite this old code so it still works”).
- A Docker image: this is like a sealed, clean mini-computer with all the right files and software inside, so every AI faces the exact same setup.
- Tests: automatic checks that say “pass” only if the task is truly completed (like a grader that looks at the final result, not how you got there).
- A reference solution: a human-written way to finish the task, proving it’s solvable.
Tasks are interactive: the AI must explore and act inside the terminal by running commands (like grep, find, python, etc.), editing files, and installing tools to get the job done.
To build a strong and varied challenge set, the team:
- Collected 229 candidate tasks from 93 contributors, then selected 89 hard, realistic tasks after multiple rounds of quality checks by expert reviewers.
- Verified tasks with automated checks, human audits, and even “adversarial” tests to ensure you can’t cheat (for example, by peeking at future versions of a code repo).
To compare models fairly, they also built:
- Terminus 2: a simple, neutral agent that only uses a headless terminal and Bash commands. This reduces bias from fancy extra tools and makes it easier to see model differences.
- Harbor: a framework to run many tasks in parallel, so they could test lots of models and agents at scale.
Examples of tasks include building Linux from source, reverse engineering binary files, implementing algorithms, and translating old COBOL programs into Python.
What they found (and why it matters)
Overall performance:
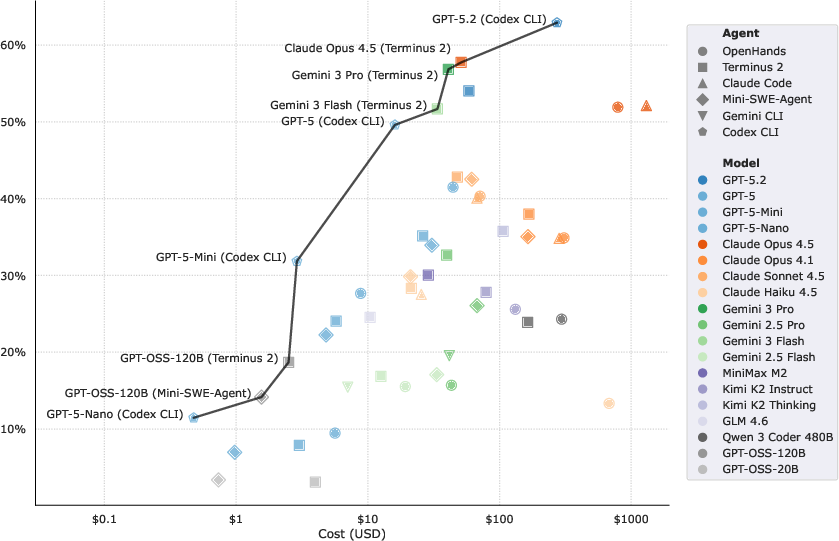
- Even the strongest model-agent combos solved under about 65% of the tasks. The top score was 63%.
- Smaller or open-weight models did much worse on average (around 15–36%).
- Some tasks were unsolved by any model, showing there is still a real gap to human experts.
Cost and effort:
- Running the full benchmark can cost from a few dollars to about $100, depending on the model’s price.
- Some attempts ran for up to two hours and made hundreds of model calls, showing these are long, multi-step tasks—not quick one-shot answers.
- Using more steps or more tokens didn’t automatically mean better results.
Model vs. agent:
- Choosing a stronger model usually helped more than choosing a different agent “scaffold” (the wrapper that helps the model act). In other words, brains mattered more than the toolbox—though both matter.
Difficulty:
- When humans said a task was “hard,” models generally also struggled. But many tasks humans called “medium” turned out to be “hard” for AIs, especially ones needing creative or adversarial thinking (like bypassing a tricky filter).
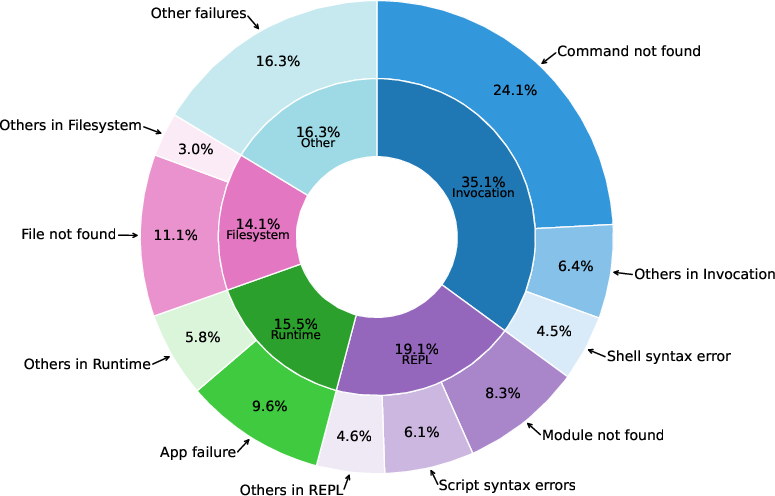
Where AIs fail (error analysis):
- Execution mistakes: doing the wrong actions in the terminal, misusing commands, or not following instructions tightly.
- Coherence mistakes: losing track of the plan, being inconsistent, or forgetting what was already done.
- Verification mistakes: not checking whether the result truly satisfies the goal.
- Command-level issues: a very common problem was trying to run tools that weren’t installed or weren’t in the system’s PATH, plus various run-time errors.
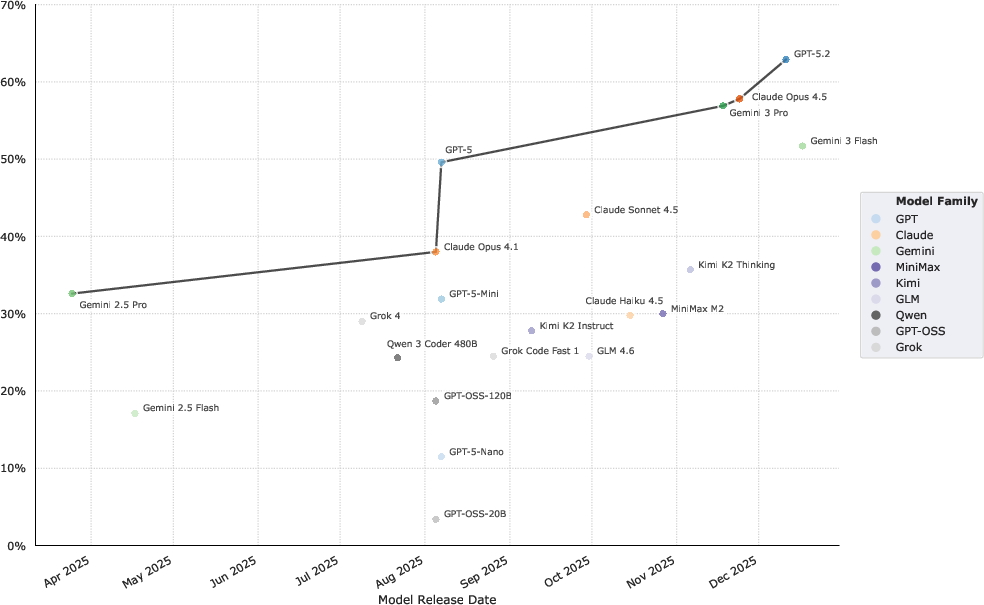
Progress over time:
- Newer models did noticeably better. Performance roughly doubled across a recent 8‑month period. At this pace, models may soon handle most well-defined terminal tasks, and the benchmark will need to get harder again.
Why this work is important
- Real-world relevance: These tasks look like the actual work that software engineers, researchers, and power users do. That makes this benchmark a meaningful way to measure whether AI can truly help (or autonomously do) valuable jobs.
- Clear feedback for builders: The detailed error breakdown shows where to improve—better command reliability, stronger planning and memory, and better self-checking.
- A moving target: As models improve fast, Terminal-Bench offers a way to track progress and will evolve with new, tougher tasks to keep pushing the frontier.
- Safer, smarter agents: By focusing on outcome-based tests and preventing “cheats,” the benchmark encourages building agents that are robust, honest, and effective in realistic settings.
Key terms in plain language
- Terminal: A text window where you type commands to control the computer.
- AI agent: An AI that takes actions step by step (not just chat), like running commands and editing files to reach a goal.
- Docker image: A sealed “computer-in-a-box” that gives everyone the exact same setup to make tests fair and repeatable.
- Benchmark: A standardized test to compare different systems.
- Tests (for tasks): Automatic checks that only pass if the final outcome is correct, no matter which steps the agent took.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces Terminal-Bench 2.0 and reports initial findings, but it leaves several important questions unresolved. Below is a concise list of concrete gaps and open problems that future researchers could address:
- Benchmark scope beyond Linux containers
- No evaluation on non-Linux operating systems (Windows, macOS), heterogeneous hardware (GPUs/TPUs), distributed systems, or GUI-based workflows; design and measure cross-platform, hardware-aware, and GUI-inclusive task suites.
- Representativeness and selection bias
- Crowdsourced task selection (89 of 229) is guided by subjective difficulty/quality assessments; quantify representativeness of tasks relative to real industry workflows and identify systematic biases in categories, domains, and difficulty.
- Private test-set and contamination controls
- Only public tasks with a Big-Bench canary; develop a private test split, watermarking, and automated contamination detection pipelines (e.g., source fingerprinting and telemetry) to mitigate training leakage or agent “solution lookup.”
- Internet variability and reproducibility
- External dependencies (APIs, package repos) introduce drift; quantify run-to-run variance due to internet changes, provide mirrored artifacts/caches, and define an offline mode to isolate reasoning from retrieval.
- Container runtime/provider effects
- Results use a single sandbox provider (Daytona); measure performance differences across providers/runtimes (e.g., Docker, containerd, Kubernetes) and enforce standardized resource limits to ensure comparability.
- Binary pass/fail metric limitations
- Resolution rate masks partial progress, efficiency, and safety; introduce graded metrics (partial credit per test subset), action efficiency (commands, time, tokens), safety/side-effects, and robustness under perturbations.
- Time-limit sensitivity
- Tasks have time limits, but their influence on success is not analyzed; perform sensitivity studies to determine how time budgets affect planning depth, success, cost, and error modes.
- Decoupling agent scaffold vs. model capability
- Most proprietary agents are only paired with their respective models; systematically cross-pair agents and models to quantify scaffold contributions and interaction effects.
- Reasoning effort and inference settings
- Models with configurable reasoning are run at provider defaults; ablate reasoning effort, temperature, tool-use policies, and planning strategies to map effort-cost-performance trade-offs.
- Web access reliance
- Internet is allowed but its impact is not characterized; ablate web access (on/off, restricted retrieval) to quantify reliance on external information vs. internal reasoning.
- Multi-agent collaboration
- Benchmark evaluates single-agent settings; add coordinated multi-agent setups (planner/executor/reviewer) and measure whether collaboration resolves currently unsolved tasks.
- Human baselines
- No empirical human performance on the tasks; collect human resolution rates and time/cost curves to calibrate “frontier-level” difficulty and measure economic value.
- Empirical difficulty definition bias
- Difficulty is computed via Terminus 2 pass rates across selected models; design model-agnostic difficulty measures (e.g., using broader ensembles, human baselines, or capability probes) to avoid scaffold/model bias.
- Failure-to-intervention mapping
- Error taxonomy identifies categories but lacks controlled interventions; run ablations (e.g., environment introspection tools, package managers, PATH management, build fixers) to reduce dominant failures like “executable not installed/not in PATH.”
- Reliability of LLM-as-judge analyses
- Trajectory/command labeling relies on LLM judges with limited human calibration; scale human annotations, test cross-judge agreement, and validate judges on adversarial/edge cases to strengthen error analysis.
- Command-level failure remediation
- High prevalence of environment-related failures (install/execute/PATH); evaluate agents with explicit environment diagnostics, dependency solvers, sandbox-aware installers, and PATH/virtualenv management to quantify gains.
- Safety and side-effects
- Safety is not scored beyond anti-cheat checks; add safety metrics (privilege escalation, destructive actions, data exfiltration), red-teaming agents, and policy enforcement within the harness.
- Authentication and secrets
- No tasks requiring secure credential handling; design tasks with secrets (vaults/KMS/SSO) and measure agents’ secure practices (secret redaction, least privilege, token lifecycle).
- Signal handling and interactive I/O
- Some tasks require keyboard interrupts, but harness-level fidelity for signals/TTY behavior is not evaluated; verify and benchmark robustness of agent control over signals, pseudo-terminals, and interactive programs.
- Variance and stability across trials
- Results report CIs but do not analyze per-task volatility or seed sensitivity; measure variance sources (prompt seeds, environment drift, tool non-determinism) and introduce stability scores.
- Cross-benchmark external validity
- No correlation analysis with related benchmarks (SWE-Bench, WebArena, EnvBench, τ-Bench); quantify transfer and identify shared vs. benchmark-specific capability gaps.
- Tool-rich vs. Bash-only scaffolds
- Terminus 2 uses only a headless Bash terminal; test richer toolkits (editors, debuggers, build systems, retrieval/search tools) to determine the marginal value of specific tools per failure mode.
- Multilingual/generalization
- Tasks and instructions appear English-centric; introduce multilingual instructions, codebases, and documentation to measure language generalization in terminal contexts.
- Cost-aware agent policies
- Cost-performance curves are reported, but budgeted policies are not explored; design agents with dynamic stopping, caching, and retrieval throttling to optimize “success per dollar.”
- Dataset licensing and compliance
- Licensing and legal constraints for task artifacts are not discussed; audit and standardize licensing to enable broader training, evaluation, and redistribution.
- Roadmap for saturation
- The benchmark may saturate within a year; specify a roadmap for “Terminal-Bench Next” (harder task distributions, dynamic/rotating private sets, adversarial tasks, environment randomization) and criteria for retiring saturated items.
Glossary
- Adversarial exploit agent: A specialized agent designed to intentionally probe for vulnerabilities or shortcuts in task design to “cheat” the tests. "An adversarial exploit agent was run to detect design flaws that could allow agents to cheat and pass the tests."
- Agent harness: The surrounding integration that couples a model to tools and runtime to execute tasks. "Performance of each model with its best agent harness as a function of release date."
- Agent scaffold: The control logic and structure that guides an agent’s planning and actions. "The agent scaffold used to report each model was chosen to maximize performance."
- Agentic LLMs: LLMs equipped to autonomously plan, act, and use tools over multi-step tasks. "that can be used to evaluate agentic LLMs on challenging tasks."
- Big-Bench canary string: A distinctive marker embedded in files to help detect benchmark contamination in training datasets. "We include the Big-Bench \citep{srivastava2023beyond} canary string in each file in our repository to aid in training corpus decontamination."
- Cohen's-kappa: A chance-corrected statistic for measuring inter-annotator agreement. "On a calibration subset of 20 trials, annotators achieve high agreement (93% Cohen's-)."
- Container runtime enforcement: The constraints and policies applied by the container engine that affect execution behavior. "Additionally, variability in machine resources and container runtime enforcement can lead to differences in effective task environments."
- Container sandbox providers: Services that provision and isolate containers at scale for safe, reproducible evaluations. "Harbor comes pre-integrated with multiple container sandbox providers."
- Containerized environment: A self-contained computational environment packaged with dependencies inside a container. "Each task consists of (1) a containerized environment initialized with relevant packages and files..."
- Differential cryptanalysis: A cryptanalytic technique that studies differences in input-output pairs to attack block ciphers. "feal-differential-cryptanalysis (differential cryptanalysis of the FEAL cipher)"
- Docent: A tool/system that uses LLMs to summarize, cluster, and analyze agent transcripts. "The failed trials are analyzed with Docent \citep{meng2025docent}, together with a custom pipeline, to annotate, refine, and validate the rubrics in \cite{pan2025why}."
- Docker image: A portable, versioned snapshot of software and its environment used to instantiate containers. "A Terminal-Bench task consists of an instruction, a Docker image, a set of tests, an example solution, and a time limit (\autoref{fig:hero_figure})."
- FEAL cipher: A symmetric block cipher studied in cryptographic research, notably as a target of attacks. "feal-differential-cryptanalysis (differential cryptanalysis of the FEAL cipher)"
- Frontier models: The most advanced, cutting-edge AI models available at a given time. "We show that frontier models and agents score less than 65\% on the benchmark..."
- Harbor harness: The execution framework within Harbor that runs tasks and manages agent interactions. "Tasks are specified using the Harbor task format and are run using the Harbor harness, which supports popular agents..."
- Harbor registry: The distribution hub for publishing and retrieving Harbor-formatted task datasets. "Terminal-Bench~2.0 is distributed via the Harbor registry and can be run with harbor run -d [email protected]."
- Harbor task format: The specification schema used to define tasks, their environments, and tests in Harbor. "Tasks are specified using the Harbor task format..."
- Headless terminal: A terminal interface without a graphical UI, controllable programmatically by agents. "Terminus 2 has a single tool, a headless terminal, and completes tasks using only Bash commands."
- LLM-as-judge: A methodology where a LLM evaluates outcomes or trace segments according to predefined criteria. "An LLM-as-judge (GPT-5, medium reasoning, 92.4\% agreement with the majority vote label as determined by three annotators reviewing 66 pairs) is used to review individual command input-output pairs..."
- Multi-Agent System Taxonomy (MAST): A structured classification of failure modes and behaviors in agent systems. "We derive a failure categorization building from the Multi-Agent System Taxonomy (MAST) \citep{pan2025why}..."
- Open-weight models: AI models whose parameters (weights) are publicly available for use and fine-tuning. "and several popular open-weight models (GPT OSS 120B \citep{openai2025gptoss120bgptoss20bmodel}, GPT OSS 20B \citep{openai2025gptoss120bgptoss20bmodel}, Llama 4 Maverick \citep{meta2025llama4maverick}, Qwen 3 Coder 480B \citep{qwen3technicalreport}, Kimi K2 Instruct \citep{kimik2technicalreport}, Kimi K2 Thinking \citep{moonshotai2025kimiK2Thinking}, GLM 4.6 \citep{zai2025glm46}, and Minimax M2 \citep{minimaxm2_2025})."
- Oracle solution: A trusted, ground-truth script that is known to complete the task and make all tests pass. "each task has an oracle solution script that mirrors a real workflow and, when executed, causes all test cases to pass."
- Pareto frontier: The set of trade-off optimal points where improving one metric necessarily worsens another. "The Pareto frontier of agent performance showing the tradeoff between performance and cost (log scale) on~Terminal-Bench 2.0."
- PATH: An environment variable listing directories to search for executables. "We find that command failures calling executables that are not installed or not in PATH are the most frequent (24.1\% of all failures) followed by failures when running executables (9.6\%)."
- Path tracing: A Monte Carlo rendering technique that simulates light transport for physically based images. "path-tracing (implementing a physics-based renderer)"
- Pinning package versions: Fixing dependency versions to ensure reproducibility across runs. "Terminal-Bench tasks are designed for reproducibility by pinning package versions, providing prebuilt Docker images, and requiring dependencies to be included in the Docker context."
- Redcode: The assembly-like language used in the Core War programming game for competitive strategy. "winning-avg-corewars (Redcode strategy)."
- Reverse engineering: Analyzing binaries or systems to recover their design or functionality without source code. "to reverse engineering binary files."
- Training corpus decontamination: The process of removing benchmark content from training data to prevent contamination. "We include the Big-Bench \citep{srivastava2023beyond} canary string in each file in our repository to aid in training corpus decontamination."
- XSS filter bypasses: Techniques that evade cross-site scripting protection mechanisms. "break-filter-js-from-html (XSS filter bypasses)"
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Terminal-Bench 2.0, the Harbor harness, and the paper’s error analyses.
- Vendor and model evaluation scorecards for enterprise agent adoption
- Sectors: software, IT operations, cybersecurity, finance, healthcare
- What: Use Terminal-Bench 2.0 to compare agent-model pairs on resolution rate, cost (Pareto trade-offs), and failure profiles; build procurement scorecards and SLAs for agent capabilities in terminal-heavy workflows.
- Tools/workflows: Harbor run pipelines, Daytona or equivalent sandbox, automated reporting dashboards, task subsets aligned to your domain.
- Assumptions/dependencies: Containerized compute with Docker; internet access policy for agents; access to model/provider APIs; alignment between benchmark tasks and your production workloads.
- CI/CD gate for agent features and devtools releases
- Sectors: software, DevOps, MLOps
- What: Integrate a representative subset of Terminal-Bench tasks into pre-release checks to catch regressions in agent scaffolds, tool integrations, and model settings.
- Tools/workflows: Harbor as a test harness; per-commit or nightly runs; pass-rate thresholds; failure triage.
- Assumptions/dependencies: Build time budget; stable task selection; reproducible container sandboxes.
- AgentOps observability using trajectory and command-level failure taxonomies
- Sectors: software, cybersecurity, scientific computing
- What: Instrument agents with the paper’s simplified failure taxonomy (Execution, Coherence, Verification) and command-level error taxonomy (e.g., PATH/executable-not-found, runtime errors) to speed diagnosis and remediation.
- Tools/workflows: LLM-as-judge for automated labeling, Docent-like trace summarization, failure heatmaps, alerting on high-rate error modes.
- Assumptions/dependencies: Storage of agent transcripts; privacy controls; compute for post-hoc judging; annotator calibration for accuracy.
- Cost governance and quota tuning for agent runs
- Sectors: enterprise IT, finance, DevOps
- What: Use benchmark distributions to set timeouts, token budgets, and max-turn policies; identify diminishing returns when agents exceed certain turns/tokens without higher success.
- Tools/workflows: Budget policies per task class; model/agent policy files; dashboards showing cost-performance Pareto.
- Assumptions/dependencies: Accurate provider pricing; reliable telemetry; internal cost-accounting integration.
- Security red teaming of agent environments
- Sectors: cybersecurity, compliance, critical infrastructure
- What: Run adversarial exploit checks from the paper to detect task-design shortcuts (e.g., leaking future git commits) and environment flaws that enable “cheating.”
- Tools/workflows: Exploit-agent runs; task integrity audits; sandbox isolation checks; logging and incident workflows.
- Assumptions/dependencies: Hardened container runtimes; safe internet configuration; red-team staffing or automated exploit agents.
- Reproducibility audits for ML and scientific pipelines
- Sectors: MLOps, scientific computing
- What: Validate agents against tasks requiring training ML models or reimplementing research under outcome-based tests; use resolution rates to gate “reproducible” pipelines.
- Tools/workflows: Harbor task runs for ML pipelines; artifact checks; pass/fail gating in publishing or deployment.
- Assumptions/dependencies: Deterministic builds; pinned versions; adequate GPU/CPU resources; controlled external dependencies.
- Neutral internal baseline with Terminus 2
- Sectors: software R&D, platform engineering
- What: Use Terminus 2 (headless terminal only) as a simple, unbiased scaffold to compare models without toolchain confounders; identify model-specific behaviors.
- Tools/workflows: Standardized prompts; single-tool constraints; comparative runs across models.
- Assumptions/dependencies: Teams accept terminal-only constraints for fair comparison; broader toolchain tested separately.
- Rapid domain-specific benchmark authoring using the Harbor format
- Sectors: enterprise IT, regulated industries
- What: Apply the paper’s specification and verification checklist to build your own task set (e.g., finance data ETL, healthcare batch reporting) with outcome-driven tests.
- Tools/workflows: Harbor task format; multi-stage review; oracle solutions; adversarial checks.
- Assumptions/dependencies: Subject-matter experts; reviewer bandwidth; test completeness; internal registry for task distribution.
- Curriculum and hands-on labs for engineering education
- Sectors: education
- What: Use diverse tasks (reverse engineering, legacy systems, async Python, build-from-source) as graded labs; incorporate failure analysis to teach debugging and verification.
- Tools/workflows: Course modules; automated grading via tests; student sandboxes.
- Assumptions/dependencies: Academic compute; controlled internet access; instructor familiarity with Docker/Harbor.
- Daily-life power-user automation and personal assistant validation
- Sectors: daily life, prosumer workflows
- What: Validate CLI assistants on personal tasks (server setup, backups, dotfiles, media processing) using outcome tests; establish safe-run checklists before applying changes.
- Tools/workflows: Home lab containers; pre/post state checks; snapshotting and rollbacks.
- Assumptions/dependencies: Willingness to sandbox; basic CLI proficiency; backups; careful scoping of destructive commands.
- Procurement and policy-ready minimum performance thresholds
- Sectors: government, healthcare, finance
- What: Define minimum resolution rates and error ceilings for adopting agents in regulated contexts; require documented benchmark runs and failure-mode reports.
- Tools/workflows: Standardized evaluation dossiers; third-party attestation; model/agent change logs.
- Assumptions/dependencies: Agreement on task representativeness; legal approval; periodic re-certification cadence.
- Dataset-building methodology (multi-stage manual verification)
- Sectors: academia, industry R&D
- What: Adopt the paper’s verification process (oracle solvability, integrity checks, multi-auditor review, automated LLM checks) as a template for building high-quality agentic benchmarks.
- Tools/workflows: Contributor checklists; automated workflows; adversarial agents; reviewer rotations.
- Assumptions/dependencies: Community engagement; audit time; maintenance of canary strings for decontamination.
Long-Term Applications
These applications require further research, scaling, reliability improvements, or standardization before broad deployment.
- Autonomous terminal workers for SRE and release engineering
- Sectors: software, cloud, enterprise IT
- What: Agents execute long-horizon runbooks (patching, rollbacks, build-from-source, incident mitigation) with high autonomy.
- Tools/workflows: Verified runbooks mapped to outcome tests; real-time monitoring; human-in-the-loop escalation.
- Assumptions/dependencies: Resolution rates >95%, robust verification and rollback, stringent access controls.
- Large-scale legacy system migration (e.g., COBOL-to-Python)
- Sectors: finance, government, insurance
- What: Agents translate and validate legacy codebases with formal IO-equivalence tests and differential test suites.
- Tools/workflows: Corpus-specific tasks; static/dynamic analysis; staged deployment.
- Assumptions/dependencies: Domain experts for edge cases; comprehensive test coverage; strong auditability.
- Agent certification and compliance standards built on Terminal-Bench
- Sectors: policy, enterprise procurement
- What: Industry-wide certifications for terminal-capable agents; minimum performance, integrity, and safety criteria; reproducibility attestations.
- Tools/workflows: Accredited test centers; standardized task suites; versioned benchmarks; public reporting.
- Assumptions/dependencies: Multi-stakeholder consensus; governance and auditing bodies; avoidance of “overfitting” to public tasks.
- Outcome-based reinforcement learning for execution agents
- Sectors: AI research, platform engineering
- What: Use task tests as reward signals to train agents that plan, verify, and self-correct; scale curricula from medium to hard tasks.
- Tools/workflows: RL pipelines; curriculum scheduling; trajectory scoring; synthetic augmentation.
- Assumptions/dependencies: Access to large-scale compute; robust reward shaping; contamination controls.
- Safety monitoring pipelines with trajectory judges at scale
- Sectors: cybersecurity, regulated industries
- What: Deploy LLM-as-judge and human-calibrated rubrics to detect unsafe or incoherent agent behaviors in production terminals.
- Tools/workflows: Real-time judging; alerting; forensics; policy enforcement.
- Assumptions/dependencies: High-accuracy judges; privacy-preserving transcript storage; clear remediation playbooks.
- Scientific discovery and lab-in-the-loop automation via CLI
- Sectors: biotech, materials science, computational science
- What: Agents orchestrate data processing, experiment planning, and code execution in CLI-based research pipelines, verified by outcome tests.
- Tools/workflows: Benchmarks tailored to lab tasks; hardware integration; result validation.
- Assumptions/dependencies: Model robustness on domain-specific tasks; safe instrument control; data governance.
- Enterprise “Harbor-as-a-Service” and Agent QA platforms
- Sectors: software, platform tooling
- What: Managed services offering scalable task runs, audits, dashboards, failure analytics, and cost optimization for agent portfolios.
- Tools/workflows: Multi-cloud container orchestration; role-based access; report generation.
- Assumptions/dependencies: Commercial-grade reliability; vendor support; integration with internal tooling.
- Governance frameworks for benchmark decontamination and transparency
- Sectors: policy, academia, industry
- What: Policies mandating canary strings, contamination reporting, and private test sets for critical certifications; procurement clauses requiring ongoing performance disclosures.
- Tools/workflows: Data governance registries; attestations; independent audits.
- Assumptions/dependencies: Enforcement mechanisms; privacy-respecting evaluation; community-maintained private suites.
- Unified terminal + GUI agent benchmarks and workflows
- Sectors: office productivity, operations, robotics DevOps
- What: Combine terminal tasks with GUI/web tasks (e.g., OS World, WebArena) for end-to-end automation of realistic multi-interface workflows.
- Tools/workflows: Multimodal harnesses; accessibility-aware agents; cross-interface verification.
- Assumptions/dependencies: Mature multimodal agents; cross-environment sandboxing; richer test semantics.
- Dynamic benchmark generation and difficulty scaling
- Sectors: AI research, vendor-neutral testing
- What: Auto-generate new tasks to avoid benchmark saturation, adapt to model progress, and maintain discriminatory power.
- Tools/workflows: Task generators; human-in-the-loop curation; adversarial suites; rotating private sets.
- Assumptions/dependencies: Sustained curation effort; funding; guardrails against synthetic bias.
- Continuous vulnerability management with agentic patching
- Sectors: cybersecurity, enterprise IT
- What: Agents detect, prioritize, and patch vulnerabilities via CLI workflows, verifying successful remediation with outcome tests.
- Tools/workflows: CVE feed integration; sandboxed patching; staged deployment; rollback plans.
- Assumptions/dependencies: High reliability; strict access control; comprehensive tests to prevent regressions.
- Sector-specific compliance dashboards and risk scorecards
- Sectors: healthcare, finance, government
- What: Map benchmark results to compliance risks (e.g., PHI/PII handling, audited change management), enabling policy-aligned adoption.
- Tools/workflows: Risk mappings; evidence repositories; periodic re-evaluation.
- Assumptions/dependencies: Legal alignment; mapping benchmark capabilities to regulatory controls; third-party validation.
Collections
Sign up for free to add this paper to one or more collections.