- The paper introduces CAIA, a benchmark assessing AI robustness in high-stakes financial markets with misinformation and irreversible consequences.
- It employs a multi-stage curation process and evaluates models under both closed-book and open-book conditions to mirror real-world adversarial challenges.
- The study highlights significant cost-performance tradeoffs and systematic failures in tool selection, emphasizing the need for enhanced adversarial resilience.
Benchmarking AI Agents in Adversarial Financial Markets: The CAIA Framework
Introduction
The paper introduces CAIA, a benchmark specifically designed to evaluate AI agents in adversarial, high-stakes financial environments, with a focus on cryptocurrency markets. Unlike conventional benchmarks that assess task completion in controlled, cooperative settings, CAIA exposes models to environments characterized by misinformation, active deception, and irreversible financial consequences. The benchmark is motivated by the observation that current state-of-the-art LLMs, despite excelling in reasoning and knowledge tasks, exhibit fundamental vulnerabilities when deployed in domains where adversaries actively exploit AI weaknesses.
Benchmark Design and Curation
CAIA's design is grounded in three core challenges: irreversible financial consequences, adversarial information landscapes, and high-density, multi-source data. The benchmark curation pipeline is community-driven, involving over 3,000 contributors from diverse roles in the crypto ecosystem. The process consists of five stages: automated filtering using LLMs, expert review, format standardization, ground truth validation, and fine-grained categorization. This ensures ecological validity, resistance to training-data contamination, and objective, reproducible evaluation.

Figure 1: Data Curation Pipeline illustrating the multi-stage process for generating high-quality, adversarially-grounded benchmark tasks.
Tasks are anchored to recent market events with explicit temporal constraints, mitigating memorization-based solutions and ensuring liveness. Each task is validated to guarantee that a reproducible toolchain exists for obtaining the ground truth, reflecting the analytical workflows of domain experts. The final benchmark comprises 178 tasks distributed across six analytical categories, including on-chain analysis, project discovery, tokenomics, overlap, trend analysis, and general knowledge.
Experimental Evaluation
Seventeen state-of-the-art LLMs, both proprietary and open-source, are evaluated under two conditions: without tools (closed-book) and with tools (open-book, agentic framework). Tool augmentation provides access to 23 specialized resources, including web search APIs, blockchain analytics, market data feeds, and computational interpreters. Human baseline performance is established using junior analysts from university blockchain clubs and early-stage companies, achieving 80% accuracy with full tool access.
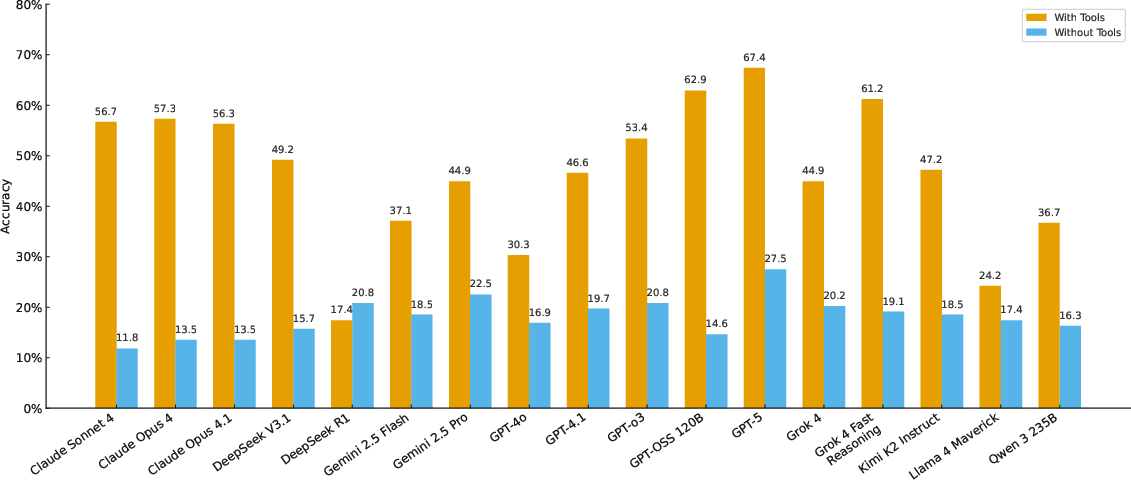
Figure 2: Average accuracy across five evaluation runs using majority voting. The dashed line indicates 80% human baseline performance. Without tools, all models perform near random (12–28%); with tools, performance improves but plateaus below human capability.
Without tools, all models—including frontier systems—perform near random, achieving only 12–28% accuracy. Even with tool augmentation, the best-performing model (GPT-5) reaches only 67.4% accuracy, significantly below the human baseline. This performance ceiling persists despite unlimited access to professional-grade resources, indicating architectural limitations rather than mere knowledge gaps.
Cost-Accuracy Tradeoff
The evaluation includes a detailed cost-efficiency analysis, revealing substantial economic disparities across model families. Open-source models such as GPT-OSS 120B achieve competitive accuracy at orders of magnitude lower cost compared to proprietary APIs. Specifically, GPT-OSS 120B and Grok 4 Fast are identified as Pareto-optimal, delivering near-frontier performance at minimal cost.
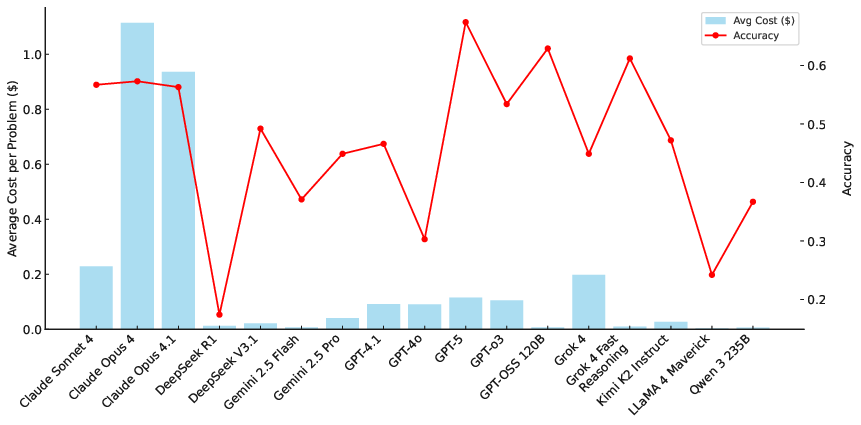
Figure 3: Cost-accuracy tradeoff reveals GPT-OSS 120B and Grok 4 Fast as Pareto-optimal choices, achieving near-frontier performance at minimal cost.
This finding has significant implications for large-scale deployment, challenging the assumed superiority of commercial APIs in specialized adversarial domains.
A critical analysis of tool usage patterns reveals a systematic failure in tool selection. Models overwhelmingly prefer generic web search (55.5% of invocations) over authoritative blockchain analytics, even when the latter provides direct access to ground truth. This behavior exposes models to SEO-optimized misinformation and social media manipulation, a dangerous vulnerability in adversarial environments.
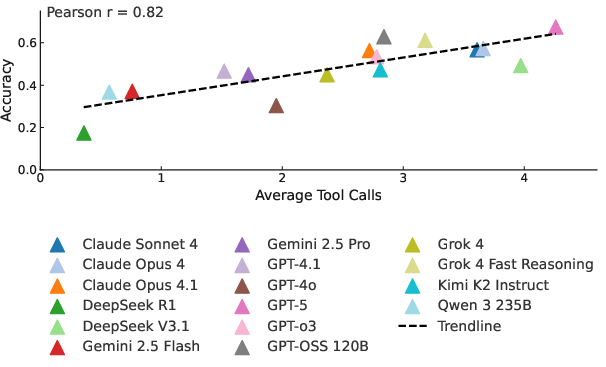
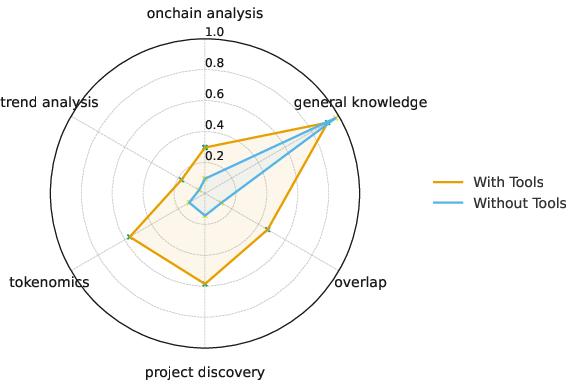
Figure 4: Tool usage frequency vs. accuracy, demonstrating a positive correlation but highlighting the importance of strategic tool selection over mere quantity.
The correlation between tool usage frequency and accuracy (Pearson coefficient 0.82) suggests that more tool calls can help refine responses, but effective performance depends on strategic selection. Models making numerous unfocused tool calls often perform worse than those making fewer, well-targeted queries. Category-wise analysis shows that on-chain analysis and trend analysis remain the most challenging, with minimal benefit from tool access due to the need for sophisticated reasoning and source validation.
A case study on a simple task—retrieving monthly token launch counts—demonstrates that all evaluated models failed by relying on outdated or manipulated web sources, never invoking the correct blockchain analytics API. This highlights a fundamental inability to recognize when specialized tools are necessary and to identify sources of truth.
Pass@k Metrics and the Illusion of Competence
The paper critically examines the use of Pass@k metrics in high-stakes adversarial contexts. While Pass@5 scores are higher than Pass@1, this improvement reflects trial-and-error rather than strategic reasoning. In financial domains, where errors are irreversible, such behavior is unacceptable. Majority voting yields only modest gains, indicating that errors are due to fundamental reasoning failures rather than stochastic variation.
Implications and Future Directions
CAIA exposes a critical blind spot in current AI evaluation: the lack of adversarial robustness. The findings demonstrate that leading LLMs are fundamentally unprepared for deployment in environments where misinformation is weaponized and errors have catastrophic consequences. The vulnerabilities identified extend beyond cryptocurrency to any domain with active adversaries, such as cybersecurity and content moderation.
For trustworthy autonomy, future research must prioritize adversarial robustness, skeptical reasoning, and strategic tool orchestration. CAIA provides a durable testbed for developing and evaluating agents capable of surviving in hostile, high-stakes environments. The benchmark's contamination controls and continuous updates ensure its relevance for ongoing model development and deployment decisions.
Conclusion
CAIA establishes adversarial robustness as a necessary condition for trustworthy AI autonomy in financial markets and beyond. The benchmark reveals that current models, despite impressive reasoning scores, remain dangerously unreliable when exposed to active opposition. Addressing these vulnerabilities requires a paradigm shift in agent evaluation, emphasizing survival and truth-seeking under adversarial pressure rather than mere task completion.

