GPIC: A Giant Permissive Image Corpus for Visual Generation
Abstract: Studying scalable methods for visual generative modeling requires large, accessible, and stable datasets. We introduce GPIC, a Giant Permissive Image Corpus of approximately 28 trillion pixels. GPIC comprises diverse internet images captioned by a state-of-the-art vision-LLM, including 100M training, 200K validation, and 1M test examples. Moreover, all GPIC images are permissively licensed for both research and commercial use. GPIC is safety-filtered, deduplicated, and centrally hosted on Hugging Face. We provide a benchmarking protocol for generative modeling on GPIC. Finally, we provide a reference baseline for pixel-space flow matching on GPIC. Our dataset, benchmark, and models are available at https://huggingface.co/datasets/stanford-vision-lab/gpic. Evaluation toolkit and code are available at https://gpic.stanford.edu


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GPIC (Giant Permissive Image Corpus), a huge collection of 100 million images with matching text descriptions (captions). It’s built to help researchers fairly train and test image‑generation AI models (the kind that turn text prompts into pictures). GPIC is designed to be legal to use, stable over time, big enough for modern models, and easy to download.
What questions were the authors trying to answer?
In simple terms, the authors asked:
- How can we build a modern, legal, and stable image dataset that anyone (schools, labs, companies) can use to train and compare image‑generating AIs?
- Can we provide better, clearer ways to judge these AIs so scores really reflect image quality and variety—not just “teaching to the test”?
- What does a transparent, realistic training + testing setup look like today?
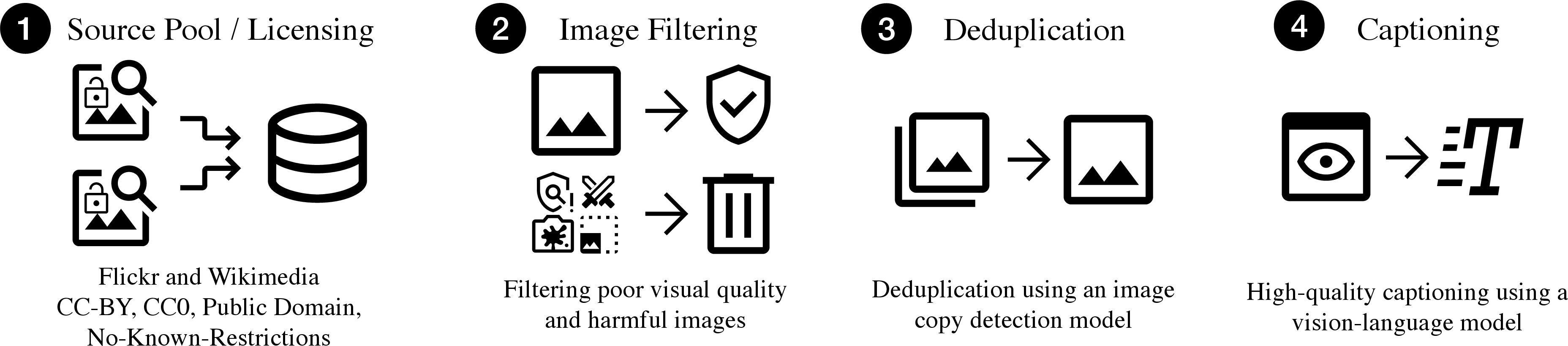
How did they build GPIC?
To make GPIC, the team followed a careful pipeline, like organizing a massive photo album that’s clean, legal, and well‑labeled.
Finding legally usable images
They collected images from sites like Flickr and Wikimedia that allow reuse (licenses like CC BY, CC0, and public domain). “Permissive” means the images can be used for both research and commercial projects. They kept info like the license and who to credit for each image.
Cleaning and safety filtering
They removed images that were too small, too blurry, nearly blank, or otherwise poor quality. They also used an AI to flag images that might be unsafe, and removed those. Think of this like tossing out photos that are too dark, out of focus, or inappropriate.
Removing duplicates
Lots of online images are copies or near‑copies (like taking several shots of the same scene). The team used a “copy detection” method to find similar images and remove clear duplicates—like using a smart “find similar photos” feature on your phone. They did this carefully to keep truly different images (even if they’re similar), while cutting out obvious repeats.
Writing captions for every image
Most web images don’t have good descriptions. So the team used a strong vision‑language AI (Qwen3‑VL‑4B) to write captions for every image. They used four styles:
- Tags (short keyword lists)
- Short captions
- Medium captions
- Long, more detailed captions Most captions are short or medium so they’re fast and useful for training.
Splits and packaging (making it easy to use)
They split the dataset into training (100M images), validation (200K), and test (1M). They also made smaller versions:
- GPIC‑Nano: 1M images
- GPIC‑Lite: 10M images Everything is hosted on Hugging Face in balanced chunks (“shards”), so you can download and stream them easily without special tools.
How do you judge image‑generating models fairly?
The authors propose a better evaluation method:
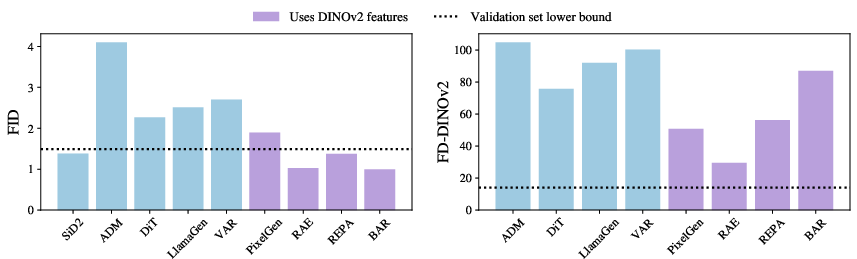
- Instead of using the old FID score (which many models have already “maxed out” on older datasets), they use a newer approach based on DINOv2 features. Think of DINOv2 as a modern way for a computer to “look” at images more like a human would.
- Their main score is FD‑DINOv2 (a distance between real and generated images in DINOv2’s “vision space”). Lower is better.
- They also report Precision/Recall and Density/Coverage to capture both faithfulness (images look real) and diversity (images aren’t all the same).
- Importantly, they compare generated images to a separate, held‑out test set (1M images), not the training set. That helps catch cheating or memorization.
To make comparisons fair, they provide:
- A fixed set of 50K test captions: everyone runs their model on the same prompts.
- Precomputed test statistics and a public evaluation toolkit.
What did they find, and why does it matter?
Here are the main takeaways:
- GPIC meets four goals at once: it’s permissive (legal), stable (doesn’t change behind your back), large (100M images ≈ 28 trillion pixels), and accessible (easy to download and use).
- Captions are high‑quality and varied (from simple tags to detailed descriptions), making the dataset better for today’s text‑to‑image models.
- Their evaluation method (FD‑DINOv2) stays informative, unlike older scores that are now “saturated.” It also lines up better with what humans think looks good.
- They release a simple, transparent baseline model trained on GPIC. Its results show GPIC is challenging and useful for tracking improvements.
- Everything is public: the dataset, the evaluation code, and the baseline. That encourages fair, reproducible science instead of secret, ever‑changing data.
Why does this work matter?
- For students and researchers: GPIC makes it possible to train and compare image‑generating models on a large, stable, legal dataset without guessing what others used.
- For companies: The permissive licenses reduce legal risk and make it easier to build on this work.
- For the field: Better benchmarks lead to better models. By avoiding outdated tests and by using a held‑out test set, the results are more meaningful.
- For safety and transparency: The dataset includes safety filtering, clear attribution, and a frozen release (not just a list of URLs that might disappear). That reduces data drift and hidden changes.
In short, GPIC is like a well‑organized, openly shared “mega‑library” of images and captions—designed for today’s AI image generation—plus a fair grading system and a starter model. It should help the community build better, safer, and more reliable image‑generating AIs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research.
- Dataset representativeness and bias: No quantitative audit of geographic, demographic, cultural, or category distributions (e.g., people, objects, scenes), nor analysis of source-platform (Flickr/Wikimedia) biases and their downstream impact on generative models.
- Train/val/test leakage via near-duplicates: Deduplication is intentionally conservative and details do not explicitly confirm cross-split near-duplicate removal; the paper does not quantify residual near-duplicates across splits or their effect on evaluation.
- Post-dedup residual duplicate rate: No corpus-level measurement (manual or automated) of remaining near-duplicate prevalence after the two-tier SSCD rule, nor ablations of thresholds vs. diversity/quality trade-offs.
- License accuracy and “No-Known-Restrictions”: No audit of mislabelled licenses at this scale or clarity on the legal basis and due diligence for the “No-Known-Restrictions” category across jurisdictions.
- Attribution compliance for CC BY: No guidance on how users should satisfy CC BY attribution at 100M scale (e.g., aggregated attributions, downstream model releases), or whether derived models incur attribution obligations.
- Safety filtering scope and validity: Safety removal (~0.35%) lacks a disclosed taxonomy, thresholds, or precision/recall estimates; no human validation of false positives/negatives; unclear coverage of categories (e.g., sexual content, violence).
- Privacy/PII risks: No explicit detection/removal policy for faces (including minors), identity documents, license plates, or other PII in images or captions (including OCR-extracted text).
- Caption faithfulness at scale: Captions are generated by one VLM (Qwen3-VL-4B) with only a 1,520-image microbenchmark and LLM-as-a-judge scoring; no large-scale human audit or error-rate estimates (hallucinations, miscounts, spatial errors) across 100M images.
- Caption style homogeneity: Reliance on a single captioner risks stylistic and linguistic homogeneity; no ablations with multiple VLMs or human-mixed captions to assess generalization and overfitting to caption style.
- Caption-type mixture choice: The 1%/45%/45%/9% tag/short/medium/long mix is heuristic; no experiments probing how this ratio affects model learning, prompt faithfulness, or sample diversity.
- Content coverage statistics: Absent taxonomic breakdowns (objects, scenes, activities, long tail) to guide targeted data curation or interpret model failures by domain.
- Multilingual support: Captions appear English-only; no multilingual variants or evaluation, limiting research on multilingual text-to-image generation.
- Watermarks and low-quality artifacts: No reported prevalence of watermarks, heavy compression, overlays, or manipulated images post-filtering; no watermark detection or corruption statistics.
- Evaluation ignores text–image alignment: Primary metrics (FD-DINOv2, Precision/Recall, Density/Coverage) are marginal distribution metrics and do not evaluate prompt fidelity; no CLIPScore/TIFA/human studies for conditional alignment.
- Human correlation on GPIC: No user studies validating that FD-DINOv2 correlates with human judgments of quality and faithfulness for GPIC’s text-conditioned setting.
- Metric contamination risk: DINOv2 may have been trained on overlapping web data; no empirical overlap audit with GPIC Test-1M; the degree to which familiarity inflates FD-DINOv2 remains unquantified.
- Adversarial optimization of the metric: Beyond discouragement/disclosure, no safeguards, secondary primary metric, or leaderboard policy to mitigate optimization to DINOv2 features.
- Baseline scope and scaling: Only a single pixel-space flow model trained for one epoch at 256×256; no comparisons to latent diffusion/DiT/AR models, no scaling laws, no Nano/Lite vs. Full ablations, and no higher-resolution studies.
- Aspect ratio handling: Baseline uses square crops at 256×256; no analysis of aspect-ratio preservation or resolution scaling vs. performance relative to GPIC’s resolution distribution.
- Overlap with other datasets/benchmarks: No measurement of GPIC’s overlap with common training/evaluation sets (e.g., LAION, ImageNet) to assess contamination and generalization.
- Test-set integrity: Full 1M-image test set is public; no mechanism to prevent training on test images (e.g., hidden test servers), risking benchmark gaming.
- Reproducibility of captioning: Caption generation took ~1,500 H100-hours, but it is unclear if pinning seeds/versions yields identical captions; no release of n-best candidates/logits or a deterministic reproduction protocol.
- Dataset governance and lifecycle: No versioning/change-log plan, takedown policy (e.g., for mislicensed or sensitive items), or mirroring strategy beyond a single hosting provider.
- Provenance accountability vs. stability: Removal of source URLs aids stability but impedes independent license verification and subject notification; no alternative mechanism for provenance checks or updates.
- Legal jurisdiction nuances: CC BY/PD interpretations vary by country; the paper does not discuss cross-jurisdictional risks for commercial deployment using GPIC.
- Broader multimodal benchmarks: Although GPIC is positioned for broader multimodal research, no standardized tasks or baselines are provided for retrieval, captioning, or VQA on GPIC.
- Environmental and cost considerations: Limited analysis of compute/storage costs and practical guidance for low-resource users beyond Nano/Lite tiers (e.g., streaming bandwidth, shard access patterns).
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage GPIC’s dataset, pipeline, and evaluation protocol today.
- Train and fine‑tune license‑clean text‑to‑image models for commercial products
- Sector: software, media/entertainment, advertising, e‑commerce
- How: Stream GPIC shards (Hugging Face) into existing training stacks; use provided captions (tag/short/medium/long) for flexible conditioning; start on GPIC‑Nano (1M) or GPIC‑Lite (10M), scale to GPIC‑Full (100M)
- Tools/workflows: Hugging Face datasets streaming; shards (8,000 tars); CFG sampling; reference JiT‑T2I config for a starting point
- Assumptions/dependencies: Sufficient compute/storage (≈12.9 TB for GPIC‑Full); performance at higher resolutions may require further training; attribution handling for CC BY content if needed downstream; dataset biases from Flickr/Wikimedia
- Reproducible benchmarking and model selection using FD‑DINOv2 on a held‑out test set
- Sector: AI labs, academia, enterprise AI procurement
- How: Generate 50K images from fixed GPIC test captions; compute FD‑DINOv2, Precision/Recall, Density/Coverage against released 1M‑test statistics
- Tools/workflows: gpic‑eval (PyTorch evaluation suite); DINOv2 features; published test statistics on Hugging Face
- Assumptions/dependencies: Avoid optimizing directly on DINOv2 features per protocol; disclose deviations; compute for generating 50K samples per model
- Rapid prototyping and ablations with tiered datasets
- Sector: startups, research groups
- How: Use GPIC‑Nano/Lite for quick iteration, hyperparameter tuning, and architectural comparisons; swap shard ranges to scale experiments consistently
- Tools/workflows: Shard‑based tiering; identical source/caption distributions across tiers
- Assumptions/dependencies: Consistent shard selection for reproducibility; storage/bandwidth for tier downloads
- License‑aware data curation for internal corpora
- Sector: data engineering/platforms
- How: Replicate GPIC’s pipeline—license filtering, VLM‑based quality/safety filtering, and SSCD+FAISS deduplication—for proprietary or domain datasets
- Tools/workflows: Qwen3‑VL‑4B filters; SSCD descriptors; FAISS; conservative two‑tier dedup rules (0.90 graph, >0.9625 pair removal; keep only highest‑res in connected components ≥5)
- Assumptions/dependencies: Access to VLM inference (vLLM/SGLang) and GPU capacity; threshold calibration for specific domains; quality/safety policy alignment
- Caption enrichment for existing image assets
- Sector: e‑commerce (product catalogs), DAMs, education
- How: Apply the paper’s short/medium/long/tag prompting templates with Qwen3‑VL‑4B to generate multi‑granularity captions for search, retrieval, and training
- Tools/workflows: Provided caption prompts; VLM‑inference stack; optional LLM‑as‑judge scoring
- Assumptions/dependencies: Caption quality varies by domain; English‑centric captions by default; GPU hours and batching strategy affect throughput
- Synthetic data augmentation for discriminative models
- Sector: retail (classification/search), content moderation, mapping
- How: Train or fine‑tune generators on GPIC and synthesize class/attribute‑balanced images using tags/short captions to improve minority coverage or stress‑test classifiers
- Tools/workflows: GPIC‑trained generators; diversity metrics (Recall/Coverage) to verify augmentation utility
- Assumptions/dependencies: Gains depend on domain match; risk of reinforcing dataset biases; ensure labeling alignment
- Safer dataset release and training operations
- Sector: MLOps/data governance
- How: Adopt “frozen tar shards” release pattern to prevent silent drift and poisoning; maintain per‑sample licensing/attribution metadata
- Tools/workflows: Sharded packaging; attribution strings; SHA‑256 duplicate checks
- Assumptions/dependencies: Organizational processes for provenance retention; legal review for dataset redistribution
- Standardized model reporting for publications and model cards
- Sector: academia, AI vendors
- How: Report FD‑DINOv2 on GPIC with 50K fixed captions and held‑out statistics; document auxiliary model usage per protocol
- Tools/workflows: gpic‑eval; published “oracle reference” real‑vs‑real distances to contextualize results
- Assumptions/dependencies: Community compliance; disclosure of DINOv2‑aligned training if used
- Teaching and skills development
- Sector: education
- How: Use GPIC‑Nano/Lite in courses for data pipelines, generative modeling, evaluation, and reproducibility
- Tools/workflows: Shards + evaluation suite; caption prompts/microbenchmark
- Assumptions/dependencies: Storage and bandwidth availability for students/institutions
Long‑Term Applications
These opportunities require further research, scaling, domain adaptation, or ecosystem adoption.
- Sector‑specific permissive datasets using the GPIC pipeline
- Sector: healthcare (non‑PII medical imagery), manufacturing (inspection), cultural heritage, geospatial
- What: Build licensed, stable, domain‑aligned corpora with VLM‑based quality/safety filters and conservative dedup
- Tools/workflows: Domain‑tuned safety filters; specialized VLMs; license vetting; shard packaging
- Assumptions/dependencies: Availability of permissively licensed domain data; stronger safety/taxonomy requirements; expert annotation for high‑risk domains
- Video and 3D/multimodal corpora with analogous permissive, stable design
- Sector: film/VFX, robotics, AR/VR, simulation
- What: Extend GPIC principles to video/temporal data and 3D assets; enable training/evaluation of generative video or 3D models with held‑out metrics
- Tools/workflows: License‑vetted source pools; temporal safety filters; scalable captioning/storyboarding VLMs
- Assumptions/dependencies: Video licensing complexities; much higher storage/compute; evaluation metric maturation
- Open, certifiable standards for training‑data compliance and audits
- Sector: policy/regulation, enterprise compliance
- What: “Trained on permissive corpus” certifications; lineage tracking that proves license scope and provenance at scale
- Tools/workflows: Dataset manifests, per‑sample metadata, audit APIs, internal dashboards
- Assumptions/dependencies: Regulator and industry adoption; third‑party auditors; harmonized license interpretations
- Next‑gen open‑weight generators trained entirely on permissive data
- Sector: enterprise AI, creative tools
- What: Foundation T2I/T2V models that are legally uncomplicated to deploy commercially
- Tools/workflows: Large‑scale streaming training on GPIC; higher‑res curricula; distillation/compression for deployment
- Assumptions/dependencies: Compute budgets; product‑grade guardrails and RLHF; potential need for supplemental high‑res or domain‑specific images
- Multimodal grounding and agent systems leveraging structured captions
- Sector: robotics, assistive tech, AR/vision assistants
- What: Use GPIC’s hierarchical captions (tag→long) to pretrain vision‑language components for spatial/attribute grounding
- Tools/workflows: Curriculum learning with caption lengths; integration with action/policy models
- Assumptions/dependencies: Need for task/embodiment‑specific data; bridging sim‑to‑real gaps; additional annotations (e.g., depth, actions)
- Bias and safety measurement frameworks anchored to held‑out evaluation
- Sector: academia, policy, platform safety
- What: Develop standardized stress tests and fairness audits for generators using FD‑DINOv2‑based suites plus human studies
- Tools/workflows: Expanded caption test sets targeting protected attributes; audit reporting schemas
- Assumptions/dependencies: Additional labeling and demographic taxonomies; consensus on fairness metrics and procedures
- Evaluation‑as‑a‑service and dataset streaming services
- Sector: cloud/ML platforms
- What: Managed endpoints for GPIC streaming, 50K‑caption evaluation runs, and metric dashboards
- Tools/workflows: Hosted gpic‑eval; autoscaling inference/training clusters
- Assumptions/dependencies: Cost‑effective cloud economics; privacy/security for proprietary model submissions
- On‑device and edge‑deployed generators trained on GPIC‑Lite
- Sector: mobile, creative apps, games
- What: Compressed models distilled from GPIC‑trained systems for offline use
- Tools/workflows: Quantization, pruning, distillation; mobile inference runtimes
- Assumptions/dependencies: Maintaining image quality under tight compute/memory; energy constraints
- Data‑centric research on metrics beyond DINOv2 and robustness to “metric‑gaming”
- Sector: academia/standards bodies
- What: New perceptual metrics, human‑aligned benchmarks resistant to over‑optimization
- Tools/workflows: Larger held‑out sets; multi‑facet scoring (aesthetics, grounding, diversity)
- Assumptions/dependencies: Community consensus; scalable human evaluation pipelines
- Federated training with GPIC as public backbone + private data adapters
- Sector: enterprises with proprietary catalogs
- What: Combine GPIC pretraining with private fine‑tuning via adapters/LoRA in privacy‑preserving setups
- Tools/workflows: Federated learning stacks; parameter‑efficient fine‑tuning; secure aggregation
- Assumptions/dependencies: Legal and privacy frameworks; domain shift management; heterogeneous data quality
Cross‑cutting assumptions and dependencies
- Compute and storage: GPIC‑Full is ≈12.9 TB and training at scale typically requires multi‑GPU clusters.
- Licensing and attribution: Although GPIC is permissive (CC BY/CC0/Public Domain/No‑Known‑Restrictions), CC BY may require attribution handling in some deployments; retain metadata.
- Safety and quality: VLM‑based filters reduce but do not eliminate problematic content; organizations may need stricter domain‑specific filters.
- Bias and representativeness: Flickr/Wikimedia skew may underrepresent certain geographies, demographics, or modalities; validate before critical deployments.
- Metric usage: FD‑DINOv2 should not be directly optimized without disclosure; results are most meaningful when adhering to the evaluation protocol.
- Resolution and detail: Average image resolution (~479×587) may limit ultra‑high‑res generation without additional data or upsampling strategies.
Glossary
- AdamW: A variant of the Adam optimizer that decouples weight decay from the gradient update for better regularization. "We use AdamW with learning rate , betas 0.9 and 0.95, and no weight decay."
- approximate nearest-neighbor search: A fast method to find close items in high-dimensional spaces without exact comparisons, often used for large-scale similarity search. "and use FAISS for approximate nearest-neighbor search."
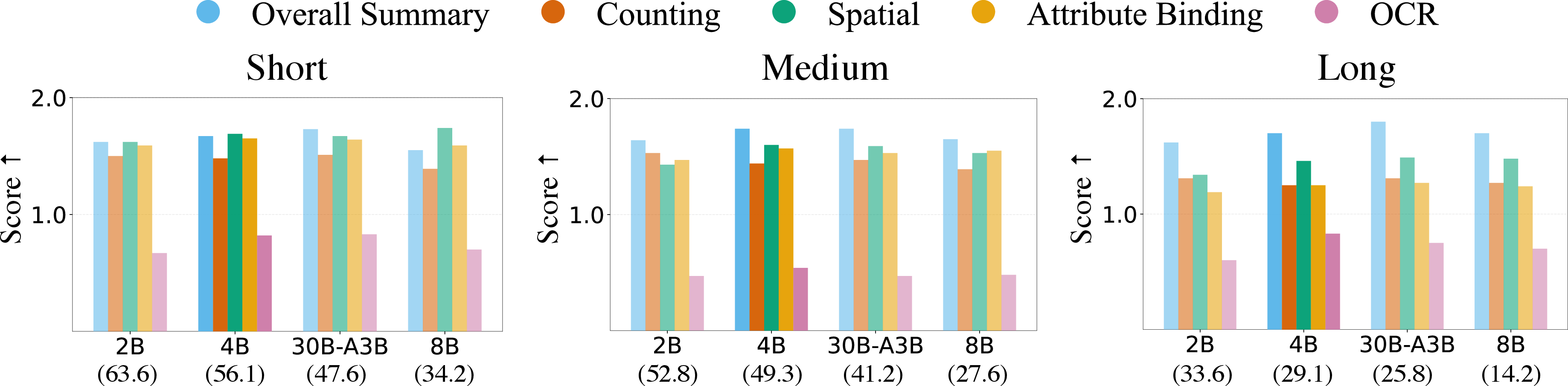
- attribute binding: The capability of a model to correctly associate attributes (like color or position) with the correct objects in an image. "best spatial understanding and attribute binding scores (1.60 and 1.55);"
- classifier-free guidance (CFG): A sampling technique for conditional generative models that adjusts the strength of conditioning without a separate classifier. "We sample with Euler sampling using 50 steps and evaluate classifier-free guidance (CFG) scales 1.75, 4.0, and 6.25."
- connected component: A set of nodes in a graph where each node is reachable from any other within the set; used here to group near-duplicate images. "for connected components containing at least five images, we keep only the highest-resolution image in the component,"
- copy detection features: Visual descriptors designed to identify copies or near-copies of images under transformations. "deduplicate images using similarity scores derived from SSCD~\cite{pizzi2022self} copy detection features (Stage 3)"
- Coverage (metric): A diversity metric for generative models measuring how much of the reference distribution is covered by generated samples. "We also report Precision and Density, which measure fidelity, and Recall and Coverage, which measure diversity"
- deduplication: The process of identifying and removing duplicate or near-duplicate items in a dataset. "We run SSCD-based deduplication on six subsets ranging from 108K to 3.4M images, across thresholds ."
- Density (metric): A fidelity-oriented metric assessing how well generated samples fall within dense regions of the reference distribution. "We also report Precision and Density, which measure fidelity, and Recall and Coverage, which measure diversity"
- DINOv2: A self-supervised vision model whose features are used for evaluation metrics more aligned with human perception. "On GPIC, we evaluate generated images using metrics computed over DINOv2 features."
- DINOv3: A newer large-scale self-supervised vision model; use of its features during training can bias evaluation on DINO-based metrics. "such as DINOv3 \cite{simeoni2025dinov3} or SigLIP \cite{zhai2023sigmoidlosslanguageimage}."
- Euler sampling: A numerical sampler used for generative diffusion/flow models, specifying the integration steps during image generation. "We sample with Euler sampling using 50 steps"
- FAISS: A library for efficient similarity search and clustering of dense vectors at scale. "and use FAISS for approximate nearest-neighbor search."
- FD-DINOv2: A Frechet Distance metric computed over DINOv2 features, used as the primary evaluation metric in GPIC. "We recommend DINOv2 features because ImageNet-1K FID is saturated, while FD-DINOv2 remains informative for current models."
- FID: Fréchet Inception Distance, a standard metric for evaluating generative models that has become saturated on some benchmarks. "ImageNet-1K FID is saturated, while FD-DINOv2 remains informative for current models."
- flow matching: A generative modeling approach that learns continuous flows in data space, here used in pixel space for image generation. "JiT~\cite{li2025back}, a pixel-space flow matching model with a Transformer backbone."
- Goodhart's law: The principle that once a measure becomes a target, it loses its effectiveness as a measure. "Goodhart's law: When a measure becomes a target, it ceases to be a good measure."
- link rot: The phenomenon where URLs become inaccessible over time, undermining dataset stability and reproducibility. "which makes comparisons difficult due to link rot~\cite{datacomp, yfcc100m}."
- LLM-as-a-judge: An evaluation setup where a LLM is used to score or judge outputs along specified criteria. "Each axis is scored on a 0--2 scale using an LLM-as-a-judge pipeline, and we also measure captioning throughput."
- Maximum Mean Discrepancy: A non-parametric statistical distance between distributions used to evaluate generative models. "and Maximum Mean Discrepancy as a non-parametric alternative to FD."
- MoE (Mixture of Experts): A model architecture where inputs are routed to specialized sub-networks (experts), often sparsely activated for efficiency. "We evaluate Qwen3-VL-Instruct models at 2B, 4B, 8B, and 30B-A3B (sparse MoE) on this benchmark."
- OCR: Optical Character Recognition, the task of extracting text from images. "We score captions along five axes: overall summary quality, counting accuracy, spatial understanding, attribute binding, and OCR."
- Power law: A functional relationship where one quantity varies as a power of another, often used for extrapolating scaling behavior. "and fit a power law to predict removals at full scale."
- Precision (metric): A fidelity metric indicating how closely generated samples match the support of the reference distribution. "We also report Precision and Density, which measure fidelity, and Recall and Coverage, which measure diversity"
- Recall (metric): A diversity metric showing how well generated samples cover the variety present in the reference distribution. "We also report Precision and Density, which measure fidelity, and Recall and Coverage, which measure diversity"
- SGLang: An inference/serving framework optimized for efficient generation with large language/vision models. "and support efficient inference through standard serving frameworks such as vLLM~\cite{kwon2023efficient} and SGLang~\cite{zheng2024sglang}."
- SHA-256: A cryptographic hash function used here to detect exact duplicate files. "We also verify that no exact duplicates remain by computing SHA-256 hashes over image file bytes."
- shard: A partition of a large dataset into manageable chunks to facilitate storage and streaming training. "We package GPIC as tar shards containing images, captions, and metadata, and release the dataset on Hugging Face with documentation."
- SigLIP: A language-image pretraining approach; using its features during training may confer unfair advantages in evaluation. "such as DINOv3 \cite{simeoni2025dinov3} or SigLIP \cite{zhai2023sigmoidlosslanguageimage}."
- SSCD: A self-supervised descriptor for image copy detection used to identify near-duplicate images. "Specifically, we extract SSCD features~\cite{pizzi2022self} for all images and use FAISS for approximate nearest-neighbor search."
- URL index: A dataset format that lists source URLs instead of hosting files directly, which can be unstable over time. "Many modern image datasets are distributed as URL indices, which makes comparisons difficult due to link rot~\cite{datacomp, yfcc100m}."
- URL-level data poisoning: Malicious manipulation of web-hosted data that can contaminate datasets built from URL lists. "eliminating silent dataset drift, exposure to URL-level data poisoning, and the need to re-scrape source images outside our filtering pipeline."
- vLLM: An optimized serving system for large language and vision-LLMs aimed at high-throughput inference. "and support efficient inference through standard serving frameworks such as vLLM~\cite{kwon2023efficient} and SGLang~\cite{zheng2024sglang}."
Collections
Sign up for free to add this paper to one or more collections.

