- The paper presents a fully automated, hierarchical taxonomy for decomposing complex image generation and editing tasks.
- It demonstrates significant performance gains with up to 18% improvement on editing benchmarks and 13% on generation benchmarks.
- The dataset comprises 80,000 instruction-image pairs across diverse domains, ensuring robust and scalable model training.
OpenGPT-4o-Image: A Systematic Dataset for Advanced Multimodal Image Generation and Editing
Motivation and Context
Unified multimodal models capable of both image generation and editing from natural language instructions have become central to AI research. However, the progress of such models is fundamentally limited by the quality, diversity, and structure of their training data. Existing datasets typically focus on basic tasks—such as style transfer or simple object manipulation—and lack systematic coverage of complex, real-world scenarios, including scientific illustration, compositional reasoning, and multi-turn editing. OpenGPT-4o-Image addresses these deficiencies by introducing a large-scale, hierarchically organized dataset, constructed via an automated pipeline leveraging GPT-4o, to support the next generation of multimodal models.
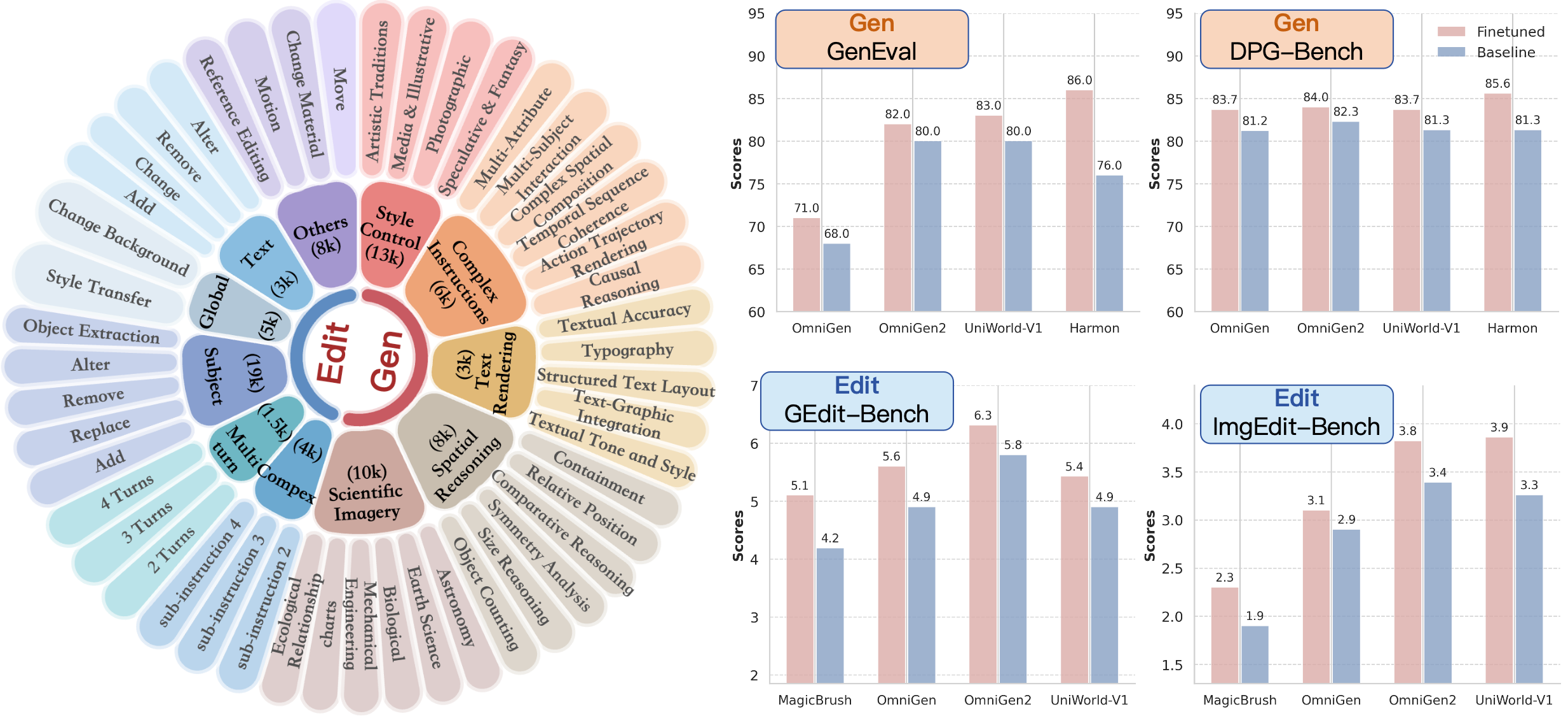
Figure 1: Overview of OpenGPT-4o-Image, illustrating the breadth of image generation and editing tasks covered by the dataset.
Hierarchical Task Taxonomy
A key innovation of OpenGPT-4o-Image is its hierarchical taxonomy, which decomposes the space of image generation and editing into fine-grained, capability-driven modules. For image generation, five core modules are defined:
- Style Control: Rendering diverse artistic, photographic, and speculative styles.
- Complex Instruction Following: Adhering to prompts with multiple compositional or logical constraints.
- In-Image Text Rendering: Accurate and aesthetic placement of text within images, including multilingual and typographic control.
- Spatial Reasoning: Geometric precision in object positioning, counting, and comparative reasoning.
- Scientific Imagery: Generation of domain-specific visuals for mathematics, physics, biology, engineering, and more.
For image editing, six categories with 21 subtasks are defined, including subject manipulation, text editing, complex/multi-turn editing, global editing (e.g., style transfer, background replacement), and other challenging forms such as reference image editing and object movement.

Figure 2: Representative image generation tasks, categorized by core capability: style control, complex instruction following, in-image text rendering, spatial reasoning, and scientific imagery.

Figure 3: Representative image editing tasks, including subject manipulation, text editing, complex/multi-turn editing, global editing, and other challenging scenarios.
Automated Data Construction Pipeline
The dataset construction pipeline is fully automated and consists of two primary phases:
- Task Definition and Scoping: Each capability is precisely defined, decomposed into hierarchical categories, and assigned difficulty grades. This ensures that the dataset covers both fundamental and advanced skills, with explicit boundaries to avoid ambiguity and overlap.
- Structured Prompt Generation: Instructions are generated at scale using syntactic templates populated from structured resource pools (objects, actions, qualifiers). This approach enables controlled diversity and difficulty, while maintaining high semantic fidelity.
For image editing, the pipeline integrates high-quality source images from multiple corpora, uses GPT-4o to generate editing instructions, and produces edited images via the gpt-image-1 API. Special handling is implemented for reference image editing, multi-turn editing, and style transfer to ensure coverage of complex, real-world scenarios.
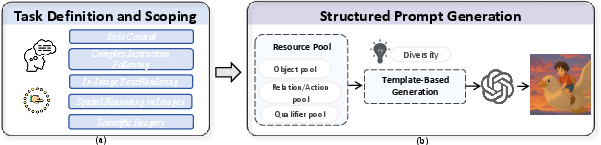
Figure 4: Image generation data construction pipeline, illustrating task definition, hierarchical decomposition, and structured prompt generation.
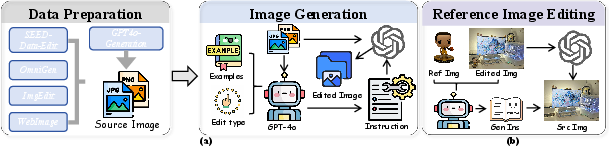
Figure 5: Image editing data construction pipeline, including source image acquisition, instruction generation, and reference image editing.
Dataset Composition and Coverage
OpenGPT-4o-Image comprises 80,000 high-quality instruction-image pairs, spanning 11 major domains and 51 subtasks. The dataset is balanced to ensure both breadth and depth:
- Image Generation: 40,000 samples, with major allocations to style control (13k), scientific imagery (10k), spatial reasoning (8k), complex instruction following (6k), and in-image text rendering (3k).
- Image Editing: 40,000 samples, with major allocations to subject manipulation (19k), global editing (5k), other challenging editing (8k), text editing (3k), complex instruction editing (4k), and multi-turn editing (1.5k).
This structure enables systematic training and evaluation of models on both canonical and underexplored tasks, such as scientific illustration and compositional editing.
Experimental Evaluation
Comprehensive experiments are conducted using leading models (UniWorld-V1, Harmon, OmniGen2, MagicBrush) across four standardized benchmarks: GenEval and DPG-Bench (generation), GEdit-Bench and ImgEdit-Bench (editing). The results demonstrate:
- Consistent and significant improvements across all models and benchmarks after fine-tuning on OpenGPT-4o-Image.
- Up to 18% relative improvement on editing tasks (UniWorld-V1 on ImgEdit-Bench) and 13% on generation tasks (Harmon on GenEval).
- Superior performance compared to concurrent datasets such as ShareGPT-4o-Image, with gains of 3.2% (ImgEdit-Bench), 1.7% (GEdit-Bench), 1.2% (GenEval), and 1.1% (DPG-Bench) under identical training protocols.
Qualitative analysis further confirms that models fine-tuned on OpenGPT-4o-Image exhibit enhanced instruction-following, compositionality, and semantic fidelity, particularly in complex or multi-turn scenarios.
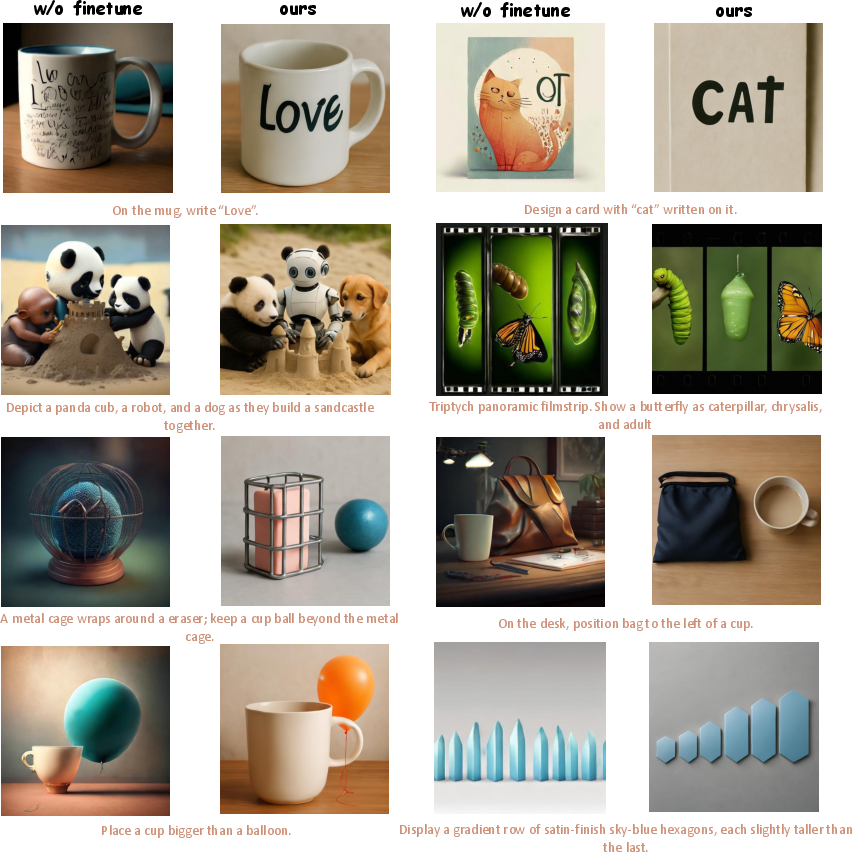
Figure 6: Qualitative comparison of Harmon before and after fine-tuning on OpenGPT-4o-Image, demonstrating improved compositionality and instruction adherence.
Implementation and Practical Considerations
The automated pipeline is designed for scalability and reproducibility. Key implementation details include:
- Template-based prompt generation with resource pools for objects, actions, and qualifiers, enabling systematic coverage and controlled diversity.
- Difficulty calibration within each subtask to ensure a spectrum of challenge levels, targeting both current model limitations and future research needs.
- Quality control via hierarchical categorization and proactive curation, rather than post-hoc filtering, to maximize semantic correctness and instruction fidelity.
- Integration with GPT-4o for both instruction and image generation, ensuring high visual and semantic quality, but with the caveat that model-specific biases may be introduced.
Resource requirements are moderate: the dataset is constructed with 80k samples, and fine-tuning experiments demonstrate that even subsets (e.g., 40k) yield strong performance gains. The pipeline is compatible with both diffusion-based and autoregressive architectures.
Limitations and Future Directions
While OpenGPT-4o-Image represents a substantial advance in dataset design for multimodal models, several limitations remain:
- Dependence on GPT-4o for data generation may propagate its biases and failure modes into downstream models.
- Benchmark-driven evaluation may not fully capture the diversity and unpredictability of real-world user scenarios.
- Unified vs. task-specific training: Experiments reveal trade-offs between unified and separate fine-tuning for generation and editing, suggesting potential task interference and the need for tailored optimization strategies.
Future work should explore human-in-the-loop data curation, expansion to additional modalities (e.g., video, 3D), and the development of new benchmarks that better reflect real-world application demands.
Conclusion
OpenGPT-4o-Image establishes a new standard for systematic, capability-driven dataset construction in multimodal AI. By combining a hierarchical taxonomy, automated scalable pipelines, and comprehensive coverage of both fundamental and advanced tasks, it enables robust training and evaluation of unified models for image generation and editing. The demonstrated performance gains across diverse architectures and benchmarks underscore the critical role of structured data in advancing the field. The dataset and methodology provide a foundation for future research on compositionality, instruction following, and domain-specific visual reasoning in multimodal systems.