Pico-Banana-400K: A Large-Scale Dataset for Text-Guided Image Editing
Abstract: Recent advances in multimodal models have demonstrated remarkable text-guided image editing capabilities, with systems like GPT-4o and Nano-Banana setting new benchmarks. However, the research community's progress remains constrained by the absence of large-scale, high-quality, and openly accessible datasets built from real images. We introduce Pico-Banana-400K, a comprehensive 400K-image dataset for instruction-based image editing. Our dataset is constructed by leveraging Nano-Banana to generate diverse edit pairs from real photographs in the OpenImages collection. What distinguishes Pico-Banana-400K from previous synthetic datasets is our systematic approach to quality and diversity. We employ a fine-grained image editing taxonomy to ensure comprehensive coverage of edit types while maintaining precise content preservation and instruction faithfulness through MLLM-based quality scoring and careful curation. Beyond single turn editing, Pico-Banana-400K enables research into complex editing scenarios. The dataset includes three specialized subsets: (1) a 72K-example multi-turn collection for studying sequential editing, reasoning, and planning across consecutive modifications; (2) a 56K-example preference subset for alignment research and reward model training; and (3) paired long-short editing instructions for developing instruction rewriting and summarization capabilities. By providing this large-scale, high-quality, and task-rich resource, Pico-Banana-400K establishes a robust foundation for training and benchmarking the next generation of text-guided image editing models.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Pico-Banana-400K: A big, high-quality dataset for teaching AI to edit images with words
Overview
This paper introduces Pico-Banana-400K, a huge collection of about 400,000 examples that teach AI how to edit real photos using simple text instructions. Think of it like a giant practice workbook for an AI photo editor: each example shows a real picture, a written instruction (like “make the sky look like sunset” or “add a hat to the cat”), and the edited result. The goal is to help researchers build better, safer, and more accurate image-editing AIs.
Key objectives and questions
The authors set out to:
- Build a large, shareable dataset from real photos (not just AI-generated images).
- Cover many different kinds of edits (colors, adding/removing objects, styles, text changes, people edits, zooming, and expanding the scene).
- Make sure the edits are high quality and truly follow the instructions.
- Support different research tasks: single edits, multi-step edits, and “which edit is better?” preference training.
In simple terms, they ask: Can we create a big, trustworthy set of before-and-after examples that helps AI follow editing instructions well? What kinds of edits are easy or hard for current models? And how can we automatically check quality without needing a human for every image?
How they built the dataset (methods)
The team used a step-by-step pipeline, like an assembly line:
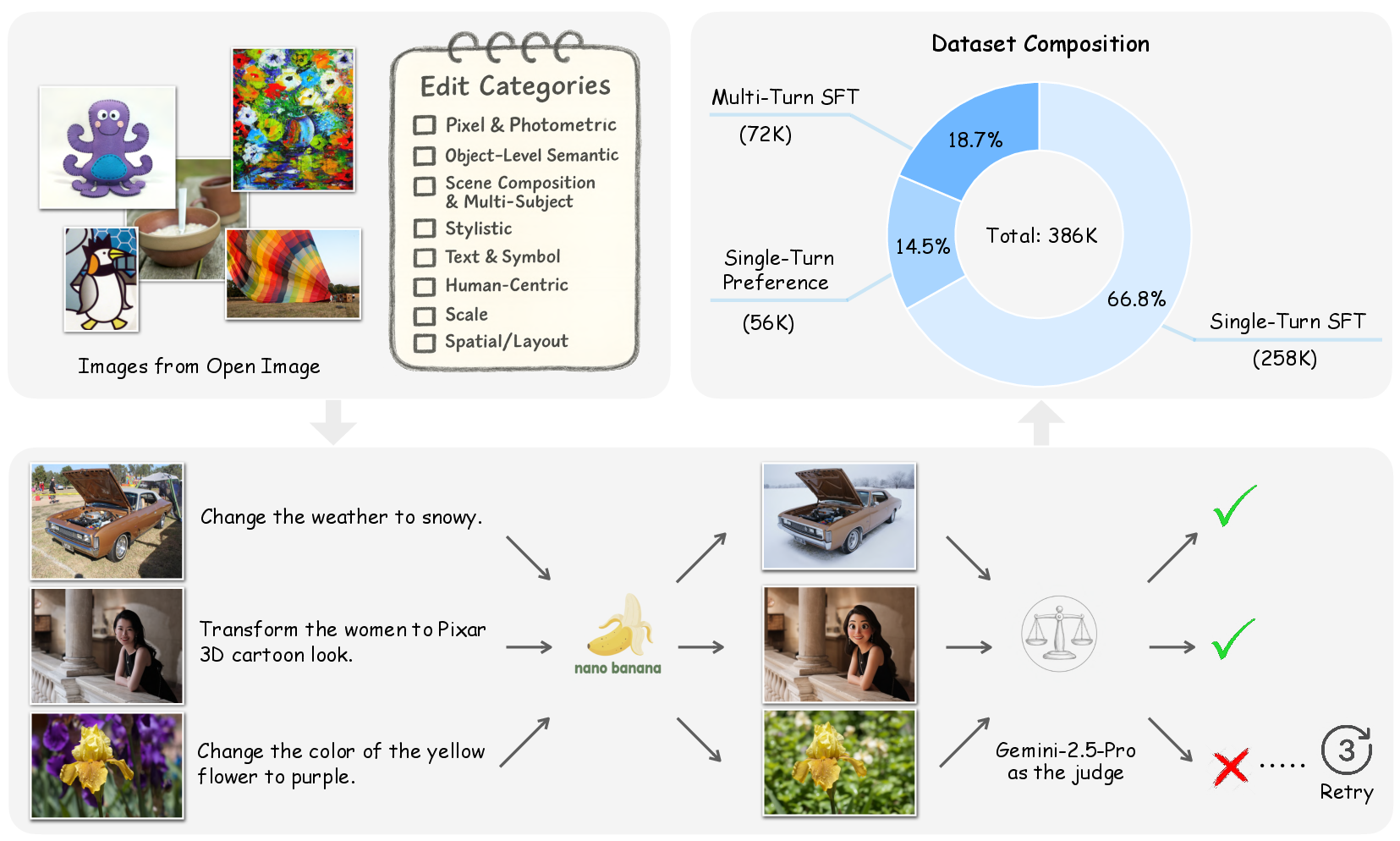
- Start with real photos from OpenImages, a public collection.
- Organize edits into a “taxonomy,” which is a careful list of 35 edit types grouped by category. For example: change overall color tone, add/remove an object, replace a background, switch seasons, apply an art style, edit text on signs, adjust a person’s expression, zoom in, or extend the edges of a photo.
- Create two versions of instructions for each edit:
- Long, detailed instructions that are extra clear for training.
- Short, user-style instructions that sound like how people normally talk.
- Use an editing model (called Nano-Banana) to carry out the instructions on the image.
- Use another model (Gemini) as an “automatic judge” to score the result on four things:
- Instruction compliance: did it follow the request?
- Seamlessness: does the edit look natural, without weird artifacts?
- Preservation balance: did it keep the parts that shouldn’t change?
- Technical quality: is the image sharp, well-lit, and properly colored?
- If the edit fails, automatically try again. Keep both the good result and the failed one for “preference” training, where models learn which output is better.
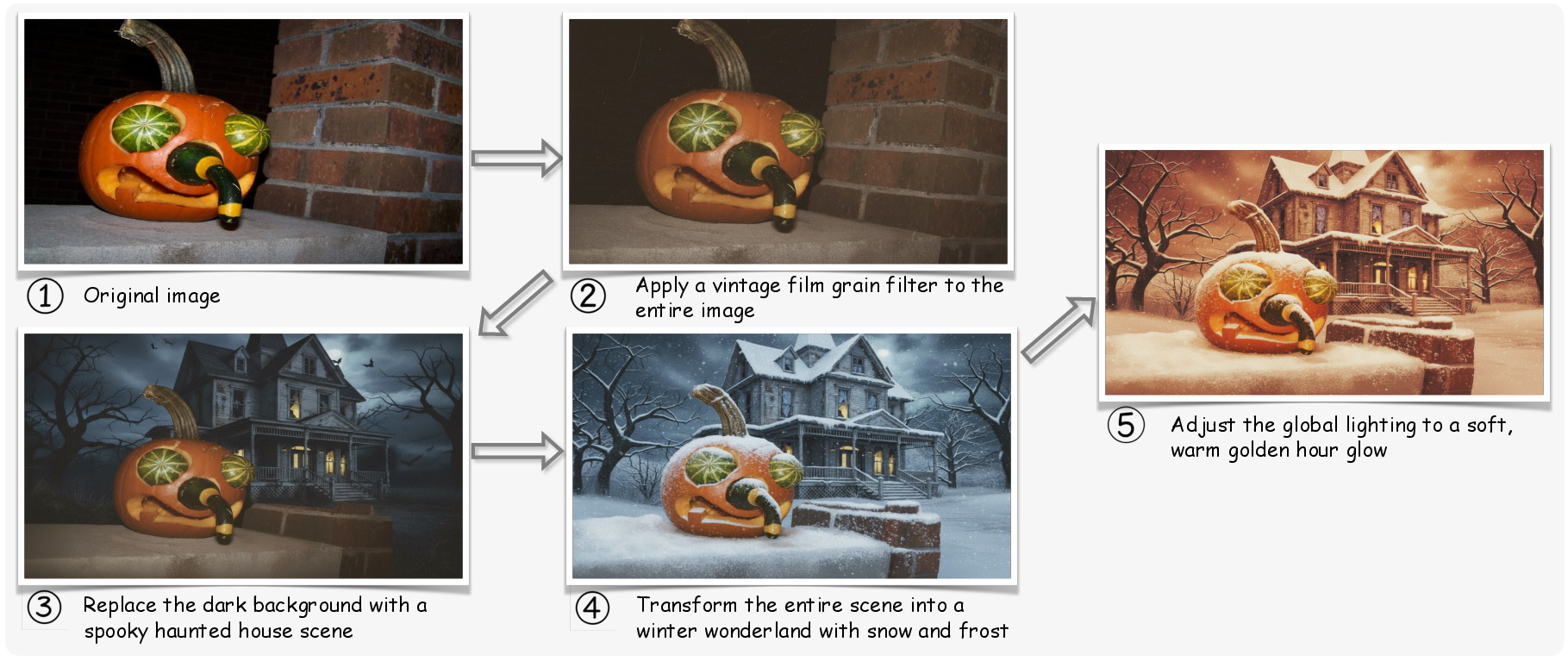
- Build multi-turn sequences (2–5 step edit chains) to study how models handle a series of related changes, like first adding a hat, then changing its color, then adjusting the lighting.
Think of the “judge” like a fair teacher grading homework. If the edit scores high enough, it’s kept in the dataset; if not, it’s marked as a failure and saved for training models to prefer better edits.
Main findings and why they matter
The dataset reveals which edits current AI models do well and which they struggle with:
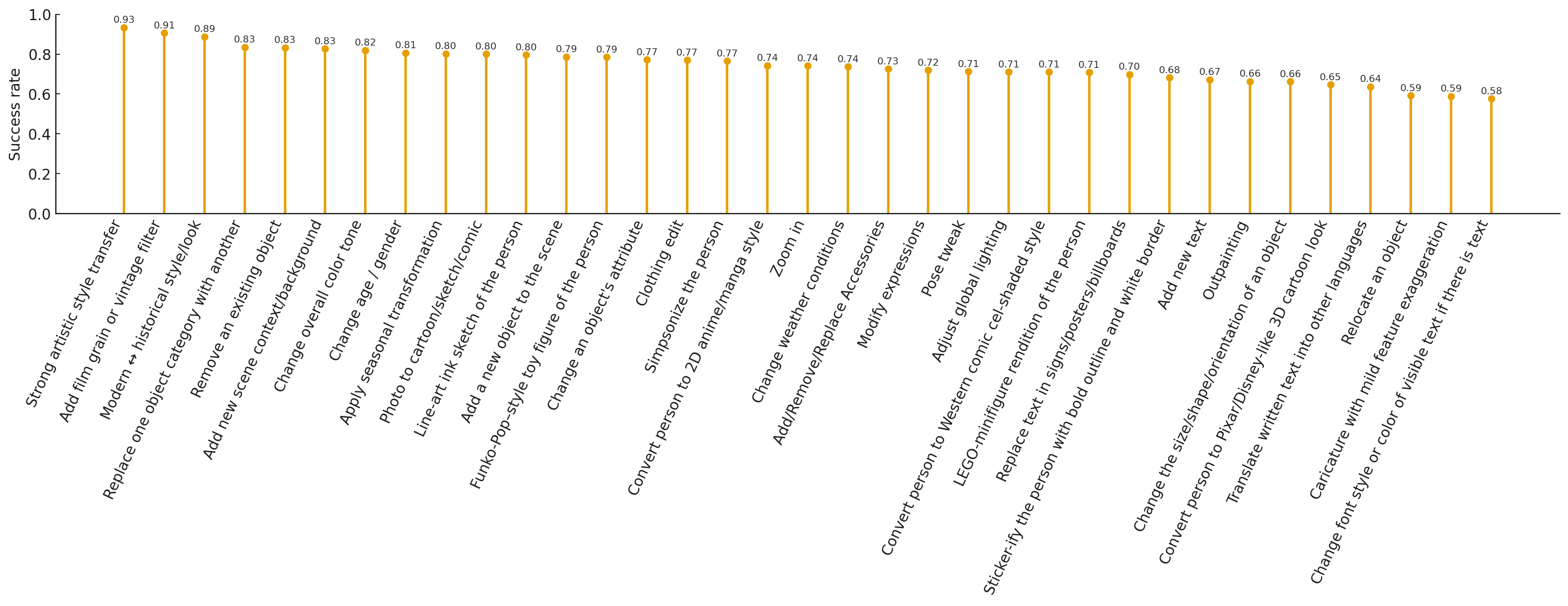
- Easier edits: Big, global changes and style effects. For example, making an image look vintage, switching the overall color tone, or transforming the photo into an artist’s style. These succeed often (around 0.9 success rate for some).
- Medium difficulty: Object-level changes and scene tweaks. Removing or replacing an object or changing the season and weather usually work fairly well, but can sometimes affect nearby areas or drift slightly in color or texture.
- Hard edits: Precise geometry and text. Moving an object to a specific spot, changing its size or angle perfectly, or editing the exact font on a sign is tough. Text edits are especially brittle because letters must look clean, aligned, and readable in a realistic photo.
These insights matter because they point researchers toward the biggest challenges: fine spatial control, accurate layout changes, and clean text rendering. The dataset gives them the training material and the measurements to make progress on these tricky areas.
What this means for the future
Pico-Banana-400K is a strong foundation for building the next generation of text-guided image editors. It can help:
- Train models to follow instructions more faithfully and avoid breaking parts of the image that shouldn’t change.
- Align models using preference pairs (good vs. bad edits), so they learn what great edits look like.
- Teach models to plan multi-step edits and keep track of context across several changes.
- Bridge the gap between detailed training prompts and natural, human-style requests through its long and short instruction versions.
In the long run, this can lead to smarter, more reliable photo-editing tools that artists, students, and everyday users can trust—tools that make realistic changes, respect the original content, and understand what people want when they describe edits in plain language. The authors plan to use the dataset for model training and benchmarking, and they share it publicly to support open research and faster progress for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what the paper leaves missing, uncertain, or unexplored.
- Reliance on proprietary models: The dataset generation (Nano-Banana), instruction authoring (Gemini-2.5-Flash/Pro), and automated judging (Gemini-2.5-Pro) depend on closed systems, leaving reproducibility with open-source tooling and the influence of vendor-specific biases unaddressed.
- Judge validity and calibration: No human ground-truth evaluation is reported to validate the automated judge’s scores or weights (40/25/20/15), nor any inter-rater agreement, calibration curves, or per–edit-type reliability analyses.
- Threshold sensitivity: The 0.7 quality cutoff is “empirically set,” but the paper does not examine how varying this threshold affects dataset composition, success rates, or downstream model performance.
- Human evaluation gap: There is no human-verified benchmark or audit (single- and multi-turn) to quantify instruction compliance, artifact types, preservation balance, typography fidelity, or identity preservation relative to the automated judge.
- Annotation richness: The dataset lacks spatial supervision (masks, bounding boxes, keypoints, click points/scribbles) and does not include region-level annotations for where edits occurred, limiting training of localization-aware editing models.
- Text edit ground truth: For text-related operations, there is no OCR transcript before/after, font metadata, bounding boxes, alignment/kerning metrics, or typography-specific labels to evaluate symbolic fidelity rigorously.
- Identity preservation signals: Human-centric edits have no identity-level annotations (face embeddings, landmarks, attributes) to measure identity drift or shading/geometry artifacts quantitatively.
- Multi-turn realism: Multi-turn sequences are created by randomly sampling additional edit types; the paper does not verify whether these sessions reflect real user workflows or measure discourse coherence/coreference resolution with human raters.
- Instruction diversity: Instructions appear to be English-only and are largely model-generated/summarized; there is no exploration of multilingual, noisy, ambiguous, or colloquial user prompts and their impact on training.
- Long vs short instructions: No ablations or training studies demonstrate how long (Gemini-authored) versus short (Qwen-summarized) instructions affect controllability, fidelity, generalization, or robustness.
- Preference data granularity: Preference pairs are binary (success vs failure) and sourced from retry attempts; there is no graded/ranked preference spectrum, taxonomy of failure types, or diversification beyond “failed until success,” which may bias negative samples.
- Per-criterion judge outputs: It is unclear whether per-criterion judge scores (instruction compliance, seamlessness, preservation, technical quality) are released; without them, reward modeling and error analysis are constrained.
- Dataset balance: The taxonomy is imbalanced across edit types (some with far fewer examples), but the effects of imbalance on training, generalization, and fairness are not studied.
- Hard-case retention: Examples that fail all three retries are discarded, potentially underrepresenting the hardest edits; the impact of excluding these cases on model robustness remains unknown.
- Domain coverage: Images are from OpenImages; generalization to other domains (e.g., medical, satellite, UI/screens, diagrams) and out-of-distribution settings is not evaluated.
- Safety and ethics: Human-centric edits (age/gender changes, caricatures, stylizations) raise questions about consent, identity misuse, demographic bias, and societal harms; the dataset lacks safety annotations, usage guidelines, or fairness audits.
- Typography challenges: The paper notes low success for typography edits but provides no specialized supervision (vector text overlays, font libraries, layout constraints) or benchmarks to address symbolic correctness.
- Spatial/layout conditioning: Difficult spatial operations (relocation, size/shape/orientation changes, outpainting) lack auxiliary conditioning signals (e.g., reference points, masks, depth/geometry priors); feasibility of adding such signals is not explored.
- Compositional single-turn edits: Each single-turn example is assigned one primary edit type; complex multi-constraint single-turn instructions (common in real use) are not represented or annotated.
- Artifact taxonomy: There is no systematic taxonomy or statistics of common artifacts (perspective breaks, boundary discontinuities, texture drift, color shifts) by edit type and content domain.
- Benchmarking baselines: The paper does not provide baseline models trained on Pico-Banana-400K or standardized evaluation suites to quantify gains over prior datasets on key axes (spatial accuracy, text fidelity, identity preservation).
- Versioning and provenance: Model versions, prompts, seeds, and configuration details (for Nano-Banana, Gemini variants) are not exhaustively documented, hindering precise replication and longitudinal comparisons.
- Resolution and canvas metadata: Image resolution/aspect changes (especially for zoom and outpainting) are not documented; lack of per-turn dimension metadata limits analysis of boundary continuity and scaling artifacts.
- Multi-turn state annotations: There are no intermediate state-change annotations (e.g., which regions were modified per turn, dependency graphs), making it hard to study planning, coreference, and cumulative error.
- Impact on training dynamics: The dataset’s effects on training stability, sample efficiency, scaling laws, and compute cost trade-offs are not empirically assessed.
- Comparative quality: Although related datasets are listed, there is no quantitative side-by-side evaluation (human or automated) comparing Pico-Banana-400K’s instruction faithfulness, artifact rates, or diversity against alternatives.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging Pico-Banana-400K’s openly released data, taxonomy, dual-instruction format, preference pairs, and multi-turn sequences. They are most feasible for edit types with higher success rates (global style and scene-level edits), while more spatially precise operations should include safeguards and QA.
- Bold: Instruction-to-Edit Fine-Tuning for Creative Tools (Software, Media/Entertainment, Advertising/Marketing)
- Use Pico-Banana-400K’s 258K single-turn triplets to fine-tune diffusion or MLLM-based edit models for natural-language photo editing (e.g., “warm the tone,” “replace background,” “apply vintage style”).
- Product/workflow: “Edit-by-Instruction” SDK for Photoshop/Figma/GIMP plugins and mobile camera apps; preset packs built from the dataset’s stylistic categories; batch background replacement pipelines for agencies.
- Assumptions/dependencies: Access to compute for SFT; model architecture supporting (instruction, before, after) triplets; handle license terms of OpenImages; adopt guardrails for human-centric edits.
- Bold: Automated Quality Gate for Generative Editing (Software Ops/ML Platform)
- Operationalize the paper’s multi-criteria judge (instruction compliance, seamlessness, preservation, technical quality) as a production QC step for edits before publishing.
- Product/workflow: “Edit Quality Gate” microservice scoring outputs; continuous monitoring dashboards; triage failed cases into retrial or human review queues.
- Assumptions/dependencies: Re-implement judge prompt or substitute with internal image quality model; threshold tuning by use case; maintain audit logs for compliance.
- Bold: Preference Alignment via DPO and Reward Modeling (Software/Research)
- Train edit reward models and run DPO using the 56K success–failure pairs to improve instruction-following and robustness of editing models.
- Product/workflow: “EditReward” tuning pipeline; auto-retry loop driven by reward score; preference-based online learning to reduce artifact rates.
- Assumptions/dependencies: Stable DPO/GRPO training stack; careful curation for human-centric and typography edits; avoid reward hacking by mixing metrics and human checks.
- Bold: Multi-Turn Edit Planning and Iterative Refinement (Software, Creative Agencies)
- Use the 72K multi-turn sequences (2–5 steps) to train/edit co-pilots that maintain context and coreference over consecutive modifications (e.g., “add a hat,” then “make it red,” then “swap background”).
- Product/workflow: “Edit Planner” assistants embedded in creative suites; session-aware editing for client feedback cycles; scripted multi-step campaigns (e.g., seasonal variants).
- Assumptions/dependencies: Track history state and referential language; ensure edit accumulation doesn’t degrade technical quality; add undo/versioning.
- Bold: E-Commerce Catalog Retouch and Variant Generation (Retail/E-Commerce)
- Automate background replacement, lighting normalization, stylistic harmonization across product photos; create seasonal variants (summer/winter) for campaign planning.
- Product/workflow: Marketplace seller tools for consistent storefront imagery; platform-side batch retouch service; automated aspect-ratio adaptation via outpainting.
- Assumptions/dependencies: Higher reliability for global edits; additional QA for object-level edits (relocation, resizing); ensure policy compliance for brand colors and logos.
- Bold: Rapid Creative Prototyping and A/B Testing (Advertising/Marketing)
- Generate multiple ad creatives by varying style, background, and lighting; test engagement before full production.
- Product/workflow: “Creative A/B Engine” that enumerates edit types; integrate click-through analytics to select winning variants.
- Assumptions/dependencies: Measurement stack; rights clearance; preserve product integrity (avoid deceptive edits).
- Bold: Social and Avatar Stylization (Social Media, Gaming)
- Deploy identity-preserving but fun stylizations (anime, Simpsonize, LEGO, Pixar-like) for profile pictures or in-game avatars.
- Product/workflow: “Stylize Me” features in social apps; opt-in avatar pipelines; moderation for sensitive attributes (age/gender edits).
- Assumptions/dependencies: Address identity drift and shading artifacts noted in paper; robust consent and safety layers; avoid misuse (deepfake risks).
- Bold: Localization Mockups for Visual Text (Localization/Publishing)
- Use text edit types to prototype sign/billboard replacements and quick translations for visual assets.
- Product/workflow: “Visual Localization Preview” tool for publishers; pre-flight checks before design handoff.
- Assumptions/dependencies: Lower success rates for typography; augment with OCR-informed losses or dedicated text rendering to reach production quality.
- Bold: Education and Curriculum Assets (Academia/Education)
- Teach multimodal instruction-following, preference learning, and multi-turn editing; demonstrate the gap between long vs. short instructions with the dataset’s dual prompts.
- Product/workflow: Course labs on SFT, DPO, and judge-based evaluation; reproducible benchmarks for compositional edits.
- Assumptions/dependencies: GPU access; clear data usage policies; simplified subsets for coursework.
- Bold: Benchmarking and Model Validation (Academia/ML Evaluation)
- Standardize edit taxonomy coverage and per-type success tracking; compare models on single-turn and multi-turn scenarios using consistent QC criteria.
- Product/workflow: Public leaderboards for instruction-faithfulness and preservation; per-category breakdowns to guide research.
- Assumptions/dependencies: Agreement on evaluation protocol; transparent reporting of failure cases; discourage cherry-picking.
- Bold: Content Pipeline Governance Templates (Policy/Responsible AI)
- Adopt the paper’s structured judge criteria as a template for internal review guidelines; require audit trails for human-centric edits and identity changes.
- Product/workflow: “Generative Editing Governance” SOPs; red-team checklists for typography, face edits, and compositing.
- Assumptions/dependencies: Policy buy-in; enforcement mechanisms; escalation paths for sensitive content.
Long-Term Applications
These applications require advances in fine-grained spatial control, typography, identity preservation, scaling, or new tooling, building on the dataset’s multi-turn structure, preference data, and taxonomy.
- Bold: High-Precision Object Layout Editing (Software, Creative Production)
- Robust relocation, size/shape/orientation changes with correct perspective and geometry (currently lower success rates).
- Product/workflow: Region-aware instruction editors using masks, pointers, or bounding boxes; attention steering and geometry-aware objectives.
- Assumptions/dependencies: Spatial conditioning interfaces; improved training losses; reliable depth/pose estimation.
- Bold: Production-Grade Typography and Text-in-Image Editing (Publishing, Localization, Advertising)
- Accurate font, kerning, alignment, contrast, and language translation in real scenes.
- Product/workflow: “TypoEdit Pro” powered by OCR-informed losses and explicit text rendering; WYSIWYG overlays for enterprise teams.
- Assumptions/dependencies: OCR integration; font libraries; photometric consistency modeling; human-in-the-loop QC.
- Bold: Real-Time Video Editing by Instruction (Media/Entertainment)
- Extend multi-turn image editing to video sequences for stylistic changes, background swaps, and scene lighting adjustments while preserving temporal coherence.
- Product/workflow: “Edit-by-Voice” for video; scene-aware planners that keep continuity across frames.
- Assumptions/dependencies: Temporal consistency modules; compute-efficient pipelines; rights and disclosure practices.
- Bold: Personalization-Aware Edit Reward Models (Software, CX/Marketing)
- Reward models tuned to brand or user preferences, enabling adaptive editing co-pilots.
- Product/workflow: Preference learning from user feedback logs; brand style memory for consistent outputs.
- Assumptions/dependencies: Preference data collection (privacy-safe); continuous learning infrastructure; mitigation of bias.
- Bold: End-to-End Creative Co-Pilots with Planning and Revision (Software, Agencies)
- Agents that propose, plan, and revise multi-step edits, track client feedback, and produce deliverables automatically.
- Product/workflow: “Art Director Assistant” that drafts edit sequences, rationales, and alternatives; integrates with DAM/PM tools.
- Assumptions/dependencies: Reliable coreference handling; version control; content provenance and approvals.
- Bold: Synthetic Data Factories Using the Pipeline Pattern (Multiple Sectors)
- Replicate the paper’s generate–judge–retry pipeline to build domain-specific edit datasets (e.g., retail, real estate, automotive), improving instruction-following for sector-specific images.
- Product/workflow: Verticalized data generation services; automated retries and curated negatives for preference learning.
- Assumptions/dependencies: Access to domain image corpora; licensing; tailored judge criteria; sector expertise for curation.
- Bold: On-Device Editing Models (Mobile/Edge Computing)
- Compress and distill instruction-following models for local, privacy-preserving photo edits.
- Product/workflow: “On-device Edit” features in camera/gallery apps; offline stylization packs.
- Assumptions/dependencies: Efficient architectures; hardware acceleration; model size vs. quality trade-offs.
- Bold: Content Authenticity, Watermarking, and Provenance Standards (Policy/Standards)
- Use the dataset to stress-test detection and provenance systems for edited content; define standards for disclosure of multi-step edits.
- Product/workflow: “Edit Provenance Ledger” capturing edit chains; watermark protocols compatible with multi-turn transforms.
- Assumptions/dependencies: Cross-industry standards; robust watermark resilience; consumer-readable disclosures.
- Bold: Safety Frameworks for Human-Centric Edits (Policy, Social Platforms)
- Develop safeguards for identity changes, age/gender edits, and stylizations to prevent misuse (e.g., deepfakes).
- Product/workflow: Consent checks, sensitive attribute policies, detection of manipulations; restricted modes for minors.
- Assumptions/dependencies: Accurate face/identity preservation metrics; legal guidance; platform enforcement.
- Bold: Cross-Modal Editing with Region-Referential Interfaces (Software/UI)
- Combine language with pointing, sketching, or bounding box selection to drive precise edits.
- Product/workflow: “Hybrid Prompting UI” where users click regions and describe edits; improves challenging edit types identified in the paper.
- Assumptions/dependencies: UI instrumentation; training on multimodal prompts; handling ambiguity resolution.
- Bold: Enterprise Content Pipelines with Automated QA and Compliance (Enterprise IT, Retail, Publishing)
- Integrate judge-based scoring, preference-aligned models, and audit logs into end-to-end content production systems.
- Product/workflow: “Generative Content Factory” with edit gates, policy checks, and automated escalation to human review.
- Assumptions/dependencies: MLOps maturity; governance alignment; scalable retraining and rollback.
- Bold: Research Directions: Geometry- and Identity-Aware Objectives (Academia/Research)
- Explore losses and constraints to fix perspective inconsistencies, topology breaks, and identity drift in human-centric stylizations.
- Product/workflow: Benchmarks for geometry/identity fidelity; public shared tasks using Pico-Banana’s multi-turn chains and preference data.
- Assumptions/dependencies: New annotations (e.g., masks, depth, identity features); community consensus on metrics; compute for experimentation.
Glossary
- attention manipulation: Adjusting internal attention maps of a generative model to influence which parts of an image are emphasized during editing. "attention manipulation, or cross-attention control"
- attention steering: Guiding a model’s attention mechanism toward specific spatial regions or features to improve control over edits. "region-referential prompting or attention steering"
- automatic judge: An automated evaluation component that scores the quality and faithfulness of generated edits. "Gemini-2.5-Pro serves as an automatic judge that evaluates the edit quality"
- compositionality: The ability to combine multiple edit operations coherently within a single workflow or sequence. "exercises both compositionality (multiple edit types) and pragmatic reference"
- coreference: Linking expressions (e.g., pronouns) to the correct previously mentioned entities across editing turns. "pragmatic reference (coreference across turns)"
- cross-attention control: Manipulating cross-attention layers to align text tokens with image regions for targeted edits. "attention manipulation, or cross-attention control"
- diffusion-based: Refers to generative/editing models built on diffusion processes that iteratively denoise images. "diffusion-based visual editing models"
- Direct Preference Optimization (DPO): A training method that aligns models using pairwise preference data without explicit reward modeling. "methods like DPO~\citep{rafailov2024directpreferenceoptimizationlanguage}"
- domain shifts: Differences in data distributions between training and evaluation that can degrade model performance. "these datasets frequently exhibit domain shifts"
- edit taxonomy: A structured categorization of edit types used to organize and cover the space of editing operations. "organized by our comprehensive edit taxonomy (top left)"
- finetuning-based methods: Approaches that adapt models to tasks by additional supervised training on instruction-edit pairs. "In contrast, finetuning-based methods achieve more precise instruction-following through supervised learning."
- identity drift: Unintended changes to a subject’s identity characteristics during stylization or editing. "exhibit identity drift and shading artifacts"
- identity-preserving constraints: Techniques or objectives intended to maintain a subject’s identity across edits. "identity-preserving constraints for human-centric stylization."
- in-context demonstrations: Example prompts included in the system prompt to guide models to produce desired instruction styles. "in-context demonstrations within the system prompt for Qwen2.5-7B-Instruct"
- Instruction Compliance: Degree to which an edited image follows the given instruction. "Instruction Compliance (40%)"
- instruction faithfulness: How closely an edit adheres to the specified instruction without adding or omitting requested changes. "instruction faithfulness through MLLM-based quality scoring"
- instruction-following: A model’s capability to perform edits exactly as described in natural language. "more precise instruction-following through supervised learning."
- layout extrapolation: Extending or plausibly filling out image layouts beyond original boundaries or with new structure. "fine spatial control, layout extrapolation, or symbolic fidelity remain challenging."
- MLLM (Multimodal LLM): A LLM that processes and reasons over both text and images. "multimodal LLMs (MLLMs)"
- multi-dimensional scoring: Evaluation across multiple axes (e.g., compliance, quality, preservation, technical aspects) for robust quality control. "quality assurance through multi-dimensional scoring (instruction compliance, editing quality, preservation balance, and technical quality)"
- multi-turn: Editing scenarios involving sequences of consecutive instructions applied to the same image. "a 72K-example multi-turn collection"
- negative examples: Failed or suboptimal edits retained to train alignment or preference-based methods. "Failure cases (56K) are retained as negative examples paired with successful edits for preference learning."
- OCR-informed losses: Training losses that use optical character recognition signals to improve text rendering/editing in images. "OCR-informed losses"
- outpainting: Extending an image beyond its original borders while maintaining plausible content and style. "Outpainting (extend canvas beyond boundaries)"
- pragmatic reference: Referring to prior edits or context in natural language instructions to maintain discourse continuity. "exercises both compositionality (multiple edit types) and pragmatic reference"
- preference learning: Learning from pairwise comparisons of outputs (success vs. failure) to align a model with human preferences. "retained as negative examples paired with successful edits for preference learning."
- preference triplets: Data tuples containing the original input, a successful edit, and a failed edit for alignment training. "a 56K subset of preference triplets pairing successful and failed edits"
- Preservation Balance: Ensuring unchanged regions remain consistent after editing. "Preservation Balance (20%)"
- region-referential prompting: Instructions that specify particular regions or objects to focus editing operations. "region-referential prompting"
- reward modeling: Building a learned scoring function that predicts human preferences to guide model training. "and reward modeling~\citep{wu2025editrewardhumanalignedrewardmodel}"
- Seamlessness: The visual naturalness and artifact-free integration of edits within the original image. "Seamlessness (25%)"
- semantic fidelity: Maintaining accurate semantics (objects, attributes, relationships) after editing. "high semantic fidelity and visual realism"
- spatial conditioning: Conditioning the model on spatial cues to better localize and control edits. "stronger spatial conditioning (e.g., region-referential prompting or attention steering)"
- SFT (Supervised Fine-Tuning): Training a model on paired instruction and edited outputs to improve instruction-following. "single-turn SFT (66.8%)"
- Technical Quality: Image-level attributes such as sharpness, color accuracy, and exposure fidelity. "Technical Quality (15%)"
- typography: The visual form and arrangement of text in images, including font, alignment, and legibility. "and typography remain open problems."
Collections
Sign up for free to add this paper to one or more collections.