SkillsInjector: Dynamic Skill Context Construction for LLM Agents
Abstract: LLM agents now draw on growing skill libraries to handle complex tasks. However, injecting more skills does not always improve task completion and can even degrade it. Existing methods still treat skill injection as a static step, selecting skills with fixed criteria, fixing the budget in advance, and leaving descriptions unchanged. We argue that this static treatment can undermine the utility of skills, because which skills are exposed, how many are included, and how they are presented all affect downstream performance. We propose SkillsInjector, a two-stage adaptive method that jointly addresses these decisions. First, a context planner learns execution-grounded skill preferences and admits an adaptive number of skills for each task. A set-aware renderer then tailors how selected descriptions are presented relative to their co-injected neighbors. Across tau2-bench, SkillsBench, and ALFWorld, SkillsInjector achieves the highest score, improving over the strongest baseline by 3.9, 6.1, and 7.3 percentage points, respectively. Ablation studies show that skill selection, adaptive budgeting, and set-aware rendering each contribute to the gain. These results show that skill-augmented agents benefit from optimizing the injected context itself. Code will be released upon publication
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI assistants (powered by LLMs) to use the right “skills” at the right time. Think of an AI’s skills like tools in a toolbox: search, summarize, check a policy, run a small program, and so on. Many people assume that giving the AI more tools always helps. The authors show that’s not true—too many tools can confuse the AI and make it perform worse. Their solution, called SkillsInjector, helps the AI pick a small, smart set of tools for each task and explains those tools clearly so the AI uses them well.
What questions were the researchers trying to answer?
The paper asks three simple questions:
- Which skills should an AI see for a specific task?
- How many skills should it see (not always the same number)?
- How should those skills be presented so they don’t overlap or confuse the AI?
In short, instead of dumping a big list of tools on the AI, the authors want to carefully choose, size, and describe the toolset for each task.
How did they do it?
The authors built a two-part system that behaves a bit like a good coach packing a backpack for a player before a game:
- The “coach” (Context Planner) picks which tools to bring and how many.
- The “labeler” (Set-Aware Renderer) rewrites the tool descriptions so each tool’s role is crystal clear next to the others.
Here’s how each part works, in everyday language:
- Context Planner (picking the right tools and number)
- Analogy: You’re packing for a trip. If you bring everything, your bag is heavy and messy. If you bring too little, you’re unprepared. You need a smart list.
- What it does: The planner looks at how well each skill actually helped on similar tasks in the past (not just how “related” it sounds). It learns a preference for useful skills and uses a flexible cutoff so different tasks can have different numbers of skills. Some tasks might need only 1–2 skills; others might need more.
- Set-Aware Renderer (making tool labels easy to use)
- Analogy: If two tools are both labeled “fix stuff,” you might pick the wrong one. Better labels say “tighten screws” vs. “hammer nails.”
- What it does: After the planner selects the set of skills, the renderer rewrites each skill’s description so it’s clear what it does and how it’s different from the others in the same set. This reduces overlap and prevents the AI from mixing up similar skills.
How they trained it:
- The planner “learns from experience”: it sees which skills helped complete tasks and which hurt, then learns to score future skills accordingly.
- The renderer is trained using a bigger, stronger “teacher” model that shows good examples of clean, non-overlapping descriptions. The authors then distill this into a smaller, faster “student” model so it’s inexpensive to run during real use.
How they tested it:
- They evaluated on three different benchmarks:
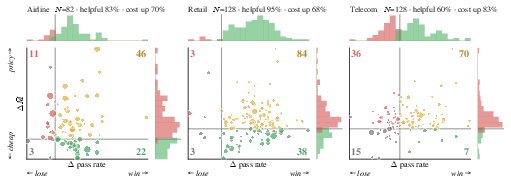
- tau2-bench (customer service tasks like airlines, retail, and telecom),
- SkillsBench (varied, human-curated skills),
- ALFWorld (text-based tasks in a virtual home).
- They kept the main AI the same for all methods and only changed how the skills were chosen and shown. This isolates the effect of their approach.
What did they find, and why is it important?
Main results:
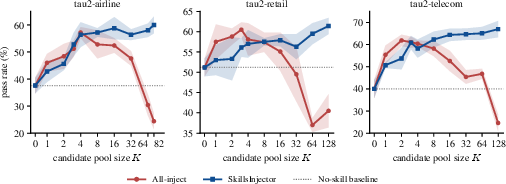
- SkillsInjector beat all other methods on all three benchmarks. On average, it improved task success by about 3.9 to 7.3 percentage points over the strongest baseline, depending on the benchmark.
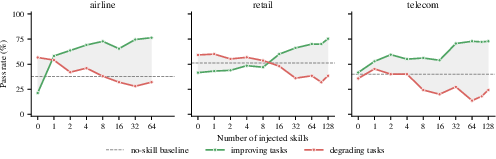
- When the pool of possible skills got bigger, the “just inject everything” strategy got worse, but SkillsInjector stayed strong. This shows that more is not always better.
- Each part of SkillsInjector mattered:
- The planner (skill selection) gave the biggest boost.
- Adaptive budgeting (letting the number of skills vary by task) prevented overload.
- The renderer (rewriting descriptions with awareness of the other skills) reduced confusion and cut down on extra back-and-forth messages the AI needed to solve tasks.
Why this matters:
- Many skills look relevant but can actually distract the AI or make it slower.
- Different tasks need different numbers of skills—there is no one-size-fits-all.
- Clear, non-overlapping descriptions help the AI choose the right skill at the right time.
What’s the bigger picture?
This research suggests that success with AI assistants isn’t just about building more skills—it's about crafting the “skill context” the AI sees for each task. By carefully choosing which skills to show, how many to include, and how to describe them together, we can make AI assistants more accurate, faster, and less confused.
In the future, this idea could:
- Make customer support bots more reliable by showing them only the rules and tools they truly need for each conversation.
- Help coding or household-assistant AIs pick the right functions without wading through long lists.
- Guide developers to focus not only on making new tools but also on presenting the right tools clearly at the right time.
In short, SkillsInjector is like a smart coach: it packs the right tools, in the right amount, with clear labels—so the AI can focus and perform better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Set-level utility modeling is absent: the planner learns per-skill benefits from single-skill rollouts, but does not model pairwise or higher-order interactions (synergy, redundancy, interference) among co-injected skills. Evaluate and learn combinatorial set utility (e.g., submodular models, pairwise terms, Shapley-style attribution) to inform joint selection.
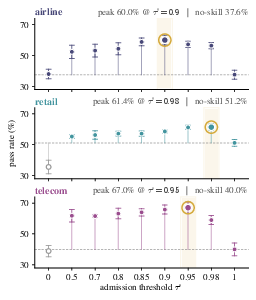
- Budgeting is tuned via a per-domain threshold, not learned per-task: the admission threshold τ* is fixed per domain and chosen on dev data. Investigate learning a per-task budget policy (predicting ) and adaptive thresholds that respond to task features, runtime constraints, and observed rollout signals.
- No explicit multi-objective optimization: the objective targets pass rate only; cost (latency, tokens, messages), stability, and risk are not jointly optimized. Formulate and test multi-objective or constrained optimization (e.g., maximize utility subject to token/latency budgets) and measure Pareto trade-offs.
- Labeling cost and scalability are unquantified: computing requires execution rollouts per skill per task. Characterize the data/compute requirements, sample efficiency, and scaling behavior for libraries with thousands of skills and new tasks; explore off-policy estimation, logged-bandit learning, or proxy signals to reduce rollout costs.
- Renderer fidelity to skill bodies is unverified: adapted descriptions may drift semantically from the underlying execution
b_i. Establish automatic checks (semantic equivalence, invocation consistency), human audits, and failure-case analyses to ensure adapted descriptions do not mislead or suppress correct tool use. - Safety and failure modes of description adaptation are not analyzed: “Do NOT call…” guards might block necessary actions or induce overcaution. Systematically measure harmful adaptations (false negatives/positives), introduce guardrails, and design safe adaptation constraints.
- Robustness to noisy, adversarial, or conflicting skill descriptions is untested: evaluate SkillsInjector on corrupted/outdated/misaligned catalogs and quantify resilience of both planner and renderer under realistic noise/adversarial perturbations.
- Mixed skill pools are not studied: each benchmark uses a single source (human-curated or LLM-generated). Test mixed pools (human + LLM + auto-evolved), cross-domain libraries, and heterogeneous quality distributions to assess generalizability.
- Cross-model transfer is unknown: the planner/renderer are trained/evaluated with Qwen backbones. Assess transfer to other LLM agents (e.g., GPT-4-class, Claude, Llama variants), including zero-shot and fine-tuned settings, to validate backbone-agnostic utility.
- Handling evolving libraries is unresolved: the library is treated as fixed at inference. Develop incremental scoring and rendering updates for newly added/retired skills (cold-start skill scoring, continual learning) without full retraining.
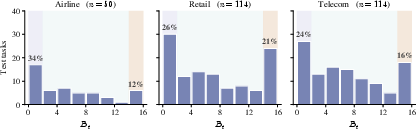
- Sensitivity to the budget cap is not characterized: the cap occasionally binds but its choice (16) and impact are not explored. Sweep caps, design token-aware caps, and study effects on tasks that require many skills.
- Injection is a single pre-invocation step: there is no mid-trajectory re-planning or re-rendering based on interaction feedback. Investigate closed-loop, online context construction (triggered updates, failure recovery) and its latency/utility trade-offs.
- Renderer bypass for single-skill cases is unexamined: set-aware adaptation is skipped when . Evaluate whether task-aware adaptation still improves single-skill performance or reduces interaction cost.
- Evaluation coverage is limited: GUI automation, open-web agents, very long-horizon embodied tasks, and other domains are acknowledged but untested. Extend benchmarking to these settings and report domain-specific behaviors.
- Statistical significance and uncertainty are not consistently reported: results show means over 5 seeds (and whiskers in one figure), but formal statistical tests and confidence intervals across all comparisons are missing. Add rigorous significance testing to support claims.
- Token-level cost is not measured: the paper reports average messages but not token counts, memory footprint, or context-window utilization. Quantify token budgets, context length, truncation effects, and memory usage to guide practical deployment.
- Planner interpretability is limited: a simple MLP over embeddings provides scores without explanation. Provide rationales or saliency for selections/rejections, and auditing tools for human oversight.
- Threshold calibration under distribution shift is untested: τ* is chosen on dev data and assumed stable. Study calibration drift across test distributions and propose auto-calibration or uncertainty-aware selection strategies.
- Baseline coverage omits some recent tool/skill selection methods: experiments do not include newer alignment approaches (e.g., PORTS), generative retrieval/calling (e.g., ToolGen), proactive retrieval frameworks (e.g., ToolOmni), or in-context skill internalization (e.g., SKILL0). Add these baselines for broader context.
- Multi-agent or hierarchical routing is not considered: assess how dynamic skill context interacts with multi-agent systems, hierarchical skills, or orchestration frameworks that route across agents/tools.
- Sample efficiency and few-shot generalization are unclear: quantify how many labeled examples are needed to train a reliable planner, measure data efficiency, and test few-shot or zero-shot generalization to new tasks/domains.
- Renderer curriculum details and biases need deeper analysis: the teacher-driven D1→D2 pipeline may embed teacher biases. Ablate curriculum schedules, explore alternative distillation (preference learning, RLHF on adaptation), and measure teacher-student divergence.
- Negative interaction rates are only qualitatively shown: quantify and categorize cases where co-injection reduces pass rate, identify root causes (semantic overlap, policy conflicts), and design filters/penalties to avoid harmful sets.
- Procedural content (
b_i) remains untouched: only descriptions are adapted. Explore safe, parameterized body-level adaptation (e.g., argument defaults, guard conditions) and measure its impact on reliability. - Privacy/compliance implications are not discussed: adapted descriptions for domains like telecom/airline may affect policy communication. Evaluate compliance, auditability, and potential leakage in adapted contexts.
- Reproducibility is pending code release: until code, data, and teacher prompts are released, replicability is limited. Provide full artifacts (skills, rollouts, renderer datasets, prompts) and ablation scripts to enable verification.
Practical Applications
Immediate Applications
Below are practical, deployable applications that leverage SkillsInjector’s dynamic skill selection, adaptive budgeting, and set‑aware rendering. Each item notes sectors, example tools/workflows, and feasibility assumptions.
- Adaptive skill middleware for customer support agents
- Sectors: customer service (airlines, retail, telecom), e-commerce, BPO/contact centers
- What it enables: a drop-in middleware that selects and renders only the most useful policy/procedure skills per ticket, reducing attention dispersion and tool misuse; expected gains mirror reported pass‑rate improvements on tau2-bench
- Potential tools/workflows: “SkillsInjector” service between the agent and the skill catalog; per-domain threshold calibrator; runtime renderer that contextualizes overlapping skills (refund vs compensation vs cancellation)
- Assumptions/dependencies: access to a stable skill library with descriptions/bodies; ability to collect dev-set rollouts or historical logs to calibrate thresholds; frozen or slowly changing agent backbone; telemetry for periodic re-calibration
- Enterprise knowledge assistants with skill-aware context construction
- Sectors: enterprise search/assistants, legal ops, HR, procurement
- What it enables: injecting a focused subset of playbooks/policies per query and rewriting descriptions to clarify boundaries (e.g., “Do NOT call X if Y is requested”)
- Potential tools/workflows: LangChain/OpenAI function-calling integrations with an adaptive planner; set-aware renderer SDK for MCP-like catalogs; observability dashboards showing per-skill utility and selected budgets
- Assumptions/dependencies: structured catalogs with stable identifiers; governance approval for runtime rewriting of descriptions; lightweight teacher model or pre-distilled renderer available
- IT operations and SRE runbook routing
- Sectors: software infrastructure, cloud/SaaS operations
- What it enables: selecting the minimal set of remediation skills per incident (restart, rollback, throttle) and rendering guardrails to prevent conflicting actions
- Potential tools/workflows: “SkillOps” pipeline to compute execution-grounded utility from incident simulations/postmortems; dynamic budget caps tied to incident severity; playback harness for A/B validation
- Assumptions/dependencies: runbook skills codified as callable tools; incident simulators or historical traces for supervision; cost/latency SLOs to set budget thresholds
- Coding assistants with curated “micro-skills”
- Sectors: software engineering, DevEx
- What it enables: per-task injection of refactoring, test-generation, API-usage, and code-modding skills; set-aware rendering to differentiate near-duplicate utilities (lint vs format vs fix‑imports)
- Potential tools/workflows: repo-level planner trained on CI logs; pre-commit hooks that log skill utility; editor plugins that display the rendered skill cheat‑sheet for the current task
- Assumptions/dependencies: availability of code-task traces (CI outcomes, lints, test diff); stable skill wrappers; guardrails to prevent destructive actions
- Compliance and policy assistants that reduce tool misuse
- Sectors: finance (KYC/AML), insurance, regulated support desks
- What it enables: rendering explicit “not‑for” scopes across overlapping compliance checks; adaptive budget keeps only high-utility checks to reduce false positives/latency
- Potential tools/workflows: compliance skill catalog with renderer-enforced exclusions; domain thresholds tied to risk tiers; audit logs of selected skills and their rendered scopes
- Assumptions/dependencies: legal review of rewritten descriptions; human-in-the-loop confirmation for high-risk actions; access control over skills
- Conversational RPA and GUI automation with fewer brittle steps
- Sectors: back-office automation, shared services
- What it enables: choosing a small, non-conflicting set of UI macros per workflow and clarifying when each macro should not be invoked
- Potential tools/workflows: planner wrapped around RPA skill libraries (e.g., UiPath/Power Automate scripts); renderer that embeds “Do NOT call” conditions tied to sibling macros
- Assumptions/dependencies: script metadata of sufficient quality; replay environment for utility estimation; versioning to handle frequent UI changes
- Cost/latency optimization for existing agent deployments
- Sectors: any production agent with tool catalogs
- What it enables: lower average message count by avoiding overloaded contexts; adaptive budgets tied to SLA budgets (latency/tokens)
- Potential tools/workflows: cost-aware τ* calibration; budget caps enforced by domain; telemetry to monitor cost-quality tradeoffs
- Assumptions/dependencies: visibility into token/latency budgets; stable cost models; monitoring to avoid under-injection on complex tasks
- Research and benchmarking plug-in for agent evaluation
- Sectors: academia, applied research labs
- What it enables: a reproducible layer to study execution-grounded skill utility, heterogeneity across tasks, and the effects of set-aware description rewriting
- Potential tools/workflows: add-on module for AgentGym/ALFWorld/SkillsBench harnesses; per-skill Δ(t,s) estimation; open-source renderer distilled from a larger teacher
- Assumptions/dependencies: access to benchmarks and logs; reproducible seeds; compute to run rollouts for label generation
- Procurement and documentation hygiene for tool catalogs
- Sectors: policy/IT governance in enterprises and government
- What it enables: immediate policy to require disambiguation clauses in tool/skill docs; renderer-generated templates to standardize scopes and exclusions
- Potential tools/workflows: catalog QA pipeline that flags overlapping skills; “description linter” that checks for role boundaries
- Assumptions/dependencies: change-management for catalog updates; buy-in from tool owners; exception process for high-risk tools
Long-Term Applications
These applications build on the paper’s methods but require further research, validation, or scaling.
- Clinical decision support with skill-aware orchestration
- Sectors: healthcare
- What it enables: dynamically injects only validated clinical pathways, calculators, and order sets; renderer clarifies contraindications and adjacent-but-inappropriate pathways
- Potential tools/workflows: EHR-integrated planner trained on simulated/retrospective cases; renderer aligned with clinical guidelines; rigorous offline validation and prospective trials
- Assumptions/dependencies: strong safety/ethics oversight; high-precision utility labels; regulatory approval; privacy-preserving data pipelines
- Embodied agents and robotics with hierarchical skills
- Sectors: robotics, logistics, manufacturing
- What it enables: selecting and disambiguating manipulation/navigation skills under tight context budgets; renderer clarifies pre/post-conditions across co-injected controllers
- Potential tools/workflows: sim-to-real curriculum to collect execution-grounded benefits; latency-aware budgeting tied to control loops; hybrid symbolic constraints in rendering
- Assumptions/dependencies: reliable simulators; real-world validation; safety envelopes; low-latency inference on edge hardware
- Open-web and long-horizon autonomous agents
- Sectors: search, travel, personal assistants
- What it enables: task-phase–aware budgets (planning vs execution vs verification) and set-aware skill reshaping across dynamic web tools
- Potential tools/workflows: online threshold adaptation driven by reward shaping; failure-aware renderer that updates scopes after tool errors
- Assumptions/dependencies: robust reward proxies; drift management for changing tools; security hardening to prevent prompt injection via tool outputs
- Education and personalized tutoring via skill playlists
- Sectors: education technology
- What it enables: adaptive injection of pedagogical tactics (Socratic prompts, worked examples, error analysis); renderer clarifies when to avoid certain strategies
- Potential tools/workflows: learning-analytics–derived utility labels; course/unit-specific budget policies; content safety checks baked into rendering
- Assumptions/dependencies: longitudinal outcome data; age-appropriate safety constraints; accessibility requirements
- Cross-organization skill marketplaces with interoperability
- Sectors: software platforms, ecosystems
- What it enables: standardized “set-aware rendering contracts” so third-party skills can be co-injected without conflict; marketplace-level adaptive budgeting
- Potential tools/workflows: MCP-style schemas extended with renderer hints; governance APIs that expose skill utility telemetry to publishers
- Assumptions/dependencies: ecosystem standards; trust and security models; incentives for publishers to supply rich metadata
- Continual co-training of skills and injection policy
- Sectors: foundational AI platforms, MLOps
- What it enables: joint optimization where skills evolve while the planner learns from live traffic; renderer adapts as new sibling skills appear
- Potential tools/workflows: off-policy RL with counterfactual evaluation; safe exploration with guardrails; auto-curation of skill descriptions
- Assumptions/dependencies: robust offline evaluation to prevent regressions; drift/rollback mechanisms; privacy-aware logging
- SLA- and cost-aware planning at scale
- Sectors: cloud AI services, finance, telecom
- What it enables: dynamic budgets that optimize end-to-end utility under token/latency/cost constraints; multi-objective selection (quality, cost, risk)
- Potential tools/workflows: budget controllers integrated with serving infra; per-tenant policies; differential thresholds by user tier
- Assumptions/dependencies: accurate online cost models; safe degradation strategies; fairness considerations
- Safety, auditability, and policy governance
- Sectors: regulators, enterprise risk, public sector
- What it enables: auditing overlaps and conflicts in tool catalogs; renderer-enforced scoping as “explainable control” for when tools are or aren’t used
- Potential tools/workflows: compliance dashboards visualizing per-skill Δ and rendered exclusions; attestations attached to agent decisions
- Assumptions/dependencies: standard metrics and reporting formats; legal frameworks that recognize runtime rendering as a control; third-party audits
Notes on cross-cutting dependencies
- Training signals: Execution-grounded utility labels Δ(t,s) require rollouts, simulators, or high-quality historical logs; proxy signals may be needed when ground truth is scarce.
- Model and compute: A small renderer can be distilled from a larger teacher; availability of strong teachers and compute budgets affects onboarding time.
- Catalog quality: Benefits depend on clean, stable skill identifiers and minimally sufficient descriptions/bodies; noisy catalogs reduce gains.
- Change management: Domain thresholds (τ*) and renderer behavior must be recalibrated as catalogs and tasks drift; observability is essential.
- Governance and safety: Runtime description rewrites should be reviewed for high-risk domains; human oversight is mandatory in regulated settings.
Glossary
- Admission threshold: A cutoff score for admitting skills into the injected context for a task. "Admission-threshold sweep."
- AgentGym: A framework/environment used to host interactive agent tasks for evaluation. "We host the environment via AgentGym~\citep{xi-etal-2025-agentgym}."
- ALFWorld: A text-based interactive decision-making benchmark for household tasks. "ALFWorld~\citep{shridhar2021alfworld} is a text-based decision-making benchmark across six household categories."
- BM25: A classical sparse information retrieval method used to rank text documents (or tools/skills) by relevance. "BM25 as a sparse retriever"
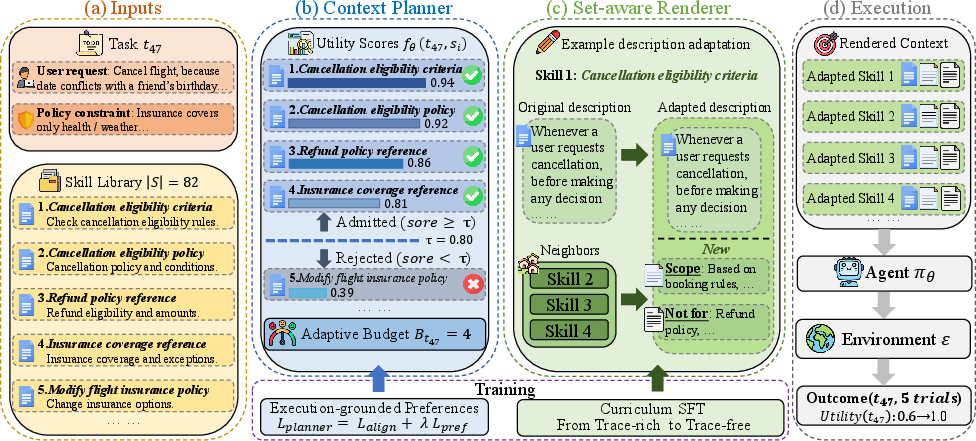
- Budget (B_t): The number of skills selected for a task’s injected context. "The induced budget is "
- Context planner: A component that scores and selects which skills to inject and how many to include for a given task. "The first component is a context planner."
- Context-construction operator: The mapping that outputs both the selected skill set and a rendering function for descriptions. "the context-construction operator,"
- Curriculum (training): A staged training strategy that gradually changes inputs or difficulty to improve learning. "via a curriculum~\citep{10.1145/1553374.1553380}."
- Dense Cosine retriever: A dense retrieval method that ranks by cosine similarity of embeddings. "a Dense Cosine retriever that ranks skills by cosine similarity between task and skill embeddings"
- Dependency-aware graph structure: A retrieval approach that models relationships/dependencies between skills/tools via a graph. "dependency-aware graph structure"
- Distribution alignment: Training a model to match a target probability distribution (here, over skill benefits). "Distribution alignment alone can blur fine-grained orderings among close skills,"
- Execution-grounded benefit: The improvement in task success attributable to injecting a specific skill, measured by actual execution outcomes. "The execution-grounded benefit of skill for task is "
- Execution utility: The expected task completion rate of the agent under a given injected context. "expected execution utility"
- Frozen agent: An agent whose policy parameters are not updated during evaluation or context construction. "We consider skill injection for a frozen agent operating over a fixed skill library."
- Graph of Skills: A retrieval method/baseline that operates over a skill-similarity graph. "Graph of Skills~\citep{liu2026graphskillsdependencyawarestructural}"
- Kullback–Leibler (KL) divergence: A measure of difference between two probability distributions used to align predicted and target distributions. "\mathrm{KL}!\left( q_\Delta(\cdot \mid t) \,|\, p_\theta(\cdot \mid t) \right)"
- Listwise reranking: A retrieval optimization that reorders a list of candidates jointly rather than per-item. "listwise reranking"
- Odds-ratio form: A loss formulation using odds (p/(1−p)) to model pairwise preferences; connected to ORPO-style objectives. "We use an odds-ratio form~\citep{hong-etal-2024-orpo}"
- Pairwise preference: A training signal that enforces an ordering between pairs of candidates based on relative utility. "we add a pairwise preference term"
- Preference learning: Learning to rank or choose items (skills) based on observed preferences/utility signals. "We therefore treat planning as a preference learning problem"
- Pytest verifier: An automatic test harness that validates task success on SkillsBench. "the pytest verifier result"
- Renderer (set-aware renderer): A module that rewrites skill descriptions conditioned on the selected set to reduce overlap and clarify roles. "The second component is a set-aware renderer."
- Set-aware adaptation: Conditioning description rewriting on the specific set of co-injected skills. "We distill set-aware adaptation into a small renderer"
- Skill context: The collection of selected and possibly rewritten skill descriptions injected into the agent’s prompt. "skill context construction"
- Skill injection: Supplying an agent with explicit skill descriptions/tools at inference time to enhance performance. "Existing methods still treat skill injection as a static step"
- Skill library: The repository of available skills/tools that can be injected into the agent. "Skill libraries are now a standard layer in LLM agent systems"
- SkillRouter: A baseline method that performs skill routing/reranking at scale. "SkillRouter~\citep{zheng2026skillrouterskillroutingllm}"
- SkillsBench: A benchmark suite of agent tasks with human-curated skills for evaluation. "SkillsBench~\citep{li2026skillsbenchbenchmarkingagentskills} releases 87 agent tasks across 11 domains with human-curated skills."
- Softmax temperature: A scaling parameter in softmax that controls distribution sharpness in probability assignments. "with temperature ,"
- Spearman correlation: A rank correlation metric used to relate skill set size and reward trends per task. "Spearman correlation between and reward"
- SFT (Supervised Fine-Tuning): Fine-tuning a model on labeled examples to imitate target outputs. "which serves as the SFT target for the student."
- tau2-bench: A benchmark of customer-service domains used to evaluate agent performance with skills. "tau2-bench"
- Top-K rule: Selecting the K highest-scoring items; a fixed-size selection heuristic. "a fixed top- rule"
Collections
Sign up for free to add this paper to one or more collections.