MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation
Abstract: LLM agents rely on reusable skills to solve complex tasks. However, existing skill creation approaches treat skills as isolated and static artifacts, limiting their reusability, reliability, and long-term improvement. We propose MUSE-Autoskill Agent (Memory-Utilizing Skill Evolution), a skill-centric agent framework that lets agents continuously improve their task-solving capability by creating, reusing, and refining skills under a unified lifecycle (creation, memory, management, evaluation, and refinement). Our framework enables agents to create skills on demand, store and reuse them across tasks, organize and select them efficiently, and evaluate them through unit tests and runtime feedback for continuous refinement. We further introduce skill-level memory that accumulates experience for each skill across tasks, enabling more effective reuse and adaptation over time. Experiments on SkillsBench provide initial evidence that lifecycle-managed skills can improve task success, efficiency, reuse, and cross-agent transfer, highlighting the importance of treating skills as long-lived, experience-aware, and testable assets.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation”
What is this paper about?
This paper is about teaching AI assistants to collect and improve their own “skills” over time, a bit like a person building a toolbox and getting better at using each tool. The system is called MUSE-Autoskill. It helps an AI create new skills when needed, remember how well those skills work, test them, fix them if they fail, and reuse them later. The goal is to make AI agents more reliable, faster, and better at solving real-world tasks.
What questions are the researchers asking?
In simple terms, they ask:
- How can an AI make and improve its own reusable skills instead of relying on fixed, one-time tricks?
- Can these skills be stored with “memories” so they get better the more they are used?
- Can we test and fix skills automatically so they’re trustworthy?
- Do these skills actually help on real tasks?
- Can skills created by one AI be used by another?
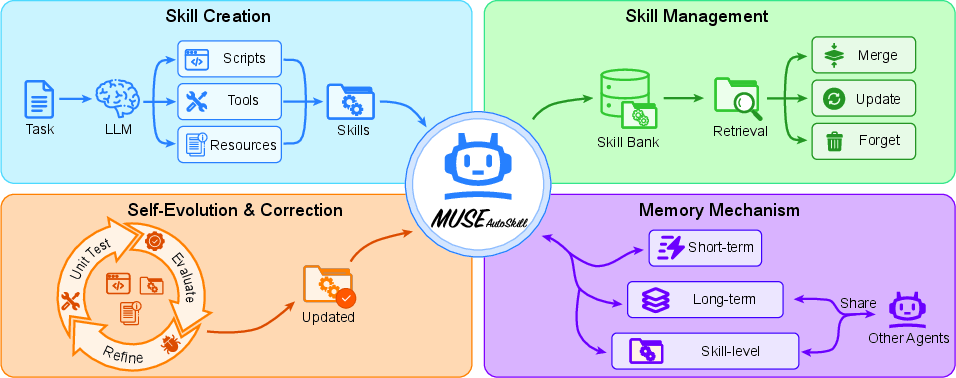
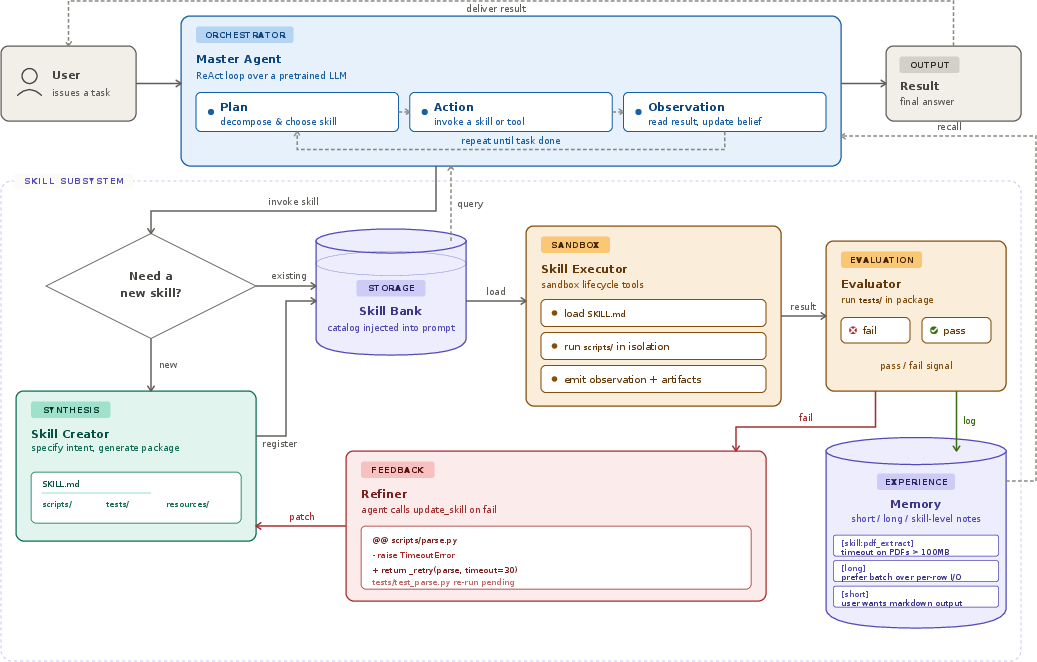
How does MUSE-Autoskill work?
Think of the AI as a student with a growing binder full of step-by-step “recipe cards” (skills). Each card explains what the skill does, what it needs, and how to do it. The system follows a simple loop: plan what to do, act, then look at what happened.
Here are the key ideas, with easy analogies:
- Skill creation: When the AI faces a new problem and doesn’t have a good “recipe,” it writes one. It creates a skill package with:
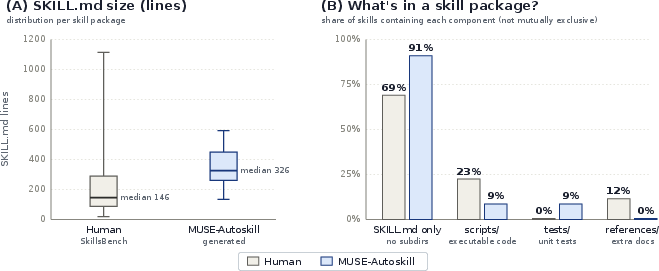
- A SKILL.md (a plain-English instruction sheet describing the skill)
- Optional code files (scripts) the AI can run
- Small tests (unit tests) to check the skill works
- Skill memory: Each skill keeps a mini diary (like notes on the recipe card) with tips such as “This input format works best” or “Watch out for this error.” Over time, these notes help the AI avoid past mistakes.
- Skill management: The AI keeps a neat skill library. It:
- Finds skills that match the current task
- Merges duplicate skills
- Deletes skills that aren’t useful
- Updates skills when tests fail
- Skill evaluation: Before a new or changed skill is trusted, the AI runs unit tests—tiny checks that say “If I give this input, do I get the expected output?” If tests fail, the AI repairs the skill and tries again.
- Refinement: When something goes wrong during a task, the AI uses the error message like a clue, fixes the skill, and keeps going.
Under the hood, the agent runs in a “ReAct” loop:
- Planning: break the problem into steps
- Action: run a skill or tool
- Observation: see what happened and adjust
Some technical bits explained simply:
- Sandbox: a safe, separate “computer box” where the AI can run code without breaking anything else.
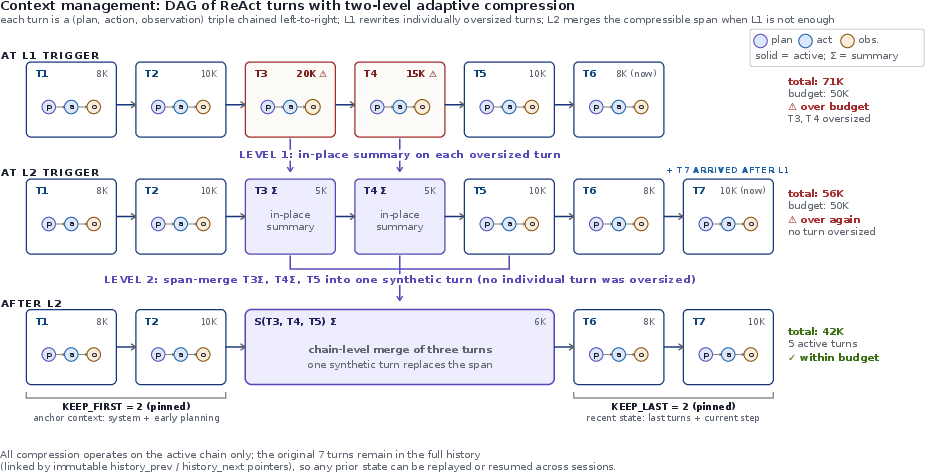
- Context management: when conversations and steps get very long, the AI summarizes older parts so it can still “remember” the important bits without overflowing its memory limit—like making a neat summary of earlier notes.
What did they test, and how?
They used a benchmark called SkillsBench: 51 real, computer-based tasks across areas like science and engineering, data analysis, document processing, and operations/planning. Each task is run in a standard “box” (a Docker container) and checked by an automatic grader to see if the final answer is correct.
They compared three AI agents (all using the same underlying LLM) in different situations:
- With no skills
- With human-written skills
- With skills that MUSE-Autoskill created by itself
- They also tried moving MUSE’s self-made skills into a different agent to see if they still worked.
What did they find, and why does it matter?
Main results, in plain language:
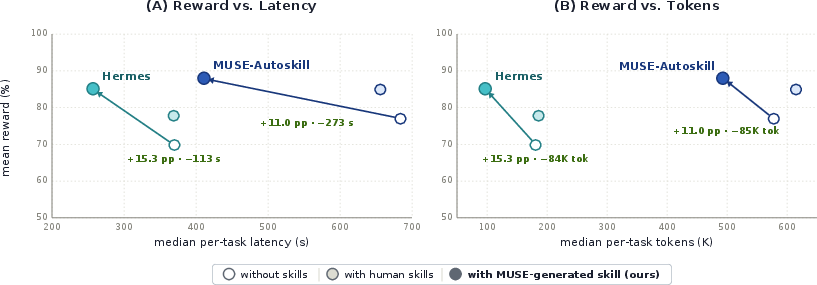
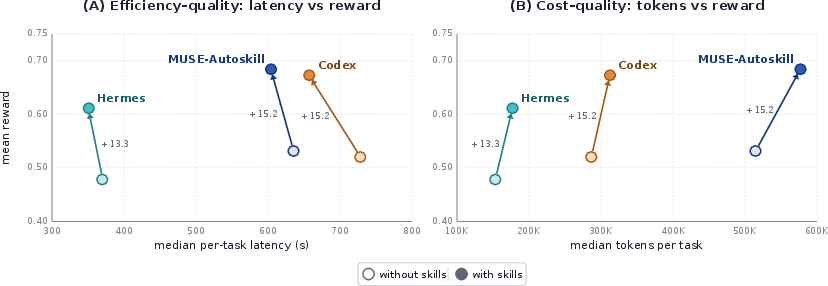
- Skills help a lot: All agents got much better when using skills. MUSE-Autoskill reached 68.4% accuracy with human-written skills, about 15 percentage points higher than without skills.
- Self-made skills can be excellent: When MUSE-Autoskill created skills from its own successful attempts, it achieved 87.94% accuracy on the tasks where it managed to make a skill. That’s even better than using the human-written skills for those tasks.
- Coverage matters: Across all 51 tasks (including ones where it couldn’t yet create a skill), MUSE’s overall score with its own skills was 60.35%. The drop comes from tasks where it never succeeded in Phase 1, so it couldn’t create a skill for them.
- Skills transfer to other agents: When they gave MUSE’s self-made skills to a different agent (called Hermes), Hermes improved by about 10.5 percentage points, getting close to its own “with human skills” performance. This shows the skills are portable “knowledge packages,” not tied to one specific agent’s quirks.
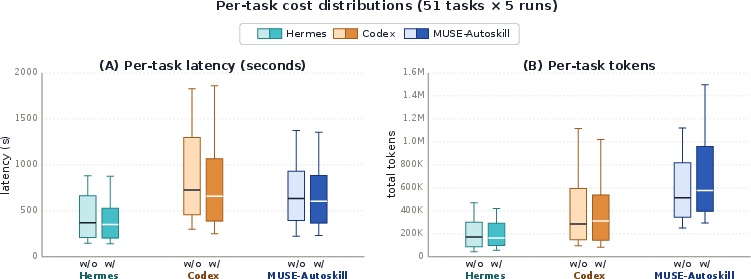
- Cost and speed: Using self-made skills often made tasks faster and used fewer tokens (the “words” the model processes), because a good skill replaces long, messy reasoning with a clear, short procedure.
Why it matters:
- Reliability: Skills get tested like tiny apps before being reused. That makes agents more trustworthy.
- Reuse and speed: Once a skill exists, the agent finishes similar tasks more quickly and cheaply.
- Learning over time: Skills accumulate memories and improvements, so the agent genuinely gets better with experience.
- Sharing: Skills can be passed between different agents, spreading useful know-how.
What’s the bigger picture?
This work suggests a practical path for AI assistants that:
- Learn new abilities on their own when needed
- Keep improving those abilities with real-world practice and tests
- Store and organize what they learn so it’s easy to reuse
- Share their best skills with other agents
If widely adopted, this could make future AI helpers more dependable and efficient at schoolwork, research, office tasks, coding, data analysis, and more—especially for multi-step jobs where careful procedures beat guesswork.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what this paper leaves uncertain or unexplored, aimed to guide future research:
- Component ablations and causal attribution
- No ablation isolating the marginal contribution of each lifecycle stage (creation, evaluation, refinement, skill-level memory, context compression) to performance, cost, and reuse.
- Lack of controlled comparisons for alternative designs (e.g., evaluation without unit tests, refinement disabled, no skill-level memory, different context compression strategies).
- Coverage bottleneck in self-skill generation
- Only 68.6% of tasks produced self-created skills; 16/51 tasks with zero successful Phase-1 runs remain uncovered. Methods to bootstrap skill creation without a prior success trajectory (e.g., curriculum, search, simulation, retrieval-augmented demonstrations) are not explored.
- Unit-test design, validity, and overfitting
- How unit tests are generated, their coverage guarantees, and susceptibility to overfitting to a single successful trajectory are unspecified.
- No use of test adequacy metrics (e.g., code coverage), mutation testing, or cross-task validation to detect spurious test passes.
- Open question: how to automatically generate robust tests that generalize across task variants and prevent “teaching-to-the-test.”
- Generalization beyond SkillsBench
- Evaluation is limited to 51 SkillsBench tasks (pre-filtered to avoid environment failures), risking selection bias and limited ecological validity.
- Unclear performance on dynamic, interactive, or adversarial environments (e.g., web tasks, online tools, multi-session workflows), and on other benchmarks (GAIA, SWE-bench, AgentBench, SkillRet/LifelongAgentBench).
- Cross-agent and cross-backbone portability
- Transfer validated only from MUSE-Autoskill to a single different agent (Hermes) using the same model family; portability to diverse agent architectures and different LLM backbones (open-source and proprietary) is untested.
- Open question: what skill properties (interface granularity, procedural specificity, dependency footprint) are necessary and sufficient for robust cross-agent transfer?
- Scaling the skill bank
- No empirical study of retrieval at scale (e.g., thousands of skills): indexing methods, ranking quality, latency/throughput, and degradation under “skill bloat.”
- Merge/prune criteria are described but lack concrete algorithms, thresholds, or evaluation of false merges/prunes and their effect on performance.
- Versioning, dependency management, and rollbacks for refined skills are not specified; reproducibility across versions is unaddressed.
- Skill-level memory accuracy and governance
- How per-skill .memory.md avoids drift, hallucinations, or poisoning is unspecified; mechanisms for verification, summarization quality, and conflict resolution are missing.
- Retrieval and surfacing policies for long-term memory (which is unbounded and uncompressed) are undefined; risk of memory overload or irrelevant recall is not quantified.
- Context compression trade-offs
- Effects of the two-level DAG compression on task accuracy, failure modes, and error propagation are not quantified; thresholds (KEEP_FIRST/KEEP_LAST, per-node budgets) are not justified or tuned via experiments.
- Open question: can learned or adaptive compression policies outperform handcrafted heuristics?
- Reliability, variance, and statistical rigor
- Results are averaged over five runs but report no variance, confidence intervals, statistical tests, or sensitivity to random seeds.
- Test flakiness, verifier stability, and run-to-run reproducibility (especially under refinement) are not analyzed.
- Cost modeling and amortization
- Token/latency costs are reported for two agents on 35 tasks, but broader cost models (varying API prices, hardware, caching, parallelism) and storage/maintenance costs of large skill banks and memories are missing.
- Open question: how do break-even points shift under different deployment budgets and task reuse frequencies?
- Security, safety, and supply-chain risks
- Executing generated scripts raises risks (sandbox escape, privilege escalation, network/data exfiltration). Threat modeling, permissioning, sandbox hardening, and skill signing/attestation are not addressed.
- No defenses against prompt injection, malicious or poisoned skills/memories, or cross-session memory poisoning.
- Failure analysis and specification alignment
- Only cursory analysis of boundary failures (e.g., verifier penalizing methodology choices). Systematic methods to detect ambiguous task specs and reconcile methodology differences are missing.
- Open question: how to design verifiers/specs or agent negotiation strategies that reduce penalization for reasonable methodological choices.
- Continual and lifelong learning dynamics
- Although state persistence is claimed, no longitudinal learning curves quantify improvement across sessions, tasks, or time.
- Catastrophic forgetting vs. accumulation trade-offs, and stability under continuous refinement, are unstudied.
- Decision policies: when to create vs. reuse vs. refine
- Criteria and policies for deciding between retrieving an existing skill, creating a new one, or refining are unspecified and unevaluated.
- Open question: can meta-controllers or bandit/RL formulations improve these choices at inference time without full retraining?
- Dependency and environment management
- Handling external dependencies (pinning versions, caching, reproducible environments), cross-OS portability, and hermetic builds is not detailed; their impact on reliability is unknown.
- Human-in-the-loop and governance
- When and how to solicit human review (e.g., for high-risk skills, failing refinements), approve merges/prunes, or audit memory entries is not specified.
- Policies for provenance tracking (who/what created/edited a skill) and accountability are missing.
- Robustness to distribution shift and adversarial conditions
- No tests for robustness under perturbed inputs, noisy tools, partial observability, or adversarial verifiers/tests.
- Open question: can the evaluation/refinement loop detect and recover from distribution shifts without human intervention?
- Out-of-task transfer and compositionality
- Self-created skills were evaluated mostly on their source tasks; generalization to related or novel tasks and compositional reuse in multi-skill pipelines are not measured.
- Multimodal and tool-ecosystem breadth
- The framework focuses on text/code skills. Extension to multimodal skills (e.g., images, audio) and compatibility with broader tool ecosystems (APIs, cloud services, databases) remains open.
- Ethical and privacy considerations
- Persisting execution logs, data artifacts, and skill memories may capture sensitive information; policies for PII redaction, retention limits, and access control are not discussed.
- Benchmark scope and transparency
- Task selection was constrained to avoid environment failures; release of code, generated skills, tests, and full prompts for independent replication is not stated.
- Open question: how do results change when including tasks with environment variability or failures that agents must handle autonomously?
Practical Applications
Practical, real-world applications of MUSE-Autoskill
Below we translate the paper’s findings into concrete applications, grouped by deployment horizon and annotated with sectors, potential tools/workflows, and key dependencies that affect feasibility.
Immediate Applications
- Enterprise skill registries for software and DevOps automation
- Sectors: software, IT operations
- What: Package common scripts/runbooks (e.g., log triage, CI/CD steps, dependency pinning) into SKILL.md-based units with tests; gate new automations via unit-test evaluation; reuse across teams.
- Tools/workflows: “SkillHub” (internal skill bank), skill CI/CD (create → evaluate → register), sandboxed execution, progressive disclosure catalogs.
- Assumptions/dependencies: Access to a capable LLM with tool-use; containerized/sandbox infra; code signing/permissions; test coverage for critical paths.
- Repeatable data analysis and ETL
- Sectors: data platforms, analytics, research
- What: Distill successful EDA/ETL notebooks into reusable skills (schema parsing, cleaning, aggregation, charting), each with tests and per-skill memory (edge cases, performance caveats).
- Tools/workflows: Jupyter/VS Code extensions to “skillify” notebooks, Airflow/Dagster operators that call skills, dataset-specific test suites.
- Assumptions/dependencies: Stable data access/permissions; representative test data; governance over PII handling.
- Document processing automation
- Sectors: legal, operations, content, RPA
- What: Skills for OCR, parsing, PDF-to-structured, templated drafting, and QA with unit-testable verifiers; reuse across document types with skill-level notes on quirks.
- Tools/workflows: RPA pipelines integrating SKILL.md packages, document verifiers, batch processing via sandbox.
- Assumptions/dependencies: Availability of OCR/format converters; robust tests for layout variance; privacy controls for sensitive docs.
- Self-updating runbooks for SRE/IT
- Sectors: IT operations, cloud platforms
- What: Turn runbooks into executable skills with tests; attach failure modes to skill-level memory; refine on test/runtime feedback.
- Tools/workflows: PagerDuty/ServiceNow integrations; sandboxed shell skills (create_sandbox, sandbox_run); merge/prune policies to keep the bank compact.
- Assumptions/dependencies: Least-privilege execution; rollback/safe restore; alignment of tests with production acceptance criteria.
- Cross-agent skill sharing inside organizations
- Sectors: enterprise software
- What: Vendor-agnostic, portable skills (SKILL.md + scripts/tests) shared across different agent platforms (evidence: cross-agent transfer closes ~79% of performance gap).
- Tools/workflows: Internal package index, import tooling for multiple agents, license/compliance checks.
- Assumptions/dependencies: Agreement on packaging conventions; IP and security review for code sharing.
- Cost and latency optimization via skill reuse
- Sectors: platform engineering, FinOps
- What: Replace long reasoning trajectories with compact, well-specified skills to reduce tokens/latency (paper: −20–48% tokens; −30–37% latency); break-even after ~3 reuses.
- Tools/workflows: Token/latency dashboards, caching, automated identification of high-cost trajectories to “skillify.”
- Assumptions/dependencies: Reliable cost telemetry; budget policies; initial creation overhead.
- Long-horizon workflows with resumability
- Sectors: customer support, project management, professional services
- What: Use DAG-based context and adaptive compression to maintain coherence over multi-session tasks; persist and resume task state.
- Tools/workflows: CRM/PM integrations (e.g., Zendesk, Jira); session snapshots; privacy-aware storage of short-/long-term memory.
- Assumptions/dependencies: Data retention policies; PII controls; guardrails for context injection.
- Reproducible academic/industrial experiments
- Sectors: academia, R&D, scientific computing/engineering
- What: Package experimental procedures and simulations as tested skills; share Dockerized skills alongside papers/code for verifiable replication.
- Tools/workflows: Artifact repositories (e.g., GitHub + containers), auto-run test harnesses.
- Assumptions/dependencies: Container-friendly environments; stable dependencies; community adoption.
- Personal automation with safety nets
- Sectors: daily life, prosumer productivity
- What: Personal skills for budgeting, resume formatting, trip planning; unit tests encode user-specific expectations; per-skill memory stores preferences.
- Tools/workflows: Desktop/mobile “skill runner,” local sandbox execution, human-in-the-loop approval before actions.
- Assumptions/dependencies: Local execution for privacy; safe defaults; explicit consent for data use.
- Compliance-friendly reporting and checks
- Sectors: finance, GRC, internal audit
- What: Encode reporting workflows and controls as skills with auditable tests; preserve evaluation logs for audit trails.
- Tools/workflows: Skill CI with control tests, evidence capture (artifacts, logs), change review gates.
- Assumptions/dependencies: Tests aligned to policy/regulation; change-management process; segregation of duties.
- API/tool orchestration as reusable skills
- Sectors: software, product operations
- What: Standard API wrappers (rate limits, retries, auth) as skills; per-skill memory captures API deprecations/quirks.
- Tools/workflows: Secret managers, quota monitoring, automatic patch/refine when tests fail.
- Assumptions/dependencies: Stable API contracts; key management; monitoring for drift.
- Course and tutoring assistants that accumulate skills
- Sectors: education, edtech
- What: Skills for feedback on code/homework transformations with unit tests and curated examples; memory of common student pitfalls.
- Tools/workflows: LMS plugins; sandboxed grading harnesses; content moderation.
- Assumptions/dependencies: Institutional policies on AI usage; academic integrity safeguards.
- Living SOP/knowledge management
- Sectors: enterprise operations, HR, finance ops
- What: Convert SOPs into executable, testable skills; merge/prune to control sprawl; annotate with per-skill memory.
- Tools/workflows: Versioned skill catalogs; governance committees; skill analytics (usage, pass/fail rates).
- Assumptions/dependencies: Ownership and review; version control; access boundaries.
- Backbone flexibility without retraining
- Sectors: platform, procurement
- What: Deploy skills across different LLM backbones or agent shells without fine-tuning (training-free design).
- Tools/workflows: Compatibility tests; fallback routing to alternate models.
- Assumptions/dependencies: Comparable tool-calling capabilities and context limits across providers.
Long-Term Applications
- Open skill marketplaces and standards
- Sectors: software platforms, ecosystems
- What: Cross-vendor marketplaces for audited, portable skills (SKILL.md+tests) usable by multiple agents; publisher reputation and certification.
- Tools/workflows: Skill signing/scanning, dependency SBOMs, marketplace QA, interoperability tests.
- Assumptions/dependencies: Industry-wide standardization; legal/licensing frameworks; supply-chain security.
- Healthcare workflow skills with governance
- Sectors: healthcare operations, revenue cycle, informatics
- What: Tested skills for scheduling, documentation, coding, and administrative processes; unit tests aligned to clinical policies; human review gates.
- Tools/workflows: EHR integrations (sandboxed), audit trails, PHI-safe memories.
- Assumptions/dependencies: HIPAA/GDPR compliance, rigorous validation, clinical oversight; limited for direct clinical decision support.
- Robotics skill lifecycle
- Sectors: robotics, manufacturing, logistics
- What: Package robot behaviors/procedures as skills with simulation-based unit tests and per-skill memory (failure modes, calibration tips); transfer across platforms.
- Tools/workflows: Simulator harnesses; hardware-in-the-loop evaluation; safety interlocks.
- Assumptions/dependencies: Reliable sim-to-real transfer; hardware APIs; safety certification.
- Energy and grid operations planning
- Sectors: energy, utilities
- What: Planning/optimization skills validated on historical/replay scenarios; operator-in-the-loop refinement from runtime feedback.
- Tools/workflows: Data pipelines for telemetry; sandboxed model execution; what-if test suites.
- Assumptions/dependencies: Access to high-fidelity data; regulator approvals; robust robustness tests.
- Model risk and regulatory reporting automations
- Sectors: finance, insurance
- What: Skills for risk aggregation, stress testing, and regulatory templates; formalized tests that mirror regulatory checks.
- Tools/workflows: Controlled environments with immutable logs; attestation workflows; periodic revalidation.
- Assumptions/dependencies: Model risk management policy; regulator engagement; conservative deployment.
- Public-sector digital services and inter-agency reuse
- Sectors: government, civic tech
- What: Shared skill libraries for licensing, permitting, benefits processing; cross-agency portability with tests expressing statutory rules.
- Tools/workflows: GovCloud sandboxes; accreditation (ATO); public repositories for non-sensitive skills.
- Assumptions/dependencies: Security accreditation, procurement updates, transparency mandates.
- Org-scale continual learning and curation
- Sectors: enterprise platforms
- What: Automated merging/pruning and conflict resolution for thousands of skills; multi-tenant skill memories with access controls.
- Tools/workflows: Skill graph analytics, version semver, A/B skill selection, drift detection.
- Assumptions/dependencies: Strong governance; privacy partitioning; change-impact analysis.
- Multi-agent ecosystems that negotiate and compose skills
- Sectors: platforms, autonomous ops
- What: Agents discover, share, and compose skills dynamically with metadata schemas for capabilities and constraints.
- Tools/workflows: Capability ontologies; protocol for skill discovery and trust scoring.
- Assumptions/dependencies: Interop protocols, sandbox federation, trust and identity frameworks.
- Formal verification and adversarial evaluation for skills
- Sectors: safety-critical software, security
- What: Extend unit tests with formal specs and red-team suites; auto-refinement triggered by proofs or adversarial findings.
- Tools/workflows: Model checking, property-based testing, fuzzing in CI.
- Assumptions/dependencies: Formalizable specs; tooling maturity; performance budgets.
- Privacy-preserving skill memory
- Sectors: healthcare, finance, multi-tenant SaaS
- What: Federated skill updates and encrypted per-skill memories; differential privacy for usage notes.
- Tools/workflows: Secure enclaves, KMS, audit logging, federated orchestration.
- Assumptions/dependencies: Cryptographic infrastructure; privacy budgets; cross-jurisdiction compliance.
- Skills-as-artifacts in MLOps
- Sectors: ML platforms
- What: Treat skills like deployable services with telemetry, SLOs, rollout/rollback, and A/B tests.
- Tools/workflows: Feature flags for skills, observability (traces/metrics), canarying.
- Assumptions/dependencies: Platform support for artifact management and runtime metrics.
- Accredited educational skill packages
- Sectors: education, certifications
- What: Standardized skill bundles for lab exercises and assessments with proctored tests and auditability.
- Tools/workflows: Accreditation-aligned rubrics; locked-down sandboxes.
- Assumptions/dependencies: Collaboration with accrediting bodies; integrity safeguards.
- Scientific/engineering lab automation and sharing
- Sectors: science, engineering
- What: Protocols encoded as skills (instrument control, data reduction) with test harnesses and safety gates; shared across labs.
- Tools/workflows: Instrument APIs; hardware simulators; provenance tracking.
- Assumptions/dependencies: Device interoperability; safety standards; institutional approvals.
Notes on feasibility across applications:
- Core dependencies recur: high-capability LLMs with tool-calling, secure sandbox/container execution, robust unit tests/verifiers, memory governance, and adoption of a portable skill format (e.g., SKILL.md).
- For regulated domains, human oversight and compliance-aligned tests are essential; autonomous deployment should be restricted until verification and governance mature.
- Economic viability benefits from demonstrated token/latency reductions and break-even after a small number of reuses; monitoring and analytics are necessary to realize these gains.
Glossary
- Adaptive context compression: An agent-level summarization technique that reduces context length by compressing nodes or merging spans to stay within the model’s token limits; "MUSE applies adaptive context compression with two levels."
- AgentBench: A benchmark suite for evaluating general LLM agents across environments and tool-use tasks; "including GAIA, SWE-bench, and AgentBench"
- Anthropic's Agent Skills: A standardized, portable skill format (folders with SKILL.md and scripts) for LLM agents; "Anthropic's Agent Skills standardize skills as portable folders of instructions and scripts."
- API retrieval: The process of discovering and selecting relevant APIs at scale for tool-using agents; "large-scale API retrieval"
- AutoSkill: A method for automatically deriving, maintaining, and reusing skills from agent traces; "AutoSkill"
- Automated verifier: A programmatic grader that checks final outputs to score task success; "graded by an automated verifier"
- Contrastive induction: A refinement approach that learns from differences between successful and failed trajectories; "SkillGen iteratively refines skills via contrastive induction over successful and failed trajectories"
- Counterfactual downstream utility: A credit assignment signal estimating the impact of edits by comparing outcomes had the edit not been made; "edits credited by counterfactual downstream utility."
- Cross-agent skill transfer: Reusing skills authored by one agent in a different agent without modification; "cross-agent skill transfer that makes generated skills usable beyond their authoring agent."
- Cross-session state persistence: Saving and reloading agent state across sessions to support long-horizon tasks; "cross-session state persistence supports long-horizon tasks"
- DAG (Directed Acyclic Graph): A non-cyclic graph structure used here to manage conversation and context nodes; "The agent maintains context as a DAG of conversation nodes"
- Distillation (skill distillation): Compressing or consolidating skill knowledge into more efficient forms; "skill selection, utilization, and distillation"
- Docker: Containerization technology providing isolated, reproducible environments for tasks and evaluation; "Each task runs in an isolated Docker container"
- Few-shot tool calling: Enabling agents to call tools using limited examples rather than extensive training; "few-shot tool calling"
- Fine-tuning: Adjusting model parameters on additional data to specialize behavior; "without any fine-tuning"
- GAIA: A benchmark for agent capabilities including web and tool use; "GAIA"
- Hybrid policy optimization: An RL-style approach that jointly optimizes multiple components (e.g., tools and configurations); "hybrid policy optimization of tools and agent configurations"
- KV retention: Techniques to keep key–value attention cache information for long sequences; "attention-sink-based KV retention for streaming inference"
- LLM backbone: The underlying LLM used by an agent system; "portable across LLM backbones"
- Macro-average: An averaging method that weights each task equally when computing overall accuracy; "macro-average"
- MemGPT: An agent memory architecture that pages between in-context and external memory like an operating system; "MemGPT pages between in-context and external memory in an OS-style hierarchy"
- Multimodal autonomous agents: Agents that handle multiple input/output modalities (e.g., text, images) autonomously; "multimodal autonomous agents such as Agent-Omni and OmniGAIA"
- Pareto-frontier selection: Choosing solutions that optimally trade off multiple objectives without being dominated; "under a Pareto-frontier selection"
- Pareto-optimal: A configuration where improving one objective would worsen another; "the unique Pareto-optimal configuration"
- Percentage points (pp): An absolute difference between percentages (not a relative percent change); "a pp lift"
- Progressive disclosure: Gradually revealing skill content or tools to the agent to reduce overload; "loaded via progressive disclosure"
- ReAct loop: A decision-making pattern interleaving reasoning (Thought) and acting (Action) steps; "The Master Agent runs a ReAct loop"
- Reinforcement learning (RL): An optimization framework where policies are improved based on rewards from interactions; "use reinforcement learning to optimize skill behavior"
- Sandbox: An isolated execution environment/container for running code safely with controlled side effects; "Each sandbox is an isolated process / container"
- SKILL.md: A standardized skill interface file specifying name, description, inputs, outputs, and usage; "It includes a SKILL.md file that defines its interface"
- Skill Bank: The repository where validated, reusable skills are stored and retrieved; "registers the skill into the Skill Bank"
- Skill-level memory: A per-skill memory store of usage notes, failures, and observations to inform future calls; "skill-level memory stores the skills themselves along with their metadata"
- SWE-bench: A benchmark for software engineering tasks used to evaluate coding agents; "SWE-bench"
- Token budget: The maximum number of tokens available for context and generation in a model call; "without exceeding the model's token budget"
- Tool orchestration: Coordinating multiple tools or APIs, often via a learned/model-based selector; "tool orchestration via model selection"
- Unit-test-driven evaluation: Assessing skills by executing unit tests to validate correctness and reliability; "unit-test-driven evaluation"
- Virtual context management: System-level techniques to manage and simulate longer effective context than the model window; "OS-style virtual context management for general LLM agents"
Collections
Sign up for free to add this paper to one or more collections.