- The paper introduces a three-stage pipeline—skill retrieval, incorporation, and application—to extend LLM capabilities with dynamic, executable skills.
- Empirical evaluations on SRA-Bench demonstrate significant performance gains with controlled skill injection while highlighting sensitivity to retrieval noise.
- The study emphasizes the importance of need-aware, selective skill incorporation and the structuring of skill libraries for scalable agent augmentation.
Skill Retrieval Augmentation for Agentic AI: Technical Analysis
The paper introduces Skill Retrieval Augmentation (SRA) as a scalable paradigm for augmenting LLM-based agents with external, reusable skills retrieved from large skill corpora rather than relying on explicit in-context enumeration. SRA departs from knowledge-centric Retrieval-Augmented Generation (RAG) by targeting executable capability packages, which include instructions, invocation conditions, procedural guidance, and code resources. The paradigm is operationalized through a three-stage pipeline: skill retrieval (identifying relevant skills from an external corpus), skill incorporation (selective loading and transformation of useful retrieved skills), and skill application (downstream leveraging of incorporated skills for reasoning and action). This reformulates the agent's problem-solving from prompt-constrained selection to dynamic, corpus-scale capability access.
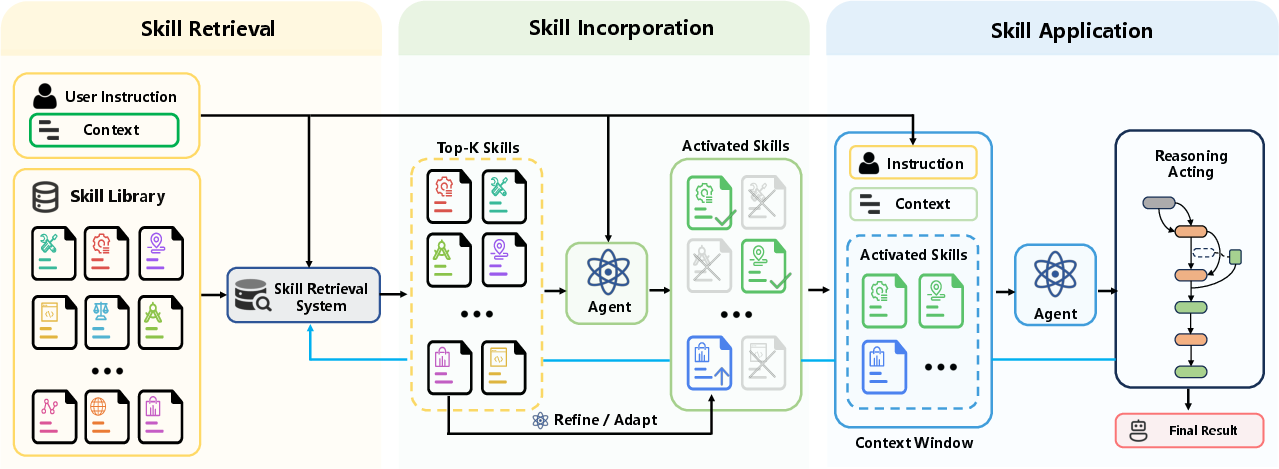
Figure 1: Illustration of SRA workflow, with agents retrieving candidate skills from an external corpus, incorporating selectively, and applying them iteratively during downstream reasoning and acting.
Benchmark Construction and Empirical Methodology
To make SRA scientifically tractable, the authors construct SRA-Bench, a decomposed benchmark featuring 5,400 capability-intensive instances paired with 636 gold skills, mixed into a noisy web-collected corpus of 26,262 skills. The benchmark allows explicit evaluation of retrieval, incorporation, and application stages. Source datasets span theorem-based reasoning, logic patterns, tool workflows, medical calculators, competition mathematics, and Python software libraries. Gold skills are manually curated via a two-stage LLM drafting and expert revision pipeline, emphasizing generalizability, correctness, and leakage control. The corpus design ensures realistic retrieval challenges, as gold skills comprise only 2.4% of the corpus.
The empirical analysis covers a spectrum of LLMs (open-weight and frontier), retrieval methods (BM25, TF-IDF, dense/BGE, hybrid, LLM reranking), skill-use strategies (direct injection, selection, progressive disclosure), and task domains. Evaluation metrics include Recall@K, nDCG@K for retrieval and standard accuracy/pass@1 for end-task execution.
Empirical Findings: Promise, Bottlenecks, and Robustness
Impact of Skill Augmentation
Retrieving and injecting external skills yields significant gains over skill-free baselines; Oracle-skill access outperforms direct parametric reasoning across nearly all models and datasets, validating the paradigm's practical utility. Retrieval-based augmentation (even with simple pipelines) achieves meaningful improvements, but is highly sensitive to strategy and model. Selection-based injection (after metadata filtering) is consistently more reliable than direct top-k injection, indicating that controlled skill exposure is crucial.
Robustness to Retrieval Noise
SR-Agents exhibit pronounced brittleness to distractor skills. Injection of multiple retrieved skills (including hard negatives) sharply degrades end-task accuracy, with Full-Skill Injection particularly susceptible. Progressive Disclosure, which exposes only minimal metadata and loads skill content on demand, confers improved robustness under noise, highlighting the necessity of selective, staged disclosure in scalable augmentation.
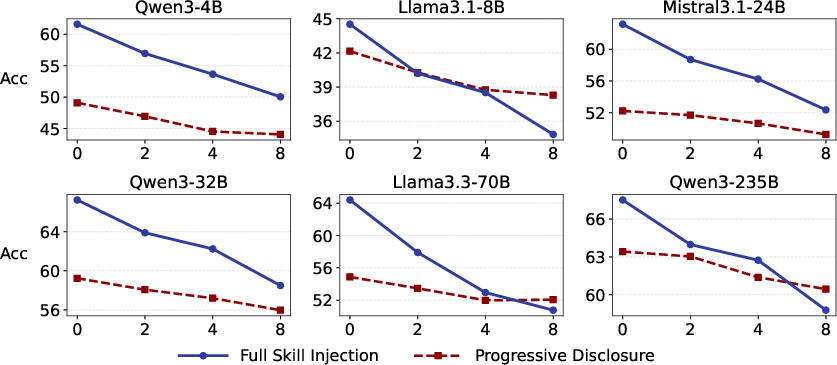
Figure 2: End-task accuracy versus number of hard-negative distractors. Progressive Disclosure is more resilient to noise than Full-Skill Injection across models.
Retrieval Quality Versus Utilization
Lexical and dense retrieval methods provide complementary strengths; dense retrieval (BGE) outperforms BM25 in semantically indirect domains, while sparse methods excel in formula/code-heavy tasks. LLM reranking applied to BM25 candidate pools yields the best retrieval and downstream performance, but end-task gains are mediated by skill incorporation and application stages. Improvements in retrieval metrics (Recall, nDCG) do not translate monotonically to task success due to bottlenecks in selection and execution.
Analysis of Skill-Loading Behavior
Skill-loading rates are highly model-dependent and do not monotonically improve with scale; current LLMs are not reliably relevance-aware. Gold-skill presence among retrieved candidates only marginally affects loading decisions for most models, with only frontier LLMs showing strong separation. Need-awareness is absent: agents load skills at comparable rates whether or not the task exceeds their parametric capacity, indicating indiscriminate augmentation and failure to operationalize the paradigm as a compensatory mechanism.
Implications and Directions for Scalable Agentic Augmentation
The findings establish SRA as a distinct open research problem: the bottleneck shifts from retrieval alone to controlled, selective, need-aware skill incorporation. Practical deployments require structured skill libraries rather than unstructured lists, utility-driven retrieval beyond semantic matching, and advances in skill quality control, offline refinement, and skill evolution. The authors highlight the potential of parametric skill augmentation via plug-in modules, which could amortize context costs and enable durable internalization of frequently used skills.
The SRA-Bench resource, gold skills, and detailed construction methodology serve as a foundation for future research in utility-aware skill indexing, feedback-driven refinement, and lifelong accumulation. Hybrid architectures combining parametric head skills and open-ended retrieval are viewed as promising for scalable agent systems.
Conclusion
Skill Retrieval Augmentation provides a scalable framework for extending agentic AI with dynamically retrieved executable capabilities. Empirical results demonstrate substantial performance improvements and robustness challenges, underscoring the critical importance of controlled, need-aware skill incorporation. The SRA paradigm and SRA-Bench benchmark recast skill augmentation as a decomposed, evaluable research agenda. Achieving scalable capability augmentation—and realizing the full promise of agentic AI—will require advances in skill library structuring, retrieval optimization, quality control, and parametric internalization (2604.24594).