- The paper introduces a two-stage compression framework that leverages delta debugging and taxonomy-driven classification to optimize LLM agent skills.
- It achieves up to 77.5% token reduction while preserving or enhancing agent performance, with an 86.0% baseline retention rate.
- The approach underscores the importance of structure-aware optimization for reducing computational costs and minimizing cognitive distraction in LLM systems.
SkillReducer: Structure-Aware Optimization of LLM Agent Skills for Token Efficiency
Motivation and Empirical Findings
SkillReducer addresses inefficiencies in the token consumption of LLM agent skills, which act as pre-packaged instruction sets containing domain-specific rules, templates, and reference material. Empirical analysis of 55,315 skills across major repositories revealed three systemic issues: (1) 26.4% of skills lack descriptions, undermining routing and wasting tokens; (2) only 38.5% of skill body content is actionable, with the remainder dominated by background, examples, or templates; and (3) reference files can inject disproportionately large token volumes regardless of task relevance. These observations highlight the absence of separation between specification, documentation, and data within skills, motivating an automated, structure-aware optimization pipeline.
SkillReducer Framework and Algorithmic Design
SkillReducer implements a two-stage compression strategy informed by classical software engineering: delta debugging and program slicing.
Stage 1: Routing Layer Optimization
A skill's description serves as the routing signal for agent invocation. Stage 1 uses delta debugging to isolate the minimally sufficient subset of semantic clauses in the description that preserve correct routing behavior, employing a simulated LLM oracle augmented with adversarial distractors. For skills with missing or underspecified descriptions, SkillReducer generates candidate descriptions from the skill body, extracting primary capability, trigger condition, and unique identifiers. Final compressed descriptions are validated in real agent runtime with selective recovery, ensuring that query-response mappings are preserved.
Stage 2: Body Restructuring via Progressive Disclosure
Skill bodies interleave actionable rules and supplementary material without explicit syntactic boundaries. SkillReducer applies taxonomy-driven classification using an LLM to segment content into core rules, background, examples, templates, and redundancies. Only core rules are included in the always-loaded module; other categories are offloaded into on-demand references, each annotated with trigger metadata to support selective loading. Deduplication removes overlaps between body and reference files, reducing inadvertent redundancy. Faithfulness and task-based gates (using both deterministic and LLM-judged evaluation) ensure that essential operational concepts and task performance are retained, with a self-correcting feedback loop to promote necessary non-core content back into the core.
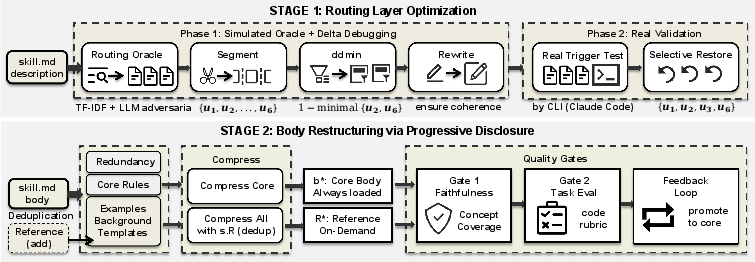
Figure 1: SkillReducer's two-stage pipeline optimizing descriptions by delta debugging and restructuring body content via taxonomy-driven classification, progressive disclosure, deduplication, and iterative validation.
Numerical Results and Comparative Analysis
SkillReducer was evaluated on 600 skills and the SkillsBench benchmark. Stage 1 achieves a mean description compression of 48%, while Stage 2 yields a 39% mean reduction in body tokens. End-to-end savings are 26.8%, scaling up to 77.5% reduction in wild skills with longer bodies. Functional quality is preserved or improved: compressed skills retain or exceed baseline performance in 86.0% of cases, with a mean retention of 0.965 across five models from four families and a 100% pass rate on SkillsBench. Notably, removing extraneous content exposes a less-is-more effect, wherein agent performance increases by 2.8%—a phenomenon independently supported by studies on context inflation and distraction [Liu2024LostMiddle,Shi2023Distracted,Levy2025ContextLength].
Baseline comparisons demonstrate SkillReducer's superiority: perplexity pruning (LLMLingua), direct LLM summarization, truncation, and random removal all exhibit lower retention rates and higher regression, confirming that taxonomy-driven, structure-aware compression is essential for maintaining the functional integrity of skills.
Component Contribution and Generalization
Ablation studies identify taxonomy-based classification as the critical component—without it, retention drops by 6.8pp. Reference deduplication is universally safe, improving performance through less-is-more effects. The feedback loop recovers 82% of originally failing skills, effectively mitigating cases where content classification omits implicit dependencies.
Compression benefits generalize across agent frameworks (OpenCode retention: 0.944) and models varying in strength and architecture (GLM-5, Qwen3-max, DeepSeek-V3, GPT-OSS-120B, Qwen2.5-7B). Weak models derive greatest benefit, suggesting skill content's utility diminishes as LLMs advance, motivating adaptive skill lifecycle management.
Practical and Theoretical Implications
SkillReducer demonstrates that structure-aware token optimization is both tractable and effective as a build-time preprocessing step. Its design, inspired by classical debloating, program slicing, and progressive disclosure, systematically enforces separation-of-concerns in skill artifacts, reducing monetary cost and cognitive distraction for LLMs. The findings challenge assumptions underlying token-pruning methods that ignore content structure and highlight the importance of agent-centric modularity. Less-is-more emerges as a general principle: curating the context window to only include essential content improves downstream agent behavior.
From a theoretical perspective, SkillReducer's feedback mechanism guarantees monotone improvement in retention up to a fixpoint, and expected end-to-end cost reduction under progressive disclosure is formally quantifiable (empirical body cost reductions ranging from 26.8% to 77.5%).
Future Directions
Automated skill optimization can be further refined by integrating finer-grained dependency extraction, robust identification of specification-by-example, and adaptive lifecycle management that retires obsolete skills as models become increasingly capable. Structure-aware compression protocols could extend to other LLM-driven artifacts (e.g., tools, workflows) and guide the development of scalable skill marketplaces.
Conclusion
SkillReducer operationalizes structure-aware token optimization for LLM agent skills through delta-debugging-driven routing compression and taxonomy-based progressive disclosure, achieving substantial token savings and improved functional quality. Its framework is robust, modular, and generalizes across models and agent architectures, laying foundational principles for efficient skill authoring and management in LLM-centric ecosystems (2603.29919).