Self-Improving Language Models with Bidirectional Evolutionary Search
Abstract: Search has been proposed as an effective method for self-improving LLMs and agentic systems, both for post-training sample generation and for inference. However, widely used methods such as best-of-N sampling and tree search face two fundamental limitations: they are guided by sparse verification signals, and they construct candidates primarily through autoregressive expansion, restricting exploration to regions with substantial model probability mass. To address these, we propose Bidirectional Evolutionary Search (BES), a search framework that couples forward candidate evolution with backward goal decomposition. In the forward search, BES augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout. In the backward search, BES recursively decomposes the original task into checkable subgoals, producing dense intermediate feedback that guides forward search. We provide theoretical motivation showing that candidates generated by expansion-only search are confined to a narrow entropy shell while evolutionary operators can escape it, and that backward search can exponentially reduce the number of required samples to find a correct answer. Experiments show that on challenging post-training tasks where mainstream post-training algorithms fail to improve, BES enables consistent gains, and on three open problem solving benchmarks at inference time, BES outperforms existing open-source frameworks in both average and best-case performance. Code and trained models are available at https://github.com/Embodied-Minds-Lab/BES.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to help AI LLMs get better at solving hard problems on their own. The method is called Bidirectional Evolutionary Search (BES). It teaches models to:
- explore new ideas by smartly mixing and editing their past attempts, and
- guide that exploration using a step-by-step checklist of smaller goals.
Together, this helps the AI break out of its “comfort zone” and find correct answers more often, especially on tough tasks.
What questions does the paper try to answer?
The authors focus on two big questions:
- How can we make AI try bolder, more creative solutions instead of only what it already thinks is likely?
- How can we give the AI clearer, more frequent hints about whether it’s on the right track, instead of only telling it “right or wrong” at the very end?
How does the method work?
To understand BES, it helps to see what’s wrong with common methods and then how BES fixes it.
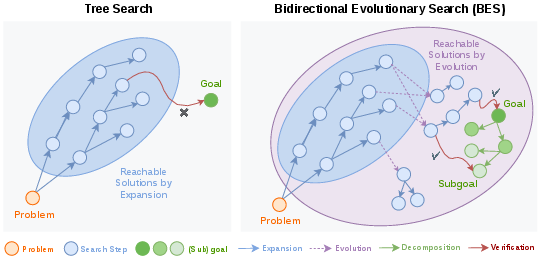
The problem with current methods
- Best-of-N: The model writes N answers and picks the best one. This is simple but can miss rare, correct solutions—like buying more lottery tickets but still playing the same numbers.
- Tree search: The model builds answers step by step, exploring several paths. But it still mostly grows answers in the same way it usually writes, so it sticks close to what it already thinks is likely.
Both methods have two issues:
- Sparse feedback: They mostly get a “yes/no” at the end, which doesn’t help guide the middle steps.
- Limited exploration: They build answers by extending a single path, which makes it hard to jump to creative combinations that the model wouldn’t naturally write in one go.
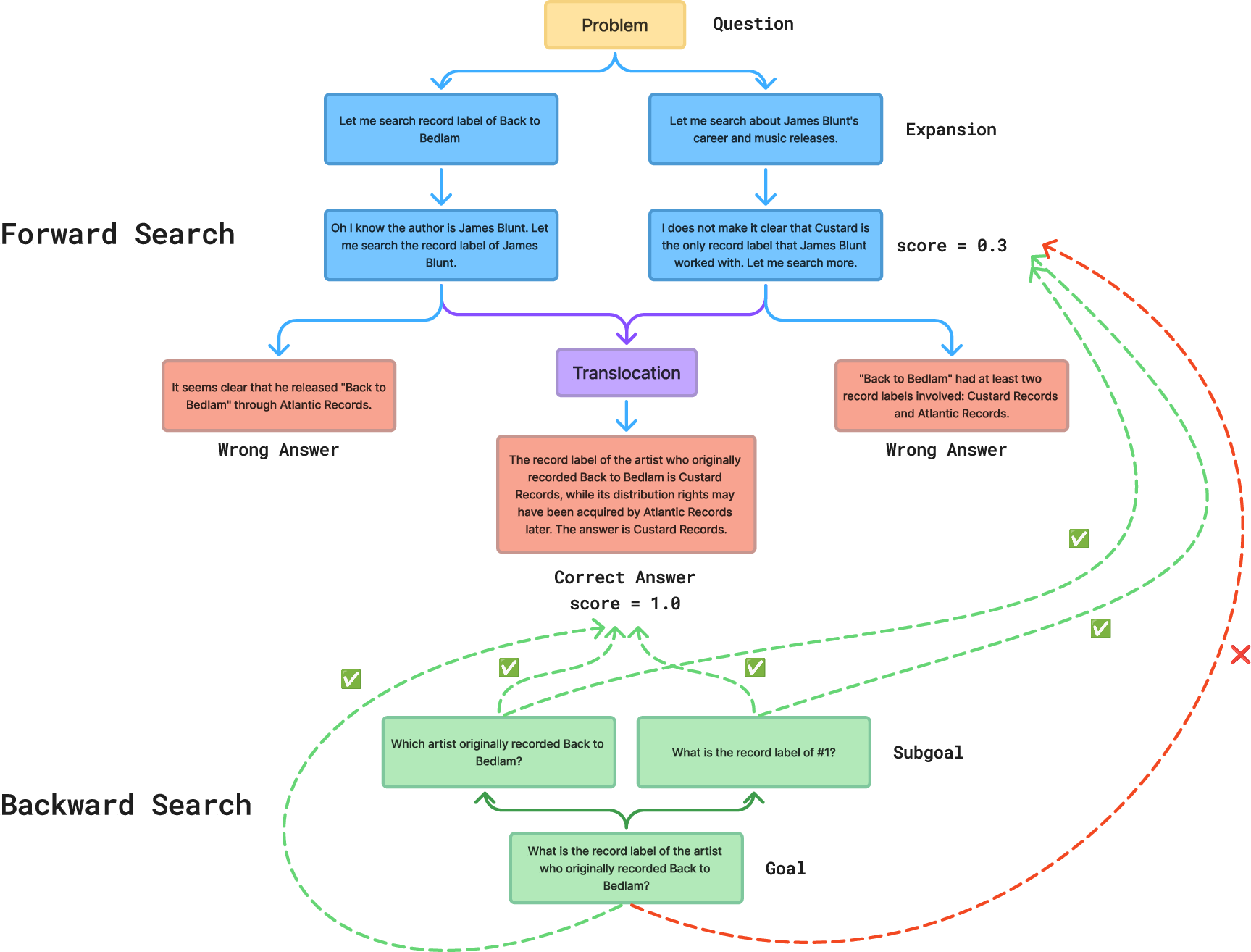
BES forward search: evolve better answers
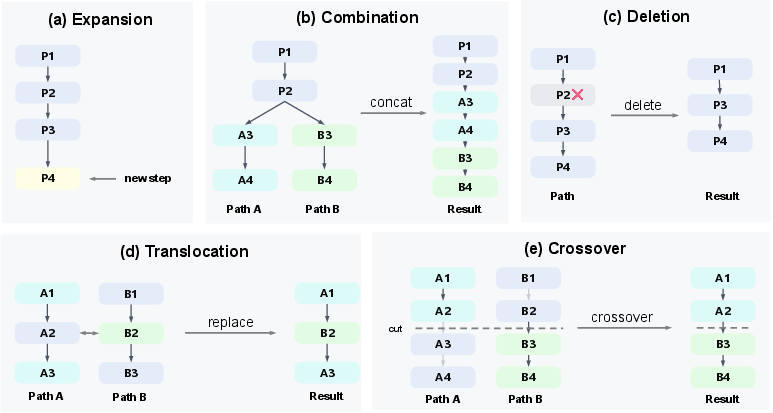
BES treats partial answers like Lego builds and improves them with four “evolution” moves, inspired by biology:
- Combination: If two solutions share a beginning but take different good turns later, merge their good parts into one.
- Deletion: Remove a shaky or useless step to simplify and strengthen the answer.
- Translocation: Take one strong step from one answer and insert it into another.
- Crossover: Cut two answers at a point and swap their endings, like mixing genes from two parents.
These moves help the model create candidates it would rarely produce in a single straight-through try.
BES backward search: make a step-by-step checklist
Instead of just checking the final answer, BES breaks a big problem into smaller, checkable sub-goals—like turning a long homework problem into a checklist. For example, in a math expression, sub-goals might be:
- add these numbers,
- multiply the result,
- divide,
- subtract.
Each partial answer gets scored by how many sub-goals it has correctly handled. This gives the model helpful, frequent feedback and shows which parts still need work.
Why both directions together help (the big idea)
- Forward “evolution” helps the model explore beyond its usual guesses—escaping its “comfort zone” to discover unusual but correct solutions.
- Backward “checklists” give dense, meaningful feedback—telling the model which pieces are right and where to focus next.
The authors also offer simple theory to support this:
- Without evolution, most candidates stay in a narrow “typical” region of what the model usually writes—so it misses rare correct answers.
- With evolution, the search can leap outside that region to explore new combinations.
- With sub-goals, the number of tries needed to find a full solution can drop dramatically, because you can find and reuse partial progress much faster.
What did the experiments show, and why is that important?
The authors tested BES in two ways: during training (to help a model improve itself with better examples) and during inference (solving problems at test time with extra compute).
Here is a brief summary of results:
- Training: On tough logical puzzles (Knights-and-Knaves) and multi-step questions requiring web search (MuSiQue), standard methods like GRPO, MaxRL, and Tree-GRPO struggled or barely improved. BES reliably found higher-quality training samples and improved accuracy more clearly. It also trained agents that actually perform sensible search actions instead of guessing.
- Inference: On open-ended puzzle benchmarks (packing circles into shapes and arranging points to maximize the smallest polygon area), BES beat other open-source systems on both average and best scores and showed more stable performance across runs.
- Component check: Removing either the evolution moves or the backward sub-goal scoring made performance worse, confirming both parts are useful.
- Cost: BES took slightly more time or API calls than some baselines, but the gains in quality and stability were significant and consistent.
Why this matters: When problems are hard and correct answers are rare, simply sampling more isn’t enough. BES finds creative answers more reliably and makes training safer and more effective.
What’s the potential impact?
- Better self-improvement: Models can generate stronger training examples for themselves, speeding up learning and reducing failure modes like reward hacking or random guessing.
- Stronger problem solving: With smarter search and step-by-step guidance, models can tackle more complex tasks in math, logic, planning, coding, and scientific exploration.
- More efficient use of compute: Instead of wasting tries on similar answers, BES targets diverse, promising candidates and learns from partial progress, making each attempt count.
- A general recipe: The idea—evolve candidates forward and guide them with backward checklists—can apply to LLMs, agents, and even code-generation systems.
In short, BES helps AI get out of its comfort zone and learn faster by remixing good ideas and following a clear checklist to the goal.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future work:
- Verifier reliability and sub-goal quality: No systematic evaluation of the accuracy, consistency, or robustness of LLM-generated sub-goals and verifiers across domains, nor safeguards against cascading errors from mis-specified decompositions.
- Sensitivity to verifier noise and reward hacking: While reward hacking is observed in baselines, BES’s resilience to gaming sub-goal verifiers is not quantified; protocols to detect and mitigate sub-goal gaming are unspecified.
- Verifier design choices: Lacks comparative analysis of rule-based checkers vs. test suites vs. LLM judges (cost–quality trade-offs, precision/recall, calibration), and guidance for constructing verifiers in tasks without clear automatic checks.
- Backward decomposition policy: The criterion for when and which leaf to split (frequency K, selection heuristic) is heuristic; sensitivity analyses and adaptive policies are absent.
- Step segmentation: “Step” granularity (tokens, reasoning chunks, actions) is not standardized or justified; impact of segmentation on operator validity, scoring, and performance remains unexplored.
- Evolution operator efficacy: No per-operator ablation, operator-selection probability study, or analysis of how each operator contributes by task type; the benefits and failure modes of combination, translocation, deletion, and crossover are unclear.
- Hyperparameter sensitivity: No study of α (score mixing), τ annealing schedule, λ bonus, Kmax, or population size; lacks tuning guidelines and robustness tests to hyperparameters.
- Parent selection scalability: Pair scoring for two-parent operators is potentially O(n²); no discussion of scalable approximations, memory/computation costs, or batch selection strategies for large populations.
- Validity and repair of recombined candidates: The rate and handling of syntactically/semantically invalid candidates produced by evolution are not reported; absence of automatic repair or constraint enforcement mechanisms.
- Program evolution specifics: For code/program tasks, operator implementation via prompting lacks details (prompt patterns, compiler/runtime failure rates, test coverage), and generality across languages/runtimes is unassessed.
- Theoretical–practical gap (evolution): The “k-time evolution” theoretical model assumes independence that practical operators may not achieve; no formal mapping from concrete operators to the idealized product distribution Q or conditions under which escape guarantees hold.
- Theoretical assumptions validation: Bounded per-step surprise, decaying dependence, and linear block total correlation are unverified in real LLMs; no empirical measurement of H_T, typical-set concentration, or block total correlation on actual tasks.
- Typical-set “entropy shell” in practice: No empirical evidence showing expansion-only candidates concentrate in a narrow shell and that BES escapes it (e.g., estimated log-probability distributions of candidates before vs. after evolution).
- Backward search independence assumption: The exponential sample-complexity gain relies on independent leaf sub-goals and necessity of all sub-goals; many tasks have dependent/overlapping/alternative sub-goal structures—no analysis or extensions to dependent or redundant sub-goals.
- Cost of decomposition: Theoretical gains ignore the overhead of constructing/verifying goal trees; missing accounting of how sub-goal count m and decomposition depth affect wall-clock and token cost.
- Convergence and stopping criteria: BES is budget-limited without principled stopping rules or anytime guarantees; lack of bounds linking budget, operator mix, and success probability.
- Generalization breadth: Experiments span a narrow set of tasks/models (Knights-and-Knaves, MuSiQue, packing/Heilbronn) with small-to-medium open models in training and a closed-source model for inference; transfer to math theorem-proving, complex codebases, planning, or real-world agents is untested.
- Closed-source dependency in inference: Reliance on GPT-5 for open-problem benchmarks limits reproducibility; parity of results with open models or smaller models is not established.
- Compute fairness and reproducibility: Although “same compute” is claimed for some baselines, token-level budgets, prompt lengths, and exact API settings are not exhaustively reported; statistical significance and seed variance (beyond one table) are largely missing.
- Training stability and data shift: Using recombined trajectories for post-training could induce out-of-distribution patterns; impacts on stability (e.g., degeneration, overfitting, forgetting) and long-horizon training dynamics are not analyzed.
- Failure analysis: No qualitative or quantitative analysis of common failure modes (e.g., incoherence from crossover, semantic drift after deletion, brittle sub-goals, dead-ends), nor diagnostic tools to detect them during search.
- Applicability beyond discrete text: Extension to continuous/control domains or non-Markovian environments is not addressed; how to define and validate operators and verifiers in such settings remains open.
- Multi-objective scoring: The framework assumes a single scalar verifier; many applications require trade-offs (e.g., correctness vs. brevity vs. computational cost); no support or study of multi-objective or constrained optimization.
- Interaction with learning algorithms: BES is “agnostic” to the trainer but only tested with GRPO/MaxRL-like pipelines; effects with preference optimization, DPO variants, off-policy corrections, or on-policy RL (credit assignment from sub-goals) are unexplored.
- Decomposition over-dependence: Risk that low-quality decompositions steer search toward suboptimal regions is not studied; no mechanism for revising or pruning erroneous sub-goal trees (e.g., meta-verification or ensemble decomposition).
- Safety and faithfulness: Recombination may yield logically inconsistent or unfaithful reasoning; no evaluation of truthfulness/faithfulness, nor mitigation strategies for hallucination amplification during recombination.
- Robustness under adversarial settings: No tests under adversarial or misleading verifiers/prompts, or distribution shifts in tasks and tools (e.g., retrieval drift), to quantify BES’s robustness margins.
Practical Applications
Immediate Applications
The following applications can be deployed with current LLMs/agents, standard verifiers (tests, rule-based checkers, simulations), and available compute, leveraging BES’s forward evolution + backward goal decomposition to improve sampling for post-training and inference.
- Bold use case: Self-improvement sampler for post-training (RLHF/RLAIF/RLVR)
- Sectors: AI/ML platform teams, foundation model labs, software industry
- How to deploy: Replace best-of-N rollouts in post-training with a BES sampler that (i) recombines partial trajectories and (ii) scores candidates against sub-goal verifiers; feed high-scoring trajectories into GRPO/DPO/MaxRL-style updates
- Potential tools/products/workflows: “BES Sampler” module for TRL-style pipelines; hooks for GRPO, Tree-GRPO, DPO; dataset curation utilities that store trajectories + sub-goal coverage
- Assumptions/dependencies: Task-specific verifiers/sub-goal checkers; training stability monitoring; acceptance of moderate extra compute versus tree search
- Feasibility signal from paper: On logical and multi-hop reasoning, BES reliably finds higher-quality training samples and improves over GRPO/Tree-GRPO
- Bold use case: Test-time scaling for hard reasoning (math, logic, planning)
- Sectors: Education (tutoring/assessment), productivity apps, scientific computing
- How to deploy: Add a “BES Reasoning” mode that decomposes user queries into sub-goals and evolves multiple reasoning paths; return the terminal trajectory with best verified coverage/score
- Potential tools/products/workflows: Inference-time search switch in chatbots; math/logic solvers that show sub-goal satisfaction; audit logs of goal trees for explainability
- Assumptions/dependencies: Verifiers for intermediate steps (symbolic calculators, equation checkers, parsers); acceptance of higher latency/cost for hard queries
- Bold use case: Program synthesis with unit tests as verifiers
- Sectors: Software engineering, DevOps, QA
- How to deploy: Use BES to evolve candidate code snippets/programs; backward search derives sub-goals (e.g., pass specific test categories, satisfy interface constraints); forward evolution uses crossover/patch translocation via prompts
- Potential tools/products/workflows: CI plugins that run BES when tests fail or coverage is low; “BES Fix” buttons in IDEs; code review assistants that present sub-goal pass/fail matrix
- Assumptions/dependencies: High-quality unit tests/specs; sandboxing and execution safety; cost control (tests can be expensive)
- Feasibility signal from paper: BES outperforms open-source evolutionary frameworks on program-evaluated benchmarks and shows lower variance
- Bold use case: Multi-hop question answering and enterprise RAG
- Sectors: Knowledge management, customer support, enterprise search
- How to deploy: Integrate BES into agent toolchains—backward search creates sub-questions; forward search evolves retrieval/action sequences; verifiers check sub-answer consistency, citation completeness
- Potential tools/products/workflows: RAG agents that report sub-goal coverage (retrieved key facts, cross-document consistency) and use recombination to merge partial chains-of-thought
- Assumptions/dependencies: Reliable retrieval; verifiers for factual consistency and citation validation; guardrails to prevent hallucinated sub-goals
- Feasibility signal from paper: BES trained agents show more valid searches and higher finish ratios compared to GRPO/Tree-GRPO
- Bold use case: Optimization of layouts and configurations via simulators
- Sectors: Manufacturing, logistics, EDA/CAD, operations research
- How to deploy: Use BES to evolve candidate configurations (e.g., packing, placement); backward search defines measurable sub-goals (min distance constraints, packing validity); simulators provide verifiers
- Potential tools/products/workflows: “BES Optimizer” wrapper over existing simulators; design-space exploration assistants that combine fragments of good solutions
- Assumptions/dependencies: Fast, reliable simulation/verifiers; prompt-based evolution for non-textual candidate representations
- Bold use case: Step-verified intelligent tutoring
- Sectors: Education technology, assessment
- How to deploy: Decompose problems into sub-steps (backward search); generate/compose student-facing solutions that satisfy intermediate checks; present sub-goal progress as feedback
- Potential tools/products/workflows: Tutors that score and explain each step; item bank authoring tools that auto-generate step rubrics; automated graders that accept multiple valid reasoning paths
- Assumptions/dependencies: Calibrated step verifiers; alignment of sub-goal rubrics with curricula; safeguards against revealing complete answers prematurely
- Bold use case: Safer agent behaviors by dense intermediate verification
- Sectors: Agentic systems (web automation, workflow orchestration), compliance/conduct risk
- How to deploy: Express task constraints and critical checks as sub-goals; use backward scores to prioritize expansions that meet constraints; use evolution to repair trajectories failing safety checks
- Potential tools/products/workflows: “BES-Guarded Agent” that won’t finalize unless safety sub-goals are satisfied; dashboards showing which guardrails are met
- Assumptions/dependencies: High-precision verifiers for safety/compliance; careful design to avoid reward hacking on proxy metrics
- Feasibility signal from paper: Backward search mitigates reward hacking and increases valid action rates in agents
- Bold use case: Higher-stability search for high-value tasks
- Sectors: MLOps, platform reliability
- How to deploy: Use BES when variance in solution quality across runs is costly (e.g., release-time code gen, report generation); select final candidates with best sub-goal coverage
- Potential tools/products/workflows: Reliability-focused inference profiles that enable BES; A/B frameworks logging goal-coverage statistics
- Assumptions/dependencies: Acceptance of increased cost/latency; robust, interpretable sub-goals to justify run selection
- Feasibility signal from paper: BES shows lower performance variance than baselines on open problem benchmarks
Long-Term Applications
These applications are promising but require further research, more mature verifiers/simulators, scalable compute, or domain integration beyond current off-the-shelf capabilities.
- Bold use case: Autonomous scientific discovery and open problem solving
- Sectors: Mathematics, materials science, drug discovery, systems biology
- Vision: Use BES to decompose hypotheses into testable sub-goals and evolve candidate theories/experiments/models; recombine partial insights across lineages
- Potential tools/products/workflows: “BES Lab Assistant” integrating lab-notebook LLMs with high-fidelity simulators/automated experiments; theorem-proving pipelines using formal verifiers
- Assumptions/dependencies: Trustworthy, domain-grade verifiers (formal checkers, validated simulators, lab automation); strong safeguards against spurious correlations; substantial compute
- Bold use case: Long-horizon robotics and embodied planning
- Sectors: Industrial automation, logistics, assistive robotics
- Vision: Backward decomposition into skill primitives/subtasks; forward evolution recombines successful motion/skill sequences across trials; dense feedback accelerates exploration
- Potential tools/products/workflows: Hierarchical planners that evolve skill graphs; sim-to-real pipelines where sub-goal verifiers are perception and task success metrics
- Assumptions/dependencies: Reliable sub-goal detection; sim-real transfer; safety around evolving low-probability behaviors; real-time constraints
- Bold use case: Energy and grid optimization
- Sectors: Power systems, smart grids, data center operations
- Vision: Represent dispatch/scheduling constraints as sub-goals; use BES to evolve feasible schedules/policies and recombine partial successes under uncertainty
- Potential tools/products/workflows: “BES Scheduler” for grid dispatch or microgrid control; what-if scenario planners with verifiable constraints
- Assumptions/dependencies: High-fidelity, real-time simulators; regulatory constraints as machine-checkable verifiers; robustness and safety certification
- Bold use case: Finance strategy discovery and risk-aware planning
- Sectors: Asset management, algorithmic trading, credit risk
- Vision: Sub-goals reflect factor exposure, drawdown, liquidity, and compliance constraints; strategies evolve and recombine based on backtesting verifiers
- Potential tools/products/workflows: Research platforms that evolve strategies under realistic cost/slippage models; “BES Risk Engine” monitoring sub-goal satisfaction
- Assumptions/dependencies: Accurate backtesting with survivorship-bias control; anti-overfitting protocols; regulatory oversight and auditability
- Bold use case: Policy drafting, analysis, and compliance engineering
- Sectors: Public policy, legal tech, enterprise governance
- Vision: Decompose statutes or policies into verifiable obligations; evolve draft language that satisfies sub-goals and recombine compliant sections
- Potential tools/products/workflows: Compliance authoring assistants that verify obligations/constraints; change-impact analyzers comparing sub-goal coverage across versions
- Assumptions/dependencies: Machine-checkable interpretations of legal requirements; expert-in-the-loop verification; ethical and jurisdictional safeguards
- Bold use case: Personalized education and mastery learning at scale
- Sectors: K–12, higher ed, corporate training
- Vision: Build per-learner goal trees; evolve instructional paths and problem sequences tailored to sub-goal mastery; recombine effective micro-lessons
- Potential tools/products/workflows: Mastery platforms that adaptively evolve curricula; formative assessment engines logging sub-goal attainment
- Assumptions/dependencies: Validated sub-goal rubrics/psychometrics; fairness and bias auditing; longitudinal data governance
- Bold use case: General-purpose combinatorial optimization service
- Sectors: Logistics, manufacturing, chip design, network design
- Vision: “BES-as-a-Service” where users register objective functions and verifiers; the system decomposes constraints into sub-goals and evolves solutions with recombination
- Potential tools/products/workflows: Cloud APIs for problem templates (routing, packing, scheduling); hybrid solvers combining BES with OR methods
- Assumptions/dependencies: Problem-specific verifiers/simulators; scaling to large search spaces; cost controls and performance SLAs
- Bold use case: Multi-agent system design and coordination
- Sectors: Swarm robotics, distributed systems, marketplaces
- Vision: Decompose global objectives into agent-specific sub-goals; evolve and recombine policies/communication protocols across agent populations
- Potential tools/products/workflows: Protocol synthesizers that iteratively evolve and evaluate coordination strategies; simulators with verifiable multi-agent metrics
- Assumptions/dependencies: Reliable multi-agent evaluation; stability and convergence guarantees; safety around emergent behaviors
Glossary
- Ablation study: A controlled experiment removing components to assess their contribution to overall performance. "We conduct an ablation study on the Knights-and-Knaves benchmark."
- Agentic systems: AI systems that act through sequences of decisions/actions in an environment, often guided by goals or feedback. "LLMs and agentic systems have demonstrated remarkable capabilities"
- AlphaEvolve: A closed-source evolutionary framework used as a high-compute reference for program synthesis and problem solving. "AlphaEvolve~\citep{alphaevolve}"
- Annealing (temperature): Gradually lowering a sampling temperature parameter to shift from exploration to exploitation during search. "The temperature is annealed linearly from an initial value"
- Autoregressive expansion: Constructing candidates by sequentially appending steps/tokens according to the model’s conditional probabilities. "construct candidates primarily through autoregressive expansion,"
- Beam search: A tree search heuristic that keeps the top-k partial candidates at each step to explore promising branches. "Tree search methods such as beam search and Monte Carlo Tree Search~\citep{mcts}"
- Best-first search: A search strategy that expands the most promising node according to a heuristic score. "Classic methods include beam search, best-first search, and Monte Carlo Tree Search~\citep{mcts};"
- Best-of-N sampling: Generating N independent candidates and selecting the one with the highest verifier score. "Best-of-N sampling is simple and efficient."
- Bidirectional Evolutionary Search (BES): The paper’s proposed framework combining forward evolutionary search with backward goal decomposition for dense guidance. "we propose Bidirectional Evolutionary Search (BES)"
- Bidirectional search: Coupled forward and backward procedures that generate candidates and decompose goals to provide dense verification signals. "we introduce bidirectional search: the forward search seeks better candidate solutions, while the backward search discovers finer-grained sub-goals"
- Boltzmann distribution: A probabilistic selection mechanism that samples options with probability proportional to the exponential of a score divided by temperature. "we sample the parent from a Boltzmann distribution over backward score"
- Circle Packing: A geometric optimization task of placing circles to maximize radius (or density) within a container. "Circle Packing (Square), which seeks to pack circles into a unit square with maximum radius"
- Combination (operator): An evolution operator that merges two trajectories by concatenating their distinct suffixes beyond a shared prefix. "Combination merges two trajectories by concatenating their suffixes beyond a shared prefix"
- Crossover (operator): An evolution operator that splices the prefix of one trajectory with the tail of another. "Crossover splices the prefix of one trajectory onto the tail of another."
- Decaying step dependence: An assumption that the influence of earlier steps on later ones diminishes with temporal distance. "\begin{assumption}[Decaying step dependence]"
- Deletion (operator): An evolution operator that removes an interior step to shorten and potentially simplify a trajectory. "Deletion removes one interior step, producing a shorter candidate"
- Entropy shell: The narrow band of trajectory probabilities around the model’s entropy where expansion-only search is confined. "responses generated by expansion-only search are confined to a narrow entropy shell"
- Evolution operators: Non-autoregressive edits that recombine or modify trajectories (combination, translocation, deletion, crossover) to explore beyond model-likely regions. "we introduce four evolution operators: combination, translocation, deletion, and crossover."
- Expansion (operator): The standard forward operator that extends a trajectory by sampling additional steps from the policy. "Expansion extends a parent node by sampling new steps."
- Forward search: The process that proposes and evolves candidate trajectories toward higher-quality solutions. "a forward search that seeks better candidates,"
- GEPA: An open-source evolutionary framework baseline for program synthesis/problem solving compared against BES. "including OpenEvolve~\citep{openevolve}, GEPA~\citep{gepa}, and ShinkaEvolve~\citep{shinkaevolve}"
- Goal decomposition: Splitting a task into finer sub-goals to provide dense, intermediate verification signals. "backward goal decomposition."
- Goal tree: A hierarchical structure of sub-goals used to score partial trajectories during backward search. "producing a rooted backward goal tree."
- GRPO: A post-training algorithm (Group Relative Preference Optimization) widely used for generating and scoring samples. "post-training algorithms such as GRPO~\citep{dsr1}"
- Heilbronn (Convex) problem: A geometric placement problem maximizing the minimum area of any convex polygon formed by a set of points. "and the Heilbronn Convex problem."
- Linear block total correlation: An assumption that inter-block dependence (total correlation across trajectory segments) grows linearly with trajectory length. "\begin{assumption}[Linear block total correlation]"
- MaxRL: A post-training method baseline compared with BES in challenging settings. "mainstream post-training algorithms such as GRPO~\citep{dsr1}, MaxRL~\citep{maxrl}"
- Monte Carlo Tree Search (MCTS): A search algorithm using randomized simulations and tree statistics to guide exploration. "Tree search methods such as beam search and Monte Carlo Tree Search~\citep{mcts}"
- MuSiQue dataset: A multi-hop QA dataset requiring retrieval and integration across documents. "we use the MuSiQue dataset~\citep{musique}."
- OpenEvolve: An open-source evolutionary baseline framework for program evolution and problem solving. "including OpenEvolve~\citep{openevolve}, GEPA~\citep{gepa}, and ShinkaEvolve~\citep{shinkaevolve}"
- Pair score: A metric evaluating the joint coverage of sub-goals by two candidate trajectories to select complementary parents. "we further define a pair score that measures their joint coverage of the goal tree."
- Policy: The conditional generative model (e.g., LLM or agent) producing steps/trajectories given a problem. "Given a policy "
- Post-training: Additional training stage after pretraining/supervised fine-tuning that uses generated samples and verifiers to improve models. "For post-training, we test on challenging logical reasoning and multi-hop reasoning tasks"
- Reward hacking: Degenerate behavior where a model exploits the reward signal (or verifier) without truly solving the task. "likely due to reward hacking where the model learns to skip search actions and guess directly"
- ShinkaEvolve: An open-source base framework using evolutionary program modifications, on top of which BES is applied for inference. "We apply BES\ on top of ShinkaEvolve."
- Sub-goals: Fine-grained intermediate objectives derived from the main task to enable dense verification. "break each goal into finer sub-goals"
- Test-time scaling: Improving performance by allocating more computation (e.g., larger searches) during inference. "they serve as a natural mechanism for test-time scaling"
- Translocation (operator): An evolution operator that replaces a step in one trajectory with a step from another trajectory. "Translocation transplants a single step from one trajectory into another"
- Tree of Thoughts (ToT): A reasoning-time search framework that explores multiple reasoning paths by branching thoughts. "Tree of Thoughts explores multiple reasoning paths at inference time~\citep{tot}."
- Tree-GRPO: A post-training variant that integrates tree search for generating higher-quality samples. "Tree-GRPO leverages tree search for sample generation during post-training~\citep{treegrpo}"
- Typical set: The set of trajectories whose negative log-probability is within a small tolerance of the entropy, capturing most of the probability mass. "define the typical set ."
- Verifier: A scoring function that evaluates how well a trajectory solves the problem or a sub-goal. "where is a verifier"
Collections
Sign up for free to add this paper to one or more collections.