Controlled Self-Evolution for Algorithmic Code Optimization
Abstract: Self-evolution methods enhance code generation through iterative "generate-verify-refine" cycles, yet existing approaches suffer from low exploration efficiency, failing to discover solutions with superior complexity within limited budgets. This inefficiency stems from initialization bias trapping evolution in poor solution regions, uncontrolled stochastic operations lacking feedback guidance, and insufficient experience utilization across tasks. To address these bottlenecks, we propose Controlled Self-Evolution (CSE), which consists of three key components. Diversified Planning Initialization generates structurally distinct algorithmic strategies for broad solution space coverage. Genetic Evolution replaces stochastic operations with feedback-guided mechanisms, enabling targeted mutation and compositional crossover. Hierarchical Evolution Memory captures both successful and failed experiences at inter-task and intra-task levels. Experiments on EffiBench-X demonstrate that CSE consistently outperforms all baselines across various LLM backbones. Furthermore, CSE achieves higher efficiency from early generations and maintains continuous improvement throughout evolution. Our code is publicly available at https://github.com/QuantaAlpha/EvoControl.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI code-writing systems to not just make programs that work, but to make programs that are fast and use less memory. The authors introduce a new way for an AI to improve its own code over several tries, called Controlled Self-Evolution (CSE). It helps the AI avoid getting stuck with bad ideas, make smart changes using feedback, and remember useful lessons for future problems.
Key Objectives
The paper focuses on a simple question: how can an AI quickly find better, more efficient code with only a limited number of attempts?
To answer that, the authors try to:
- Start the AI with several different plan ideas so it doesn’t get stuck in one bad approach.
- Guide the AI’s changes using test results and performance feedback (not just random edits).
- Help the AI remember what worked and what didn’t, both within a single problem and across different problems.
Methods and Approach
Think of the AI like a student improving homework:
- It writes some code.
- Runs it against tests to see if it’s correct and how fast it is.
- Uses the feedback to improve the code.
- Repeats this several times.
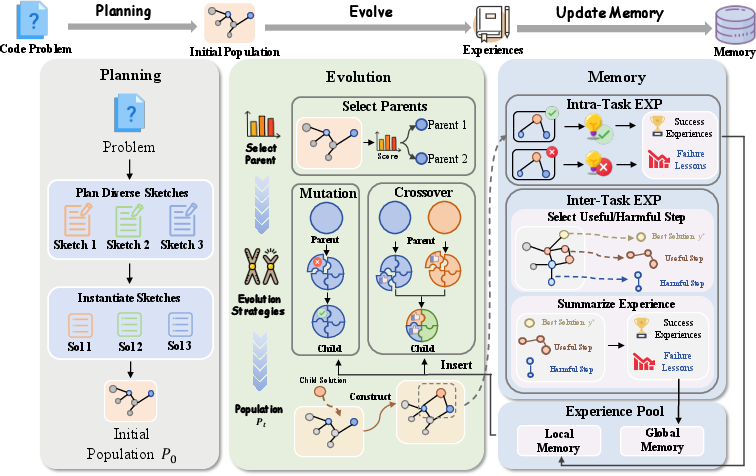
CSE organizes this improvement in three parts:
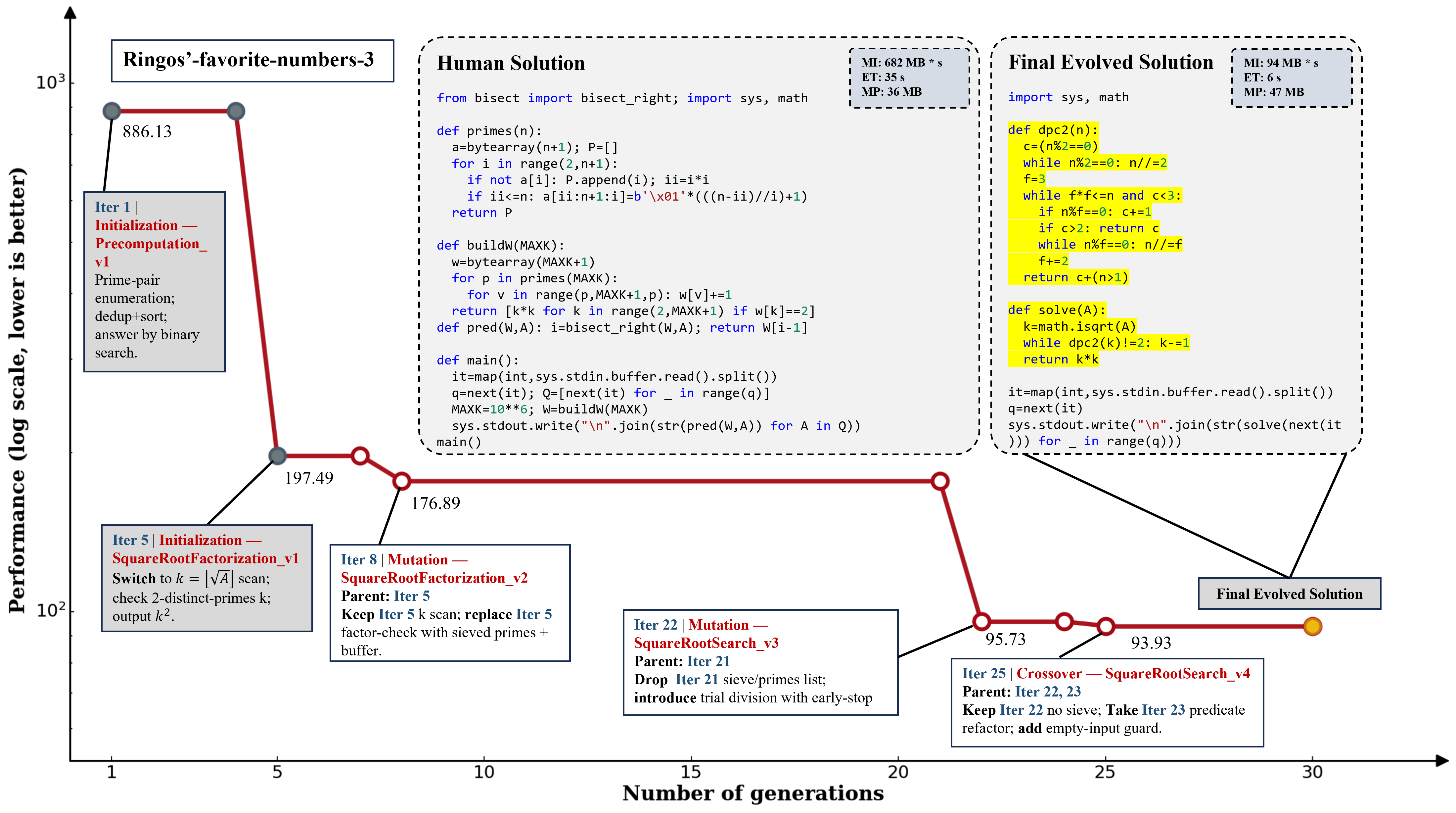
- Diversified Planning Initialization: Before writing full code, the AI brainstorms multiple different strategies (for example, “greedy,” “dynamic programming,” or “bit tricks”) and then turns each strategy into a complete program. This is like starting with several different game plans instead of repeating one idea.
- Genetic Evolution: This borrows ideas from biology (but stays very practical):
- Controlled Mutation: The AI breaks the code into parts (like input reading, core algorithm, edge-case handling). If tests show one part is causing problems, the AI fixes only that part while keeping good parts unchanged. Think “repair the broken gear without rebuilding the whole machine.”
- Compositional Crossover: If one version is super fast and another is more robust, the AI combines those strengths into a new program. This is like mixing the best paragraphs from two essays into one stronger essay.
- Parent Selection: The system doesn’t only pick the single best version to improve. It also keeps some lower-scoring versions in the mix because they might contain a clever piece worth reusing.
- Hierarchical Evolution Memory: The AI keeps helpful notes to guide future attempts:
- Local Memory (within the same problem): It records what changes improved the code and what changes made it worse, so it won’t repeat mistakes.
- Global Memory (across many problems): It stores patterns and tips that worked on similar tasks in a searchable “experience library,” so it can quickly reuse winning ideas later.
The team tested CSE on EffiBench-X, a big set of programming problems (like those on AtCoder, Codeforces, and LeetCode), with strict time and memory rules. They measured:
- ET (Execution Time ratio): How fast the AI’s code runs compared to a human solution.
- MP (Memory Peak ratio): How much peak memory it uses compared to a human solution.
- MI (Memory Integral ratio): A combined score that tracks memory use over time.
Main Findings and Why They Matter
- Across two languages (Python and C++), CSE consistently beat other methods on efficiency metrics (ET, MP, MI).
- It worked well no matter which AI model was used (Qwen3, DeepSeek, Claude, GPT-5).
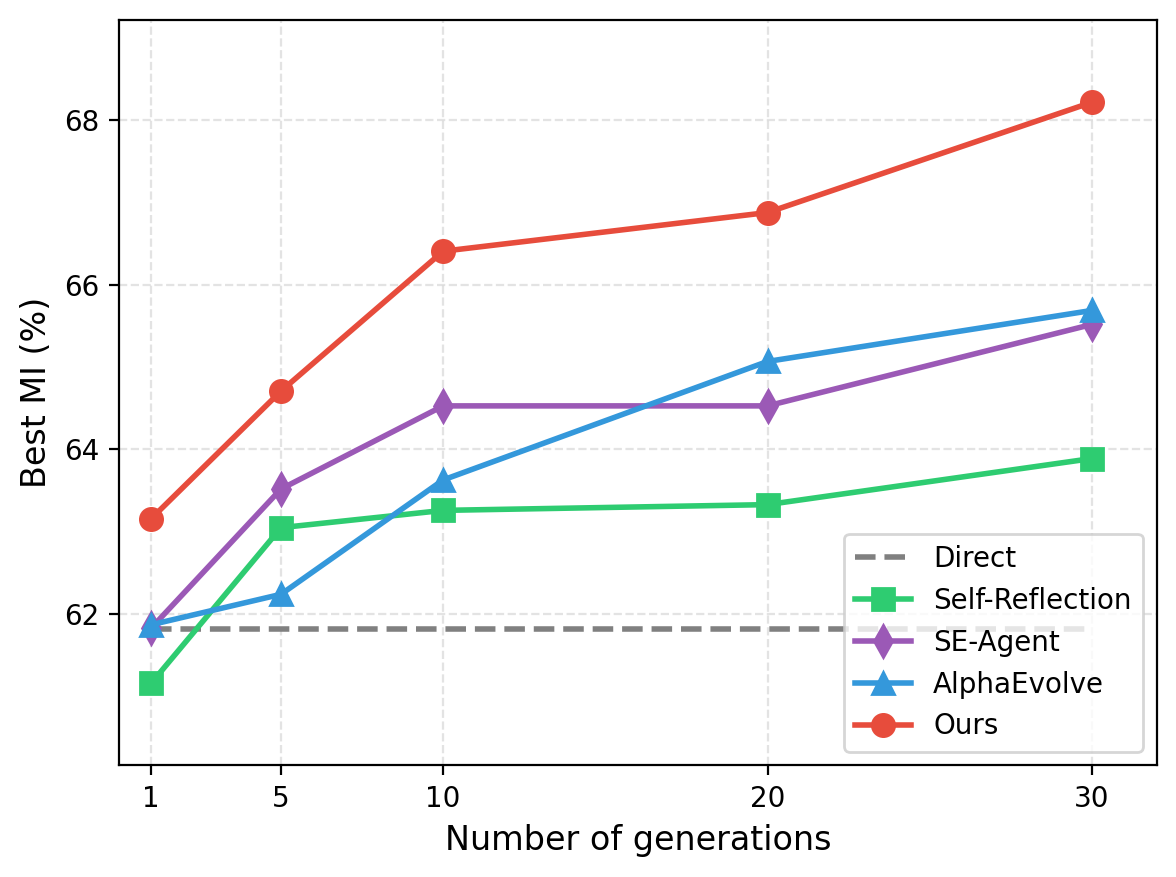
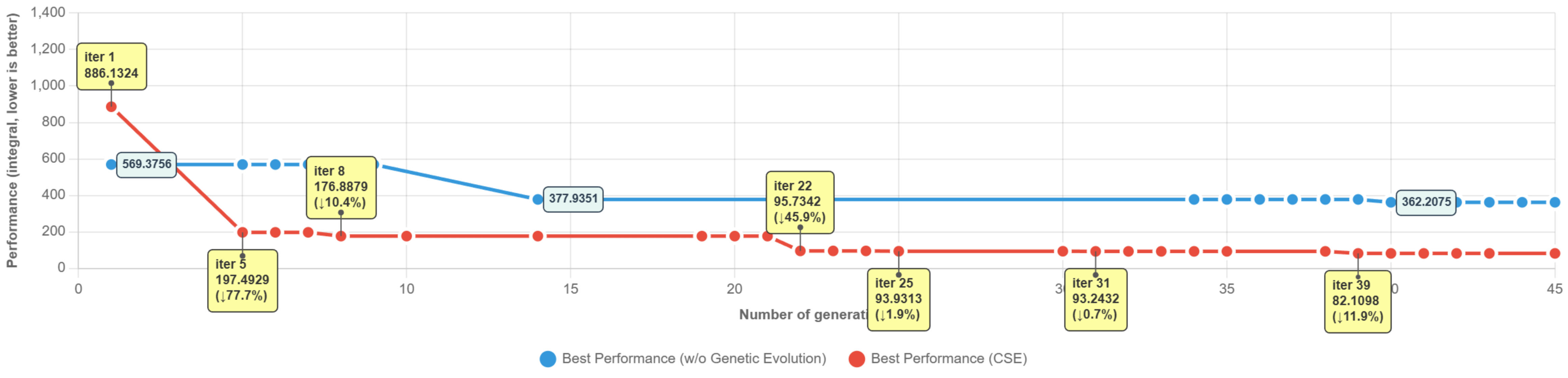
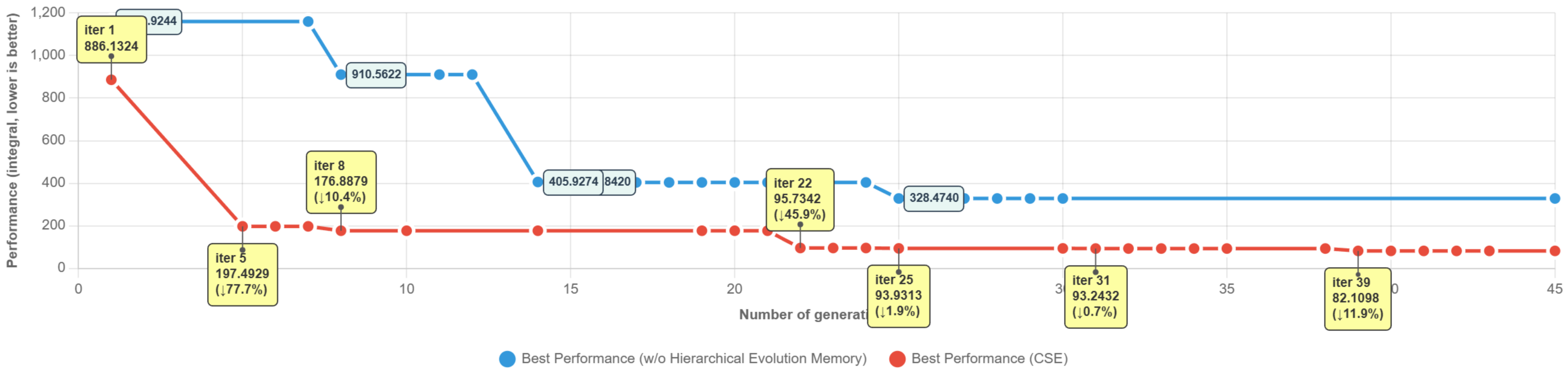
- CSE improved quickly in early tries and kept improving later, meaning it uses limited attempts wisely.
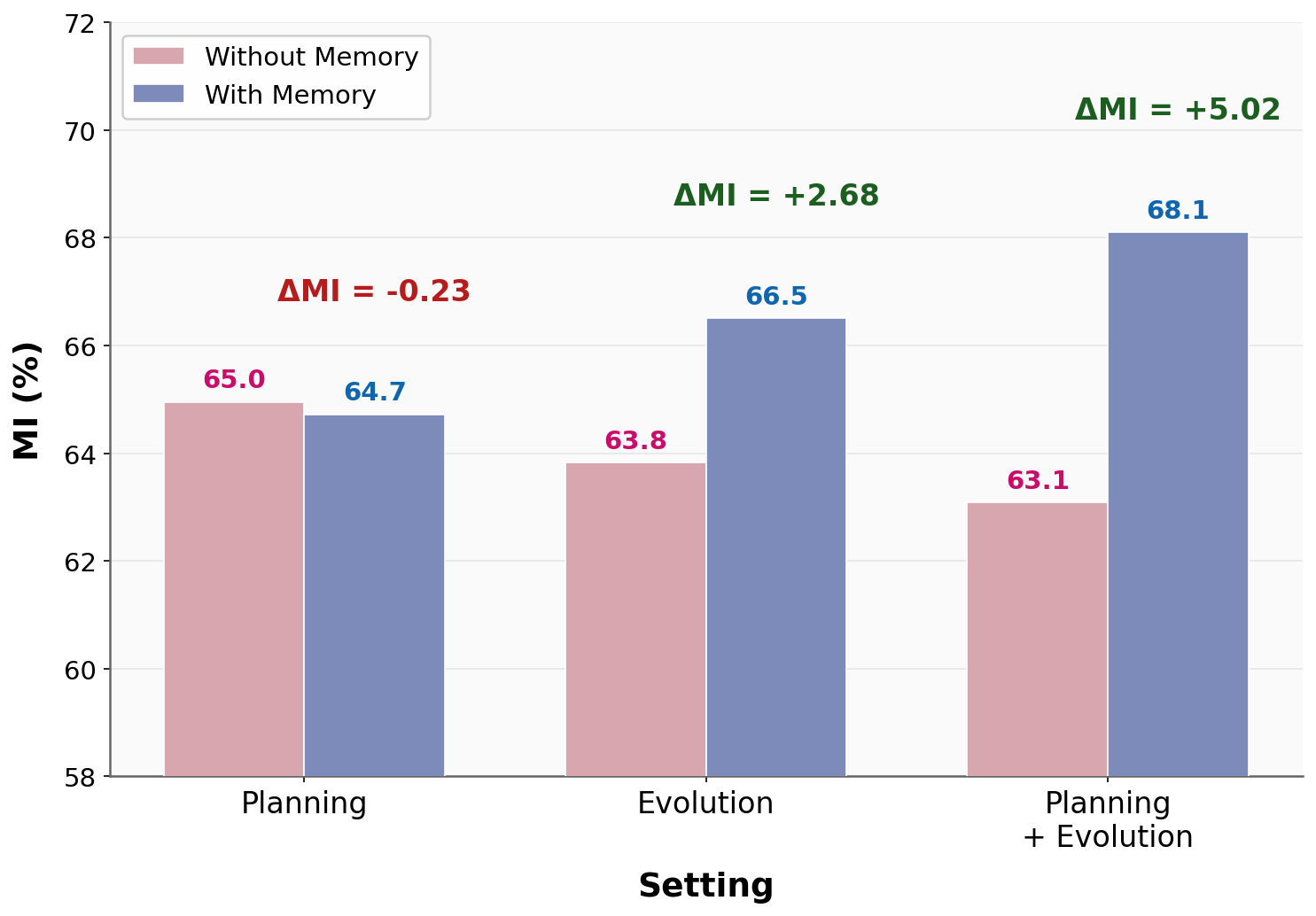
- When the authors removed parts of CSE in tests:
- Taking away the memory hurt performance the most.
- Removing diversified planning or controlled evolution also reduced gains.
- This shows all three parts are important and work best together.
- CSE made more frequent improvements and didn’t stall near the end, showing stronger, steady progress.
These results matter because efficient code runs faster, costs less (especially in the cloud), and handles large inputs better.
Implications and Impact
CSE shows a practical way to get AI to write not just correct code, but smart, efficient code with fewer tries. This could:
- Help developers and students get better solutions faster.
- Reduce computing costs and energy use by creating leaner programs.
- Be adapted to other “write–test–improve” tasks beyond coding (like data processing or planning).
- Eventually be used to train base AI models directly, so they start off better at optimization from the first attempt.
In short, CSE makes AI code improvement more like a careful, guided search than a random trial-and-error process, turning feedback and experience into steady progress toward high-quality, efficient programs.
Knowledge Gaps
Below is a single, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Scope of evaluation: CSE is only tested on Python and C++, leaving generalization to other languages (e.g., Java, Rust, Go, TypeScript), multi-file projects, build systems, and ecosystems with different runtime behaviors unexplored.
- Correctness-treatment mismatch: Although the reward function claims to capture correctness and efficiency, efficiency is measured only on tasks already solved by Direct, masking CSE’s impact on correctness, failure recovery, and ability to solve previously unsolved tasks.
- Real-world applicability: The method is evaluated on algorithmic tasks; its effectiveness on production code (multi-module, large repositories, dependencies, concurrency, I/O, GPU/parallelization) is unexplored.
- Runtime measurement robustness: The paper does not quantify hardware variance, caching/JIT warm-ups, GC effects, OS noise, or run-to-run variability; error bars and statistical significance for ET, MP, MI are absent.
- Asymptotic complexity verification: Claims of superior algorithmic complexity are inferred from runtime/memory metrics on fixed test sets rather than explicit Big-O estimation (e.g., controlled input scaling and complexity classification), leaving true asymptotic gains uncertain.
- Cost–benefit analysis: Exploration efficiency is claimed, but end-to-end costs (LLM token usage, wall-clock latency, energy) and throughput under real resource constraints are not reported.
- Hyperparameter sensitivity: The influence of N_init, T (iterations), selection temperature, parent-selection schedule, top-K in memory, and N_q (queries) is not analyzed; no guidance on robust defaults or tuning is provided.
- Diversity quantification: Diversified Planning Initialization lacks a formal metric for “structural diversity,” coverage, and redundancy control; it is unclear how to ensure diverse algorithmic families rather than superficial variants.
- Functional decomposition reliability: The method assumes the LLM can accurately decompose code into components; decomposition accuracy, stability across tasks, and failure cases (mislocalized faults, overlapping components) are unmeasured.
- Controlled mutation failure modes: Targeted repairs may break hidden invariants or interfaces; there is no measurement of mutation-induced regressions, semantic drift, or rollback mechanisms when localized edits misfire.
- Compositional crossover safety: Interface mismatches, dependency conflicts, and inconsistent assumptions across recombined components are not discussed; no safeguards or validation strategies for structural integration are reported.
- Memory quality and negative transfer: Hierarchical Evolution Memory lacks evaluation of hallucinated, stale, or harmful experiences; strategies to detect, prevent, or mitigate negative transfer across tasks are not provided.
- Memory compression fidelity: Semantic compression of local memory is proposed without evaluating information loss, drift over long runs, or trade-offs between recall and prompt budget pressure.
- Retrieval design specifics: The global memory’s vector database lacks details on embedding choices, indexing, cross-language retrieval, query generation calibration, and data contamination risks; retrieval precision/recall is not quantified.
- Pareto trade-offs: The framework aggregates ET, MP, MI but does not analyze Pareto fronts or user-controllable trade-offs; how CSE navigates competing objectives (e.g., runtime vs memory) remains unclear.
- Baseline comparability: Reproducing AlphaEvolve via OpenEvolve may introduce prompt or implementation differences; the paper does not fully audit prompt equality, reward parity, or agent tooling to ensure fairness.
- Theoretical guarantees: There is no analysis of convergence properties, sample-efficiency bounds, or conditions under which controlled evolution outperforms stochastic search in theory.
- Robustness across LLM capabilities: “Model-agnostic” claims are not validated on smaller/weaker models; minimal capability thresholds and degradation curves with weaker backbones are unknown.
- Safety and maintainability: Efficiency-oriented edits could reduce readability, portability, or rely on undefined behavior (especially in C++); impacts on code quality, security, and maintainability are not assessed.
- Failure recovery: Strategies for escaping collectively poor initial populations or correcting persistent failure loops are not studied; mechanisms for diversification refresh or adaptive exploration are missing.
- Task distribution effects: Sensitivity to input distribution shifts, adversarial cases, and out-of-domain tasks is not evaluated; generalization under changing constraints or time/memory limits is uncertain.
- Memory governance and privacy: Storing cross-task experiences in a global database raises questions about privacy, licensing, and contamination (e.g., proprietary code patterns), which are not addressed.
- RL/finetuning integration: As noted in the Limitations, trajectories are not distilled into training signals; open questions include reward design, off-policy stability, credit assignment, and avoiding reward hacking when amortizing CSE into base models.
- Debugging/verification tooling: The paper does not specify static/dynamic analysis tools to validate edits, verify invariants, or detect undefined behavior; integrating program analyses could improve reliability but is unexplored.
- Early- vs late-stage dynamics: While MI curves are shown for one backbone, broader analysis across models and budgets (e.g., learning curves, improvement distributions, diminishing returns) is limited.
- Reproducibility details: Environment specs (CPU/OS, compilers, interpreter versions), exact harness settings, and seeds are not fully reported; reproducibility and cross-lab consistency need stronger documentation.
Glossary
- Algorithmic code efficiency optimization: Formalization of the task of making code both correct and efficient. "We formalize the algorithmic code efficiency optimization task as follows."
- Compositional Crossover: An evolution operator that recombines complementary code components at the logic level. "Compositional Crossover. To facilitate the flow of advantageous traits across the population, we introduce compositional crossover, which performs logic-level recombination of strengths rather than naive textual concatenation."
- Controlled Mutation: Targeted modification of a localized faulty component while preserving other components. "Controlled Mutation. The agent employs self-reflection to identify the specific faulty component c_{\text{faulty}$ responsible for low reward."
- Controlled Self-Evolution (CSE): A framework that guides iterative code improvement through diversified initialization, controlled evolution, and memory. "We propose Controlled Self-Evolution (CSE), which consists of three key components."
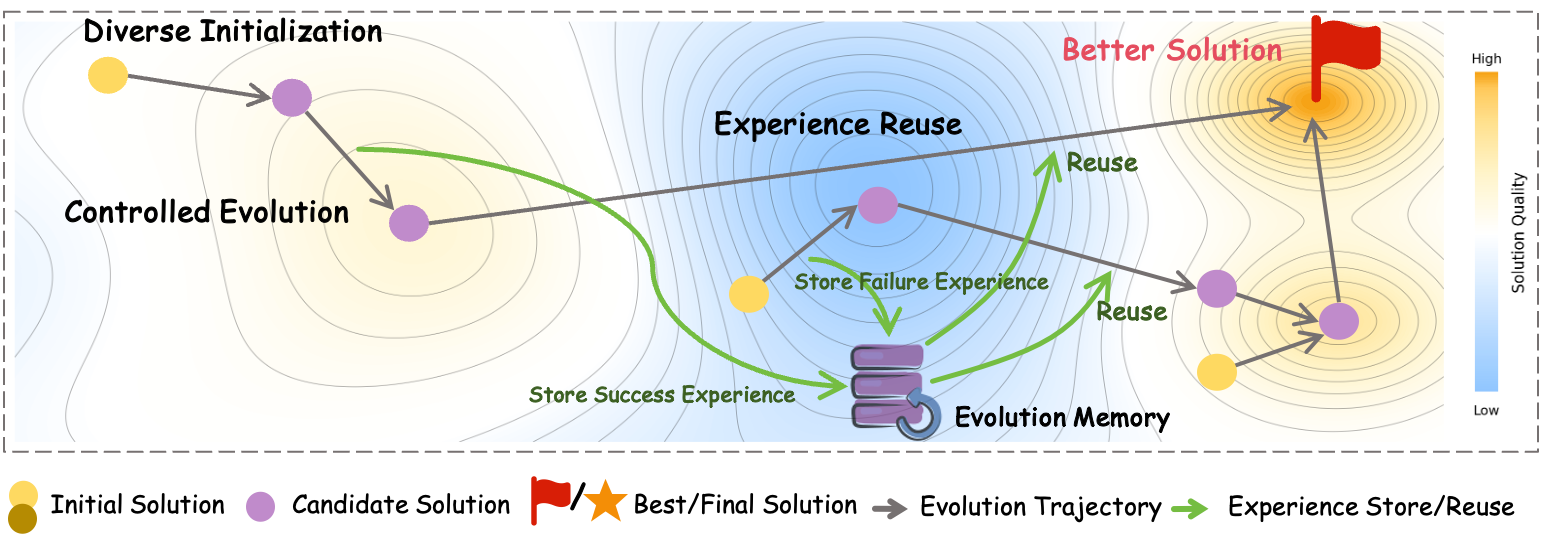
- Diversified Planning Initialization: Generating multiple distinct high-level solution strategies before instantiating them into code. "Diversified Planning Initialization generates structurally distinct algorithmic strategies for broad solution space coverage."
- EffiBench-X: A benchmark for measuring efficiency of LLM-generated code across languages and problems. "Experiments on EffiBench-X demonstrate that CSE consistently outperforms all baselines across various LLM backbones."
- Evolutionary resampling: Population-based exploration that resamples candidates with mutations to search the solution space. "Population-based approaches such as AlphaEvolve employ evolutionary resampling with stochastic mutations, while SE-Agent introduces trajectory-level evolution via step-wise recombination."
- Exploration budget: The limited number of iterations/candidates allowed during search. "within a limited exploration budget."
- Exploration efficiency: How effectively the search process finds better solutions given constrained resources. "Controlled Self-Evolution improves exploration efficiency."
- Execution-Time ratio (ET): A normalized metric comparing runtime of LLM-generated code to human solutions. "we report three normalized efficiency metrics: Execution-Time ratio (ET), Memory-Peak ratio (MP) and Memory-Integral ratio (MI)"
- Functional decomposition: Breaking code into disjoint functional components to enable fine-grained interventions. "functional decomposition enables targeted mutation that refines faulty components while preserving high-performing parts"
- Genetic Evolution: Feedback-guided selection, mutation, and crossover tailored for code optimization. "Genetic Evolution replaces stochastic operations with feedback-guided mechanisms"
- Global Memory: Cross-task experience store that distills and retrieves reusable optimization patterns. "Global Memory. $\mathcal{M}_{\text{glb}$ aims to distill and reuse inter-task experiences."
- Hierarchical Evolution Memory: A two-level memory (local and global) that captures and reuses experiences across and within tasks. "Hierarchical Evolution Memory captures both successful and failed experiences at inter-task and intra-task levels."
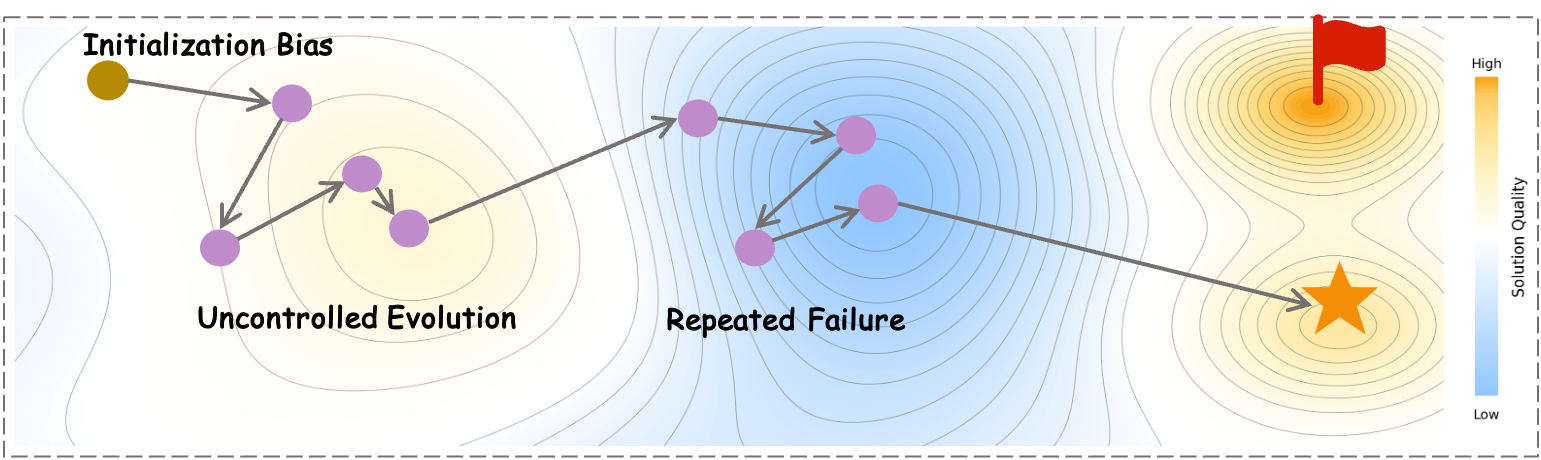
- Initialization bias: Starting evolution from suboptimal regions due to limited or biased initial solutions. "First, initialization bias: methods \cite{afterburner,effilearner} typically begin evolution from a single or few initial solutions generated by the base model, which may lie in poor regions of the solution space"
- LLM backbones: The underlying model architectures used as the base for code generation. "across various LLM backbones."
- Local Memory: Intra-task experience buffer that records and compresses success and failure insights during evolution. "Local Memory. $\mathcal{M}_{\text{local}$ aims to capture immediate experiences from intra-task search trajectories."
- Memory–Time Integral: A reward signal combining runtime and memory usage into a single integral measure. "the reward is the raw memory--time integral, inverted into a maximization score"
- Memory-Integral ratio (MI): A normalized metric comparing overall memory usage integral to human solutions. "we report three normalized efficiency metrics: Execution-Time ratio (ET), Memory-Peak ratio (MP) and Memory-Integral ratio (MI)"
- Memory-Peak ratio (MP): A normalized metric comparing peak memory usage to human solutions. "we report three normalized efficiency metrics: Execution-Time ratio (ET), Memory-Peak ratio (MP) and Memory-Integral ratio (MI)"
- Normalized reward: Scaling of rewards so selection probabilities reflect relative quality within a population. "We design a probability-based parent selection strategy where the selection probability of each candidate is proportional to its normalized reward:"
- Population-based evolutionary process: Optimization that maintains and evolves a set of candidate solutions over iterations. "The optimization unfolds as a population-based evolutionary process over iterations."
- Probabilistic selection: Choosing parents according to a soft probability distribution based on rewards. "samples parent solution(s) from via probabilistic selection (Eq.~\ref{eq:select})"
- Reward function: A scoring function that evaluates solution correctness and efficiency. " is a reward function evaluating solution quality."
- Semantic compression: Condensing memory content to preserve high-information insights within a length budget. "we perform semantic compression to maintain high information density in the local memory."
- Self-reflection: Model-driven analysis of feedback to guide iterative code refinement. "Self-reflection approaches enable models to learn from execution feedback"
- Stochastic mutations: Random changes applied to candidates during evolution, often unguided by feedback. "employ evolutionary resampling with stochastic mutations"
- Trajectory-level evolution: Recombination and optimization at the level of multi-step reasoning trajectories. "SE-Agent \cite{Se-agent} introduces trajectory-level evolution via step-wise recombination."
- Vector database: An embedding-based store used to retrieve relevant past experiences across tasks. "stores it in a vector database:"
Practical Applications
Immediate Applications
Below are deployable use cases that leverage CSE’s diversified planning, feedback‑guided mutation/crossover, and hierarchical memory to improve code efficiency (runtime, memory) with a bounded budget.
- CI/CD performance-optimization agent for repositories
- Sector: software, cloud
- What: A GitHub/GitLab Action that runs CSE on changed modules to propose algorithmically efficient alternatives, with before/after ET/MP/MI benchmarks and diffs as PRs.
- How: Diversified Planning creates multiple strategy sketches; Genetic Evolution applies targeted mutation to hot components and compositional crossover across candidate implementations; Memory avoids repeating known anti-patterns and retrieves prior wins on similar code.
- Tools/Products/Workflow: “EvoControl for CI” plugin; integrates with unit/integration tests and microbenchmarks; gates merges on efficiency budgets (e.g., must not regress ET/MP/MI).
- Assumptions/Dependencies: Reliable test suites and reproducible benchmarking; safe sandbox/executor; build system integration; human-in-the-loop code review.
- APM-driven hot-path auto-optimization
- Sector: web backends, finance, e-commerce
- What: Turn profiling traces (APM) into targeted code improvements for endpoints, trading/risk engines, and batch jobs.
- How: Use APM traces to prioritize functions; CSE decomposes code and applies targeted mutations on hot components; crossover merges fast logic with robust error handling.
- Tools/Products/Workflow: Connectors for Datadog/New Relic/Grafana; staging environment for generate‑verify‑refine; PRs with SLO impact and cost savings.
- Assumptions/Dependencies: Production-like staging data; privacy-compliant trace export; performance tests approximating live traffic.
- Data/ML pipeline optimizer (ETL, feature engineering, training loops)
- Sector: data engineering, MLOps
- What: Optimize Python/SQL/Spark/Polars code for job wall‑time and memory footprint.
- How: Diversified plans explore algorithmic rewrites (e.g., windowing vs. joins, indexing, vectorization); mutation focuses on slow transforms; memory caches successful rewrite patterns (global memory).
- Tools/Products/Workflow: VS Code/Jupyter extension; Airflow/Prefect operator that runs a “CSE pass” using sampled workloads; regression tests on metrics and outputs.
- Assumptions/Dependencies: Representative sample datasets; query/plan access (EXPLAIN); deterministic outputs for verification.
- Embedded/robotics control loop optimization
- Sector: robotics, automotive, IoT
- What: Optimize C/C++ control loops to meet real‑time deadlines and memory budgets.
- How: Functional decomposition isolates hot loops; mutation swaps naive loops with logarithmic or table‑driven logic; crossover combines numerically stable and fast code paths.
- Tools/Products/Workflow: CMake/Yocto integration; simulator- or HIL‑based verification; per‑target profiles in memory to reuse device‑specific strategies.
- Assumptions/Dependencies: Accurate timing harnesses; deterministic simulators; cross-compilation and profiling support.
- Performance-aware code review assistant
- Sector: software, open source
- What: PR bot that highlights potential complexity issues (e.g., O(n2) patterns), proposes efficient alternatives, and cites similar solved cases from org‑wide memory.
- How: CSE Memory retrieves matched prior optimizations; controlled mutation generates localized fixes; benchmark diffs attached to review.
- Tools/Products/Workflow: “Performance Reviewer” bot integrated with code hosts; policy rules (e.g., “no ET/MP/MI regressions on hot paths”).
- Assumptions/Dependencies: Lightweight, fast benchmarking; adequate tests for functional equivalence; org governance for auto‑suggestions.
- SQL/query optimization co-pilot
- Sector: analytics, ad tech, fintech, healthcare IT
- What: Rewrite slow queries and propose indexing/partitioning strategies, with workload‑aware benchmarking.
- How: Diversified plans propose alternative relational algebra routes; mutation swaps joins/orderings; memory retains workload-specific heuristics.
- Tools/Products/Workflow: DB connector using EXPLAIN/ANALYZE; shadow runs on staging; side‑by‑side plan/latency comparisons.
- Assumptions/Dependencies: Access to representative data and query plans; guardrails for correctness and access control.
- Competitive programming/course assistant for algorithmic efficiency
- Sector: education
- What: Tutor that demonstrates multiple algorithmic strategies, iteratively fixes inefficiencies, and explains trade‑offs.
- How: Show Planning sketches (e.g., greedy vs. DP vs. bitset), then evolution steps with feedback; memory surfaces “common pitfalls” and “winning patterns.”
- Tools/Products/Workflow: Integration with online judges/LMS; auto‑grading includes ET/MP/MI; visual timeline of evolution steps.
- Assumptions/Dependencies: Curated test sets; time/memory limits; anti‑cheating safeguards.
- Open-source maintenance bot for performance issues
- Sector: open source, software
- What: Automatically reproduces issues tagged “performance,” proposes fixes with benchmarks, and links to prior similar fixes across projects.
- How: Uses global memory to generalize optimization patterns (e.g., deduplication, heap usage, fast I/O).
- Tools/Products/Workflow: Issue triage + PR generation; maintainers review diffs and benchmarks.
- Assumptions/Dependencies: Reproducible issue repro scripts; CI resources; project contribution policies.
- Cloud/serverless cost reduction assistant
- Sector: cloud, energy/cost management
- What: Run CSE on serverless functions and microservices to reduce cold‑start latency, execution time, and memory to cut cloud bills.
- How: Diversified strategy search (e.g., precomputation vs. streaming), targeted mutation on hot handlers, and caching patterns from memory.
- Tools/Products/Workflow: “CSE audit” in FinOps pipelines; scheduled optimization cycles; savings reports.
- Assumptions/Dependencies: Synthetic workloads; function-level tests; cost observability (billing + telemetry).
- Regression guard for time/memory complexity
- Sector: software, security/performance
- What: Pre‑merge gate that detects potential asymptotic regressions and, when possible, auto‑suggests efficient alternatives.
- How: Memory enforces “negative constraints” (avoid known harmful edits); mutation proposes local algorithmic fixes while preserving correctness.
- Tools/Products/Workflow: Static+dynamic checkers; microbenchmarks; policy integration with blocking thresholds.
- Assumptions/Dependencies: Stable measurement harness; tight CI budgets; developer acceptance of auto‑suggestions.
- Scientific Python/NumPy/Numba optimizer for research scripts
- Sector: academia, scientific computing
- What: Speed up exploratory analysis, simulations, and preprocessing by vectorizing, batching, and re‑ordering computations.
- How: Planning explores algorithmic refactors; mutation introduces vectorization/Numba; memory stores domain‑specific patterns (e.g., convolution tricks).
- Tools/Products/Workflow: Notebook extension with “optimize cell” button; show ET/MP/MI deltas and fallbacks.
- Assumptions/Dependencies: Deterministic seeds; numerically stable transformations; result‑equivalence tests.
Long-Term Applications
The following use cases require further research, scaling, integration, or new guardrails before broad deployment.
- Org-wide Global Evolution Memory as a knowledge platform
- Sector: software across industries
- What: Centralized, privacy-preserving memory of optimization wins/failures across all teams, enabling retrieval of proven patterns company‑wide.
- How: Curate task‑level distilled experiences; embed and retrieve by code/task context; governance for sharing across repos.
- Tools/Products/Workflow: “Performance Pattern DB” with APIs for IDEs/CI/APM; dashboards of reusable strategies by stack/language.
- Assumptions/Dependencies: PII/code IP protection; standardization of metrics and metadata; de‑duplication and quality ranking.
- Autonomous “production performance engineer” with closed-loop learning
- Sector: software, cloud
- What: Always‑on agent that prioritizes hot services, proposes changes, validates on canary traffic, and continuously learns via RL from CSE trajectories.
- How: Distill CSE evolution traces into training signals; schedule safe rollouts; rollback on regressions.
- Tools/Products/Workflow: Canary orchestration; reinforcement learning pipelines; risk scoring; human override.
- Assumptions/Dependencies: Strong guardrails; robust rollback; organizational trust and auditability; high test coverage.
- Compiler/toolchain “algorithmic autotuner”
- Sector: software tooling
- What: A compiler/IDE pass that proposes algorithm‑level transformations (beyond peephole/LLVM) using controlled self‑evolution.
- How: Program analysis for functional decomposition; cost models; CSE explores algorithmic alternatives under constraints.
- Tools/Products/Workflow: Integration with Clang/LLVM/GCC/Rust/C#; SARIF outputs for devs.
- Assumptions/Dependencies: Precise component boundaries; equivalence checking; composability with existing optimizations.
- Verified optimization for safety‑critical systems
- Sector: healthcare, automotive, aerospace, robotics
- What: Efficiency improvements with formal guarantees of functional equivalence and timing constraints.
- How: Couple CSE with SMT solvers/contracts; mutation constrained by specs; crossover only among proven-safe components.
- Tools/Products/Workflow: Contracts in code (Design by Contract); model checking; certification artifacts.
- Assumptions/Dependencies: Formal specs; tool qualification; regulatory acceptance.
- Energy-aware optimization on edge/IoT
- Sector: energy, IoT, mobile
- What: Optimize for energy per task (J/op) alongside ET/MP/MI under battery/thermal limits.
- How: Extend reward to include energy; on‑device profiling; memory of device‑specific energy patterns.
- Tools/Products/Workflow: Energy profilers (e.g., power rails, OS counters); device fleet A/B testing.
- Assumptions/Dependencies: Accurate energy measurement; safe firmware update cycles; heterogeneous hardware support.
- Domain-specialized optimizers (GPU kernels, HPC, DB engines)
- Sector: scientific computing, AI systems, databases
- What: CSE-guided exploration of algorithmic transforms (tiling, blocking, sparsity, fusion) with domain cost models.
- How: Integrate with autotuners (TVM, Halide, OpenTuner) and schedulers; memory stores successful schedules per architecture.
- Tools/Products/Workflow: Hardware‑aware cost models; kernel verification suites; cross‑arch portability.
- Assumptions/Dependencies: Accurate performance models; large search spaces; reproducibility across hardware.
- Educational platforms for “efficiency literacy”
- Sector: education
- What: Curricula and graders that assess and teach algorithmic efficiency via transparent evolution traces and reflections.
- How: CSE shows multi‑strategy planning, improvement steps, and failure lessons; students iterate with guided hints.
- Tools/Products/Workflow: LMS integration; analytics on ET/MP/MI; personalized feedback using local memory.
- Assumptions/Dependencies: Scalable sandboxes; plagiarism controls; fair grading policies.
- Legacy code modernization at scale
- Sector: enterprise IT, government
- What: Migrate COBOL/Fortran/C++ legacy systems to modern, efficient implementations with measured performance guarantees.
- How: Generate tests from traces; diversify strategies for target stacks; evolve toward efficiency while preserving behavior.
- Tools/Products/Workflow: Trace‑based test harness generation; phased replacement; compliance reports.
- Assumptions/Dependencies: Sufficient coverage from production traces; regulatory constraints; change‑management processes.
- Policy and standards for green, efficient software
- Sector: policy, public sector procurement
- What: Encourage/mandate efficiency audits (ET/MP/MI and energy metrics) in procurement and compliance, with recommended CSE‑style tooling.
- How: Define minimum performance budgets; require audit logs of evolution attempts and outcomes.
- Tools/Products/Workflow: Certification schemes; open benchmarks; reporting templates.
- Assumptions/Dependencies: Consensus on metrics; vendor neutrality; avoiding perverse incentives.
- Financial simulation and risk engines with auditable speedups
- Sector: finance
- What: Optimize Monte Carlo and valuation code while keeping audit trails of changes and verification steps.
- How: CSE stores provenance (planning sketches, mutations, reward deltas) for model governance; reproducible seeds and datasets.
- Tools/Products/Workflow: Model risk management integration; automatic documentation of evolution history.
- Assumptions/Dependencies: Strict reproducibility; regulatory review; data confidentiality.
Notes on cross-cutting feasibility factors:
- Test and reward quality: CSE assumes correct, representative tests and a reward function aligned with real‑world costs (e.g., joint runtime/memory; potentially energy).
- Sandboxing and observability: Secure execution environments with precise, stable measurement harnesses are essential.
- LLM capabilities and cost budgets: Better backbones improve outcomes; budgets must be set to balance latency and gains.
- Human oversight and governance: Especially in production and regulated domains, human review and rollback strategies are required.
- Generalization beyond Python/C++: While validated on Python/C++, broader language support needs additional engineering and benchmarking.
Collections
Sign up for free to add this paper to one or more collections.

