AIRA_2: Overcoming Bottlenecks in AI Research Agents
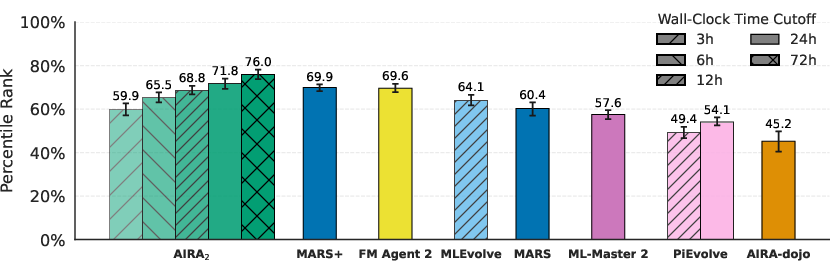
Abstract: Existing research has identified three structural performance bottlenecks in AI research agents: (1) synchronous single-GPU execution constrains sample throughput, limiting the benefit of search; (2) a generalization gap where validation-based selection causes performance to degrade over extended search horizons; and (3) the limited capability of fixed, single-turn LLM operators imposes a ceiling on search performance. We introduce AIRA$_2$, which addresses these bottlenecks through three architectural choices: an asynchronous multi-GPU worker pool that increases experiment throughput linearly; a Hidden Consistent Evaluation protocol that delivers a reliable evaluation signal; and ReAct agents that dynamically scope their actions and debug interactively. On MLE-bench-30, AIRA$_2$ achieves a mean Percentile Rank of 71.8% at 24 hours - surpassing the previous best of 69.9% - and steadily improves to 76.0% at 72 hours. Ablation studies reveal that each component is necessary and that the "overfitting" reported in prior work was driven by evaluation noise rather than true data memorization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about building a better “AI research agent” — a computer program that tries lots of ideas to solve machine learning challenges, similar to how people compete on Kaggle. The authors point out three big problems that stop today’s agents from getting better with more time and computers. Then they design a new agent system that fixes those problems and show it beats previous top systems.
What questions did the paper ask?
In simple terms, the paper asks:
- How can we make AI agents try and test many ideas faster, instead of waiting around?
- How can we make sure agents don’t “fool themselves” by optimizing for practice scores that don’t match the real test?
- How can we let agents think and debug in multiple steps, instead of following one fixed prompt and giving up when something breaks?
How did they build their agent?
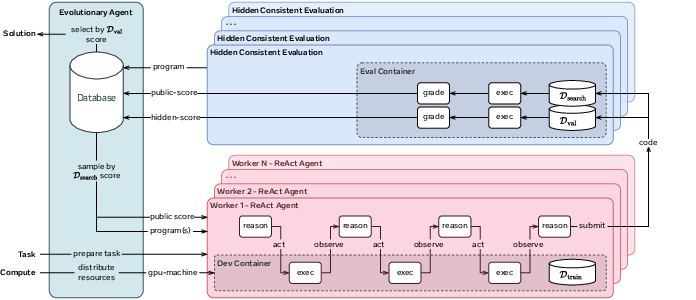
To fix the three problems, the authors combine several ideas. Think of the whole system like a well-run kitchen where many cooks experiment in parallel, test their dishes fairly, and learn from each other’s best recipes.
1) More ovens, less waiting: Asynchronous multi-GPU workers
Analogy: If you bake cookies with one oven, you make batches slowly. If you have eight ovens and keep them all busy, you get cookies much faster.
- The agent runs many experiments at the same time on different GPUs (computer chips).
- Each experiment happens in its own “container” (a clean, safe sandbox) so one failed experiment doesn’t break anything else.
- Because everything runs independently and in parallel, adding more GPUs lets the agent test more ideas per hour — roughly 8× more ideas with 8 GPUs.
Why this matters: Search works best when you can try lots of different candidates. More parallel tests = more chances to find great solutions.
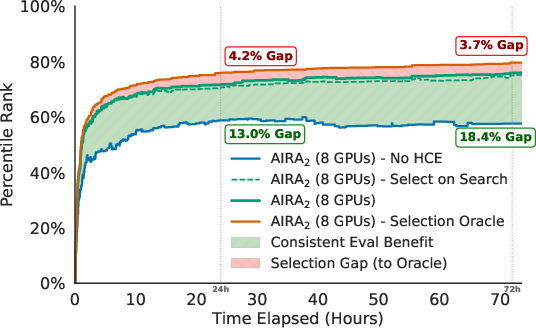
2) Fair, steady scoring: Hidden Consistent Evaluation (HCE)
Analogy: Practicing for a test is useful, but if you peek at the answer key while practicing, your practice score looks great yet doesn’t reflect how you’ll do on the real test.
- The data is split into three parts up front and kept the same the whole time:
- Training data the agent can see to build models.
- A hidden “search set” used to score each idea during the run (the agent sees only the score, not the labels).
- A separate hidden “validation set” used only at the very end to pick the final model.
- Scores are computed outside the agent, so it can’t “game” the metric.
- Keeping splits fixed removes randomness and noise from scoring.
Why this matters: A stable, hidden scoring system prevents overfitting to practice and helps the agent keep improving over longer runs.
3) Smarter actions, not just one-shot prompts: ReAct agents
Analogy: A good student doesn’t just answer once and walk away. They think, try, read error messages, and try again.
- Instead of a single-turn prompt like “Write code to solve X,” the agent uses a loop of Reason → Act → Observe:
- It thinks about what to do,
- Runs code or commands,
- Reads outputs and errors,
- Adjusts and tries again,
- Submits the best attempt when ready.
- This lets it do exploratory data analysis, small test runs, and interactive debugging inside one attempt.
Why this matters: Many real problems need multi-step troubleshooting. This approach avoids getting stuck on simple errors.
4) Evolving ideas: a population with selection, mutation, and crossover
Analogy: Imagine a tournament of ideas. The better ideas are more likely to continue, sometimes being improved (mutation) or combined (crossover) to produce new candidates.
- The system keeps a “population” of candidate solutions with their scores.
- When a worker is free, it picks strong parents and:
- Mutates a single parent (refines it), or
- Combines two parents (crossover) to mix good parts.
- Because this runs asynchronously, there’s no waiting for everyone to finish — the search keeps flowing.
Why this matters: Good ideas get refined, and mixing ideas can spark breakthroughs that single-shot attempts might miss.
What did they find?
Here are the main results, explained simply:
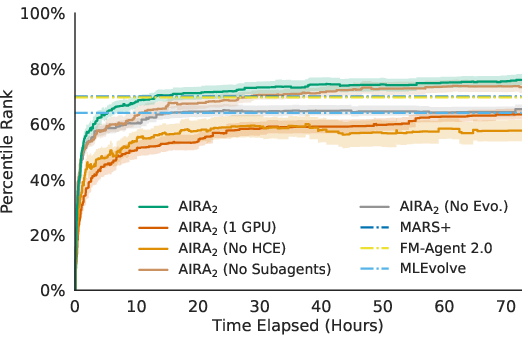
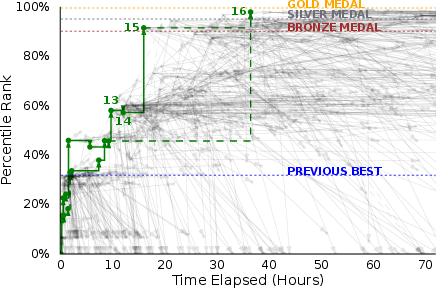
- Better than the best previous systems: After 24 hours, the new agent reached a Percentile Rank of about 72%. That means it beat roughly 72 out of 100 competitors, and it topped the previous best (about 70%). After 72 hours, it climbed to about 76%.
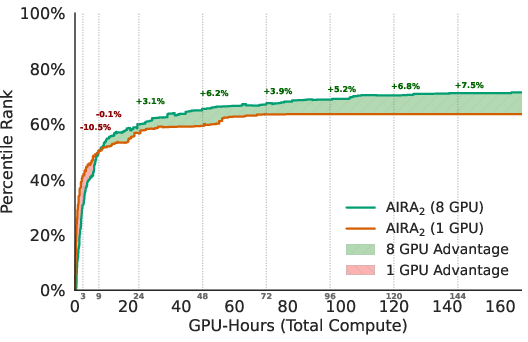
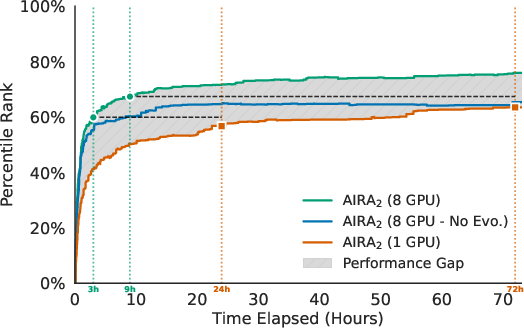
- More GPUs = not just faster, but smarter: Using 8 GPUs didn’t just speed things up. It led to better end results than 1 GPU, because the agent explored more diverse ideas and avoided getting stuck on “okay but not great” solutions.
- Parallelism needs memory and sharing: Simply running 8 separate agents without sharing (each starting from scratch) plateaued early. Sharing a population and evolving ideas was key to using extra compute effectively.
- Fair scoring prevents the “get worse over time” trap: Past systems often got worse if you let them run longer (they overfit to noisy practice scores). With the Hidden Consistent Evaluation setup, the agent kept improving instead of falling off.
- Multi-step ReAct agents help especially early: Being able to think–try–debug in a loop boosted early performance. Over longer runs, even simple one-shot operators can catch up somewhat through evolution, but ReAct still gave a useful edge.
A cool example: On a tough chemistry task predicting molecular properties, the agent tried a better model plus an extra prediction task. Scores dipped at first. Instead of abandoning the idea, it checked logs, noticed training was too short (underfitting), and decided to train longer and scale the model. That insight led to medal-winning performance — a “eureka” moment that a one-shot prompt likely would have missed.
Why this matters
- Stronger automated research: The system shows how to design agents that keep improving with more time and compute, instead of hitting a wall.
- Fairer, more reliable progress: By fixing how we score ideas (HCE), we reduce noise and avoid being tricked by misleading validation results. This means future improvements are more likely to be real, not illusions.
- Practical blueprint for scaling: The combination — parallel workers, stable evaluation, and multi-step reasoning — is a recipe others can reuse to build better research agents.
- Better use of resources: Extra GPUs only help if your agent knows how to share knowledge and evolve ideas. This paper shows a way to do that.
- Path to automated science: While the paper evaluates on Kaggle-style tasks, the same principles (parallel exploration, fair scoring, interactive reasoning) are important for automating parts of real scientific research, where experiments are slow, signals are noisy, and careful thinking matters.
In short, the authors show that agent design — not just the brain of the AI, but how it runs experiments, measures progress, and learns from mistakes — makes a big difference. With the right setup, AI research agents can explore more, learn faster, and keep getting better the longer they run.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and open questions that future work could address:
- Scaling beyond 8 GPUs: verify whether throughput and performance scale linearly past 8 workers; quantify orchestration overheads, DB contention, and diminishing returns at 16, 32, 64+ GPUs.
- Dynamic scheduling and resource allocation: replace static 1:1 GPU mapping with adaptive schedulers (e.g., straggler mitigation, priority queues, preemption) and measure effects on sample throughput and final performance.
- Multi-fidelity evaluation and early stopping: integrate ASHA/Hyperband-style resource allocation within mutations to terminate low-promise runs early and reallocate budget; quantify gains in GPU-hour efficiency.
- Compute fairness and cost-normalized comparisons: report performance at matched GPU-hour budgets versus baselines and include token/energy cost per point of Percentile Rank to enable apples-to-apples comparisons.
- Generalization to commodity hardware: evaluate on more modest GPUs (e.g., A100 40GB or consumer GPUs) and CPU-limited settings to assess practicality and portability of the approach.
- Sensitivity to LLM choice: replicate results with multiple base models (closed and open-source), quantify performance variance, and assess robustness to model drift and rate limits; report token usage per mutation.
- ReAct scope under richer tool use: test on tasks requiring internet browsing, API calls, codebase navigation, or multimodal tools to validate the hypothesized larger advantage of ReAct over single-turn operators.
- ReAct trajectory design: ablate maximum trajectory length, tool set, and introspection prompts; measure error-repair success rates, average iterations to resolution, and their impact on end performance.
- Evolutionary policy alternatives: compare rank-based selection with UCB/bandit policies, quality-diversity (MAP-Elites), novelty search, and multi-objective selection (e.g., score, diversity, time) under identical compute.
- Adaptive meta-parameters: study sensitivity and online adaptation of temperature T, crossover probability pc, mutation rates, and population size to task difficulty and observed diversity.
- Crossover mechanisms: formalize and ablate recombination strategies (e.g., code-aware merge, artifact-level recombination, lineage-aware crossover) and measure when/why crossover helps or hurts.
- Diversity maintenance: introduce and evaluate explicit diversity metrics/penalties and archives; quantify their effect on avoiding premature convergence in long runs.
- HCE split design: test robustness to different split seeds, sizes (e.g., 90/5/5 vs 70/15/15), stratification schemes, time-aware splits, and repeated evaluation to quantify residual variance under HCE.
- Statistical reliability under HCE: incorporate repeated runs per candidate (with fixed split) and adopt statistical racing/paired testing to avoid selecting candidates on stochastic noise; report confidence intervals on fitness.
- Long-horizon overfitting: extend runs well beyond 72h to test whether performance remains monotonic under HCE as compute increases and agent sophistication grows.
- Post-selection retraining: compare current “no refit” policy with refitting the selected program on all labeled data before final test submission; quantify the trade-off between reliable search and peak leaderboard performance.
- External validity beyond Kaggle: evaluate on non-Kaggle, non-tabular, and non-i.i.d. research tasks (e.g., time series, scientific simulation, wet-lab planning, robotics) to test the generality of the architecture and HCE.
- Benchmark selection bias: assess representativeness of MLE-bench-30 versus the full benchmark (and other suites); provide per-task breakdowns to identify systematic strengths/weaknesses and failure modes.
- Noise exploitation risk under fixed splits: analyze whether agents implicitly exploit training stochasticity (e.g., random seeds, data order) on the fixed search split; enforce controlled randomness and audit mitigation strategies.
- Evaluation integrity and sandboxing: systematically test for evaluation bugs/metric-hacking with invariant checks, unit tests, and adversarial probes; harden containers against sandbox escape and resource abuse.
- Systems scalability: stress-test the in-memory program DB and artifact store with large populations and long runs; measure deduplication efficacy, provenance tracking, and I/O bottlenecks.
- Subagent architecture clarity: detail and ablate subagent roles, communication protocols, and credit assignment; explore specialization vs. generalist ReAct agents and their coordination benefits.
- Reproducibility assets: release prompts, container images, orchestration code, seeds, and logs; provide deterministic runs (where feasible) or variance envelopes so others can replicate the findings.
Practical Applications
Immediate Applications
Below are applications that can be deployed today by adapting the paper’s architectural choices—asynchronous multi-GPU execution, Hidden Consistent Evaluation (HCE), ReAct-based operators, and steady-state evolutionary orchestration—into existing workflows.
- High-throughput AutoML and model search in MLOps
- Sectors: software, finance, marketing, healthcare
- What: Use an asynchronous multi-GPU worker pool with a steady-state evolutionary orchestrator to parallelize candidate generation, hyperparameter tuning, feature engineering, and ensembling. Expect near-linear throughput scaling and better asymptotic performance than single-GPU or Best-of-K setups.
- Tools/workflows: Integrate an “Evo-Orchestrator” component into Kubeflow/MLflow/Optuna; run experiments in ephemeral Apptainer containers with a standardized “superimage”; store population state in a central database; stateful Bash/Jupyter tools for interactive runs.
- Assumptions/dependencies: Access to multiple GPUs (on-prem or cloud), LLM operator access (e.g., via API), container support (Apptainer/Singularity), budget for compute, and tasks with code-executable evaluation.
- Hidden Consistent Evaluation (HCE) for reliable model selection
- Sectors: finance (risk/scoring), healthcare (clinical ML), government/defense, enterprise analytics
- What: Adopt train/search/validation/test splits with externalized, fixed evaluation during search; hide search/validation labels from agents/teams to curb metric gaming and overfitting.
- Tools/workflows: Stand up an “evaluation microservice” that scores submissions on fixed splits and reports only metrics; incorporate selection-on-val separate from search-on-search in CI/CD.
- Assumptions/dependencies: Adequate labeled data to reserve 10–20% for hidden splits; governance buy-in to accept slightly lower short-term metrics for higher trustworthiness; privacy/security controls.
- ReAct-based interactive dev and debugging agents
- Sectors: software/data science across industries
- What: Replace single-shot prompts with multi-turn ReAct agents that run code, inspect outputs/tracebacks, retry, and iterate within a single mutation attempt; especially valuable for brittle pipelines and complex dependencies.
- Tools/workflows: JupyterLab/VS Code extensions that expose stateful Bash/Python kernels; CI bots that execute and fix failing training jobs before escalating to humans.
- Assumptions/dependencies: Reliable sandboxing, audit logs, role-based access controls (RBAC) for tool use; LLMs with sufficient reasoning ability.
- Robust competition and procurement evaluations
- Sectors: education (Kaggle-style coursework), public-sector tenders, enterprise model bake-offs
- What: Run leaderboards and RFP evaluations with HCE-like protocols to reduce noise and metric hacking; report continuous metrics (e.g., Percentile Rank) rather than binary thresholds.
- Tools/workflows: Hidden/consistent splits and externalized scoring; tournament infrastructure upgrades; standardized reporting on variance and noise.
- Assumptions/dependencies: Platform changes; participant buy-in; transparent governance to build trust.
- Noise-robust online experimentation (A/B testing) guardrails
- Sectors: consumer tech, ads, e-commerce, product analytics
- What: Decouple exploration metrics from final selection with held-out traffic for commit decisions; minimize “lucky” splits and p-hacking analogs in product experiments.
- Tools/workflows: Experimentation platforms with hidden holdouts or multi-armed bandit layers mirroring HCE; automatic detection of evaluation anomalies.
- Assumptions/dependencies: Sufficient traffic volume; willingness to allocate true holdouts; cultural acceptance of slower—but more reliable—“wins.”
- Reproducible, secure, and flexible research environments
- Sectors: academia, enterprise R&D, HPC centers
- What: Use ephemeral, fakeroot-enabled Apptainer containers with preinstalled ML stacks to isolate runs, simplify dependency management, and improve reproducibility at scale.
- Tools/workflows: Organization-wide “superimages”; per-run ephemeral containers; artifact offloading and centralized metadata.
- Assumptions/dependencies: HPC policies must allow container runtimes and fakeroot; security review of dynamic package installs.
- Population-sharing across teams to accelerate exploration
- Sectors: large enterprise analytics groups, research labs
- What: Maintain a shared candidate population and lineage across teams to improve sample-efficiency, avoid duplicated effort, and converge faster to strong solutions.
- Tools/workflows: Central population/metadata store with lineage tracking and access controls; permissioned reuse of artifacts and models.
- Assumptions/dependencies: IP and privacy constraints; clear policies for sharing; versioning and provenance tracking.
- Cloud “bursting” for parallel ML competitions or hackathons
- Sectors: education, community data science, internal hackathons
- What: On-demand 4–8× GPU pools to accelerate competitive/problem-solving sprints using the paper’s orchestration; achieve strong results in <24 hours.
- Tools/workflows: Cloud templates/AMIs with orchestrator + containers; per-team queues; fixed-time budgets with HCE scoring.
- Assumptions/dependencies: Cloud credits/budget; scheduler integration; cost governance.
Long-Term Applications
These opportunities require further research, scaling, integration with real-world systems, or policy development before broad deployment.
- Autonomous scientific research agents for physical labs
- Sectors: biotech, chemistry, materials, advanced manufacturing
- What: Couple the agent’s asynchronous search and ReAct operators with robotic lab platforms and instrument APIs; run parallel wet/dry experiments with HCE-like protocols to reduce p-hacking and ensure generalizable discoveries.
- Tools/products: “Autonomous Lab Orchestrator” connecting LIMS, lab robots, and compute; automated protocol optimization with hidden holdouts.
- Assumptions/dependencies: Robust lab automation and safety interlocks, high-fidelity measurements, regulatory oversight, and substantial compute budgets.
- Research-as-a-Service platforms with secure multi-tenancy
- Sectors: cloud/SaaS providers, enterprise R&D
- What: Offer managed agentic research clusters that provide parallel experiment pools, externalized evaluations, and audited ReAct tool use as a service.
- Tools/products: Managed “Agentic AutoML/R&D” platform; customer-specific enclaves; billing/quotas per worker.
- Assumptions/dependencies: Strong isolation and IP protections; variable LLM model availability and costs; SLAs for compute and evaluation latency.
- Standards and regulation for trustworthy AI evaluation
- Sectors: policy/regulatory bodies, procurement, certification
- What: Codify HCE-like protocols into standards for AI claims (e.g., holding out evaluation sets, externalized scoring, anti-gaming controls).
- Tools/products: Compliance checklists, audits, and certification programs; standardized public testbeds with fixed splits and noise reporting.
- Assumptions/dependencies: Stakeholder consensus; enforcement mechanisms; balancing transparency with leakage risk.
- Advanced cluster scheduling for agentic workloads
- Sectors: cloud/HPC, enterprise IT
- What: Move beyond static 1:1 GPU mapping to elastic, preemptible, and cost-aware scheduling tuned for long-horizon search with variable-duration ReAct trajectories.
- Tools/products: Scheduler plugins for Slurm/Kubernetes that are “agent-aware” (population state, parent selection, priority boosts for promising lineages).
- Assumptions/dependencies: Integration complexity; fair-share policies; monitoring to prevent starvation.
- Autonomous debugging and ops agents for production systems
- Sectors: DevOps, SRE, cybersecurity
- What: ReAct agents with stateful tool access to continuously triage, reproduce, and fix issues; evolutionary search for rollback/roll-forward strategies and performance tuning.
- Tools/products: “Ops ReAct Bot” with read-only first, then controlled-write access; change-management integration.
- Assumptions/dependencies: High trust and auditability; guardrails to prevent unsafe actions; incident response policies.
- Personalized AI research assistants in education
- Sectors: higher education, corporate training
- What: Course-embedded agents that guide students through reproducible ML projects with HCE evaluation, emphasizing generalization and noise-aware selection.
- Tools/products: Campus clusters with agent pools, sandboxed containers, and externalized grading; learning analytics dashboards.
- Assumptions/dependencies: Budget for compute; academic integrity safeguards; faculty training.
- Robotics sim-to-real optimization at scale
- Sectors: robotics, autonomous systems
- What: Large-scale parallel simulation with evolutionary search and hidden holdout tasks to ensure real-world transfer; agents auto-debug training failures.
- Tools/products: Integration with Gazebo/Isaac Sim; automated domain randomization and selection pipelines.
- Assumptions/dependencies: High-fidelity simulators; safety validation; compute and energy costs.
- Energy system optimization and policy evaluation
- Sectors: energy/utilities, climate tech, public agencies
- What: Agents explore grid control policies or DER coordination in parallel digital twins, with hidden evaluation scenarios to avoid overfitting to known conditions.
- Tools/products: “Grid ReAct Lab” for operator training and policy search; HCE-protected scenario libraries.
- Assumptions/dependencies: Accurate digital twins, data access agreements, safety and regulatory approval.
- Agentic model governance for regulated finance and healthcare
- Sectors: finance, healthcare
- What: End-to-end model development with built-in HCE, lineage tracking, and automatic audit trails that satisfy model risk management and FDA-like review.
- Tools/products: Model governance suites with population lineage, hidden holdouts, and structured approvals.
- Assumptions/dependencies: Alignment with evolving regulations; third-party validation; cultural shift towards slower, more reliable deployment.
- Privacy-preserving and federated variants of HCE
- Sectors: cross-institution research consortia, sensitive data domains
- What: Secure enclaves or federated evaluation services that externalize scoring without exposing labels or raw data, enabling trustworthy cross-org benchmarking.
- Tools/products: TEEs/SMPC-backed scoring; federated split management; differential privacy options.
- Assumptions/dependencies: Maturity of secure computation stacks; performance overheads; legal frameworks for cross-institution collaboration.
These applications leverage the paper’s key insights: parallel, asynchronous exploration boosts both speed and asymptotic quality; evaluation reliability (HCE) is a prerequisite for long-horizon gains; and multi-turn, tool-using operators unlock broader problem-solving capacity. Feasibility hinges on access to compute and LLMs, container/runtime policies, data availability for held-out splits, and organizational willingness to trade short-term metrics for long-term reliability.
Glossary
- Ablation studies: Systematic experiments where components are removed or modified to assess their individual contributions to performance. "Ablation studies reveal that each component is necessary"
- Apptainer: A container runtime (formerly Singularity) used to run reproducible, isolated environments for scientific computing. "Workers execute code within ephemeral Apptainer containers"
- Asynchronous multi-GPU worker pool: A parallel execution setup where independent workers on multiple GPUs run without synchronization barriers, increasing throughput. "an asynchronous multi-GPU worker pool that increases experiment throughput linearly"
- Auxiliary prediction task: An additional target learned alongside the main objective to improve model performance or representation learning. "using Mulliken charges as an auxiliary prediction task during training."
- Best-of-K: A parallel search strategy that runs K independent trials and selects the best result without sharing state or lineage. "a “Best-of-K/No Evo.” parallel baseline"
- Branching factor: The number of child candidates explored from a given parent in a search process, affecting exploration breadth. "increases the effective branching factor of the search"
- Combinatorial space: A vast space of possible solutions formed by combinations of choices (e.g., models, features, hyperparameters). "the vast combinatorial space of ML solutions."
- Containerization: Packaging code and dependencies into isolated containers to ensure reproducible execution across machines. "introduces an asynchronous multi-GPU worker pool and containerization system"
- Crossover: An evolutionary operator that combines parts of two parent solutions to produce a new candidate. "crossover (combining two parents)"
- Crossover probability: The likelihood that a crossover (rather than a mutation) is applied during evolutionary search. "crossover probability p_c=15\%"
- Data partitioning: Splitting data into disjoint subsets for training, search-time evaluation, validation, and testing. "Data partitioning."
- Decoupled selection: Separating the metric used to guide search from the metric used for final model selection to reduce overfitting. "Decoupled selection."
- Embarrassingly parallel: A computation that can be trivially divided into independent tasks requiring no communication. "an embarrassingly parallel setup"
- Ephemeral containers: Short-lived, disposable container instances used to isolate and reset execution environments. "ephemeral Apptainer containers"
- Evaluation noise: Variability or errors in measured performance due to randomness, bugs, or unstable procedures, which can mislead search. "evaluation noise"
- Evolutionary lineage: The ancestry of a candidate solution indicating which parents or prior solutions it descends from. "without evolutionary lineage (no parents/shared memory)"
- Evolutionary search: An optimization approach inspired by natural evolution that maintains a population and applies selection, mutation, and crossover. "Evolutionary Search"
- Externalized evaluation: Running evaluation outside the agent’s control to prevent metric manipulation and ensure consistent measurement. "Externalized evaluation. Agents never self-report metrics."
- Fakeroot mode: A container feature that simulates root privileges for installing system dependencies without actual root access. "containers run in fakeroot mode"
- Fitness-proportionate selection: A selection strategy where the probability of picking a candidate is proportional to its fitness; contrasted here with rank-based selection. "rank-based rather than fitness-proportionate selection"
- Generalization gap: The difference between performance on a validation set used during search and a held-out test set representing true objective performance. "the generalization gap---the divergence between the validation metric (used to guide the search) and the held-out test metric (the true objective)."
- Generational evolution: An evolutionary scheme that evaluates a full generation of candidates before proceeding, in contrast to steady-state evolution. "Unlike generational evolution, which must wait for all workers to complete before proceeding"
- Hidden Consistent Evaluation (HCE): An evaluation protocol with fixed, hidden splits and externalized scoring to stabilize signals and prevent metric gaming. "Hidden Consistent Evaluation (HCE)"
- Hill-climbing dynamics: Iteratively improving solutions by following local improvements on a metric, which can cause overfitting if used for selection. "insulated from hill-climbing dynamics."
- Mean log MAE: An error metric that computes the mean of logarithms of mean absolute errors, used here per coupling type. "mean log MAE calculated per coupling type"
- Metric hacking: Manipulating procedures or feedback to inflate metrics without genuinely improving underlying performance. "preventing feedback loops that enable metric hacking."
- Mulliken charges: Atomic partial charges from quantum chemistry used as auxiliary targets or features in molecular property prediction. "Mulliken charges"
- Mutation: An evolutionary operator that modifies a single parent solution to create a new candidate. "mutation (refining a single parent)"
- Oracle experiments: Analyses that use ground-truth test information for selection to estimate the upper bound of attainable performance. "Oracle experiments in prior work"
- Orchestrator: The system component that maintains the population, selects parents, and dispatches tasks to workers. "The orchestrator maintains a population of candidate solutions"
- Percentile Rank: A continuous performance metric indicating relative standing among competitors; higher is better. "We report Percentile Rank as our primary metric"
- Population (evolutionary algorithms): The set of candidate solutions maintained and evolved over time. "maintains a population of candidate solutions"
- Rank-based selection: Choosing parents according to their rank order rather than absolute fitness, often with temperature scaling. "temperature-scaled rank-based selection."
- ReAct agents: Agents that interleave reasoning and acting in multi-step trajectories, executing tools and observing outputs iteratively. "replaces all operators with ReAct agents"
- Sample throughput: The rate at which candidate solutions are generated and evaluated during search. "Effective search requires high sample throughput"
- Sample-bound: A regime where progress is limited by the number of samples (candidate evaluations) that can be processed. "A synchronous agent is effectively “sample-bound,”"
- Sandboxed environment: An isolated execution context that restricts side effects and enhances safety during code execution. "executed in a sandboxed environment"
- SchNet: A neural architecture for molecular property prediction using continuous-filter convolutional layers. "testing SchNet"
- Self-reported metrics: Evaluation scores computed and reported by the agent itself, which can be unreliable or manipulable. "agents self-report metrics"
- Stateful interaction: Tooling that preserves execution context across multiple steps, enabling iterative workflows and debugging. "Stateful Interaction."
- Steady-state evolution: An evolutionary scheme where new candidates replace individuals continuously without synchronized generations. "steady-state evolution"
- Stochasticity: Randomness in processes (e.g., data splitting) that introduces variance into outcomes. "stochasticity in data splitting"
- Superimage environment: A pre-built software stack for ML experiments packaged for container execution. "the Superimage environment"
- Underfitting: A model failing to capture patterns in the data, typically due to insufficient capacity or training. "identifying the root cause as underfitting"
- Validation-test divergence: A mismatch between validation and test performance that misleads search and selection decisions. "validation-test divergence misleads the search signal"
- Wall-clock time: Real elapsed time measured during experiments, as opposed to compute hours normalized by hardware. "72 hours wall-clock time."
Collections
Sign up for free to add this paper to one or more collections.

