AutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
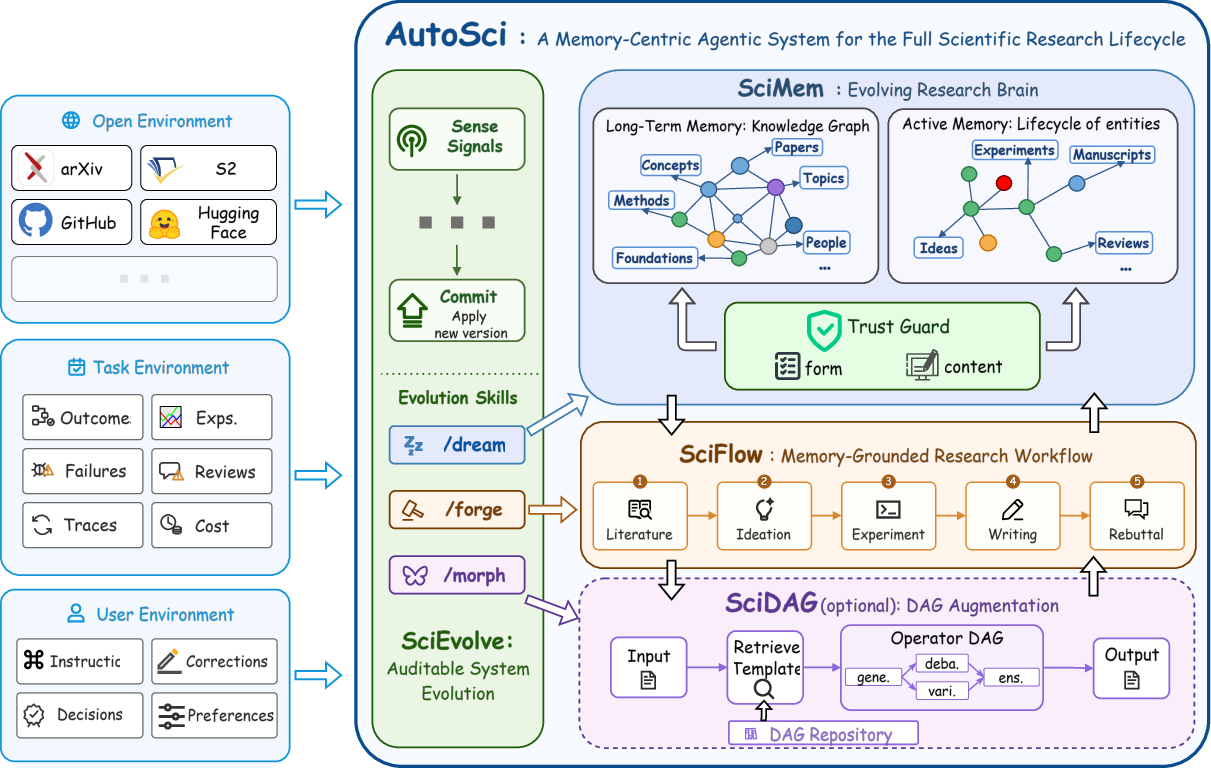
Abstract: Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “AutoSci: A Memory‑Centric Agentic System for the Full Scientific Research Lifecycle”
What is this paper about?
This paper introduces AutoSci, a computer system that helps automate almost every step of doing a scientific project. Think of it as a smart, tireless lab partner that can read papers, come up with ideas, run experiments, write up results, and even respond to reviewer comments—while also remembering what it learns so future projects get easier and better.
What questions were the authors trying to answer?
The authors asked four main questions, in plain terms:
- Can we build one system that supports the whole research journey—from reading papers to writing and revising a manuscript?
- Can the system keep a well-organized, long-term memory so it can reuse knowledge across many projects (not just one)?
- Can the system run research in a reliable, trackable way, instead of just chatting freely and hoping for the best?
- Can the system learn from feedback and improve how it works over time?
How does AutoSci work?
AutoSci has four key parts. You can think of them like a well-run lab with a great library, a project manager, a flexible team, and a habit of improving its own playbook.
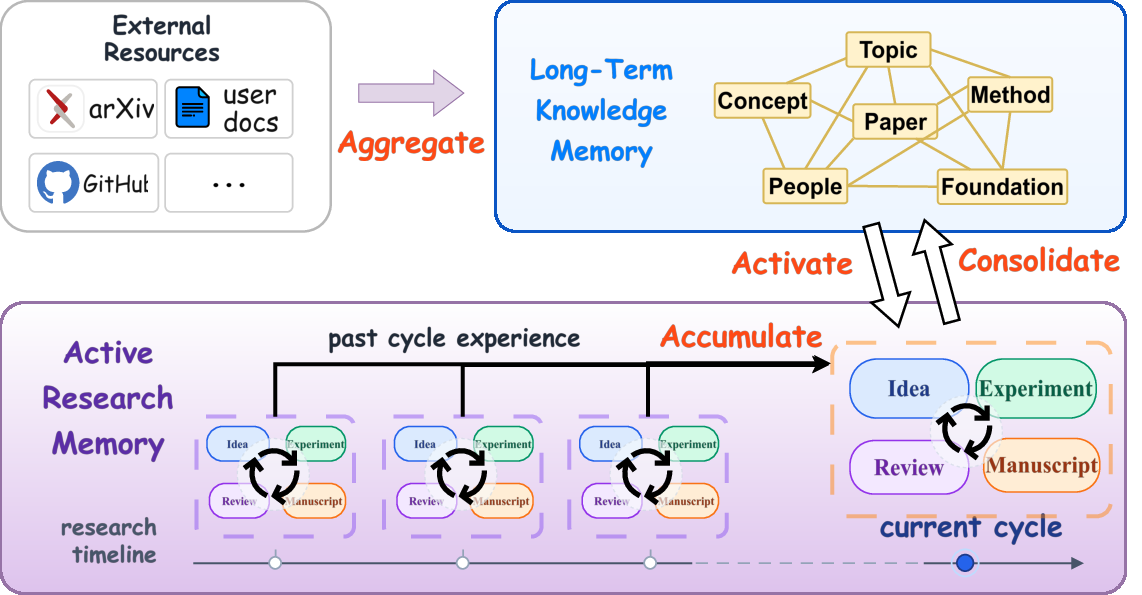
- SciMem: the memory
- Analogy: a shared lab library and notebook.
- It stores two kinds of memory:
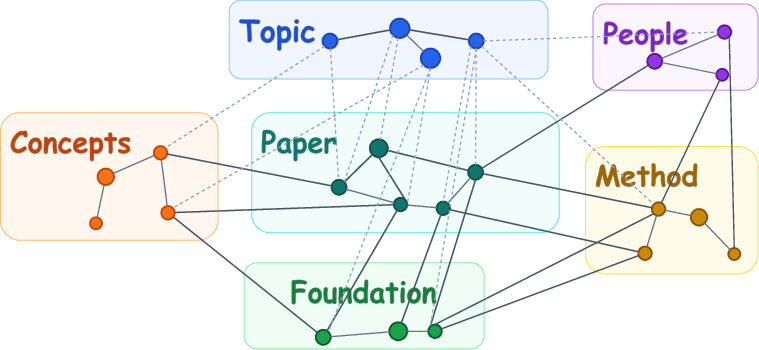
- Long-Term Knowledge Memory: stable knowledge from papers and past projects (like organized shelves in a library: topics, key concepts, methods, papers, and people).
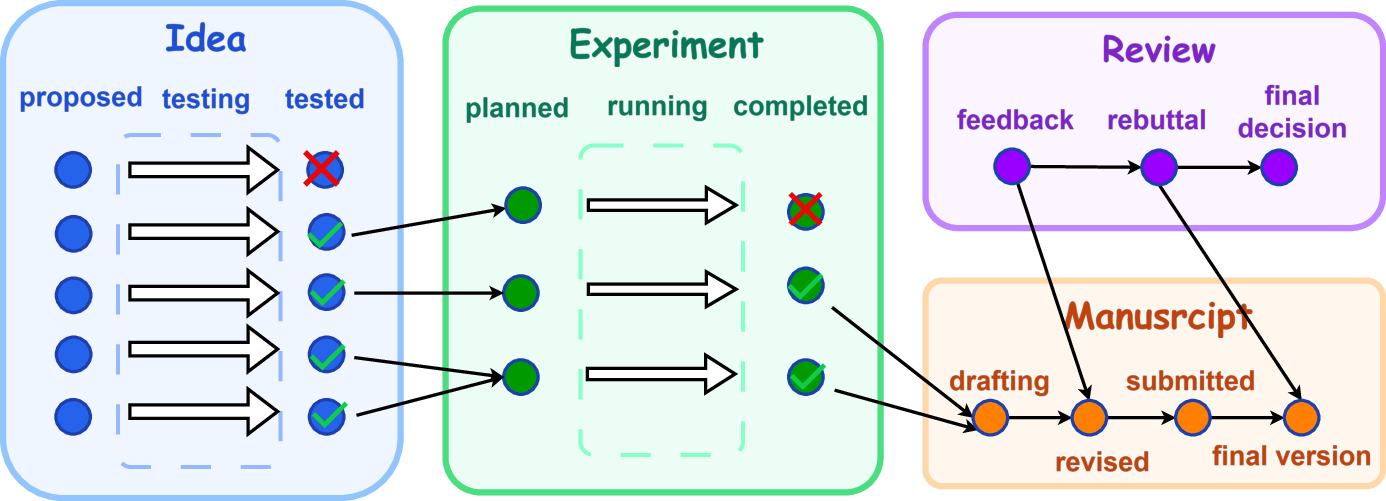
- Active Research Memory: the live project space (ideas being tested, experiments running, drafts of the paper, and reviews). Each item has a clear status, like “planned,” “running,” “completed,” or “needs revision.”
- It checks new entries with a “Trust Guard,” which is like a librarian who ensures everything is properly labeled, linked, and backed by evidence before it’s filed away.
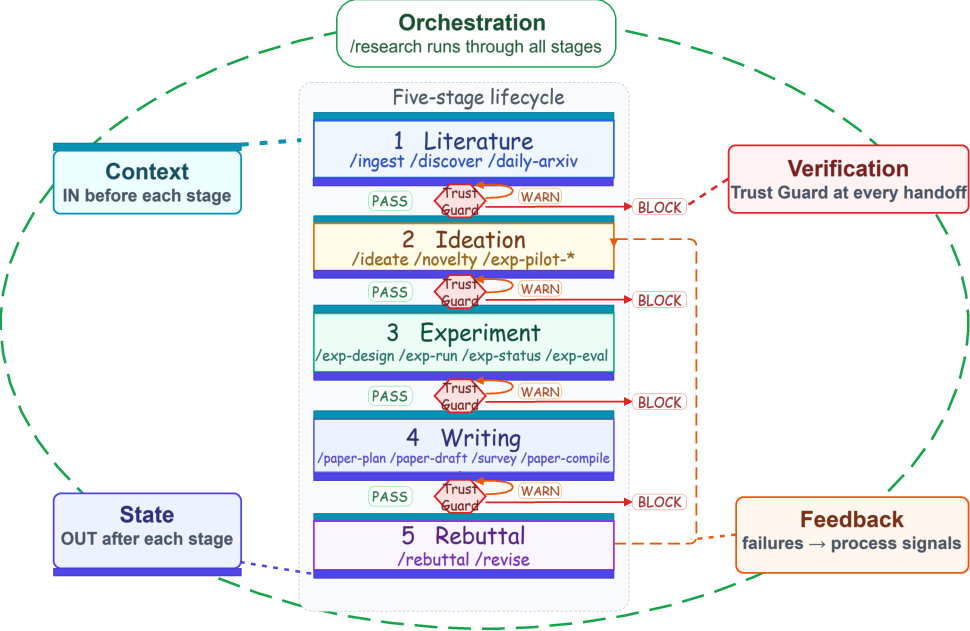
- SciFlow: the project runner
- Analogy: a careful project manager.
- It moves through five stages: Literature → Ideation → Experiment → Writing → Rebuttal.
- It “grounds” each step in memory: for example, experiments are based on earlier ideas and papers, and the paper is based on experiment evidence.
- It keeps state (progress), gives the right context to each step, verifies important handoffs, routes feedback, and can pause/resume long runs.
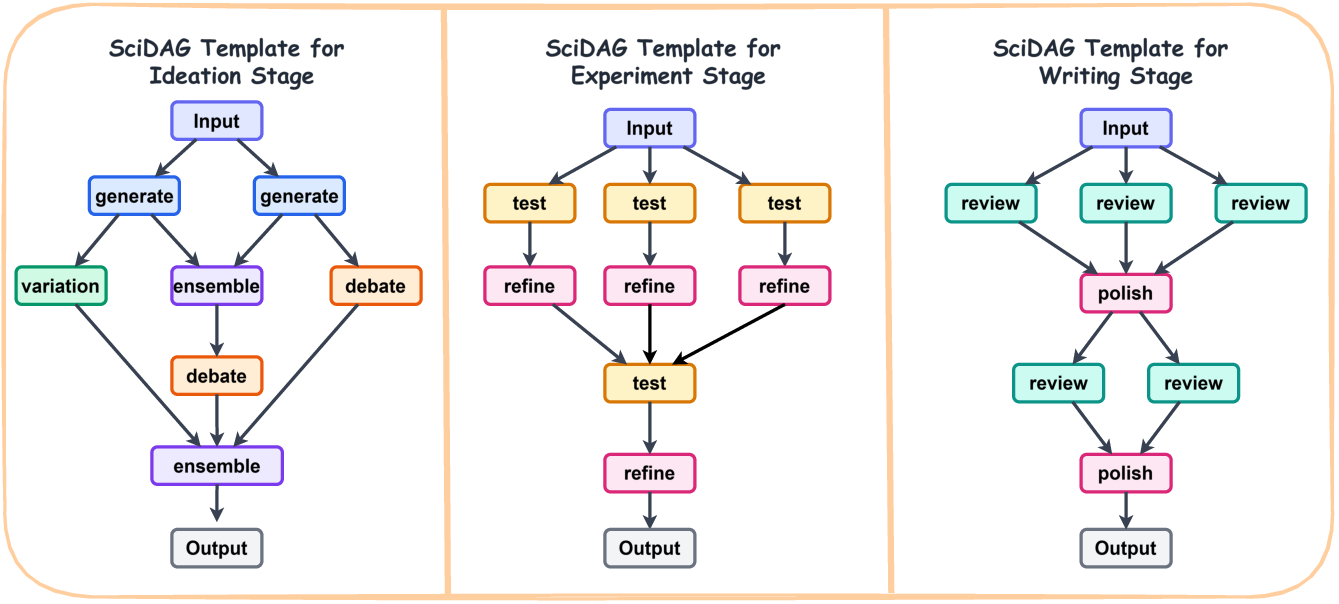
- SciDAG: the flexible team of specialists
- Analogy: a flowchart of mini-experts who can brainstorm, debate, verify, and refine.
- DAG means a flowchart with no loops. Depending on how things go, it can branch, retry, or stop early.
- Reusable templates let the system pick the right mini-team shape for tasks like idea generation, testing, or writing.
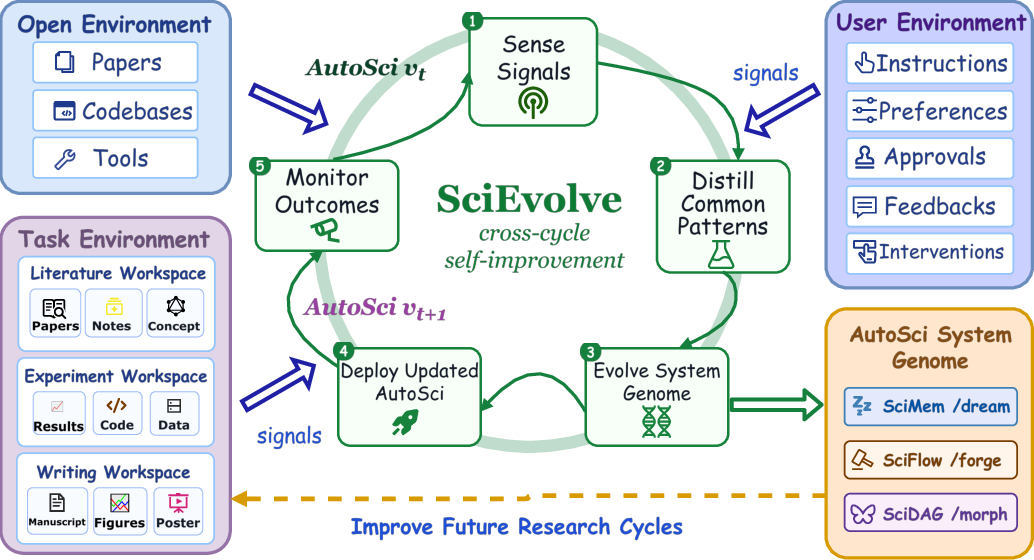
- SciEvolve: the self-improver
- Analogy: a lab that updates its own playbook when something works (or fails).
- It collects feedback from users, experiments, and reviews, then:
- Cleans and reorganizes the memory (merges duplicates, archives stale info).
- Improves skills and procedures (like tightening evidence checks before writing).
- Tunes the multi-agent templates (removing weak steps, adding verification where needed).
What did the authors test, and what did they find?
They ran AutoSci end-to-end on two very different research problems:
- GPU kernel optimization (computer performance)
- AutoSci searched ideas, picked a promising path guided by code profiling, ran a suite of experiments on NVIDIA GPUs, analyzed the changes across iterations, and wrote up results.
- It achieved meaningful speedups and provided careful analysis of how the improvements emerged over time.
- Biomedical drug discovery (protein degraders)
- AutoSci built a structured knowledge base, tried a modeling approach that accounts for specific protein changes (PTMs), ran real checks using public tools, and prepared a paper-like artifact.
- The result was a transparent “negative” outcome (the main approach didn’t beat alternatives), but with clear calibration, next steps, and pre-registered follow-up plans.
To see if AutoSci can write reviewable papers, the authors submitted the generated drafts to an automated review service (as a proxy for real peer review):
- GPU paper: 6.3/10 — viewed as a careful empirical study with strong analyses, but limited to certain hardware and settings.
- Biomedical paper: 5.8/10 — praised for transparency and planning, but missing some comparisons and follow-ups.
Why this matters:
- AutoSci didn’t just run isolated demos. It produced full, reviewable paper drafts with evidence chains and clear experiment histories.
- The system’s memory and process checks helped make the work traceable and reusable.
Why is this important?
- Speeds up research: By handling reading, organizing, proposing, testing, and writing, AutoSci can help teams move faster.
- Improves organization and reuse: Its memory acts like a high-quality lab library that grows across projects, making future work easier and more reliable.
- Increases transparency: Every idea, experiment, and write-up is linked to evidence with clear statuses, which helps others understand and reproduce results.
- Learns over time: Feedback doesn’t get lost—AutoSci actually updates how it works, not just what it knows.
What are the limits and the future impact?
- Human oversight is still needed: AutoSci is a helper, not a replacement. Scientists must judge novelty, ethics, safety, and importance.
- Coverage is limited by tools and data: Results depend on available code, models, hardware, and the quality of sources.
- Early signs are promising: Producing reviewable drafts in two tough domains shows that memory-centered, process-checked automation can support real scientific work.
- Potential impact: If refined and widely adopted, systems like AutoSci could shorten research cycles, make lab knowledge more reusable, and lift the quality and transparency of scientific studies across many fields.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items highlight where evidence is missing, where assumptions are untested, or where the system’s claims would benefit from stronger validation.
- External validity and domain breadth: Results are shown for two domains (GPU kernels, biomedical PTM/degrader). It remains unclear how AutoSci performs across other scientific areas (e.g., social sciences, materials, climate, theory-heavy fields) with different data modalities and tooling.
- Rebuttal-stage effectiveness: The Rebuttal stage is a core component of SciFlow but was not evaluated end-to-end with real peer review cycles; its impact on acceptance rates, reviewer satisfaction, and turnaround time is unmeasured.
- Cross-project benefits of persistent memory: The paper argues that SciMem enables reuse across projects, but there is no longitudinal study showing measurable improvements (e.g., reduced time-to-result, higher paper quality, fewer repeated mistakes) over multiple projects.
- Memory quality metrics: There is no quantitative evaluation of SciMem’s accuracy, coverage, link precision/recall, contradiction handling, or drift control as the knowledge graph grows.
- Trust Guard reliability: The Pass/Warn/Block gate is described but not benchmarked for precision/recall, false blocks, or false passes, nor is inter-annotator agreement against human experts reported.
- Error propagation risk: The system does not quantify how often incorrect or outdated memory entries lead to downstream errors in ideation, experiments, or writing, nor how effective quarantining and remediation are in practice.
- Schema generalizability: The suitability of the proposed entity/relation schema for non-CS/biomed domains, multi-modal artifacts (figures, spectra, microscopy, simulations), and diverse experiment types is not evaluated.
- Memory growth management: There is no study of memory bloat, aging/archival strategies, automatic consolidation quality, or performance/latency impacts as the memory graph scales to thousands of entities and relations.
- Conflict resolution and contradictions: The system lacks a measured protocol for resolving conflicting literature claims, contradictory experimental results, or reviewer disagreements, and how such conflicts are surfaced and adjudicated.
- Retrieval effectiveness from SciMem: The paper does not report retrieval quality (e.g., MRR, nDCG) or downstream task gains from typed retrieval vs. baseline vector search or unstructured summaries.
- Reusability of Active Research Memory: It remains unclear how often and how effectively terminal artifacts (failed ideas, negative results, rebuttal lessons) are reused to improve subsequent project outcomes.
- SciEvolve efficacy: There is no controlled ablation showing that /dream, /forge, /morph materially and persistently improve system performance across projects (e.g., faster convergence, fewer review warnings, better scores).
- Template evolution in SciDAG: While template evolution is described, the paper lacks evidence that updated operator graphs outperform prior versions (e.g., higher pass rates, lower cost, fewer revisions).
- Multi-agent vs. single-agent gains: No ablation quantifies the impact of SciDAG operator graphs relative to simpler single-agent or chain-of-thought baselines on quality, cost, or latency.
- Harness overhead and cost: The system reports total wall-clock times but not detailed cost/latency breakdowns per module (SciMem/SciFlow/SciDAG/SciEvolve), nor comparisons to lighter-weight pipelines to justify harness complexity.
- Model dependence: AutoSci is demonstrated with Claude Code Opus 4.7; robustness to different LLMs (open or closed), smaller models, or mixed-model configurations is untested.
- Comparative baselines: There is no head-to-head comparison against existing full-loop systems (e.g., AI Scientist variants, ARIS, NORA) on shared tasks or standardized metrics.
- Evidence-fidelity in writing: The paper asserts provenance-aware writing but does not quantify hallucination rate, citation correctness, or factual consistency under stress tests.
- Provenance and auditability: While provenance is claimed, there is no concrete evaluation of trace completeness, reproducibility of claims (code-seed-dataset linkage), or auditor UX for verifying evidence chains.
- Safety and ethics (especially in biomed): The system’s biosafety guardrails, dual-use risk controls, and compliance procedures for sensitive biological inference/tools are not specified or tested.
- Security and sandboxing: Code execution and tool use (e.g., profilers, external repos) pose security risks; the paper does not discuss sandboxing, permissioning, or vulnerability mitigation.
- Data/IP compliance: The ingestion of papers/codebases and reuse across projects raises licensing, IP, and citation-compliance questions that are not addressed.
- Human-in-the-loop roles: The frequency, granularity, and effectiveness of human oversight (when to intervene, override, or approve) are not operationalized or measured.
- Negative results handling: Although negative findings are recorded, there is no study of how their presence affects future idea selection (e.g., avoidance of dead-ends) or contributes to stronger experiments.
- Scalability under concurrency: The system’s behavior under multiple simultaneous projects, multi-user teams, and conflicting writes to SciMem is not evaluated; transactional guarantees and merge policies are unspecified.
- Resource orchestration: Generality of the experimental runtime interface (beyond TritonBench, PTM pipelines) and standardization for diverse HPC/cluster environments are not demonstrated.
- Generalized tool integration: How easily new profilers, simulators, or wet-lab interfaces can be added (contracts, adapters, testing) is unclear; no plugin ecosystem or API stability guarantees are presented.
- Robustness to literature update cadence: The system lacks an evaluation of continuous ingestion (/discover) under rapidly evolving fields, including staleness detection and automatic re-analysis triggers.
- Review-proxy validity: PaperReview.ai scores are used as a proxy; their correlation with real peer-review outcomes and sensitivity to manuscript changes remains unvalidated.
- Rebuttal strategy optimization: There is no analysis of which rebuttal tactics (e.g., new experiments vs. clarifications) are chosen by AutoSci and their measured impacts on reviewer stance changes.
- User preference modeling: SciEvolve claims to learn user preferences, but the paper does not quantify preference capture accuracy or downstream effects (e.g., style adherence, venue fit).
- Failure mode taxonomy: A systematic catalog of common failure modes (e.g., experiment setup errors, claim-evidence mismatches) and their frequencies is missing, limiting targeted improvements.
- Compute efficiency vs. quality trade-offs: The paper does not investigate how cost caps, DAG depth, or operator diversity affect final outcome quality, nor provide guidance for budget tuning.
- Reproducibility across hardware/software: The kernel case is limited to A40s and specific software versions; portability and reproducibility on different accelerators, drivers, and compiler stacks are untested.
- Schema/version evolution risks: Changes to schema, skill contracts, or templates could break backward compatibility; migration policies, semantic diffs, and automatic repair of existing memory are not detailed.
Practical Applications
Overview
AutoSci introduces a memory-centric, harnessed, and self-evolving agentic system for scientific work. Its main innovations—schema-governed research memory (SciMem), a five-stage lifecycle harness (SciFlow), DAG-based multi-agent operators (SciDAG), and a self-evolution loop (SciEvolve)—enable persistent, auditable, and reusable scientific workflows spanning literature, ideation, experimentation, writing, and rebuttal. Below we outline practical applications derived from these capabilities, grouped by deployment horizon and linked to relevant sectors, tools/products, and feasibility considerations.
Immediate Applications
The following applications can be piloted now using AutoSci v1.0.0 (or adaptations of its modules) with currently available LLMs, code execution, and common research tooling.
- Research knowledge management and onboarding
- Sectors: academia, R&D (software, biotech, materials), corporate research.
- What: Use SciMem’s typed entities (Topic, Paper, Concept, Method, Foundation, People; Idea, Experiment, Manuscript, Review) to organize literature, methods, and project artifacts as a navigable knowledge graph rather than flat notes. Store as markdown (.md) in Git-backed “vaults” (e.g., Obsidian), enabling search by type/relations and fast onboarding of new team members.
- Potential tools/products/workflows: “SciMem Vault” (Obsidian/Git), schema linting and link-check CI, semantic retrieval over typed entities.
- Assumptions/dependencies: Team adoption of the schema; connectors for arXiv/GitHub/Semantic Scholar; basic LLM retrieval and summarization accuracy; governance for shared repositories.
- Structured literature triage and domain mapping
- Sectors: academia, policy (systematic reviews, white papers), healthcare (guidelines), energy/materials R&D.
- What: Auto-ingest papers/code and build a domain map (topics ↔ concepts ↔ methods ↔ evidence), enabling targeted reading lists, novelty checks, and rapid state-of-the-art summaries grounded in citations.
- Tools/products: Ingestion pipelines; “Long-Term Knowledge Memory Builder.”
- Assumptions: Access to bibliographic APIs; citation extraction reliability; reviewer-agent checks (Trust Guard) mitigate hallucinated claims.
- Project tracking, provenance, and reproducibility
- Sectors: academia, pharma/biotech, software R&D, finance (model governance), regulated industries.
- What: Use Active Research Memory lifecycle states (proposed/testing/tested/validated/failed) for ideas, and planned/running/completed for experiments, to maintain auditable progress and evidence chains. Enables resumption without chat logs and supports internal/external audits.
- Tools/products: “Research Runbook” dashboards; provenance graphs; experiment-to-manuscript traceability.
- Assumptions: Teams store code/data artifacts with persistent identifiers; integration with Git/LFS/ELNs.
- Manuscript drafting and rebuttal assistance
- Sectors: academia, corporate R&D comms, tech blogs/whitepapers.
- What: Generate manuscript sections and rebuttals that cite SciMem evidence and experiments; retain review feedback as reusable, cross-project guidance (e.g., common concerns, venue expectations).
- Tools/products: “Writing Harness” with claim-evidence verification gates; rebuttal memory retrieval.
- Assumptions: Human-in-the-loop review; adherence to journal ethics and authorship policies; accurate evidence grounding via Trust Guard.
- Automated benchmarking, ablations, and QA for software performance research
- Sectors: software, AI infrastructure, semiconductors.
- What: Replicate the GPU kernel optimization case study: integrate profiling tools (e.g., NVIDIA nsys/ncu), use SciDAG to orchestrate iteration loops, baselines, and ablations; auto-generate result summaries and edit-behavior analyses.
- Tools/products: “Profiler-integrated Research Harness,” Triton/PyTorch adapters, ablation templates.
- Assumptions: Access to target hardware/toolchains; safe code execution environments; reproducible runners and time budgets.
- Early-stage target nomination and validation planning in biotech
- Sectors: pharma/biotech.
- What: Orchestrate structure-aware scoring and validation planning (as in PTM-aware degrader nomination); capture negative results transparently with pre-registered follow-ups, improving decision-making and knowledge reuse.
- Tools/products: Pipeline adapters for public model repos (e.g., deep learning scorers), negative-result templates.
- Assumptions: Access to models/data; domain-specific evaluation criteria; biosecurity and compliance review.
- Internal “desk-check” review before submission/release
- Sectors: academia, corporate R&D, journals/conferences (editorial assistance).
- What: Run Trust Guard and stage-specific verification templates to check schema validity, claim-evidence consistency, and risk flags prior to submissions or public releases.
- Tools/products: “Trust Guard Validator” CI; reviewer-agent bundles.
- Assumptions: Defined artifact contracts; configured tolerance levels for Pass/Warn/Block.
- SOP codification and process compliance
- Sectors: pharma/biotech (GxP), energy, aerospace, safety-critical R&D.
- What: Encode standard operating procedures as SciFlow skills with explicit inputs, steps, checks, and handoff rules; use SciEvolve to version and improve protocols from recurring deviations and outcomes.
- Tools/products: “Versioned SOP Harness;” change-control logs.
- Assumptions: Organizational buy-in; validation and QA sign-off; audit-ready record keeping.
- Teaching and supervised student research
- Sectors: education.
- What: Use SciFlow to scaffold capstones/theses: structured literature maps, explicit ideation gates, reproducible experiments, and evidence-grounded writing.
- Tools/products: Course templates; grading rubrics mapped to lifecycle stages.
- Assumptions: Instructor oversight; institution policies on AI use.
- Enterprise scientific search and discovery
- Sectors: cross-industry R&D.
- What: Leverage “semantic addressability” to retrieve by entity type and relation (e.g., “methods applying concept X with evidence Y”), improving discoverability over generic vector search.
- Tools/products: Organization-wide SciMem Graph with role-based access control.
- Assumptions: Data access permissions; metadata normalization; privacy controls.
- Continuous improvement of research workflows
- Sectors: all R&D.
- What: Use SciEvolve (/dream, /forge, /morph) to capture recurring failure modes and user fixes, promoting successful patches into stable protocols and operator templates.
- Tools/products: “SciEvolve Coach” with patch proposal/review workflows.
- Assumptions: Governance for prompt/protocol changes; A/B validation of changes; change logs.
Long-Term Applications
The following require further research, integration, scaling, or standardization before widespread deployment.
- Autonomous lab orchestration (wet and dry labs)
- Sectors: chemistry, bio, materials, robotics.
- What: Integrate SciFlow with laboratory information/robotic systems (LIMS/ELN/SLIMS, scheduling, sensors) to run closed-loop experiments with provenance and Trust Guard checkpoints.
- Tools/products: “AutoSci–LIMS Bridge,” robotics adapters, safety interlocks.
- Assumptions/dependencies: Reliable hardware control; safety certification; high-fidelity digital twins; robust error recovery.
- Enterprise-wide research operating system
- Sectors: large R&D organizations across domains.
- What: A multi-project, multi-team platform aggregating SciMem across portfolios; cross-team reuse of methods, negative results, and review lessons; policy-driven access control and knowledge distillation.
- Tools/products: “AutoSci Cloud;” organization-scale graph DB; SSO/SCIM integration.
- Assumptions: Data governance and IP protections; scalable storage/query; cultural adoption.
- Federated and privacy-preserving scientific memory
- Sectors: healthcare, finance, government labs.
- What: Federate SciMem across institutions with permissions, anonymization, or privacy-preserving methods (e.g., differential privacy, secure enclaves) to share patterns without exposing sensitive data.
- Tools/products: Federated graph services; policy engines; audit trails.
- Assumptions: Inter-institutional legal frameworks; standardized schemas/ontologies.
- Living evidence bases for policy and regulation
- Sectors: public policy, regulatory science.
- What: Maintain “living” systematic reviews and regulatory impact analyses that continuously ingest new evidence and evolve protocols; transparent provenance and rebuttal logs for public trust.
- Tools/products: Policy-focused SciMem schemas; stakeholder interfaces; comment/rebuttal workflows.
- Assumptions: Government adoption; standards for machine-aided evidence synthesis; auditability requirements.
- Learning health systems and guideline maintenance
- Sectors: healthcare.
- What: Auto-update clinical guidelines or care pathways by linking literature, trial outcomes, and post-market surveillance into a versioned SciMem; produce change logs and rationales.
- Tools/products: EHR connectors; clinical evidence adapters; governance dashboards.
- Assumptions: Strict privacy/security; clinician oversight; validation and regulatory approvals.
- Standardized, verifiable agentic research harnesses
- Sectors: academia, journals, regulators.
- What: Establish community standards for agentic research harnesses (state, gates, orchestration, memory schemas) and certify pipelines for reproducibility and compliance.
- Tools/products: Open standards; certification suites; “Trust Guard++” with formal checks.
- Assumptions: Multi-stakeholder consensus; testbeds and benchmarks; formal verification advancements.
- Marketplace of reusable SciDAG templates and skills
- Sectors: software, biotech, materials, education.
- What: Share and monetize stage-specialized operator graphs (ideation, verification, writing, ablations) and skill protocols across domains.
- Tools/products: Template registry; versioning and rating systems; usage analytics.
- Assumptions: IP/licensing frameworks; quality control; interoperability.
- Deep integration with simulation and digital twins
- Sectors: aerospace, energy, manufacturing, climate.
- What: Couple SciFlow with simulation engines and digital twins; use SciDAG to manage uncertainty quantification, design-of-experiments, and validation with real-world feedback.
- Tools/products: Simulation adapters; UQ operators; co-simulation orchestration.
- Assumptions: High-fidelity models; compute budgets; model validation workflows.
- AI-augmented editorial and peer-review ecosystems
- Sectors: scholarly publishing.
- What: Editors and reviewers use SciMem-like context packs, automated claim-evidence checks, and reproducibility harness reports; living rebuttal records improve community memory.
- Tools/products: “Editorial Guardrails;” reproducibility badges backed by harness traces.
- Assumptions: Policy and ethics frameworks; conflict-of-interest controls; tooling integration with submission systems.
- Cross-lingual, cross-discipline scientific synthesis
- Sectors: global science community.
- What: Extend memory schemas and operators to multi-language and interdisciplinary contexts, enabling unified views over diverse sources and venues.
- Tools/products: Multilingual ingestion and NER; ontology alignment tools.
- Assumptions: Robust multilingual LLMs; ontology mapping; evaluation datasets.
- Program-level oversight and impact tracking for funders
- Sectors: funding agencies, foundations.
- What: Aggregate project SciMem into program-level dashboards (evidence, methods, negative results, reuse), improving accountability and strategic planning.
- Tools/products: Program analytics; cross-project dependency graphs; grant-to-output traceability.
- Assumptions: Reporting mandates; standard schemas; security and access control.
- IP management and knowledge capture
- Sectors: corporate R&D, tech transfer.
- What: Detect and draft invention disclosures from SciMem traces; track prior art and method provenance; support patent drafting with evidence links.
- Tools/products: IP assistant; prior-art graph queries; disclosure templates.
- Assumptions: Legal review; confidentiality safeguards; integration with IP management systems.
- Safety-centric research automation
- Sectors: biosecurity, chemical safety, critical infrastructure.
- What: Enforce safety guardrails and off-switches in orchestrated research; mandatory verification nodes and red-team operators in SciDAG for dual-use concerns.
- Tools/products: Safety policy engines; red-team templates; compliance logs.
- Assumptions: Clear safety policies; oversight boards; auditability and incident response.
Notes on Feasibility and Dependencies
- Model capability and reliability: Many applications require capable LLMs with tool-use and code execution; performance may degrade in niche domains without fine-tuning or specialized tools.
- Tooling integration: Impact depends on connectors to profilers (nsys/ncu), ELNs/LIMS, EHRs, simulation engines, and repository APIs.
- Data governance and compliance: Persistent memory implies retention and reuse; organizations must define access controls, consent, and deletion policies.
- Trust Guard and verification: Content validation currently relies on reviewer agents plus schema linting; higher-stakes deployments benefit from formal checks, human review, and validated benchmarks.
- Compute and cost: Orchestrated experiments (e.g., GPU optimization) require budgeted compute and reproducible environments.
- Human-in-the-loop: For high-stakes outputs (papers, regulatory analyses, clinical guidance), expert review remains essential; AutoSci should be positioned as an assistant, not an autonomous authority.
Glossary
- ablation experiment: A controlled study that removes or isolates components to measure their contribution to overall performance or behavior. "The ablation experiment isolates the value of metric feedback by replaying two 60-operator cohorts with a blind autotuning baseline;"
- Active Research Memory: A structured, project-level workspace that tracks evolving research artifacts and their lifecycle states during an ongoing study. "Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews."
- agentic system: A system composed of autonomous agents capable of planning and acting to achieve complex goals. "a memory-centric agentic system for the full scientific research lifecycle."
- autotuning: Automatic exploration of implementation parameters or kernel configurations to optimize performance without manual tuning. "a blind autotuning baseline"
- bidirectional cross-references: Two-way links between entities that ensure navigable, consistent connections in a structured memory graph. "typed links are stored as schema-constrained bidirectional cross-references"
- bilevel LLM--simulation optimization: An optimization setup where a LLM’s reasoning guides or is guided by simulation in nested (upper/lower) optimization loops. "bilevel LLM--simulation optimization connects LLM reasoning with scientific simulation"
- directed acyclic graph: A graph with directed edges and no cycles, used here to structure multi-agent operator workflows. "A selected skill can call a directed acyclic graph of reusable multi-agent operators"
- domain guardrails: Constraints and safeguards specific to a domain that prevent invalid actions or claims during automated research. "review gates, domain guardrails, and recoverable long-running execution."
- execution harness: A controlled runtime that manages state, context, verification, feedback routing, and recovery across long-running workflows. "Execution harness. Long-running research cannot rely on unconstrained conversations alone; it requires persistent state, controlled context, verification gates, feedback routing, and recoverable orchestration."
- Foundation entities: Stable background knowledge entries in long-term memory that ground concepts and methods. "Foundation entities provide stable background knowledge that grounds Concept and Method entities."
- geometric-mean speedup: A multiplicative average speedup metric that summarizes performance gains across multiple tasks or benchmarks. "with a geometric-mean speedup of 1.52× over matched baselines"
- Long-Term Knowledge Memory: A persistent, structured repository of consolidated scientific knowledge reusable across projects. "Long-Term Knowledge Memory for reusable scientific knowledge"
- memory-augmented discovery: An approach where accumulated memory enhances an agent’s ability to discover and refine research insights. "memory-augmented discovery, as in CycleResearcher"
- memory-grounded: An execution mode in which each stage reads from and writes to structured memory rather than relying on transient conversations. "The research lifecycle is memory-grounded because each stage is coupled to SciMem through explicit read and write operations."
- non-blocking execution: Running long tasks asynchronously so the system can continue other work while monitoring progress. "supports long-running experiments through non-blocking execution and monitoring."
- orchestration: The coordination of agents, tools, and stages, including state management and handoffs, in a complex workflow. "state, context, verification, feedback, and orchestration."
- post-translational modification (PTM): Chemical modifications to proteins after synthesis that affect function, stability, or localization. "post-translational modification (PTM) modeling"
- PROTAC-STAN: A specialized inference repository/tooling used for evaluating or modeling PROTAC-related tasks in drug discovery. "PROTAC-STAN inference repositories"
- provenance: Documentation of the origin and history of data, claims, or artifacts to enable verification and auditing. "monitoring, provenance or claim checks, review"
- rebuttal: The process of responding to reviewers’ critiques after submission, often influencing revision and acceptance. "from literature understanding to rebuttal"
- retrieval-augmented: Enhanced with information fetched from external or long-term memory sources to inform generation or refinement. "retrieval-augmented refinement loop"
- review gates: Explicit checkpoints where artifacts are reviewed and validated before proceeding to downstream stages. "review gates, domain guardrails, and recoverable long-running execution."
- schema-governed: Constrained and validated by an explicit data schema to ensure consistency, interpretability, and extensibility. "schema-governed research memory"
- scientific knowledge graph: A structured network of scientific entities and typed relations enabling traversal and reasoning. "a traversable scientific knowledge graph."
- semantic addressability: The ability to retrieve entities by meaning and type rather than by unstructured text search. "semantic addressability, which lets downstream skills retrieve typed scientific objects and relations directly;"
- skill contract: A formalized specification of inputs, context, steps, checks, and outputs for an executable capability. "Each stage is implemented as a harness-based skill contract."
- Trust Guard: A validation layer that enforces schema correctness and evidence consistency before memory writes are accepted. "Trust Guard checks both form validity"
- typed entity schema: A structured definition of entity types and relations used to organize knowledge beyond flat documents. "organized by a typed entity schema"
- work-stealing dispatcher: A scheduling mechanism where idle workers dynamically take tasks from busier workers to balance load. "work-stealing dispatcher;"
Collections
Sign up for free to add this paper to one or more collections.

