- The paper’s main contribution is a rigorous comparison of GRPO and SFT for enhancing reasoning in large language models.
- It demonstrates that GRPO amplifies pre-existing capabilities with minimal out-of-domain degradation, whereas SFT induces significant internal shifts with potential knowledge loss.
- Extensive parameter-level and freezing experiments reveal key trade-offs between achieving in-domain gains and preserving broad model competence.
Comparative Analysis of GRPO and SFT for Reasoning Training in LLMs
Introduction
This work presents a controlled comparative study of two prominent post-training paradigms for LLMs in reasoning domains: Group Relative Policy Optimization (GRPO), a reinforcement learning (RL) method, and supervised fine-tuning (SFT) on synthetic chain-of-thought (CoT) traces. The investigation is motivated by the widespread adoption of "reasoning training" in LLMs, particularly in mathematics and code, and the lack of mechanistic understanding of how these training regimes affect model capabilities and internal representations. The study leverages OLMo-2-1124-7B-Instruct as the base model and aligns training setups to minimize confounds, enabling a direct comparison of the impact of GRPO and SFT on both in-domain (maths) and out-of-domain (knowledge-intensive) tasks, as well as on model parameters.
The authors first establish that GRPO is computationally expensive and unstable, requiring careful tuning of question difficulty, reward function design, and hyperparameters to achieve effective training. In contrast, SFT is found to be stable and reliable, with smooth loss and gradient norm curves.
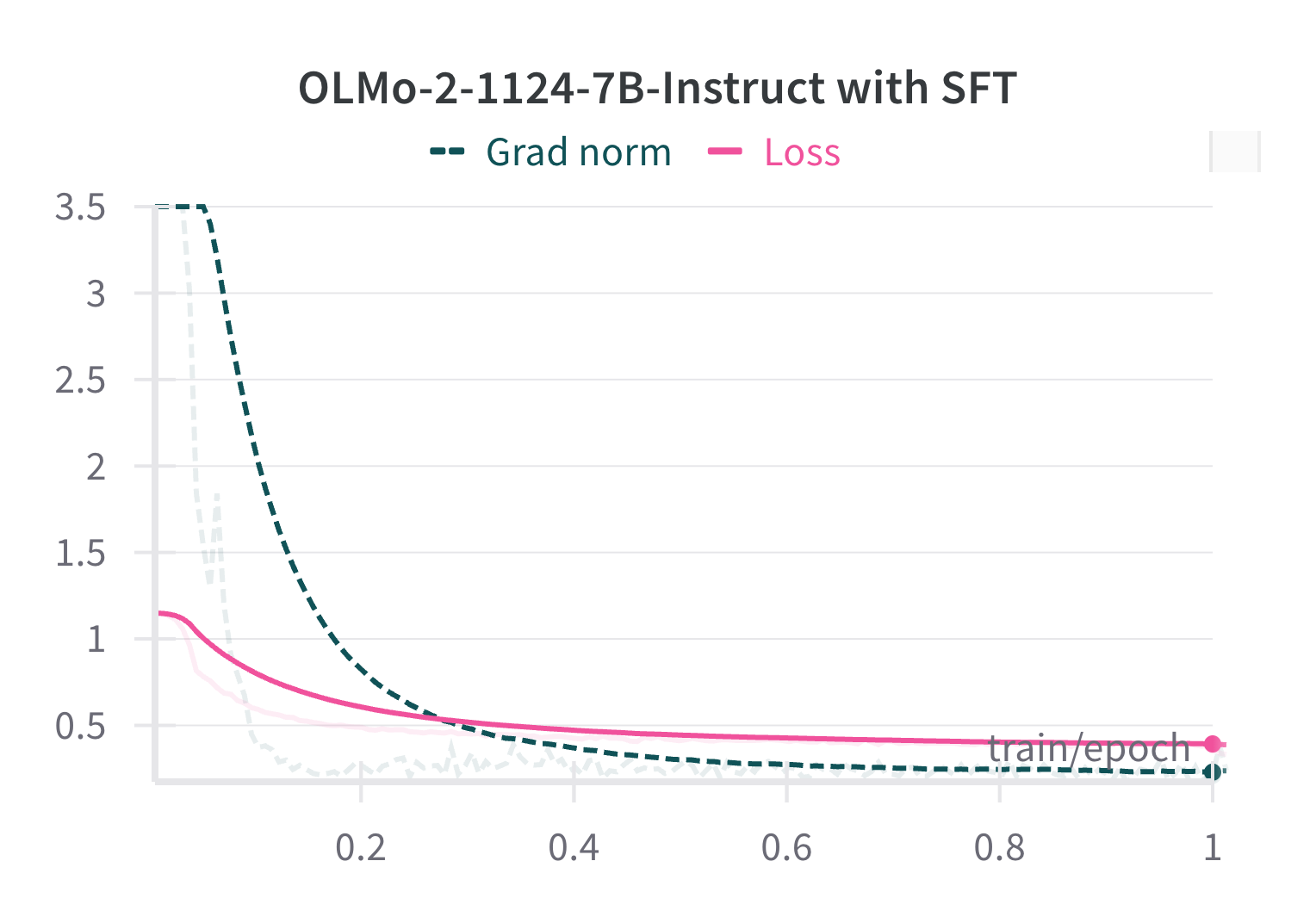
Figure 1: The gradient norm and loss curves of OLMo-2-1124-Instruct during SFT on questions and completions from the CN-K12-91k subset.
A key insight is that the effectiveness of GRPO is highly sensitive to the alignment between model capability and question difficulty. When training on olympiad-level questions, even 7B models fail to improve, whereas restricting to K-12 level questions yields reliable learning signals.
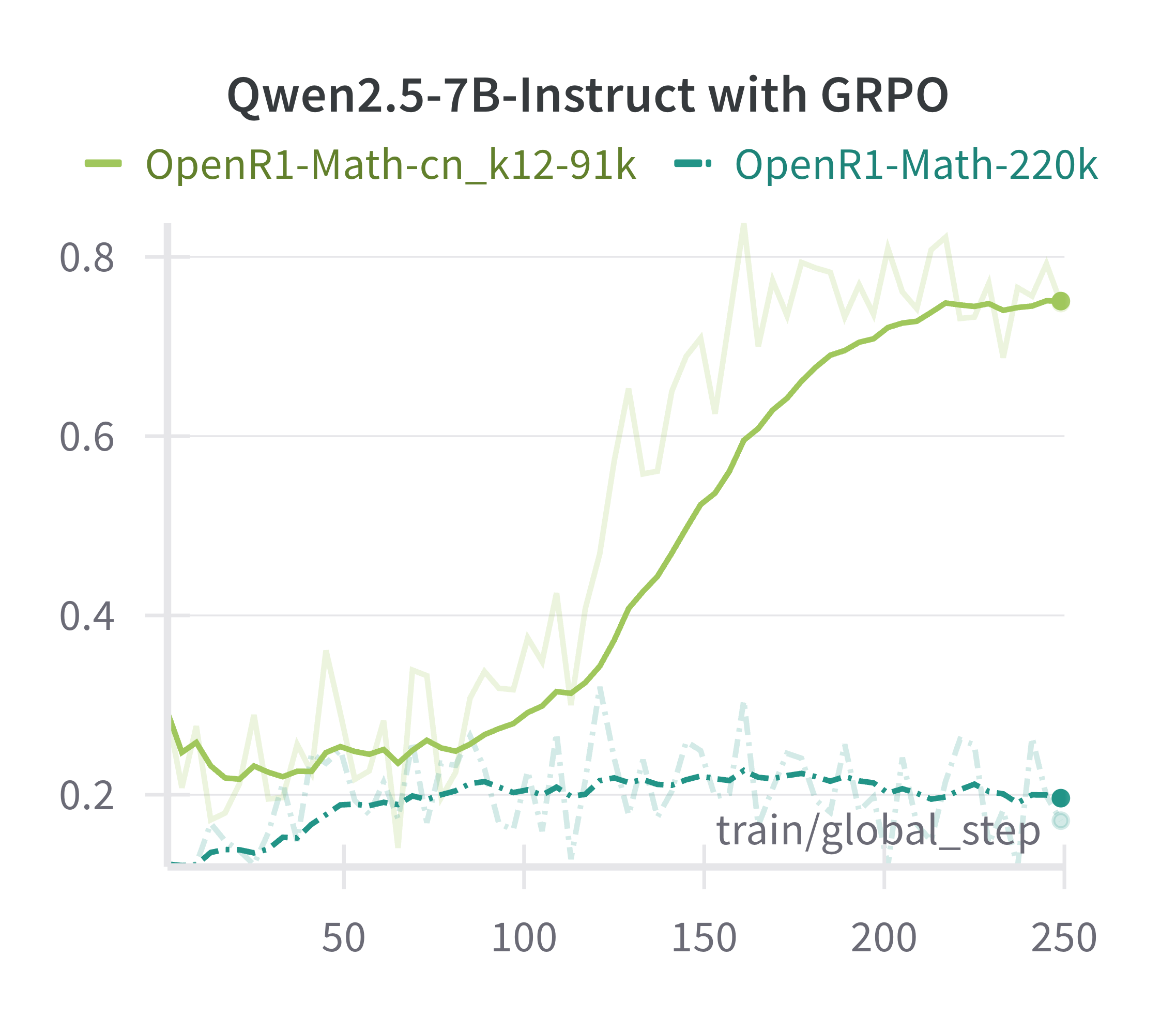
Figure 2: Accuracy rewards of Qwen2.5-7B-Instruct during GRPO on questions sampled from OpenR1-Math-220k and the CN-K12 subset. In the former, the model continuously struggles, while in the latter, it gradually exhibits much stronger performance.
Reward function design is also critical. The study finds that overemphasizing format rewards can lead to reward hacking, where the model learns to output correct XML tags without improving accuracy. Scaling accuracy and format rewards appropriately is necessary to balance learning.
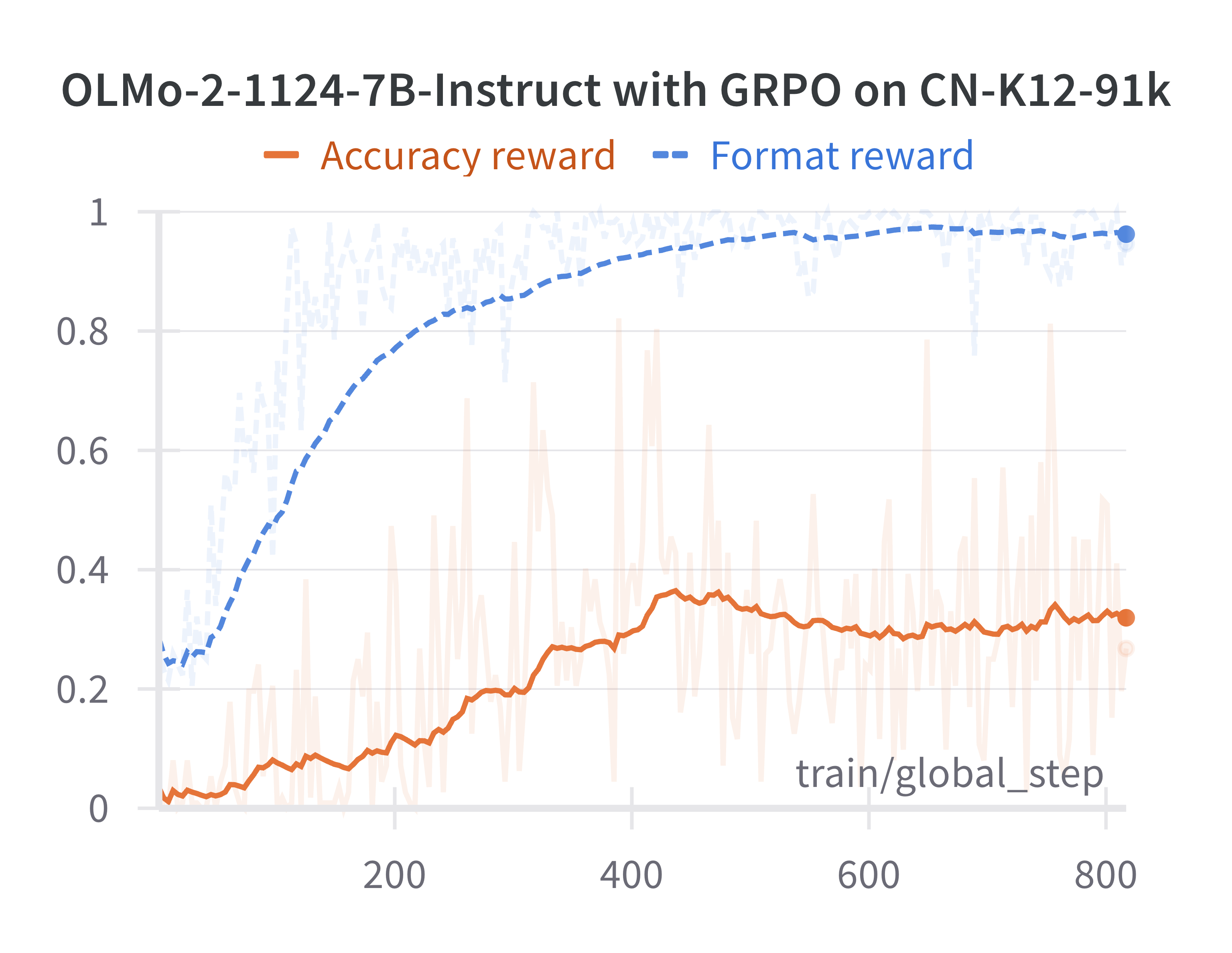
Figure 3: Accuracy and format rewards of OLMo-2-1124-Instruct during GRPO on questions sampled from CN-K12-91k subset. Format rewards increase quickly as the model follows instructions, while accuracy rewards increase more slowly and plateau.
On benchmark evaluations, SFT yields more pronounced in-domain gains (e.g., on MATH-500) but at the cost of greater degradation on out-of-domain tasks (e.g., MMLU, IFEval). GRPO provides modest in-domain improvements with less out-of-domain degradation.
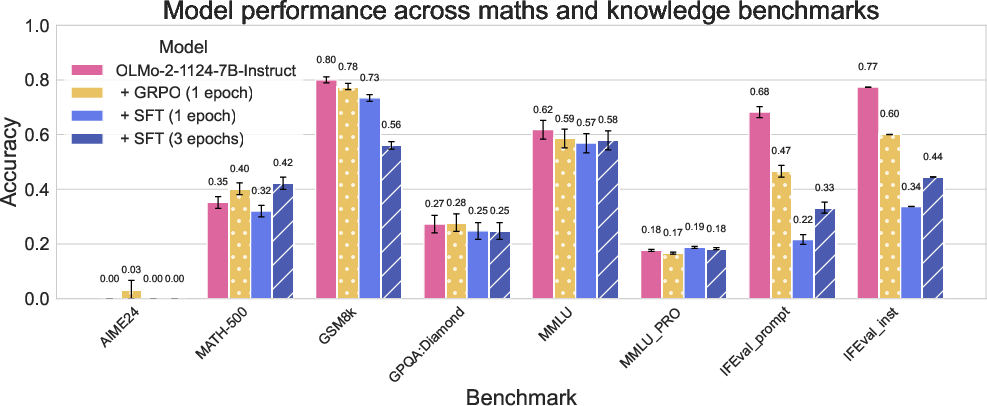
Figure 4: Evaluation results on a wide range of benchmarks. All results use extractive match and training sampling parameters; most are zero-shot CoT.
This trade-off is robust to the number of SFT epochs, with longer SFT exacerbating both in-domain gains and out-of-domain losses. The results suggest that SFT can overwrite existing capabilities, while GRPO primarily amplifies those already present in the base model.
Cross-Checkpoint and Parameter-Level Analysis
To elucidate the mechanistic differences between GRPO and SFT, the authors analyze 20 intermediate checkpoints for each training regime. They compute the per-token KL divergence between the base model and each checkpoint on a held-out math dataset.
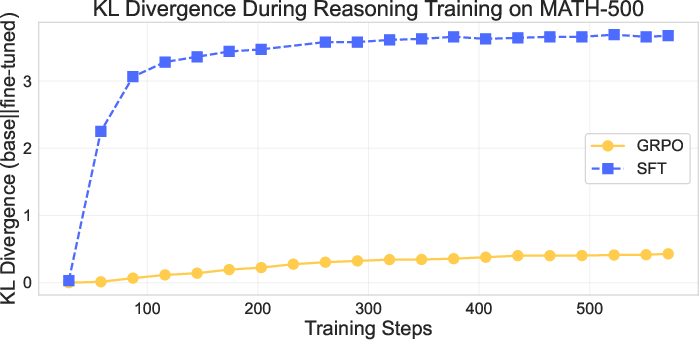
Figure 5: The KL divergence between OLMo-2-1124-7B-Instruct before training and during training on the withheld MATH-500 dataset. SFT causes divergence from the base model much more quickly and to a more pronounced degree than GRPO.
SFT induces a rapid and substantial increase in KL divergence early in training, indicating a significant shift in the output distribution. GRPO, in contrast, leads to a gradual and much smaller divergence, consistent with the hypothesis that it reinforces existing behaviors rather than introducing new ones.
At the parameter level, both GRPO and SFT primarily update the query and key matrices in the attention mechanism, with the largest changes in mid-layers. However, the magnitude of updates is much greater for SFT, especially in the mid-layer MLPs.
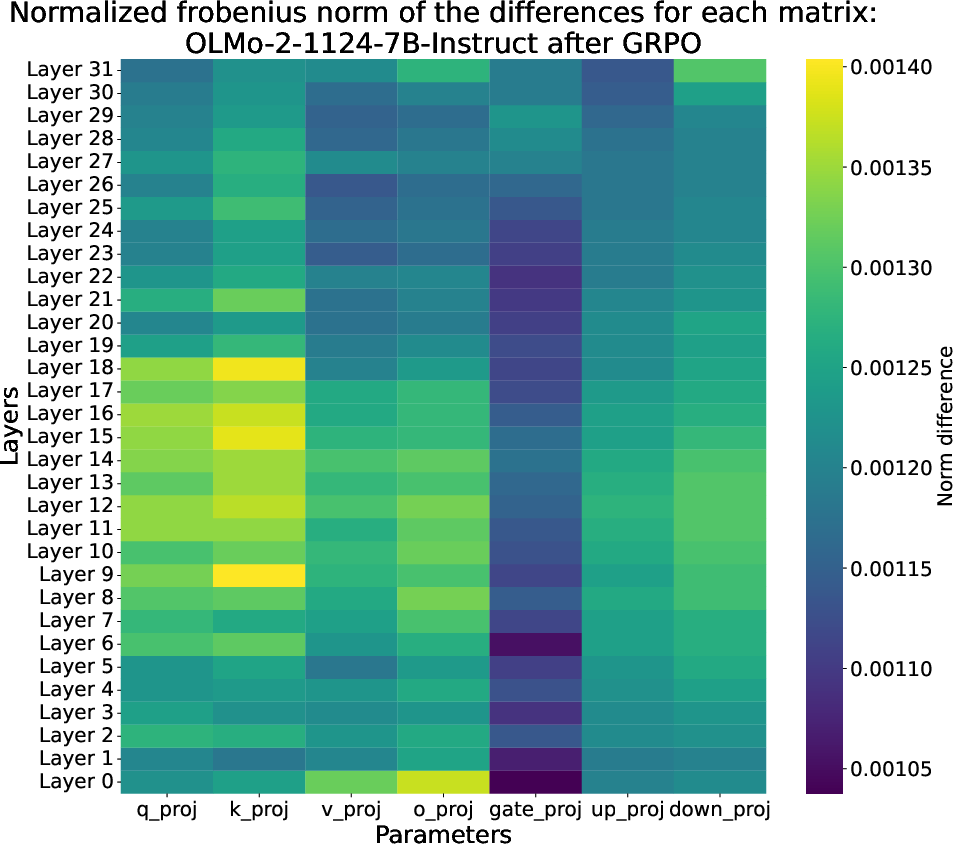
Figure 6: The parameter-level impact of GRPO, as measured by the normalized Frobenius norm of the difference between every matrix of OLMo-2-1124-7B-Instruct before and after GRPO.
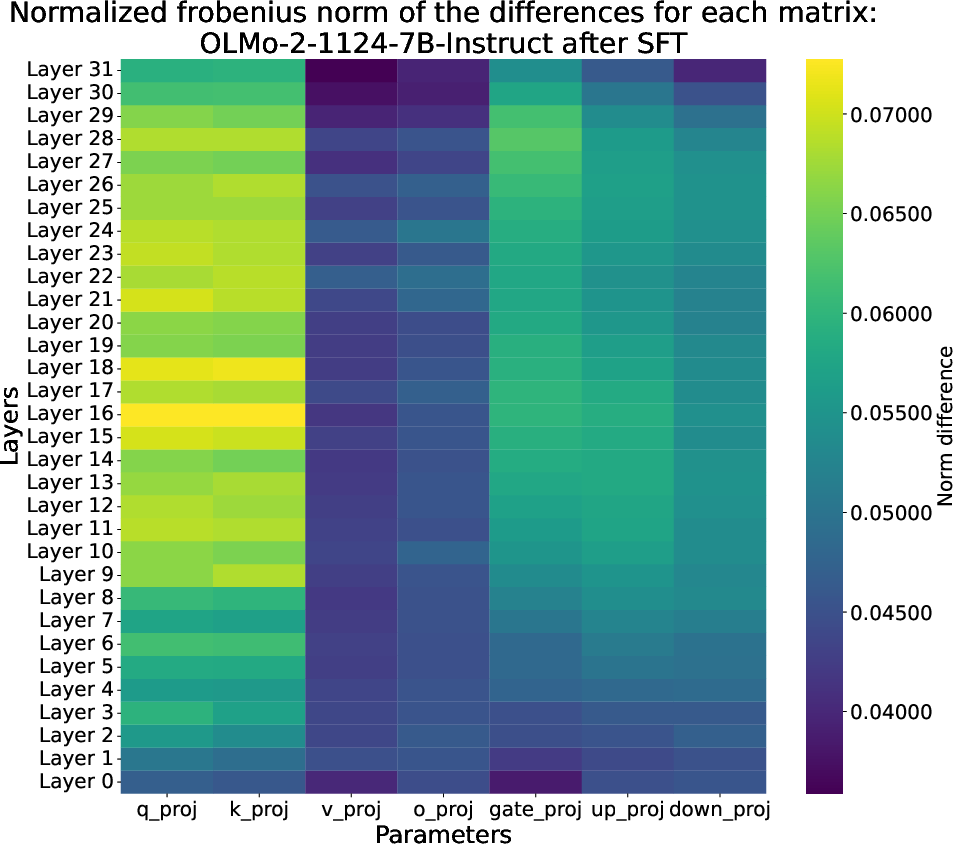
Figure 7: The parameter-level impact of SFT, as measured by the normalized Frobenius norm of the difference between every matrix of OLMo-2-1124-7B-Instruct before and after SFT.
This observation aligns with prior work indicating that mid-layer MLPs are critical for storing factual associations. The authors hypothesize that SFT's larger updates to these regions may underlie the observed degradation on knowledge-intensive tasks.
Freezing Experiments: Applying Mechanistic Insights
To test whether targeted interventions can mitigate SFT-induced degradation, the authors conduct freezing experiments:
- Training Only Query and Key Matrices: Restricting updates to these matrices degrades in-domain performance and does not prevent out-of-domain loss, indicating that broader parameter adaptation is necessary for effective learning.
- Freezing Mid-Layer MLPs: Motivated by causal tracing results showing high average indirect effect (AIE) in these layers, the authors freeze MLPs with high AIE during SFT. This intervention stabilizes performance on some knowledge-intensive benchmarks (e.g., GPQA-Diamond) but underperforms on others, and does not fully prevent degradation.
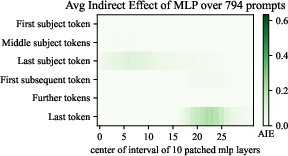
Figure 8: The average indirect effect (AIE) of the MLPs of OLMo-2-1124-7B-Instruct, motivating which layers to freeze.
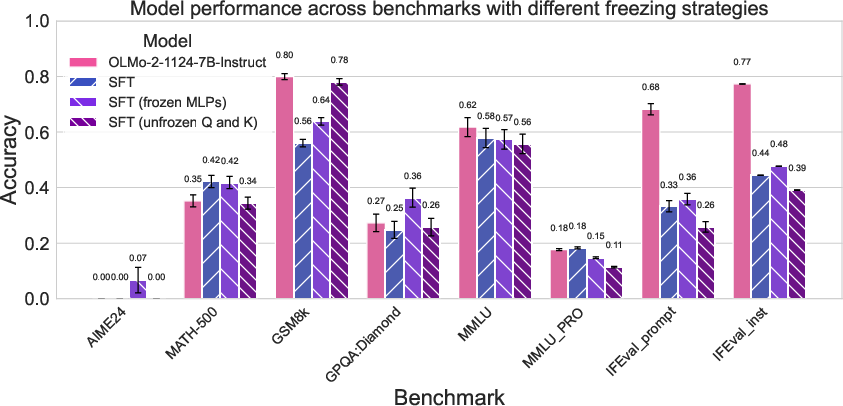
Figure 9: Evaluation results on the same benchmarks as in Figure 4, showing the impact of freezing strategies.
These results suggest that while mechanistically informed freezing can modulate the trade-off between in-domain and out-of-domain performance, it is not a panacea. The interplay between parameter adaptation and knowledge retention is complex and not fully captured by simple freezing heuristics.
Practical and Theoretical Implications
The findings have several implications for both practitioners and theorists:
- For Practitioners: SFT is more accessible and stable but risks overwriting existing knowledge, especially in mid-layer MLPs. GRPO is computationally demanding and sensitive to question difficulty but better preserves out-of-domain capabilities. Careful curation of training data and reward functions is essential for both methods.
- For Theorists: The distinct parameter-level signatures of GRPO and SFT provide a mechanistic basis for their behavioral differences. The results support the view that RL-based post-training amplifies pre-existing circuits, while SFT can induce more global reorganization, including the erasure of factual associations.
- For Future Work: More sophisticated interventions, such as dynamic freezing, targeted regularization, or hybrid RL/SFT approaches, may better balance the trade-off between capability amplification and knowledge retention. Further research is needed to generalize these findings across architectures, scales, and domains.
Conclusion
This study provides a rigorous comparative analysis of GRPO and SFT for reasoning training in LLMs, revealing that GRPO primarily amplifies existing capabilities with minimal out-of-domain degradation, while SFT can replace old skills with new ones at the cost of knowledge loss. Parameter-level analyses show that both methods target attention queries and keys, but SFT induces larger and more disruptive changes, especially in mid-layer MLPs. Freezing experiments demonstrate that mechanistic insights can inform training interventions, but the trade-off between learning and forgetting remains unresolved. These results underscore the need for further research into the internal dynamics of LLM post-training and the development of methods that can selectively enhance reasoning without sacrificing general knowledge.

