Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Abstract: Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can reduce response length while degrading performance. We trace this degradation to the suppression of epistemic verbalization - the model's expression of uncertainty during reasoning. Through controlled experiments varying conditioning context richness and task coverage, we show that conditioning the teacher on rich information suppresses uncertainty expression, enabling rapid in-domain optimization with limited task coverage but harming OOD performance, where unseen problems benefit from expressing uncertainty and adjusting accordingly. Across Qwen3-8B, DeepSeek-Distill-Qwen-7B, and Olmo3-7B-Instruct, we observe performance drops of up to 40%. Our findings highlight that exposing appropriate levels of uncertainty is crucial for robust reasoning and underscore the importance of optimizing reasoning behavior beyond merely reinforcing correct answer traces.


 Degrade the Reasoning Capability of LLMs?")
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper asks a surprising question: why does a training trick that often makes AI models better and more concise sometimes make their math reasoning worse?
The trick is called “self‑distillation.” It’s like having a model teach itself by looking at hints or solutions while it trains, then trying to sound like that during real use. In many subjects (like chemistry or coding), this makes answers shorter and more accurate. But in math, the authors find that it can shorten answers while actually hurting accuracy—sometimes a lot. They dig into why this happens and what we should do about it.
The main goals and questions
The paper aims to figure out:
- Why can self‑distillation make math performance drop even though the model is trained with correct solutions?
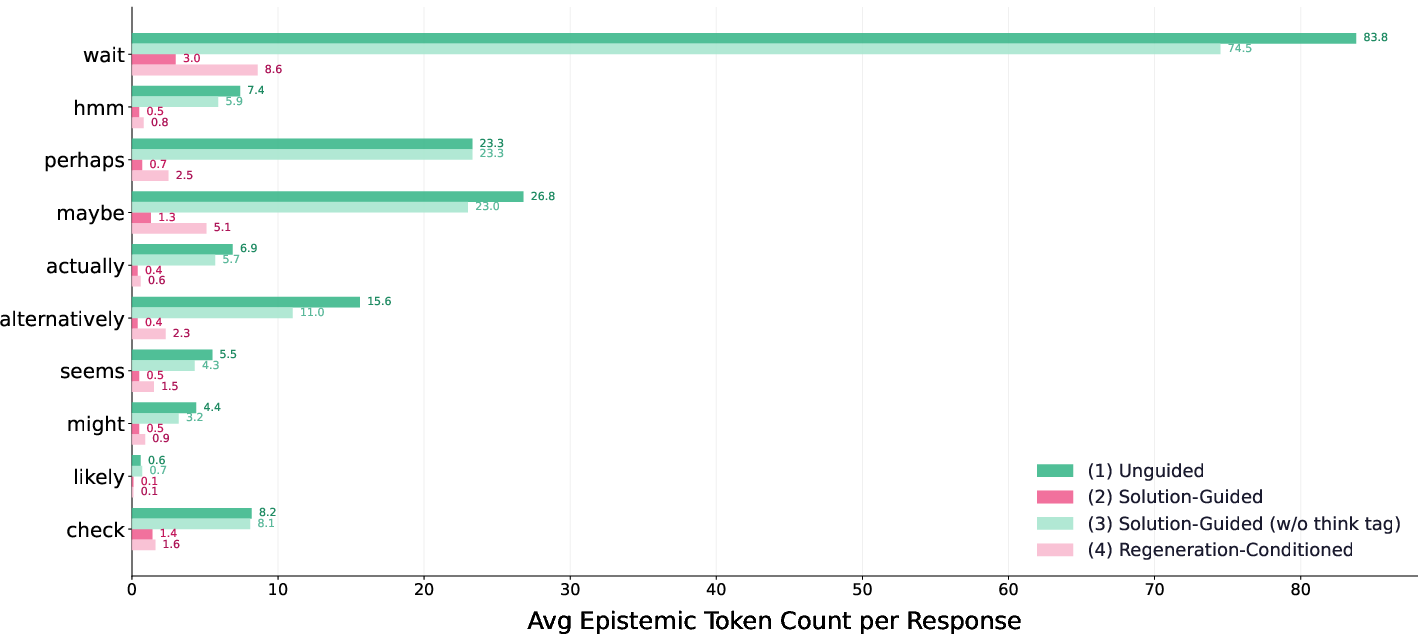
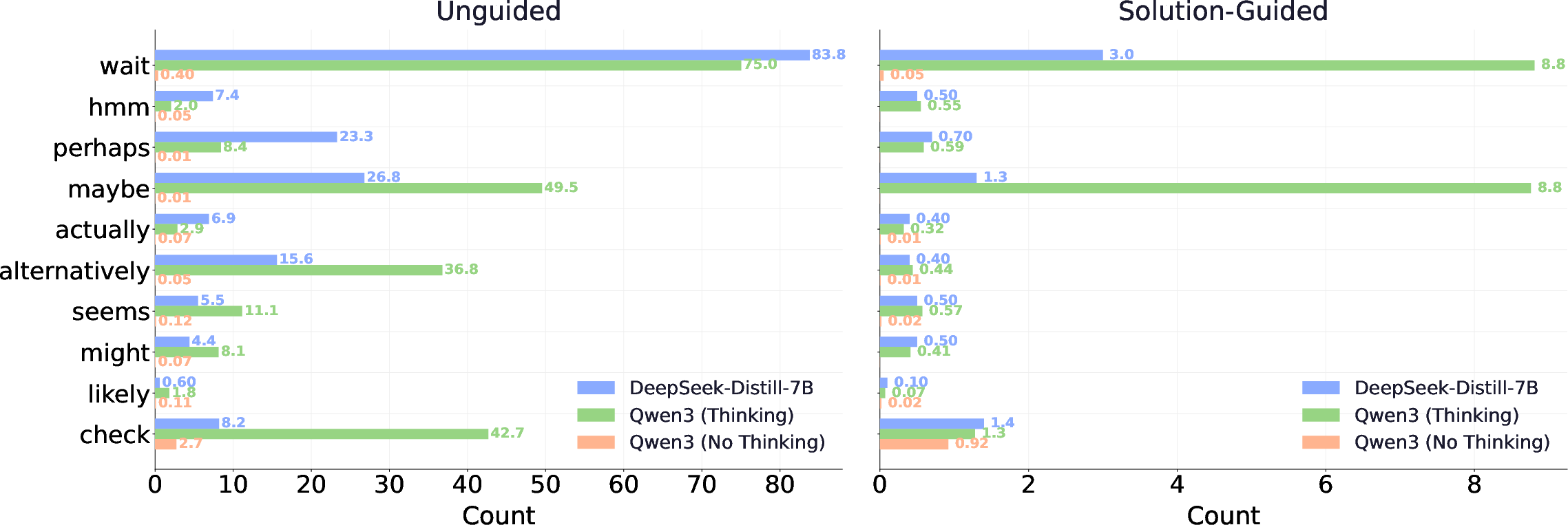
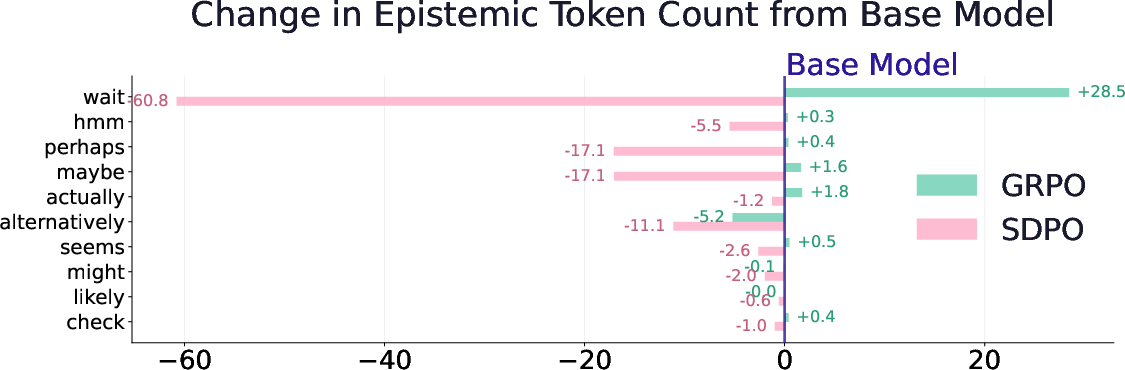
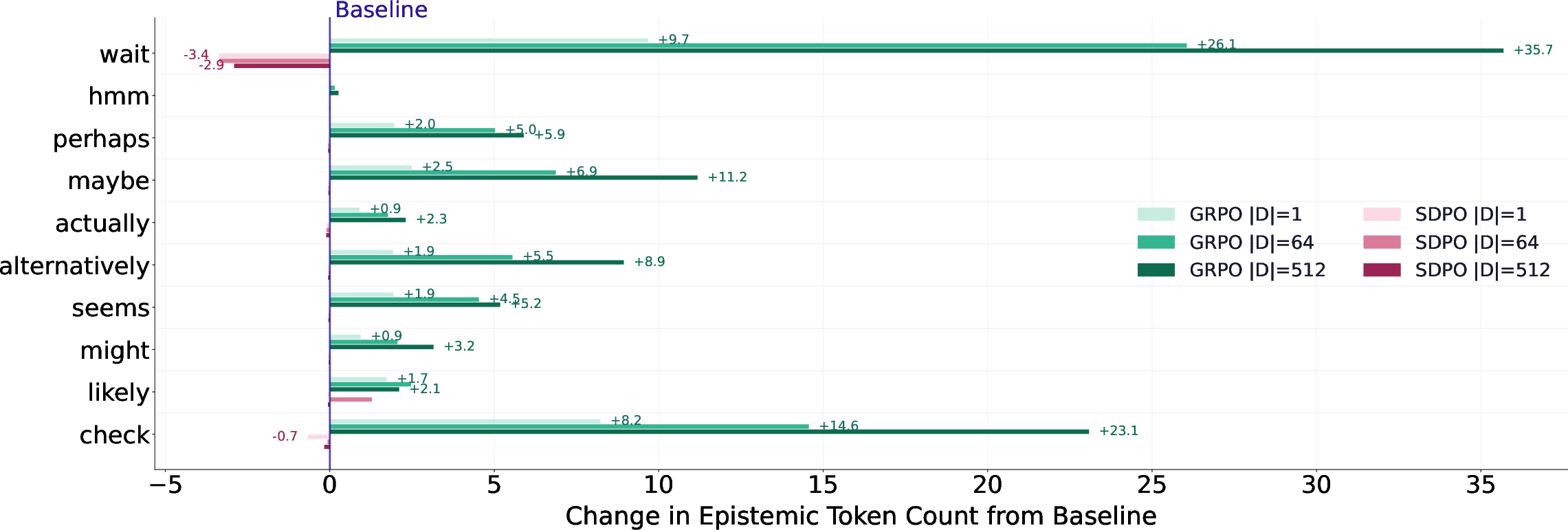
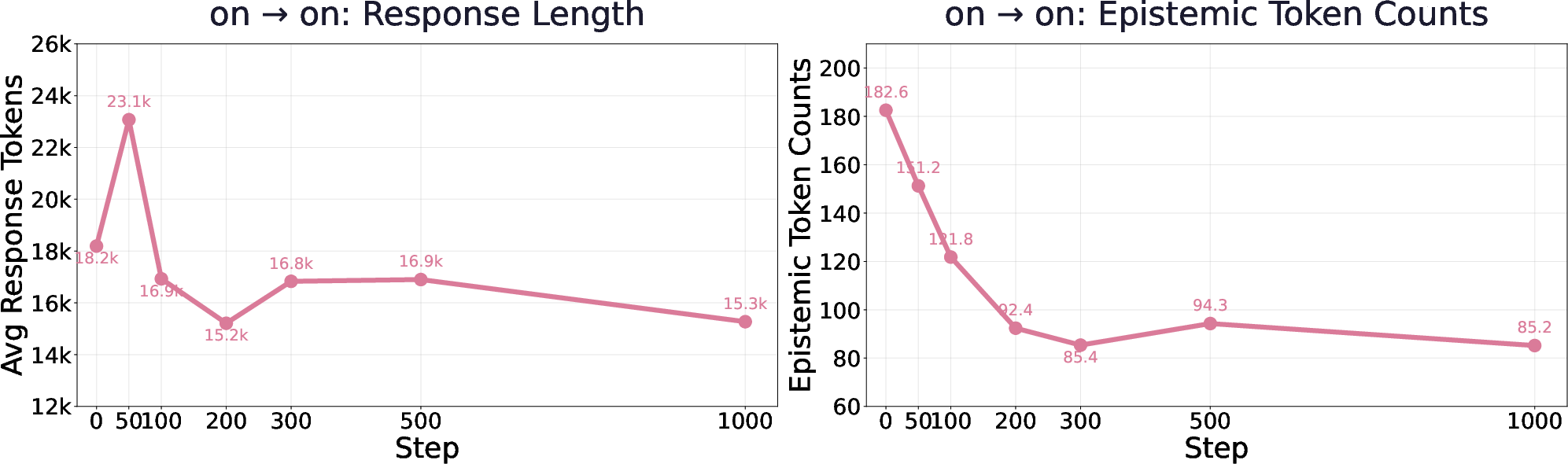
- What happens to a model’s “thinking out loud” style—especially moments where it says things like “wait,” “maybe,” or “let me check”—when the teacher gives very rich hints?
- When does making answers shorter help, and when does it hurt, especially on new, unseen problems?
- How does the variety of training tasks (task coverage) change whether self‑distillation helps or harms?
How the researchers studied it
To keep things easy, think of the setup like this: the same model plays two roles.
- Teacher model: sees extra info (like the correct solution or a previous correct answer) and gives “hints.”
- Student model: doesn’t see those extra hints but tries to learn to sound like the teacher.
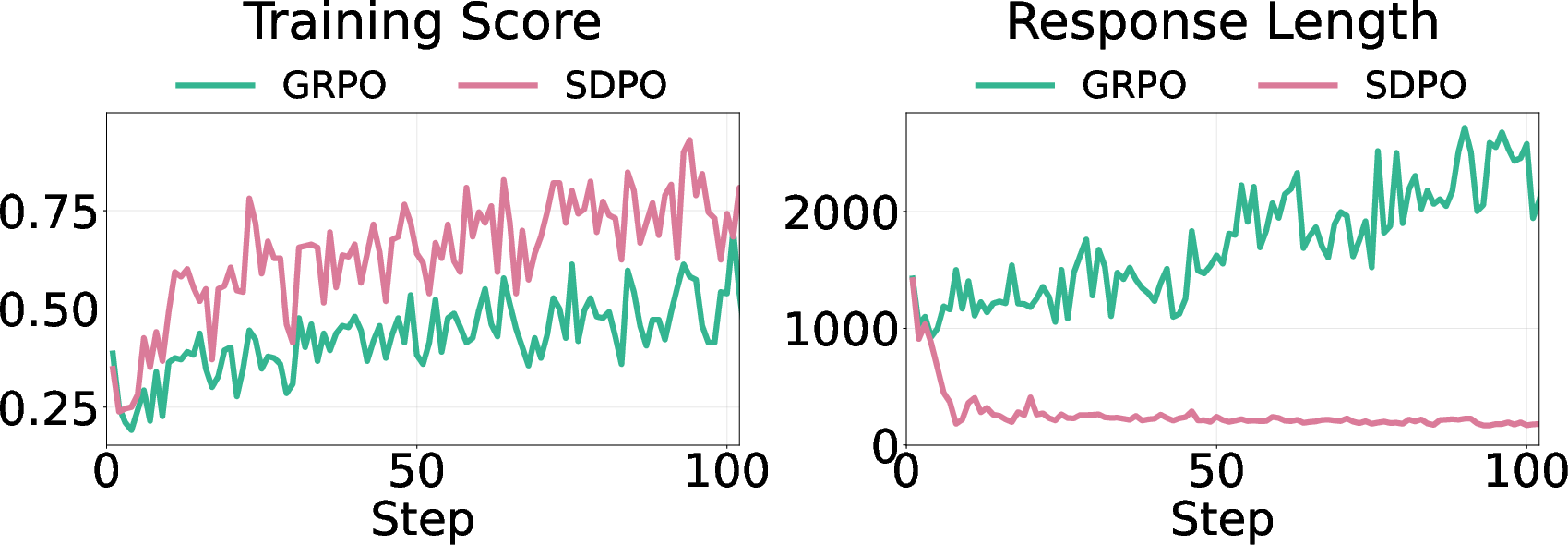
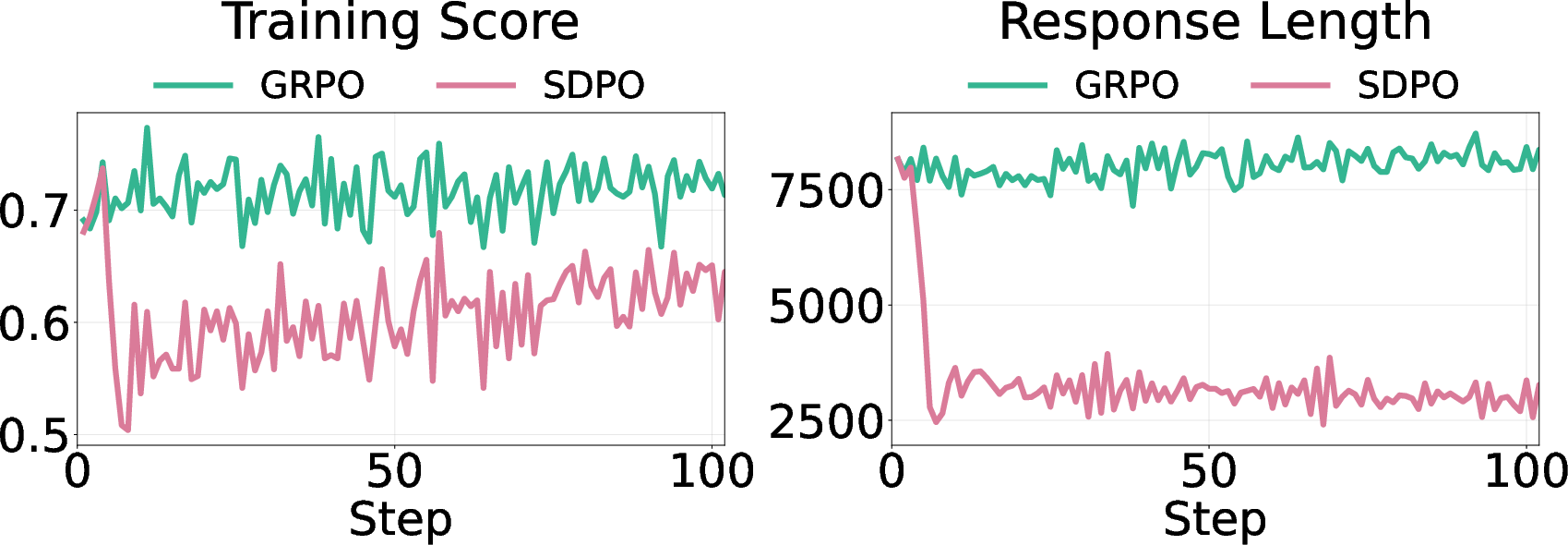
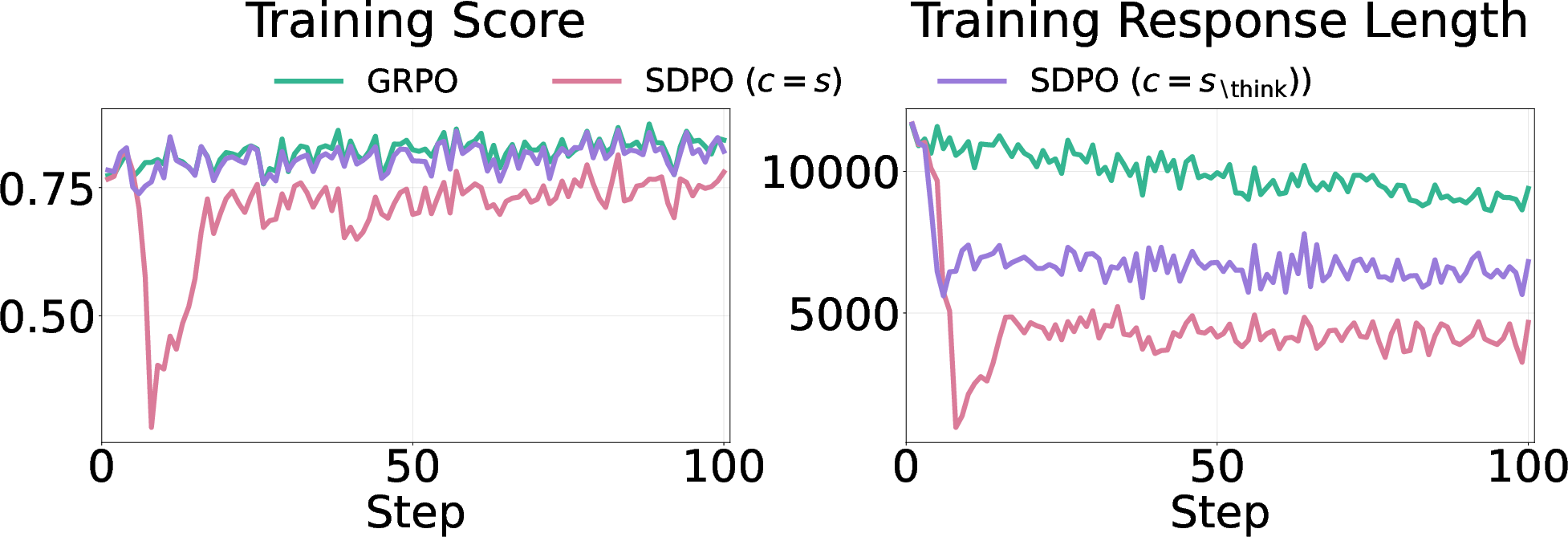
They tested this across several math datasets and models (DeepSeek-R1-Distill-Qwen-7B, Qwen3-8B, OLMo3-7B-Instruct). They compared two types of training:
- Regular reinforcement learning (called GRPO), where the model improves by trying and getting feedback.
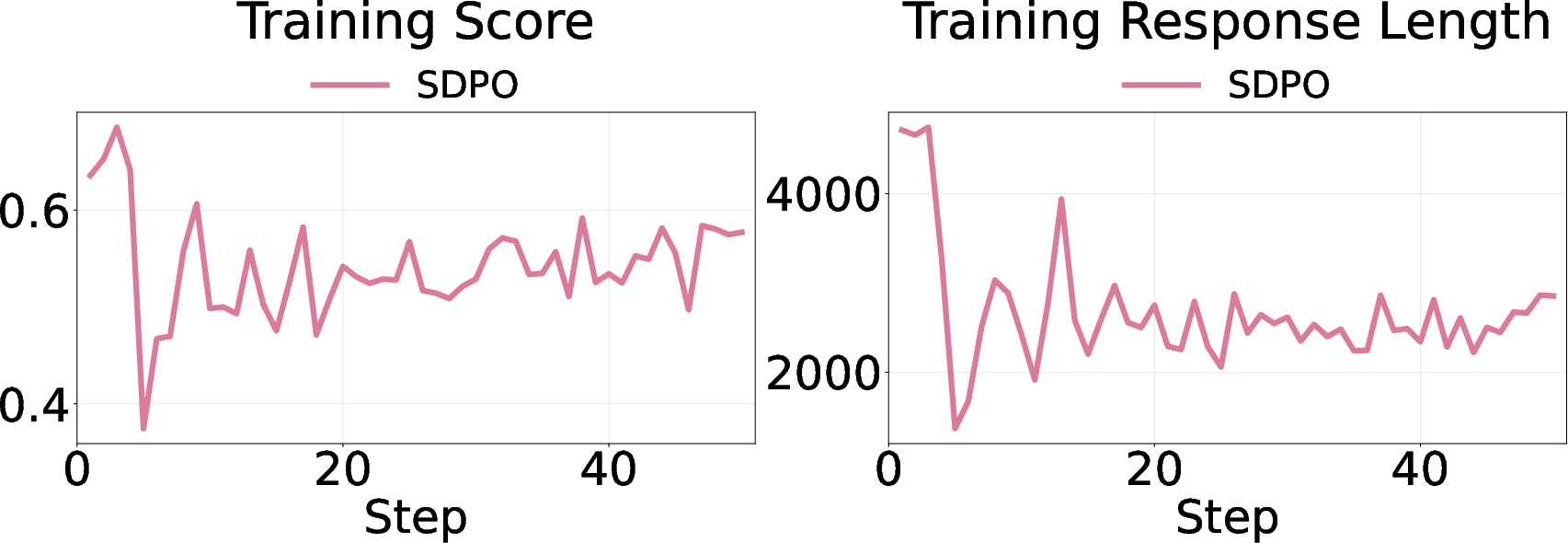
- Self‑distillation training (called SDPO), where the model tries to match a teacher that has extra information.
They measured three things:
- How long the answers are.
- How often the model shows uncertainty (by counting “epistemic tokens” like “wait,” “hmm,” “maybe,” “check”).
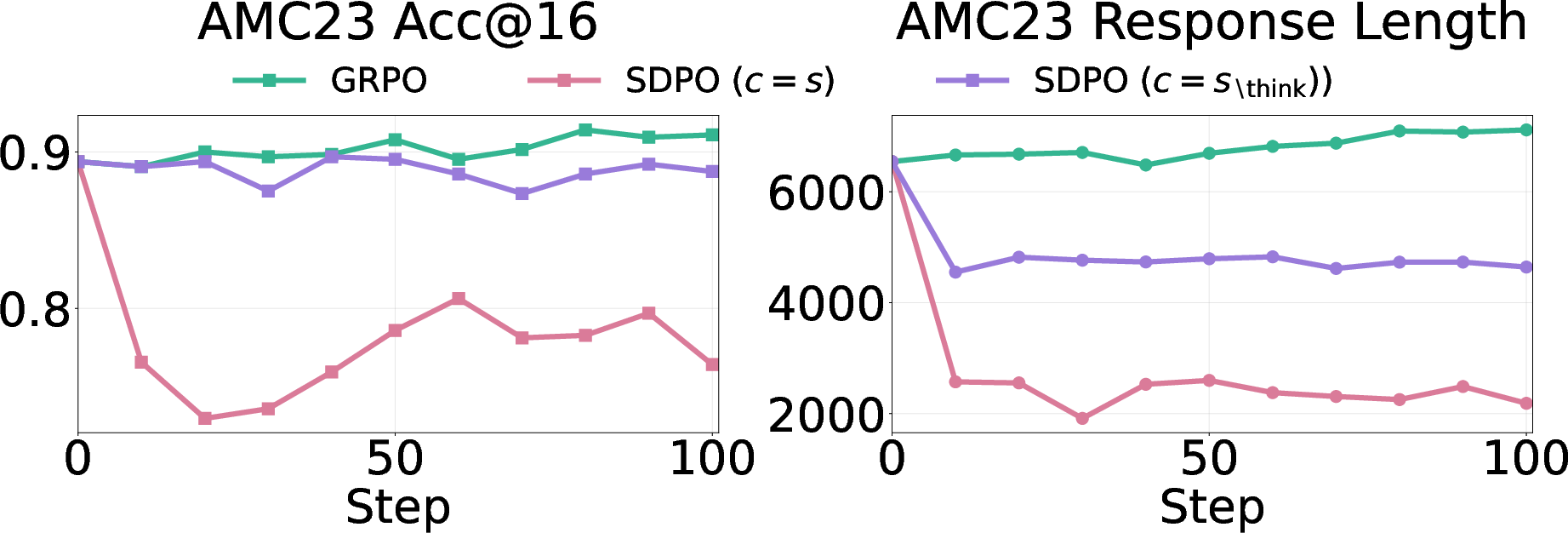
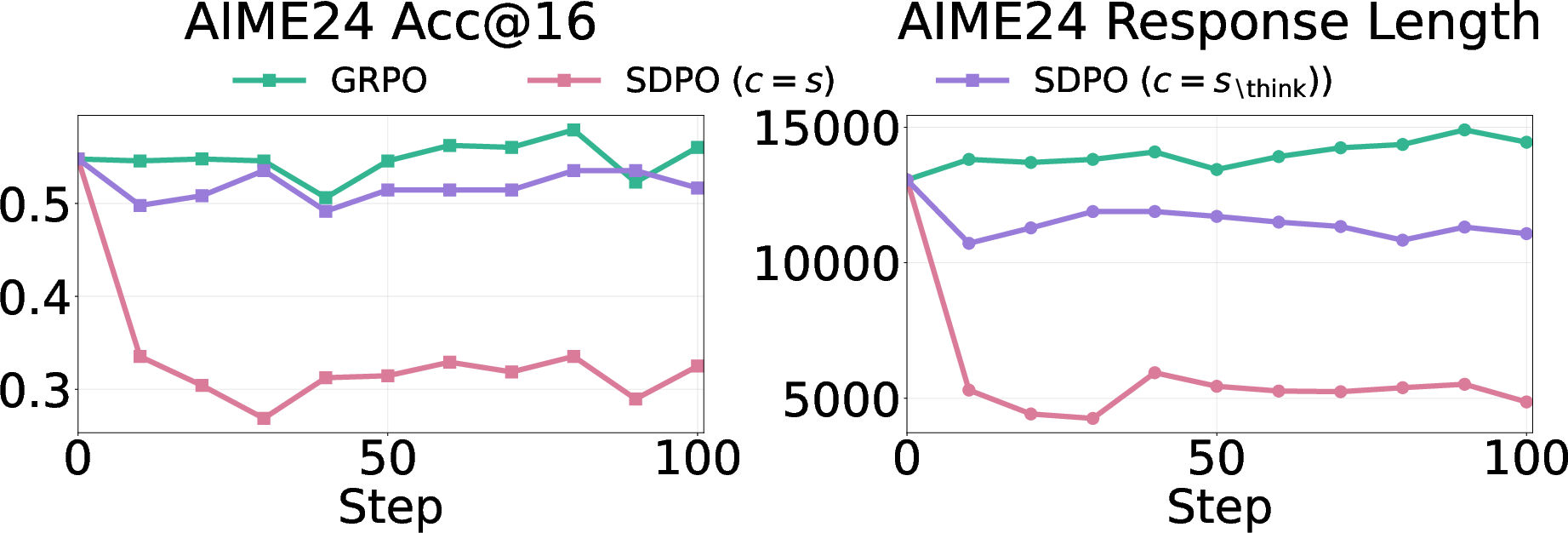
- How accurate the answers are, especially on new tests the model hasn’t seen before (this is called out‑of‑distribution or OOD).
They also ran careful “what if” checks:
- Gave the teacher different levels of help: no help, the full solution (max help), the solution without the hidden “thinking,” or a previously generated correct answer (a weaker hint).
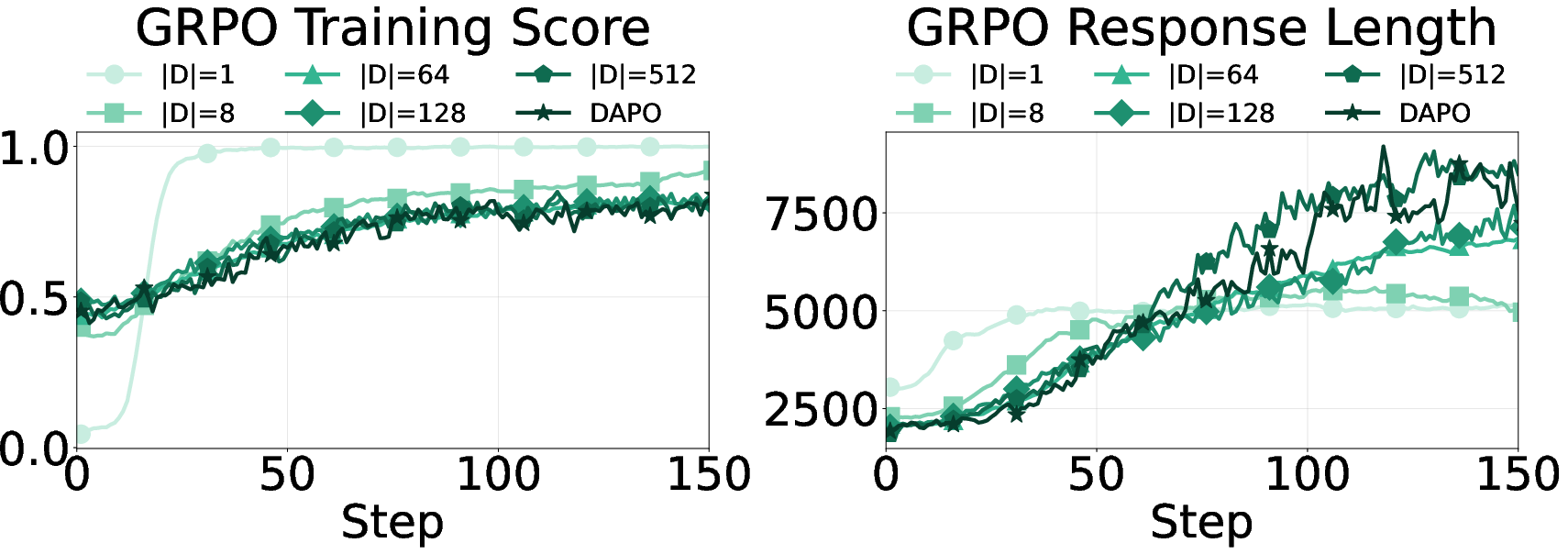
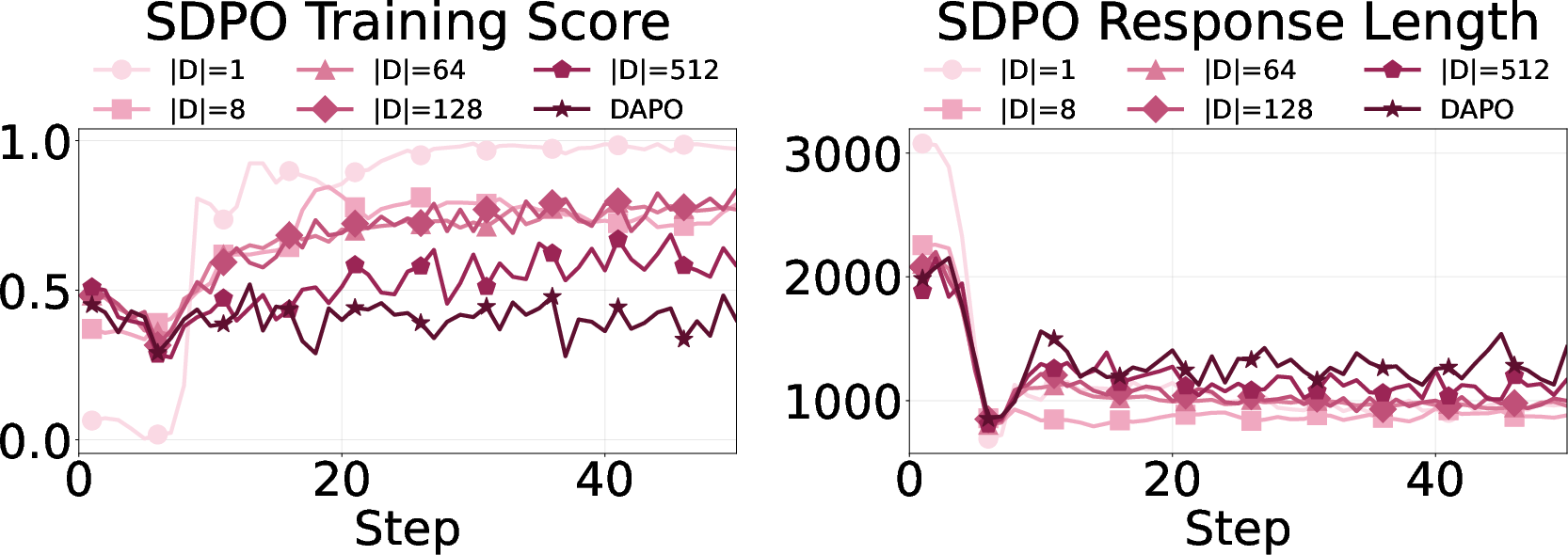
- Trained on small vs large sets of problems to vary “task coverage” (how wide the variety of practice is).
- Used a fixed teacher vs a teacher that keeps updating during training.
Simple analogy for a key idea (information richness): The more the teacher whispers the correct steps, the more the student learns to sound confident and brief. But if the student won’t get those whispers during a real test, that confidence can backfire.
What they found (and why it matters)
Here are the main takeaways, explained plainly:
- Richer hints make answers shorter and more confident.
- When the teacher sees the full solution, the student learns to be brief and sure of itself.
- The model uses fewer “uncertainty” words like “wait,” “maybe,” and “check.”
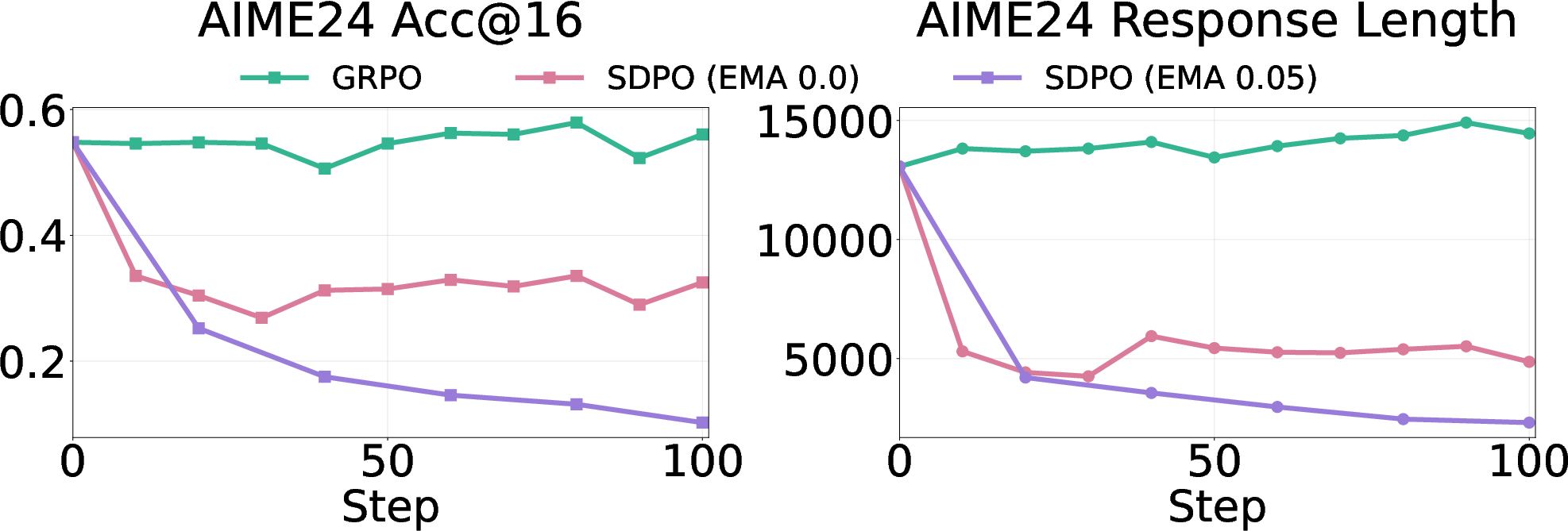
- In math, this confidence can hurt accuracy—especially on new, unseen problems.
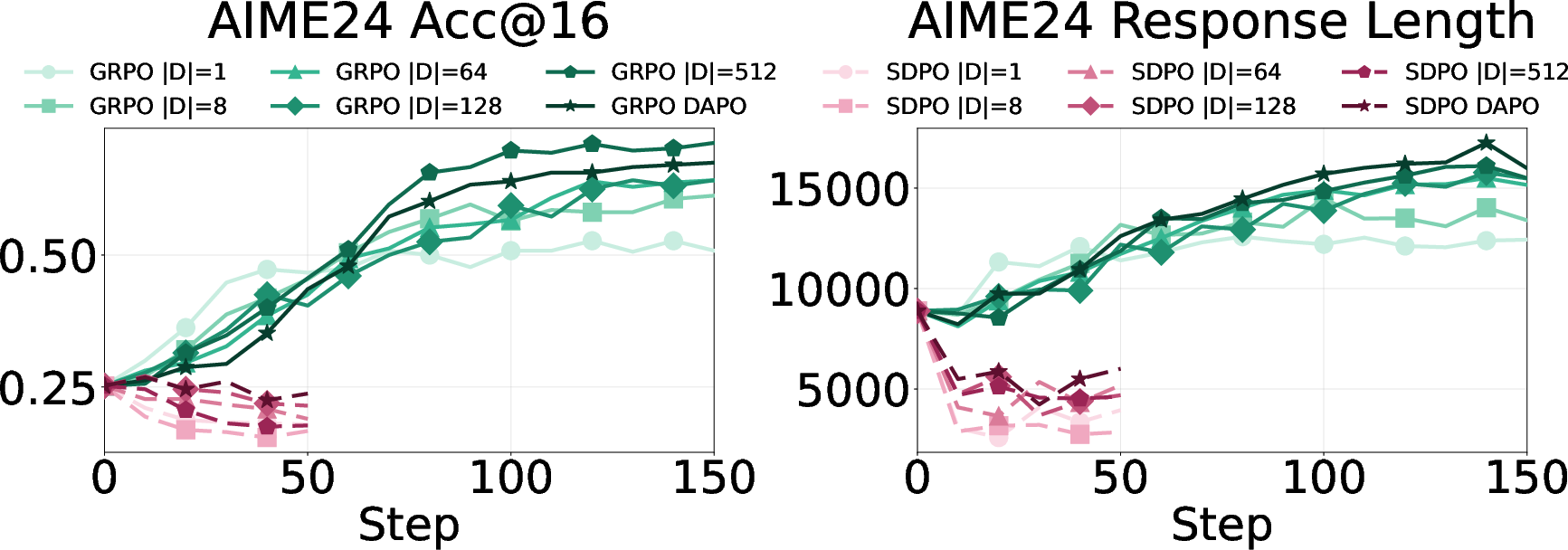
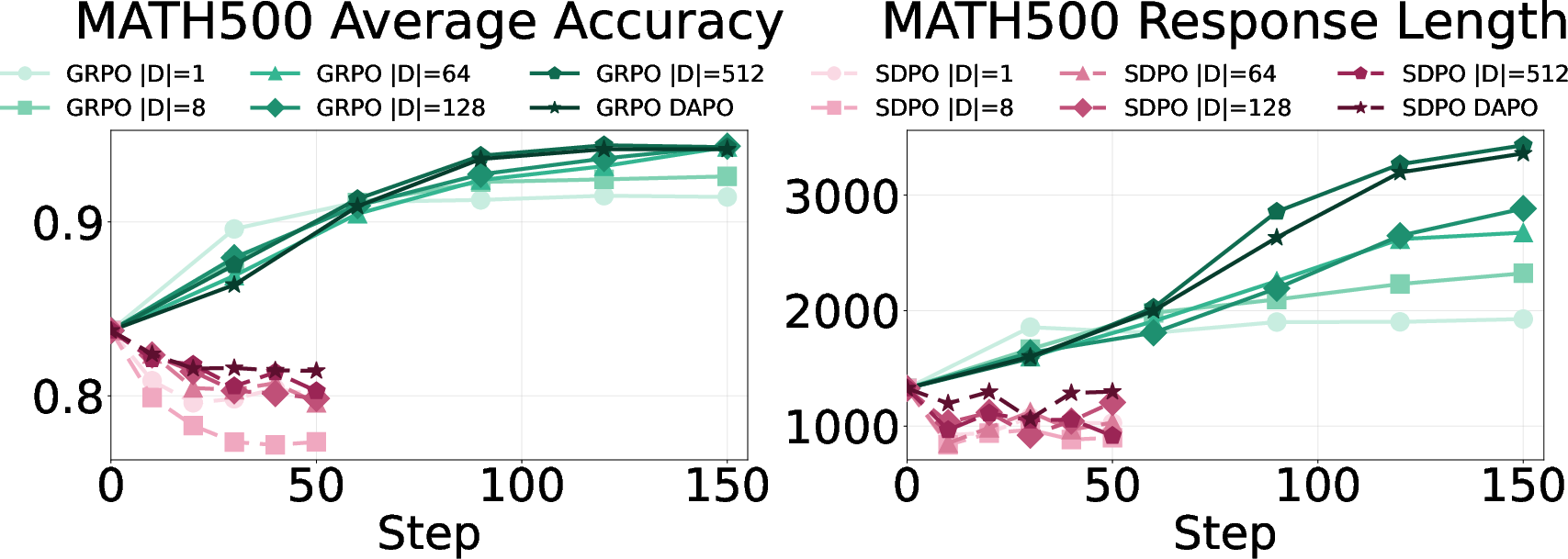
- On math benchmarks, self‑distillation sometimes caused big drops (up to around 40% on AIME24).
- Regular reinforcement learning (GRPO) often gave small gains and sometimes even increased healthy “thinking out loud.”
- Training on concise, solution‑guided examples can be harmful—even when those examples are correct.
- If you train the student to imitate a super‑confident teacher who saw the answer key, the student learns a style that assumes helpful hints it won’t have at test time.
- That style suppresses useful “pause and double‑check” moments that help catch mistakes.
- The more varied the tasks, the more important it is to keep some uncertainty.
- In areas like chemistry or coding tasks with repeated patterns or overlapping practice/test sets, cutting down “thinking out loud” helps speed and accuracy.
- In math, with lots of different problem types and deeper reasoning, keeping some “I might be wrong—let me check” behavior helps generalization.
- Technical detail that’s easy to remember: a moving teacher makes it worse.
- If the teacher keeps updating to match the student’s growing confidence, a feedback loop forms that squeezes out uncertainty even more, leading to bigger drops.
- A fixed teacher (one that doesn’t change) is more stable.
Why this is important
The big lesson is that good reasoning isn’t just about getting the right final answer—it’s also about how you get there. For tough or unfamiliar problems, openly handling uncertainty—pausing, checking, and trying alternatives—actually helps you be more right in the end. If we train AI to always sound short and sure, we can accidentally remove the very habits that prevent mistakes.
What this could change going forward
- Training should aim not only for correctness and brevity, but also for healthy “uncertainty‑aware” thinking.
- Self‑distillation should be used carefully in math and other diverse, challenging domains:
- Limit how much extra information the teacher gets, or
- Keep some uncertainty expressions during training, or
- Use a fixed teacher to avoid runaway overconfidence.
- Designers should monitor “epistemic tokens” (like “wait,” “maybe,” “check”) as a safety dial: too many could be rambling, too few could mean reckless confidence.
- In short, smarter training means teaching models when to be concise—and when to slow down and double‑check.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, organized by theme.
Measurement and operationalization of “epistemic verbalization”
- The study operationalizes epistemic verbalization via a fixed list of 10 surface-form tokens; it does not capture paraphrastic, structural, or discourse-level uncertainty expressions (e.g., backtracking, conditional branching, questions).
- No model-agnostic uncertainty proxies (e.g., token-level entropy, sequence entropy, rollout diversity, posterior variance via ensembles) are reported to corroborate the token-based measure.
- The analysis does not disentangle the effect of “epistemic tokens” from mere response length; there are no controlled interventions that fix length while varying uncertainty content (or vice versa).
- Lack of cross-lingual or cross-style robustness: uncertainty markers are English-specific and style-dependent; whether findings hold across languages or different writing conventions is unknown.
- No mapping from epistemic markers to concrete reasoning behaviors (e.g., hypothesis maintenance, self-check steps, backtracking) is provided; behavioral validation is missing.
Information-richness and mutual information
- Conditional mutual information is used only as a qualitative ordering; it is not estimated or validated quantitatively, nor is any practical estimator proposed or evaluated.
- The relationship between , epistemic suppression, and generalization is not formalized beyond empirical association; no causal or theoretical link (e.g., bounds) is established.
- Only a narrow set of teacher contexts is explored (full solution, solution without > , regenerated output); intermediate and structured forms of guidance (partial hints, step-wise hints, answer-only, noisy or uncertain hints) are not examined.
Causality and confounds
The paper argues that suppressing epistemic verbalization degrades performance, but alternative explanations (e.g., shorter chains reduce internal self-check opportunities independent of tokens) are not ruled out.
- No causal interventions isolate the effect of epistemic content from confounds like chain length, formatting, or positional context.
- The off-policy SFT comparison uses small datasets (800 examples) with different lengths and styles; selection bias and dataset-size effects are not controlled.
Training algorithms and objectives
- The work focuses on next-token KL and SDPO/GRPO; other distillation objectives (e.g., sequence-level KL, contrastive distillation, entropy-regularized RL, uncertainty-aware losses) are not evaluated.
- No training objective is implemented that explicitly preserves or rewards uncertainty-aware behavior (e.g., auxiliary rewards for self-checks, penalties for premature commitment, entropy floors).
- Only a few SD configurations are tested; broader hyperparameter and design ablations (e.g., KL coefficients, length penalties, reward shaping, schedule of teacher context richness) are limited.
- Moving-target teacher instability is observed but not formally analyzed; there is no systematic exploration of stabilization strategies beyond freezing the teacher (e.g., teacher lag, partial mixing, separate larger teacher).
- Multi-sample self-consistency (e.g., training on diverse rollouts or majority-vote rationales) is not explored as a mitigation for overconfident compression.
Scope, models, and external validity
- Model scale is limited to ~7–8B parameters; whether the degradation persists, attenuates, or reverses at larger scales is unknown.
- Architectures and pretraining regimes are limited to a few families (DeepSeek/Qwen/OLMO); generality across architectures, instruction-tuning styles, and training corpora is untested.
- Language and domain scope are narrow: the core findings are from math; only anecdotal or borrowed logs from chemistry/code are discussed; controlled multi-domain replications are missing.
- Inference settings beyond the Qwen “thinking” toggle are not systematically evaluated (e.g., hidden CoT in deployment, short-form inference, tool-augmented or retrieval-augmented settings).
- The broader applicability to tasks with tools or verifiable intermediate steps (coding with tests, theorem provers, calculators) is not assessed.
Task coverage, generalization, and evaluation
- “Task coverage” is proxied by the number of unique problems; diversity is not quantified along dimensions like skill taxonomy, compositionality, or difficulty, nor linked to performance with controlled strata.
- OOD evaluation is limited to a small set of math benchmarks (AIME24/25, AMC23, MATH500); results may not generalize to other math distributions or real-world settings.
- No rigorous contamination analysis is presented to guarantee train–test independence, especially given the use of public datasets and logs.
- Error analysis is absent: the study does not categorize failure modes (e.g., premature commitment vs arithmetic errors vs mis-parsing), missing guidance for targeted mitigation.
- Calibration is not measured; there is no evaluation of confidence–accuracy alignment (e.g., ECE/Brier) despite claims about “confidence” and its increase under self-distillation.
- Human evaluation of reasoning quality, interpretability, or perceived overconfidence is not performed.
Robustness and reproducibility
- Variance across random seeds and runs is not reported; confidence intervals and statistical significance are missing.
- Sensitivity to decoding parameters (temperature, top-k/top-p) and training hyperparameters is only lightly ablated; interactions with epistemic suppression are unclear.
- The impact of training compute budgets and efficiency trade-offs (shorter outputs vs sample efficiency vs final accuracy) is not quantified.
Practical design questions and mitigations
- How to design “uncertainty-preserving compression” (shorter but still uncertainty-aware chains) remains open; no concrete methods or benchmarks for this trade-off are proposed.
- Whether mixing GRPO and SDPO (e.g., alternating, curriculum on richness, or adaptive use by difficulty) can retain efficiency without sacrificing OOD performance is not tested.
- The effect of imperfect or noisy teachers (e.g., occasional wrong solutions, uncertain teacher rationales) on epistemic behavior and generalization is unexplored.
- Whether curriculum strategies that gradually reduce (or adapt by task difficulty) can prevent overconfident convergence is untested.
- Downstream safety implications—e.g., whether suppressed epistemic verbalization increases harmful overconfidence or hallucinations—are not investigated.
Theoretical grounding
- There is no formal framework connecting information-richness, epistemic expression, and generalization error (e.g., via capacity/complexity or PAC-Bayes style analyses).
- The hypothesized feedback loop in on-policy self-distillation (increasing confidence begets more confident teachers) is not modeled or analyzed theoretically for stability or convergence properties.
Practical Applications
Practical Applications of the Paper’s Findings
Below are concrete applications derived from the paper’s analysis of self-distillation and epistemic verbalization in LLMs. Each item notes sector(s), potential tools/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed within existing LLM training and deployment pipelines.
- Training guardrails for self-distillation in LLM pipelines
- Sectors: AI/ML platforms, software
- Tools/workflows: Add continuous metrics for epistemic token rate (e.g., counts of “wait/hmm/maybe/check”), response length, and OOD scores to training dashboards (e.g., Eval Harness + W&B). Set alerts when epistemic rate collapses or length shrinks too fast during SDPO/SFT.
- Assumptions/dependencies: Epistemic markers are a proxy for uncertainty; English-focused token lists may need localization; requires access to OOD evaluation sets.
- Safer self-distillation recipes (policy and prompt design)
- Sectors: AI model training, foundation models
- Tools/workflows:
- Prefer fixed teachers (EMA rate ≈ 0) to avoid feedback loops that over-amplify confidence.
- Reduce teacher context richness (e.g., use solution-without-> or regenerated responses) to moderate information transfer. > - Cap response-length compression and tune sampling (temperature/top‑k) to maintain some uncertainty. > - Assumptions/dependencies: Availability of solution artifacts split into “think” vs. non-think; ability to modify SDPO/OPCD pipelines. > > - Data curation for SFT to preserve uncertainty-aware reasoning > - Sectors: AI/ML data engineering > - Tools/workflows: Prioritize unguided, correct trajectories for math/logic SFT; filter out overly concise, solution-guided traces that suppress epistemic tokens. Build data filters that score E(y) and length. > - Assumptions/dependencies: Reliable correctness labels; chain-of-thought storage policies allow retention of “scratch” tokens. > > - Domain-aware deployment toggles for “uncertainty-aware mode” > - Sectors: Education, finance, legal, scientific computing, software assistants > - Tools/products: UI setting to elicit “verify/check/alternatives” in reasoning for OOD-heavy tasks (math word problems, risk analysis). Dynamic prompting that injects “Let’s verify” and “Check constraints” when difficulty/OOD signals are detected. > - Assumptions/dependencies: User acceptance of more verbose outputs; small cost increase from longer generations. > > - Evaluation protocol updates to include OOD and epistemic metrics > - Sectors: AI evaluation, enterprise ML ops > - Tools/workflows: Add AIME/AMC-style OOD tasks to CI; report epistemic token rate and response length alongside accuracy and latency. Track changes over time to detect training drift toward overconfidence. > - Assumptions/dependencies: Representative OOD sets for target domain; consistent sampling policies during evaluation. > > - Task-coverage–aware training choice: when to use SDPO vs. GRPO > - Sectors: AI/ML training > - Tools/workflows: > - Use SDPO with rich teacher context for narrow, repetitive domains (e.g., specific chemistry tasks, internal codebases). > - Use GRPO or moderated SDPO for broad or shifting domains (e.g., general math reasoning), and allow epistemic verbalization to increase with coverage. > - Assumptions/dependencies: Ability to estimate task coverage and domain shift; monitoring of deployment data for drift. > > - Education/tutoring systems that scaffold uncertainty > - Sectors: Education technology > - Tools/products: Math tutors that reward “check,” “alternative,” and verification steps in RL from feedback; avoid training solely on “perfect solution” traces; rubrics that value scratch-work. > - Assumptions/dependencies: Alignment with pedagogy and assessment standards; tolerance for longer student-like chains. > > - Risk dashboards for production monitoring > - Sectors: Finance, healthcare, customer support, compliance > - Tools/workflows: Monitor production LLMs for declining epistemic markers and shrinking responses (potential overconfidence). Trigger rollbacks or switch to “uncertainty-aware mode” when thresholds breached. > - Assumptions/dependencies: Logging/telemetry pipelines; domain-specific thresholds calibrated against outcomes. > > - Agent and tool-use pipelines that retain “check” steps > - Sectors: Software agents, robotics, dev tooling > - Tools/workflows: Keep “VERIFY/TEST/ALTERNATIVE” steps in planning workflows; don’t prune them solely for brevity. For code assistants, enforce “write tests → verify” sequences even if SD reduces verbosity. > - Assumptions/dependencies: Workflow cost/latency budgets; tool execution infrastructure in place. > > - Procurement and governance checklists > - Sectors: Policy, enterprise governance > - Tools/workflows: Require vendors to report OOD performance and uncertainty metrics pre‑deployment; discourage training practices that suppress uncertainty in broad-coverage tasks. > - Assumptions/dependencies: Organizational buy‑in; standardization of metrics and thresholds. > > ## Long‑Term Applications > > These require additional research, scaling, or development before routine deployment. > > - Uncertainty-aware objectives and RLHF extensions > - Sectors: AI research, foundation model labs > - Tools/workflows: > - Add losses that preserve epistemic verbalization when it improves OOD outcomes (e.g., token‑level rewards for “check” regions leading to correctness). > - Calibrated uncertainty penalties for overconfident wrong answers; targeted entropy regularization on epistemic spans. > - Assumptions/dependencies: Reliable detection of helpful vs. gratuitous epistemic tokens; offline/OPE methods for reward design. > > - Information-aware self-distillation schedulers > - Sectors: AI training frameworks > - Tools/workflows: Controllers that adapt the mutual information I(y; c | x) via partial masking of teacher context, randomized regeneration, or curriculum that increases/decreases guidance based on task coverage and OOD risk. > - Assumptions/dependencies: Estimators for task diversity and difficulty; infrastructure to vary teacher prompts on the fly. > > - Internal–external thought separation architectures > - Sectors: AI systems, privacy-preserving AI > - Tools/products: Models with private scratchpads that maintain and leverage uncertainty internally while emitting concise final answers; selective exposure of uncertainty to users when appropriate. > - Assumptions/dependencies: Reliable mechanisms to retain benefits of epistemic reasoning without leaking sensitive CoT; regulatory clarity on CoT exposure. > > - OOD detectors that modulate reasoning style and compute > - Sectors: Platforms, robotics, finance > - Tools/workflows: Online estimators of distributional shift trigger more epistemic reasoning and longer chains; allocate more tokens or additional tool calls when OOD detected. > - Assumptions/dependencies: Accurate shift detection; latency/compute budgets; robust fallbacks. > > - Benchmarks and certifications for uncertainty-aware reasoning > - Sectors: Standards bodies, regulators, safety-critical industries > - Tools/workflows: New cross-domain OOD suites and metrics (accuracy × calibration × epistemic density) for certification of LLMs used in healthcare, finance, legal, and autonomy. > - Assumptions/dependencies: Community agreement on metrics; correlation with real-world safety/performance. > > - Cross-domain agent frameworks with recoverability > - Sectors: Robotics, healthcare, scientific discovery > - Tools/products: Planning agents that maintain alternative hypotheses and “check” actions (e.g., replan/verify/test) as first-class objects; retain uncertain branches to recover from errors. > - Assumptions/dependencies: Task simulators, evaluation harnesses, and liability frameworks; user trust in uncertainty presentation. > > - Curated datasets emphasizing unguided, uncertainty-rich reasoning > - Sectors: Data platforms, research consortia > - Tools/workflows: Collection and annotation pipelines that capture expert scratchwork and mark epistemic spans; privacy-preserving sharing for SFT/RL. > - Assumptions/dependencies: Expert time/cost; IP and privacy protections; standardized annotation schemes. > > - Language-agnostic uncertainty detection libraries > - Sectors: Open-source tooling, multilingual AI > - Tools/products: Embedding-based detectors of uncertainty beyond fixed token lists; integration with TRL/HybridFlow for training-time feedback. > - Assumptions/dependencies: Cross-lingual validation; robustness to stylistic variation. > > - End-user interfaces for calibrated uncertainty > - Sectors: Product design, education, professional tools > - Tools/products: Adaptive UI controls that surface differential diagnoses, alternative plans, or confidence bands; toggle verbosity by user role (novice vs. expert). > - Assumptions/dependencies: UX research to balance trust, clarity, and cognitive load; domain-specific compliance (e.g., medical device regulations). > > - Legal and policy frameworks discouraging overconfident AI > - Sectors: Policy, compliance > - Tools/workflows: Guidance that penalizes training practices which degrade OOD performance by suppressing uncertainty; incentives for reporting uncertainty metrics. > - Assumptions/dependencies: Evidence base linking metrics to harms; coordination across regulators.
Glossary
- Autoregressive distribution: A probability model where each token is generated conditioned on previous tokens in a sequence. "The model defines an autoregressive distribution"
- Chain-of-thought: An explicit sequence of intermediate reasoning steps embedded in a solution. "including chain-of-thought in > tags"
Conditional mutual information: The amount of information shared between two variables given a third, measuring how much extra context reduces uncertainty. "we define the information that provides about the target sequence as the conditional mutual information"
- Data processing inequality: An information-theoretic principle stating that processing cannot increase mutual information between variables. "By the data processing inequality, ."
- Epistemic markers: Specific tokens that signal uncertainty being verbalized during reasoning. "we define a set of 10 epistemic markers "
- Epistemic verbalization: The explicit expression of uncertainty during the reasoning process. "Even when trained on correct trajectories, excessively suppressing epistemic verbalization can substantially degrade reasoning performance."
- Exponential Moving Average (EMA): A smoothing technique that updates parameters (e.g., a teacher model) using a decayed average of past values. "SDPO uses an EMA-smoothed teacher (EMA rate: 0.05)."
- GRPO: A reinforcement learning baseline method used to optimize LLM policies. "GRPO yields modest OOD gains with a slight increase in epistemic verbalization"
- KL divergence: A measure of how one probability distribution diverges from a reference distribution, used as a training objective. "\mathrm{KL}!\left("
- Off-policy self-distillation (SFT): Learning from pre-collected trajectories using self-generated teachers, applied as supervised fine-tuning. "we conduct off-policy self-distillation (SFT)"
- On-policy self-distillation: Training where the model learns from rewards or signals generated using its current policy while a teacher with extra context evaluates or guides it. "We now turn to on-policy self-distillation"
- Out-of-distribution (OOD): Data or tasks that differ from those seen during training, often used to test generalization. "harming OOD performance"
- Parametric knowledge: Information encoded in a model’s learned parameters, as opposed to external context. "especially in smaller models with limited parametric knowledge."
- Regeneration-conditioned generation: Producing outputs conditioned on a previously generated response used as guidance. "(4) Regeneration-conditioned generation: "
- Reinforcement Learning from Verifiable Rewards (RLVR): An RL approach where rewards are derived from automatically verifiable criteria. "Reinforcement Learning from Verifiable Rewards (RLVR)"
- SDPO: A specific method—Reinforcement Learning via Self-Distillation—where a model learns from a teacher with richer context. "Reinforcement Learning via Self-Distillation (SDPO)"
- Self-Bayesian reasoning: Viewing step-by-step reasoning as iterative belief updating based on prior tokens and the problem context. "math reasoning can be viewed as self-Bayesian reasoning"
- Self-distillation: A training paradigm where a model serves as both teacher and student under different conditioning, transferring knowledge from richer to leaner contexts. "Self-distillation has emerged as an effective post-training paradigm for LLMs"
- Solution-guided generation: Producing responses when the model is provided with the correct solution (or parts of it) as context. "(2) Solution-guided generation: "
- Stop-gradient (stopgrad): An operator that prevents gradients from flowing through certain parts of the computation graph during training. "\mathrm{stopgrad}\big(\pi_\theta(\cdot \mid x,c,y_{<t})\big)"
- Teacher policy: The policy used to generate guidance with richer context, which the student attempts to match. "The teacher policy is obtained by conditioning the model on a richer context "
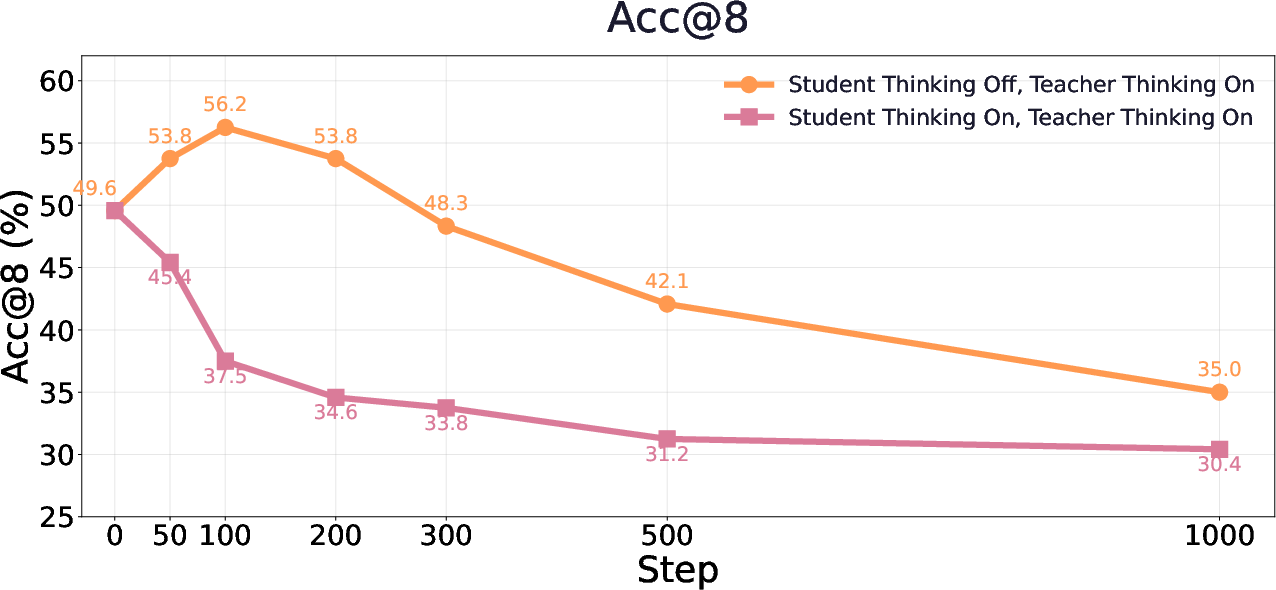
- Thinking mode: A model configuration that enables or disables explicit internal reasoning traces (e.g., <think> tags). "With thinking mode enabled, Qwen3-8B initially generates very long responses"
- Top-k logits: The highest-k predicted token logit values used to analyze or control sampling and training dynamics. "Further ablations on learning rate and top-k logits are in Appendix~\ref{appendix:more_ablation}."
- Unguided generation: Producing responses without any additional guidance context beyond the input problem. "(1) Unguided generation: "
Collections
Sign up for free to add this paper to one or more collections.

