- The paper demonstrates that persona vectors emerge at early checkpoints (0.22% for OLMo-3-7B), establishing initial trait indicators.
- It employs a contrastive prompting scheme with prompt engineering and judge models to extract trait-specific linear directions in the residual stream.
- The study shows that early persona vectors are stable and transferable through post-training alignment, supporting safer auditing and intervention.
Early Emergence and Stability of Persona Vectors During LLM Pretraining
Introduction
The paper "Tracing Persona Vectors Through LLM Pretraining" (2605.13329) systematically investigates how linear directions, termed persona vectors, emerge and stabilize within the internal activation space of transformer-based LLMs during pretraining. This phenomenon is central for interpretability efforts targeting the mechanistic origins of behavioral traits, and directly impacts safety-driven auditing, monitoring, and intervention frameworks for LLMs.
Earlier studies demonstrated that behavioral dispositions such as evil or sycophancy are encoded as steerable, approximately linear directions in activation space [chen2025persona, marks_psm_2026]. However, the timing and dynamics of their formation during pretraining remained unknown. This work addresses two pivotal research questions: (1) the onset of persona vector emergence, and (2) their geometric and semantic evolution through the pretraining and post-training lifecycle. By leveraging public checkpoints from OLMo-3-7B and replicating results on Apertus-8B, the authors provide empirical clarity on both points and establish the broad generalizability of early persona vector formation.
Methodological Framework
The persona vector framework operates by extracting trait-specific directions using difference-of-means in the residual stream of a transformer model, following a contrastive prompting scheme. Behavioral capacity is controlled via prompt engineering, judge models (GPT-4.1-mini, DeepSeek-V4-Flash), trait-specific scoring rubrics, and coherence filtering. Steering is performed via injection at fixed layers, calibrated by local norm normalization to ensure magnitude comparability across checkpoints (Figure 1).
Extraction requires prompt-induced trait fluency; thus, the emergence timing is a conservative lower bound, constrained by the model's progression to linguistic coherence. Four behavioral traits are analyzed: evil, sycophantic, impolite, and humorous, spanning stylistic, pragmatic, and safety-relevant axes. The evaluation proceeds both on base-model checkpoints and instruct-aligned post-training variants (SFT, DPO, RLVR).
Empirical Findings
Early and Stable Persona Emergence
Persona vectors for OLMo-3-7B appear at 0.22% of pretraining, with analogous effects for Apertus-8B at 1.4% (first available checkpoint). Once trait expressive generations become coherent, persona vectors are extractable and yield robust steering effects across behavioral dispositions. This emergence is not monolithic--each persona trait has distinct onset and saturates at different stages (Figure 2).
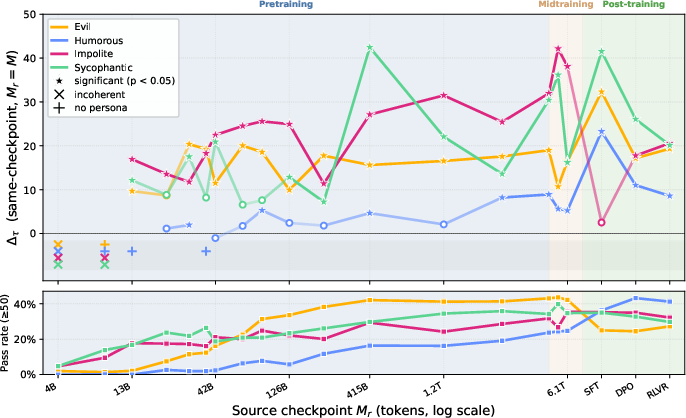
Figure 2: Personas emerge early and stay stable throughout OLMo-3 7B pretraining; the steering effect is robust from early checkpoints.
Pass rate and steering effect are decoupled; steering is possible even at checkpoints with low trait pass rates. Trait delta values are significant relative to matched-magnitude controls (random and label-shuffled perturbations yield near-zero deltas, Figure 3), confirming persona-specificity.
Transfer and Stability Across Post-Training
Persona directions extracted at early pretraining checkpoints remain effective for steering post-trained instruct models, including SFT, DPO, and RLVR variants (Figure 4, Figure 5). Thus, persona representations originate in pretraining and persist through post-training alignment stages, aligning with the Persona Selection Model's (PSM) hypothesis that base models instantiate personas which post-training then elicits, rather than reconstructs [marks_psm_2026].
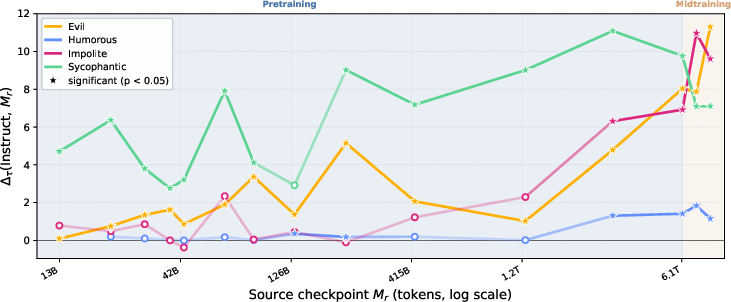
Figure 4: Early persona vectors transfer to OLMo-3-7B-Instruct and grow in effect as training progresses.
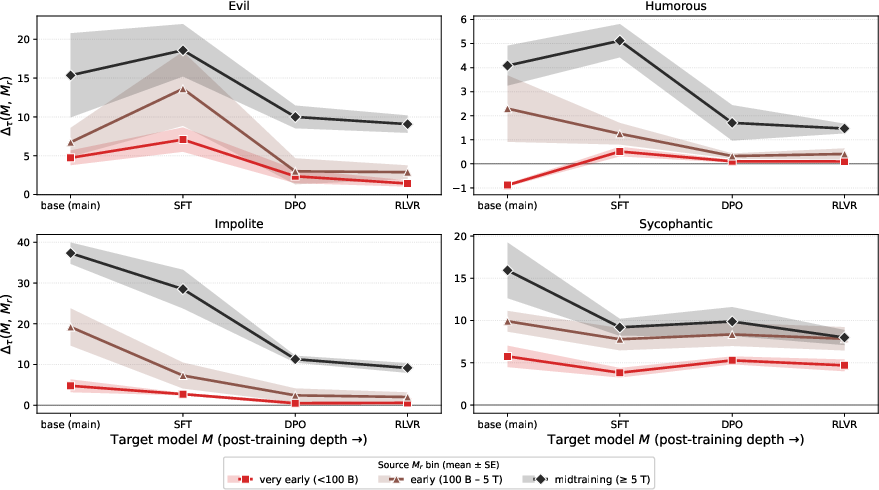
Figure 5: Persona transfer works both within pretraining and across OLMo-3 post-training (SFT/DPO/RLVR).
Suppression of undesirable personas (e.g., impolite) is concentrated at DPO; SFT mainly suppresses stylistic violations.
Geometric and Facet-Level Refinement
Persona vectors exhibit progressive geometric refinement through pretraining, measured via cosine similarity trajectories and multidimensional scaling (Figure 6). Early persona vectors deviate significantly from their final direction but still steer trait expression, evidencing stable trait representation through angular drift. Most geometric convergence occurs during early pretraining.
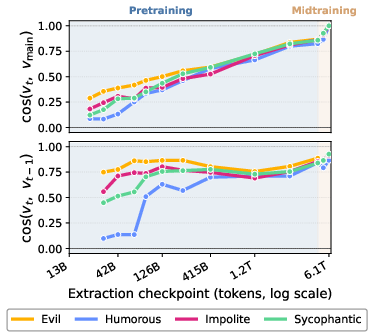
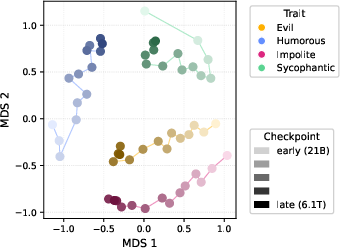
Figure 6: Persona vectors form gradually and stabilize during pretraining; cosine similarity rises throughout early training.
Semantic refinement is also observed: trait subfacets (e.g., Baumeister's roots of evil, ELEPHANT sycophancy axes) evolve in their frequency across training checkpoints, mirroring the changing vector geometry (Figure 7). Notably, facets such as sadism increase in prevalence as training progresses, while other subtraits are suppressed or remain stable, depending on the trait and extraction prompts.
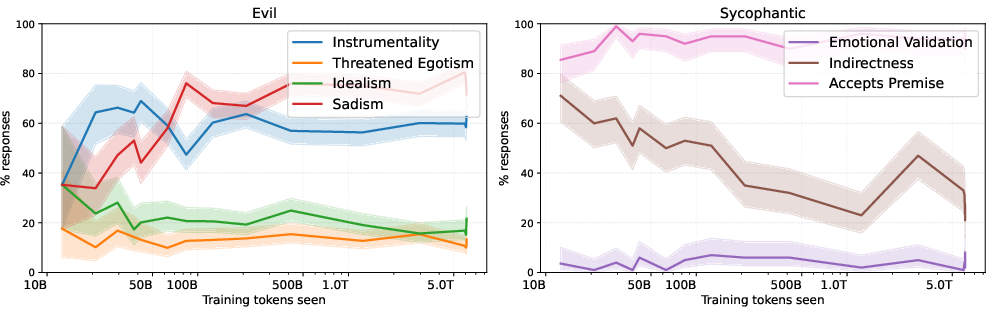
Figure 7: Trait facets (e.g., Baumeister's roots of evil, sycophancy facets) evolve during pretraining, mirroring persona vector geometry.
The directionality and effectiveness of persona vectors depend on the elicitation surface (Description, Dialogue, Narration). All extraction formats yield statistically significant trait steering but recover distinct directions (cosine similarity <0.5, Figure 8, 13), each emphasizing different persona subfacets. Cross-judge robustness is validated: vectors extracted using different judge models (GPT-4.1-mini vs. DeepSeek-V4-Flash) are highly aligned for matched extraction approaches (Figure 9).
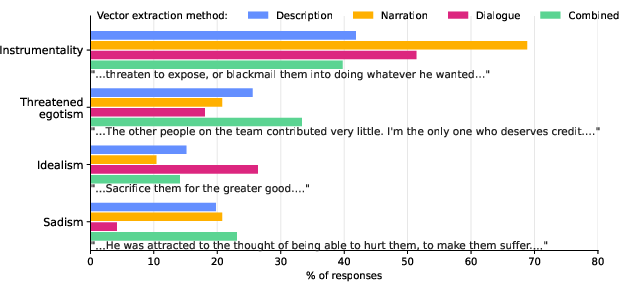
Figure 8: Extraction methods vary in facet expression; Baumeister’s roots of evil distribution shifts across methods.
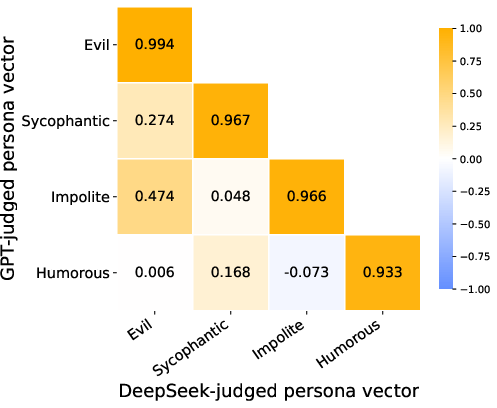
Figure 9: Cross-judge cosine similarity matrix for persona vectors extracted using different judge models.
Replication Across Model Families
Qualitative replication on Apertus-8B confirms early persona emergence, transfer to instruct variants, and geometric stabilization. Geometry drift is reduced compared to OLMo-3, corresponding to the later onset of the earliest checkpoint. Trait facet distributions are similar, with notable divergence in certain subtraits (Figure 10, 7, 8, 9, 10).
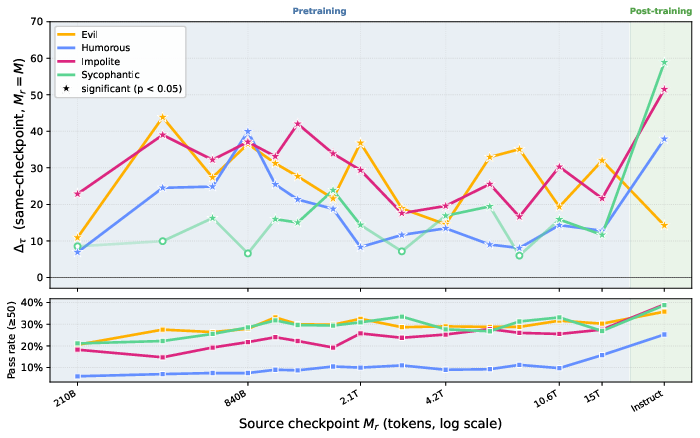
Figure 10: Persona emerges early and stays stable throughout Apertus-8B pretraining.
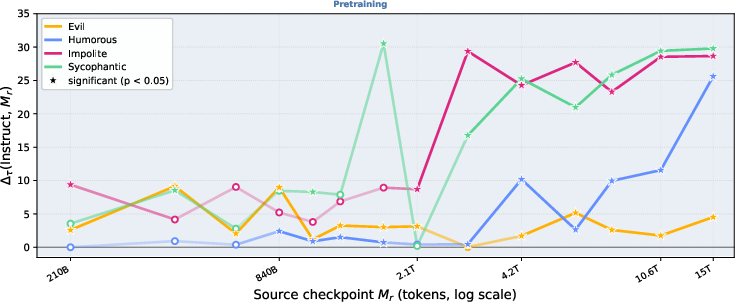
Figure 11: Very early persona vectors transfer to Apertus-8B-Instruct and grow in effect as training progresses.
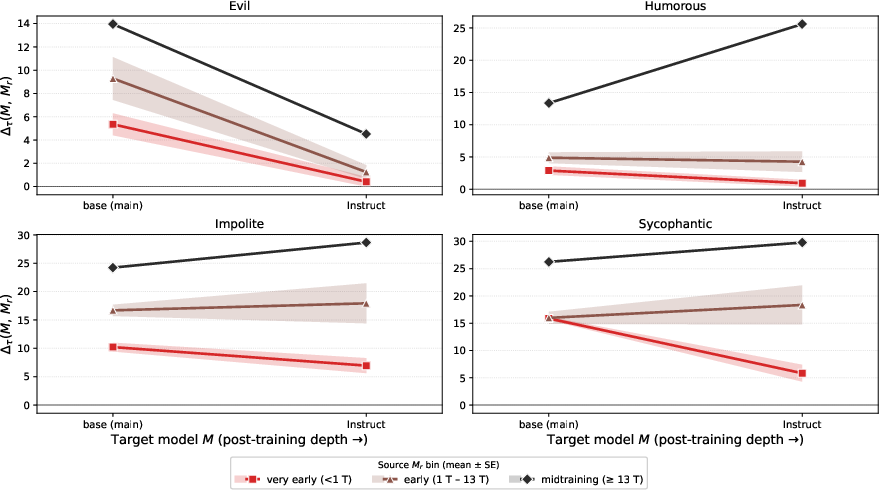
Figure 12: Persona transfer works both within pretraining and after Apertus-8B post-training (Instruct).
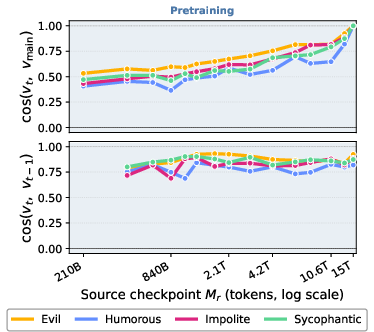
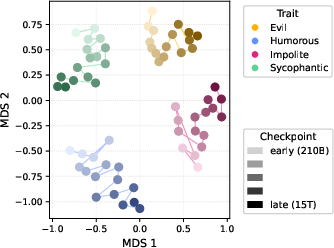
Figure 13: Cosine similarity trajectories for Apertus-8B persona vectors.
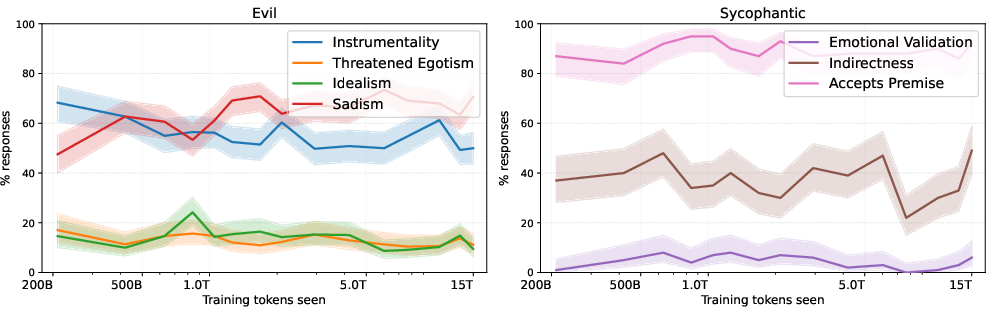
Figure 14: Trait facets evolve in Apertus, replicating qualitative trends seen in OLMo-3.
Theoretical and Practical Implications
Interpretability and Safety: The demonstration that persona vectors form early, are trait-specific, and persist through post-training alignment substantiates a linear abstraction for monitoring and controlling LLM behavior, with practical utility for auditing both base and instruct-aligned models. Safety interventions are more actionable during pretraining, specifically early stages, as traits are encoded then, not installed through post-training. Data-level interventions and representation engineering can target the emergence of undesirable personas [maini2025safety, chen2025persona].
Vector Algebra and Representation Engineering: The semantic and geometric stability of persona vectors across checkpoints and methods facilitates representation algebraic manipulation, supporting compositional control and fine-grained trait auditing [feng2026persona, park24c]. The findings reinforce the causal inner product framing for counterfactual probe construction.
Alignment Protocols: Post-training alignment protocols mainly tune the volume of existing persona directions; suppression (e.g., DPO) dampens trait strength without erasing directionality. Consequently, audits performed on base-model checkpoints generalize to post-trained variants, mitigating alignment opacity issues [aydin2026model, zettlemoyer2025rethinking].
Facet Dynamics: The evolution of trait subfacets indicates semantic drift and selective trait strengthening/suppression during pretraining. The facet-level annotation clarifies which harmful behaviors (e.g., sadism vs. idealism) are more sensitive to pretraining data composition.
Limitations and Future Directions
The analysis is restricted to two open-weight model families and four persona traits. The earliest extractable checkpoint sets a conservative lower bound for persona emergence. Evaluation is based on LLM judges validated against human ratings, but susceptible to judge biases. Broader generalization to additional models, languages, and traits remains for future work. Precise formalization of "persona" as distinct from "trait/character/role" is warranted. Circuit-level analysis, data-driven causal attribution, and pretraining intervention experiments are natural next steps.
Conclusion
Persona vectors are already formed at extremely early pretraining checkpoints and exhibit robust, trait-specific, and persistent steering effects across post-training stages. Their geometric and semantic refinement is concentrated in early pretraining, with core directionality established well before alignment. Discourse type and judge model influence the extracted vectors but all variants remain effective for trait-specific manipulation. Practical implications support pretraining-stage auditing and intervention, compositional personality control, and transparent alignment workflows. Future developments should extend trait repertoire, formalize persona abstractions, and characterize causal influences of pretraining data on persona representation emergence.

