- The paper introduces a novel closed-loop simulation framework that integrates action-conditioned video generation with proprioceptive state decoding for robotic manipulation.
- It leverages a multi-view diffusion transformer and automated reward modeling to closely align simulated outcomes with real-world robotic performance.
- The system achieves marked improvements in visual fidelity, temporal consistency, and sim-to-real policy alignment compared to traditional simulators.
GE-Sim 2.0: Comprehensive Closed-Loop Video World Simulation for Robotic Manipulation
Motivation and Framework
GE-Sim 2.0 establishes a new paradigm for robotic manipulation simulation by integrating action-conditioned video generation with closed-loop, policy-compatible interfaces, directly addressing inadequacies in classical simulators regarding contact dynamics, deformable object modeling, and visual realism. The model operates as a multi-modal, multi-view generative simulator, trained on thousands of hours of real dual-arm robot episodes spanning teleoperation, policy deployment, and rich object interaction. The core architecture couples a vision diffusion transformer and a proprioceptive state expert, delivering action-conditioned rollouts available to policy models for chunk-wise, closed-loop evaluation and learning.
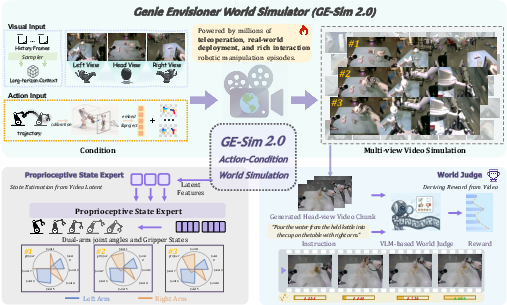
Figure 1: GE-Sim 2.0 overview, highlighting action-conditioned multi-view video generation, proprioceptive state decoding, and world judge integration.
Technical Architecture
Vision and Proprioceptive Experts
The vision expert is an action-conditioned multi-view diffusion transformer, operating in video VAE latent space and conditioned on dense action representations, including camera raymaps and spatially aligned end-effector pose maps. Conditioning employs explicit geometric priors from camera and robot calibration, preserving spatial alignment throughout the model, critically enabling robust simulation under dynamic viewpoints.
Parallel to visual simulation, the proprioceptive state expert consumes chunk-wise vision expert features and predicts future joint angles and gripper openness, closing the gap between mere action-command following and true observation-state rollouts required for modern VLA policies.
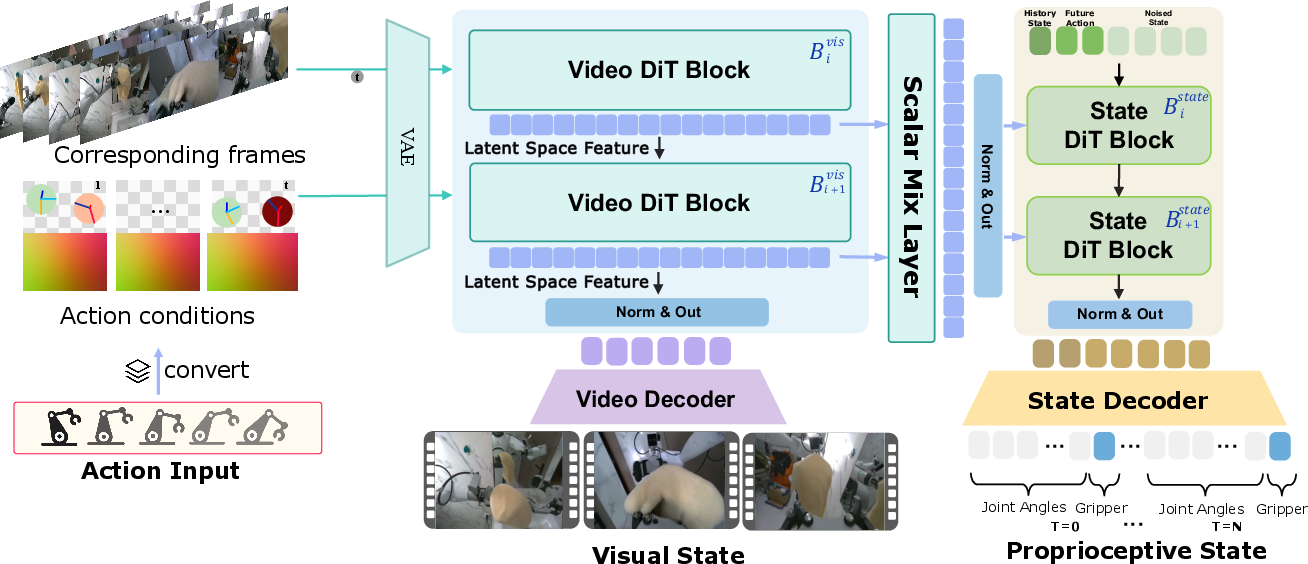
Figure 2: Vision expert generates future states, while proprioceptive expert decodes joint angles and gripper openness.
World Judge: Automated Reward Modeling
GE-Sim 2.0 integrates a vision-language world judge for reward estimation, leveraging a frozen vision encoder and task-conditioned LLM to score rollouts and output frame-level, machine-verifiable binary task success signals. Its supervision employs manual trajectory annotations, favoring sparse, per-frame feedback over unreliable progress scalar signals, and the module is outperformed by specialist heads compared to general VLMs in frame-wise task success correlation.
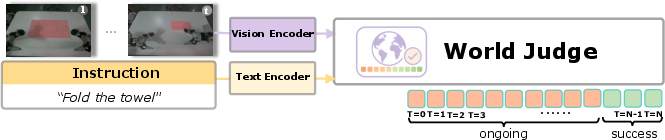
Figure 3: World Judge scoring rollouts against task instructions, providing policy evaluation signals.
Acceleration and Long-Horizon Fidelity
The simulation framework is subject to optimized throughput via two synergistic accelerations: step distillation using DMD2 for reducing diffusion inference steps, and random-stride training for temporal frame skipping, yielding efficient long-horizon generation without measurable loss in spatial-temporal consistency. GE-Sim 2.0 enables a 100-frame rollout generation in 2.3 seconds on a single H100, supporting scalable policy evaluation.
Experimental Results
Visual Fidelity and Temporal Robustness
GE-Sim 2.0 attains the best score on the WorldArena leaderboard, outperforming both open and closed-source robotic and general video generators, despite a modest 2B parameter scale. Replay metrics across six manipulation tasks demonstrate clear superiority: PSNR +3.96 dB over Ctrl-World and +5.67 dB over DreamDojo (head view), halved FID scores, and 2.5× reduction in FVD (multi-view). Visual fidelity is sustained over long-horizon, chunk-wise rollouts, exhibiting less degradation than competing baselines.

Figure 4: GE-Sim 2.0's qualitative results on the Pull out plug task, successfully modeling both action-following and final lamp state changes.

Figure 5: Pour water task, showing GE-Sim 2.0 producing faithful liquid handling rollouts, while baselines fail.
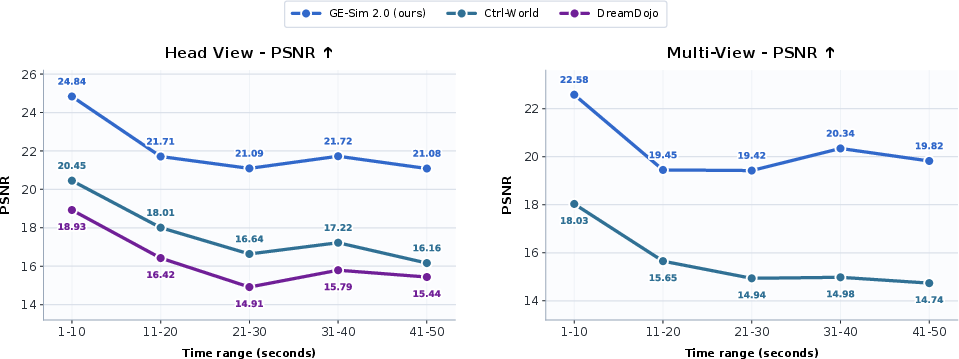
Figure 6: Temporal replay PSNR analysis, demonstrating GE-Sim 2.0's robust long-horizon visual performance.
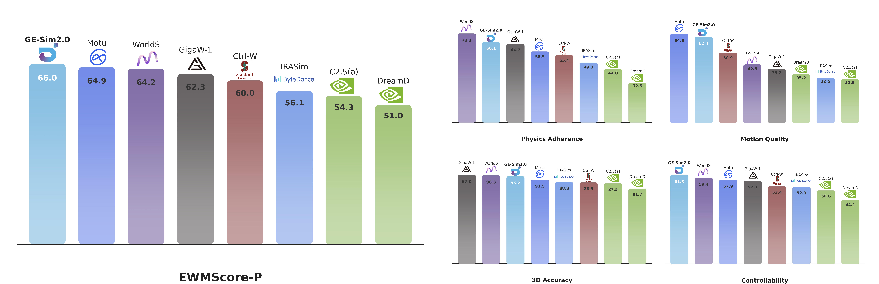
Figure 7: GE-Sim 2.0's WorldArena leaderboard results, establishing dominance over prior models.
Closed-Loop Policy Consistency
Success-rate alignment between world-model predictions and real robot outcomes is substantially improved with GE-Sim 2.0, especially when incorporating the proprioceptive state expert, reducing sim-to-real gaps to ≤1 percentage point for aggregate policy-level metrics. Episode-level confusion matrices yield accuracy improvements from 0.63/0.74 (baselines) to 0.81, and recall increases from 0.25/0.67 to 0.82, demonstrating preservation of real-world task success patterns, particularly in contact-rich domains.
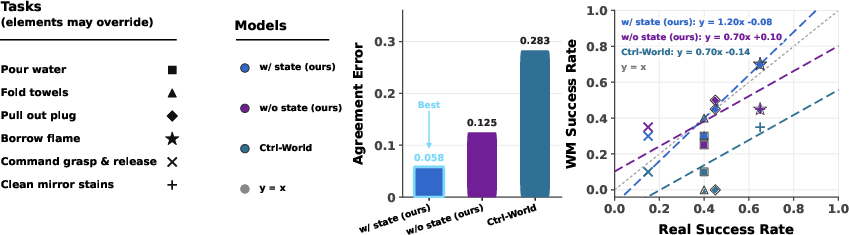
Figure 8: Task-level success-rate scatter plots, evidencing strong alignment between simulated and real-robot outcomes with state conditioning.
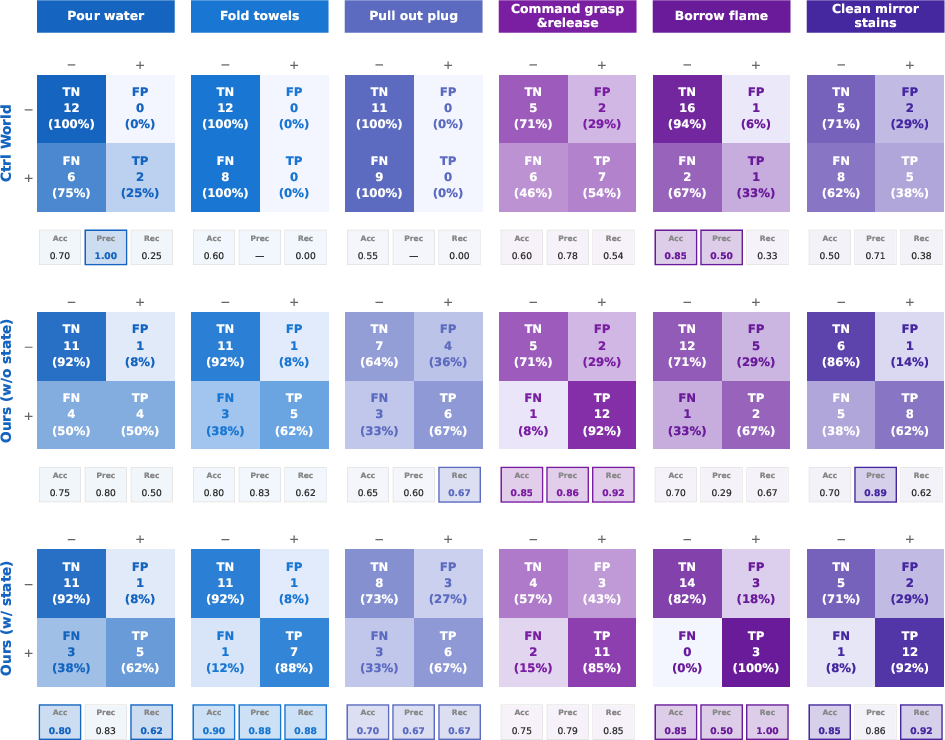
Figure 9: Confusion matrix analysis, confirming higher true-positive rates and policy-consistency.
Reward Modeling
World judge outputs success signals aligned with human annotation on both ground-truth and simulated rollouts, outperforming general VLMs (Qwen3.5-122B) by 19–29 pp in accuracy and halving event localization error. The reward model achieves robust performance across tasks, including those requiring subtle appearance discrimination (e.g., Clean mirror stains) and fine contact tracking.
Policy Improvement via Synthetic Data Generation
Behavior cloning from reward-filtered synthetic rollouts generated in GE-Sim 2.0 yields absolute policy improvements of up to 15 pp across representative manipulation tasks (liquid handling, deformable-object, fine-force interaction).
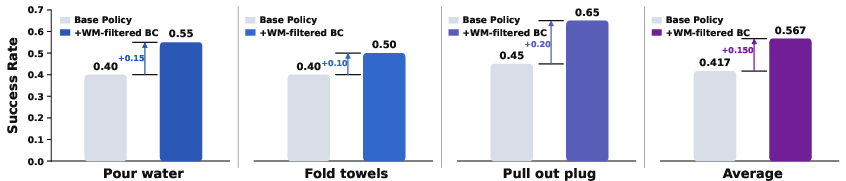
Figure 10: Policy success rates increase after augmenting BC with WM-filtered synthetic trajectories.
Ablations and Component Contributions
Removal of the proprioceptive state expert reduces closed-loop accuracy and recall, confirming its necessity for robust sim-to-real policy preservation. Specialist reward models are shown to outperform general VLMs, especially in tasks with subtle or complex success conditions.
Implications and Future Directions
GE-Sim 2.0 advances video world simulators from passive forward predictors toward active closed-loop platforms that support scalable evaluation, reward-driven policy learning, and imitation/reinforcement learning in robotic manipulation. The modular integration of visual, proprioceptive, and reward modalities forms a foundation for general embodied world simulation, encourages further data and model scaling, and opens avenues for unified state-decoding and reward estimation architectures.
Moving forward, expansion to cross-embodiment domains, ego-centric data, and large-scale UMI-style corpora are necessary for general embodied AI simulation. Unification of reward and state decoding within the world model and transitioning from offline to online, closed-loop policy learning inside the simulator represent key future milestones.
Conclusion
GE-Sim 2.0 provides a technically rigorous and demonstrably effective closed-loop video world simulation platform for robotic manipulation. Through large-scale real-world training, advanced action-conditioned multi-view generation, integrated proprioceptive state decoding, and automated reward modeling, it delivers state-of-the-art fidelity, policy alignment, and practical utility for policy evaluation and data generation, with strong implications for scalable embodied AI and reinforcement learning.

