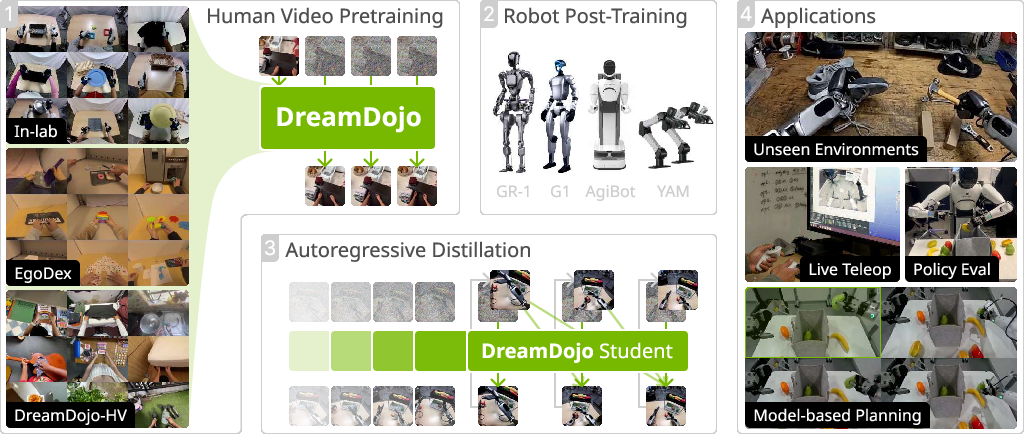
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
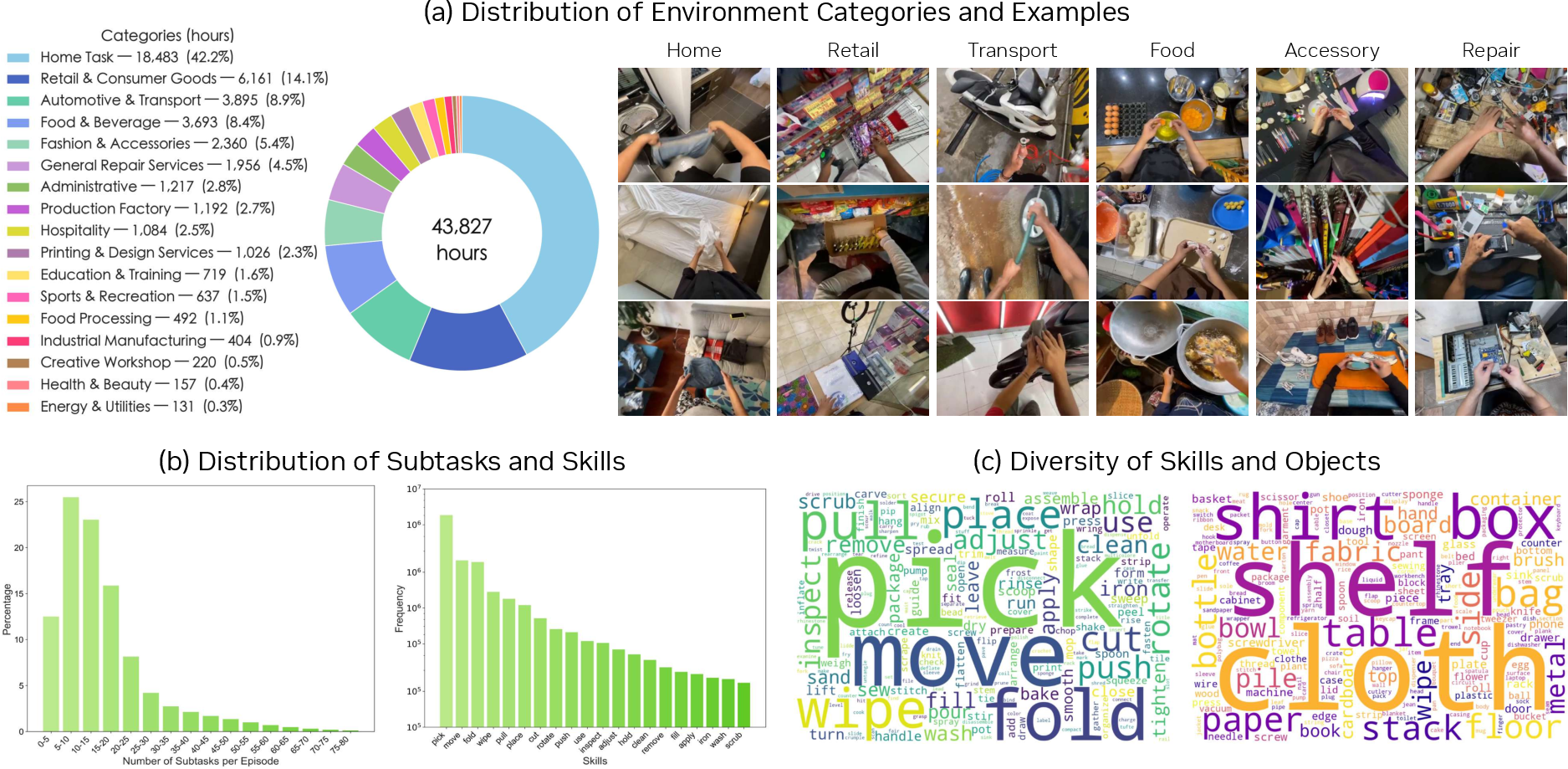
Abstract: Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief Overview
This paper introduces DreamDojo, a powerful “world model” for robots. A world model is an AI that can imagine and predict what will happen next when a robot takes certain actions, like a smart simulator. DreamDojo is trained on a massive set of head-mounted human videos (about 44,000 hours), so it learns how objects behave in everyday life. Then, with a little extra training on a specific robot, it can predict future camera frames in real time as the robot moves, even in new places and with new objects.
Key Objectives and Questions
The researchers set out to answer a few simple but important questions:
- Can we teach robots about the real world by watching lots of human videos instead of collecting expensive robot data?
- Since most videos don’t come with “action labels” (like which joints moved), can we create a smart way to guess actions from the video itself?
- Can we make the model respond quickly enough for live robot control and planning?
- Will the model work in new environments and with new objects it hasn’t seen before?
Methods and Approach
The Data: Learning from Human Headcam Videos
Human videos are everywhere and cover many different objects and situations (homes, schools, offices, stores). Robot videos are rarer and usually only show a few tasks. DreamDojo uses three human sources:
- In-lab: carefully recorded tabletop interactions with precise hand tracking.
- EgoDex: a public dataset of headcam videos with detailed hand poses.
- DreamDojo-HV: a huge crowdsourced set of daily activities across thousands of places and tasks.
“Egocentric” means the camera is worn on the person, so the view looks like what they see.
The Core Idea: A World Model that Predicts Future Frames
DreamDojo builds on a strong video-generating AI. Think of it like a “video crystal ball” that, given the current image and an action, predicts what the next images will look like. The model runs in a compressed “latent space” (a kind of internal code for images) and uses a technique called diffusion to turn noisy guesses into clean, realistic frames.
To make predictions that respond to robot control:
- Relative actions: Instead of absolute joint positions, the model uses small changes from the recent pose. This makes the action space simpler and more consistent across different motions.
- Action chunks: The video is compressed so each “latent frame” covers 4 real frames. The model groups the next 4 actions together and attaches them to the matching latent frame. This reduces confusion and respects cause-and-effect: only the actions that should affect the next frames are used at the right time.
- Temporal consistency: The training includes a loss that encourages smooth, realistic changes between frames (it’s like telling the model, “don’t just make each frame look good—make the transitions look physically right too.”).
Solving the Missing Action Labels: Latent Actions
Most videos don’t say “here are the exact joint movements.” To fix this, the team extracts “latent actions,” which are compact vectors that represent “what changed” between two frames. Think of latent actions as a hidden “controller signal” the AI discovers on its own:
- They use a VAE (Variational Autoencoder), a model that compresses information into a small code.
- The encoder looks at two consecutive frames and produces a short vector (the latent action).
- The decoder takes the first frame plus that vector and reconstructs the second frame.
- A bottleneck forces the model to focus on the most important motion, like hand movement or object motion, instead of background clutter. Because latent actions capture the essence of motion, they transfer well from human videos to robot control—even though humans and robots look different.
Adapting to Real Robots: Post-Training
After pretraining on human videos, they fine-tune the model on a small set of robot videos for the target robot (like a humanoid named GR-1). This step “maps” the internal action understanding to the robot’s specific controls. Thanks to the human pretraining, this robot step can be relatively small but still generalize well.
Making It Real-Time: Distillation (Teacher-Student Training)
The original model is accurate but slow because diffusion takes many steps. Distillation makes it fast:
- Teacher model: Slow and smart, produces high-quality predictions.
- Student model: Learns to mimic the teacher’s outputs, but with fewer steps and “causal attention” (it only looks at past frames, not future ones—just like real-time play).
- Two stages:
- Warmup: The student practices on the teacher’s outputs (“teacher forcing”), learning the right answers.
- Distillation: The student generates its own sequences and aligns its distribution with the teacher’s. This reduces errors that otherwise would build up over time. After distillation, DreamDojo runs at about 10.81 frames per second at 640×480 resolution and stays consistent for over a minute.
Main Findings and Why They Matter
Here are the main takeaways from their tests and evaluations:
Latent actions work: Pretraining with latent actions (instead of no actions) makes predictions more responsive to control. Performance comes close to setups with perfect action labels, but it scales to huge video collections without extra sensors.
- More diverse data helps: Adding more human data sources makes the model better at physics and control, especially for new objects and environments.
- Strong generalization: In human preference tests, people often preferred DreamDojo’s predictions over the base model, especially for action following and physical realism in new scenes.
- Design choices matter: Using relative actions, action chunks, and the temporal consistency loss each improved how well the model followed actions and kept objects stable.
- Real-time success: The distilled version can run live and remain stable over long sequences, enabling practical uses like teleoperation and planning.
Implications and Potential Impact
DreamDojo shows a promising path to building generalist robot “world models”:
- Safer, cheaper development: You can test robot policies in a realistic simulator before trying them in the real world, reducing risk and cost.
- Faster iteration: Engineers can evaluate and refine strategies without running the robot every time.
- Live control and planning: Real-time predictions help with teleoperation (a person controlling the robot remotely) and model-based planning (the robot simulates different options to pick the best action).
- Broad generalization: Training on huge, varied human video sets helps robots handle diverse scenes and objects, which is vital for everyday tasks.
In short, DreamDojo demonstrates that learning from large-scale human videos, plus smart action inference and fast distillation, can push robot world models toward being practical, responsive, and general-purpose.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following items highlight what remains missing, uncertain, or unexplored in the paper. Each point is formulated to be concrete and actionable for future research.
- Dataset release and ethics:
- Are DreamDojo-HV, In-lab, and the curated mixtures publicly released? If not, reproducibility and benchmarking are limited.
- How were privacy, consent, and licensing handled for crowdsourced egocentric videos? Provide protocols and documentation.
- Quantify demographic, geographic, and object diversity to surface potential biases and their downstream effects on robot behavior.
- Proxy actions (latent actions) validity and robustness:
- Provide quantitative validation that latent actions capture semantically meaningful control signals across embodiments beyond qualitative retrievals (e.g., alignment metrics against ground-truth proxies when available, causal intervention tests).
- Evaluate robustness under egocentric challenges (occlusions, rapid camera motion, motion blur) and across interaction types (hands, arms, locomotion) with failure case analysis.
- Ablate latent-action embedding dimensionality, β in the VAE objective, and encoder/decoder capacity; report trade-offs between representation capacity, transferability, and controllability.
- Compare latent actions against alternative pseudo-labeling methods (e.g., 3D human pose, optical flow, scene flow, self-supervised action tokens) across tasks.
- Embodiment gap and adaptation:
- Systematically quantify when human-to-robot transfer fails due to embodiment constraints (reachability, kinematics, compliance), and propose filtering or weighting strategies for human data to mitigate harmful transfer.
- Extend post-training beyond GR-1 and report adaptation performance and data requirements for multiple embodiments (e.g., G1, AgiBot, YAM) with standardized metrics.
- Action controllability metrics:
- Move beyond PSNR/SSIM/LPIPS and human preference to task-relevant controllability metrics (e.g., joint tracking error, end-effector pose error, contact timing error, object pose trajectory error, success rate on manipulation subtasks).
- Design counterfactual responsiveness tests with controlled action perturbations and quantify sensitivity/causality.
- Real-world closed-loop evaluation:
- Present end-to-end results for live teleoperation and model-based planning (task success rates, latency, stability under delays, operator workload), and compare against established baselines (IRASim, UniSim, Ctrl-World, WMPE, etc.).
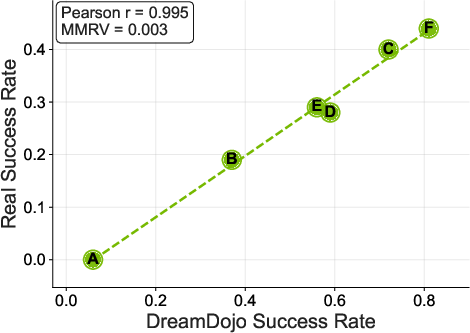
- Evaluate whether policy evaluation in the world model correlates with real-world outcomes (calibration curves, rank correlation across policies).
- Distillation and real-time constraints:
- Report latency, throughput, and memory footprint on typical robot compute hardware (onboard or edge devices) and assess whether 10.81 FPS at 640×480 is sufficient for fast manipulation or locomotion.
- Provide quantitative long-horizon degradation analysis (temporal drift, object permanence loss, compounding error rates) and benchmark student vs. teacher over >1 minute across varied tasks.
- Ablate window size, few-step schedules, and causal attention design choices; explore alternative distillation (consistency models, MCVD, single-step diffusion) for speed-quality trade-offs.
- Architectural and training design ablations:
- Chunked action injection: study different chunk lengths, alternative injection mechanisms (cross-attention, FiLM, gated MLP), and generalization across tokenizers with different temporal compression ratios.
- Relative vs. absolute actions: evaluate tasks that require absolute positioning/goals and propose hybrid conditioning schemes to avoid drift while retaining generalization.
- Temporal consistency loss: provide theoretical justification and broader empirical assessment (e.g., impact on dynamics fidelity and avoidance of over-smoothing), including λ sensitivity and stability analysis.
- Multimodal sensing and 3D grounding:
- Integrate depth, force/torque, tactile, audio, and proprioception to improve contact-rich dynamics modeling; quantify gains over RGB-only.
- Explore explicit 3D scene/state representations (object-level dynamics, contact graphs) and compare against pixel-space generation for planning utility.
- Generalization stress testing:
- Test in harder OOD settings: transparent/reflective surfaces, deformables, fluids, cluttered scenes, extreme lighting, moving backgrounds, varying camera intrinsics/extrinsics.
- Increase sample sizes beyond 25 clips per novel set and avoid reliance on image-editing models (Gemini) that may introduce artifacts; collect real OOD scenes.
- Language and goal conditioning:
- The model ignores available text annotations; evaluate instruction-conditioned world prediction and goal-conditioned control (language-driven tasks, compositionality).
- Study whether language improves counterfactual controllability and planning with high-level objectives.
- Tokenizer and foundation-model dependencies:
- Assess reliance on WAN2.2 tokenizer and Cosmos-Predict2.5 (closed or evolving ecosystems); compare with open tokenizers and alternative video generators to ensure reproducibility and portability.
- Quantify performance sensitivity to tokenizer temporal compression and latent resolution.
- Planning with world models:
- Specify the planning algorithm(s), horizons, and compute budgets; benchmark DreamDojo’s model-based planning against classical and learning-based planners on standardized tasks.
- Evaluate uncertainty calibration (aleatoric/epistemic), multimodal futures, and how stochastic rollouts affect planning reliability and safety.
- Safety and failure analysis:
- Characterize failure modes (hallucinations, object permanence violations, contact causality breaks) and their frequencies; propose detection/mitigation (guardrails, uncertainty thresholds, fallback policies).
- Provide risk assessments for teleoperation and autonomous use (collision, pinching, unsafe contact forces) and outline safety protocols.
- Data curation and benchmark hygiene:
- Document deduplication across data sources, potential train–test leakage, and annotation noise; provide tools and statistics to ensure OOD integrity.
- Release standardized OOD and counterfactual benchmarks with ground-truth controls and evaluation scripts to enable fair comparisons.
- Sample efficiency and compute:
- Quantify pretraining and post-training sample efficiency versus baselines; provide scaling laws with data diversity and model size.
- Explore lightweight variants (parameter-efficient finetuning, adapters, LoRA) for labs without 256 H100 GPUs and measure performance trade-offs.
- Locomotion and whole-body actions:
- Demonstrate that latent actions cover loco-manipulation beyond hands; provide benchmarks and quantitative results for legged locomotion, balance, and full-body coordination.
- Mapping to diverse action spaces:
- Detail how the action MLP handles varied action formats (continuous joints, hybrid discrete-continuous, non-holonomic bases) and constraints (joint limits, velocities); evaluate generality and safety-aware mapping.
- Uncertainty and multi-modality:
- Measure the diversity of generated futures and calibrate uncertainty estimates; investigate whether the model captures multimodal outcomes under ambiguous actions or scenes.
- Comparative baselines:
- Include head-to-head comparisons against recent robot world models (IRASim, UniSim, WorldGym, Ctrl-World, UWM, EnerVerse-AC) on shared benchmarks to position DreamDojo’s gains more clearly.
- Reproducibility:
- Provide training recipes, code, pretrained weights (teacher and distilled student), and evaluation harnesses to enable community replication and extension.
Practical Applications
Practical Applications of DreamDojo’s Findings and Methods
Below are actionable applications derived from the paper’s core contributions: large-scale egocentric human video pretraining (44k hours, 6,015+ skills, 43k+ objects), continuous latent actions as unified proxy actions, architecture/training innovations (relative actions, chunked action injection, temporal consistency), and a distillation pipeline enabling real-time, autoregressive prediction (10.81 FPS at 640×480, stable for >1 minute).
Immediate Applications
The following can be piloted or deployed now with modest engineering integration, small-scale post-training on target robots, and standard robotics stacks.
- Live teleoperation with predictive “ghosting” to reduce latency and error
- Sector: Robotics (humanoids, mobile manipulators), Industrial tele-ops, Field robotics
- Workflow/Product: Operator UI overlaying DreamDojo’s predicted futures (0.5–1.0 s horizon) on live camera feed to anticipate contacts and occlusions; “what-if” joystick nudges to preview outcomes before committing
- Assumptions/Dependencies: Stable camera pose and calibration; small post-training on the target robot; GPU for real-time inference; safety guardrails/human-in-the-loop
- Offline policy evaluation and counterfactual testing at scale
- Sector: Robotics R&D, QA/DevOps for autonomy
- Workflow/Product: “Policy Auditor” service that replays logs and runs counterfactual actions in DreamDojo (e.g., slight wrist rotations, missed grasps) to surface failure modes without redeploying hardware
- Assumptions/Dependencies: Access to action logs/telemetry; alignment between sim camera(s) and robot sensors; metric thresholds (LPIPS/SSIM) calibrated to task success
- Model-based planning (MPC) with a learned world model
- Sector: Manipulation, Warehouse/Logistics, Service robots
- Workflow/Product: “DojoPlan” harness that rolls out candidate action sequences in DreamDojo to score and select low-risk, high-reward trajectories; plug-in for ROS 2 planners
- Assumptions/Dependencies: Low-latency inference (distilled model); task-specific reward or success proxies; short horizon receding-window control
- Rapid embodiment adaptation with small post-training sets
- Sector: Humanoids (e.g., Fourier GR-1, Unitree G1), Cobots, Research platforms
- Workflow/Product: “Embodiment Bridge” that remaps action spaces using DreamDojo’s action MLP reinitialization + finetuning on limited in-domain data
- Assumptions/Dependencies: 1–2 orders of magnitude less data than typical teleop datasets; consistent viewpoints; clean action logging
- Cross-embodiment action retrieval and motion libraries via latent actions
- Sector: Software, Animation/Sim, Robotics
- Workflow/Product: “Action Mapper” that indexes clips by latent actions (32-D vectors) to retrieve analogous motions across humans/robots (e.g., wiping, twisting, patting)
- Assumptions/Dependencies: Latent action model trained across target domains; labeling for downstream motion taxonomy (optional)
- Dataset augmentation with diverse counterfactuals and “hard negatives”
- Sector: Autonomy training pipelines
- Workflow/Product: “Data Blender”—generate rare edge cases (near misses, slips, occlusions) for robustness training and curriculum design; simulate background shifts (EgoDex-novel, HV-novel style)
- Assumptions/Dependencies: Proven correlation between synthetic difficulty and downstream robustness; filtering to avoid compounding model biases
- Scenario generation and QA benchmarks for OOD generalization
- Sector: Simulation vendors, Research labs
- Workflow/Product: Benchmark suites mirroring paper’s OOD sets (In-lab/EgoDex/HV/Counterfactual); physics and action-following preference tests to track regressions
- Assumptions/Dependencies: Human preference evaluations in-the-loop; standard scoring protocols; shared assets
- Operator training and skills rehearsal
- Sector: Workforce training, Education
- Workflow/Product: Interactive “dry runs” with real logs and DreamDojo counterfactuals to practice resolving occlusions, misalignments, or unexpected contacts
- Assumptions/Dependencies: Training curricula; instrumented replay pipelines; latency constraints relaxed (offline)
- Predictive safety assistance (advisory)
- Sector: Manufacturing, Field service
- Workflow/Product: Advisory alerts when predicted futures show contact anomalies (tool collisions, object slips); operator-reviewed prompts only (non-blocking)
- Assumptions/Dependencies: Not safety-certified; advisory use with human-in-the-loop; calibrated false-positive/negative rates
- Academic research accelerators for world models and embodiment transfer
- Sector: Academia
- Workflow/Product: Reproducible codepaths for ablations (relative vs. absolute actions; chunked injection; temporal consistency loss), scaling laws across diverse data mixtures, and cross-embodiment transfer studies via latent actions
- Assumptions/Dependencies: Access to curated subsets; compute for pre/post-training; shared evaluation sets
- Video-first task analysis and HRI prototyping
- Sector: HRI, UX for robotics
- Workflow/Product: “Predictive storyboard” for co-design—preview human-robot interactions, test camera placements, and refine UI affordances using predictive rollouts
- Assumptions/Dependencies: Realistic camera viewpoints; qualitative evaluation with domain experts
- Distillation know-how for real-time video world models
- Sector: Generative AI, Simulation
- Workflow/Product: Port “Self Forcing”-style two-stage distillation to other video models to achieve 4-step inference and causal attention with long-horizon stability
- Assumptions/Dependencies: Access to teacher checkpoints; engineered schedules; distribution-matching stability tuning
Long-Term Applications
These require further research, scaling, regulatory processes, or productization beyond the current state (e.g., broader safety validation, edge efficiency, expanded sensor/action spaces).
- General-purpose household humanoids with robust OOD dexterity
- Sector: Consumer robotics
- Workflow/Product: Home assistant robots trained with internet-scale human videos and small in-home post-training, performing ADLs across varied scenes
- Assumptions/Dependencies: Safety guarantees; on-device inference or reliable low-latency edge/cloud; multimodal sensing; rigorous fail-safes
- Fleet-level continuous learning with model-based evaluation in the cloud
- Sector: Robotics platforms, Autonomy ops
- Workflow/Product: Cloud “DreamDojo Hub” that ingests fleet logs, runs nightly counterfactual rollouts, and recommends policy updates validated in silico
- Assumptions/Dependencies: Data governance and privacy compliance; scalable compute; automated regression testing; closed-loop MLOps
- Simulation-based certification and pre-deployment safety protocols
- Sector: Policy/Regulation
- Workflow/Product: Regulatory sandboxes using video world models to stress-test policies under rare-but-plausible scenarios before real-world trials
- Assumptions/Dependencies: Accepted validity of learned simulators; standardized OOD scenario catalogs; third-party audits; reporting standards
- Autonomous model-based planning in highly unstructured environments
- Sector: Industrial maintenance, Construction, Agriculture
- Workflow/Product: End-to-end planners that roll out long-horizon “what-if” futures to plan sequences involving contact-rich manipulation and locomotion
- Assumptions/Dependencies: Longer-horizon stability; task rewards; integration with tactile/force sensing; reliable object-state estimation
- AR predictive overlays for human–robot collaboration
- Sector: HRI, Manufacturing, Field service
- Workflow/Product: Wearable or tablet AR that shows robot’s predicted next-second motion and contact points, improving team fluency and trust
- Assumptions/Dependencies: Precise calibration; user acceptance; latency bounds; safety co-design
- Assistive healthcare robots performing ADLs with generalization
- Sector: Healthcare
- Workflow/Product: Robots assisting in dressing, feeding prep, and tidying with policy evaluation via counterfactuals to minimize risk
- Assumptions/Dependencies: Domain-specific datasets (HIPAA-compliant); ethical oversight; extremely conservative safety envelopes; clinician-in-the-loop
- Assembly and kitting planners with “what-if” validation
- Sector: Manufacturing/Automotive/Electronics
- Workflow/Product: Task planners that validate fixture designs and action sequences via predicted contact dynamics before line changes
- Assumptions/Dependencies: Accurate modeling of small-part interactions; CAD-to-video alignment; ground-truth metrology loops
- Cross-embodiment skill marketplaces powered by latent actions
- Sector: Platforms/Ecosystems
- Workflow/Product: Shareable skill descriptors (latent actions) enabling transfer of motions between different robots and tools, with automatic retargeting
- Assumptions/Dependencies: Open standards for action embeddings; IP/licensing frameworks; safety filters on transferred skills
- Video-to-policy learning with minimal action labels
- Sector: Learning from videos
- Workflow/Product: Pipelines that leverage latent proxy actions to bootstrap policies from human internet videos, then refine with limited teleop
- Assumptions/Dependencies: Robust alignment from latent actions to robot commands; reward shaping; domain adaptation
- Digital twin integration for facilities and cities
- Sector: Smart infrastructure, Logistics
- Workflow/Product: Video world models as behavioral layers in digital twins, enabling predictive maintenance and scenario planning for mobile manipulation fleets
- Assumptions/Dependencies: Live data connectors; governance; calibration drift management; large-scale compute
- On-device, energy-efficient world models
- Sector: Edge AI, Hardware
- Workflow/Product: Quantized/distilled variants running on robot compute (Jetson/Edge TPUs) for low-latency planning and safety-advisory inference
- Assumptions/Dependencies: Further model compression; hardware-aware distillation; thermal and power constraints
- Standards for dataset governance and ethical internet-scale pretraining
- Sector: Policy/Ethics
- Workflow/Product: Best-practice frameworks covering consent, privacy, bias auditing, and annotation for large egocentric video corpora used in robotics
- Assumptions/Dependencies: Multi-stakeholder consensus; legal harmonization across jurisdictions; transparent documentation (datasheets, model cards)
Notes on Feasibility and Dependencies
- Model capabilities today: Real-time, autoregressive prediction at ~10.81 FPS (640×480), stable >1 minute; strong zero-shot transfer after small post-training; robust to OOD objects/scenes relative to in-domain robot data.
- Key technical dependencies: Camera/viewpoint alignment; small but representative post-training datasets; action-space remapping (relative actions, chunked injection); GPUs for inference or further compression; ROS 2 integration for planners/teleop.
- Risks and assumptions: Learned simulators can drift over long horizons; physics fidelity varies by domain; advisory-only safety functions until certified; data governance/privacy for human videos; regulatory acceptance of simulation-based validation remains open.
These applications translate DreamDojo’s contributions—data scale and diversity, latent action proxying, controllability-centric architecture, and real-time distillation—into concrete tools and workflows that can accelerate robot development today while laying a path to more ambitious, general-purpose autonomy.
Glossary
- Adaptive layer normalization: A normalization layer that adapts its parameters based on conditioning signals (e.g., timestep), enabling dynamic modulation of activations. "and then used by adaptive layer normalization for dynamic modulations (scale, shift, gate)"
- Action controllability: The degree to which a model can follow and respond precisely to action inputs to produce intended outcomes. "strong understanding of physics and precise action controllability."
- Action chunking: Grouping consecutive action inputs into fixed-size segments aligned with latent video frames to respect causality and improve control. "we inject actions into the latent frames as chunks"
- Action-conditioned: Conditioning the model’s predictions on action inputs to capture causal effects of control. "leading to inferior knowledge transfer for action-conditioned world simulation."
- Autoregressive: A generation process where each new output depends on previously generated outputs in sequence. "can autoregressively predict future frames"
- Bidirectional attention: An attention mechanism that allows tokens (e.g., frames) to attend to both past and future positions, often used in non-causal transformers. "their bidirectional attention architecture, which defines a fixed horizon length"
- Causal attention: An attention mechanism that restricts each position to attend only to past (and current) positions, enabling online/streaming generation. "replaced with causal attention"
- Classifier-free guidance: A diffusion sampling technique that mixes conditioned and unconditioned predictions to control fidelity vs. diversity. "Classifier-free guidance~\citep{ho2022classifier} is disabled"
- Counterfactual actions: Action inputs that differ from those in the recorded ground-truth trajectory to test causal understanding and responsiveness. "counterfactual actions not present in current robot learning datasets"
- Cross-attention: An attention mechanism that injects external conditioning (e.g., text) into a model by attending from latent features to condition embeddings. "The text embedding is processed by cross-attention layers"
- DiT block: A Diffusion Transformer block used in diffusion models for video/image generation with transformer-based denoising. "each DiT block~\citep{peebles2022scalable}"
- Distillation: Transferring knowledge from a large/slow “teacher” model to a smaller/faster “student” model while maintaining performance. "We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS"
- Distribution matching loss: A loss that aligns the student’s generative distribution with the teacher’s, often via KL divergence. "via a distribution matching loss~\citep{yin2024one}~\nocite{yin2024improved}"
- Egocentric: First-person perspective video captured from the viewpoint of the actor performing the task. "egocentric human videos"
- Embodiment gap: The mismatch between human and robot bodies/sensors that complicates transfer of skills or data. "Despite the embodiment gap, the underlying physics during interactions is largely consistent between humans and robots"
- EMA (exponential moving average): A smoothed average of model parameters maintained during training to stabilize evaluation and sampling. "An exponential moving average (EMA) is maintained throughout the training and used to generate all our results."
- Flow matching loss: A training objective for diffusion/flow models that matches predicted velocities to ground-truth flows in noise space. "The whole network is trained using flow matching loss~\citep{lipman2022flow}."
- Foundation world model: A large, general-purpose world model pretrained on broad data to support many downstream tasks and embodiments. "a foundation world model for open-world dexterous robot tasks"
- Information bottleneck: A design that forces a model to compress inputs into a compact latent capturing only task-relevant information. "It has an information bottleneck design that can automatically disentangle the most critical action information"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another, used as a regularizer or distribution matching target. "based on the Kullback-Leibler (KL) divergence between real (teacher) and fake (student) distributions"
- Latent actions: Compact, continuous representations inferred from video that capture the underlying actions between frames. "we introduce continuous latent actions as unified proxy actions"
- Latent video diffusion model: A diffusion model that operates in a compressed latent space rather than pixel space for video prediction/generation. "a latent video diffusion model that predicts future frames"
- Loco-manipulation: Combined locomotion and manipulation skills in embodied agents/robots. "a wide spectrum of loco-manipulation skills"
- LPIPS: A learned perceptual image patch similarity metric used to evaluate visual similarity aligned with human perception. "LPIPS~\citep{zhang2018unreasonable}"
- MANO: A parametric hand model widely used to represent human hand pose and shape. "transformed into MANO~\citep{romero2022embodied} by ourselves as conditions during pretraining."
- Model-based planning: Using a learned model of the environment’s dynamics to plan sequences of actions before execution. "model-based planning"
- ODE solutions: Outputs of an ordinary differential equation-based sampler/solver used to define the teacher trajectory in distillation. "match ODE solutions generated by our teacher,"
- Out-of-distribution (OOD): Data or scenarios that differ from the training distribution, used to test generalization. "out-of-distribution (OOD) benchmarks"
- Policy evaluation: Assessing the performance of a control policy, often using a simulator or world model instead of the real robot. "policy evaluation"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-space metric measuring reconstruction fidelity. "PSNR~\citep{hore2010image}"
- Retargeted actions: Actions captured in one embodiment (e.g., human hands) mapped onto another (e.g., robot joints). "retargeted to the GR-1 robot actions"
- Self-supervised: Learning signals derived from the data itself without manual labels. "in a self-supervised manner"
- Sinusoidal embeddings: Positional/timestep encodings based on sinusoids used to inject ordering/time into transformer models. "timestep information is first encoded by sinusoidal embeddings"
- Spatiotemporal Transformer: A transformer architecture that models spatial and temporal dimensions jointly for video. "using the spatiotemporal Transformer architecture"
- SSIM: Structural Similarity Index, a perceptual metric for image/video quality considering luminance, contrast, and structure. "SSIM~\citep{hore2010image}"
- State transition function: A function describing how the environment’s state evolves given an action. "acts as a state transition function"
- Teacher forcing: A training strategy where the student model conditions on ground-truth or teacher-generated context rather than its own outputs. "the student generates via teacher forcing"
- Teleoperation: Controlling a robot remotely by a human, often to collect demonstrations. "previous methods that typically rely on teleoperation data"
- Temporal consistency loss: A loss that enforces consistency across time by matching predicted and true temporal differences. "the proposed temporal consistency loss can be expressed as:"
- WAN2.2 tokenizer: A learned video tokenizer that compresses frames into latents for efficient modeling/generation. "WAN2.2 tokenizer~\citep{team2025wan}"
- Variational Autoencoder (VAE): A generative model that learns a latent variable distribution with a reconstruction and KL regularization objective. "as a VAE~\citep{kingma2013auto}"
- Zero-shot generalization: Performing well on tasks or scenarios not seen during training, without additional finetuning. "shows zero-shot generalization to unseen objects and novel environments."
Collections
Sign up for free to add this paper to one or more collections.