Genie Sim 3.0 : A High-Fidelity Comprehensive Simulation Platform for Humanoid Robot
Abstract: The development of robust and generalizable robot learning models is critically contingent upon the availability of large-scale, diverse training data and reliable evaluation benchmarks. Collecting data in the physical world poses prohibitive costs and scalability challenges, and prevailing simulation benchmarks frequently suffer from fragmentation, narrow scope, or insufficient fidelity to enable effective sim-to-real transfer. To address these challenges, we introduce Genie Sim 3.0, a unified simulation platform for robotic manipulation. We present Genie Sim Generator, a LLM-powered tool that constructs high-fidelity scenes from natural language instructions. Its principal strength resides in rapid and multi-dimensional generalization, facilitating the synthesis of diverse environments to support scalable data collection and robust policy evaluation. We introduce the first benchmark that pioneers the application of LLM for automated evaluation. It leverages LLM to mass-generate evaluation scenarios and employs Vision-LLM (VLM) to establish an automated assessment pipeline. We also release an open-source dataset comprising more than 10,000 hours of synthetic data across over 200 tasks. Through systematic experimentation, we validate the robust zero-shot sim-to-real transfer capability of our open-source dataset, demonstrating that synthetic data can server as an effective substitute for real-world data under controlled conditions for scalable policy training. For code and dataset details, please refer to: https://github.com/AgibotTech/genie_sim.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Genie Sim 3.0, a “practice world” for robots. Think of it like a very realistic video game where robots can learn to see, understand instructions in plain English, and use their hands to do tasks—without risking real damage or taking lots of time in the real world. The platform builds detailed virtual scenes, collects huge amounts of training data, and automatically tests how well robot models perform. The big idea: make robot learning faster, cheaper, and more reliable, and make its results transfer well to the real world.
What were the main goals?
The authors wanted to solve three everyday problems in robot learning:
- It’s expensive and slow to gather enough real-world data for training.
- Existing simulators are either too narrow (few scenes/tasks) or not realistic enough, so skills don’t transfer well to real life.
- Testing is often manual and small-scale, so it’s hard to know if a robot is truly good and whether it will work outside the lab.
In simple terms: Can we build a single platform that quickly creates many realistic practice scenes, gathers lots of training data, and fairly tests robot skills—so the results predict what happens in the real world?
How does Genie Sim 3.0 work?
To keep this simple, imagine five building blocks working together.
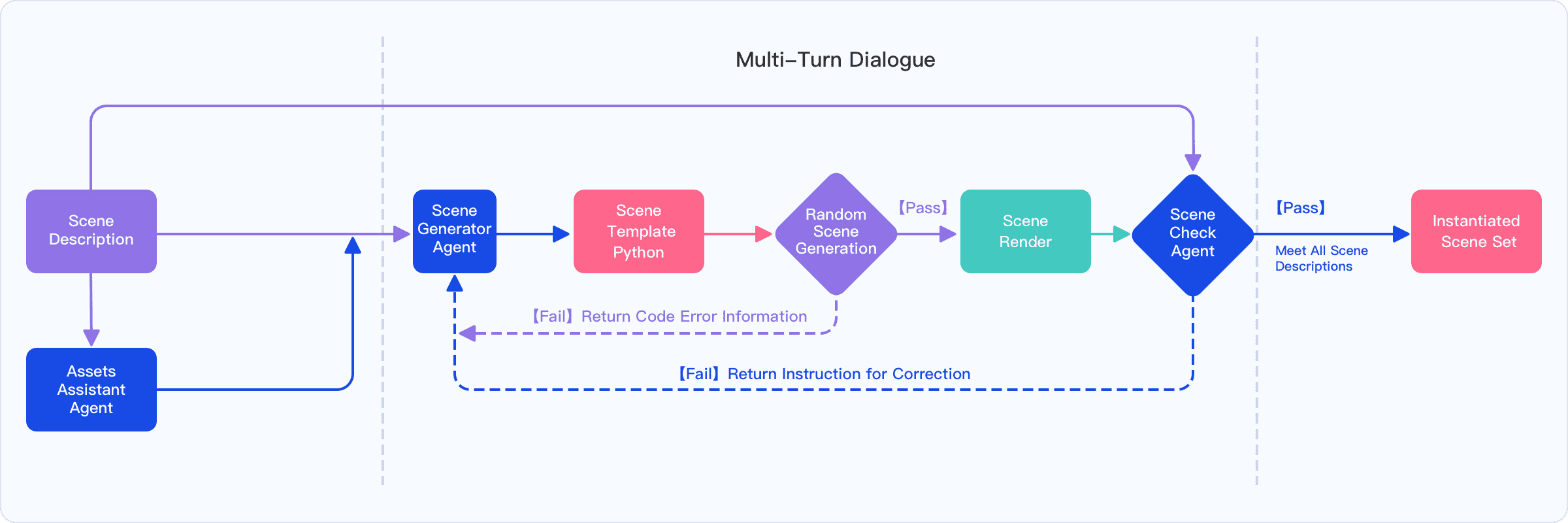
1) Building virtual worlds from plain English
You type a request like “Set up a messy desk with books, a cup, and a phone, then ask the robot to tidy it.” A LLM—a smart AI that understands text—turns your words into a detailed plan. It then:
- Finds the right 3D objects from a library of 5,140 ready-to-use items (like a giant, searchable closet).
- Writes the “instructions” (code) that place these objects in the scene with exact positions and rules (like “the phone is on the desk, next to the book”).
- Randomizes things like lighting, object colors, and layout—similar to shuffling a deck—to create many variations. This helps the robot learn to handle surprises.
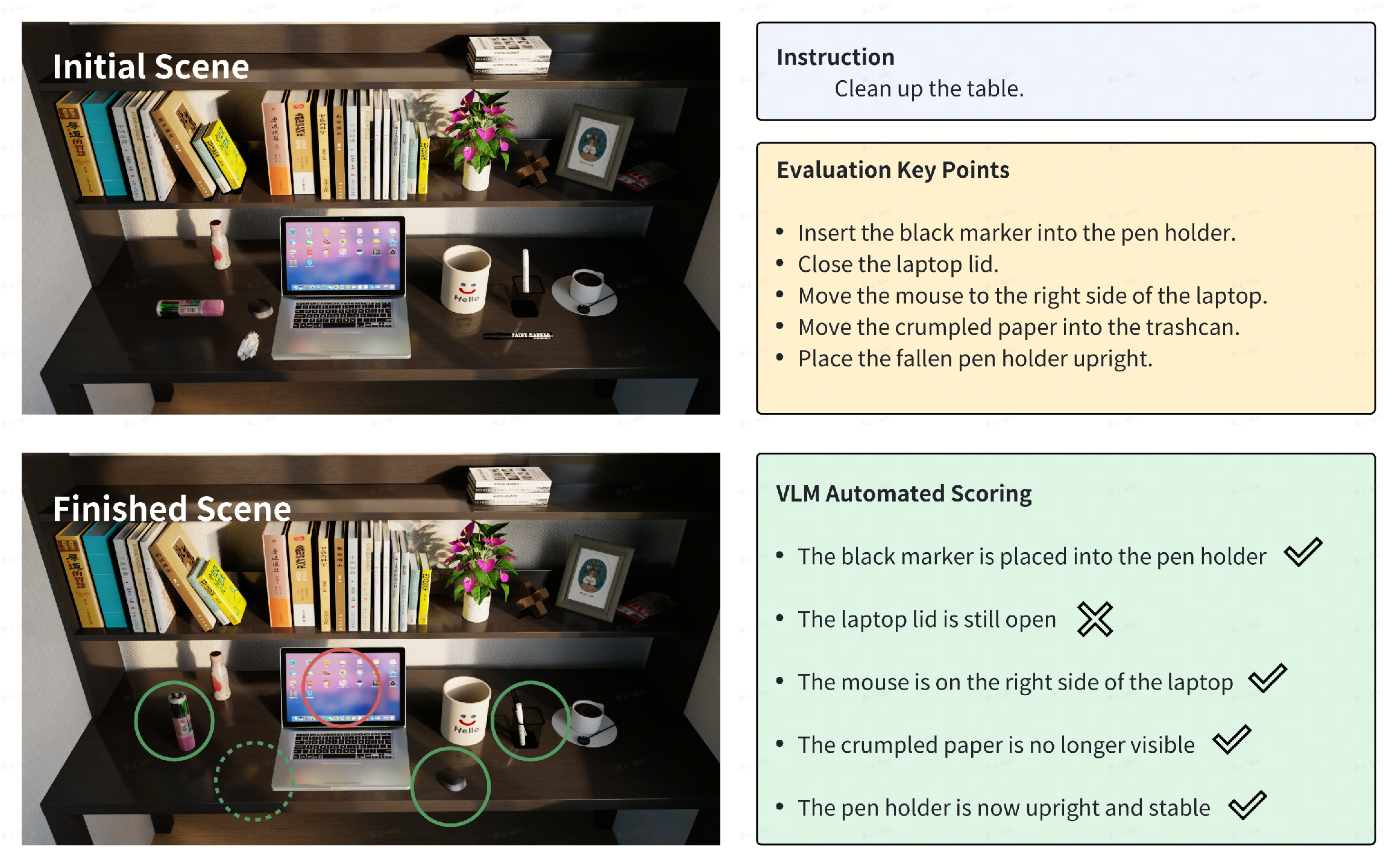
2) Creating tests automatically
The platform uses an LLM to mass-produce task instructions and evaluation rules. Then a vision-LLM (VLM)—an AI that “looks” at images and “reads” the task—watches what the robot did and scores the result automatically. It’s like an AI referee that checks, “Did the robot really put the red cup on the top shelf?”
3) Making virtual worlds look and feel real
The team scans real rooms with a special camera (laser + photos), then uses advanced 3D tech to rebuild those spaces inside the simulator. You can think of it as turning lots of photos into a crisp 3D model you can walk around in. They also fix camera errors and even use AI to fill in missing viewpoints so the final virtual room looks photorealistic and behaves realistically.
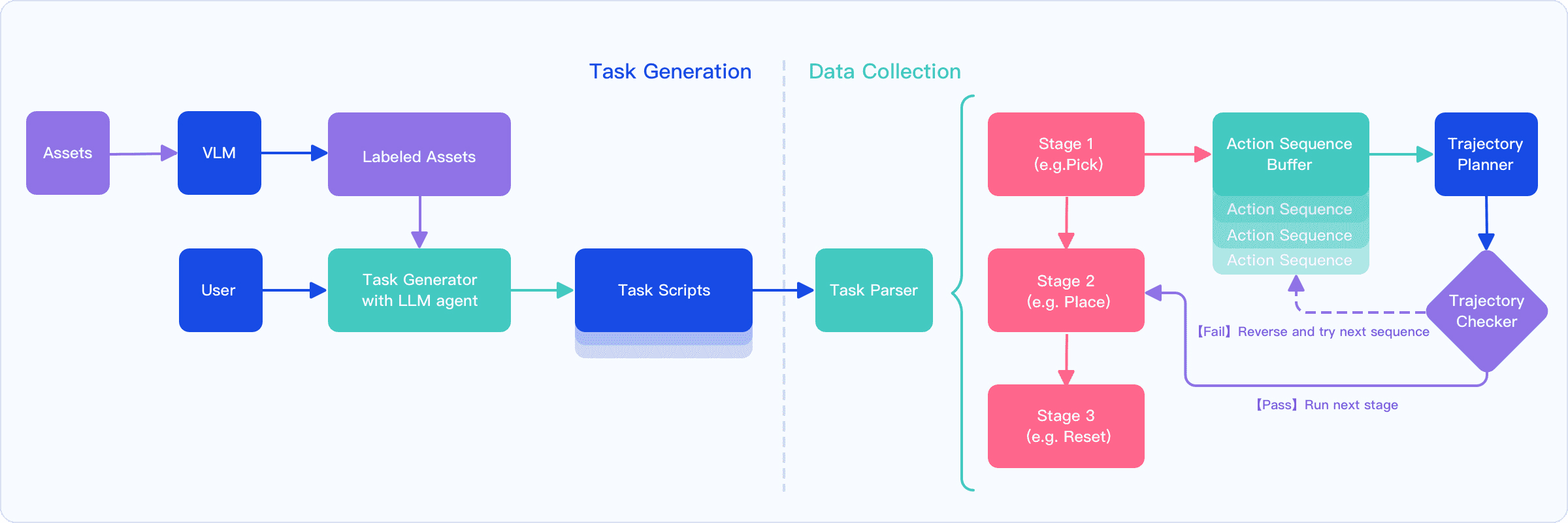
4) Collecting training data two ways
- Teleoperation: A person wears a VR headset and controls the robot in simulation to demonstrate complex tasks (like teaching by example).
- Automation: A fast motion planner finds safe arm motions on its own, tries different step-by-step plans, and retries if something fails. This gathers large amounts of useful training data quickly.
5) Testing robots in a “closed loop”
During testing, the simulator sends camera images to the robot’s brain (the model), gets back the robot’s actions, and immediately applies them—just like a real robot operating in real time. The system supports many popular robot models and different robot hands.
What did they find?
Here are the main takeaways, written plainly:
- More data usually makes robots better. Models trained with more episodes (practice runs) performed better across tasks.
- Synthetic data can be powerful. A model trained only with 1,500 synthetic episodes did best in real-world tests across four tasks (choosing by color, recognizing size, grasping targets, organizing objects). Put simply: if synthetic data is big and varied enough, it can compete with or even beat smaller real-world datasets.
- Real data is still “sharper” per episode. With the same amount of data (e.g., 500 episodes), real-world data usually beats synthetic data because it captures tricky physics (like friction and collisions) that are hard to simulate perfectly.
- Simulation scores predict real-world performance. Results in the simulator strongly matched results in real-life tests (very high correlation). That means if a model does better in Genie Sim 3.0, it’s very likely to do better in the real world too.
Numbers that show the scale:
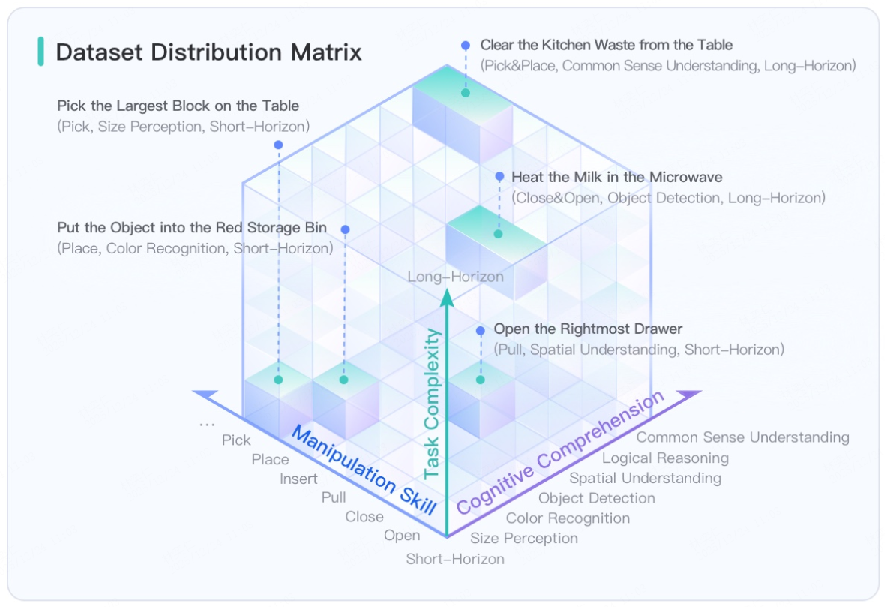
- 5,140 simulation-ready object assets across 353 categories
- Over 10,000 hours of synthetic training data covering 200 tasks
- 100,000+ evaluation scenarios for testing
- Strong sim-to-real agreement (the trends match very closely)
Why does this matter?
This platform makes it much easier to build and test robot skills:
- Faster progress: You can generate new scenes and tasks from plain English, gather tons of data automatically, and run huge tests without human graders.
- Lower cost and safer: Robots can practice thousands of times in simulation instead of wearing out real hardware or breaking things.
- More reliable: Because simulation performance predicts real-world results, researchers can trust the simulator to guide improvements.
- Community boost: The authors open-source assets, datasets, and code. That helps students, startups, and labs build better robots more quickly.
In short, Genie Sim 3.0 is like a complete training ground, exam hall, and replay system for robots—all in one. It brings us closer to robots that can understand instructions and handle messy, real-life situations with confidence.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers can address:
- Quantify the accuracy and reliability of the VLM-based auto-scoring pipeline against human annotations across diverse tasks, scene complexities, occlusions, and lighting conditions; report confusion matrices and failure modes.
- Provide a formal specification and empirical validation of the Action Domain Evaluation Rule (ADER) system: coverage of task types, correctness guarantees, ambiguity handling, and sensitivity to instruction paraphrases.
- Measure robustness of LLM-generated instructions and DSL scene code to adversarial, underspecified, or contradictory prompts; characterize error rates, recovery strategies, and the frequency/impact of manual corrections.
- Detail domain-randomization parameter ranges and probability distributions (lighting, textures, physics, sensor noise, robot morphology) and run ablations to identify which dimensions most influence sim-to-real transfer.
- Calibrate and validate physics fidelity (contact dynamics, friction, restitution, damping) against real measurements; report quantitative sim-to-real discrepancies per task and object class, and propose auto-calibration methods.
- Evaluate the impact of 3DGS view-extrapolation using generative models on downstream perception/manipulation: metrics for photorealism (e.g., PSNR/SSIM), geometric accuracy, and artifact-induced control errors.
- Provide quantitative improvements from the camera pose optimization pipeline (e.g., reprojection error reductions, BA convergence statistics) and ablate feature extractors (SuperPoint/LightGLue vs baselines).
- Assess the physical suitability of reconstructed meshes (PGSR outputs) for contact simulation: mesh watertightness, surface smoothness, thickness, collision stability, and their effects on manipulation success.
- Report hardware/software resource requirements and performance profiles for scene generation, environment reconstruction, data collection, and automated evaluation (e.g., GPU-hours, memory footprints, throughput).
- Analyze dataset composition and balance: distribution across the 353 categories and 5,140 assets, long-tail coverage, object attribute diversity (size, material, color), and potential biases that affect generalization.
- Clarify licensing and provenance of released assets and synthetic data; specify usage restrictions and compliance with third-party model/data licenses (LLMs, VLMs, embeddings).
- Extend experiments beyond the four reported tasks to include contact-rich, deformable, fluid, and long-horizon tasks; provide systematic task taxonomies and standardized splits for robust benchmarking.
- Strengthen statistical reporting of experimental results: include confidence intervals, standard errors, trial variance, power analyses, and sensitivity to random seeds for both sim and real evaluations.
- Control for data quantity confounds when comparing sim vs real training: equalize episodes and explore data-efficiency curves to locate break-even points and quantify “sim scaling advantage.”
- Investigate generalization across robot embodiments beyond Agibot G1/G2: kinematic/actuation differences, gripper/end-effector variability, and porting costs to common platforms (Franka, UR, mobile manipulators, true humanoids).
- Characterize sensor modeling fidelity: camera intrinsics/extrinsics, latency, rolling shutter, motion blur, depth noise, proprioceptive and actuator noise; show their contributions to transfer performance.
- Evaluate closed-loop evaluation stability under network latency and packet drops in the HTTP-based inference setup; quantify effects on control and outcomes, and define reproducibility protocols.
- Analyze differences between teleoperated and automated demonstrations: trajectory smoothness, subgoal selection, error correction behaviors, and how these affect learned policy robustness and sample efficiency.
- Report the reliability of waypoint selection and grasp annotations (e.g., from GraspNet) in cluttered and novel-object settings; quantify planning failures attributable to annotation errors or mesh simplification.
- Provide a formal description, versioning, and validation suite for the DSL and asset APIs to ensure reproducibility across LLM versions and simulator updates; include determinism controls and seed management.
- Examine instruction-language coverage (multi-lingual support beyond English), embedding/model biases (QWEN text-embedding v4), and retrieval performance for non-English queries or domain-specific vocabularies.
- Compare the proposed benchmark’s scoring and task coverage against existing benchmarks (Meta-World, BEHAVIOR-1K, ManiSkill/ManipulaTHOR), including cross-benchmark transfer and calibration.
- Quantify the degree to which VLM-based evaluation can be “gamed” by models (e.g., by producing visual states that mislead scorers); propose countermeasures (multi-view checks, temporal consistency tests, physical verifiers).
- Explore safety-critical evaluation: simulating hazards, near-collisions, and compliance behaviors, and defining metrics for safe execution and recovery in both sim and real.
- Clarify alignment between the “humanoid” focus in the title and the manipulation-centric experiments; evaluate whole-body control, locomotion-manipulation coupling, and humanoid-specific tasks within Genie Sim 3.0.
- Provide guidelines and tools for automatic physics parameter identification from real trials (system identification) to reduce sim-to-real gaps without manual tuning.
- Investigate scalability of the LLM/VLM-based evaluation generation to long-horizon, compositional tasks with hierarchical dependencies; measure instruction diversity, redundancy, and semantic drift at scale.
Glossary
- 3D Gaussian Splatting (3DGS): A neural rendering technique that represents scenes with 3D Gaussian primitives for photorealistic reconstruction and rendering. "3D Gaussian Splatting (3DGS) imposes relatively stringent requirements on camera pose accuracy"
- Action Domain Evaluation Rule (ADER): A rule-based system that formalizes actions and evaluation criteria to auto-generate task instructions and configs for benchmarking. "Genie Sim Benchmark leverages the capabilities of the LLM by combining it with Action Domain Evaluation Rule (ADER) system"
- anthropomorphic feasibility: The degree to which planned robot motions resemble or are feasible for human-like manipulation. "evaluated based on kinematic reachability, collision avoidance, and anthropomorphic feasibility."
- Bundle Adjustment (BA) optimization: A nonlinear optimization technique that refines camera poses and 3D points jointly using reprojection errors. "implement BA optimization together."
- chain-of-thought (CoT): An LLM prompting method that elicits intermediate reasoning steps to improve structured task interpretation. "A chain-of-thought (CoT)–enabled LLM first parses and decomposes the natural language prompt"
- ChromaDB: An open-source vector database used to store and retrieve high-dimensional embeddings efficiently. "stored in a ChromaDB vector database."
- COLMAP-PCD: A COLMAP variant or pipeline integrating point cloud data for camera pose and structure estimation. "After obtaining the camera pose and 3D point data output using COLMAP-PCD, we train 3DGS"
- cuRobo: A GPU-accelerated motion planning library for fast trajectory generation in robotics. "Leveraging cuRobo~\cite{sundaralingam2023curobo}âa GPU-accelerated motion plannerâas the core trajectory planning module"
- Domain Randomization: Systematic variation of visual and physical parameters in simulation to improve policy generalization to real-world. "equipped with comprehensive domain randomization capabilities;"
- Domain Specific Language (DSL): A specialized programming language tailored to express and generate structured simulation scenes. "domain specific language (DSL) code generation"
- end-effector: The tool or gripper at the end of a robot arm that interacts with objects. "target end-effector pose"
- GraspNet: A dataset/tool providing annotated grasping poses and labels to support robotic grasp planning. "grasping poses labeled by GraspNet~\cite{DBLP:journals/corr/abs-1912-13470}"
- gsplat: An open-source implementation/framework for training 3D Gaussian Splatting models. "open-source gsplat \cite{ye2025gsplat}framework."
- human-in-the-loop evaluation: An assessment process requiring human oversight or annotation, often limited by scalability and subjectivity. "human-in-the-loop evaluation is inefficient, subjective, and non-scalable"
- Isaac Sim: NVIDIA’s robotics simulation platform used for high-fidelity physics and rendering. "assets for Isaac Sim."
- kinematic reachability: Whether a robot can achieve a pose or waypoint given its joint limits and kinematic constraints. "evaluated based on kinematic reachability, collision avoidance, and anthropomorphic feasibility."
- LiDAR SLAM: Simultaneous Localization and Mapping using LiDAR sensors to estimate trajectories and reconstruct environments. "using the prior poses of the camera obtained by LiDAR SLAM"
- LightGLue: A learned feature matcher for robust image correspondence, used in pose optimization pipelines. "and LightGLue \cite{lindenberger2023lightglue} to replace the DSP-SIFT"
- OpenUSD: The open standard for Universal Scene Description, enabling interoperable scene composition and simulation assets. "OpenUSD Schema"
- PICO VR Head-Mounted Display (PICO): A VR device used for teleoperating robots by streaming human motions into simulation. "a PICO VR Head-Mounted Display (PICO) device"
- PGSR: A method for point-guided surface reconstruction to obtain high-precision meshes from point clouds and images. "We use PGSR \cite{chen2024pgsr} for surface reconstruction"
- Proprioceptive states: Internal robot sensor readings (e.g., joint positions/velocities) used to inform control. "the simulator transmits the robot’s observation images and proprioceptive states"
- QWEN: text-embedding-v4: A text embedding model used to encode semantic descriptions into vector representations for retrieval. "encoded into 2048-dimensional vectors via the QWEN: text-embedding-v4 model"
- Retrieval-Augmented Generation (RAG): An approach where generation is guided by retrieved context to improve accuracy and grounding. "retrieval-augmented generation (RAG) agents"
- Scene Graph: A structured representation of a scene with nodes (objects) and edges (spatial relations) for simulation and evaluation. "produces Scene Graph for downstream task evaluations."
- SuperPoint: A learned interest point detector and descriptor used to extract robust image features. "we first utilize SuperPoint \cite{detone2018superpoint} and LightGLue"
- Universal Scene Description (USD): A format and framework for describing, composing, and exchanging 3D scenes and assets. "Universal Scene Description (USD) paths"
- Vision-Language Action (VLA) models: Models that map visual and language inputs to actionable robot commands. "vision-language-action (VLA) models"
- Vision-LLM (VLM): Models that jointly process visual and textual inputs for understanding and evaluation. "employs Vision-LLM (VLM) to establish an automated assessment pipeline."
- Zero-shot sim-to-real transfer: Deploying models trained in simulation directly to the real world without additional real-world fine-tuning. "zero-shot sim-to-real transfer capability"
- mesh simplification: Reducing geometric complexity of mesh models to speed up planning while preserving essential shape. "mesh simplification is applied to object geometries during scene initialization"
- state rollback: Reverting the simulator to a previous state to retry an alternative action sequence after failure. "a state rollback is performed before the next candidate sequence is attempted."
- teleoperation: Controlling a robot remotely by human operators, often via VR or other interfaces. "Teleoperation: Our teleoperation framework utilizes a PICO VR Head-Mounted Display (PICO) device"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s capabilities of Genie Sim 3.0. Each item specifies sectors, the core workflow/tooling, and key assumptions or dependencies.
- Rapid scenario generation and variation for robot R&D — Robotics, Software/AI
- What: Convert natural-language descriptions into high-fidelity, parameterized scenes for debugging, ablations, and coverage testing (lighting, textures, object layouts, sensor noise).
- Tools/workflows: Genie Sim Generator (LLM + RAG asset index with 5,140 USD assets), Isaac Sim/OpenUSD scene graphs, domain randomization presets.
- Assumptions/dependencies: Access to LLM/VLM stack, NVIDIA Isaac Sim-compatible GPUs, asset licensing, operator familiarity with scene DSL.
- Synthetic data augmentation for VLA model training — Robotics, Software/AI, Education
- What: Use the open-source 10,000+ hours dataset (200 tasks) and/or auto-generated data to scale model training and reduce reliance on costly real-robot data.
- Tools/workflows: Dual-mode data factory (teleoperation via VR + automated cuRobo pipeline), instruction synthesis (LLM), waypoint filtering/retry.
- Assumptions/dependencies: Sim-to-real gap mitigated by domain randomization; alignment between training tasks and target deployment; sufficient compute.
- Robotics CI/CE (continuous integration/continuous evaluation) — Software/AI Tooling, Robotics
- What: Add regression testing and performance dashboards using 100,000+ evaluation scenarios and VLM auto-scoring to catch model regressions before deployment.
- Tools/workflows: HTTP-based closed-loop evaluation with any VLA model, VLM-derived success judgments, batch simulation farms.
- Assumptions/dependencies: Stable VLM accuracy on task-specific success criteria; reproducible simulator seeds; storage/compute for large-scale runs.
- Vendor-neutral benchmarking and model selection — Industry (Manufacturing, Logistics, Domestic Robotics), Academia
- What: Compare candidate VLA/policy stacks across standardized capabilities (semantic understanding, spatial reasoning, execution).
- Tools/workflows: Genie Sim benchmark suite, capability heatmaps, scenario coverage analytics.
- Assumptions/dependencies: Adapters for different embodiments/end-effectors; acceptance that reported simulation scores correlate with real (paper shows R2 ≈ 0.924).
- Virtual commissioning and feasibility studies — Manufacturing, Logistics, Service Robotics
- What: Validate task feasibility, reachability, and cycle times before purchasing hardware or rearranging facilities.
- Tools/workflows: Scene reconstruction/import, cuRobo planning in clutter, mesh simplification for planning performance.
- Assumptions/dependencies: Adequate modeling of contacts/friction; accurate CAD or reconstructed digital twin; facility-specific constraints modeled.
- Digital twin creation of indoor spaces — Smart Buildings, Retail, Warehousing, Facilities
- What: Build photorealistic, physically interactive digital twins from scans for planning, training, and remote operations.
- Tools/workflows: 3DGS pipeline (MetaCam LiDAR + COLMAP-PCD with SuperPoint/LightGlue + gsplat + PGSR), generative view synthesis (Difix3D+) to fill sparse views.
- Assumptions/dependencies: Scanning permissions; sufficient view coverage/pose accuracy; compute budget for reconstruction; quality of generative extrapolated views.
- Teleoperation-driven demonstrations for complex skills — Robotics, Education
- What: Collect human-like trajectories for long-horizon or dexterous tasks via VR.
- Tools/workflows: PICO HMD teleop interface, motion controller, Isaac Sim logging (observations, joint states, object poses).
- Assumptions/dependencies: HMD availability, operator training, low-latency links, ergonomic safety.
- Automated skill library generation — Robotics
- What: Use automated planning and annotated grasp poses to mass-generate pick/place/push/open/close trajectories across assets and scenes.
- Tools/workflows: cuRobo planning, GraspNet-based grasp annotations, multi-candidate waypoint evaluation and rollback mechanism.
- Assumptions/dependencies: Quality of grasp annotations; collision models; compute for planning at scale.
- Language dataset expansion and task variation — Software/AI (NLP + Embodied AI)
- What: Scale instruction-following corpora via LLM-generated task decompositions, paraphrases, and evaluation rules.
- Tools/workflows: ADER (Action Domain Evaluation Rule) + LLM prompt expansion, scenario parameterization.
- Assumptions/dependencies: Human review to de-bias/filter instructions; guardrails for instruction validity.
- Automated visual QA of task completion — Robotics Operations, Quality Assurance
- What: Replace or reduce human-in-the-loop judging of trials with VLM-based pass/fail and evidence generation on execution videos.
- Tools/workflows: VLM auto-scoring pipeline integrated with simulator and potentially with real cameras.
- Assumptions/dependencies: Adequate camera views; VLM robustness to lighting/clutter; calibration between real and simulated visual distributions.
- Teaching and lab-in-a-box for robotics courses — Education
- What: Provide hands-on, reproducible assignments and exams without physical hardware; support at-scale MOOCs.
- Tools/workflows: Open-source assets, scenarios, HTTP inference adapters, cloud-hosted simulation.
- Assumptions/dependencies: Student GPU access or institution-provided cloud; curricular alignment; software setup support.
- Procurement support and pilot evaluations — Enterprise, Policy/Government
- What: Test prospective robot platforms and policies against standardized scenarios before purchase/deployment.
- Tools/workflows: Scenario packs mapped to target use cases (e.g., pick/place in clutter, shelf tasks), scorecards and reports.
- Assumptions/dependencies: Fairness controls for embodiment differences; buy-in from vendors; governance for test transparency.
- Marketing and customer demos in simulation — Robotics Vendors
- What: Showcase repeatable demonstrations for sales or training without shipping hardware to the customer site.
- Tools/workflows: Scene generalization scripts, scripted runs, auto-video capture with VLM overlays.
- Assumptions/dependencies: Visual realism acceptable to stakeholders; clear disclaimers on sim-to-real considerations.
Long-Term Applications
The following applications are feasible but require further research, scaling, or standardization (e.g., higher-fidelity physics, soft-body modeling, tactile simulation, standards alignment).
- Household humanoid training at scale — Consumer Robotics
- What: Train generalist bimanual household policies for cleaning, organizing, cooking prep, and tool use entirely in sim before deployment.
- Tools/workflows: Multi-million-hour synthetic data factory; richer dynamics (contacts, deformables), tactile/force simulation; curriculum learning.
- Assumptions/dependencies: Improved physics fidelity; improved dexterous hand and soft-body models; robust sim-to-real adaptation.
- Safety and compliance certification sandbox — Policy/Regulation, Insurance
- What: Standardized certification suites and evidence packages for regulators/insurers (near-miss rates, hazard response, failure modes).
- Tools/workflows: Adverse scenario generators (spills, occlusions, adversarial layouts), VLM evidence, auditing dashboards.
- Assumptions/dependencies: Industry consensus on metrics; third-party oversight; legal acceptance of simulation-based evidence.
- Healthcare robotics validation — Healthcare, Policy
- What: Preclinical validation of assistive tasks (medication fetch, tool handover, simple sanitization) under rigorous protocols.
- Tools/workflows: High-fidelity patient/clinical environment models; HRI scenario generation; auto-scoring with safety constraints.
- Assumptions/dependencies: Soft-body and human-robot safety modeling; privacy and regulatory (e.g., FDA-like) pathways; ethical review.
- Digital-twin-driven facility optimization — Manufacturing, Logistics, Retail
- What: Co-optimize layouts, robot fleets, and workflows using large-scale scenario generation and automated evaluation.
- Tools/workflows: End-to-end “simulate-to-optimize” loops; bottleneck analysis; multi-agent simulation; cost/time trade-off exploration.
- Assumptions/dependencies: Accurate demand/arrival models; validated throughput physics; integration with WMS/MES/ERP.
- Robot “app store” for evaluated skills — Robotics Ecosystem
- What: Publish, discover, and license skills/policies that are pre-evaluated on public benchmark suites for different embodiments.
- Tools/workflows: Standardized APIs, scorecards, scenario badges; on-device adapters; continuous re-evaluation.
- Assumptions/dependencies: IP/licensing frameworks; cross-embodiment standardization; secure model distribution.
- Fully synthetic foundation models for Embodied AI — Software/AI
- What: Train next-gen VLA policies predominantly on synthetic interaction at web scale, with minimal real-robot fine-tuning.
- Tools/workflows: Generative scene/task factories; progressive domain randomization; data curation and automatic difficulty scaling.
- Assumptions/dependencies: Data-quality scaling laws hold; reduced sim-to-real gap via better physics and sensor modeling; massive compute budgets.
- HRI stress-testing for language, social cues, and ambiguity — Social Robotics, Customer Service
- What: Use LLM-generated ambiguous, multi-turn instructions and social contexts to evaluate robustness and safety of HRI policies.
- Tools/workflows: Agent-based scenario generators; evaluation for misunderstandings, recovery behaviors, and escalation handling.
- Assumptions/dependencies: Realistic human avatar behaviors; ethics and safety frameworks; evaluation agreement on acceptable behaviors.
- Autonomy risk pricing and robotics insurance — Finance/Insurance
- What: Derive actuarial risk models from large-scale simulated failure statistics to inform premiums and warranties.
- Tools/workflows: Scenario libraries of rare hazards; incident simulation; portfolio-level Monte Carlo over environments.
- Assumptions/dependencies: Regulatory acceptance; proven correlation between simulated and real incident rates; transparent model governance.
- Remote work via telepresence + shared autonomy — Daily Life, Enterprise
- What: Mixed teleop/autonomy workflows for remote manipulation in homes, labs, or maintenance sites.
- Tools/workflows: VR teleop bootstrapped with simulation-trained assistive policies; shared-control arbitration; training in sim.
- Assumptions/dependencies: Reliable low-latency networks; robust safety interlocks; ergonomic operator interfaces.
- National or sectoral procurement benchmarks — Government, Standards Bodies
- What: Sector-specific test suites (e.g., eldercare, postal sorting, lab automation) for fair public procurement and performance transparency.
- Tools/workflows: Curated scenario packs; public leaderboards; audit trails with VLM evidence.
- Assumptions/dependencies: Multi-stakeholder governance; periodic updates; vendor participation and conformance tooling.
- Education at planetary scale via cloud labs — Education, Workforce Development
- What: Global practical training for robotics/AI learners without physical labs; competency-based assessment.
- Tools/workflows: Cloud-hosted simulation pods; standardized exams; automated grading with VLMs.
- Assumptions/dependencies: Subsidized GPU access; curriculum standardization; accessibility and language localization.
- Sustainable prototyping and lifecycle assessment — Sustainability
- What: Reduce material waste and travel through sim-first prototyping, testing, and iteration for robot deployments.
- Tools/workflows: Simulation-first design gates; digital twin maintenance plans; embodied energy modeling.
- Assumptions/dependencies: Executive buy-in for sim-first processes; validation that sim savings translate to real-world impact.
Collections
Sign up for free to add this paper to one or more collections.