- The paper introduces LogicalRAG, a novel framework that empowers LLMs with explicit Boolean logic to overcome redundant retrieval and backend overhead.
- It demonstrates that LogicalRAG achieves comparable accuracy to embedding-based methods while reducing indexing costs by 41× and enhancing serving efficiency.
- Experiments show that explicit lexical constraints improve intent recovery and curb hallucinations, ensuring precise and controlled evidence retrieval.
Rethinking Agentic RAG: LLM-Driven Logical Retrieval Beyond Embeddings
Motivation and Problem Analysis
Recent advances in Retrieval-Augmented Generation (RAG) frameworks have increasingly adopted agentic paradigms, where LLMs actively interact with retrieval engines in multi-turn search loops. Typical approaches employ dense embeddings, hybrid retrieval (combining sparse and dense), or graph-based backends to optimize semantic relevance and recall. However, as highlighted in this paper, these architectures pose several limitations in agentic RAG settings:
- Redundant retrieval: Semantic similarity in embedding space often leads to high overlap across refined queries, impairing query repair and evidence accumulation.
- Backend complexity: Dense, hybrid, and graph-based systems entail substantial preprocessing, indexing, maintenance, and serving costs, especially at corpus scale.
- Limited control: LLMs lack explicit mechanisms to impose fine-grained lexical constraints or dynamically broaden or constrain the retrieval space, leading to inefficient recovery from distractors and hallucination when evidence is absent.
The paper advocates delegating greater control to the LLM via high-level retrieval interfaces enabling explicit intent specification, precise query refinement, and transparent signals for evidence failures. It introduces LogicalRAG: an agentic RAG framework leveraging logical expressions for query formulation and an inverted-index backend for execution.
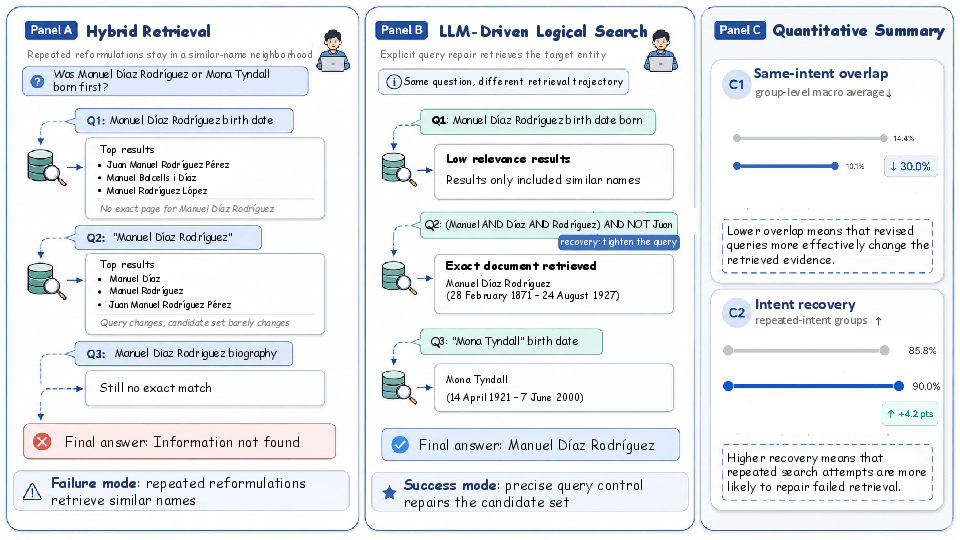
Figure 1: Trajectory statistics reveal Agentic Hybrid repeatedly retrieves distractors for same-intent queries, while LogicalRAG achieves superior intent recovery with explicit lexical constraints.
LogicalRAG Framework: LLM-Driven Search Control
LogicalRAG operationalizes the interface-control paradigm with a lightweight yet powerful retrieval action space:
Interface Design
- Queries are formulated by the LLM via Boolean logic, phrase matching, field targeting, and term boosting.
- Constraints are directly mapped onto Lucene-style expressions for execution over corpus titles and content.
- Adjustable granularity allows alternating between broad keyword matches and exact phrase/entity retrieval—crucial for multi-hop QA.
Backend Implementation
- The retrieval infrastructure is strictly lexical: standard inverted-index and BM25 ranking.
- Logical constraints dictate candidate selection, with BM25 providing final ranking within candidate sets.
- Absence of embeddings or graph indices bypasses corpus-wide processing costs and serving latency.
This separation ensures intent-faithfulness: query modifications by the LLM directly and transparently alter retrieved evidence, facilitating efficient search repair and robust abstention.
Experimental Evaluation
Datasets and Baselines
Evaluations span medium (HotpotQA, 2WikiMultiHopQA, MuSiQue) and large-scale (KILT Wikipedia) corpora. Baselines include No-Retrieval, Agentic Hybrid (sparse/dense fusion), HippoRAG2 (graph-based), and MA-RAG (embedding/multi-agent).
Answer Accuracy
LogicalRAG matches or slightly outperforms Agentic Hybrid on medium-scale datasets, and achieves near-parity on KILT-scale data. Average LLM-as-a-Judge accuracy is 0.717 for LogicalRAG vs. 0.716 for Agentic Hybrid. The numerical results underscore the competitive efficacy of lexical retrieval when the interface exposes sufficient control.
Efficiency Metrics
LogicalRAG demonstrates dramatically superior construction and serving efficiency:
- Indexing cost: $1.27$ hours for LogicalRAG vs. $52.02$ hours (embedding generation, FAISS indexing) for Agentic Hybrid—a 41× reduction.
- Online serving: 2.3× higher throughput and 3.1× lower latency at concurrency 16.
- Graph-based systems are infeasible at scale due to corpus-wide LLM preprocessing requirements.
Model Scaling: Capability Thresholds for Logical Retrieval
A central finding is that logical retrieval's viability is agent-dependent. On KILT-scale corpora, Agentic Hybrid retains an edge for weaker LLMs. As LLM capability increases (Qwen3.5 model scaling), LogicalRAG's performance rises rapidly and soon attains parity with Agentic Hybrid. This threshold effect suggests that high-control retrieval interfaces become increasingly effective as LLMs master query decomposition and constraint expression.
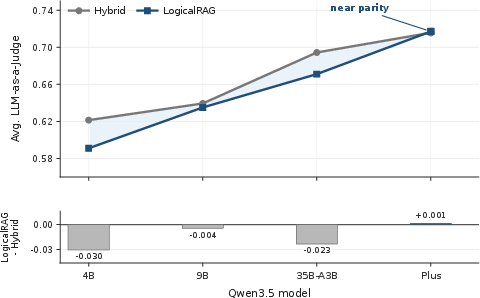
Figure 2: Model scaling demonstrates LogicalRAG closing the accuracy gap with Agentic Hybrid as LLM capability increases, achieving parity at Qwen3.5-Plus.
Robustness: Hallucination Reduction in Evidence-Absent Scenarios
LogicalRAG exhibits improved refusal rates and reduced hallucination when gold evidence is unavailable. Explicit lexical constraints yield clearer retrieval failures, signaling answer-unavailability and prompting abstention—contrasted with the semantic fallback of embedding-based systems that may encourage unsupported answers.
Implications, Limitations, and Future Directions
Practical Implications
- LogicalRAG offers a scalable, cost-effective alternative to embedding-based systems in knowledge-intensive agentic RAG tasks.
- The framework facilitates fine-grained search repair, efficient distractor exclusion, and robust hallucination mitigation—critical for QA, research agents, and sensitive information synthesis domains.
Theoretical Impact
- The results underscore an interface-centric design principle: retrieval efficacy in agentic RAG is increasingly a function of LLM expressivity and action space controllability, rather than backend complexity.
- Model scaling experiments indicate emergent retrieval capabilities in modern LLMs, with logical interfaces rapidly approaching parity to dense/hybrid approaches.
Limitations
- LogicalRAG's efficacy is contingent on precise query formulation by the LLM. Scenarios requiring highly abstract semantic matching or fuzzy entity associations still benefit from dense retrieval.
- Current system focuses on textual corpora; adaptation to multimodal or evolving knowledge bases poses open challenges.
Future Outlook
- Integrations combining logical and dense retrieval tools could capture both lexical precision and semantic coverage, though with increased complexity and resource costs.
- Expanding interface control paradigms to handle multimodal evidence and adaptive corpus evolution remains critical.
Conclusion
The paper positions LogicalRAG as a compelling agentic RAG framework: by equipping LLMs with explicit logical search interfaces and simplifying backend retrieval, it matches hybrid retriever accuracy while dramatically reducing construction and serving overhead. The paradigm foregrounds the growing power of LLM-driven retrieval planning, suggesting that future agentic RAG systems should prioritize high-control, intent-faithful interfaces, leveraging increasingly capable LLMs to orchestrate retrieval with precision and efficiency.