- The paper introduces Corpus2Skill, a two-phase framework that converts enterprise corpora into a hierarchical, navigable skill tree to enhance QA and RAG.
- It employs offline semantic embedding, K-Means clustering, and LLM summarization along with online agent navigation to outperform traditional retrieval methods on key metrics.
- The framework enables active multi-branch reasoning and evidence synthesis, offering promising improvements for enterprise and compliance-critical question answering.
Distilling Enterprise Knowledge into Navigable Agent Skills: The Corpus2Skill Framework
Introduction
Retrieval-Augmented Generation (RAG) has emerged as the default approach for grounding LLM outputs in external knowledge by retrieving evidence passages relevant to queries. However, classical RAG architectures position the LLM as a passive consumer of retrieved content, depriving it of visibility into the structure and breadth of the source corpus. This limitation constrains the LLM’s ability to reason about corpus organization, cross-reference evidence, or effectively backtrack when needed. “Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG” (2604.14572) introduces Corpus2Skill, a framework that transforms enterprise knowledge corpora into hierarchical, navigable agent skills, enabling active exploration and reasoning at inference time.
Corpus2Skill: System Overview and Key Innovations
Corpus2Skill presents a two-phase pipeline: (1) an offline compile phase converts a document corpus into a navigable hierarchy of skills, and (2) a serve phase where an LLM agent interacts with the skill hierarchy using file-browsing and document-lookup tools.
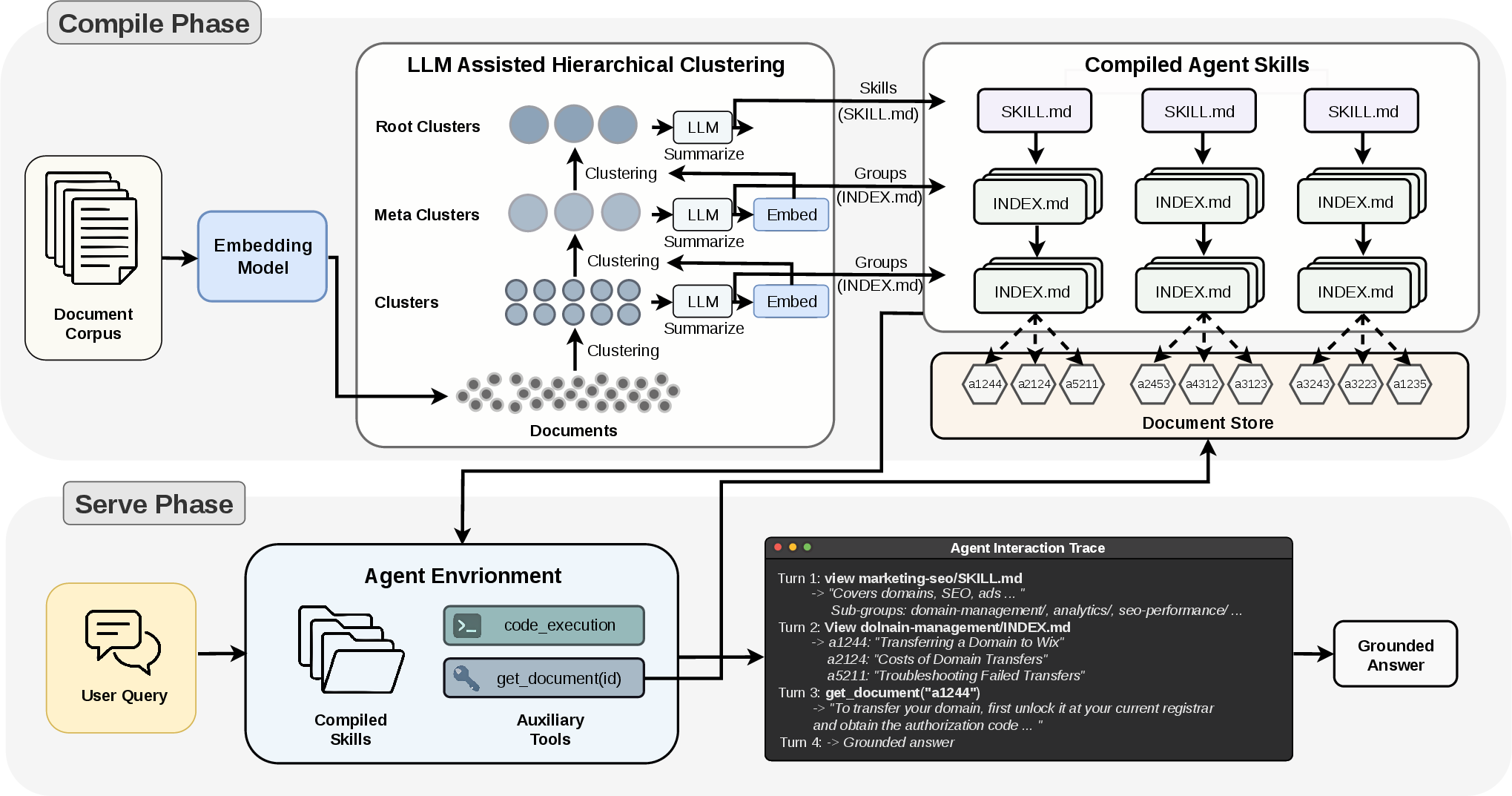
Figure 1: Corpus2Skill system architecture, detailing the hierarchical clustering and summarization at compile time and active agent navigation at serve time.
Hierarchical Skill Compilation
Offline, Corpus2Skill applies semantic embedding (using a sentence transformer), followed by iterative K-Means clustering in embedding space, and LLM-based summarization at each hierarchical level. Each cluster (at each level) gets materialized as a “skill” directory, with SKILL.md and INDEX.md files containing structured YAML metadata, tree summaries, and document references. Skill directories are labeled for both human and agent interpretability.
Documents are deterministically assigned to a single path in the tree to ensure reproducibility and filesystem-based navigation. By separating navigation (i.e., summary metadata) from raw documents, the agent can browse efficiently, loading details only when necessary via progressive disclosure.
Active Navigation at Inference
At serve time, an LLM agent is initialized with the top-level skill names and summaries, which incurs minimal token overhead. The agent uses file-browsing (ls/cat analogs via code_execution) to progressively drill into relevant branches and employs get_document(doc_id) for retrieving selected full documents when needed. Crucially, the agent reasons about the structure—knowing which branches are unexplored, revisiting previous choices, and synthesizing evidence from across multiple branches for multifaceted queries.
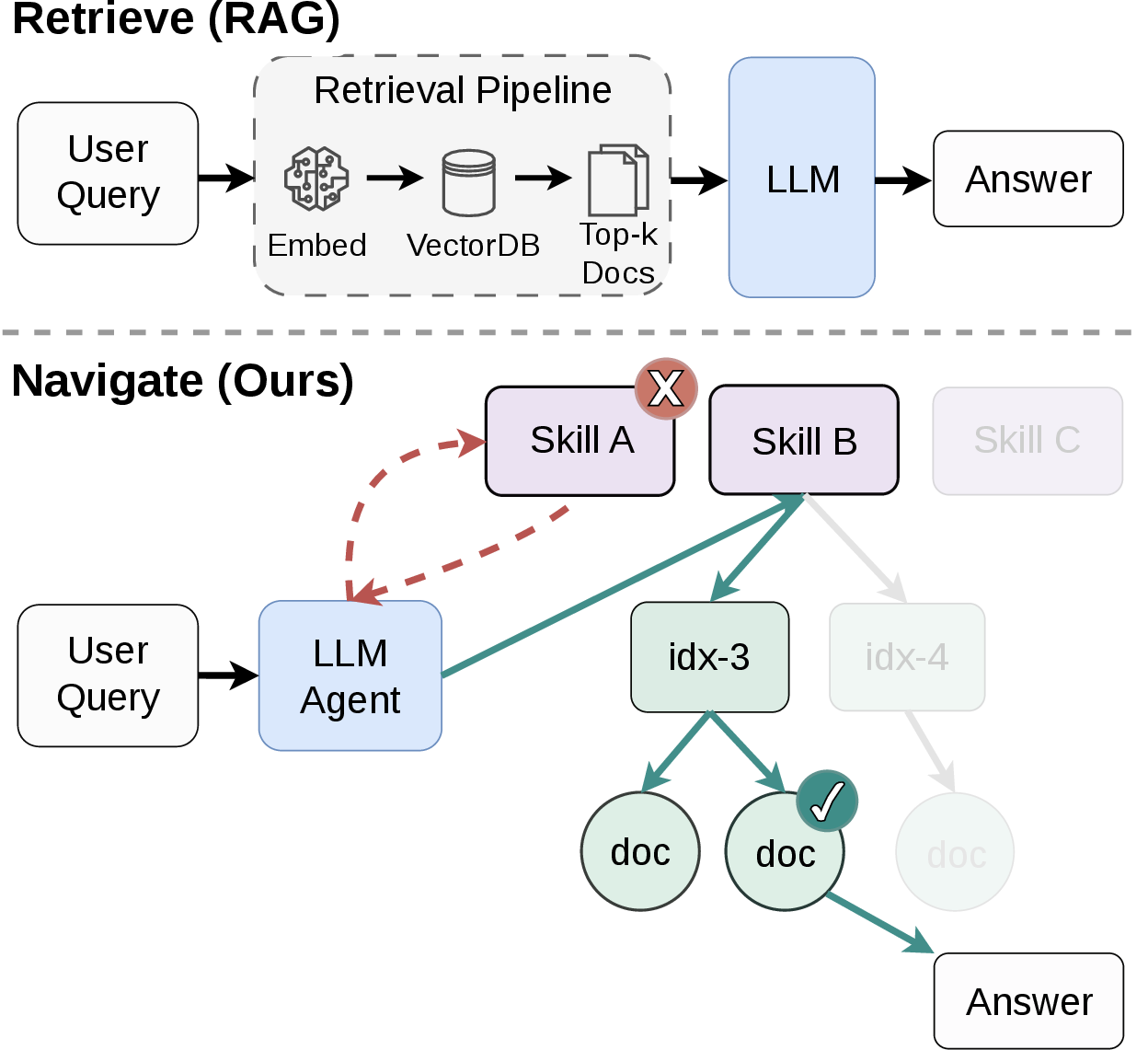
Figure 2: Comparison between traditional RAG (retrieve) and Corpus2Skill (navigate), emphasizing the agent’s active exploration and evidence combination.
Experimental Results and Empirical Analysis
Experimentation is conducted on the WixQA dataset, a robust enterprise QA benchmark comprising over 6,000 documents and hundreds of multi-hop, expert-written queries. Corpus2Skill is compared against five baselines: BM25, dense vector search, hybrid retrieval, RAPTOR (hierarchical but retrieval-centric), and agentic RAG with tool-use.
Corpus2Skill outperforms all baselines on every quality metric, including Token F1 (0.460), BLEU (0.137), ROUGE-2 (0.231), LLM-judged factuality (0.729), and context recall (0.652). This represents a 19% improvement in F1 over the strongest agentic RAG and a 27% improvement over dense retrieval. Hierarchical approaches (RAPTOR, Corpus2Skill) substantially outscore flat retrievers, validating the benefit of explicit corpus structure (2604.14572).
Cost per query (\$0.17) is higher than classical retrieval methods due to token usage from progressive file loading, but this is justified in scenarios where quality is paramount. Corpus2Skill retrieves fewer, but highly targeted, output tokens per query compared to agentic or flat retrieval.
Agent navigation traces reveal the system’s capacity for direct descent (single-branch navigation) as well as cross-branch synthesis (retrieving and combining evidence from multiple branches), showing true agentic reasoning beyond basic search.
Ablations and Design Analysis
Several ablation studies clarify the trade-offs between hierarchy depth (controlled by branching ratio), agent exploration budget, and serving LLM sophistication:
- Hierarchy shape: Deeper, narrower trees facilitate slightly higher quality (F1 up to 0.461) with modest increase in token usage, while wider, shallow hierarchies degrade performance.
- Agent exploration: Performance is robust to limited exploration budgets; most queries are resolved in 2-3 turns, demonstrating the efficacy of the hierarchical organization.
- Serving model: A cheaper LLM yields only a minor drop in answer quality but substantially reduces cost, confirming the utility of the pre-compiled skill structure independently of navigation model capacity.
Limitations
Corpus2Skill depends on the API’s skill/file limits, which constrain the top-level branching and depth; though WixQA fits comfortably, massive corpora might require compacting leaves. The strict single-path (hard clustering) assignment can hinder multi-topic queries, as documents straddling topics are only accessible via a single branch. Compilation currently does not support incremental updates and must be re-run after corpus modifications. Finally, higher per-query costs restrict applicability to high-value, domain-critical queries.
Theoretical and Practical Implications
Corpus2Skill demonstrates that explicit corpus navigability is an underexploited axis in retrieval-augmented systems. By transforming static document collections into skill-based, structured knowledge, LLM agents can actively reason about where information is located, resulting in improved factual consistency and context recall. The approach departs from reliance on embedding-based retrieval at inference, decoupling runtime from vector store dependencies and shifting computational investment to the compile phase.
Pragmatically, this paradigm is highly relevant for enterprise and compliance-critical QA, where traceability and controllability of context are necessary, and the cost of error is high. As LLM agent platforms mature and context/pricing constraints relax, this navigation-based design may become more competitive at scale.
Future Directions
Potential directions for advancing the Corpus2Skill framework include:
- Incremental and online compilation to support dynamic corpora.
- Soft or multi-parent clustering to address multi-topic documents.
- Prompt caching and reusable summaries to further reduce per-query costs.
- Application to broader, less structured corpora and new QA modalities (e.g., structured data, procedural knowledge).
Conclusion
Corpus2Skill establishes that transforming enterprise corpora into navigable agent skills yields superior answer quality for agentic QA systems relative to traditional RAG methods. By leveraging the LLM's reasoning and exploration abilities within a transparent, hierarchical knowledge structure, the system enables richer, traceable, and more contextually aware answers. While cost and API constraints currently pose practical limits, this framework delineates an important direction for future research in agentic, structure-aware knowledge access for large-scale AI systems.

