Introspective X Training: Feedback Conditioning Improves Scaling Across all LLM Training Stages
Abstract: We tackle the question of how to scale more efficiently across the many, ever-growing stages of current LLM training pipelines. Our guiding intuition stems from the fact that the dynamics of later stages of the pipeline, e.g. post-training, can be used to inform earlier stages such as pre-training. To this end, we propose Introspective Training (or IXT), inspired by offline reward-conditioned reinforcement learning and applicable to any stage of training. IXT uses a thinking reward model to annotate data with natural language critique based feedback, enabling quality aware training from the earliest stages of the pipeline. Models are then trained by prefix-conditioning the data with the generated feedback -- ensuring that not all tokens are treated equally starting much earlier in training than usual. Comprehensive experiments on 7.5-12B transformer-based dense LLMs trained from scratch all the way up to 18 Trillion tokens seen show that our method: bends scaling curves resulting in up to 2.8x more compute efficiency generally; and reaches performance levels unachievable for models trained otherwise in domains such as math and code.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple idea to make training LLMs faster and smarter: add a short “teacher note” to each training text that says how good it is and why. The model reads this note first, then the text. Doing this at every stage of training—early (pretraining), middle (continued training), and late (fine‑tuning)—helps the model learn more efficiently, especially for math and coding.
What questions were the researchers trying to answer?
- Can adding feedback to training data make LLMs learn more efficiently at all stages of training?
- Can this approach help specialize models for certain skills (like math or coding) using less compute?
- Does it still help when training on a big mix of topics, not just one domain?
- Is natural-language feedback (short explanations in plain text) better than simple labels like “high quality” or “low quality”?
How did they do it?
Think of training as teaching a student with lots of articles and problems. The new trick is to attach a small “sticky note” on top of each article that says how good it is and gives a quick critique.
Here’s the process in everyday terms:
- A judge model (another LLM) reads each training document and writes:
- A few quality scores (like writing quality, accuracy, usefulness).
- An overall rating from 1 to 5.
- A tiny critique in natural language (1–2 sentences) that explains the rating.
- The training model then sees the “sticky note” first (this is called a prefix) and learns the text that follows. This teaches it that not all examples are equal—and what “good” looks like.
- Two kinds of “sticky notes” were tested:
- Simple labels: words like “[low]” or “[high]” (easy but less detailed).
- Natural-language critiques: short, readable comments explaining quality (richer and more helpful).
- They used this method at all stages:
- Pretraining (early learning on huge internet text).
- Continued training on specific topics (like math or code).
- Supervised fine-tuning (learning from curated question–answer pairs).
- For small, carefully curated datasets (like late-stage fine-tuning), they also tried “pairwise” judging: compare two documents and pick the better one repeatedly, then rank everything. This is like running mini “face-offs” to build a quality leaderboard.
- Measuring efficiency: They counted total compute, including the one-time cost of generating all those “sticky notes.” Compute is measured in FLOPs (think: how much calculator work the computer does). They asked: for the same compute, which method gets better scores?
What did they find?
Here are the main results, in simple terms:
- Big efficiency gains:
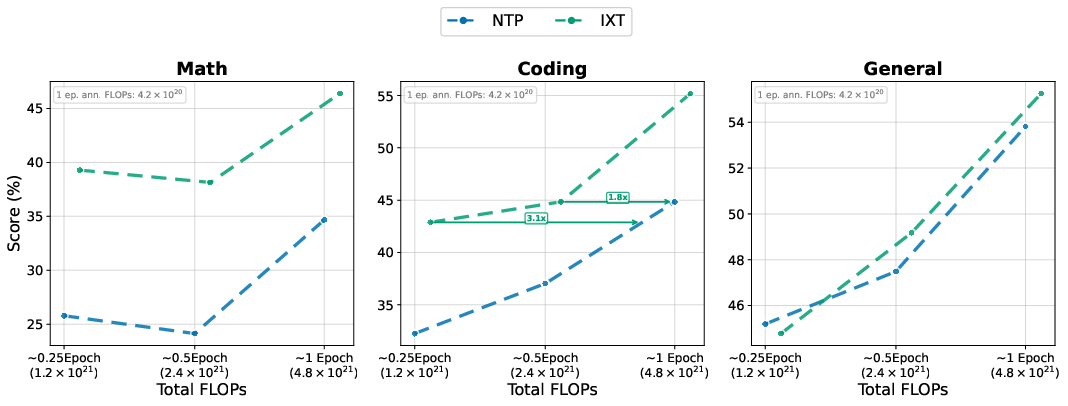
- With feedback conditioning, models reached the same accuracy using up to about 2.8× less compute. In other words, they learned faster for the same effort.
- Stronger math and coding skills:
- Early in training (after ~95 billion tokens), math and code scores jumped a lot (for example, around +9 to +10 points on popular coding/math tests like HumanEval and MATH), and the gains stuck around even later.
- On several coding benchmarks, the feedback method beat what standard training could reach at all, even if you kept training longer.
- Works from start to finish:
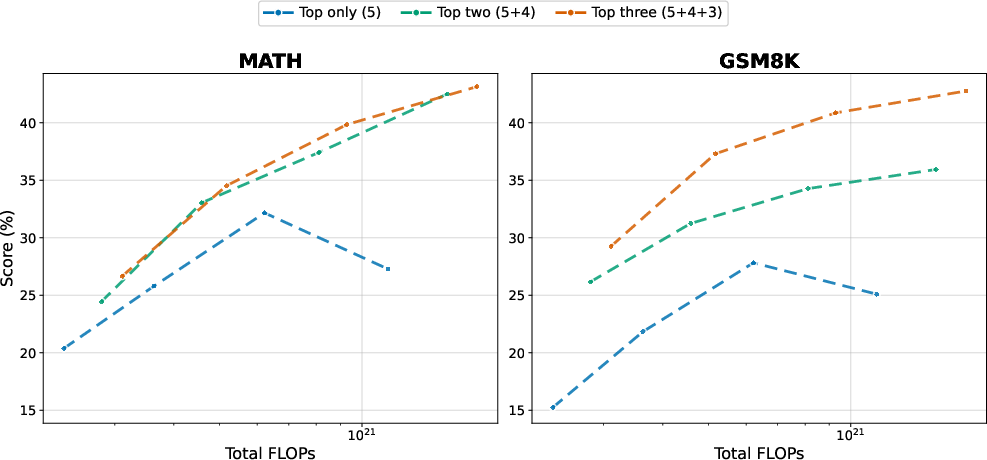
- It helps when training from scratch, at mid-stages (after 12–18 trillion tokens seen), and during supervised fine-tuning. Gains during fine-tuning were smaller (the data there is already filtered), but still positive overall—and got better with the pairwise judging trick.
- You don’t need to annotate everything:
- Annotating just the parts of the data where quality varies clearly (like structured math/code sources—about 15% of the whole mix) gave most of the benefits. This saves time and compute.
- Natural-language critiques help the most:
- Using short critiques generally beat simple labels by a couple of points on average. Critiques are also easier for people to write or adjust, so they’re practical for steering the model’s behavior.
- Fair compute accounting:
- All reported efficiency gains include the cost of creating the feedback notes once, up front.
Why is this important?
- Faster, cheaper training: Getting more accuracy out of the same compute saves money, time, and energy.
- Better skills where it counts: Big gains in math and coding mean stronger problem-solving and more reliable code generation.
- A unified recipe: The same simple idea—prepend feedback—works across all training stages, which simplifies complicated pipelines.
- Practical control: Because the feedback is in natural language, people can guide models at test time by describing the kind of answer they want (clear, concise, step-by-step, etc.).
Limitations and what’s next
- The quality rubric used was general-purpose. For code, you might want code-specific criteria (correctness, efficiency), which could improve results further.
- The feedback is created once before training. As the model gets better, you might want to re-annotate or update the critiques.
- Future work: design better rubrics per domain, refresh annotations over time, and explore mixing labels and critiques for the best of both worlds.
In short
Attaching short, judge-written feedback to training texts teaches LLMs to value high-quality examples from the very beginning. This bends the usual “more compute = better model” rule in your favor: you get more skill per unit of compute, especially in math and code, and the method stays useful from the first training steps all the way to the final polish.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete research directions that the paper leaves open.
- Rubric calibration and design
- The general-purpose 5-axis rubric may be suboptimal for domains like code and math; how to design or learn domain-specific rubrics (axes, weights, and aggregation from s to q) that correlate with downstream utility?
- What is the optimal granularity (document-, paragraph-, or token-level) and verbosity of critiques for different domains and tasks?
- Judge model choice, reliability, and bias
- The study uses a single judge (Qwen3-30B-A3B); how do results vary across judge models, sizes, and instruction styles? What is inter-judge reliability and stability over time?
- How robust is X to noisy, biased, or adversarial annotations? Can we estimate annotation confidence/uncertainty and incorporate it during training?
- What calibration or normalization is needed to make scores comparable across domains and datasets with different length and style distributions?
- Static vs online/iterative annotation
- Annotations are computed once; does periodic re-annotation (online/iterative X) against evolving checkpoints produce better gains per FLOP?
- Can active learning select which documents to (re-)annotate to maximize marginal utility of annotation compute?
- Scope and scalability of results
- Results are shown for 7.5B dense transformers and a 12B hybrid; do the gains persist for larger models (e.g., 30–70B+), MoE architectures, and mixtures of decoder/encoder-decoder models?
- Do findings transfer to multilingual/multimodal corpora and non-English benchmarks?
- Mechanistic understanding
- Why does prefix feedback bend scaling curves? Is the improvement due to better gradient allocation, implicit curriculum effects, or distributional conditioning? Formal analyses or controlled diagnostics are missing.
- Under what conditions does X surpass the NTP asymptote on fixed corpora, and when does it not (e.g., MBPP regressions)?
- Compute accounting and systems effects
- Training with prefixes increases sequence length; how do added prefix tokens affect effective content tokens per step, memory bandwidth, throughput, and wall-clock time?
- The FLOP accounting includes annotation inference but does not explicitly analyze the training overhead from longer sequences; a clear, apples-to-apples comparison of end-to-end time/energy is needed.
- Inference-time costs and policies
- Using critiques at inference increases prompt length and latency; what is the latency–quality trade-off and best practices for deployment?
- How should one select or generate inference-time critique prefixes (set construction, retrieval, automatic policy selection) for arbitrary tasks?
- Subset vs full-blend annotation strategy
- Targeted subset annotation was effective, but what fraction of a blend should be annotated for best cost–benefit at different scales?
- Can we learn a principled schedule for which sources to annotate and when, conditioned on model state and target metrics?
- Comparisons to strong data-quality baselines
- Direct empirical comparisons to filtering/reweighting methods (e.g., DoReMi, QuRating, Meta-rater, PPLCorr, PreSelect, BETR) are missing; how does X perform relative to or in combination with these?
- What is the marginal gain of X when layered on top of state-of-the-art mixture/selection pipelines?
- Contamination and evaluation hygiene
- GSM8K is present in Dolmino; improvements may reflect reinforcement of in-blend training data. A contamination-controlled evaluation (document-level decontamination and family-wise filtering) is required to isolate genuine generalization gains.
- Report variance across seeds and statistical significance to assess robustness of improvements.
- Negative transfer and forgetting
- Some regressions (e.g., MBPP) suggest domain-specific rubrics can misalign with task utility; how to detect and mitigate negative transfer?
- Does repeated use of quality-conditioned prefixes induce forgetting or overfitting to rubric-congruent styles?
- SFT-specific design choices
- During SFT the system message is masked while used for conditioning; what is the effect of masking vs unmasking the prefix on stability, capability, and alignment?
- Pairwise annotation helped on SFT > 4k; does pairwise (or listwise) annotation consistently outperform pointwise across SFT mixtures and sizes?
- Granularity of conditioning
- The method conditions at document level; would sentence-/span-level or token-level feedback yield better signal-to-noise and controllability without excessive overhead?
- Safety, alignment, and misuse risks
- How does X affect toxicity, bias, refusal behavior, and jailbreak robustness? Can adversarial or “low-quality” prefixes steer models toward harmful outputs?
- Can safety rubrics and critiques be integrated to steer both capability and alignment simultaneously? How does X interact with safety pretraining and RLHF?
- Interplay with RL and reasoning training
- How does X combine with RL-style post-training (e.g., GRPO/RLHF) or chain-of-thought supervision? Is there an optimal ordering or joint objective?
- Does X reduce the need for later RL or enable more sample-efficient RL?
- Data governance and privacy
- Do feedback critiques introduce new privacy/IP concerns (derivative data, revealing sensitive info) or audit obligations? What best practices mitigate risks?
- Deduplication and mixture interactions
- How do annotation and prefixing interact with deduplication heuristics, mixture reweighting, and curriculum schedules?
- Broader task coverage
- Effects on long-context reasoning, retrieval-augmented generation, tool use, and planning are unexplored; does prefix conditioning help or hinder these capabilities?
- Reproducibility and release
- Full prompts, annotations, and code are not released; without them, replication of annotation quality and scaling claims is difficult.
These gaps offer clear, testable directions to strengthen the empirical and theoretical foundations of feedback-conditioned training across the modern LLM pipeline.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, drawing directly from the paper’s findings on feedback-conditioned training (X), its compute efficiency gains (up to 2.8×), and its effectiveness across pretraining, continued pretraining (CPT), and SFT.
- Quality‑conditioned continued pretraining for targeted domains
- Sector: software (code), education (math), research
- What: Use X to annotate domain corpora (e.g., math/code) with rubric scores or critiques and prepend these prefixes during CPT. Reported gains: +9–10 points on HumanEval/MATH in early stages; sustained improvements at 12T/18T; up to 2.8× FLOP efficiency at matched accuracy.
- Tools/workflows: Judge-LLM annotation service; prefix-injection dataloader; evaluation with matched prefix selection.
- Dependencies/assumptions: Access to a capable judge model (e.g., 30B); domain-calibrated rubric; privacy-preserving annotation for proprietary data.
- Targeted subset annotation to reduce cost while maximizing impact
- Sector: AI training/ops, enterprise ML
- What: Annotate only high-signal subsets (e.g., structured math/code within a general blend). Paper shows annotating ~15% of data can match or exceed full-blend annotation and deliver large gains (e.g., coding up to 3.1× compute efficiency).
- Tools/workflows: Mixture analysis to identify high-signal sources; annotation scheduler; per-source prefixing.
- Dependencies/assumptions: Accurate identification of high-yield subsets; mixture stability across training runs.
- Pairwise annotation for SFT to avoid score compression
- Sector: model alignment/finetuning (academia/industry)
- What: For curated SFT datasets, use pairwise judgments with a Bradley–Terry fit to derive better-calibrated quality scores; observed +0.7 avg. improvement over pointwise X and +2.4 over NTP on SFT > 4k.
- Tools/workflows: Pairwise rater; L-BFGS scorer; bucketing to five-level labels; system-message prefixing in SFT.
- Dependencies/assumptions: Additional annotation compute; well-designed pair sampling; mitigation for position bias.
- Critique‑based inference steering (no retraining required if model already X‑trained)
- Sector: software, education, enterprise assistants
- What: At deployment, prepend short natural-language critiques describing desired traits (concise, step-by-step, cite facts) to steer outputs, leveraging the paper’s finding that critique prefixes can outperform templated tokens (+2.6 avg. over tokens in general blends).
- Tools/workflows: “Critique prompt library”; prefix templates per task; A/B testing for KPI impact.
- Dependencies/assumptions: The model has seen critique-style prefixes during training; rubric-task alignment (e.g., code may require code-specific rubrics).
- Faster KPI attainment in multi-stage training pipelines
- Sector: foundation model providers, startups
- What: Insert X early (pretraining from scratch or early CPT) to hit math/code KPIs faster than NTP baselines, enabling earlier productization or staged releases.
- Tools/workflows: Cross-stage X recipes (pre, mid, post); compute dashboards using total FLOPs (training + annotation).
- Dependencies/assumptions: Internal adoption across pipeline owners; accurate compute accounting.
- Quality-aware data governance and auditing
- Sector: policy/compliance, data engineering
- What: Store per-document quality scores and critiques as dataset metadata to support audits, removal of low-quality segments, and provenance reporting.
- Tools/workflows: “Annotation store” with searchable scores/axes (style, expertise, accuracy, educational value, efficiency); dashboards.
- Dependencies/assumptions: Annotation bias management; retention policies for critiques; legal review for storing critiques of proprietary text.
- Lower‑compute enterprise domain adaptation
- Sector: healthcare, legal, finance, customer support
- What: Use X on proprietary, in-domain corpora to build vertical models with reduced compute (thanks to annotated prefixes) while improving accuracy/consistency (e.g., clinical notes, regulatory summaries, support playbooks).
- Tools/workflows: On-prem/in-VPC judge model; domain-specific rubric design; prefix-aware CPT/SFT.
- Dependencies/assumptions: Strict data privacy; regulatory constraints (PHI/PII); domain rubrics capturing correctness and risk dimensions.
- SFT system-message conditioning without loss masking changes
- Sector: alignment and instruction tuning
- What: Inject feedback prefixes as system messages during SFT (paper uses standard masking, conditioning only), improving overall averages across diverse SFT sets.
- Tools/workflows: SFT trainer with system-message prefix injection; per-dataset critique generation.
- Dependencies/assumptions: High-quality SFT mixtures leave less headroom; pairwise annotation may be needed for additional gains.
- Compute planning and sustainability reporting
- Sector: AI ops, finance, energy/sustainability
- What: Adopt the paper’s FLOP accounting that includes annotation inference, enabling apples-to-apples budget planning and “green AI” reporting for stakeholders.
- Tools/workflows: Training ledger that logs model size, tokens, annotation tokens; CO2 calculators tied to data center mix.
- Dependencies/assumptions: Accurate logging; consensus on reporting standards.
- Developer‑facing plugins for training stacks
- Sector: AI tooling/software
- What: Ship a “Prefix Manager” for PyTorch/DeepSpeed/Transformers that prepends quality tokens/critiques, plus a “Judge & Rubric” microservice to annotate corpora once.
- Tools/workflows: Dataloader hooks; tokenizer-safe prefix templates; retries and QC for annotation outputs.
- Dependencies/assumptions: Compatibility with long-context batchers; cost controls for annotation bursts.
Long-Term Applications
The items below require further research, scaling, or productization before broad deployment.
- Iterative/online introspective training
- Sector: foundation models, research
- What: Periodically re-annotate data as the model improves (closing the loop) to avoid stale quality signals and maintain separability of high/low-quality distinctions over time.
- Dependencies/assumptions: Annotation compute amortization; drift detection; scheduling and versioned annotations.
- Domain‑optimized rubrics and multi‑attribute control
- Sector: software, healthcare, finance, legal
- What: Replace general-purpose rubrics with domain rubrics capturing correctness, safety, compliance, and efficiency; enable explicit control across multiple axes at inference.
- Dependencies/assumptions: Expert-designed axes; bias/fairness review; calibration and unit tests per domain.
- Standardized “quality‑annotated dataset” format
- Sector: data marketplaces, academia, open data
- What: Ship corpora with attached critiques and per-axis scores as first-class metadata; enable mixture design, sampling, and training-time conditioning out-of-the-box.
- Dependencies/assumptions: Community standards (schemas, licenses); storage overhead; judge transparency.
- Self‑refinement loops with verbal feedback
- Sector: model serving platforms
- What: At inference, have the model generate or retrieve critiques and then regenerate answers conditioned on those critiques, trading test-time compute for quality.
- Dependencies/assumptions: Latency/throughput budgets; reliability of self-critiques; guardrails to prevent error reinforcement.
- Cross‑modal introspective training (VLMs, speech, agents)
- Sector: robotics, multimodal AI, assistive tech
- What: Extend prefix feedback to next-token-style multimodal models (e.g., plan quality critiques for robotics instruction or visual question answering).
- Dependencies/assumptions: Multimodal rubrics; alignment of critiques with non-text modalities; sequence formatting.
- Safety/ethics conditioning during pretraining
- Sector: safety, policy
- What: Bring safety/refusal/harms critiques into pretraining via X to reduce later alignment burden and improve robustness out-of-the-box.
- Dependencies/assumptions: High-quality safety judges; adversarial evals; monitoring for over-refusals or utility loss.
- Privacy‑preserving, federated annotation
- Sector: regulated industries
- What: On-device or on-prem judge models annotate sensitive corpora; differenties are harmonized via secure aggregation to build global quality-aware models without exposing data.
- Dependencies/assumptions: Efficient on-prem judges; cryptographic or federated protocols; governance.
- Audit trails and compliance workflows
- Sector: regulators, procurement, enterprise governance
- What: Mandate and verify interpretable quality annotations in procurement and compliance checklists, enabling third-party audits of data quality and curation decisions.
- Dependencies/assumptions: Regulatory consensus; standardized attestations; red-team audits for annotation bias.
- Certified “green training” metrics that include annotation overhead
- Sector: energy/sustainability reporting
- What: Industry certifications that require total FLOP reporting (training + annotation), enabling better comparisons and incentives for efficient training recipes like X.
- Dependencies/assumptions: Auditable logs; third-party verifiers; alignment with ESG frameworks.
- LLMOps automation around “annotation‑as‑a‑service”
- Sector: AI platform providers
- What: Managed services for scalable annotation, rubric design, score calibration, and prefix-aware training schedules integrated into MLOps pipelines.
- Dependencies/assumptions: SLAs for cost/latency/quality; QBEs (query-by-example) for rubric tuning; robust retry/QC loops.
- Personalized models steered by user‑level critiques
- Sector: consumer apps, education
- What: Let users specify preference critiques (tone, depth, pedagogy), which become prefixes for generation, enabling controllable personalization without full finetuning.
- Dependencies/assumptions: Preference safety; stable behavior across sessions; conflict resolution between global and user rubrics.
- Integration with RL from verbal feedback
- Sector: research, advanced alignment
- What: Combine X’s critique conditioning with RL-style objectives (e.g., RLP), leveraging richer verbal signals for both pretraining and post-training optimization.
- Dependencies/assumptions: Stable optimization; reward hacking mitigation; careful compute accounting.
Notes on feasibility across applications
- Performance generalization: Reported gains are on 7.5–12B models; extrapolation to much larger models is plausible but unproven and requires replication.
- Rubric fit: Miscalibrated rubrics (e.g., generic text critique applied to code) can reduce gains; domain-specific rubrics are important.
- Bias and fairness: Judge models can encode biases that propagate through annotations; routine bias audits are needed.
- Overheads: Prefixes increase sequence length; while overall FLOP efficiency improved in the paper’s setups, engineering must watch for throughput/latency effects in production.
- Data privacy: Proprietary corpora may require on-prem annotation and strict access controls.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update for improved training stability. Example: "AdamW optimizer"
- autoregressive LLM: A model that predicts each token conditioned on all previous tokens in a sequence. Example: "autoregressive LLM"
- Bradley-Terry model: A statistical model for estimating item scores from pairwise comparisons by modeling the probability that one item beats another. Example: "Bradley-Terry model"
- bucketing: Grouping continuous scores into discrete bins or categories for downstream use. Example: "manual bucketing"
- continued pretraining (CPT): Further pretraining of a model on targeted or domain-specific data after an initial general pretraining phase. Example: "Domain Specific Continued pretraining (CPT)."
- Decision Transformer: A sequence-modeling approach to reinforcement learning that conditions on desired return (reward) and predicts actions tokenwise. Example: "Decision Transformer"
- FLOPs: Floating-point operations; a compute metric used to account for training and inference costs. Example: "All FLOPs comparisons account for both training compute and the one-time annotation inference cost."
- gradient clipping: A technique to cap the magnitude of gradients to stabilize training and prevent exploding gradients. Example: "gradient clipping 1.0"
- ILF-style training: A training paradigm that learns from iterative language feedback (ILF), incorporating critiques into the learning process. Example: "ILF-style training"
- judge LLM: A LLM used to assess and score documents according to a rubric and produce critiques. Example: "A judge LLM scores each document along various rubric dimensions and produces a natural language critique."
- L-BFGS: A quasi-Newton optimization algorithm commonly used for parameter estimation in statistical models. Example: "using L-BFGS"
- Mamba-Transformer hybrid model: An architecture combining Mamba components with Transformer blocks for language modeling. Example: "a 12B-parameter Mamba-Transformer hybrid model"
- natural language critique: A short textual analysis describing the quality and shortcomings of a document. Example: "produces a natural language critique."
- next-token prediction (NTP) objective: The standard language modeling objective of predicting the next token given previous tokens. Example: "next-token prediction (NTP) objective"
- offline reward-conditioned reinforcement learning: Conditioning learning on reward signals using pre-collected data rather than online interactions. Example: "offline reward-conditioned reinforcement learning"
- pairwise annotation: A labeling process where items are compared in pairs to elicit preference judgments for scoring. Example: "we also consider a pairwise annotation procedure"
- policy optimization: Techniques for improving a policy (e.g., a LLM) through optimization guided by feedback or rewards. Example: "policy optimization"
- position bias: A bias introduced when item order influences preference judgments in comparative evaluations. Example: "position bias"
- prefill: The initial input tokens processed by a model during inference before generating outputs, counted in compute accounting. Example: "prefill"
- prefix-conditioning: Prepending a conditioning sequence (e.g., feedback) to inputs so the model conditions its predictions on that prefix. Example: "prefix-conditioning the data"
- reward-conditioned learning: Training where desired reward or quality signals are provided as conditioning inputs to guide generation. Example: "reward-conditioned learning"
- reward-token conditioning: Using discrete tokens that represent reward or quality levels to condition model behavior. Example: "reward-token conditioning"
- rubric: A predefined set of criteria or axes used to evaluate and score document quality. Example: "using a rubric to annotate data"
- scaling curves: Plots showing performance as a function of compute, data, or model size, used to study efficiency and scaling. Example: "bends scaling curves"
- sequence concatenation: Combining token sequences end-to-end into a single input for training or inference. Example: "sequence concatenation"
- supervised finetuning (SFT): Training a model on labeled instruction–response data to align behavior with desired outputs. Example: "Supervised finetuning (SFT)."
- system message: The special meta-instruction in chat-style training/inference that sets behavior or context for the conversation. Example: "in the system message."
- Templated Quality Tokens: Fixed textual labels (e.g., [low]…[high]) representing discrete quality levels used to condition training. Example: "Templated Quality Tokens."
- thinking reward model: A model that evaluates and provides feedback on reasoning or “thinking” quality for training data. Example: "thinking reward model"
- token prefix: A short sequence of tokens prepended to the input to condition the model’s behavior. Example: "token prefix"
- tokenizer: The component that converts text into tokens according to a vocabulary and encoding scheme. Example: "Nanov2 tokenizer"
- token-level filtering: Selecting or discarding individual tokens (not just documents) based on quality or utility criteria. Example: "token-level filtering"
- upsampling: Increasing the sampling frequency of certain data (e.g., domain data) during training to emphasize it. Example: "late-stage upsampling of domain data"
- warmup-stable-decay (WSD) learning rate schedule: A schedule that warms up the learning rate, holds it stable, then decays it. Example: "a warmup-stable-decay (WSD) learning rate schedule"
- zero-shot setting: Evaluating a model without task-specific finetuning or examples, relying only on general capabilities. Example: "We evaluate in a zero-shot setting"
Collections
Sign up for free to add this paper to one or more collections.