Reinforcement Learning on Pre-Training Data (2509.19249v1)
Abstract: The growing disparity between the exponential scaling of computational resources and the finite growth of high-quality text data now constrains conventional scaling approaches for LLMs. To address this challenge, we introduce Reinforcement Learning on Pre-Training data (RLPT), a new training-time scaling paradigm for optimizing LLMs. In contrast to prior approaches that scale training primarily through supervised learning, RLPT enables the policy to autonomously explore meaningful trajectories to learn from pre-training data and improve its capability through reinforcement learning (RL). While existing RL strategies such as reinforcement learning from human feedback (RLHF) and reinforcement learning with verifiable rewards (RLVR) rely on human annotation for reward construction, RLPT eliminates this dependency by deriving reward signals directly from pre-training data. Specifically, it adopts a next-segment reasoning objective, rewarding the policy for accurately predicting subsequent text segments conditioned on the preceding context. This formulation allows RL to be scaled on pre-training data, encouraging the exploration of richer trajectories across broader contexts and thereby fostering more generalizable reasoning skills. Extensive experiments on both general-domain and mathematical reasoning benchmarks across multiple models validate the effectiveness of RLPT. For example, when applied to Qwen3-4B-Base, RLPT yields absolute improvements of $3.0$, $5.1$, $8.1$, $6.0$, $6.6$, and $5.3$ on MMLU, MMLU-Pro, GPQA-Diamond, KOR-Bench, AIME24, and AIME25, respectively. The results further demonstrate favorable scaling behavior, suggesting strong potential for continued gains with more compute. In addition, RLPT provides a solid foundation, extending the reasoning boundaries of LLMs and enhancing RLVR performance.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to train LLMs called RLPT, which stands for Reinforcement Learning on Pre-Training data. The big idea is to help AI models learn to “think” better by practicing how to continue real text from the internet, like guessing the next sentence in a paragraph, and getting points when they do it well—without needing people to label or grade the data. This makes training smarter and more scalable.
What Are the Authors Trying to Achieve?
In simple terms, the authors want to:
- Teach AI models to develop stronger reasoning skills by learning from huge amounts of existing text, not just from small sets of human-graded examples.
- Remove the need for expensive human feedback during reinforcement learning by creating rewards directly from unlabeled text.
- Improve performance on tough tests—both general knowledge and math—while showing that this method keeps getting better as you use more compute and data.
How Does the Method Work?
Imagine training the AI like a game:
- The AI reads part of a paragraph.
- It tries to predict the next sentence (or fill in a missing section).
- A “judge” model checks if the AI’s prediction matches the real next part of the text in meaning.
- If it matches, the AI gets a point (a reward). If not, it gets zero.
- Over time, the AI learns strategies that earn more points, improving its reasoning.
Here are the two main tasks the AI practices:
Autoregressive Segment Reasoning (ASR)
Think of reading a book and guessing the next sentence. Given the earlier sentences, the model predicts the next sentence. If its guess matches the real sentence in meaning, it earns a reward. This is similar to how LLMs normally generate text—one piece after another.
Middle Segment Reasoning (MSR)
This is like a fill-in-the-blank puzzle. The model is shown text before and after a missing section and must fill in the middle part so it fits smoothly. This teaches the model to understand context on both sides, which helps with tasks like code completion and editing.
The “Judge” (Reward Model)
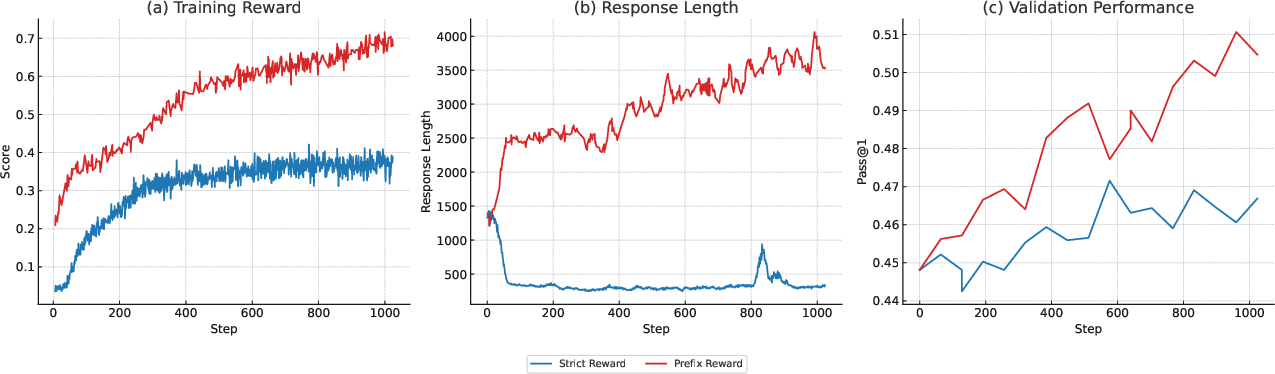
The reward model acts like a fair referee. It doesn’t require exact word matches. Instead, it checks if the predicted sentence means the same thing as the start of the real next text. This “prefix reward” is helpful because sometimes the next idea spans multiple sentences. Allowing meaningful matches, not just exact words, makes training more stable and effective.
Training Steps
- Cold start: Before playing the “guess the next sentence” game, the AI gets a short training to follow instructions properly.
- Segmenting text: Internet text (like Wikipedia and papers) is split into sentences. The model trains by predicting or filling in these segments.
- Reinforcement learning: The model generates several possible answers, the judge scores them, and the model updates itself to favor high-scoring answers.
- No human grading: Rewards come from the text itself, so this scales to very large datasets.
What Did They Find and Why Does It Matter?
The method improves the model’s performance across many areas:
- General knowledge tests: Scores went up on benchmarks like MMLU, MMLU-Pro, GPQA, and KOR-Bench. For example, with the Qwen3-4B model, RLPT increased accuracy by about 3–8 points on several tough tests.
- Math reasoning: The model got better at solving math problems, including competitive exams like AIME. It improved the chance of getting a problem right on the first try (Pass@1) and within a few tries (Pass@8).
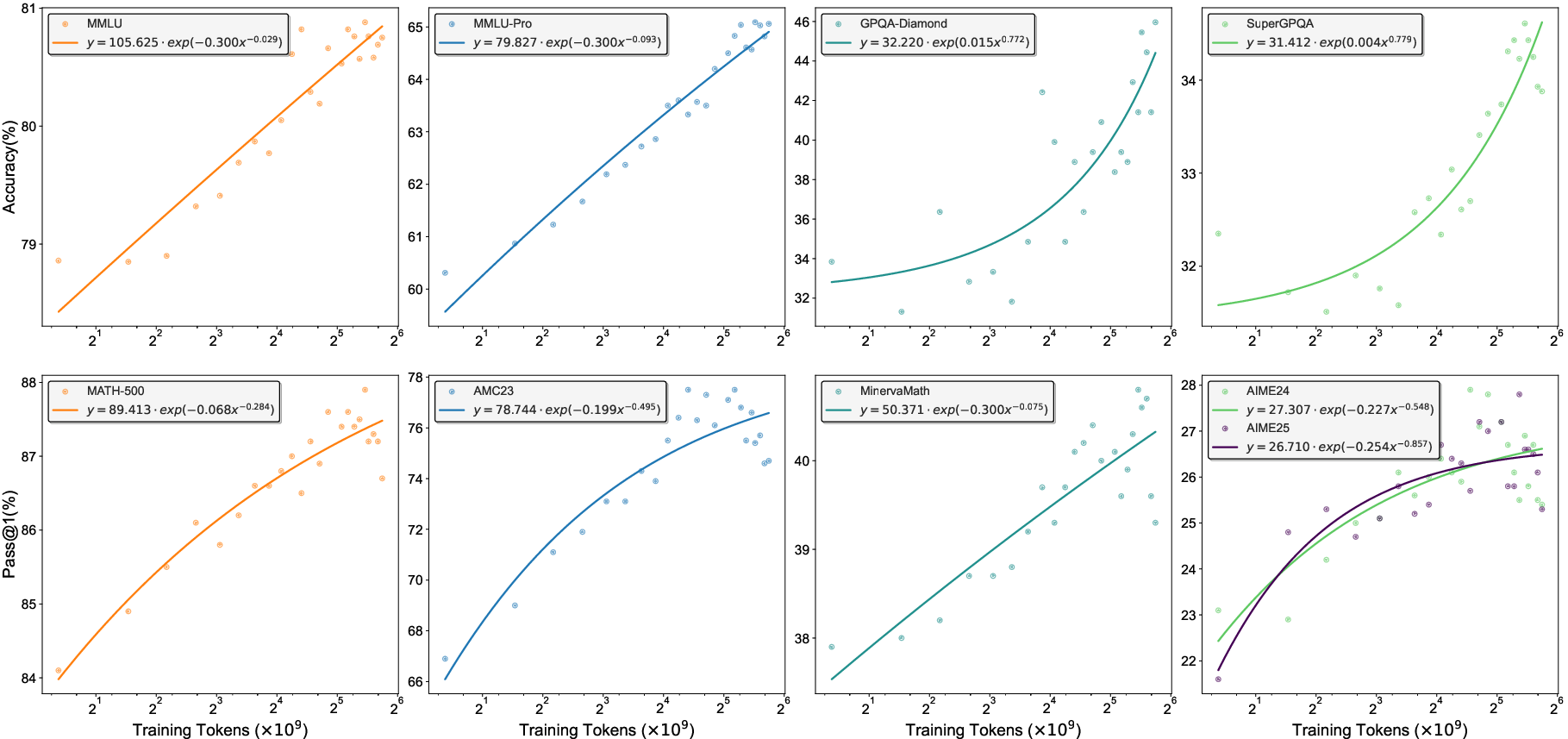
- Scaling behavior: As they trained on more tokens (more data and compute), performance kept improving in a steady trend. This suggests that RLPT has room to grow even further as training resources increase.
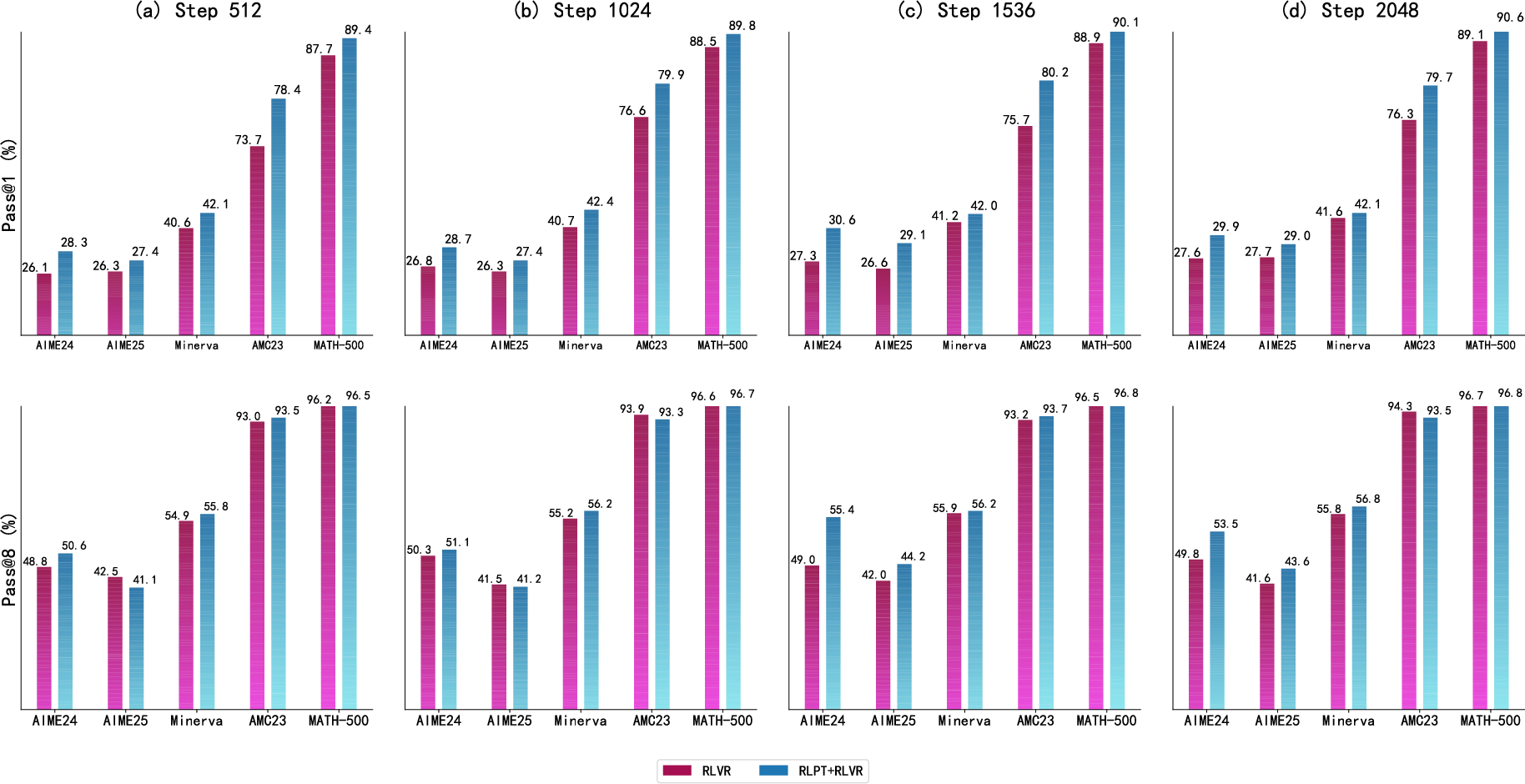
- Strong foundation: Models trained with RLPT serve as better starting points for other reinforcement learning methods (like RLVR), leading to extra gains in math reasoning.
This matters because it shows a practical path to making AI reason more reliably—without depending on lots of human-labeled data, which is expensive and limited.
Implications and Why This Is Important
- More scalable training: RLPT uses the massive text already available online, turning it into a teaching tool with automatic rewards. This reduces reliance on human feedback, making training cheaper and more scalable.
- Better reasoning, not just memorization: Instead of only copying patterns, the model learns to plan and check steps, like a student who writes out their thought process before giving the answer.
- Stronger foundations: RLPT makes models more general and helps other methods (like verifiable reward training) work better.
- Continual improvement with more compute: The results follow a clean “scaling law,” meaning performance should keep rising as you use more data and training time.
Key Takeaway
RLPT is like training an AI to read and think ahead—predicting the next sentence or filling in missing steps—and rewarding it when its reasoning matches what comes next in real-world text. This simple idea, backed by a fair judge model and lots of unlabeled data, leads to stronger reasoning skills, better test scores, and a scalable path forward for improving AI—without needing armies of people to grade the work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow-up research.
- Reward-model reliability and calibration: No quantitative assessment (accuracy, precision/recall, calibration) of the generative reward model’s judgments of “semantic prefix equivalence,” nor analysis of its failure modes (e.g., paraphrase sensitivity, adversarial phrasing, domain/length bias).
- Binary reward design: The 0/1 prefix reward may be too coarse; the paper does not evaluate graded rewards, partial-credit schemes, or token-level shaping to reduce sparsity and improve credit assignment.
- Reward hacking risks: The prefix criterion could incentivize overly generic or hedged prefixes and “gaming” with verbose or template-like starts; no adversarial tests to detect or mitigate such behaviors.
- Impact of reward prompt design: No ablation on reward-prompt wording, the number of reference segments provided, or instruction strictness, and how these factors affect reward noise, accept/reject rates, and downstream gains.
- Provenance and training of the reward model: The architecture/size, training data, domain coverage, and biases of the generative reward model are unspecified, limiting reproducibility and interpretation of results.
- Segment granularity choice: Although sentence-level segmentation is adopted, there is no systematic exploration of alternative units (clauses, discourse units, paragraphs, code blocks, formal “steps”) or adaptive/hierarchical segmentation strategies.
- ASR vs MSR contributions: No ablation isolating the individual and joint effects of Autoregressive Segment Reasoning vs Middle Segment Reasoning; unclear when MSR helps (e.g., code, long-form) and how to set the mixing coefficient λ.
- Sensitivity to λ and sampling hyperparameters: No paper of how λ, temperature, top-p, number of on-policy samples per prompt, or max response length affect stability, reward rates, and task performance.
- Effect of KL regularization: GRPO is used without KL constraints; the paper does not analyze distributional drift, stability, or whether adding KL (or other proximity controls) would improve robustness.
- Credit assignment granularity: It is unclear whether the policy update assigns credit only to the extracted prediction span or to the full generated trajectory; no token-level credit analysis or variance reduction techniques reported.
- Training stability and variance: No multi-seed runs, confidence intervals, or training variance analyses; lacks diagnostics on reward variance, collapse, or oscillations.
- Compute and efficiency trade-offs: No accounting of end-to-end compute (policy rollouts × reward-model inference) vs SFT baselines; unclear cost-performance efficiency and scalability to frontier models.
- Scaling-law specification: The “power-law” behavior is asserted but not quantified (fit parameters, exponents, goodness-of-fit, breakpoints), nor compared against SFT-only scaling on the same data/compute.
- Cold-start dependence: The necessity, size, and composition of the instruction SFT “cold-start” stage are not ablated; unclear how minimal instruction-following suffices and whether better cold-start data reduces RLPT cost.
- Data filtering and contamination auditing: Although decontamination is performed, no leakage audits, quantitative contamination rates, or sensitivity to imperfect decontamination are reported—especially critical for AIME/GPQA.
- Domain and language coverage: Experiments focus on English general/maths tasks; no evaluation on multilingual corpora, domain specialization (e.g., biomed, law), or code-specific datasets despite MSR’s claimed relevance to code.
- Long-context generalization: Training response length (8192) is shorter than evaluation length (32768); no analysis of context-length scaling, truncation effects, or retrieval/recency biases.
- Comparison to stronger baselines: Missing head-to-head comparisons with (i) continued SFT on the same data, (ii) self-training/bootstrapping (e.g., STaR/Quiet-STaR), (iii) RPT/Reinforcement Pre-Training, and (iv) test-time scaling alone under matched compute.
- Synergy vs redundancy with RLVR/RLHF: While RLPT improves RLVR, no comparison against SFT+RLVR and no analysis of when RLPT adds unique value beyond data curation or stronger verifiable-reward curricula.
- Generalization claims: The paper cites RL’s superior generalization over SFT but does not directly test out-of-distribution robustness, transfer to novel domains, or resistance to spurious correlations.
- Safety, alignment, and honesty: No human evaluations of helpfulness/harmlessness or tests for factuality/faithfulness drift when optimizing prefix-style rewards; unclear impact on safety-related behaviors.
- Output verbosity and style drift: Prefix rewards may encourage longer or formulaic reasoning; no measurement of verbosity inflation, repetition, or style homogenization across tasks.
- Error propagation across segments: The approach treats segments locally; no paper of compounding errors across multi-segment reasoning chains or techniques for cross-segment consistency rewards.
- Effect on few-shot or tool-use settings: No evaluation of RLPT in few-shot prompting, tool-augmented reasoning, or program-of-thought settings where segment prediction may interact differently with external tools.
- Robustness to noisy web data: Despite filtering, no robustness analysis to residual noise, contradictions, and low-quality segments; unclear whether RL magnifies spurious patterns.
- Human-grounded validation of “reasoning”: The qualitative “thinking pattern” example is anecdotal; no blinded human studies verifying actual improvement in intermediate reasoning quality vs superficial structure.
- Metric limitations: Heavy reliance on MMLU/GPQA/AIME (each with known caveats); no statistical significance testing or error analysis to reveal what capabilities improved vs remained unchanged.
- Reproducibility details: Precise data sources/sizes, filtering thresholds, segmentation rules, compute budgets, and reward-model checkpoints are not fully specified or released, limiting independent replication.
- Applicability beyond text: Open question whether RLPT extends to multimodal pretraining (text–image/audio/video) and how next-segment reasoning maps to cross-modal alignments.
- Theoretical grounding: No formal analysis explaining why optimizing self-supervised segment-level rewards via RL should confer stronger generalization than SFT or under what conditions it will fail.
- Curriculum and scheduling: Unexplored whether curriculum learning (e.g., increasing segment difficulty, progressively longer contexts) improves stability and gains over flat interleaving of ASR/MSR.
- Partial-credit for near-miss predictions: Open question whether semantic distance metrics (e.g., BERTScore, BLEURT, NLI entailment) or learned preference models could provide smoother rewards and faster learning.
- Evaluation of exploration: Claims about exploration are inferred from Pass@k; no direct measures of diversity/entropy, novelty of trajectories, or collapse avoidance under on-policy sampling.
- Downstream deployment impacts: No paper of inference-time cost (e.g., longer reasoning chains), latency, or energy usage trade-offs induced by RLPT-trained policies in production systems.
Practical Applications
Practical Applications Derived from “Reinforcement Learning on Pre-Training Data (RLPT)”
Below are concrete, real-world applications that follow from the paper’s findings, methods (ASR/MSR next-segment reasoning), and innovations in reward modeling (generative, prefix-based reward). Applications are grouped by deployability timeline and mapped to sectors. Each item notes potential tools/workflows and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Industry (Enterprise AI, Product Teams)
- Domain adaptation without labels
- What: Fine-tune base LLMs on in-house, unlabeled text (e.g., contracts, research memos, support tickets) using RLPT’s ASR/MSR to improve domain reasoning, coherence, and long-context utilization.
- Sectors: Legal, finance, healthcare, customer service, manufacturing.
- Tools/workflows: Cold-start SFT on internal instructions → sentence segmentation (NLTK or equivalent) → ASR/MSR prompts → generative reward model with prefix matching → on-policy GRPO training.
- Assumptions/dependencies: Sufficient de-identified, rights-cleared corpora; compute to sample multiple outputs per prompt; robust PII masking/contamination checks; lightweight instruction-following base model.
- Smaller, more capable on-prem/edge models
- What: Deploy improved 3B–8B models that, after RLPT, close part of the gap to larger models on reasoning-heavy tasks at lower inference cost.
- Sectors: Software, telco, embedded/edge, regulated industries with on-prem requirements.
- Tools/workflows: Qwen/Llama base → RLPT curriculum → quantization/distillation for deployment.
- Assumptions/dependencies: Adequate local compute for RLPT; long-context configuration during training and inference.
- RLVR booster for STEM and QA pipelines
- What: Use RLPT models as an initialization for RLVR to reduce reward hacking and improve sample efficiency and final Pass@k in math and verifiable QA workflows.
- Sectors: Edtech, scientific publishing, technical support, search/QA products.
- Tools/workflows: RLPT pre-stage → RLVR with verifiable rewards → sampling orchestration (n=64+) → Math-Verify or task-specific verifiers.
- Assumptions/dependencies: Verifiers for target domains; ability to handle longer responses encouraged by prefix-reward design.
- Software and Developer Tools
- Code span completion and refactoring via MSR
- What: Improve IDE copilots for missing-span inference, diff repair, and multi-file edits by training with masked middle segment reasoning on code repositories and code reviews.
- Sectors: Software engineering, DevOps, security.
- Tools/workflows: Code-specific segmentation (functions/blocks) → MSR prompts → prefix-based generative reward referencing several subsequent code spans → IDE integration.
- Assumptions/dependencies: High-quality, license-compliant code corpora; code-aware segmentation; careful reward prompts to avoid syntactic false positives.
- Long-form drafting and document continuation via ASR
- What: Increase coherence and topical persistence for product docs, support knowledge bases, and RFP/contract drafting using ASR-trained continuation.
- Sectors: Enterprise knowledge management, technical writing, legal ops.
- Tools/workflows: Document segmentation → ASR prompts → enterprise drafting assistants with stepwise reasoning traces.
- Assumptions/dependencies: Clean, deduplicated corpora; content governance and style constraints reflected in prompts.
- Education and Training
- Math and science tutoring with better stepwise reasoning
- What: Improve solution quality, self-checking, and alternative-path exploration in tutoring systems by exploiting RLPT’s structured reasoning trajectories.
- Sectors: Edtech, online learning platforms.
- Tools/workflows: RLPT-tuned base → verifier-backed hints (optional RLVR) → multi-attempt sampling with budget control.
- Assumptions/dependencies: Safe scaffolding and guardrails; verifiable problem banks; alignment to curricula.
- Healthcare and Life Sciences
- Literature-grounded drafting and summarization
- What: Use RLPT-trained models to produce more faithful, stepwise, and context-aware summarizations of de-identified clinical notes or research abstracts.
- Sectors: Clinical documentation, pharmacovigilance, research synthesis.
- Tools/workflows: Preprocessing pipeline (PII masking; contamination checks) → ASR/MSR on domain corpora → audit trails of reasoning chains for review.
- Assumptions/dependencies: Strict privacy/compliance pipelines; domain-specific evaluation harnesses; human-in-the-loop review.
- Finance and Legal
- Multi-step reasoning for analyses and memos
- What: Better argument structure and consistency for research notes, risk summaries, and memos by training on firm-specific, unlabeled archives.
- Sectors: Asset management, banking, legal practice, compliance.
- Tools/workflows: RLPT over rights-cleared archives → retrieval-augmented drafting with ASR-guided continuation.
- Assumptions/dependencies: Strong data governance; segmentation tuned to document styles (clauses, sections).
- Policy and Governance
- Data governance blueprints for self-supervised RL at scale
- What: Immediate adoption of PII masking, deduplication, and contamination removal pipelines from the paper as baseline policy for organizations training LLMs on internal data.
- Sectors: Government, public research labs, regulated industries.
- Tools/workflows: MinHash dedup, PII detection/masking, eval-set contamination checks; audit documentation of reward prompts and sampling budgets.
- Assumptions/dependencies: Tooling maturity; compliance teams; dataset licenses.
- Academia and Research Labs
- Reproducible training-time scaling studies
- What: Use RLPT as a testbed to paper compute–performance scaling laws, reward shaping (strict vs prefix), and segmentation granularity.
- Sectors: NLP/ML research, foundations of reasoning.
- Tools/workflows: Open models (Llama/Qwen) → RLPT trainer with GRPO → ablations on λ (ASR/MSR mix), segment units, on/off-policy variants.
- Assumptions/dependencies: Access to compute; benchmark hygiene; standardized logging of trajectories.
- Daily Life (Consumer Apps)
- More consistent assistants for long emails, reports, and planning
- What: Deploy RLPT-enhanced assistants that maintain topic coherence and exhibit better self-checking (verifying flow, exploring alternatives).
- Sectors: Productivity apps, personal knowledge management.
- Tools/workflows: ASR continuation and self-verification prompts; configurable sampling for quality vs latency.
- Assumptions/dependencies: Latency budgets; content safety filters; privacy settings for user data.
Long-Term Applications
- Industry and Foundation-Model Providers
- Segment-level RL as a mainstream pretraining stage
- What: Incorporate RLPT into the core pretraining curriculum at scale to move beyond token-level NTP toward trajectory-aware learning that generalizes better.
- Sectors: Frontier labs, cloud providers, model vendors.
- Tools/products: “RLPT Trainer” as a scalable library; on-policy sampling infrastructure; reward-model evaluation suites; cost-aware decoding strategies.
- Assumptions/dependencies: Large-scale compute; infrastructure for multi-sample generation; stability of on-policy RL with long contexts; mitigation of reward hacking.
- Retrieval-augmented RLPT
- What: Couple ASR/MSR with retrieval to condition next-segment reasoning on curated context, improving factuality and domain grounding.
- Sectors: Enterprise search/QA, scientific assistants.
- Tools/workflows: RAG index → RLPT prompts include retrieved chunks → reward evaluates semantic prefix against multi-segment references.
- Assumptions/dependencies: High-recall retrieval; careful negative sampling to avoid spurious rewards.
- Multimodal and Agentic Systems
- Multimodal next-segment RL
- What: Extend to code+text, text+image, or video “next-scene” prediction using segment-level rewards (e.g., semantic alignment between predicted and reference clips/captions).
- Sectors: Robotics, autonomous systems, creative media, video understanding.
- Tools/workflows: Segmenters for multimodal streams; generative reward models per modality; unified GRPO training.
- Assumptions/dependencies: Reliable multimodal reward modeling; segmentation that respects temporal coherence; large, licensed datasets.
- Tool-using agents with improved planning
- What: Use RLPT-trained policies as the backbone of planning agents; next-segment reasoning encourages stepwise plan synthesis and self-verification before acting.
- Sectors: Operations automation, IT ops, data engineering, scientific workflow orchestration.
- Tools/workflows: Agent frameworks with scratchpad; ASR/MSR reasoning traces; verifiable subgoals (RLVR) for critical steps.
- Assumptions/dependencies: Robust tool simulators/verifiers; safety constraints; interpretability of reasoning traces.
- Privacy-Preserving and Federated Training
- Federated RLPT for continual on-device learning
- What: Adapt models to user distributions via segment-level RL with differential privacy and on-device reward inference.
- Sectors: Mobile assistants, enterprise endpoints.
- Tools/workflows: Federated orchestration; compressed sampling; private aggregation of reward statistics.
- Assumptions/dependencies: Efficient on-device sampling; DP accounting; battery/latency constraints.
- Low-Resource and Multilingual
- Instructionless adaptation to new languages/domains
- What: Use unlabeled web or document corpora to grow capability in low-resource languages without expensive annotation.
- Sectors: Global public sector, NGOs, localization.
- Tools/workflows: Language-specific segmentation/tokenization; multilingual generative reward models; contamination checks across languages.
- Assumptions/dependencies: Sufficient raw text; multilingual RM quality; culturally aware PII masking.
- Safety, Evaluation, and Standards
- Reward transparency and auditing standards
- What: Establish documentation norms for generative reward prompts, prefix-vs-strict criteria, and on-policy sampling budgets to enable audits and reproducibility.
- Sectors: Policy bodies, standards organizations, regulators.
- Tools/workflows: Reward report cards; standardized logs of reward/rationale; open benchmark suites for next-segment evaluation.
- Assumptions/dependencies: Community consensus; regulator engagement; tooling for logging and redaction.
- Robustness and generalization testing
- What: Build new benchmarks to detect overfitting vs genuine generalization in segment-level RL, including adversarial segmentation and spurious feature controls.
- Sectors: Academia, third-party evaluators.
- Tools/workflows: Controlled corpora with varied segment entropy; sensitivity tests to prompt formatting; OOD generalization batteries.
- Assumptions/dependencies: Shared datasets; carefully designed ablations; cross-lab replication.
- Efficiency and Algorithmic Innovations
- Off-policy and KL-regularized RLPT
- What: Reduce sampling cost and stabilize training with off-policy corrections, KL control, or value baselines tailored to segment rewards.
- Sectors: All compute-constrained model developers.
- Tools/workflows: Replay buffers for ASR/MSR; variance-reduction critics; partial decoding for multi-sample efficiency.
- Assumptions/dependencies: Reliable off-policy estimators; careful bias–variance trade-offs.
- Products and Ecosystem Tools That Could Emerge
- Generative Reward Studio
- What: A managed service for designing, validating, and monitoring generative prefix-based reward models and prompts, with drift alerts.
- Dependencies: High-quality reference segmentation; evaluation datasets per domain.
- Segmentizer SDK
- What: Pluggable segmentation libraries (sentence, clause, “atomic step” extraction) with metrics for informativeness and balance.
- Dependencies: Domain heuristics; LLM-assisted segmentation research.
- RLPT Orchestrator
- What: End-to-end pipeline that handles cold-start SFT, ASR/MSR sampling, reward inference, GRPO training, and evaluation dashboards.
- Dependencies: Cluster scheduling; data governance modules; cost monitoring.
Notes on cross-cutting assumptions and risks
- Data quality and rights: Success depends on large, rights-cleared corpora; rigorous PII masking and eval-set contamination removal are essential for both effectiveness and compliance.
- Compute and sampling: RLPT relies on multi-sample generation (e.g., 8–64 samples per prompt) and long context windows; budgets and infrastructure must match target scale.
- Reward model fidelity: Generative, prefix-based rewards reduce brittleness but must be validated to avoid false positives/negatives and reward hacking.
- Cold-start requirement: Models need minimal instruction-following ability before RLPT; a brief SFT phase is assumed.
- Safety and alignment: Segment-level RL can lengthen outputs and surface richer reasoning; safety filters and post-hoc moderation should track these changes.
- Transferability: Gains shown on Qwen/Llama families likely transfer, but segmentation granularity and domain specifics may require tuning.
Glossary
- AIME: A competitive mathematics benchmark (American Invitational Mathematics Examination) used to evaluate reasoning performance. "AIME24 and AIME25"
- AMC: The American Mathematics Competitions, used as a benchmark for mathematical reasoning. "AMC23"
- annealing dataset: A curated dataset of high-quality question-answer pairs used to enhance mathematical reasoning. "we curated high-quality QA data from the annealing dataset"
- Autoregressive Segment Reasoning (ASR): An RLPT task where the model predicts the next sentence given the preceding context. "which we term the Autoregressive Segment Reasoning (ASR) task."
- cold-start: An initial supervised fine-tuning phase to endow the model with instruction-following ability before RLPT. "we introduce a cold-start phase consisting of supervised fine-tuning on instruction-following data."
- contamination removal: The process of removing overlaps between training data and evaluation/dev sets to avoid leakage. "contamination removal with respect to all development and evaluation sets."
- cosine scheduler: A learning rate scheduling strategy that follows a cosine decay pattern during training. "a learning rate of with a cosine scheduler"
- Generative reward model (G_rm): A model that evaluates semantic equivalence between predicted and reference segments to produce rewards. "evaluated by a generative reward model ."
- GPQA-Diamond: A challenging subset of the GPQA benchmark targeting graduate-level, Google-proof questions. "GPQA-Diamond"
- GRPO: A policy gradient algorithm (Group Relative Policy Optimization) used for on-policy RL in LLMs. "on-policy GRPO \citep{shao2024deepseekmath} without KL regularization."
- instruction-tuned LLM: A model fine-tuned to follow natural language instructions, often used for quality assessment or prompting. "employs an instruction-tuned LLM"
- KL regularization: A regularization technique penalizing divergence from a reference policy during RL optimization. "without KL regularization."
- KOR-Bench: A benchmark for knowledge-orthogonal reasoning tasks that stress reasoning independent of memorized facts. "KOR-Bench"
- masked LLMing: A training objective where models infer masked tokens/spans using surrounding context. "This resembles masked LLMing"
- Math-Verify: An automated tool for checking the correctness of mathematical solutions. "Correctness in mathematical reasoning is evaluated using Math-Verify"
- Middle Segment Reasoning (MSR): An RLPT task where the model predicts a masked middle span using both preceding and following context. "which we designate as the Middle Segment Reasoning (MSR) task."
- Minerva: A benchmark suite focused on quantitative and mathematical reasoning. "Minerva"
- MinHash-based near-deduplication: A scalable technique for removing near-duplicate texts using MinHash signatures. "MinHash-based near-deduplication"
- MMLU: A widely used benchmark for Massive Multitask Language Understanding across diverse academic subjects. "MMLU"
- MMLU-Pro: A more robust and challenging variant of MMLU for multitask language understanding. "MMLU-Pro"
- NLTK toolkit: A natural language processing library used here for sentence segmentation. "we use the NLTK toolkit"
- Next-segment reasoning: The RLPT objective that rewards predicting the next coherent text segment based on context. "we propose a novel next-segment reasoning objective"
- Next-token prediction (NTP): The standard autoregressive training objective for LLMs to predict the next token. "Next-token prediction (NTP) is the fundamental training objective of modern LLMs."
- OlympiadBench: A benchmark of olympiad-level problems testing advanced reasoning capabilities. "OlympiadBench"
- on-policy: An RL training regime that samples trajectories from the current policy being optimized. "on-policy GRPO"
- Pass@k: A metric measuring the probability that at least one correct solution appears among k sampled attempts. "using the Pass@ metric"
- policy distribution: The probability distribution over outputs/actions induced by the current model policy. "maintains proximity to the original policy distribution"
- policy gradient: A family of RL methods that optimize expected reward via gradients of the policy. "policy gradient algorithms such as PPO \citep{schulman2017proximal} and GRPO \citep{shao2024deepseekmath}."
- PPO: Proximal Policy Optimization, a widely used stable policy gradient algorithm. "policy gradient algorithms such as PPO \citep{schulman2017proximal} and GRPO \citep{shao2024deepseekmath}."
- prefix reward: A relaxed reward that grants credit when the prediction is a valid semantic prefix of the reference. "we introduce a relaxed prefix reward"
- reinforcement learning from human feedback (RLHF): An RL paradigm where rewards come from a learned preference model trained on human annotations. "reinforcement learning from human feedback (RLHF)"
- reinforcement learning with verifiable rewards (RLVR): An RL approach that uses programmatic checks against reference answers to provide rewards. "reinforcement learning with verifiable rewards (RLVR)"
- scaling law: An empirical relationship describing how model performance scales with compute or data. "Scaling law of RLPT\ performance on various benchmarks with respect to training tokens."
- semantic consistency: The criterion that the predicted segment must convey the same meaning as the reference for reward assignment. "The reward is defined as the semantic consistency between the predicted and reference segments"
- SuperGPQA: A large-scale extension of GPQA covering hundreds of graduate disciplines. "SuperGPQA"
- supervised fine-tuning (SFT): Post-training via labeled data to refine behavior; often contrasted with RL for generalization. "supervised fine-tuning (SFT) under the NTP paradigm"
- temperature (sampling): A decoding parameter that controls randomness when sampling model outputs. "temperature $0.6$"
- test-time scaling: Increasing inference compute (e.g., longer reasoning) to improve accuracy at prediction time. "test-time scaling allocates more compute during inference"
- top-p: Nucleus sampling that restricts sampling to the smallest set of tokens whose cumulative probability exceeds p. "top- $0.95$"
- training-time scaling: Increasing compute during training (e.g., larger models/data or RL) to improve general capabilities. "Training-time scaling primarily relies on next-token prediction"
Collections
Sign up for free to add this paper to one or more collections.

