Language Models Can Learn from Verbal Feedback Without Scalar Rewards
Abstract: LLMs are often trained with RL from human or AI feedback, yet such methods typically compress nuanced feedback into scalar rewards, discarding much of their richness and inducing scale imbalance. We propose treating verbal feedback as a conditioning signal. Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP). FCP learns directly from response-feedback pairs, approximating the feedback-conditional posterior through maximum likelihood training on offline data. We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself. This reframes feedback-driven learning as conditional generation rather than reward optimization, offering a more expressive way for LLMs to directly learn from verbal feedback. Our code is available at https://github.com/sail-sg/feedback-conditional-policy.
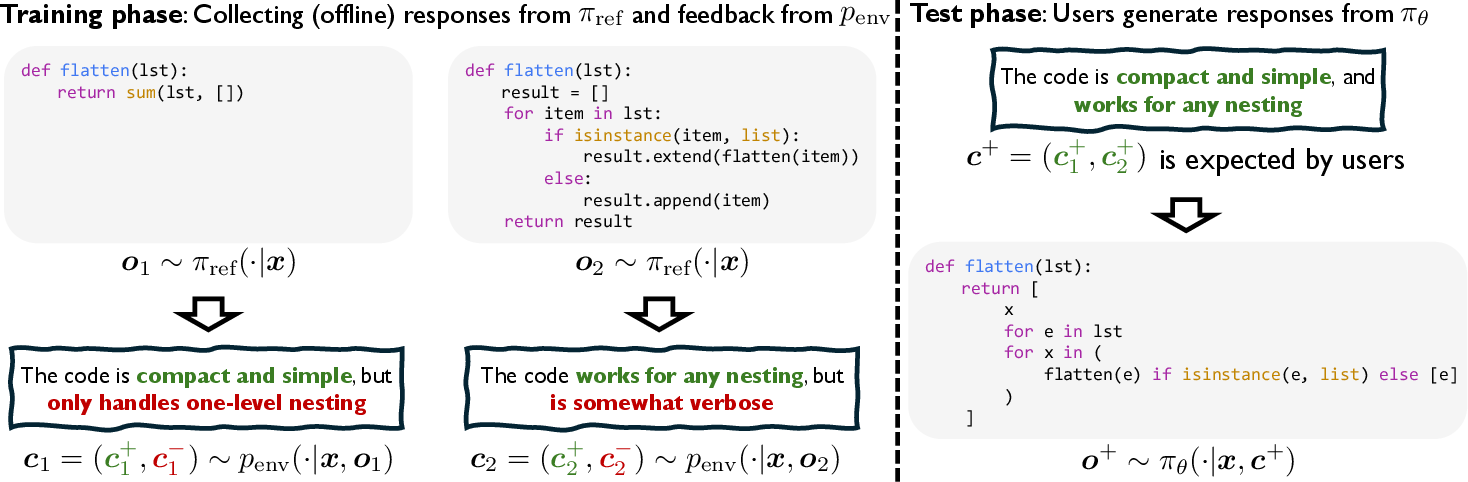

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: Can we teach AI LLMs using plain words (like “Nice job, but be more concise”) instead of turning those words into a single number score (like 0.8 out of 1)? The authors say yes. They introduce a new way to train models called a “feedback‑conditional policy” (FCP), which treats verbal feedback as a direct instruction for how the model should respond, rather than squeezing it into a reward number.
What are the main goals or questions?
The paper focuses on three easy‑to‑grasp goals:
- Use real, detailed feedback (the kind a person might write) to teach a model, without converting it into one scalar reward number.
- Let the model learn how to respond differently depending on the kind of feedback it’s given (for example, “be correct and clear” versus “has code and is concise”).
- Show that this approach can work as well as, or better than, popular methods that rely on numeric rewards.
How does their method work?
Think of it like a student learning to write essays:
- Traditional grading gives a single score (e.g., 85/100). That’s simple, but it throws away useful details.
- Real comments, like “Your idea is great, but your paragraphs are too long,” contain richer guidance.
The authors build a system that learns from those richer comments in two stages:
Offline stage: Learn from past pairs of responses and feedback
- The model (the “reference policy”) writes responses to lots of questions or tasks.
- An “environment” (could be a person or another model) gives verbal feedback on those responses.
- The new model, FCP, is trained on the pairs: instruction + response + feedback.
- The key idea: treat the feedback itself as a condition. In everyday terms, the model learns “If the feedback says ‘correct and clear,’ what kind of response would produce that feedback?” It’s like learning the inverse relationship between responses and the comments they get.
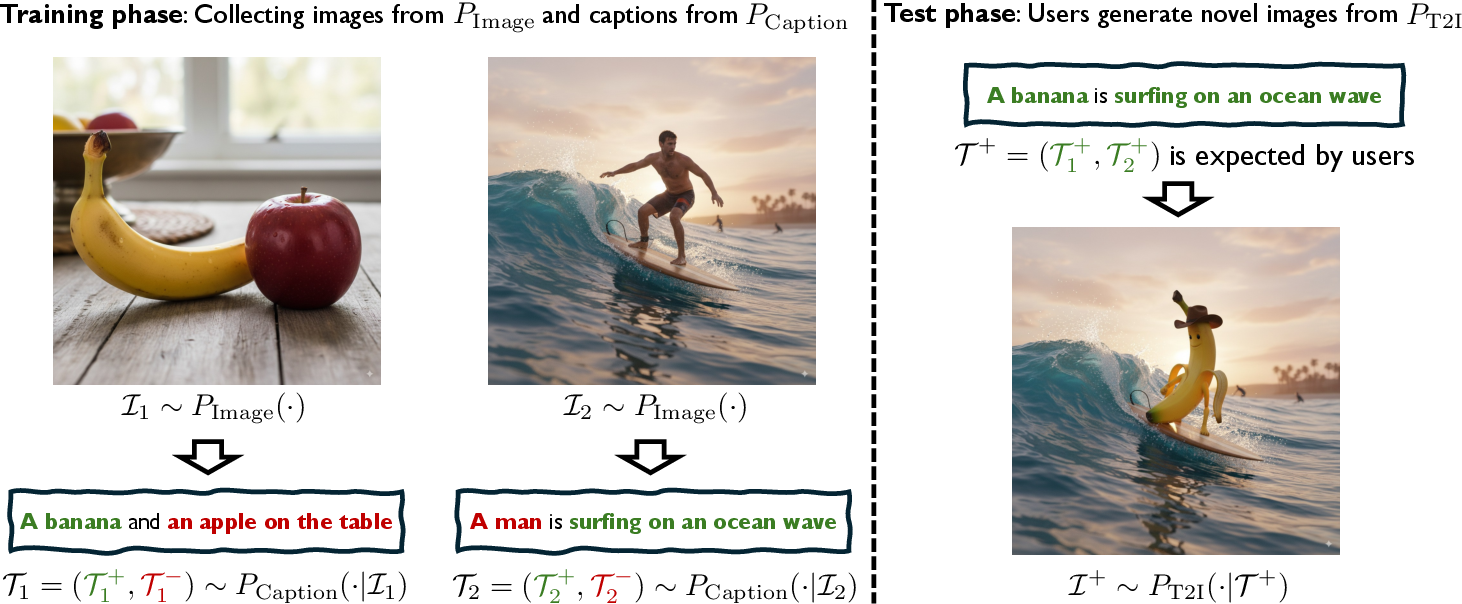
Analogy: In text‑to‑image tools, you can combine ideas from different captions (“a banana” + “surfing on the ocean”) to make a new image (“a banana surfing on the ocean”). Similarly, FCP uses mixed, varied feedback to assemble better responses that fit the desired feedback style.
Online stage: Bootstrap with “positive feedback” goals
- After the offline training, the model tries generating new responses while aiming for a chosen “positive” feedback condition (like “correct, efficient, and concise”).
- It then receives fresh feedback on these new attempts.
- The model updates itself using this new feedback, getting better over time at producing responses that match the chosen positive condition.
In short: instead of chasing higher reward numbers, the model learns how to produce answers that would draw the kind of feedback you want.
What did they find, and why does it matter?
Here are the main results and why they’re important:
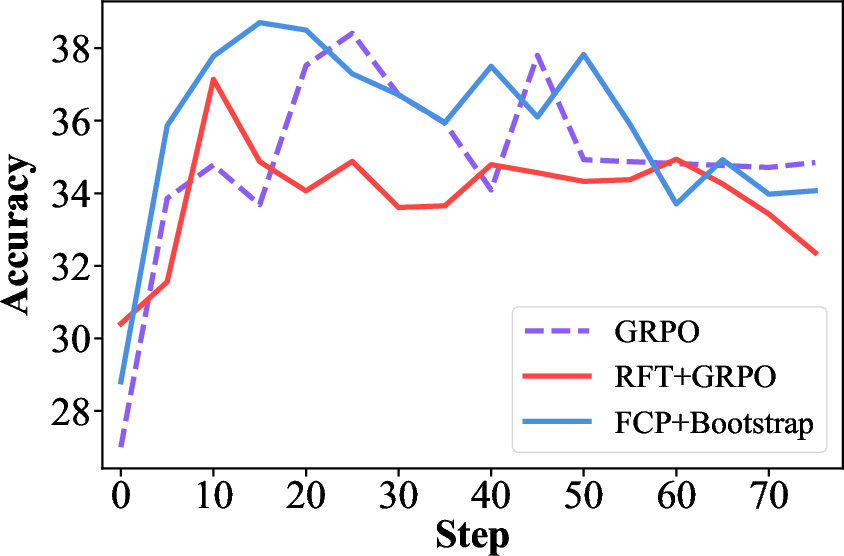
- FCP is competitive with strong baselines that use numeric rewards. On math and general reasoning tests, the FCP method (with the online bootstrapping step) matched or slightly beat top reward‑based methods like GRPO and RFT+GRPO.
- It works without special “verifiers.” Many reward‑based methods depend on reliable automatic graders or strict rules. FCP learns directly from feedback text, so it can be used in messy, real‑world tasks where grading isn’t clear.
- It preserves rich feedback. Instead of compressing mixed comments (“correct but too wordy”) into a single score, FCP uses the full detail to shape the model’s behavior.
- It supports controllable behavior. If you tell the model to aim for feedback like “has code and is concise,” it shifts its style accordingly. This shows it truly understands the feedback condition.
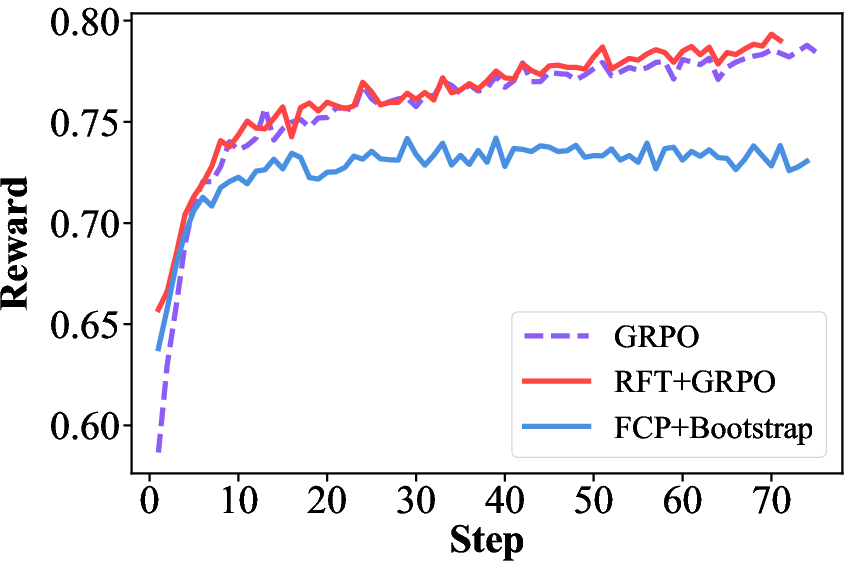
- It seems less prone to “reward hacking.” Reward‑based methods can over‑optimize for the number a scorer likes, sometimes at the cost of actual usefulness. FCP reaches high accuracy without chasing the reward model’s favorite patterns.
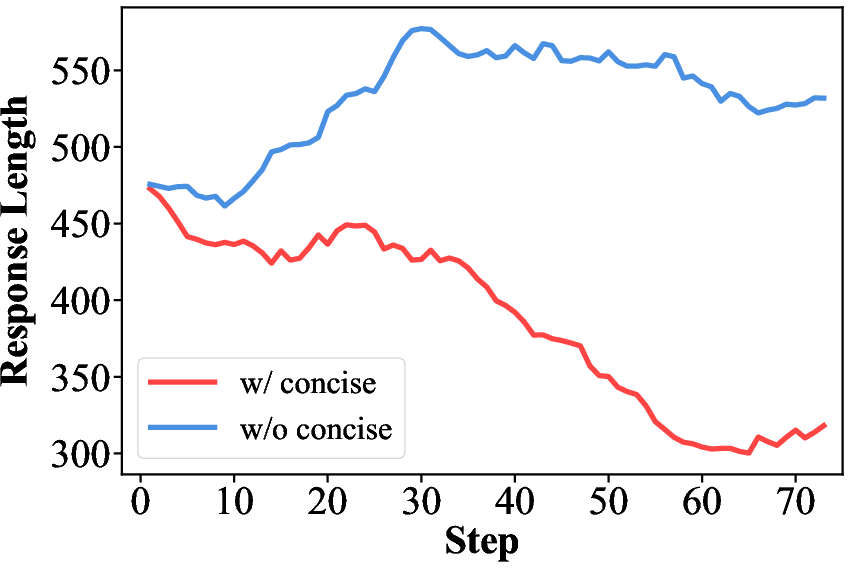
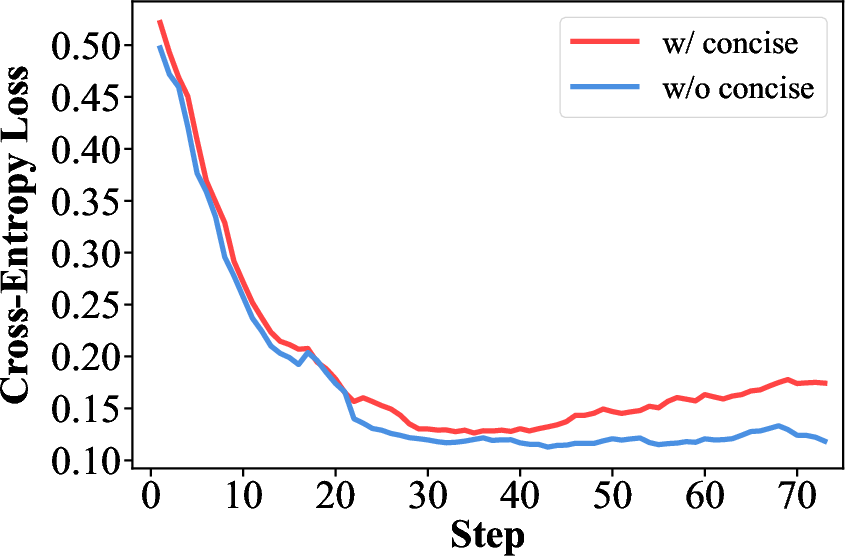
A caution they discovered: feedback conditions about length (like “be concise”) can make the model’s answers get shorter and shorter over time, which hurt math reasoning. Filtering out length‑related goals made training more stable.
What’s the bigger impact?
This work suggests a shift in how we train LLMs:
- We don’t always need to force feedback into numbers. Treating verbal feedback as a first‑class training signal can make models learn more naturally.
- It could reduce the need for expensive, carefully designed scoring systems and allow training from everyday user comments.
- It opens the door to personalization: at test time, you could set the feedback condition to match your preferences (“explain step‑by‑step,” “use code,” “keep it simple”), and the model adapts.
- Future ideas include combining verbal feedback with verifiable rewards when available, learning from multi‑turn conversations, adapting to a user’s style from a few examples, and even using multimodal feedback (like images or audio).
Bottom line: Instead of training models to chase a number, we can train them to listen to our words—and that might make them both smarter and more aligned with what we actually want.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- Human feedback realism and variance: All feedback is simulated by an LLM (“GPT-5-nano”); no experiments with real human feedback, inter-annotator disagreement, or heterogeneous user styles, leaving real-world robustness untested.
- Generalization to unseen or compositional feedback conditions: The model is conditioned on a pool of “positive” feedback seen during training. It is unclear how well FCP adheres to novel, compositional, or out-of-distribution conditions at test time.
- How to choose the conditioning “goal” at inference: There is no principled method to select or compose the expected positive feedback c+ per task/domain; sensitivity to the phrasing, specificity, and granularity of c+ is unquantified.
- Residual reliance on scalar signals: The construction of the “positive feedback” pool uses scalar scores, partially undermining the “no scalar rewards” claim; scalar-free ways to identify or generate positive conditions are not provided.
- Robustness to noisy, contradictory, deceptive, or adversarial feedback: The method assumes “non-deceptive” feedback. Failure modes and defenses under malicious or systematically biased feedback are not studied.
- Support coverage and off-policy limits: Offline MLE only learns on the support of the reference policy. How to mitigate missing modes (e.g., rare high-quality responses) and support mismatch (importance weighting, exploration, conservative objectives) is left open.
- Theoretical guarantees and identifiability: There are no convergence, consistency, or error-bound guarantees when optimizing forward KL to an intractable posterior with unknown and misspecified p_env; the causal implications of conditioning on a post-hoc signal (feedback) are not analyzed.
- Token-level guidance vs sequence-level conditioning: Since p_env is defined after full responses, decoding is only guided via prepended feedback text. Whether more granular token-level credit assignment (e.g., latent alignment, token-level critics) improves learning remains open.
- Multi-turn feedback and credit assignment: The framework is single-turn; extending to multi-turn, iterative critiques with memory and inter-turn credit assignment is only suggested as future work, with no algorithmic or empirical validation.
- Hybridization with verifiable rewards: Although proposed in discussion, there are no experiments assessing how to combine verifiable signals with verbal conditioning (e.g., weighting schemes, curriculum, or switching policies).
- Style-content disentanglement: Results suggest conditioning can sway style (e.g., “has_code”) at the expense of accuracy. Methods to disentangle stylistic preferences from correctness to avoid “style over substance” are missing.
- Safety and misuse: Conditioning on harmful or negative feedback can drive unsafe or low-quality behavior (demonstrated by “fully_negative” conditions). Guardrails, constraints, and safe conditioning policies are not developed.
- Stability under condition selection: Length-related conditions destabilize training (collapse to shorter outputs). There is no general method to detect and mitigate destabilizing conditions (e.g., condition classifiers, regularization, constraint-based objectives).
- Scaling behavior: Only Qwen2.5-7B is evaluated. Scaling laws w.r.t. model size, data volume, feedback quality/quantity, and compute are not characterized.
- Breadth of baselines: Comparisons omit strong scalar-free or preference-learning baselines (e.g., DPO/IPO, KTO, RLAIF with generative preference models, pairwise/ranking methods), limiting the scope of empirical claims.
- Domain coverage: Evaluations are on math and general reasoning; no tests on coding, tool use, agentic tasks, or multi-modal settings where verbal tool feedback is most relevant.
- Condition adherence metrics: Aside from a small probe, there is no systematic measurement of how faithfully outputs satisfy specified conditions (e.g., adherence precision/recall, calibration of control strength).
- Reward hacking claims: The paper infers less reward hacking because scalar reward scores lag while accuracy is high, but does not include adversarial or off-distribution reward-model tests to substantiate robustness to reward gaming.
- Distribution shift in online bootstrapping: The environment (feedback generator) is fixed and synthetic. How FCP behaves when feedback style drifts (new users, tools, domains) is untested.
- Self-reinforcement and forgetting: Online bootstrapping samples from the current policy without off-policy correction or replay; risks of compounding bias, mode collapse, or forgetting are not quantified; no ablation on replay/regularization.
- Data selection bias: Offline data discards prompts where all responses are correct/incorrect, potentially biasing training; the impact of this filtering on generalization has not been analyzed.
- Sensitivity to prompting and architecture choices: Only simple concatenation with <EF> tokens is tested; effects of feedback placement, adapters, conditioning layers, or other architectures on control and stability are unexplored.
- Inference UX and latency: Conditioning requires users (or systems) to craft c+; the usability burden, default templates, and latency overhead are not assessed.
- Decoding strategy effects: All inference uses greedy decoding; the impact of sampling/temperature, beam search, or guidance methods on condition adherence and accuracy is unknown.
- Data efficiency and cost: Claims of simplicity and data efficiency are not supported by ablations across feedback/data budgets or cost analyses (LLM feedback generation vs scalar pipelines).
- Combining positive and negative feedback: While negative conditioning is shown to degrade performance when requested, principled ways to leverage negative feedback for improved learning (e.g., contrastive or adversarial training) are not explored.
- Alternatives to forward KL: The choice of forward KL (mode-covering) is not compared to reverse KL or other f-divergences/contrastive objectives; importance weighting or variational estimators for p_env are not examined.
- External, independent evaluation: Apart from accuracy benchmarks, there is no human evaluation or independent preference model to validate perceived quality gains and condition satisfaction beyond the training-time feedback style.
Practical Applications
Overview
This paper introduces Feedback-Conditional Policy (FCP), a training paradigm that treats verbal feedback as a conditioning signal rather than compressing it into scalar rewards. FCP is trained offline on response–feedback pairs via maximum likelihood and then bootstrapped online by generating under positive conditions and collecting fresh feedback. Empirically, FCP matches or surpasses scalar-reward baselines (RFT, GRPO) on math and general reasoning tasks, while preserving the richness of feedback and reducing reward-hacking risk.
Below are practical applications derived from the paper’s findings, organized as Immediate and Long-Term. Each item highlights concrete use cases, relevant sectors, enabling tools/workflows, and assumptions/dependencies affecting feasibility.
Immediate Applications
These applications can be deployed now with current LLMs and standard training infrastructure, leveraging response–feedback datasets (human or model-generated) and the FCP training loop.
- Feedback-driven customer support assistants that learn from user critiques
- Sector: software, retail/e-commerce, telecom
- Use cases: Chatbots that adapt to mixed user feedback (“too long,” “not sure,” “try a shorter answer”) without reward engineering; support agents tuned to sentiment and style.
- Tools/workflows: FCP fine-tuning pipeline; feedback collection UI; feedback wrapper tokens (e.g., <EF>…</EF>); bootstrapping loop that samples “positive” feedback conditions; A/B testing on contact-center metrics.
- Assumptions/dependencies: Availability of non-deceptive textual feedback; privacy safeguards; stable reference model with strong language priors.
- Developer copilot and code-review assistants conditioned on textual reviews
- Sector: software/DevTools
- Use cases: Code assistants that adjust to reviewers’ written comments (e.g., “prefer functional style,” “optimize complexity,” “avoid global state”) and produce responses likely to elicit positive reviews.
- Tools/workflows: IDE extension capturing PR comments; feedback-pool builder; offline dataset generation from existing repos/issues; online bootstrapping on internal code tasks.
- Assumptions/dependencies: Access to structured review text; internal policy around code privacy; careful handling of length-related conditions to avoid unstable brevity.
- Reasoning tutors and graders that learn from teacher comments without detailed rubrics
- Sector: education
- Use cases: Math and general reasoning tutors trained on teacher feedback (“rigorous logic,” “too verbose,” “steps unclear”); auto-grading systems that incorporate teacher comments rather than binary pass/fail.
- Tools/workflows: LMS integration to collect student-response + teacher-feedback pairs; FCP training with reviewer-style feedback; inference with preferred positive conditions (e.g., “clear reasoning, correct answer”).
- Assumptions/dependencies: Sufficient quantity/quality of teacher feedback; consent and data governance; avoidance of scalar-reward dependence when rubrics are unavailable.
- Editorial and marketing content generation tuned via free-form stakeholder feedback
- Sector: media/marketing
- Use cases: Copy, blog posts, and summaries that adapt to editorial notes (“more concise,” “more data-backed,” “tone: confident”); campaign assets conditioned on desired feedback (clarity, coherence, persuasion).
- Tools/workflows: Editorial feedback capture tool; condition library (fully_positive, neutral, style tags); FCP fine-tuning and online bootstrapping cycle.
- Assumptions/dependencies: Availability of consistent feedback; style taxonomies; safeguards against collapse from aggressive conciseness conditions.
- Enterprise knowledge-base Q&A systems incorporating employee critiques
- Sector: enterprise software, HR/IT
- Use cases: Internal assistants that improve based on mixed feedback (“partly correct but outdated,” “good start, but too technical”), reducing reliance on hard verifiers.
- Tools/workflows: Feedback ingestion from helpdesk and wiki comments; maximum likelihood offline training on response–feedback pairs; online bootstrapping targeting “clear, accurate, current” conditions.
- Assumptions/dependencies: Reliable feedback sources across departments; data hygiene; role-based access control.
- Agentic LLMs that leverage tool outputs as verbal feedback
- Sector: software/AI agents
- Use cases: Agents that integrate critiques from tools (linters, test runners, search results) expressed verbally (e.g., “unit tests failing in function X,” “retrieved doc contradicts answer”), improving conditional generation without reward hacking.
- Tools/workflows: Tool-critique adapters that convert logs/results into natural-language feedback; FCP training and bootstrapping conditioned on “passes tests, consistent with sources.”
- Assumptions/dependencies: High-quality tool-to-feedback translation; stable reference policies; careful handling of ambiguous or mixed tool feedback.
- Compliance and documentation assistants that respond to reviewer-style feedback
- Sector: finance, healthcare, legal
- Use cases: Drafts adjusted to compliance comments (e.g., “missing disclosure,” “unclear rationale”), improving alignment with policy constraints without handcrafted reward functions.
- Tools/workflows: Reviewer feedback templates; feedback pools for “complete, compliant, transparent”; FCP inference with target positive feedback conditions.
- Assumptions/dependencies: Domain-expert feedback availability; regulatory constraints on data use; audit trails for updates.
- Evaluation teams adopting richer feedback signals to reduce reward hacking
- Sector: AI governance, ML operations
- Use cases: Model training/evaluation workflows replacing scalar-only scoring with verbal critiques, mitigating reward gaming and preserving nuanced preferences.
- Tools/workflows: Unified feedback prompt template; side-by-side comparison dashboards (accuracy vs. reward scores); bootstrapping schedule tuned to avoid over-optimization of scalar signals.
- Assumptions/dependencies: Organizational buy-in to move beyond scalar metrics; calibration practices for feedback quality; monitoring of length/verbosity dynamics.
- Personal digital assistants learning from everyday user comments
- Sector: consumer software
- Use cases: Assistants that quickly adapt to preferences (“short summaries,” “more examples,” “avoid jargon”) via verbal conditioning rather than parameterized settings only.
- Tools/workflows: In-app feedback capture; light-weight offline FCP fine-tuning; on-device or privacy-preserving bootstrapping.
- Assumptions/dependencies: Consent and privacy; sufficient interactions per user; careful guardrails to avoid amplifying negative conditions.
Long-Term Applications
These rely on further research, scaling, or development—e.g., multi-turn integration, personalization, multimodal feedback, standardized practices, and sector-specific validation.
- Multi-turn feedback integration for iterative guidance
- Sector: software, education, healthcare
- Description: Extend FCP to incorporate feedback at each turn (teacher-forcing style), enabling richer iterative instruction and correction.
- Potential products: “Multi-Turn FCP Trainer” with conversation-level datasets; adaptive tutoring agents; clinical documentation assistants that refine notes through clinician rounds.
- Dependencies: Datasets with turn-level critiques; sequence-level stability; safety review for sensitive domains.
- Hybrid verifiable + verbal feedback training
- Sector: software engineering, math/science reasoning
- Description: Combine verifiable signals (tests, proofs) with the “null feedback” condition to complement verbal critiques where available, improving robustness.
- Potential products: “Verifier-Aware FCP SDK”; pipelines that treat missing feedback as neutral and plug in verifiable rewards where applicable.
- Dependencies: Reliable verifiers; routing between verifiable and verbal pathways; calibration to avoid domain imbalance.
- Personalization via few-shot feedback conditioning
- Sector: consumer apps, enterprise tools
- Description: Test-time adaptation using a small set of user feedback exemplars, yielding fast alignment to style and preferences.
- Potential products: “Feedback Persona Cards”; per-user condition libraries; cross-session memory integration.
- Dependencies: On-device storage or privacy-preserving personalization; handling preference drift; opt-in frameworks.
- Multimodal feedback conditioning (text, audio, images, UI signals)
- Sector: robotics, accessibility, design tools
- Description: Fuse non-text feedback (e.g., gestures, audio comments, marked-up documents) into the condition to guide generation across modalities.
- Potential products: “Multimodal Feedback Encoder”; design co-pilots that learn from annotated mockups; robots that adapt to operator utterances and demonstrations.
- Dependencies: Multimodal models; robust alignment across modalities; domain-specific safety validations.
- Standardized feedback taxonomies and collection protocols
- Sector: AI governance, enterprise ML
- Description: Establish shared schemas (e.g., clarity, correctness, coherence, conciseness, compliance) for feedback capture, improving model conditioning and comparability.
- Potential products: “Feedback Schema Registry”; SDKs for CRM/LMS/IDE integration; analytics for feedback quality and coverage.
- Dependencies: Cross-organizational consensus; training data pipelines; UX that elicits useful critiques without high burden.
- Sector-specific validated FCP deployments (healthcare, finance, legal)
- Sector: healthcare, finance, legal
- Description: Rigorous pilots where FCP is tuned with domain-expert feedback, measuring error reduction and compliance improvements while avoiding reward hacking.
- Potential products: Clinical note assistants; regulatory report generators; case summarizers conditioned on reviewer feedback.
- Dependencies: Expert-labeled datasets; auditability; bias/fairness assessments; regulatory approvals.
- Agentic systems robust to deceptive or mixed feedback
- Sector: autonomous agents, search/retrieval systems
- Description: Research on detecting and mitigating deceptive/low-quality feedback, learning robust conditioning from noisy tool outputs and human critiques.
- Potential products: “Feedback Robustifier” (quality filters, uncertainty models); trust-aware bootstrapping schedulers; safety monitors for agent loops.
- Dependencies: Feedback quality estimation; adversarial testing; organizational safety policies.
- Curriculum design for feedback conditioning and stability
- Sector: ML research, MLOps
- Description: Study curriculum schedules (e.g., avoid early over-emphasis on conciseness) to prevent length collapse and stabilize bootstrapping.
- Potential products: “Condition Curriculum Planner”; length/verbosity controllers; training diagnostics that track accuracy vs. scalar scores vs. response length.
- Dependencies: Longitudinal experimentation; task-dependent heuristics; deployment monitoring.
- Benchmarks and metrics beyond scalar rewards
- Sector: ML research, standardization bodies
- Description: New evaluation sets capturing nuanced verbal feedback efficacy (e.g., accuracy under different conditions, controllability, robustness to mixed feedback).
- Potential products: “Feedback-Conditioned Reasoning Benchmarks”; multi-dimensional metrics dashboards; shared leaderboards.
- Dependencies: Community adoption; data curation; reproducible FCP baselines.
- Privacy-preserving, on-device FCP
- Sector: consumer devices, enterprise privacy
- Description: Localized training from user feedback, enabling personalization without transferring raw critiques off-device.
- Potential products: Edge FCP runtimes; federated bootstrapping; secure condition libraries.
- Dependencies: Efficient fine-tuning (LoRA/PEFT), device compute; federated learning infrastructure; robust consent mechanisms.
- Marketplace and tooling for feedback-as-a-signal
- Sector: developer platforms, marketplaces
- Description: Ecosystem around collecting, sharing, and leveraging feedback conditions (e.g., style packs, reviewer presets) for domain-specific models.
- Potential products: “Condition Store” (e.g., compliance, editorial, tutoring styles); feedback aggregation services; API for feedback-conditioned inference.
- Dependencies: IP/licensing norms; quality control; interoperability across model providers.
Cross-cutting assumptions and dependencies
- Non-deceptive, sufficiently informative feedback: FCP depends on feedback that reflects actual quality or preferences; low-quality conditions degrade training.
- Strong language priors: Base models must already interpret and compose feedback; larger, instruction-tuned LLMs help.
- Data pipelines: Need robust collection of response–feedback pairs; attention to privacy, consent, and governance.
- Stability under condition choice: Length-related conditions can destabilize bootstrapping (e.g., pushing excessive conciseness); curriculum and filtering may be required.
- Reference policy and inference controllability: FCP relies on a reference model and user-specified “positive” conditions at inference; tooling should expose condition selection safely.
- Domain validation: Safety-critical domains (healthcare, finance, legal) require rigorous evaluation, auditing, and regulatory compliance.
- Avoiding scalar over-optimization: Benefits include reduced reward hacking, but organizations must adopt richer evaluation practices to replace scalar-only metrics.
Glossary
- Advantage estimation: Computing advantage values to guide policy updates in reinforcement learning. "GRPO instead uses group-normalized scalar rewards to estimate advantages and has become one of the strongest online methods, especially in math reasoning where answers can usually be verified automatically."
- Behavior cloning: Supervised learning that imitates expert or reference behavior by directly learning from demonstrations. "We observe that our FCP learning in Eq.~(\ref{eq2}) aligns with modeling inverse dynamics~\citep{brandfonbrener2023inverse}, complementing supervised finetuning (SFT) as behavior cloning, and critique finetuning (CFT)~\citep{wang2025critique} as forward dynamics."
- Behavior policy: The policy used to generate data (rollouts) during training. "Concretely, we conduct online training by sampling rollouts from the behavior policy (goal-conditioned on positive feedback), and re-annotating them with fresh feedback to refine itself."
- Bootstrapping (online): Iteratively improving a model by generating data with its current parameters and retraining on newly obtained feedback. "We further develop an online bootstrapping stage where the policy generates under positive conditions and receives fresh feedback to refine itself."
- Critique Finetuning (CFT): Finetuning a model using detailed critiques of its outputs to improve reasoning quality. "CFT can perform well with high-quality and detailed critiques~\citep{wang2025critique}, but applying it to the same coarse and lightweight feedback used for FCP leads to severe degradation—worse than the base model (Table~\ref{tab:main_result_math})."
- Feedback-conditional policy (FCP): A policy that conditions generation on verbal feedback signals rather than scalar rewards. "Inspired by language priors in text-to-image generation, which enable novel outputs from unseen prompts, we introduce the feedback-conditional policy (FCP)."
- Feedback-conditional posterior: The distribution over responses given both the instruction and observed feedback. "In the offline setting, where responses are collected from , we define the joint distribution of response-feedback pairs as , from which we derive the feedback-conditional posterior distribution:"
- Forward dynamics: Modeling how actions/responses lead to outcomes or feedback, complementing inverse dynamics. "We observe that our FCP learning in Eq.~(\ref{eq2}) aligns with modeling inverse dynamics~\citep{brandfonbrener2023inverse}, complementing supervised finetuning (SFT) as behavior cloning, and critique finetuning (CFT)~\citep{wang2025critique} as forward dynamics."
- Forward KL divergence: KL divergence computed as KL(P||Q), often used to match a target distribution with maximum likelihood. "To avoid intractability of computing in the reverse KL divergence, we instead propose to minimize the forward KL divergence between and ."
- Generative reward models: Models that produce verbalized critiques and/or scalar scores rather than binary correctness signals. "Such feedback may come from human users~\citep{stephan2024rlvf}, generative reward models~\citep{zhang2024generative,mahan2024generative}, or tool outputs in agentic scenarios~\citep{wang2025ragen,jin2025search}."
- GRPO: An online RL algorithm that uses group-normalized scalar rewards to stabilize training and estimate advantages. "GRPO instead uses group-normalized scalar rewards to estimate advantages and has become one of the strongest online methods, especially in math reasoning where answers can usually be verified automatically."
- Group-normalized rewards: Rewards normalized within groups to reduce scale imbalance and stabilize policy optimization. "GRPO instead uses group-normalized scalar rewards to estimate advantages and has become one of the strongest online methods, especially in math reasoning where answers can usually be verified automatically."
- Instruction-tuned model: A model finetuned on instruction-following datasets to better respond to user prompts. "The reference policy may represent a base model, an instruction-tuned model, or a reasoning model."
- Inverse dynamics: Learning to infer actions/responses from states and outcomes (feedback), the inverse of forward dynamics. "We observe that our FCP learning in Eq.~(\ref{eq2}) aligns with modeling inverse dynamics~\citep{brandfonbrener2023inverse}."
- KL-constrained reward maximization: An RL objective maximizing expected reward while regularizing deviation from a reference policy via KL. "Following \citet{rafailov2023direct}, we show that is the optimal solution to a KL-constrained reward maximization problem with reward function :"
- KL regularization: Penalizing divergence from a reference policy using KL to prevent overfitting or large policy shifts. "In the special case where the environment provides verifiable rewards... we can show that reduces to the optimal solution of a 0-1 binary reward maximization problem without KL regularization."
- Language priors: Pretrained linguistic knowledge that enables models to generalize and recombine conditions or prompts. "Our approach is inspired by language priors in text-to-image generation, where models compose unseen prompts from mixed captions (Figure~\ref{demo2})."
- Length bias: A training bias where longer or shorter sequences are favored due to aggregation in loss or reward. "In Algorithm~\ref{alg:online}, cross-entropy on self-sampled responses reduces to policy gradient with unit advantages, which suffers from length bias~\citep{liu2025understanding}."
- Maximum likelihood training: Optimizing parameters to maximize the likelihood of observed data under the model. "This objective in Eq.~(\ref{eq2}) reduces to maximum likelihood training, which is straightforward to implement and optimize with data collected from and ."
- Policy gradient: A class of RL methods that update policies via gradients of expected returns with respect to parameters. "In Algorithm~\ref{alg:online}, cross-entropy on self-sampled responses reduces to policy gradient with unit advantages."
- Reference policy: A fixed or pretrained policy used as a prior or baseline for training and regularization. "We begin with a reference policy model that takes an input instruction and generates a response ."
- Rejection Sampling Finetuning (RFT): Offline finetuning by filtering and training only on high-quality or correct samples. "RFT filters responses by correctness and finetunes only on the correct ones, which in the offline case reduces to training on a binary scalar score (correct/incorrect)."
- Reward hacking: Exploiting the reward model or metric to gain high scores without genuinely improving task performance. "This demonstrates a simple and scalable framework that preserves the richness of verbal feedback while avoiding the scarcity of rule-based verifiers and the risk of reward hacking."
- Reward hypothesis: The RL assumption that goals can be captured by maximizing expected cumulative scalar rewards. "“That all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward).”"
- Reverse KL divergence: KL divergence computed as KL(Q||P), often encouraging mode-seeking behavior in policy learning. "Note that the objective in Eq.~(\ref{eqRLKL}) is equivalent to minimizing the reverse KL divergence between and :"
- Scalarization: Converting rich feedback into single scalar reward values for RL, often causing information loss. "Scalarization has long been seen as unavoidable, bridging verbal feedback and the numerical signals required by RL."
- Verifiable rewards: Rewards that can be deterministically checked (e.g., correctness) rather than inferred or subjective. "In the special case where the environment provides verifiable rewards, that is, for correct responses and for incorrect responses ..."
- vLLM: An efficient LLM inference engine enabling fast decoding and serving at scale. "Inference uses vllm~\citep{kwon2023efficient} with greedy decoding and a maximum generation length of 8192 tokens."
Collections
Sign up for free to add this paper to one or more collections.