- The paper establishes a log-linear scaling relationship where pass@1 accuracy increases with the logarithm of generated reasoning tokens.
- The paper introduces randomized clipping and verification RL warmup to improve training dynamics and reduce false positives in code verification.
- It proposes a parallel thinking framework for multi-threaded, multi-round inference that scales token allocation dramatically, surpassing previous SOTA models.
Scaling Reasoning Tokens through Reinforcement Learning and Parallel Thinking for Competitive Programming
Introduction
This work rigorously investigates the scaling of reasoning token budgets in LLMs for competitive programming via two complementary methodologies: reinforcement learning (RL) at training and parallel thinking at test-time. Distinctive contributions include formal analyses of the empirical log-linear relationship between reasoning length and performance, the introduction of randomized clipping and verification RL warmup for improved training dynamics, and an end-to-end RL framework for multi-threaded, multi-round inference. Results are established on the AetherCode benchmark, leveraging Seed-OSS-36B as the backbone and comparing directly to GPT-5-high.
Empirical Scaling Law for RL Reasoning Tokens
A central result is the consistent observation of a log-linear scaling phenomenon: validation pass@1 accuracy increases approximately linearly with the logarithm of the average number of generated reasoning tokens across RL checkpoints, over various configurations. This trend emerges as a robust descriptive tool for both early diagnosis of RL recipe impact and for practical compute budgeting.
A notable mechanistic improvement is achieved through randomized clipping, which replaces the hard sequence length cutoff in the RL reward with a probabilistic alternative. This softens the reward boundary, imposes a smooth penalty on near-limit generations, and empirically steepens the log-linear accuracy scaling (Figure 1).
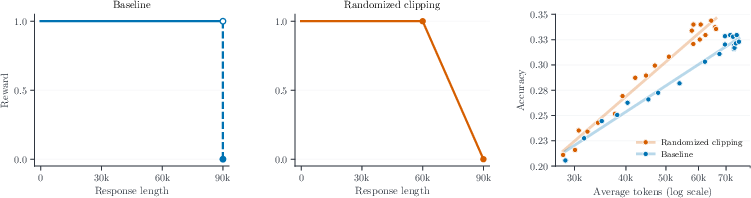
Figure 1: Randomized clipping replaces the hard reward cliff (left) with a smooth ramp (middle), producing a steeper log-linear scaling curve (right).
Additionally, verification RL warmup—pretraining the model as a verifier before generation RL—achieves a strong upward shift in the scaling curve. The warmup increases the starting accuracy and mitigates false positives in code verification, leading to improved transfer when initializing subsequent code generation RL (Figure 2).
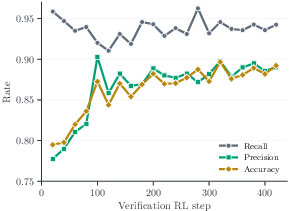
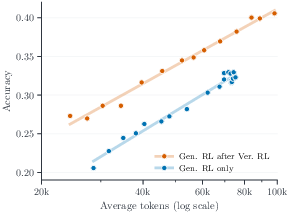
Figure 2: Verification RL warmup. Left: recall remains high while precision and accuracy improve during verification RL. Right: initializing generation RL from the verification checkpoint shifts the log-linear scaling curve upward.
The full RL pipeline—including cold start SFT, verification RL, and generation RL—is depicted in Figure 3.

Figure 3: Training pipeline: SFT cold start with generation and verification trajectories, followed by verification RL and generation RL.
The quadratic cost of long-context attention imposes a compute wall for continued RL-based sequence length scaling, motivating the necessity for more scalable test-time approaches.
Parallel Thinking: Test-Time Reasoning Budget Explosion
To circumvent the training-time compute wall, the authors design a test-time architecture dubbed parallel thinking, explicitly constructing a multi-threaded, multi-round pipeline composed of alternating solution generation, verification, and refinement.
Each thread generates candidate solutions, then verifies correctness via independent sampling (with a variable number of verdicts V). For solutions not unanimously verified as correct, a verify-refine loop ensues until termination or exhaustion of rounds. The final solution is chosen via verification vote counts, favoring early and highly-verified outputs (Figure 4).
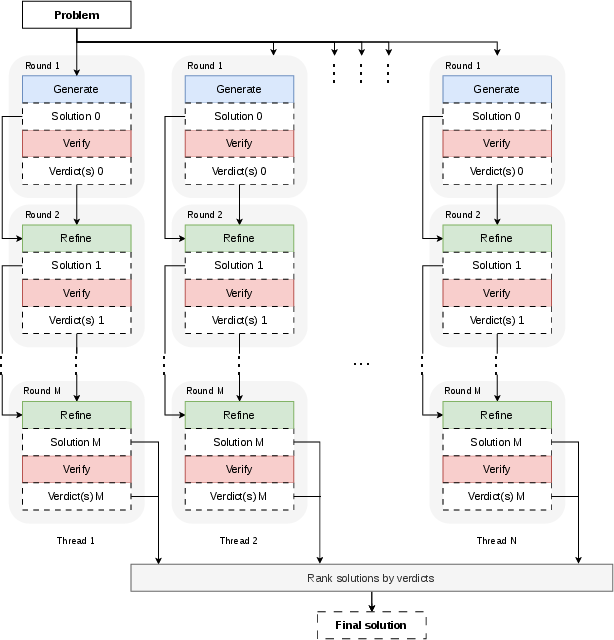
Figure 4: The parallel thinking inference pipeline.
This architecture allows for allocation of up to N×M generations per problem, scaling the total reasoning token budget by over an order of magnitude beyond RL training regimes. Empirically, sequential refinement (increasing rounds within threads) is more token-efficient than pure parallel generation, but their combination yields the highest accuracy as shown in unified scaling analyses (Figure 5).
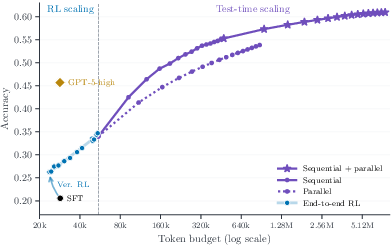
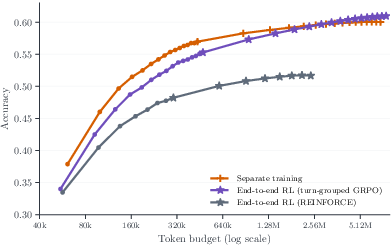
Figure 5: Left: Unified token budget axis spanning training-time RL scaling from 20K to 60K tokens and test-time parallel thinking to 7.6M tokens. Right: Effect of end-to-end RL on sequential-plus-parallel scaling.
End-to-End RL for Multi-Round Reasoning and Refinement
Conventional decoupled RL (separate generation, verification, refinement) produces a mismatch between training and inference contexts, hindering pipeline-wide coordination. This work advances the field by composing these components into a single training procedure, applying end-to-end RL on full multi-round, multi-role pipelines.
The RL objective is role-specific, with reward normalization stratified by context and stage (via turn-grouped GRPO) to avoid gradient signal distortion. This yields substantial improvements in long-horizon, high-token-budget regimes, as illustrated in scaling ablations.
Strong Empirical Results and Claims
- The unified parallel thinking framework (16 threads × 16 rounds, averaging 7.6M tokens per problem) matches the underlying RL model's oracle pass@16 at pass@1, demonstrating highly efficient compute scaling.
- The approach surpasses GPT-5-high on 456 hard AetherCode problems, achieving 0.61 pass@1 accuracy, exceeding the sequential-only plateau.
- Scaling via RL increases solution coverage, rather than merely shifting probability mass over the same solution modes. This contrasts with related findings in mathematical reasoning tasks, highlighting the unique challenge and opportunity inherent to execution-based code domains.
Implications and Future Directions
This work demonstrates that, for high-difficulty domains such as competitive programming, RL-induced reasoning scaling and sophisticated test-time token allocation are both necessary and complementary. The log-linear accuracy/token scaling enables resource-efficient hyperparameter search, while randomized clipping and verification RL warmup yield reproducible and interpretable improvements.
The parallel thinking pipeline sets a precedent for structured agentic inference, substantially mitigating attention bottlenecks and enabling practical deployment of multi-million-token computation, with immediate relevance for code LLMs in real-world settings.
Theoretically, the log-linear law provides a compact lens for future analysis of RL-induced reasoning in LLMs. Practically, the demonstrated superiority over GPT-5-high sets a new standard for LLM performance on execution-based benchmarks.
Future research should explore:
- Propagation of rewards across multi-role, multi-turn pipelines (credit assignment beyond bandit RL).
- Extension from linear verify-refine chains to tree search and evolutionary strategies.
- Multi-modal hybrid pipelines with external verification via unit tests, symbolic solvers, or human-in-the-loop judgements.
- Efficient attention mechanisms and scalable architectures to further ease the compute wall.
- Systematic investigation of transfer learning between verification and generation tasks.
Conclusion
This paper provides clear evidence that both RL-based reasoning length scaling and structured parallel test-time search are required for state-of-the-art performance in competitive programming benchmarks. The introduction of randomized clipping and verification RL warmup operationalizes improvements in the RL regime, while the parallel thinking pipeline, trained end-to-end, leverages multi-thread/multi-round reasoning to efficiently scale problem-solving accuracy far beyond previous SOTA code LLMs. By structurally aligning training and inference with the test-time objective, this framework produces scalable, robust advances in program synthesis and competitive code generation.