InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
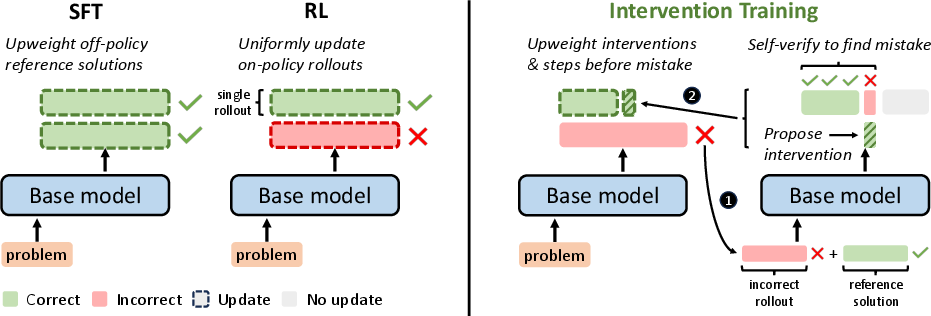
Abstract: Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of LLMs. However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Intervention Training: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning”
What is this paper about?
This paper is about teaching LLMs—like the ones that solve math problems—how to learn better from their mistakes. The authors introduce a simple way called “Intervention Training” (InT) that helps a model find the first wrong step in its own reasoning and suggest a small, targeted fix. Then they train the model on those fixes so it’s more likely to do the right thing next time.
What questions were the researchers asking?
- How can we stop a model from “blaming” or “rewarding” every step equally when only the final answer is judged right or wrong?
- Can a model, using a correct solution as a reference, find the first step where it went wrong and suggest one better step to get back on track?
- If we train the model on these small fixes, will it solve more tough problems and learn faster during reinforcement learning?
How did they do it? (In everyday language)
Think of a long math solution like a chain of steps. Traditional training with reinforcement learning (RL) often only rewards or punishes the final answer (right or wrong). That’s like a teacher marking the whole solution “X” if the final answer is wrong—even if most steps were right—and “✓” if the final answer is right—even if some steps were nonsense. This makes it hard for the model to know which step really mattered.
Here’s the new approach, with helpful analogies:
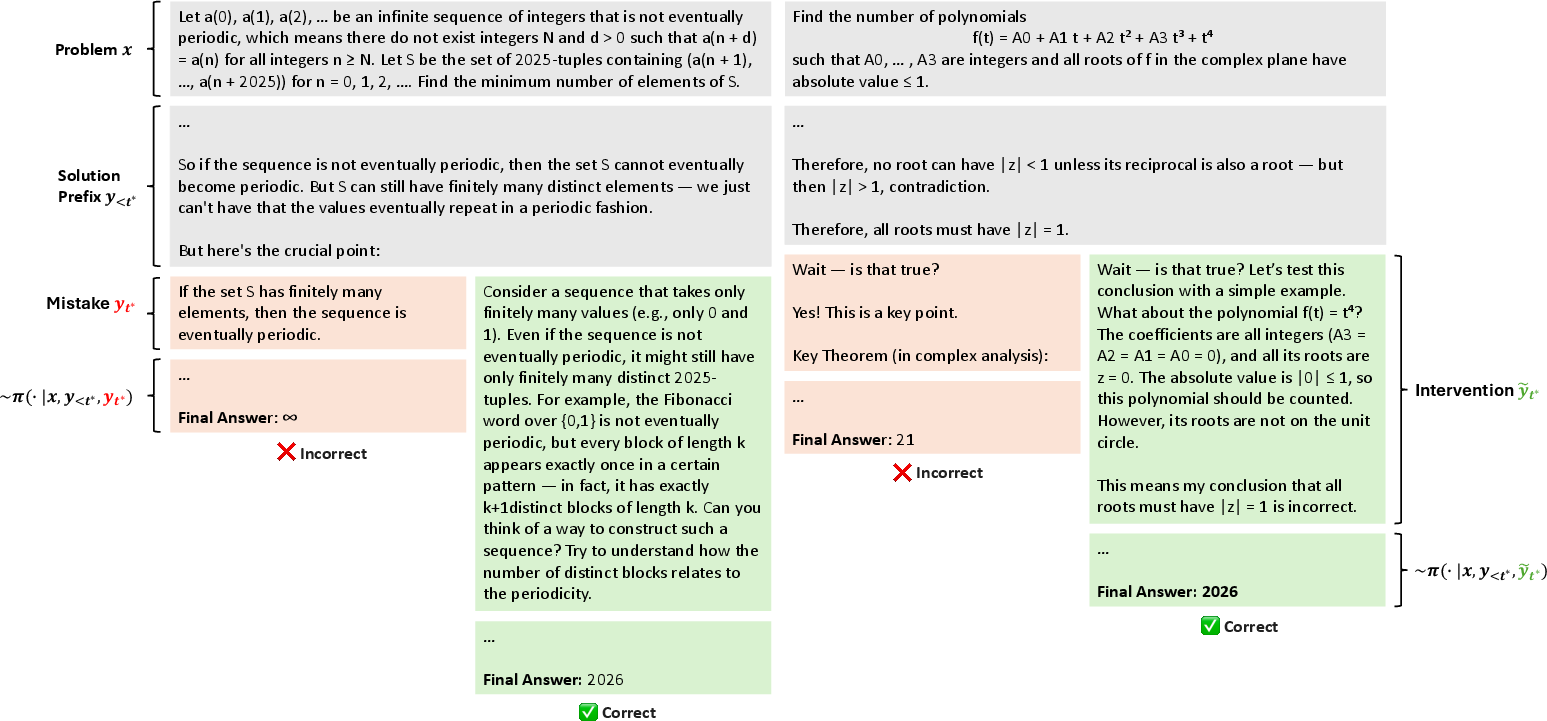
- Self-check with a “teacher copy”: The model compares its incorrect solution to a correct “reference solution” (like an answer key). It doesn’t try to solve the whole problem again; it just checks where its solution first diverges from the correct one—like doing a line-by-line “spot the difference.”
- Propose one small fix: Once it finds the first mistake, the model writes a single, corrected step (an “intervention”) to replace the wrong one—like a teacher writing a sticky note next to the exact line you need to fix.
- Test the fix: The model continues its solution from just before the mistake, but now using the corrected step. Often, this leads to a correct final answer.
- Train on fixes (not entire solutions): The model is then fine-tuned (supervised training) on the original correct prefix plus the one corrected step—but not the rest of the solution. This keeps the model flexible in how it finishes the problem later, especially during RL.
- Then do RL as usual: After this “patching,” they run normal RL. Now the model starts from a better place and learns more efficiently.
Key terms in simple words:
- Reinforcement learning (RL): Learning by trial and error with rewards for correct final answers.
- Credit assignment: Figuring out which exact step helped or hurt the final outcome.
- Intervention: A small, single-step correction inserted at the first mistake.
- Reference solution: A correct, human-written solution used as a guide for checking.
What did they find, and why is it important?
- Small fixes make a big difference: When the model continued a solution using the proposed intervention, success rates shot up by about 22× compared to continuing without a fix. It also solved many more unique problems it couldn’t solve before.
- Better than “hints” alone: Giving the model a hint (a partial correct solution prefix) helps, but the targeted intervention performed better on its own—and combining hints with interventions worked best.
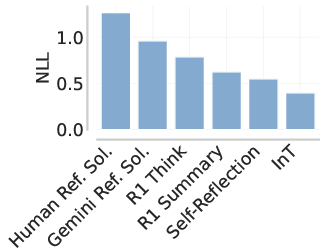
- Instruction following matters: Models tuned to follow instructions were better at generating clean, usable interventions than purely “reasoning” models.
- Bigger models propose better fixes: A larger model suggested even stronger interventions, boosting accuracy further.
- How you train on the fixes matters:
- Best setup: Train on the original correct prefix plus the one corrected step only (not the rest of the finished solution), and only keep fixes that led to at least one successful continuation.
- Including the whole finished solution actually hurt later exploration and performance.
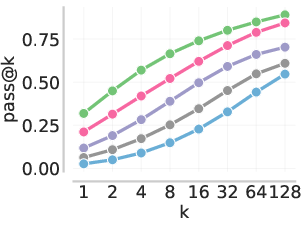
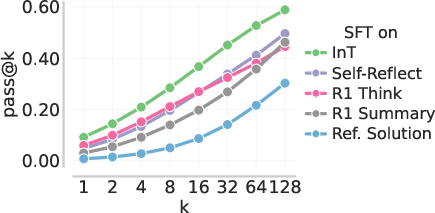
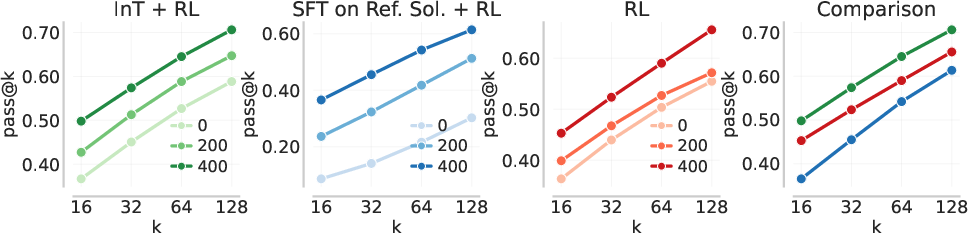
- Stronger starting point for RL: After fine-tuning on interventions, the model’s pass@k (the chance that at least one out of k attempts is correct) improved across many k values. Starting RL from this “patched” model led to big gains on hard math benchmarks.
- Real benchmark gains: On IMO-AnswerBench (International Math Olympiad–level problems), they improved accuracy by nearly 14% over the 4B base model and even beat some larger open-source models.
Why it matters: This approach figures out exactly where and how to fix mistakes, so the model learns the right lessons. It avoids more complicated, expensive methods that try to score every step (called process reward models), and it doesn’t need branching rollouts or new reward functions.
What could this mean going forward?
- Learn from mistakes at scale: On very hard problems, most attempts are wrong. Intervention Training turns those failures into useful lessons by pinpointing the first error and fixing it.
- Simpler and cheaper: It avoids training extra step-scoring models and sticks to a simple recipe: self-check, make a small fix, fine-tune on that fix, then do RL.
- Generalizable idea: While tested on math, the idea—find first error, insert a minimal correction—could help in other multi-step reasoning tasks, from coding to science questions.
- Better, safer reasoning: By rewarding the right step and discouraging the wrong one, models can become more reliable and less verbose, focusing on what actually moves the solution forward.
In short, Intervention Training is like teaching a model to debug its own work: find the exact first mistake, fix just that, practice the fix, and then keep learning. This targeted approach helps it learn faster and perform better on tough, multi-step problems.
Knowledge Gaps
Below is a concise list of concrete knowledge gaps, limitations, and open questions the paper leaves unresolved. These items are intended to guide future researchers toward actionable follow-ups.
- Dependence on reference solutions: How does Intervention Training (InT) perform when high-quality human-written reference solutions are unavailable, noisy, or stylistically misaligned with model outputs? Can InT be adapted to settings without references (e.g., proof-heavy tasks, non-math domains) via alternative verifiers or learned surrogates?
- Quality and provenance of generated references: The paper occasionally uses Gemini-generated “reference solutions.” What is the accuracy and bias of these references, and how does reference quality affect intervention correctness and downstream RL performance?
- Robustness of “first error” detection: The procedure assumes the model can reliably identify the first causally responsible mistake via a text “diff.” How accurate is this detection across diverse problems, long trajectories, and stylistically divergent solutions? Can mislocalized errors harm training, and how can we quantify and mitigate such mislocalizations?
- Step segmentation heuristic: Reasoning steps are segmented by double newlines. Does this heuristic align with true logical steps across datasets and models? What alternative segmentation strategies (e.g., semantic segmentation, learned step boundaries) yield more reliable credit assignment?
- Single-step interventions only: Many failures likely require multi-step corrections or structural rewrites. Under what conditions does a single-step fix suffice, and how can InT be extended to iterative or multi-step interventions without exploding compute or drifting off-policy?
- Selection bias in SFT data: Interventions are filtered to include only those with at least one successful continuation (≥1/32 rollouts). How does this bias training toward “easy-to-fix” errors and affect generalization to harder or less locally amendable mistakes?
- Compute and scaling analysis: What are the end-to-end costs (tokens, wall-clock, GPU hours) of generating, filtering, and training on interventions compared to PRMs or hint-guided RL at scale (e.g., tens to hundreds of thousands of problems)? How does InT scale with model size, trajectory length, and dataset size?
- Verification bottlenecks beyond numeric answers: The evaluation intentionally restricts to numerically checkable answers. Can InT handle proof-style problems, geometry, or tasks that require symbolic, programmatic, or formal verification (e.g., Lean/Coq), and what are the necessary tooling or alignment methods?
- Generalization beyond math: Does InT transfer to other reasoning domains (code synthesis, scientific reasoning, planning) where references, verification, and step structure differ? What adaptations are required?
- Prompt sensitivity and instruction-following dependence: Intervention quality hinges on prompt design and instruction adherence. How sensitive is InT to prompt variants, output formatting constraints (tags), and instruction-following failure modes? Can structured decoding or constrained generation reduce prompt brittleness?
- Using the same model for verification and correction: Self-verification may inherit the base model’s blind spots. Are there measurable gains from using a separate (or larger) verifier/corrector vs. the same model? What are the trade-offs in bias, cost, and performance?
- Leakage risks from reference solutions: Although final-answer leakage is filtered, partial leakage through near-verbatim steps remains possible. How can we quantify and prevent subtle leakage while preserving intervention effectiveness and benchmark integrity?
- Intervention alignment across divergent solution styles: Reference solutions often differ in structure and ordering from model traces. How can we robustly align steps and map conceptual content to avoid proposing “correct” but stylistically incompatible interventions?
- Effects on verbosity, truncation, and exploration: The paper motivates InT by RL pathologies (verbosity/truncation) but does not measure whether InT mitigates them. Does InT reduce token length inflation, entropy spikes, or premature stopping, and how does cloning prefixes influence exploration at RL time?
- Theoretical understanding of credit assignment improvements: Can we formalize how InT reduces gradient variance, improves signal-to-noise, or adjusts advantage allocation compared to outcome-only RL (e.g., via variance bounds, credit decomposition, or counterfactual gradient analysis)?
- RL sensitivity and robustness: How sensitive are InT gains to RL hyperparameters (temperature, top-p/k, KL coefficients, batch sizes) and rollout budgets? Do improvements persist across different RL algorithms (e.g., PPO variants, REINFORCE with baselines)?
- Measuring intervention correctness and failure rates: What proportion of interventions are incorrect, overly narrow, or degenerate (e.g., restating the step)? Can we build automatic checks (consistency, constraint satisfaction) to detect and discard bad interventions?
- Curriculum and scheduling: What is the optimal schedule for collecting interventions (e.g., earlier vs. later in training), combining hints with interventions, or mixing multi-step and single-step fixes? Can adaptive curricula target the most impactful errors first?
- Impacts on non-target capabilities and catastrophic forgetting: Does SFT on prefixes + interventions induce overfitting to specific solution paths or degrade general instruction-following and reasoning outside math? A broader capability evaluation is needed.
- Benchmark coverage and statistical validity: Many reported gains are on small subsets (e.g., 40 IMO problems, numeric-only filtering). Larger, more diverse test suites with rigorous statistical analyses (confidence intervals, multiple seeds) would strengthen claims.
- Data contamination controls: Datasets like Polaris and AceReason-Math may overlap with pretraining corpora. What controls are in place to detect and mitigate contamination, especially when using references and interventions closely derived from known solutions?
- Integration with PRMs and search: Can InT complement step-level PRMs or branching rollouts by using interventions as proposal moves in a guided search? What hybrid strategies yield the best compute–performance trade-offs?
- Formal verifiers and semantic consistency: Beyond lexical diffing, can formal verification (algebraic simplifiers, proof assistants, symbolic execution for code) be integrated to validate interventions and ensure they semantically correct the error rather than merely rephrase it?
- Open-source reproducibility: The exact intervention prompts (Box references), parsing protocols, filtering criteria, and training scripts are crucial but incompletely specified. Providing full artifacts and ablation studies would enable independent validation and extension.
Glossary
- Advantage (RL): The difference between a trajectory’s reward and a baseline, used to determine how much to reinforce or penalize a sampled response. "Outcome-reward RL normalizes these rewards across responses sampled for the same prompt $\bx$, yielding advantages."
- Binary reward: A reward signal that can only be 0 or 1, often indicating correctness of a final answer. "and a binary reward $r(\bx, \by) \in \{0,1\}$ quantifying the correctness of the final answer."
- Branched rollouts: Multiple continuations sampled from the same prefix to estimate the value or credit of intermediate steps. "requires running multiple branched rollouts conditioned on a given prefix, which is prohibitively expensive"
- Counterfactual continuations: Hypothetical continuations conditioned on a localized correction to assess if the trajectory can succeed. "Conditioned on these localized corrections, the model can generate counterfactual continuations that succeed where the original failed (2)."
- Counterfactual reasoning traces: Reasoning sequences generated after modifying an identified error to test whether the solution can be recovered. "the model can then generate counterfactual reasoning traces that succeed from right before the point of failure even when the original rollout failed."
- Credit assignment: Determining which intermediate steps in a trajectory contribute to success or failure. "We refer to this failure mode as the problem of credit assignment."
- GRPO: A policy optimization method (related to PPO-style algorithms) used to train LLMs with outcome rewards. "In policy gradient methods such as GRPO~\citep{shao2024deepseekmath}, $\tilde{\pi} = \pi_{\text{old}$ is a periodically updated copy of , with additional correction terms in Equation~\ref{eq:policy-grad} to account for the distribution shift between and ."
- Hint-guided rollouts: Sampling solutions while conditioning on partial hints (prefixes) from a reference solution to steer generation. "Hint-guided rollout generation is complementary to interventions. Both improve overall reward."
- Instruction-following: An LLM’s capability to adhere to structured prompts and directives, critical for generating usable interventions. "We leverage instruction-following LLMs to verify their own reasoning traces and propose counterfactual steps that lead to improved outcomes"
- Intervention: A single corrective step proposed to replace an erroneous step in a reasoning trace. "We refer to this alternative as an intervention, whose purpose is to steer the remainder of the trajectory toward the correct answer."
- Intervention Training (InT): A training paradigm that patches models via SFT on self-proposed interventions, then applies RL. "InT: Intervention Training"
- Long-horizon trajectories: Sequences with many steps where errors can occur far from the start and rewards depend on distant outcomes. "which are often long-horizon trajectories composed of many smaller, structured reasoning steps."
- Off-policy trajectories: Responses not sampled from the current policy, often lower-likelihood under the base model. "whereas other approaches tend to produce more “off-policy” ones."
- On-policy trajectories: Responses sampled from the current (or base) policy distribution and thus have high likelihood under it. "producing more “on-policy” trajectories (those with high likelihood under the base model)"
- Outcome-reward reinforcement learning (RL): RL where the reward depends only on the correctness of the final answer, not intermediate steps. "Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of LLMs."
- Pass@k: The probability of obtaining at least one correct answer across k sampled solutions; a diagnostic and evaluation metric. "we observe that \methodname{} makes particularly effective use of reference solutions to improve pass@ performance"
- Policy gradient: An estimator for updating the policy parameters to maximize expected reward by weighting log-probability gradients with rewards. "We can maximize the objective above by updating the policy with the policy gradient~\citep{williams}:"
- Policy optimization: The process of improving a policy to achieve higher expected returns, often challenging in large step spaces. "As a result, policy optimization remains a challenging problem, since efficiently searching for suitable replacement steps is a difficult task in itself."
- Process Reward Model (PRM): A model that assigns step-level rewards or values to parts of a reasoning trace to aid credit assignment. "training explicit value functions (or process reward models)"
- Rollout: A sampled reasoning trajectory from a policy, including all intermediate steps and final answer. "training becomes increasingly dominated by incorrect rollouts"
- Step-level value function: A function estimating the expected return attributable to a specific intermediate step in a trajectory. "If we can estimate the “credit” of each intermediate step with a step-level value function (also called Process Reward Models, or PRMs), we can update by encouraging the correct parts of a solution while discouraging the incorrect ones."
- Supervised fine-tuning (SFT): Training a model on labeled or curated data to adjust its behavior prior to RL. "We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention"
- Verification–generation asymmetry: The phenomenon that verifying steps (via comparison to references) is easier for LLMs than generating correct solutions from scratch. "we test the alternative hypothesis that the verificationâgeneration asymmetry of the base model alone~\citep{setlur2025scalingtesttimecomputeverification} is sufficient to produce high-quality interventions."
- Value function: A function that estimates expected return from a state or step, used to guide credit assignment and optimization. "training explicit value functions (or process reward models)"
Practical Applications
Immediate Applications
The following applications can be deployed with current tools and datasets, especially in domains where step-level verification is easier than end-to-end generation and reference solutions or checklists are available.
- Industry (Software Engineering): “Single-step code patching” in IDEs
- Use the paper’s self-verification + intervention prompt to compare an LLM’s code reasoning trace against unit tests or golden implementations, identify the first incorrect step (e.g., a faulty algorithmic choice or API misuse), and propose a one-step code fix.
- Integrate SFT on prefix + intervention to patch the model before deploying RL-based assistants, improving sample efficiency and reducing noisy reasoning.
- Potential product: Intervention Training plugin for code assistants (Copilot-like), an SDK that produces “counterfactual continuations” conditioned on a one-step intervention.
- Dependencies/assumptions: Access to executable tests or reference implementations; instruction-following competency; reliable step segmentation of reasoning; guardrails to avoid answer leakage.
- Academia (STEM Education): Step-focused tutoring and grading
- Automatically pinpoint and explain the first error in a student’s proof or solution and propose a single corrective step; supports formative feedback in math, physics, and CS.
- Tools/workflows: “StepFix” tutor mode, teacher dashboard summarizing first-error locations across classes, and intervention-based practice sets.
- Dependencies/assumptions: Availability of verified reference solutions or solution outlines; evaluation criteria for steps; instruction-tuned base models.
- Industry (Data/Analytics): Query repair for SQL and data pipelines
- Compare generated SQL reasoning against expected outputs (gold tables) to locate the first wrong join/filter and propose a one-step fix; then continue the query generation conditioned on the intervention.
- Integrate with BI tools for “hint + intervention” workflows (paper shows complementarity).
- Dependencies/assumptions: Golden outputs or reference query plans; deterministic verification; robust instruction-following.
- Software and ML Ops: Credit assignment in RL post-training pipelines
- Adopt Intervention Training as a pre-RL patching stage to increase pass@k and coverage on hard tasks, then run standard outcome-based RL (e.g., GRPO). This improves learning signal from failed rollouts and mitigates verbosity/truncation.
- Tools/workflows: “Intervention Studio” that automates data collection, intervention generation, filtering (retain only interventions with ≥1 successful continuation), SFT on prefix+intervention without suffix, and handoff to RL.
- Dependencies/assumptions: Reference solutions or process checkers; compute for SFT and RL; task-specific verification functions (numeric answer parsing, unit tests).
- Healthcare (Operational Guidance, Non-diagnostic): Protocol adherence checker
- Use evidence-based protocols as “reference solutions” to verify stepwise care-plan generation (e.g., scheduling labs, consent forms), flag the first deviation, and propose an intervention to align with protocol.
- Deploy as a guardrail for administrative workflows (not clinical diagnosis).
- Dependencies/assumptions: Formalized protocols; strong safety review; regulated deployment; instruction-following reliability; clear boundaries to avoid clinical decision-making without oversight.
- Finance (Compliance Drafting): Policy-constrained memo writing
- Compare a draft reasoning trace against compliance checklists (reference policy) to find the first non-compliant reasoning step and propose a wording or decision-path correction.
- Tools/workflows: “Compliance Intervention Assistant” in document editors.
- Dependencies/assumptions: Accurate, machine-readable policies; careful auditing to prevent leakage of confidential answers; human-in-the-loop review.
- Robotics (Planning Offline): Step correction in task planners
- During offline planning or simulation, compare planned steps against known safe/reference plans to identify the earliest violation (e.g., unsafe grasp, ordering error) and propose one-step corrections; retrain planners using SFT on prefix+intervention.
- Dependencies/assumptions: Reference plans and simulators for verification; careful domain adaptation; robust step segmentation of plans.
- Customer Support and Knowledge Bases: Procedural troubleshooting
- For scripted troubleshooting flows, detect first incorrect branch choice and propose a one-step intervention (e.g., re-check a prerequisite) before continuing the flow.
- Dependencies/assumptions: Verified playbooks; compatible with instruction-following; clear evaluation (did the resolution succeed?).
- Education (Authoring): Creating intervention-rich practice materials
- Generate problem sets with “first-error + one-step fix” annotations, improving metacognitive skills and reducing overthinking/underthinking behaviors (noted as RL pitfalls in the paper).
- Dependencies/assumptions: Curated references; quality control to avoid answer leakage; teacher oversight.
- Policy and Governance: Auditable step-level AI outputs
- Require models used in public-sector decision-support to provide first-error localization and intervention proposals during internal review (step-level audit trail).
- Dependencies/assumptions: Availability of reference checklists; governance frameworks for logging and evaluation; human oversight.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or tooling to make verification and intervention generation reliable beyond math-like tasks.
- Cross-domain PRM alternative: Generalized credit assignment without PRMs
- Scale Intervention Training beyond mathematics to complex domains (law, medicine, engineering) by building domain-specific “reference solutions” (protocols, standards, exemplars) and robust step segmentation schemes.
- Potential product: Cross-domain “Credit Assignment SDK” that plugs into enterprise LLMs, performing step verification, intervention generation, and RL initialization.
- Dependencies: High-quality reference corpora; standardized step schemas; robust evaluators; safety and privacy guarantees.
- Autonomy and Robotics (Online Correction): In-the-loop intervention planning
- Move from offline to online: enable robots to detect first errors mid-execution and propose single-step corrections conditioned on reference plans, then continue planning and execution safely.
- Dependencies: Real-time verification; safe control integration; certified planners; hardware constraints; latency and reliability guarantees.
- Healthcare (Clinical Decision Support): Step-level audit and correction
- Use clinical guidelines as references to identify the first deviation in diagnostic or treatment reasoning and propose corrective steps; retrain models in a “patch-then-RL” pipeline to reduce error modes (verbosity/truncation) noted in outcome RL.
- Dependencies: High-stakes validation; external oversight; legal and ethical review; robust verification functions; addressing data shift and liability.
- Formal Methods and Theorem Proving: Proof intervention training
- Apply InT to formal proof systems where verifiers (proof assistants) serve as strong reference evaluators; train LLM provers to correct the first failing inference and continue.
- Dependencies: Tight integration with proof assistants; step segmentation aligned with formal inference; compute for large-scale SFT+RL.
- Large-scale Educational Assessment: Automated step grading across subjects
- Build systems that generalize “first error + intervention” feedback to multi-step solutions in algebra, geometry, physics derivations, and programming assignments, with calibrated rubrics and unbiased error detection.
- Dependencies: Subject-specific references; fairness and bias audits; institution-level deployment tooling; privacy-preserving logging.
- Enterprise Process Optimization: Intervention-informed RL for complex workflows
- Train enterprise LLMs on interventions across long workflows (procurement, risk assessment, logistics) to improve credit assignment and sample efficiency during RL, reducing “dead-end” rollouts and improving coverage of hard scenarios.
- Dependencies: Formalized workflow references; domain-specific evaluators; trace logging standards; change-management buy-in.
- Finance and Risk Modeling: explain-then-intervene strategies
- In regulated analytics (model risk), require models to produce stepwise rationales and allow automated “first-error interventions” to correct assumptions or data joins, then continue scenario analysis.
- Dependencies: Verified scenario references; audit trails; compliance approvals; careful handling of confidential data and leakage.
- Energy and Infrastructure Planning: step-level planning corrections
- Use reference plans and standards (e.g., safety codes, optimization baselines) to identify the first misstep in multi-stage planning (grid upgrades, maintenance schedules) and propose single-step interventions; retrain planning assistants with InT + RL.
- Dependencies: Access to authoritative standards; simulation environments for verification; stakeholder validation; high reliability requirements.
- Hybrid Hint + Intervention Training ecosystems
- Combine hint-guided methods (partial reference prefixes) with single-step interventions to steer models both globally (early direction) and locally (mid-trajectory corrections). The paper shows these are complementary.
- Dependencies: Scalable hint generation; reliable intervention filtering; orchestration engines for combined pipelines; evaluation benchmarks tuned for long-horizon tasks.
- Safety and Governance (Standards Development)
- Establish standards that require step-level credit assignment capabilities (error localization and corrective interventions) in safety-critical deployments of LLMs; define metrics for coverage, pass@k improvements, and post-RL stability.
- Dependencies: Multi-stakeholder consensus; benchmarking infrastructure; reporting frameworks; validation labs.
Notes on feasibility assumptions common to many applications:
- Access to high-quality reference solutions or checklists is pivotal; performance degrades without them.
- The verification-generation asymmetry is a core dependency: the model must be able to verify steps more reliably than it can generate entire solutions.
- Instruction-following competence matters; the paper’s ablations show instruction-tuned models produce higher-quality, usable interventions.
- Step segmentation must be well-defined for the domain; poor segmentation undermines error localization.
- Intervention filtering (retain only those with ≥1 successful continuation) and avoiding leakage of final answers are critical design choices.
- SFT on prefix + intervention (without cloning the suffix) generalizes better and preserves exploration capacity for downstream RL.
Collections
Sign up for free to add this paper to one or more collections.