- The paper presents a novel gradient-free self-improvement protocol that evolves hierarchical ReAct agent memory without weight updates, yielding robust performance gains.
- It systematically compares memory representations—Rules, Examples, and Mixed—with Examples achieving peak returns and Rules offering superior token efficiency.
- The champion broadcast mechanism coupled with instance graduation effectively reduces performance volatility and compute cost in challenging, high-stakes environments.
FORGE: Self-Evolving Agent Memory With No Weight Updates via Population Broadcast
Protocol and Architecture
The FORGE protocol introduces a population-based, gradient-free paradigm for evolving natural language agent memory to improve LLM agent competence in stochastic, long-horizon sequential environments, without recourse to weight updates. Each agent is a hierarchical ReAct instance, partitioned into Planner, Analyst, and ActionChooser sub-agents, using dynamic and persistent prompt-injected memory. Upon a reward signal below a fixed threshold during an episode, a dedicated learning agent—either a Reflector (for rule synthesis) or Exemplifier (for demonstration synthesis)—analyzes the full trajectory, generating knowledge artifacts that are appended to the agent’s prompt memory for immediate reuse.
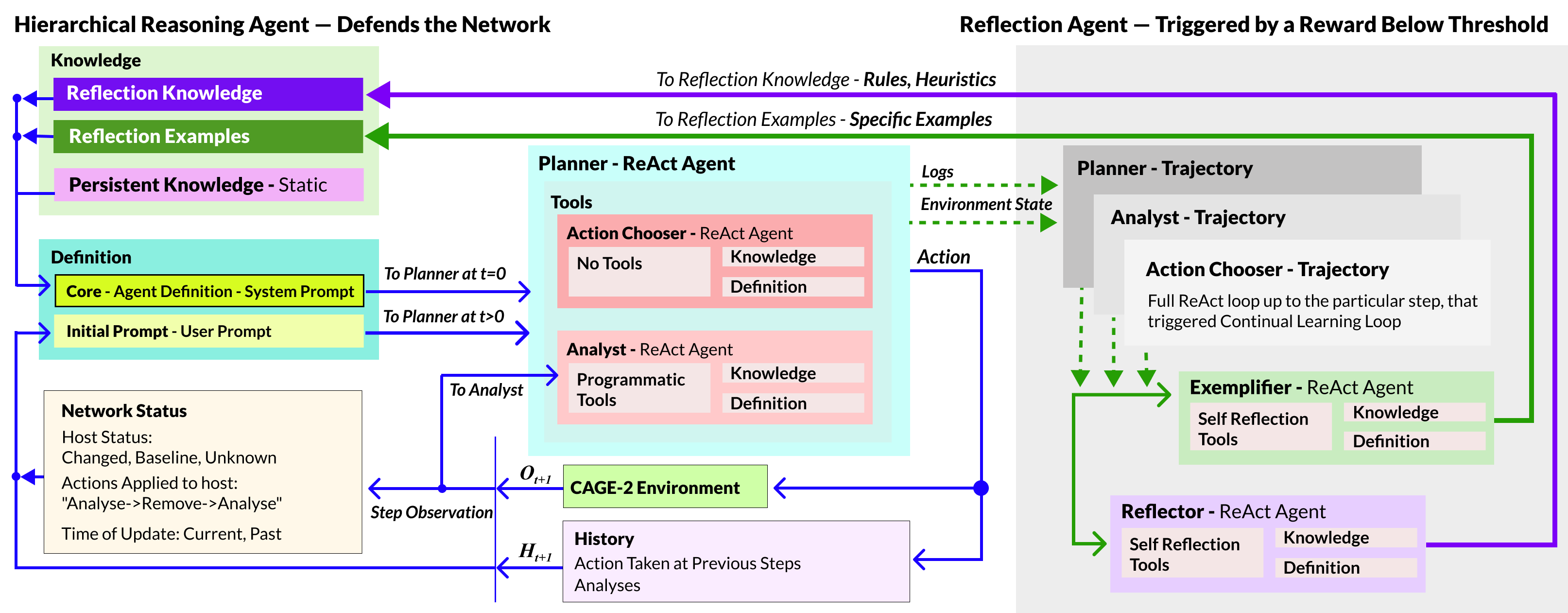
Figure 1: System overview. Hierarchical ReAct agent with dynamic memory; Reflexion loop injects synthesized artifacts after failures.
The outer FORGE protocol executes N instances in parallel, synchronizing at S intermediate stages. A champion broadcast mechanism copies the memory of the best-performing instance to the entire active population between stages. Instances that surpass a fixed performance threshold are graduated (excluded from subsequent training), saving compute while retaining high-performing memory. When broadcast is ablated (Reflexion baseline), each agent learns only from its own evolving memory.
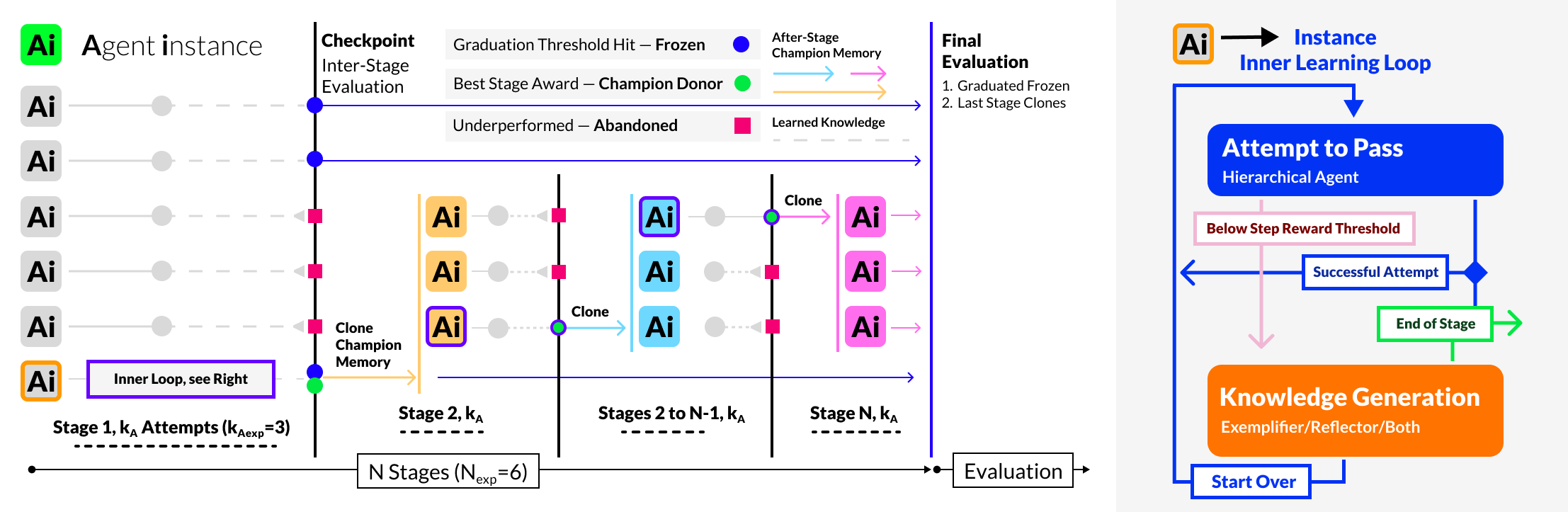
Figure 2: FORGE protocol: parallel execution, champion selection, graduation, and broadcast (left); inner abort-reflect-restart learning loop (right).
Experimental Setting
Evaluation is conducted on CybORG CAGE-2, a stochastic POMDP simulating cyber-defense with heavy partial observability over a 13-host enterprise network and a 30-step horizon. The environment presents sparse, scalar rewards with no natural language feedback and strong stochasticity. The four LLM families evaluated—Gemini-2.5-Flash-Lite, Grok-4-Fast, Llama-4-Maverick, Qwen3-235B—all perform poorly in the zero-shot regime, with episode returns typically below the weakest heuristic baselines, confirming that memory evolution is essential on this benchmark.
Three memory representations are compared systematically:
- Rules: lists of conditional textual heuristics for each sub-agent.
- Examples: structured few-shot demonstrations in ReAct format.
- Mixed: a combined approach.
FORGE yields robust performance gains: average returns improve by 1.7–7.7× over zero-shot and 29–72% over the Reflexion baseline across all model-representation pairs. FORGE also achieves marked reductions in catastrophic (major failure) episode rates, from ∼90% (zero-shot) to as low as ∼1% with the protocol.
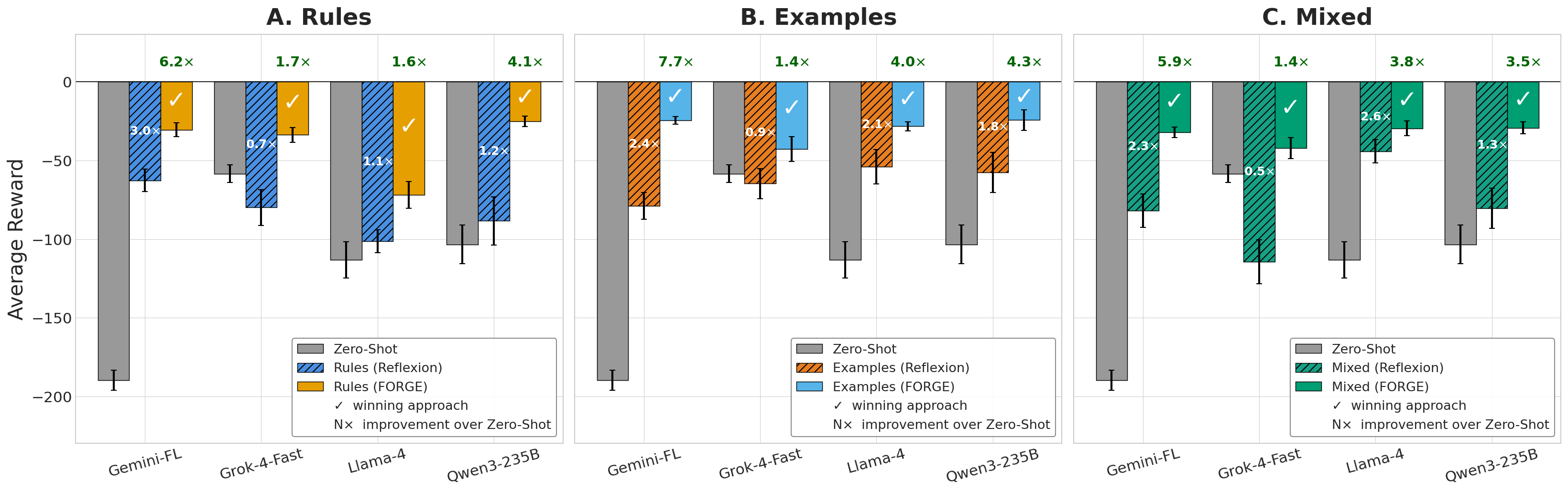
Figure 3: Zero-shot, Reflexion, and FORGE mean return comparison by memory representation and model family; improvement factors annotated.
Statistically, Examples dominates for three of four models in peak return (e.g., Gemini achieves −24.5 vs. baseline −189.6), but Rules provides superior cost-reliability tradeoffs due to terser prompt artifacts (∼40% fewer tokens, faster convergence, more instances graduated). Mixed falls in-between on both score and cost metrics.
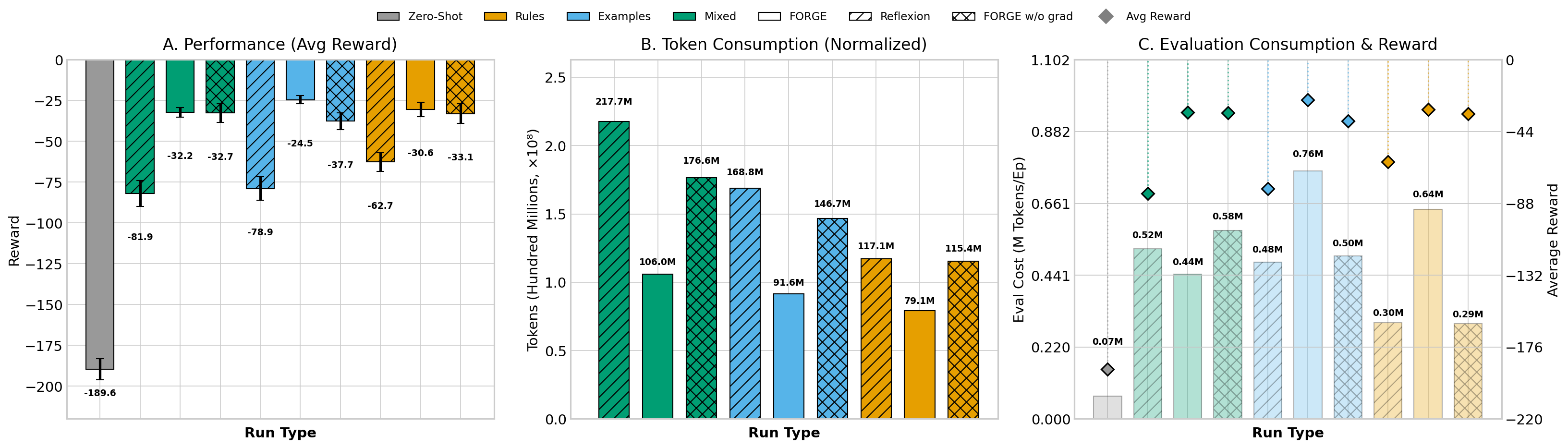
Figure 4: Gemini-2.5-Flash-Lite: all memory representations outperform baseline; Rules is most token-efficient and offers best cost-performance.
Population Broadcast and Compute Dynamics
The champion broadcast is the key driver of FORGE’s performance improvements, as evidenced by both final scores and volatilities. Protocol ablations confirm this: when graduation is disabled but broadcast is retained, performance continues to track broadcast; removing broadcast entirely (Reflexion) increases performance volatility and instance failure rates sharply. Volatility reductions, particularly in episode return distribution, are observed across training stages.
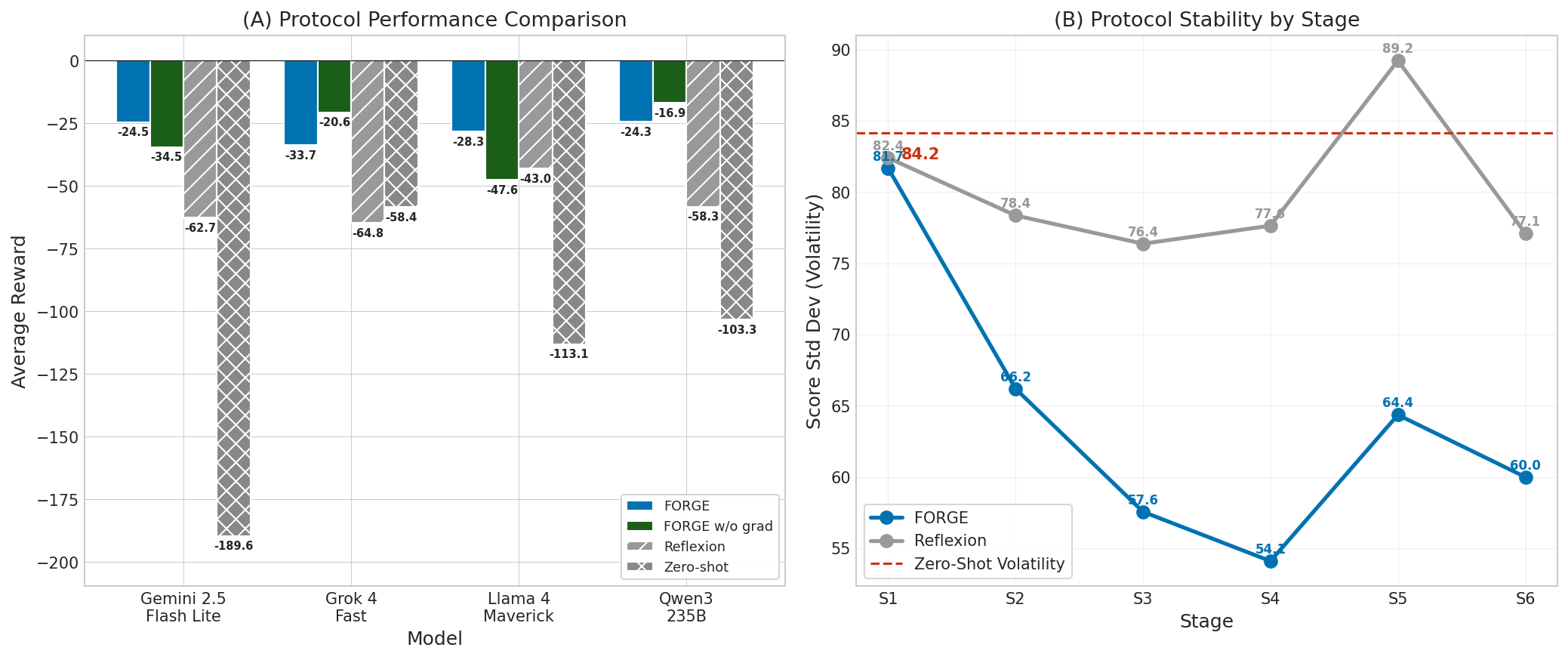
Figure 5: Mean evaluation return and checkpoint volatility by protocol; FORGE and broadcast variants consistently outperform and stabilize learning.
The graduation mechanism serves mainly to reduce compute: graduated instances are frozen, while the remaining learning resources focus on harder-to-train policies.
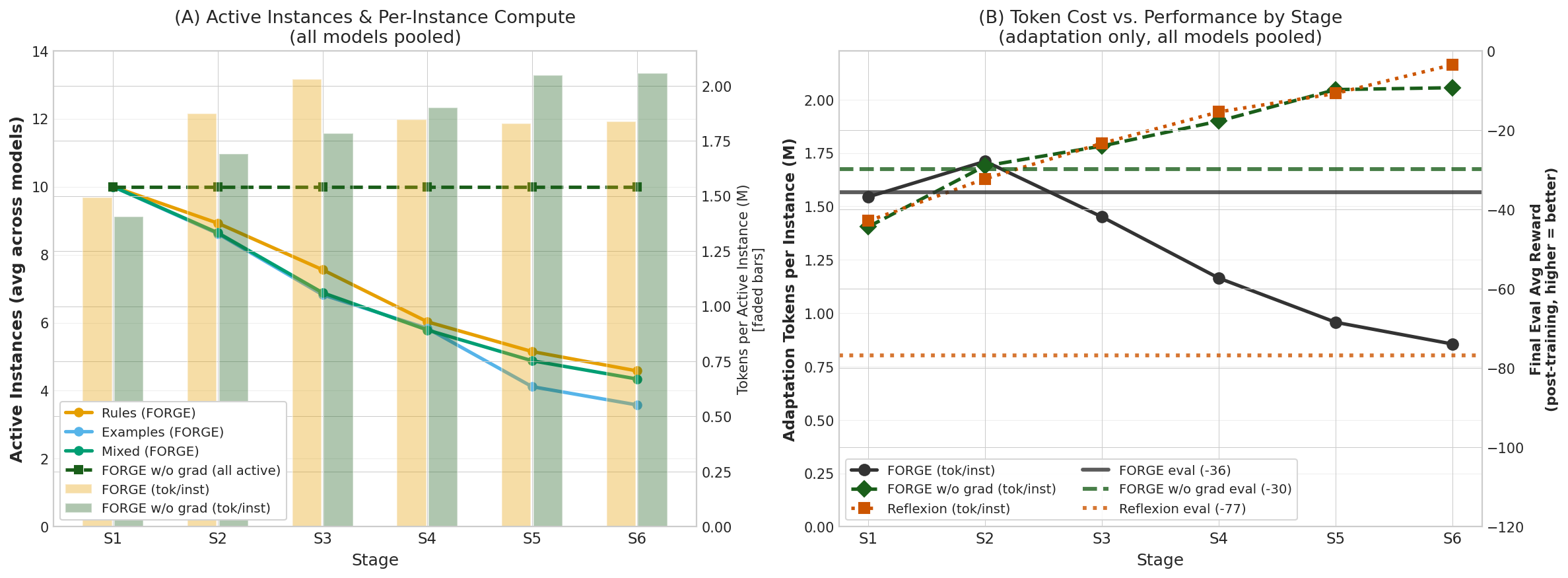
Figure 6: Active instances and per-instance token usage by stage; FORGE lowers total compute by graceful instance graduation.
Agent Reliability and Tail Risk
Beyond mean and variance reductions, FORGE compresses the heavy left tail of zero-shot and Reflexion episode returns. Catastrophic failures, as measured by returns <−100, are substantially suppressed under FORGE, which shifts the entire score distribution rightward.
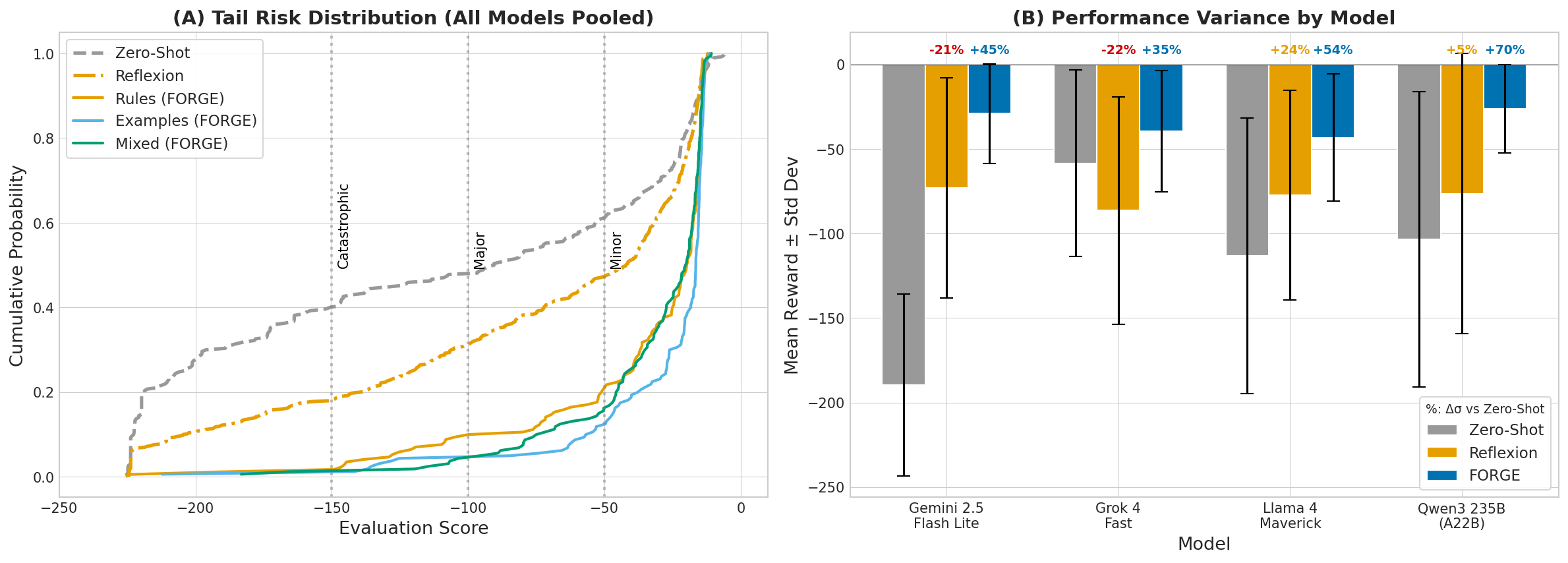
Figure 7: Cumulative score distribution and mean/SD summary; FORGE eliminates the high-failure-rate left tail and stabilizes outcomes across models.
Ablations and Sensitivity Analyses
Sweeping the reflection trigger threshold τ reveals that more severe triggers (especially τ=−11.0) can further boost reliability, supporting non-monotonic relationships between failure granularity and memory update efficacy. The protocol is robust to training hyperparameters and generalizes across all tested LLM families. Population-level transfer offers disproportionately greater benefit to weaker baselines, functioning as a variance mitigation mechanism without overfitting to spurious strategies.
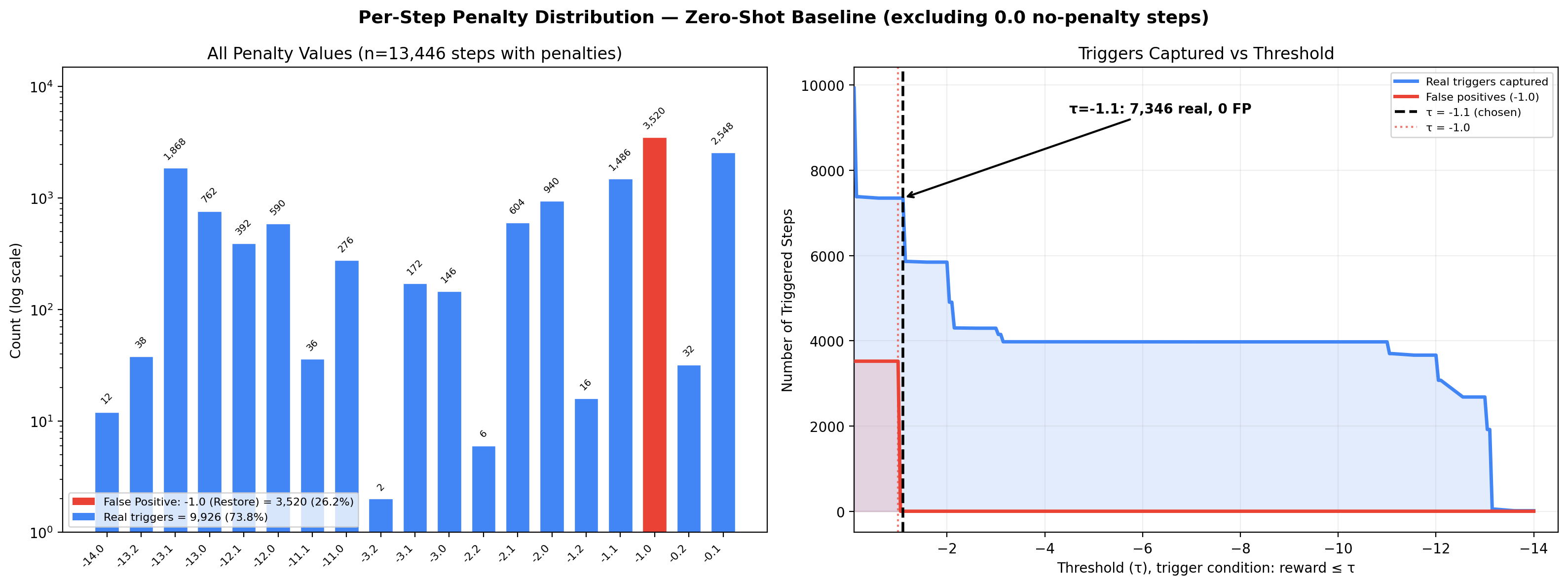
Figure 8: Failure trigger threshold analysis; strict triggers selectively capture real failures and further reduce false positives.
Implications and Future Directions
FORGE demonstrates that gradient-free agent self-improvement protocols based on structured memory evolution and population broadcast can close much of the performance gap to strong RL-based agents, entirely within a prompt-only paradigm. This is achieved without stronger teacher models, external feedback, or environment-embedded linguistic reward—demonstrably advancing the state of prompt-only, interpretable adaptation for LLM-based agents in high-stakes, stochastic POMDPs.
Practical implications include:
- Enabling more reliable online adaptation when parameter fine-tuning is infeasible.
- Support for generalized agentic learning on sparse-reward environments with minimal structural assumptions.
Theoretically, FORGE suggests memory evolution and broadcast selection can serve as a viable and robust policy search path for LLM agents, especially benefitting weaker or less-stable base models.
Future directions should expand protocol validation to different attacker types, diverse environments, and investigate artifact transfer across models, alternative memory selection functions, and more sophisticated graduation/broadcast schemes. Integrating cost-controlled protocol tuning, richer artifact synthesis (e.g., via more expressive representations or programmatic code), and alternative reflection mechanisms (e.g., TextGrad or Dynamic Cheatsheet) are also promising, to further close the gap with parameterized RL approaches and sharpen the reproducibility of large-scale prompt-based adaptation in general LLM agency.
Conclusion
FORGE establishes that staged, broadcast-driven evolution of prompt-injected memory enables robust, interpretable, and compute-efficient improvement of LLM agents, outperforming both zero-shot and isolated Reflection methods across models and representations in a demanding sequential decision-making benchmark. The protocol’s inherent population-level selection offers a clear practical and theoretical pathway for reliable, gradient-free self-improvement in stochastic, adversarial, partially observable environments (2605.16233).