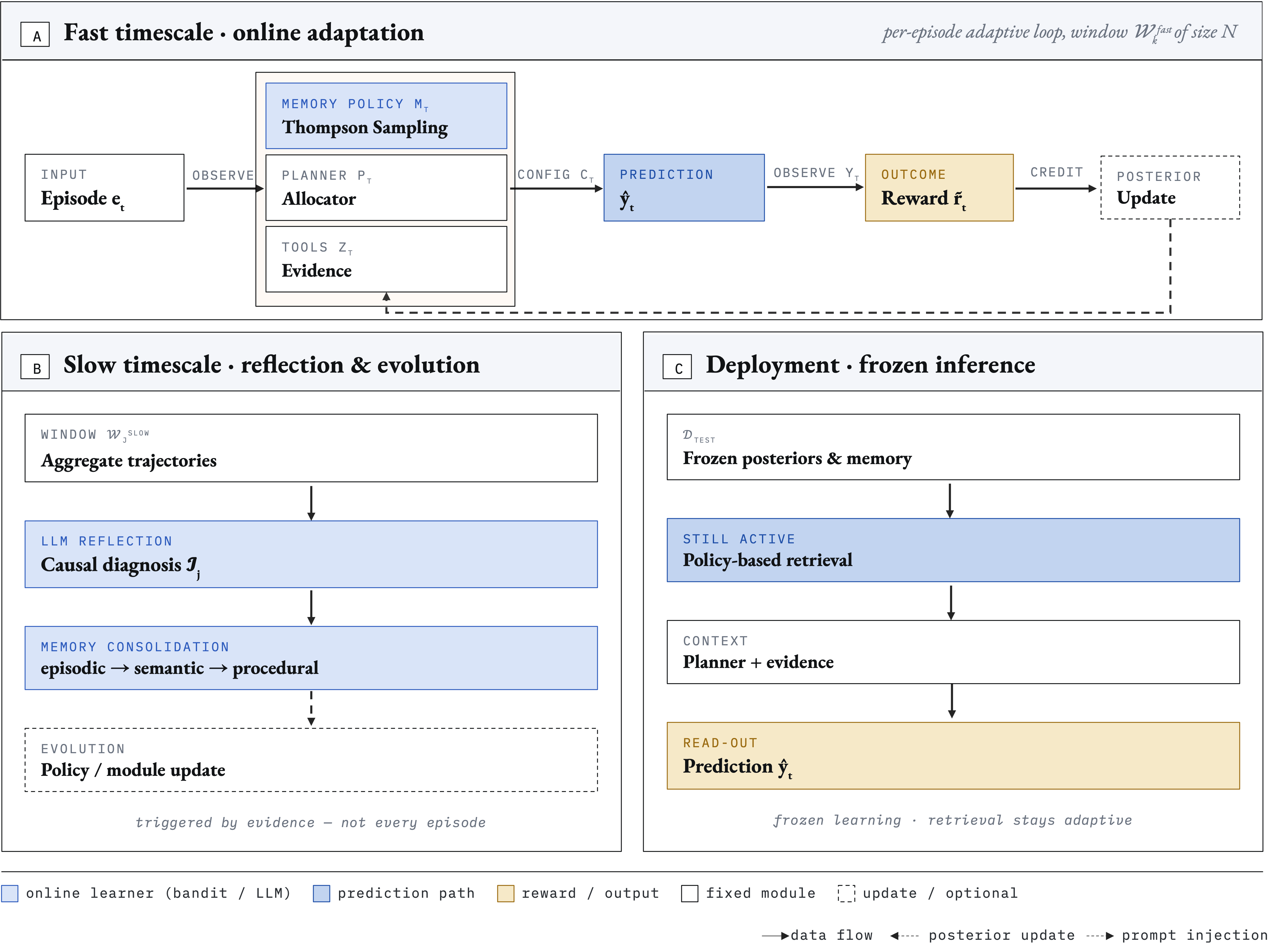
- The paper introduces a dual-timescale framework that integrates fast Thompson Sampling for episodic policy selection with slow LLM-based reflection for targeted module evolution.
- The methodology achieves superior performance metrics, including a Sharpe ratio of 2.13 and notable gains from memory-enabled improvements over complex adaptive architectures.
- The paper demonstrates that prioritizing self-diagnosis and simple uniform credit assignment yields robust, generalizable agent behavior in high-noise, short-horizon settings.
AEL: Agent Evolving Learning for Open-Ended Environments
Motivation and Positioning
AEL (Agent Evolving Learning) addresses a fundamental limitation in existing LLM agent architectures operating in open-ended, multi-episode environments: the inability to reliably leverage accumulated experience for self-improvement. Prior methods typically evolve a single module (memory, tools, or planner) in isolation, introducing ambiguity in multi-module credit assignment and resulting in fragile adaptation. The paper formally demonstrates that in high-noise, short-horizon domains, architectural complexity and sophisticated credit attribution degrade performance, and posits that self-diagnosis and targeted experience use are the true bottlenecks in agent evolution.
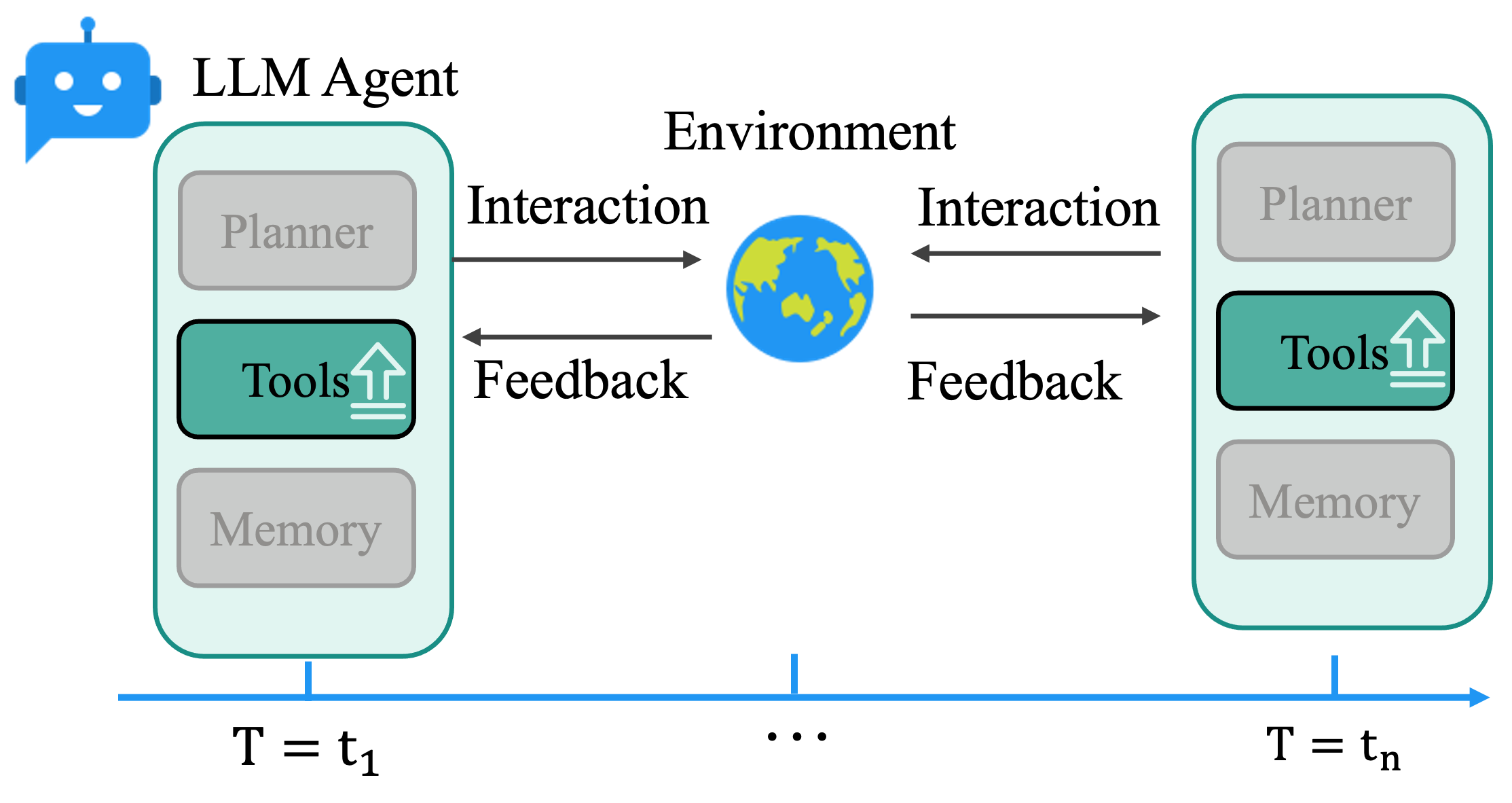
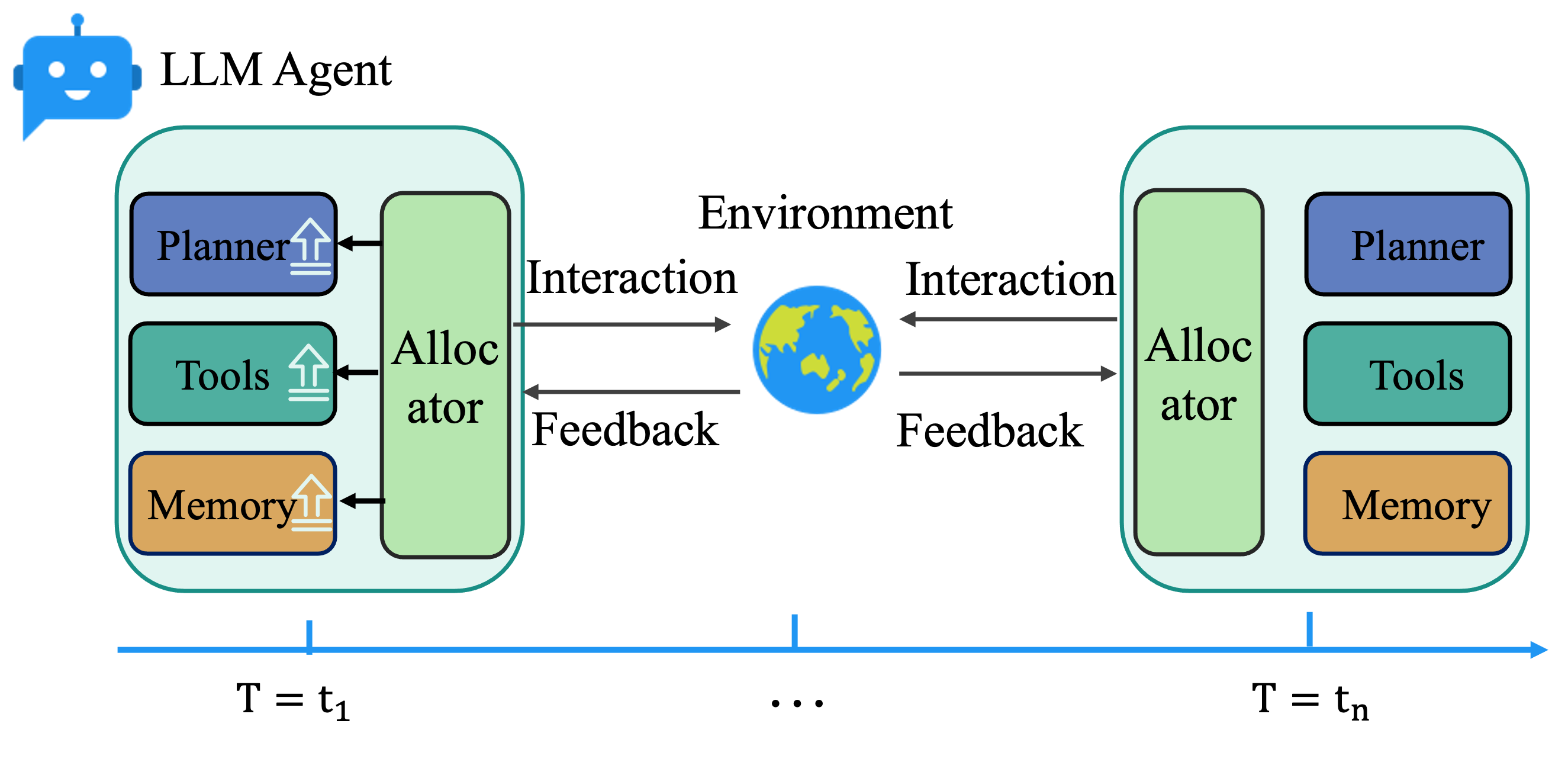
Figure 1: Left – Previous methods evolve a single module (Tools) while other components are fixed; Right – AEL enables joint evolution of planner, tools, and memory under a shared allocator with efficient credit and reflection.
Framework Design: Dual-Timescale Coupling
AEL implements a two-timescale architecture comprising:
The memory module is three-tiered (episodic, semantic, procedural) with automatic promotion. Semantic distillation captures cross-episode statistical regularities; procedural memory exposes high-trust abstraction as direct planner hints, bypassing retrieval. Retrieval policies govern both tier visibility and formatting, optimizing quality/recency/relevance tradeoff.
Learning Signal and Credit Assignment
Uniform scalar rewards (clipped and normalized outcomes) drive bandit updates; structural and Shapley-based credit assignment approaches are benchmarked but consistently degrade performance due to sampling noise and misattribution in limited-data regimes. LLM-based credit allows content-aware blame attribution but remains less reliable than uniform credit. AEL establishes the superiority of simple reward-based attribution for multi-module learning in noisy environments, directly contradicting prevailing complexity-driven credit assignment paradigms.
Empirical Evaluation and Ablation Insights
On the D-full sequential portfolio benchmark (10 tickers, 208 episodes, 5 seeds), AEL achieves:
- Sharpe ratio 2.13±0.47 (highest among all self-improving and non-LLM baselines)
- Sortino $4.08$, Calmar $10.4$, maximal drawdown −1.53%, and lowest performance variance across seeds
Incremental ablation reveals that memory enables a significant improvement (+24%) over stateless agents, while LLM-driven reflection induces an additional +27% gain. Every tested increase in architectural complexity—planner evolution, per-tool selection, skill extraction, cold start initialization, sophisticated credit assignment—degrades performance, establishing that complexity is not only superfluous but actively harmful in the evaluated context.
AEL demonstrates robust seed stability and generalization; by contrast, prior methods (EvoTool, Reflexion, ExpeL, etc.) exhibit high variance and seed dependence. HyperAgent's unconstrained code evolution (batch search over allocation functions) performs poorly, confirming the need for modular online adaptation.
Practical and Theoretical Implications
AEL's results strongly challenge the utility of architectural adaptation and complex credit assignment, advocating instead for a diagnose-before-prescribe approach centered on agentic reflection. The empirical "less is more" pattern highlights that, in practice, high-frequency adaptation is bottlenecked not by module evolution but by the agent's ability to interpret and contextualize past failures. Uniform bandit-driven credit and prompt-level causal reflection are demonstrated to be sufficient and optimal.
For practical autonomous agent systems, the implication is that stateful memory and periodic self-diagnosis should be prioritized over multi-component adaptation or agentic credit granularity, especially in noisy and short-horizon regimes. The findings are likely extensible beyond finance, as the framework is domain-agnostic and only requires context vectors and scalar rewards.
On the theoretical side, AEL opens new research axes:
- Modular credit assignment remains an open problem; robust attribution may require entirely new paradigms beyond structural, counterfactual, or Shapley-based approaches.
- Generalization and scaling may benefit from more systematic studies on cross-domain performance (e.g., coding and web navigation benchmarks).
- Procedural abstraction and reflection-driven module evolution are promising, especially as LLM capabilities improve and longer training horizons become available.
Conclusion
AEL presents a rigorously evaluated, dual-timescale framework for agent evolution in open-ended environments—combining Thompson Sampling bandits and LLM-driven causal reflection. The central empirical finding is that targeted self-diagnosis and memory utilization outperform all tested architectural complexity, and uniform credit assignment is optimal in high-noise, short-horizon settings. These results call for a repositioning of agent improvement strategies in both practical deployments and foundational research.