- The paper introduces a meta-evolution paradigm enabling LLM agents to self-evolve by autonomously exploring environments for structured world knowledge.
- It leverages supervised fine-tuning and reinforcement-based rejection sampling to enhance exploration and optimize outcome-based rewards.
- Empirical results on WebWalker and WebVoyager show up to 19% success gains and 17% reduced steps, demonstrating universal transferability.
Training LLM Agents for Reward-Free Self-Evolution Through World Knowledge Exploration
Motivation and Paradigm Shift
Autonomous agent evolution in current LLM-based systems remains fundamentally supervised, with experience-driven and adversarial paradigms still anchored to external, human-specified tasks and reward signals. This dependency manifests as bottlenecks in scalability, robustness, and genuine adaptability. The paper introduces a meta-evolution paradigm for LLM agents, targeting spontaneous self-evolution without predefined tasks or reward signals at inference time. The proposed approach enables agents to proactively explore unknown environments and distill structured world knowledge, acting as a cognitive map to facilitate downstream task adaptation. This paradigm marks a concise break from traditional guidance, aiming for workflow-free self-evolution with minimal human intervention.
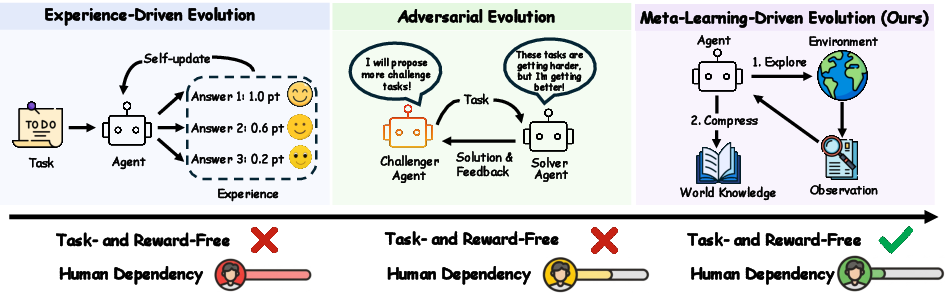
Figure 1: The evolution from experience-driven and adversarial paradigms to meta-learning-driven self-evolution, where agents autonomously derive world knowledge without reward or task supervision.
The approach centers on the concept of world knowledge (K)—structured, token-limited summaries of an environment generated via agent exploration. The agent's life cycle is decoupled:
- Native Evolution Phase: The agent independently explores the environment, generating K without external reward or task specification.
- Knowledge-Enhanced Execution Phase: For downstream tasks, the agent leverages K to drive reasoning and navigation.
Training is conducted through an outcome-based reward mechanism, where the utility of generated K is quantified as the differential in downstream task success rate when compared to the baseline (no prior knowledge). This reward is used exclusively at training time, while inference is entirely reward-free.
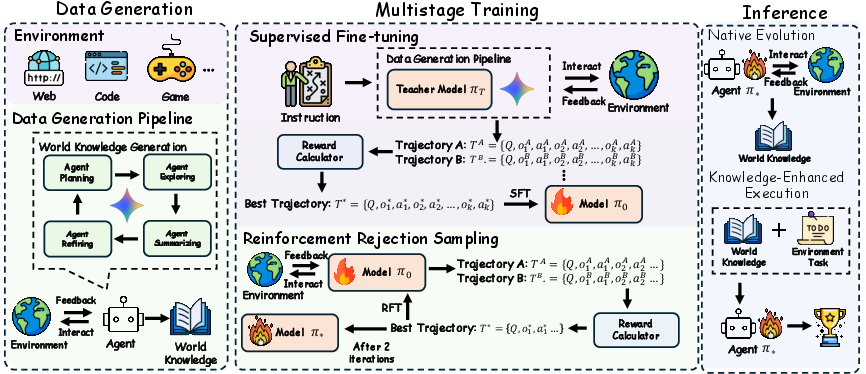
Figure 2: The pipeline: supervised fine-tuning from teacher models, followed by reinforcement-based rejection sampling to optimize world knowledge generation.
- Supervised Fine-Tuning (SFT): The base policy is initialized via imitation learning on trajectories generated by a strong teacher (e.g., Gemini-2.5-Pro), with selection based on maximum outcome-based reward.
- Reinforcement-based Rejection Sampling (RFT): Candidate world knowledge documents generated by the policy are scored and filtered, iteratively optimizing exploration and summarization efficiency.
Advantages include horizon-agnostic adaptation, decoupling from environmental reward signals, and eliminating gradient-based test-time training.
Empirical Evaluation and Numerical Results
Evaluation was conducted on WebWalker and WebVoyager benchmarks. Success rate and step efficiency were the primary metrics.
- Effectiveness: Ours (RFT) attains up to a 19% absolute gain (Qwen3-30B, WebWalker) and outperforms both the base model and teacher (Gemini-2.5-Pro) despite compact parameterization.
- Efficiency: Agents equipped with world knowledge reduce execution steps by on average 17%, demonstrating task guidance and structural prior impact.
Ablation studies confirm the major performance leap occurs after SFT and the first RFT iteration; further rounds yield diminishing marginal improvements.
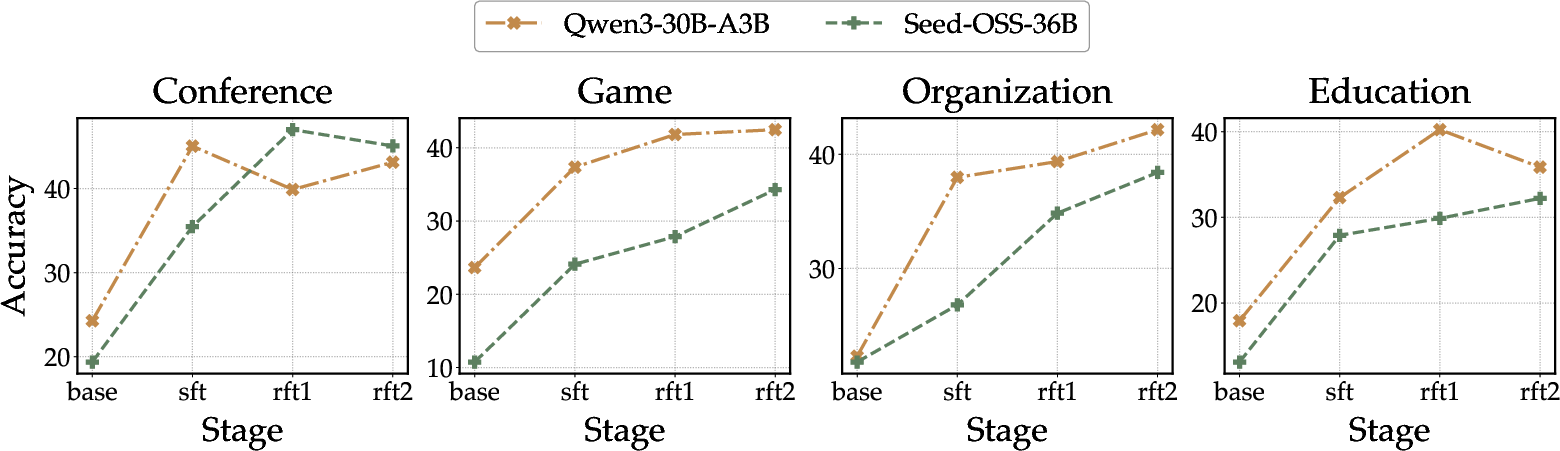
Figure 3: Success rate trends across training stages show marked performance jumps post-SFT and first RFT iteration.
Knowledge Transfer, Scaling, and Theoretical Implications
Cross-model experiments show K is universally portable—delivering substantial performance uplift irrespective of backbone architecture or scale.
Case Analysis and Token Sensitivity
A case study on ACL 2024 web navigation tasks demonstrates world knowledge enables early retrieval of critical information, reducing exploration steps and increasing answer precision.
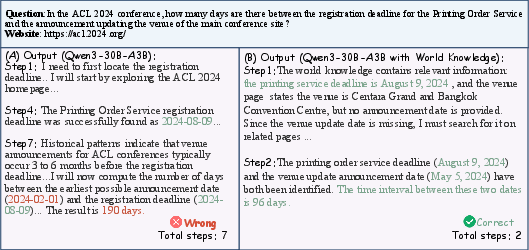
Figure 5: Comparison showing improved multi-step question answering with world knowledge integration.
Token length sensitivity reveals a non-linear relationship: increased document length improves performance up to a moderate threshold, after which added tokens introduce noise and marginal returns diminish.
Practical and Theoretical Implications
The paradigm enables agents to bootstrap world knowledge at inference, decoupling agentic cognition from reward engineering and runtime training constraints. This approach can generalize to diverse environments, laying technical groundwork for scalable, model-agnostic augmentation. In practice, world knowledge acts as structured context, enhancing navigation, reasoning, and planning in web and real-world tasks with minimal overhead.
Theoretically, the results suggest a shift toward intrinsic meta-learning as the principal driver for agent autonomy and generalization, rather than brute-force parameter scaling. The composability and portability of world knowledge facilitate agent collaboration and transfer learning, opening paths for curriculum-based evolution and automated task synthesis in future AGI systems.
Conclusion
This paper proposes and empirically validates a meta-learning paradigm for spontaneous, reward-free self-evolution in LLM agents via world knowledge exploration. The approach achieves significant performance gains, demonstrates universal transferability, and offers scalable, practical mechanisms for structuring environment cognition. The implications span both immediate agentic research and longer-term AGI prospects, highlighting environment-level exploration as the dominant axis for intelligence growth.
