- The paper introduces Echo-Forcing, a novel memory framework that structures the KV cache using hierarchical temporal and spatial mechanisms to enhance scene recall in long video generation.
- The paper employs bidirectional rolling anchors, drift-gated phase compression, and scene recall frames to ensure phase-stable token selection and adaptive forgetting of outdated information.
- The paper demonstrates significant improvements in video quality, temporal stability, and interactive prompt responsiveness, outperforming traditional baselines on multiple metrics.
Echo-Forcing: A Scene Memory Architecture for Interactive Long Video Generation
Introduction and Motivation
Autoregressive video diffusion models have made possible the open-ended synthesis of long-form video content by leveraging local attention mechanisms and key-value (KV) caching. Nevertheless, their memory management strategies are inherently simplistic, treating historical KV states as a temporally homogeneous cache. This design is effective for continuous generation under a fixed prompt but proves inadequate for interactive scenarios that require the system to respond dynamically to prompt changes, recall prior scenes, and suppress conflicting scene histories. The absence of explicit strategies for memory preservation, retrieval, or forgetting leads to critical failures: outdated background leakage, poor reactivity to prompt switches, and the loss of long-range contextual dependencies.
Echo-Forcing directly addresses these deficiencies by reformulating the KV cache as an explicit, structured scene memory, governed by a lifecycle of preservation, recall, and adaptive forgetting. The architecture is training-free and applies principled mechanisms for (1) maintaining stability across temporal scales, (2) spatially-structured recall of historical scenes, and (3) decaying memory in response to semantic drift. The resulting framework delivers significant improvements in stability, controllability, and memory-fidelity for interactive, long-horizon video generation.
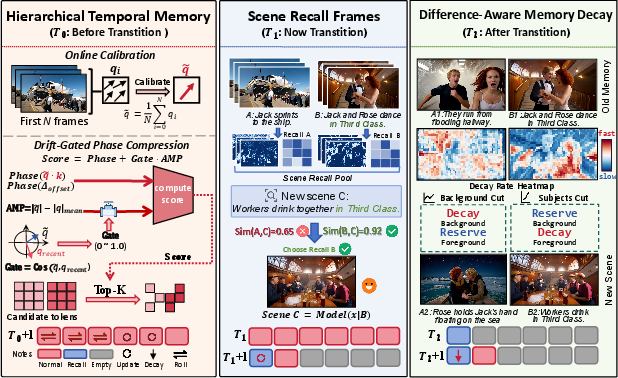
Figure 1: Overview of the Echo-Forcing framework, which integrates three scene-memory modules to preserve temporal continuity, recall historical scenes, and suppress conflicting memories during interactive long-video generation.
Scene Memory Mechanisms
Hierarchical Temporal Memory
Instead of a flat sliding window, Echo-Forcing organizes the KV cache hierarchically:
Scene Recall Frames
For efficient cross-scene recall, Echo-Forcing fuses the KV tokens of several stable scene blocks at each spatial location—producing spatially-structured Scene Recall Frames. This recall memory enables retrieval of target scene priors without incurring the noise or redundancy of storing all historical blocks, nor the information loss of single-frame selection.

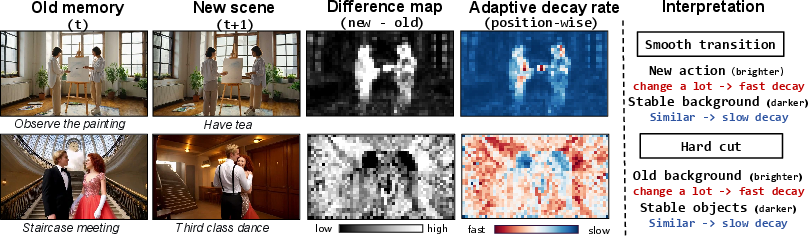
Figure 3: Echo-Forcing maintains compact scene memories for recall and applies position-wise memory decay based on scene discrepancies.
Difference-Aware Memory Decay
Upon scene transitions, historical KV states may actively interfere if not properly decayed. Echo-Forcing measures the cosine discrepancy between old-memory tokens and the new scene’s reference block, assigning spatially-varying decay rates. This results in a key-value level soft forgetting process: old-scene memories incompatible with the new prompt rapidly lose effective attention weight, while compatible priors persist to assist in early transitions.
Experimental Results
Echo-Forcing is evaluated on VBench-Long for both long-horizon generation and challenging interactive modes (smooth transition, hard cut, and long-range scene recall). Architectural baselines include Self-Forcing, Infinity-Rope, Deep-Forcing, Rolling-Sink, and LongLive.
Long-Video and Interactive Generation
Echo-Forcing consistently delivers the highest scores across key qualitative and quantitative metrics:
- Long-Video Generation: At 120s, Echo-Forcing yields top imaging quality (72.83), best temporal flickering (98.33), and the highest motion smoothness (99.05), all at competitive inference throughput. Notably, subject/background consistency and visual fidelity persist across 1- and 2-minute videos where other methods degrade sharply.
- Interactive Video Generation: For smooth transition, hard cut, and scene recall, Echo-Forcing improves prompt-following and scene consistency by 2–4 points compared to the next-best method, both in non-fine-tuned and fine-tuned settings.

Figure 4: Qualitative comparison showing how Echo-Forcing improves stability and scene control for long-horizon and interactive video generation, including smoother transitions, sharper hard cuts, and accurate scene recall.

Figure 5: Echo-Forcing preserves subject identity and background fidelity across extended rollouts in long-video generation.
Additional qualitative results highlight Echo-Forcing’s stability under both gradual and abrupt prompt changes, and its ability to recapture earlier scene semantics with minimal contamination—a capability that baseline methods lack.
Mechanism Ablations
Ablation studies validate each memory mechanism:
- Drift-Gated Compression: Removing amplitude compensation or drift gating substantially reduces dynamic degree and motion smoothness, confirming the necessity of both components for phase-stable, adaptable memory compression.
- Memory Budget Allocation: Optimal split between rolling anchors and compressed history is essential; excessive compression or over-reliance on anchors degrades either stability or dynamic responsiveness.
- Scene Recall and Decay: Scene Recall Frames outperform both first-frame and single-crucial-frame recall with substantial fidelity and text alignment gains. Difference-aware memory decay improves interactive text alignment by 2.4 points over even the best fixed-decay baselines.
Human Evaluation
User studies further corroborate quantitative improvements: Echo-Forcing achieves the highest human preference scores in text alignment, subject consistency, motion smoothness, and overall video quality for both long-form and interactive settings.
Implications and Future Directions
Echo-Forcing demonstrates that explicit, structured memory management—comprising lifecycle-aware preservation, spatially-weighted recall, and discrepancy-driven forgetting—solves critical bottlenecks in autoregressive long-video generation. The system is model-agnostic (requiring no backbone fine-tuning), memory- and computation-efficient (fixed-bounded cache), and generalizes across generation paradigms.
Practical impacts include:
- Real-Time, User-Controllable Video Synthesis: Enabling seamless, interactive editing or streaming content responsive to complex prompt evolution.
- Scene-Consistent Temporally Extended Content: Producing minute-scale or longer videos with high visual fidelity and narrative control.
Theoretically, Echo-Forcing suggests that long-sequence generation benefits from structured memory reminiscent of working memory models—decoupling “what” to remember, “when” to retrieve, and “how” to forget based on semantic change, not mere recency.
Future research may explore learned (rather than hand-crafted) memory lifecycle control policies, extend the framework to multimodal (audio-visual, language-video) conditioning, and investigate hierarchical or multi-level memory routing for even longer or more interactive scenarios.
Conclusion
Echo-Forcing represents a significant step in moving beyond undifferentiated temporal caching for video diffusion models, establishing explicit, lifecycle-driven scene memory as a fundamental component. This structured approach yields strong empirical gains for both long-horizon stability and interactive controllability, with broad implications for scalable, user-driven video generation and controllable AI generative systems.

Figure 6: Echo-Forcing produces smooth motion and coherent visual transitions through gradual prompt evolution in smooth transition scenarios.

Figure 7: Under hard-cut scene switches, Echo-Forcing suppresses old-scene residuals and adapts rapidly to the new prompt.

Figure 8: Qualitative comparison for 2-minute rollouts; Echo-Forcing maintains coherence and fidelity where baselines drift or degrade.

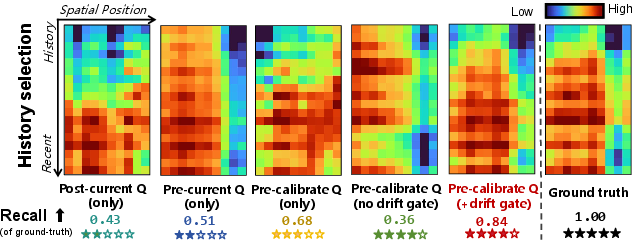
Figure 9: Each recalled frame exhibits distinct attention patterns, supporting adaptive, context-aware scene information retrieval.

Figure 10: Additional examples highlight Echo-Forcing’s robust scene-memory retrieval across extended shot intervals, reducing semantic confusion.