Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Abstract: Diffusion models have revolutionized image and video generation, achieving unprecedented visual quality. However, their reliance on transformer architectures incurs prohibitively high computational costs, particularly when extending generation to long videos. Recent work has explored autoregressive formulations for long video generation, typically by distilling from short-horizon bidirectional teachers. Nevertheless, given that teacher models cannot synthesize long videos, the extrapolation of student models beyond their training horizon often leads to pronounced quality degradation, arising from the compounding of errors within the continuous latent space. In this paper, we propose a simple yet effective approach to mitigate quality degradation in long-horizon video generation without requiring supervision from long-video teachers or retraining on long video datasets. Our approach centers on exploiting the rich knowledge of teacher models to provide guidance for the student model through sampled segments drawn from self-generated long videos. Our method maintains temporal consistency while scaling video length by up to 20x beyond teacher's capability, avoiding common issues such as over-exposure and error-accumulation without recomputing overlapping frames like previous methods. When scaling up the computation, our method shows the capability of generating videos up to 4 minutes and 15 seconds, equivalent to 99.9% of the maximum span supported by our base model's position embedding and more than 50x longer than that of our baseline model. Experiments on standard benchmarks and our proposed improved benchmark demonstrate that our approach substantially outperforms baseline methods in both fidelity and consistency. Our long-horizon videos demo can be found at https://self-forcing-plus-plus.github.io/


















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a way to make AI create long, high‑quality videos—up to several minutes—without the usual problems that appear when videos get longer (like the picture getting too bright, too dark, or the motion freezing). The method is called Self‑Forcing++, and it teaches a “student” AI to keep making good frames one after another, even far beyond what its “teacher” AI can normally do.
What are the main questions the paper tries to answer?
The researchers focus on two simple questions:
- How can we get an AI that’s great at short videos (about 5–10 seconds) to make much longer videos without the quality falling apart?
- Can we do this without needing a special dataset of long videos or a teacher model that already knows how to make long videos?
How does the method work? (Explained with everyday ideas)
Think of making a video like drawing a flipbook:
- A “bidirectional teacher” model is like an artist who draws small flipbooks very well because they look at the whole flipbook at once.
- A “student” model is like a new artist who must draw page by page in order, remembering what happened before (this is called autoregressive or streaming generation).
The challenge: The teacher only practices short flipbooks (about 5 seconds). When the student keeps drawing beyond that, mistakes pile up—motion slows, frames get too bright or too dark, and the story stalls.
Self‑Forcing++ fixes this with three key ideas:
- Generating long flipbooks on purpose
- The student draws long videos (much longer than 5 seconds), even if they start getting messy. These “messy” parts show real problems that happen in long videos.
- “Add noise and fix it” using the teacher
- Adding noise is like lightly smudging or blurring the student’s frames on purpose (called backward noise initialization).
- Then the teacher looks at short slices (windows) of the student’s long video and teaches how to clean and correct them.
- This “windowed distillation” lets the student learn to recover from mistakes anywhere in a long video, not just at the start.
- Keep a rolling memory during training and use it the same way during generation
- The model keeps a compact memory of past frames (called a “KV cache,” think of it like notes about what happened before).
- Self‑Forcing++ uses this rolling memory both while training and when actually generating, so there’s no mismatch between practice and real use. That makes the student more stable.
Optional extra: Smooth out sudden changes with light reinforcement learning
- The paper uses a method called GRPO (a type of reinforcement learning) with a motion-based reward (measured by “optical flow,” which is just how much things move between frames).
- This encourages the video to change smoothly, avoiding abrupt jumps or disappearing objects.
What did they find, and why is it important?
Main results:
- The method creates videos far longer than before—up to 4 minutes and 15 seconds in some tests—while keeping good visual quality and consistent motion.
- It avoids common long‑video issues like “over-exposure” (frames wash out and get too bright) or “error accumulation” (motion freezes or visuals degrade over time).
- It outperforms several strong baselines on both short and long video tests in fidelity (how good it looks) and consistency (how steady motion and content are).
Better evaluation:
- The team found that a popular benchmark (VBench) can accidentally give high scores to poor long videos (for example, ones that are over-exposed).
- They introduced a new score called “Visual Stability” and used a strong video‑understanding AI (Gemini‑2.5‑Pro) to judge long‑video quality more fairly.
Scaling up training helps:
- When they increased training time and compute (like practicing more), the model kept getting better at long videos—showing a clear “scaling law” for long‑video generation.
Why it matters:
- Making long, stable, and high‑quality videos opens the door to more realistic storytelling, education content, documentaries, and creative tools without needing massive long‑video datasets.
What does this mean for the future?
- Practical impact: AI can now generate much longer videos that look good throughout, which is useful for content creators, studios, and interactive media.
- Research impact: The paper shows a simple recipe—let the student model generate long sequences, “smudge” them with noise, and let a short‑video teacher fix short windows. This teaches recovery and stability without needing a long‑video teacher.
- Better measurements: The new “Visual Stability” score could help the community evaluate long videos more fairly.
- Next steps: The authors note limits like training speed and long‑term memory. Future work might add better memory, faster training, and smarter ways to keep the video consistent even when objects are hidden for a long time.
In short, Self‑Forcing++ teaches an AI to keep its cool over long videos: it learns to spot and fix its own mistakes as it goes, leading to minute‑long clips that stay clear, stable, and engaging.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that future work could address:
- Lack of theoretical analysis of long-horizon stability: No formal criteria or guarantees explain when autoregressive rollouts remain stable or collapse; derive stability conditions linking horizon length to noise schedule, window size, and cache length.
- Sensitivity to core hyperparameters is unreported: No ablations on the impact of window length K, rollout length N, cache size L, denoising steps, or noise schedules on quality, motion, and drift across horizons.
- Backward noise initialization design space is unexplored: How to choose σ_t schedules, re-injection strength, or alternative perturbations (e.g., partial-frame noise, structured noise) to optimize recovery without over-smoothing or content drift.
- Window selection strategy is simplistic: Uniform slicing ignores where degradation accumulates; study error-aware or curriculum sampling (e.g., higher-loss regions, later windows, motion-heavy segments) and their impact on robustness.
- Teacher–student mismatch remains under-characterized: The bidirectional teacher supervises short windows that may conflict with the student’s causal regime; quantify and mitigate supervision inconsistencies across time and noise scales.
- KV cache management is under-specified: Optimal cache length, cache normalization, and quantization trade-offs (latency, memory, quality) are not evaluated; effects of cache “staleness” and accumulation of bias are unknown.
- Bound by positional embeddings: The approach is capped by the base model’s positional encoding (1024 latent frames); methods to exceed PE limits (e.g., learned extrapolation, interpolation, RoPE/YaRN variants) are untested in this AR setting.
- Scaling law is anecdotal: Compute-to-quality/horizon scaling is shown qualitatively (1×–25×) without quantitative laws or resource reporting (GPU-days, memory), leaving cost-benefit unclear and replication difficult.
- Inference efficiency and latency are not reported: No throughput or real-time metrics for minute-scale generation with rolling caches; trade-offs vs. overlapping recomputation methods are unquantified.
- Robustness to occlusions and re-appearances is limited: Authors note lack of long-term memory; quantify identity reappearance consistency and devise memory/retrieval modules or state-regularization to prevent divergence after occlusion.
- GRPO formulation for diffusion is under-validated: The policy likelihood and credit assignment over denoising steps need clearer derivations, variance control, and stability analyses; compare on-/off-policy RL variants.
- Reward design is narrow: Optical-flow magnitude is a crude proxy and may encourage “flow smoothing” rather than semantic coherence; evaluate and combine richer rewards (identity consistency, text alignment over time, facial/pose consistency, geometry/physics plausibility).
- Reward hacking risks unaddressed: Check whether the model exploits the flow reward (e.g., minimizing motion) at the expense of semantic fidelity; develop anti-gaming diagnostics and counter-rewards.
- Generalization to other backbones is unknown: Results rely on Wan2.1-T2V-1.3B; test portability to different VAEs, DiT variants, resolutions, frame rates, and larger models.
- Identity and storyline coherence across minutes not measured: Introduce metrics and datasets for multi-character identity preservation, narrative consistency, and long-range text alignment beyond short-scene prompts.
- Multi-scene transitions and prompt switching are unsupported: Evaluate and extend to scene cuts, structured transitions, and mid-rollout prompt changes; compare to KV re-caching or attention-sink designs.
- Editing and continuation capabilities are untested: Assess performance when continuing from real video seeds, video inpainting/extension, and controllable camera trajectories.
- Boundary artifacts without overlap recomputation: Verify whether chunk boundaries introduce subtle flicker or temporal seams; develop seam-aware training or boundary regularizers if needed.
- Evaluation metric reproducibility and bias: Visual Stability depends on Gemini-2.5-Pro (proprietary); release prompts and scoring code, validate correlation with human judgments, and test robustness across MLLMs and domains.
- Dataset limitations: No training on true long-video corpora; evaluate benefits/risks of incorporating curated long sequences or self-bootstrapped long videos to teach narratives and episodic memory.
- Safety and alignment over long horizons: Study content drift into unsafe/off-policy regions over minutes; incorporate long-horizon safety rewards, filters, or constraints.
- Exposure/brightness stability is not systematically audited: Provide quantitative exposure/color constancy metrics across categories (lighting extremes, low texture) and mitigation strategies.
- Uncertainty calibration and error detection are missing: Explore predictive uncertainty, temporal confidence, and online correction triggers to preempt drifting segments.
- Reproducibility details are sparse: Provide seeds, prompts, full metrics, error bars, and model checkpoints; quantify variance across runs and prompts.
- Physics and 3D consistency not evaluated: Add metrics/rewards for physical plausibility (contact, gravity, collisions) and 3D consistency (multi-view coherence) to reduce long-horizon artifacts.
- Curriculum over horizon lengths is unstudied: Compare staged training (e.g., progressively increasing window/horizon) vs. immediate long-horizon rollouts; measure convergence speed and final quality.
- Adaptive scheduling policies are absent: Investigate dynamic adjustment of noise re-injection level, window size, or cache length based on online degradation indicators (e.g., flow spikes, identity drift).
- Interaction with text conditioning over time: Analyze prompt adherence drift; experiment with periodic text re-conditioning, temporal planners, or hierarchical controllers for sustained alignment.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging Self-Forcing++’s ability to generate minute-scale, high-quality, temporally consistent videos without overlapping-frame recomputation. Each item notes core assumptions or dependencies.
- Media and Entertainment
- Minute-scale previsualization and storyboarding for film, TV, and animation (1–4 minutes of coherent motion and narrative beats).
- Tools/workflows: Text-to-video generation pipeline with rolling KV cache; “windowed sampling” QA pass using Visual Stability scores for scene selection; editor plugins (e.g., Adobe After Effects, Premiere).
- Assumptions/dependencies: Access to a capable short-horizon teacher model; adequate GPU memory for KV caching; prompt engineering for story structure.
- Generative background plates and long B-roll for post production and trailers.
- Tools/workflows: Self-Forcing++ service/API integrated with editorial asset management; automated quality gating via Visual Stability.
- Assumptions/dependencies: Brand/safety filtering; compatibility with studio toolchains.
- Advertising and Marketing
- Rapid iteration of minute-long ad creatives (explainers, product demos, brand stories) with consistent motion and exposure.
- Tools/products: “Creative iteration engine” using extended DMD training and GRPO for smooth transitions; A/B testing supported by Visual Stability for QA and rejection of over-exposed/degraded variants.
- Assumptions/dependencies: Legal rights for generative content usage; compute budget for batch generation; watermarking/moderation pipeline.
- Social Media and Creator Economy
- Long-form generative videos for platforms (e.g., TikTok, YouTube) beyond short clips—travel recaps, stylized recreations, DIY/tutorials.
- Tools/workflows: Creator-facing web app with streaming inference via rolling KV cache; template prompts for common genres; Visual Stability-driven post generation filtering.
- Assumptions/dependencies: Content policy compliance; simple controls (style, pacing) in UI; compute quotas.
- Education and Training
- Minute-scale visual explainers and lab demos in physics/biology/engineering with stable motion over extended sequences.
- Tools/products: LLM plan-to-video pipeline (LLM for script/beat, Self-Forcing++ for video, Visual Stability for QA).
- Assumptions/dependencies: Pedagogical review; domain-specific prompt libraries; alignment with accessibility standards.
- Synthetic Data Generation for Vision/ML (Academia and Industry R&D)
- Long, coherent sequences for training and benchmarking tracking, action recognition, and video understanding models.
- Tools/workflows: Dataset generator using backward noise initialization and windowed distillation to enforce continuity; labels generated with auxiliary models (optical flow, tracking).
- Assumptions/dependencies: Domain gap evaluation; adherence to dataset governance; reproducible seeds and generation specs.
- Robotics and Simulation
- Long visual sequences for pretraining perception modules (e.g., warehouse navigation, pick-and-place scenarios) where temporal continuity matters.
- Tools/workflows: Scenario generator with GRPO-based smoothness for low-flicker visual streams; integration with synthetic sensor pipelines.
- Assumptions/dependencies: Visual realism sufficiency for transfer; absence of accurate physics requires caution for control policy training.
- Evaluation and Benchmarking (Academia, Standards, Policy)
- Immediate adoption of the “Visual Stability” metric to counter VBench bias toward over-exposed/degraded frames in long videos.
- Tools/products: Long Video QA suite combining Gemini-2.5-Pro rating protocol with stability scoring; CI/CD integration for generative model QA.
- Assumptions/dependencies: Access to a robust video MLLM; transparent scoring rubric; governance over metric drift.
- Platform/Infrastructure Engineering (Software)
- Streaming inference services for long text-to-video generation with rolling KV cache and no overlapping recomputation.
- Tools/workflows: “Rolling KV cache inference engine” microservice; autoscaling policies; telemetry based on stability, exposure, motion metrics.
- Assumptions/dependencies: Memory management and cache sizing; positional embedding limits of the base model.
Long-Term Applications
Below are applications that require further research, scaling, productization, or integration with additional modalities and systems.
- Long-Form Generative Content (Episodes, Shorts, Live Streams)
- Fully auto-generated episodic content with narrative arcs spanning many minutes, including mid-stream prompt switching and scene continuity.
- Tools/products: Memory-augmented Self-Forcing++ (quantized/normalized KV cache, long-term memory modules); language-based story planners; scene graph constraints.
- Assumptions/dependencies: Enhanced long-term memory; controllable consistency across occlusions; higher compute budgets; script-to-video coherence.
- Real-Time Interactive Avatars and Digital Humans (Customer Support, Education, Entertainment)
- Live, promptable avatars delivering lectures, support walkthroughs, or performances, with sustained visual consistency.
- Tools/workflows: Multimodal stack (TTS, lip-sync, gesture control) fused with streaming Self-Forcing++; GRPO for smooth transitions.
- Assumptions/dependencies: Low-latency generation; content safety; multi-speaker/speaker-ID consistency; policy compliance.
- Autonomous Driving and Smart Cities Simulation
- Long horizon synthetic environments for rare-event simulation (weather, traffic anomalies) to pretrain perception and prediction models.
- Tools/products: Domain-specific generators with physical plausibility constraints; evaluation suites combining Visual Stability and scenario coverage.
- Assumptions/dependencies: Physics fidelity and calibration; domain adaptation; city-scale rendering; regulatory acceptance for synthetic data.
- Robotics World Models and Long-Horizon Control
- Training world models on consistent, minute-scale sequences to improve planning and long-term prediction.
- Tools/workflows: Self-Forcing++ + physics simulators; curriculum generation; temporal consistency rewards beyond optical flow.
- Assumptions/dependencies: Integration with physics and interaction modeling; bridging sim-to-real gaps.
- Game Development and Virtual Production
- Auto-generated cutscenes and cinematics with style consistency across minutes, integrated into engines (Unreal, Unity).
- Tools/products: Engine plugins exposing Self-Forcing++ APIs; shot planning with LLM storyboards; scene continuity checks (Visual Stability).
- Assumptions/dependencies: IP/style control; editor interoperability; production-grade QA and versioning.
- Live Events and Stage Visuals
- Generative stage backdrops and reactive visuals sustained over entire performances.
- Tools/workflows: Real-time streaming generation with latency-optimized rolling cache; audio-reactive controls; fail-safe quality monitors.
- Assumptions/dependencies: Latency constraints; GPU provisioning; safety cues for performance venues.
- Healthcare and Public Health Communication
- Patient education sequences (e.g., rehab routines, medication instructions) with consistent visual guidance over minutes.
- Tools/products: Clinical content generation suite with medically vetted prompts; QA via Visual Stability and clinician oversight.
- Assumptions/dependencies: Regulatory approvals; bias and safety filtering; localization and accessibility.
- Standards, Policy, and Governance
- Establishing evaluation standards for long video generation (adopting Visual Stability, exposure/motion consistency audits).
- Tools/workflows: Open benchmarks for long-horizon quality; auditing guidelines; watermarking/traceability requirements for generative media.
- Assumptions/dependencies: Multi-stakeholder consensus; transparent metric definitions; energy/computational footprint reporting.
- Platform-Level Optimizations and Services
- Distillation-as-a-Service for extending existing short-video generators; KV cache optimizers (quantization/normalization) for stability and cost efficiency.
- Tools/products: Managed training pipelines (extended DMD, backward noise initialization, GRPO); cost-aware inference orchestrators.
- Assumptions/dependencies: Licensed access to teacher models; dataset governance; robust monitoring and rollback strategies.
Glossary
- Adaptive LayerNorm: A technique that adapts normalization parameters to improve model fusion across modalities. "CogVideoX introduces an expert transformer with adaptive LayerNorm to enhance cross-modal fusion"
- Attention sink frames: Special frames used as anchors in attention to balance short- and long-term consistency. "It integrates attention sink frames for balancing short- and long-term consistency"
- Attention window: The number of past tokens/frames the model attends to at once. "by reducing the attention window, the model is forced to slide attention multiple times"
- Autoregressive: A generation approach that predicts the next output conditioned on previously generated content. "shifting from bidirectional diffusion architectures to autoregressive, streaming-based models"
- Backward noise initialization: Re-injecting noise into clean rollouts to start distillation from temporally consistent states. "Our method employ backward noise initialization, extended DMD and rolling KV Cache"
- Bidirectional diffusion architectures: Diffusion models that use non-causal attention over the entire sequence during denoising. "shifting from bidirectional diffusion architectures to autoregressive, streaming-based models"
- Bidirectional teacher model: A high-quality non-causal diffusion model used to supervise a causal student. "distill a bidirectional teacher model into a streaming student model using heterogeneous distillation"
- Block causal attention: Attention restricted to past blocks to enforce causality in sequence generation. "CausVid employs block causal attention and a KV cache to autoregressively extend sequences"
- Causal 3D VAE: A variational autoencoder that compresses spatio-temporal tokens with causal structure across time. "Hunyuan Video employs a causal 3D VAE for spatio-temporal token compression in latent space"
- Consistency Models (CM): Models that learn to map noisy inputs directly to clean outputs in one or few steps. "Prominent approaches in this domain include Distribution Matching (DM) and Consistency Models (CM)"
- Continuous latent space: A smooth representation space where small changes in latents correspond to gradual changes in outputs. "arising from the compounding of errors within the continuous latent space"
- Diffusion Forcing: A method that applies varying noise schedules across frames to enable sequential generation. "Diffusion Forcing applies heterogeneous noise schedules across frames to enable sequential generation"
- Diffusion Transformer (DiT): A transformer-based backbone for diffusion that scales to high-quality image/video generation. "Diffusion Transformers (DiT), the inherently non-streaming and non-causal nature of the vanilla DiT architecture poses a significant challenge"
- Distribution Matching (DM): Distillation that aligns the student’s distribution to the teacher’s across noise levels. "Prominent approaches in this domain include Distribution Matching (DM) and Consistency Models (CM)"
- Distribution Matching Distillation (DMD): A training objective aligning student and teacher score distributions to enable few-step generation. "using techniques such as Distribution Matching Distillation (DMD) loss"
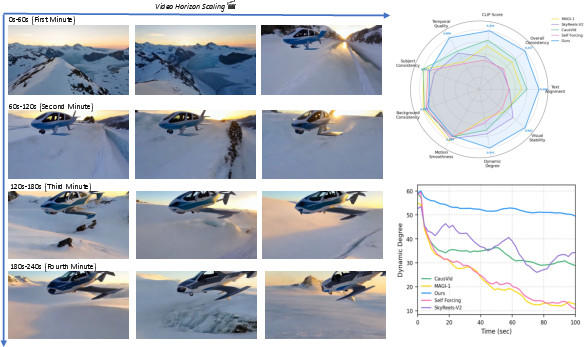
- Dynamic degree: A metric estimating motion richness or activity level over time. "Baseline methods achieve high temporal quality scores primarily due to stagnation reflected by their dynamic degree"
- Error accumulation: Progressive compounding of small generation errors that degrade long rollouts. "Second, error accumulation caused by supervision misalignment during long-horizon generation"
- Extended DMD (Extended Distribution Matching Distillation): Applying DMD over sampled windows of long self-rollouts to teach recovery from degraded states. "Our method employ backward noise initialization, extended DMD and rolling KV Cache"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm optimizing policies using groupwise relative preferences. "we show that Group Relative Policy Optimization (GRPO), a reinforcement learning technique, can be utilized in autoregressive video generation"
- Heterogeneous distillation: Distilling with varied supervision strategies or schedules to bridge teacher-student differences. "CausVid proposes a method to distill a bidirectional teacher model into a streaming student model using heterogeneous distillation"
- Heterogeneous noise schedules: Using different noise levels across frames to support sequential denoising. "applies heterogeneous noise schedules across frames to enable sequential generation"
- History KV cache: The stored past key-value tensors that preserve context for causal attention in transformers. "which correctly leverages the history KV cache to maintain context"
- KL divergence: A measure of discrepancy between two probability distributions used as a training objective. "The student is then trained to minimize the average KL divergence between its distribution and the teacher’s distribution"
- KV cache: Cached key-value tensors from attention layers enabling efficient streaming generation. "with KV caching emerging as a key mechanism for enabling performant, real-time streaming"
- Latent frame: A frame represented in latent space (compressed representation) used by diffusion backbones. "neither the recomputation of overlapping frames nor latent frame masking"
- Long-horizon: Refers to sequences that substantially exceed the training window (e.g., tens to hundreds of seconds). "quality degradation in long-horizon video generation"
- Marginal distribution: The distribution of a subset (e.g., a short contiguous segment) of a longer sequence. "any short, contiguous video segment can be viewed as a sample from the marginal distribution of a valid, longer video sequence"
- Motion Collapse: Failure mode where motion stagnates and sequences become nearly static. "Motion Collapse: While maintaining short-term temporal structure, their videos frequently collapse into nearly static sequences"
- Multi-resolution frame packing: Training strategy packing frames at multiple resolutions to improve efficiency and alignment. "supported by a 3D VAE, progressive training, and multi-resolution frame packing"
- ODE trajectories: Continuous-time denoising paths modeled by ordinary differential equations for distillation. "training a student model to replicate the Ordinary Differential Equation (ODE) trajectories sampled from the teacher"
- Optical flow: A field describing per-pixel motion between consecutive frames, used as a proxy for smoothness. "use the relative magnitude of optical flow between consecutive frames as a proxy for motion continuity"
- Over-exposure: Artifact where frames are too bright or washed out, often from train-inference mismatches. "a pronounced train-inference mismatch often results in over-exposure artifacts"
- Positional embedding capacity: The maximum sequence length a model’s positional encodings can reliably represent. "utilizing 99.9% of the base model's positional embedding capacity"
- Rolling KV cache: Updating the cache as the sequence advances, used in both training and inference for consistency. "our method naturally eliminates this mismatch by employing a rolling KV cache during both training and inference"
- Sliding-window distillation: Sampling contiguous windows from long rollouts to compute student–teacher divergence. "This sliding-window distillation process is formalized as"
- Streaming-based models: Architectures designed to generate outputs sequentially in real time with causal context. "autoregressive, streaming-based models"
- Temporal consistency: Maintaining coherent motion and scene continuity over time. "produces realistic, coherent videos with strong temporal consistency and diverse motion"
- Temporal flickering: Rapid brightness or content changes across frames causing visual instability. "the mismatch still leads to substantial error accumulation and temporal flickering in long videos"
- Text alignment score: Metric evaluating how well generated video matches the textual prompt. "our model achieves a text alignment score of 26.04"
- Train-inference mismatch: Discrepancy between training conditions and inference usage that harms performance. "a pronounced train-inference mismatch often results in over-exposure artifacts"
- Trunk size: The number of latent frames processed per step or chunk during generation. "we generate videos in a trunk size of 3"
- VBench: A benchmark evaluating text-to-video models across multiple quality dimensions. "Most prior works rely on VBench to assess image and aesthetic quality in long video generation"
- Video MLLM: A multimodal LLM specialized for video understanding and evaluation. "We adopt Gemini-2.5-Pro, a state-of-the-art video MLLM with strong reasoning ability"
- Visual Stability: A proposed metric capturing quality degradation and over-exposure in long videos. "We propose a new metric, Visual Stability, designed to systematically capture both quality degradation and over-exposure"
- Windowed sampling: Selecting random contiguous segments from long rollouts for supervision or evaluation. "combined with a long-horizon rolling KV cache and windowed sampling"
Collections
Sign up for free to add this paper to one or more collections.

