- The paper introduces a training-free method that employs Deep Sink for robust temporal anchoring to mitigate error accumulation in long video sequences.
- The method leverages Participative Compression to selectively prune the KV cache, maintaining critical contextual cues for improved video quality.
- Experimental results show that Deep Forcing outperforms traditional training-dependent approaches on metrics like Dynamic Degree and consistency while preserving real-time throughput.
Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression
Introduction and Context
Autoregressive video diffusion models have advanced the fidelity and temporal coherence of short video synthesis, yet sustaining these properties for long-horizon, causal generation remains challenging due to severe error accumulation, context drift, and motion stalling. Prior approaches, notably Self Forcing, Rolling Forcing, and LongLive, combine custom attention mask strategies with KV cache management, but typically require domain-specific training or distillation. The "Deep Forcing" framework (2512.05081) directly addresses the limitations of such training-dependent policies. It introduces a training-free method for enabling long video generation via two complementary mechanisms: Deep Sink for robust temporal anchoring, and Participative Compression for adaptive KV cache pruning. This decouples scalable, high-quality video extrapolation from any requirement for model fine-tuning.
Methodology
Deep Sink: Enlarged, Temporally-Aware Attention Sinks
Analysis of attention distributions within pre-trained Self Forcing reveals that, contrary to assumptions from streaming LLM settings, the model's heads focus not only on initial tokens but on the entire context window, attributing significant attention mass to intermediate frames. Deep Sink capitalizes on this by persistently retaining approximately 50% of the sliding window as 'sink tokens,' forming a temporally deep anchor throughout generation. Temporal RoPE adjustment is further applied, realigning the sink tokens’ temporal indices at each autoregressive step to preserve temporal coherence—this avoids spectral artifacts (flicker, regression to prior content) associated with naïve sink retention.
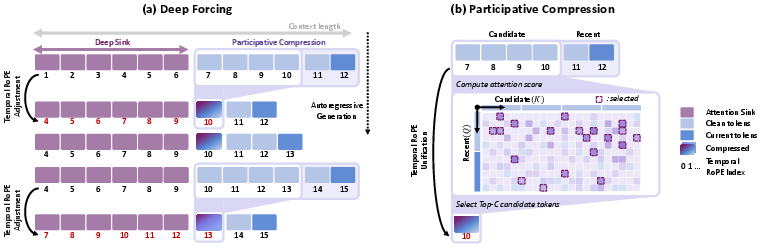
Figure 1: Architecture of Deep Forcing showing Deep Sink, large-sink ratio, participative compression, and temporal RoPE alignment.
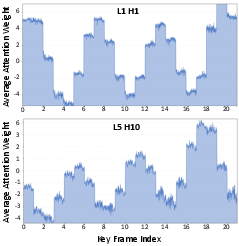
Figure 2: Visualization of query-averaged attention—heads in different layers consistently maintain non-negligible attention across the entire context window.
This shift in sink heuristics is substantiated by ablation studies: as sink size increases, aesthetic drift decreases and consistency improves, with optimal performance in the 10-15 frame range for standard 21-frame rolling windows.

Figure 3: Ablation on Deep Sink size—larger sinks robustly suppress aesthetic drift and elevate overall consistency.
Participative Compression: Query-Driven KV Cache Eviction
Simple FIFO or fixed-position eviction is suboptimal for maintaining critical temporal anchors in the KV cache as sequence lengths scale. Participative Compression ranks candidate tokens (excluding the deep sink and most recent frames) by their cumulative attention scores from the latest frames’ queries. Only the most 'participatory' (Top-C) tokens—those most actively attended—are preserved. This token-level pruning maintains contextual relevance for queries responsible for impending generation, while suppressing attention dilution from irrelevant, stale tokens. RoPE temporal adjustment is also applied to the Top-C block to ensure phase coherency across the cache.

Figure 4: Top-C token selection visualization—PC preserves semantically critical spatial regions for subsequent generation.
Detailed analysis demonstrates that this compression, applied only at the initial timestep of each denoising sequence and after full window saturation, introduces negligible computational overhead relative to gains in stability and quality.
Experimental Results
Quantitative evaluation is conducted under the VBench-Long protocol and user studies, including both conventional metrics—Dynamic Degree, Motion Smoothness, Imaging Quality, Consistency—and VLM-powered stability assessment. Deep Forcing achieves, and in several axes surpasses, state-of-the-art baselines, including methods trained with attention sinks (e.g., LongLive and Rolling Forcing):
- Dynamic Degree: 57.56 (vs. LongLive 45.55) for 30s generations.
- Imaging Quality and Consistency: On par or better than LongLive/Rolling Forcing, despite being training-free.
- Aesthetic Quality Drift: Significantly suppressed over long rollouts.
- Real-time throughput retention (15.75 FPS), with no measurable penalty relative to Self Forcing.
Ablation confirms the necessity of both components. Deep Sink alone mitigates color drift but residual artifacts persist. Full Deep Forcing (DS + PC) removes virtually all observable error accumulations, preserving both subject and background features.

Figure 5: Qualitative ablation—Deep Forcing eliminates degradation and drift found in baseline and partial variants.
User studies further validate superior perceptual quality, with Deep Forcing preferred over all baselines in color consistency, dynamic motion, subject consistency, and overall quality (e.g., 100% preference over CausVid, 87.9% over Self Forcing for overall quality).
Additional qualitative comparisons evidence stable, dynamic, and contextually consistent frame generation across 30 and 60-second horizons.

Figure 6: Frame-by-frame visual comparison over 30 seconds—Deep Forcing matches or outperforms training-based methods in temporal coherence and visual expressivity.

Figure 7: Qualitative results on 60-second videos—Deep Forcing maintains high visual consistency and avoids mode-collapse or subject drift.
Theoretical and Practical Implications
The efficacy of Deep Forcing indicates that pre-trained autoregressive video diffusion models have latent capacity for long-horizon generation, conditional on principled inference-time KV management—specifically, the combination of context-preserving, temporally phase-aligned deep sinks, and importance-aware token retention. This suggests that error accumulation and degeneration reflect not a model deficit, but primarily a cache-truncation and context-dilution artifact.
In practical terms, Deep Forcing redefines the requirements for long video generation: deployment on frozen backbones, training-free, with robust context tracking and real-time performance. For industry and large-scale generative systems, this enables scalable, dynamically extensible video generation without costly re-training or domain-specific distillation.
From a theoretical standpoint, this result invites further investigation into the emergent structure of video transformer attention and the generalization properties of attention sinks across modalities (LLM, vision, audio). Integration with hierarchical or persistent memory structures, as well as extension beyond strictly autoregressive settings, are clear directions for future work.
Conclusion
Deep Forcing presents a rigorous, theoretically principled, and empirically validated framework for enabling long-context autoregressive video generation without model re-training. By harmonizing Deep Sink—exploiting non-trivial attention anchoring in pre-trained networks—and Participative Compression—focusing context preservation where it matters most—the method establishes a new paradigm for efficient, stable, and state-of-the-art long video synthesis suitable for downstream interactive and generative applications. Limitations remain (e.g., lack of explicit external memory), but this work definitively demonstrates that inference-time cache policies, not just model architecture or dataset scale, are central to the long-form generative fidelity frontier.