- The paper introduces a Dual Memory KV Cache that decouples local motion history and global semantic anchors to overcome context limitations.
- It employs a Dual-Reference RoPE injection to decouple positional data, mitigating visual drift and ensuring robust semantic stability.
- The Asymmetric Proximity Recache mechanism enables smooth prompt transitions while maintaining long-term identity and scene consistency.
Grounded Forcing: Synergistic Memory and Positional Architectures for Long-Horizon Interactive Video Synthesis
Introduction and Motivation
Autoregressive video synthesis has emerged as a critical enabling technology for real-time, interactive world simulators and long-form video content creation. However, extending autoregressive models to infinite horizons introduces a triad of interlinked challenges: semantic forgetting due to limited context, visual drift from positional encoding extrapolation, and loss of interactive controllability during prompt switches. Existing solutions typically address these instabilities in isolation, leading to trade-offs between long-term coherence, fidelity, and user-driven control. "Grounded Forcing: Bridging Time-Independent Semantics and Proximal Dynamics in Autoregressive Video Synthesis" (2604.06939) proposes a unified framework that bridges these competing objectives, using interlocking architectural and algorithmic mechanisms designed to anchor high-level semantics while accommodating dynamic local interactions.

Figure 1: Grounded Forcing for Long-Horizon Interactive Video Generation. The method generates coherent and consistent one-minute videos with multiple characters across multi-scene narratives, supporting prompt switching and multi-shot transitions.
Methodology
Dual Memory Key-Value Cache: Decoupling Semantics and Motion
A key limiting factor in standard autoregressive video diffusion is context window size, which induces rapid semantic forgetting by discarding nonlocal frames. Prior works mitigate this via single persistent anchors (e.g., static first frame), but such solutions lack flexibility and adaptability under evolving semantics or dynamic prompts.
Grounded Forcing introduces a Dual Memory KV Cache, structurally partitioning memory into Local Temporal Memory (LTM) for sliding-window high-frequency motion history and Global Consistency Memory (GCM) for persistent identity and style anchors. The GCM is dynamically updated based on frame-level latent diversity, using cosine similarity metrics to admit only semantically novel anchors and evict redundant information, thus preserving a compact but comprehensive set of global semantic tokens even with evolving narrative contexts.
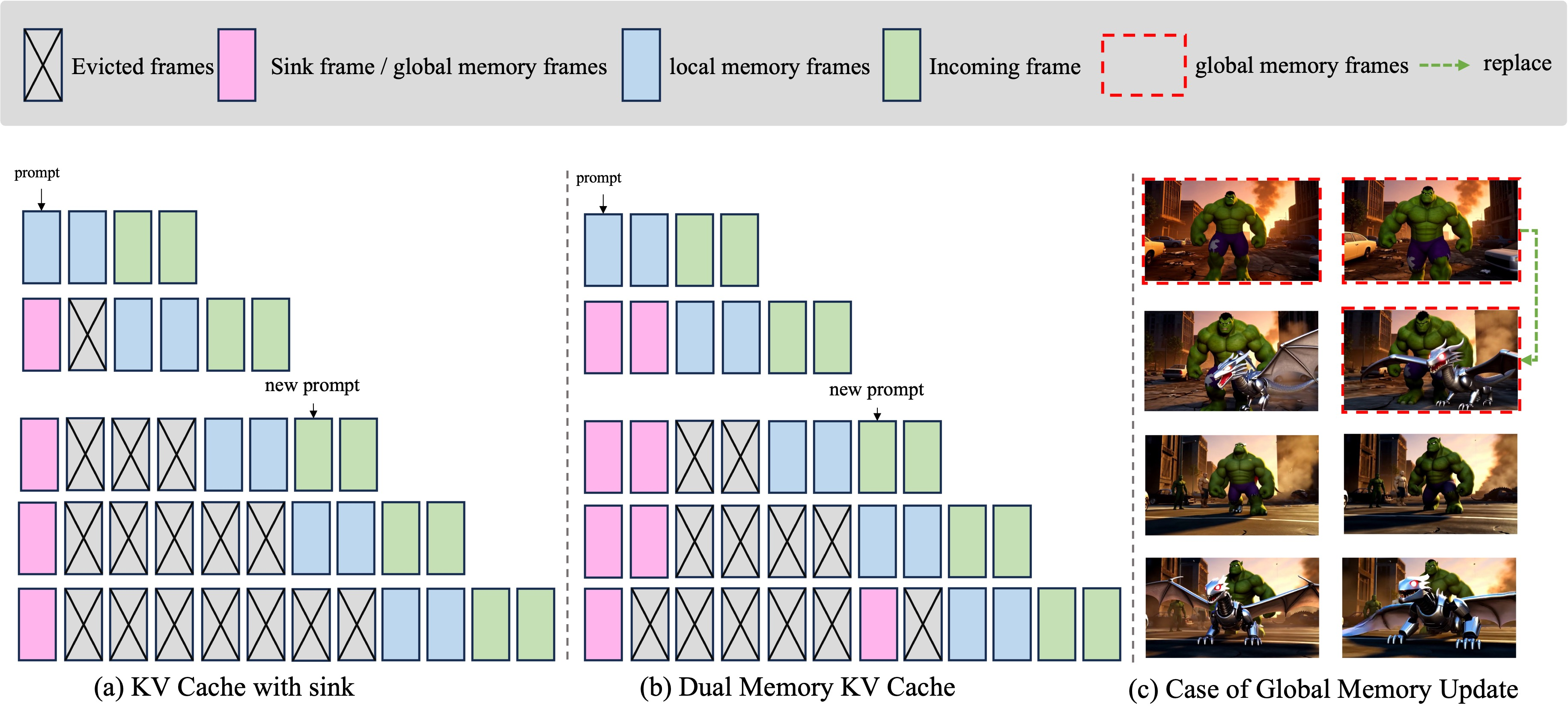
Figure 2: Dual Memory Mechanism. The model separates Local Temporal Memory (short-term dynamics) from Global Consistency Memory (long-term semantic anchors); the update mechanism ensures anchors map to evolving semantics rather than static initial states.
Dual-Reference Rotary Position Embedding Injection: Positional Stabilization
Standard RoPE-based Transformers are vulnerable to distribution shift in positional indices as the generation window extends beyond training limits, causing catastrophic visual drift and collapsed attention patterns. Existing fixes (e.g., Infinity-RoPE) only partially alleviate this, as they fail to anchor semantics during training.
In Grounded Forcing, positional information is decoupled at inference: keys are cached raw (pre-RoPE), and temporal indices are injected per access. GCM tokens are injected with a fixed RoPE index of zero, making them inherently position-invariant and suitable as timeless semantic anchors. LTM tokens utilize relative temporal indices, always remaining in-distribution for temporal dynamics. This design enables robust positional generalization and suppresses drift, supporting both long-horizon single-shot synthesis and multi-shot scene resets.
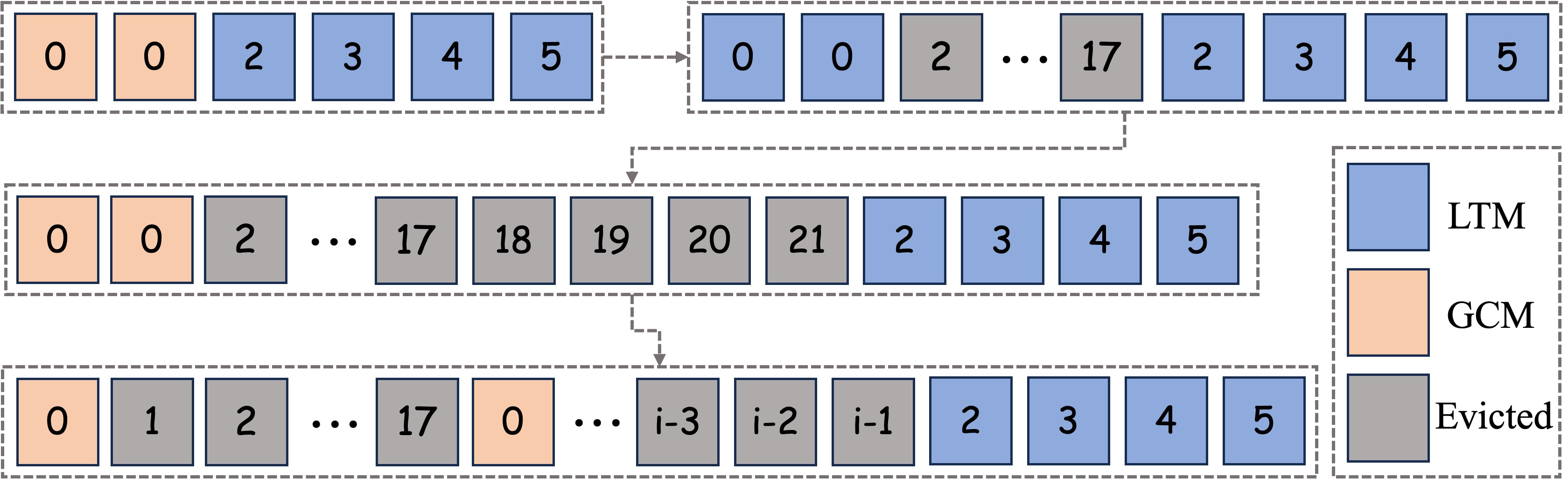
Figure 3: Dual-Reference RoPE Injection. GCM keys always receive RoPE index $0$ (orange), rendering them time-invariant, while LTM keys retain relative indices (blue); this preserves local motion fidelity and global semantic stability.
Asymmetric Proximity Recache: Gradient Semantic Bridging
Prompt or instruction switching in interactive video synthesis typically relies on uniform cache refresh (KV ReCache), which either erases too much historical context or inhibits incorporation of new semantics, leading to "semantic shock" or unresponsive generation. Grounded Forcing introduces Asymmetric Proximity Recache (APR): cache entries are refreshed with a proximity-weighted interpolation schedule, aggressively updating recent slots to reflect new prompts while retaining distant anchors to preserve long-range identity and context. The result is smooth, temporally coherent transitions during prompt switches and multi-shot compositions, eliminating abrupt semantic discontinuities.
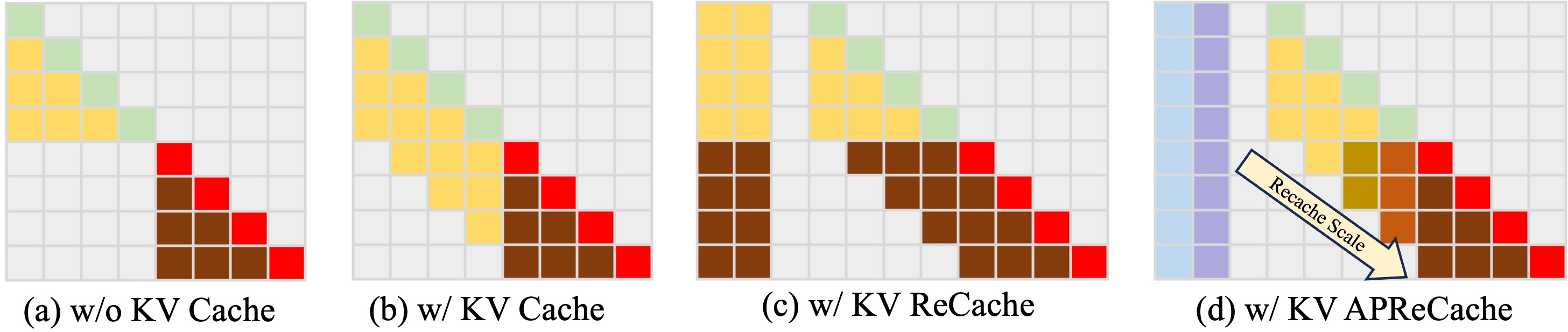
Figure 4: Asymmetric Proximity Recache (APR). Proximity-dependent cache scaling refreshes recent frames aggressively and retains distant frames for semantic inheritance, balancing prompt responsiveness and identity stability.
Empirical Evaluation
Quantitative Results
Grounded Forcing was implemented atop Wan2.1-T2V-1.3B and compared against LongLive, Rolling Forcing, and Infinity-RoPE under controlled conditions. On 240-second generation tasks, Grounded Forcing achieves best-in-class results in Background Consistency ($0.9265$) and Subject Consistency ($0.9163$), with improvement margins maintained across both short (5s, 60s) and long (240s) durations. Notably, the model sustains the highest dynamic degree (motion diversity) while suppressing temporal flickering, a regime where prior methods suffer from drift or instability.
Qualitative Analysis
Long-horizon visualizations demonstrate that Grounded Forcing robustly propagates identity and style across entity transformations and narrative expansions. In challenging multi-shot and prompt-switching sequences, the system maintains visual and semantic continuity even as prior models degrade into semantic confusion, exhibit identity drift, or hallucinate contextually irrelevant features.

Figure 5: Qualitative Comparison with Baselines. Grounded Forcing preserves character identity across multi-shot transitions and maintains smooth semantic adaptation with prompt switches, whereas baselines exhibit severe drift or abrupt visual changes.

Figure 6: Multi-shot generation with narrative continuity (60s). Character identity is preserved across scenes and camera angles, with GCM anchoring long-term semantics and APR enabling local prompt adaptation.

Figure 7: Single-prompt generation (240s). Identity and background consistency are preserved throughout minute-scale synthesis, with reduced drift relative to prior art.

Figure 8: Interactive Prompt Switching (60s). Grounded Forcing achieves smoother transition dynamics and higher content consistency under evolving user instructions.
Ablation and User Study
Ablation experiments isolate the contribution of each architectural component (Dual Memory, DR-RoPE, APR), demonstrating that performance in both subject and background consistency degrades significantly when any module is removed, especially during interactive prompt switching tasks. Further, user studies corroborate the empirical findings: Grounded Forcing is rated substantially higher in consistency, aesthetic quality, and prompt adherence compared to previous systems.
Implications and Future Directions
Practically, Grounded Forcing establishes a performant, efficient, and controllable pipeline for streaming video generation, enabling new applications in interactive story-telling, real-time simulation, and cinematic generation. Theoretically, the architectural decoupling of semantics and dynamics (via memory partitioning) and robust positional generalization (via dual-reference RoPE) provide a viable path toward infinite-horizon autoregressive synthesis beyond scale-limited diffusion architectures. Going forward, potential avenues include expanding GCM capacity for multi-entity scenarios, integrating richer multi-modal feedback channels, and augmenting hierarchical memory for multi-resolution narrative control. Incremental progress may further close the gap between simulated and realistic world models, facilitating dense, closed-loop agent-environment co-evolution and autonomous content design.
Conclusion
Grounded Forcing represents a systematic framework for autoregressive video synthesis that resolves the fundamental trade-offs of long-horizon semantic retention, positional robustness, and interactive controllability through synergistic architectural innovations. The demonstrated improvements in quantitative, qualitative, and user-perceived metrics mark a significant advance in the design of memory-efficient, infinitely extensible generative models, setting the foundation for the next generation of interactive visual AI systems.