- The paper proposes GHPO, which mitigates training instability through adaptive prompt refinement combined with imitation and reinforcement learning.
- It leverages automated difficulty detection and a multi-stage guidance approach to dynamically calibrate task difficulty based on model competence.
- Experimental results demonstrate a 5% performance gain across benchmarks and smoother optimization dynamics compared to traditional methods.
GHPO: Adaptive Guidance for Stable and Efficient LLM Reinforcement Learning
This paper introduces Guided Hybrid Policy Optimization (GHPO), a novel framework designed to address the challenges of training instability and inefficiency in Reinforcement Learning with Verifiable Rewards (RLVR) for LLMs. The method dynamically adjusts task difficulty through adaptive prompt refinement, balancing imitation learning and exploration-based RL, leading to improved training stability, sample efficiency, and overall performance in complex reasoning tasks.
Motivation and Problem Statement
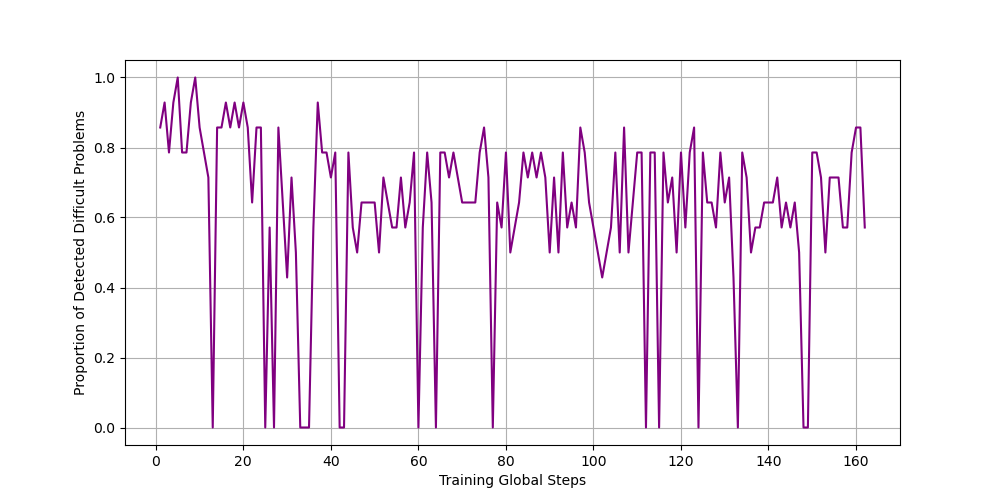
Current on-policy RLVR methods like GRPO suffer from training instability and inefficiency due to a capacity-difficulty mismatch, resulting in reward sparsity and suboptimal sample efficiency. The authors identify that the inherent difficulty of training data often exceeds the model's capabilities, leading to sparse reward signals and stalled learning progress, especially for smaller LLMs. To mitigate these issues, the paper proposes GHPO, which adaptively calibrates task difficulty by employing prompt refinement to provide targeted guidance.
Guided Hybrid Policy Optimization (GHPO) Framework
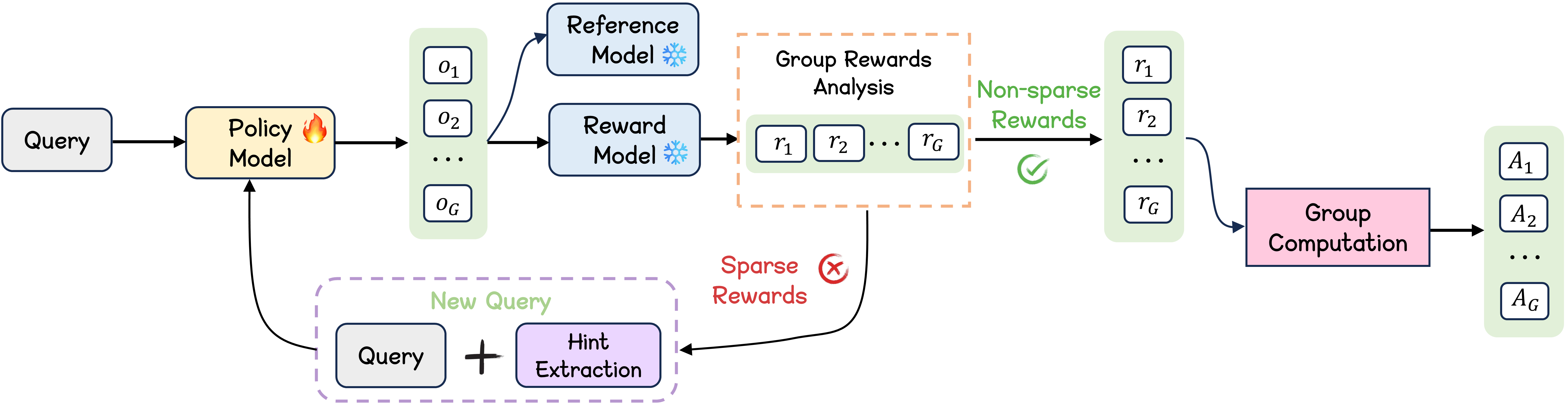
Figure 1: A visual representation of the GHPO framework, highlighting the automated difficulty detection and adaptive prompt refinement modules.
GHPO combines online RL and imitation learning within a unified framework, using a dynamic mechanism to assess sample difficulty and then employs adaptive prompt refinement to provide varying levels of guidance. For problems the model can likely handle, GHPO primarily uses standard on-policy RL. But for more challenging samples, it shifts to a form of imitation learning by offering explicit solution traces. The framework comprises two core modules:
- Automated Difficulty Detection: Assesses the inherent difficulty of the current problem to determine the subsequent learning process.
- Adaptive Prompt Refinement: Based on the detected difficulty, this module adaptively refines the prompt by incorporating different levels of ground truth guidance.
The GHPO method employs a dynamic data augmentation strategy. As the policy model's capabilities improve throughout the learning process, queries that initially required a high hint ratio ω may eventually need only a lower level of guidance, or even no guidance at all.
Implementation Details
In the GHPO framework, hints are extracted from the ground-truth solution and appended to the input problem with a guiding sentence: "The following text is the beginning part of the answer, which you can refer to for solving the problem:". The hint ratio ω is dynamically adjusted using a multi-stage guidance approach with a linear schedule. In the experiments, a maximum of three stages with ω={0.25,0.5,0.75} are used.

Figure 2: This figure illustrates the application of GHPO to address a difficult problem by extracting 50\% of the ground truth solution as a hint.
The paper also introduces an optional cold-start strategy where, for the first N optimization steps, the difficulty detection mechanism is temporarily disabled, and the original GRPO training process is applied. This allows the model to develop fundamental formatting capabilities and prevents the introduction of early bias before adaptive guidance is implemented.
Experimental Results
The authors conduct extensive experiments on six mathematics benchmarks, demonstrating that GHPO outperforms state-of-the-art RL methods and baselines like curriculum learning.
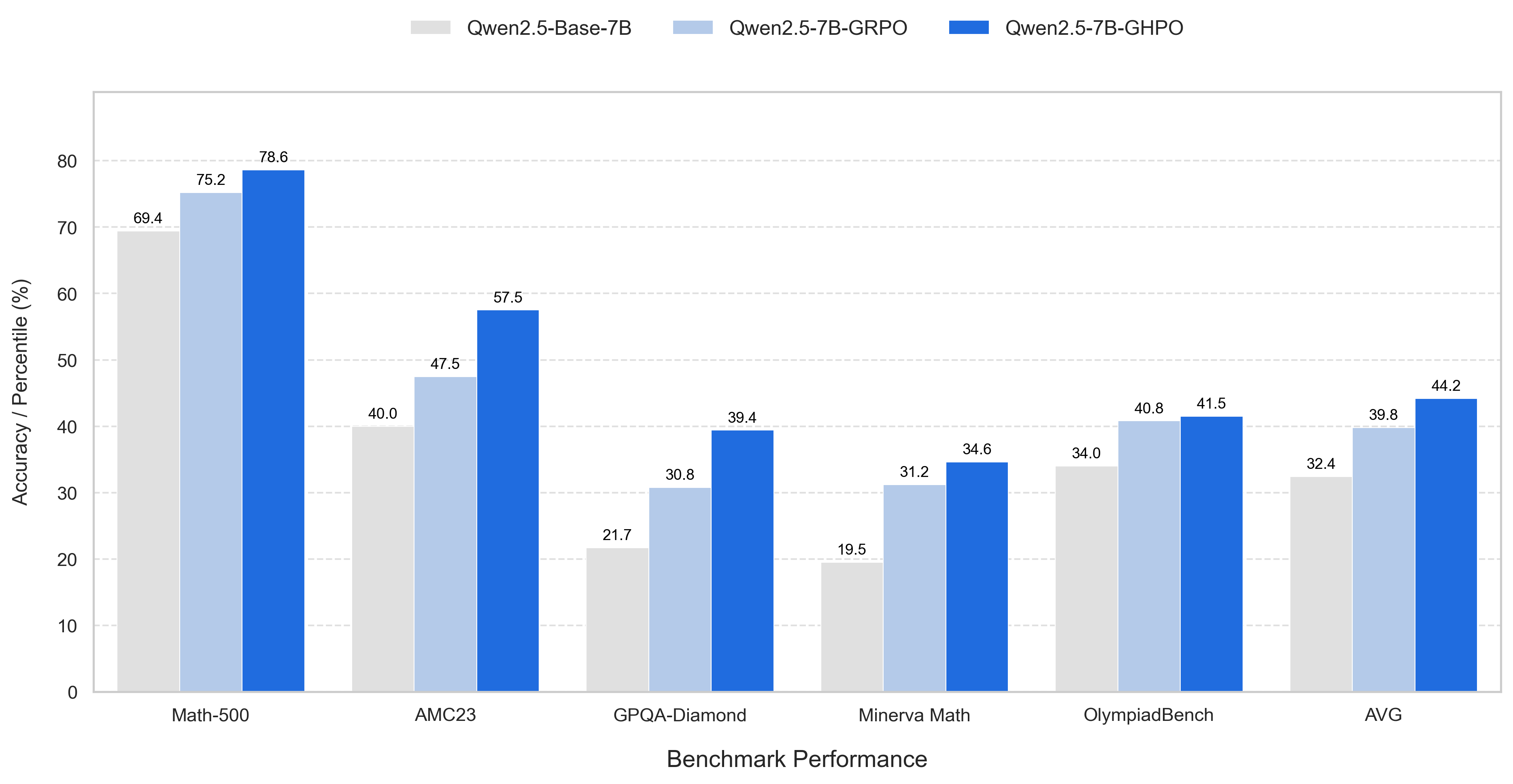
Figure 3: The bar chart compares the performance of GHPO against other models across various benchmarks, highlighting GHPO's superior performance.
Key findings include:
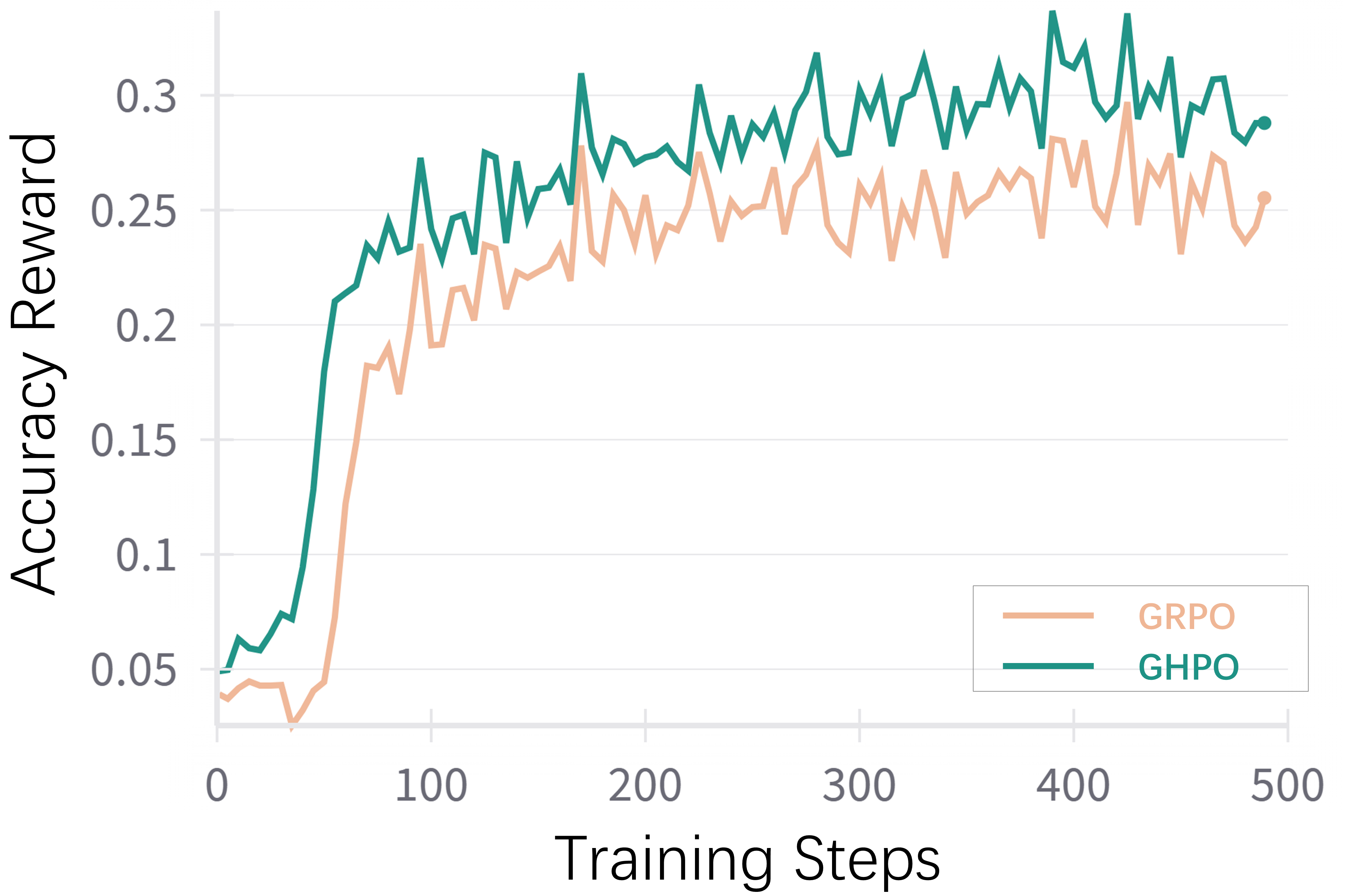
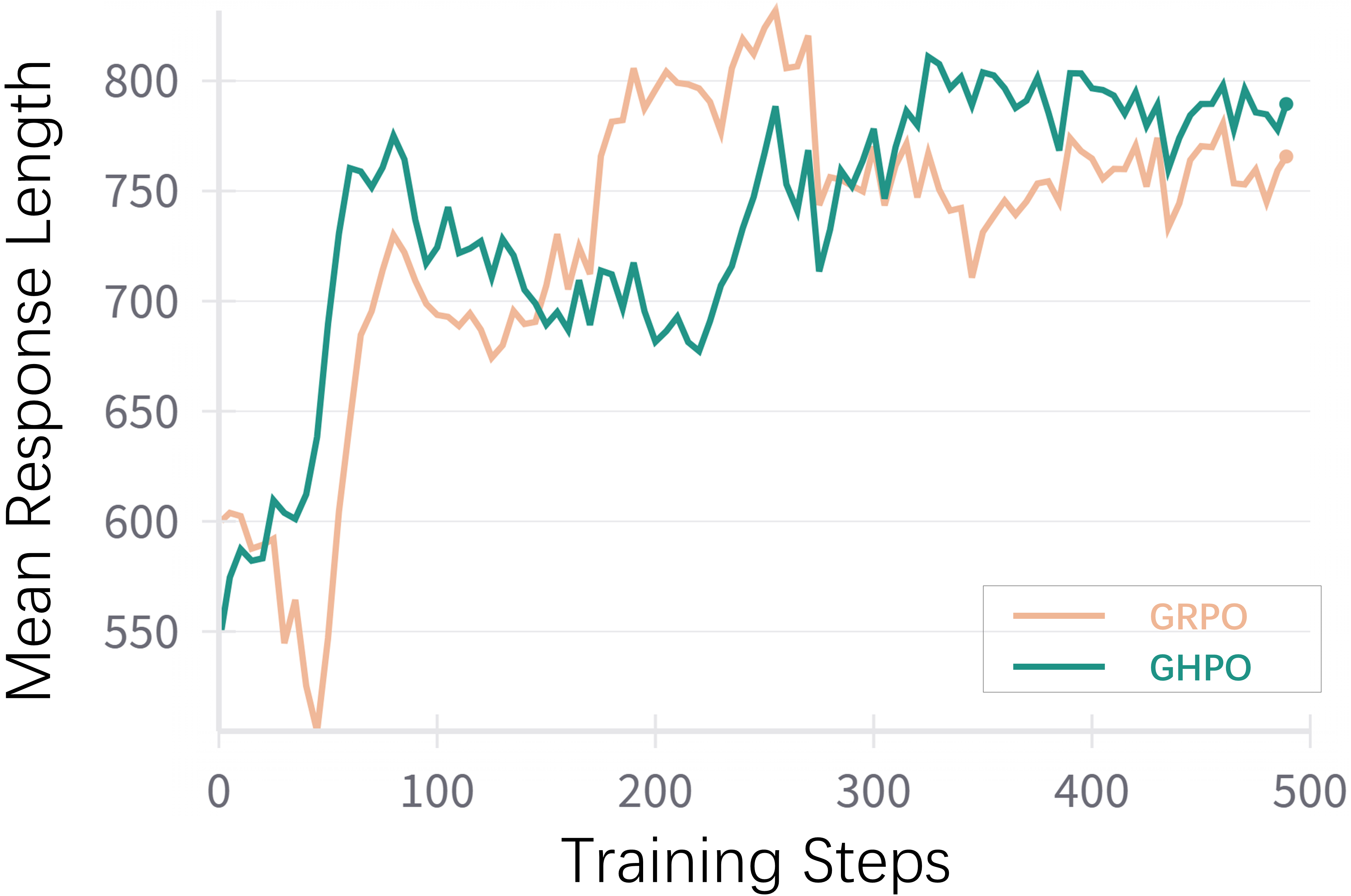
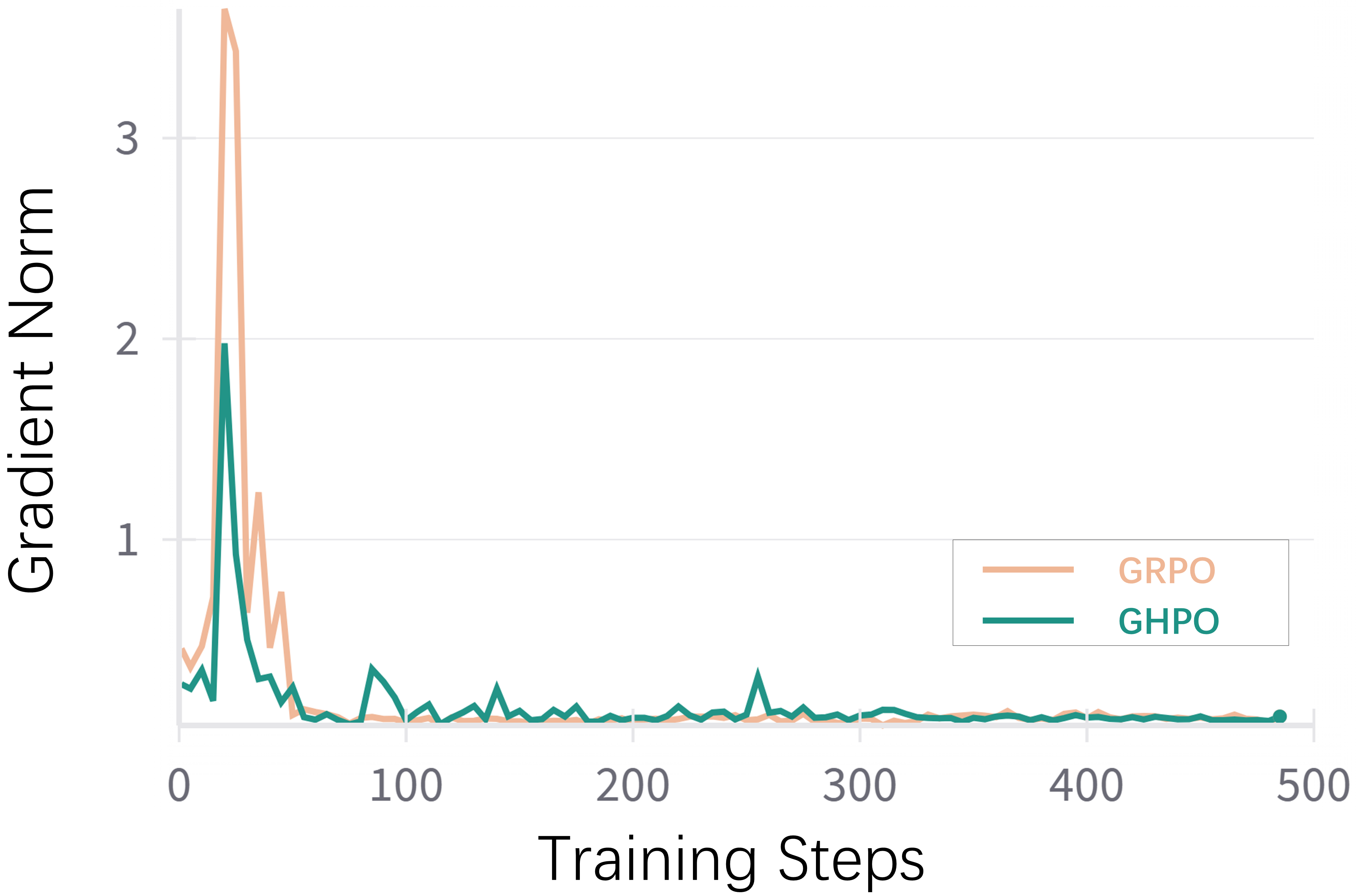
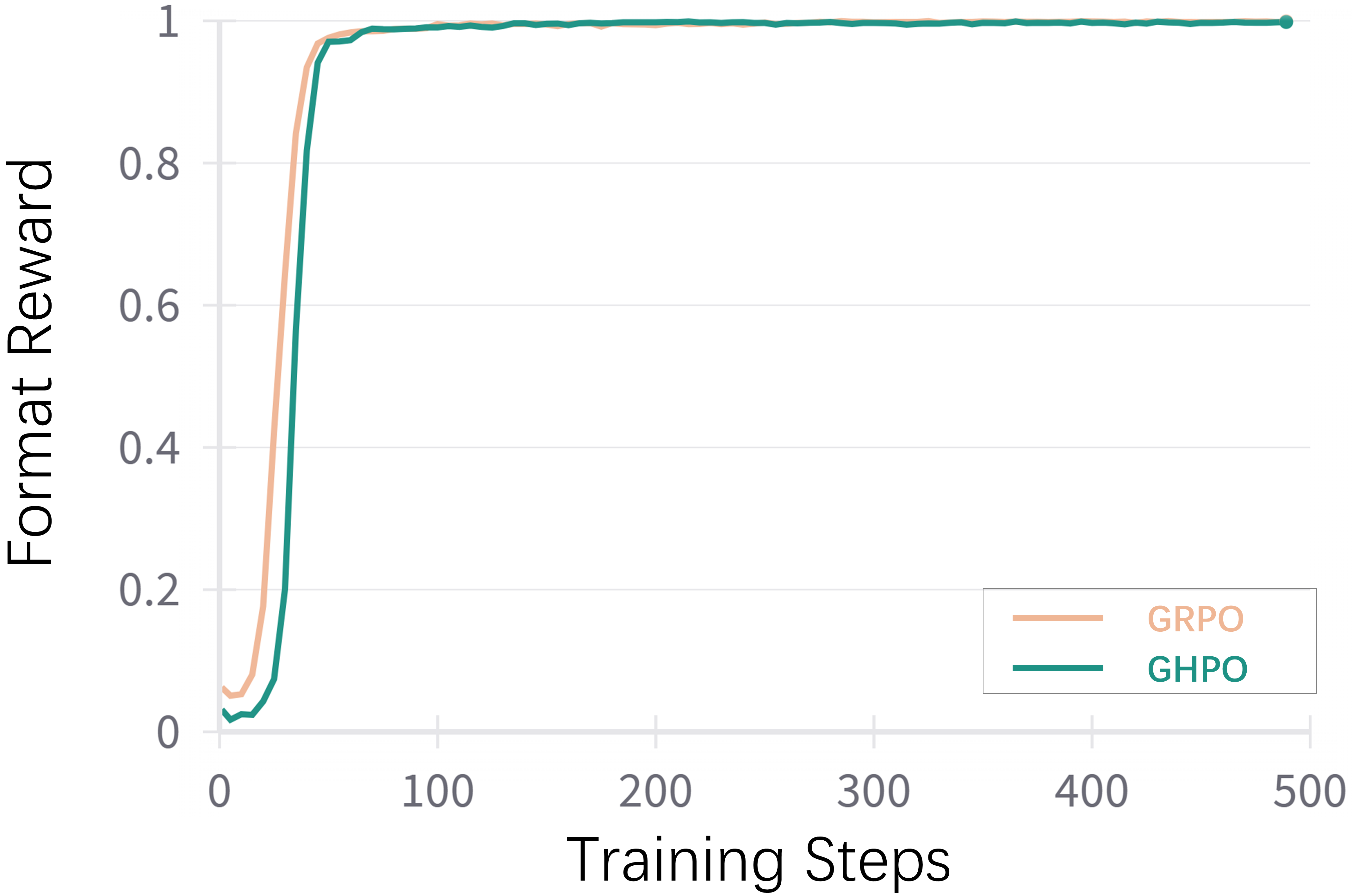
Figure 5: This figure displays the format reward during training.
The training dynamics analysis reveals that GHPO maintains smaller gradient magnitudes compared to GRPO, indicating a smoother and more stable optimization process. GHPO also generates longer responses than GRPO in later stages, suggesting an enhanced capacity to construct more detailed and elaborate reasoning processes.
Implications and Future Work
The GHPO framework offers a practical and scalable solution for developing powerful reasoning LLMs by intelligently adapting the learning process to the model's evolving capabilities, leading to more stable and effective RL fine-tuning. The adaptive guidance mechanism effectively complements even advanced pre-training, enabling more efficient and effective fine-tuning for complex reasoning tasks. Future work could explore extending GHPO to other complex reasoning tasks and investigating alternative difficulty detection and prompt refinement strategies.
Conclusion
This paper presents a compelling approach to address the challenges of training instability and inefficiency in RLVR for LLMs. The GHPO framework's ability to dynamically calibrate task difficulty through adaptive prompt refinement leads to significant performance gains and improved training stability. The results demonstrate the effectiveness and robustness of GHPO, offering a promising direction for developing powerful and robust reasoning models.