- The paper demonstrates a generative approach that synthesizes future visual frames to offset communication latency in vision-based teleoperation.
- It reveals that the LTX-2B distilled model outperforms larger variants and diffusion-based models by achieving lower MAD and enhanced temporal consistency.
- Despite promising accuracy, none of the models meet the strict 15 FPS requirement, highlighting the need for domain-specific optimization and real-time performance improvements.
Zero-Shot Benchmarking of Generative Video Models for Predictive Display in Vision-Based Teleoperation
Communication latency imposes a fundamental constraint on vision-based teleoperation systems, degrading operator situational awareness and control fidelity. While classical predictive displays primarily employ kinematic or motion overlay techniques, the paper proposes a generative approach: directly synthesizing future visual observations as short-horizon rollouts conditioned on recently received frames. Specifically, the predictive display objective is formulated as a future-frame prediction task, where a generative video model produces a sequence of frames aligned with current teleoperation time, compensating for dynamic network latency.
Quantitative evaluation emphasizes both pixel-level fidelity (mean absolute difference, MAD), temporal consistency across the rollout, inference speed, and peak GPU memory consumption. The system-level constraint requires that predictive display inference completes within the frame interval (Tinf<Tframe for per-frame streaming or Troll<KTframe for rollout-and-replay), with practical deployment needing real-time operability and consistent short-horizon prediction.
Prior work in predictive display mainly falls into two categories: (1) geometric/kinematic renderings and visual overlays and (2) task-specific future frame synthesis using GANs, RNNs, or LSTMs. While recent advances in generative video modeling—especially transformer-based and diffusion-based architectures—have enabled visually coherent synthesis, the alignment between such general-purpose models and short-horizon predictive display requirements under latency remains untested. The paper identifies the absence of unified, empirical evaluation of off-the-shelf generative video models for predictive display, particularly regarding both temporal error dynamics and real-time feasibility.
Benchmark Design and Evaluation Protocol
The benchmark targets zero-shot predictive display in teleoperation, using CARLA-simulated driving data with diverse motion patterns and scene layouts. Five model families are tested: LTX-Video (2B distilled/13B), Stable Video Diffusion (SVD 1.1), Wan VACE 1.3B, and Wan I2V 1.3B, spanning transformer and diffusion architectures and both single-frame and multi-frame conditioning regimes. Each model receives 9 observed frames as conditioning and generates 8 future frames per clip, evaluated at two spatial resolutions (256×160 and 512×320), representative of teleoperation bandwidth constraints.
Inference is standardized to warm-GPU runs on a single RTX 6000 Ada, measuring per-frame and end-to-end rollout latency. MAD metrics are computed both per timestep and as aggregate across the 8-frame rollout, with qualitative inspection highlighting temporal and spatial consistency.
Quantitative Analysis and Contradictory Findings
Aggregated numerical results show that the LTX family consistently delivers the lowest MAD error. Notably, the LTX-2B distilled variant outperforms the larger LTX-13B model at both resolutions (e.g., 14.23 vs. 22.34 MAD at 256×160; 11.55 vs. 19.57 at 512×320). This contradicts expectations about monotonic improvement with model scale, suggesting that distillation and sampling-step choices in LTX-2B produce more deterministic and temporally aligned predictions in the short-horizon context.
Diffusion-based models (SVD, Wan VACE/I2V) exhibit substantially higher MAD error and unstable temporal behavior. SVD, while offering the fastest runtime ($1.31$–$1.54$ sec/frame), is associated with MAD exceeding 78 (256×160) and 83 (512×320), manifesting convergent drift toward generic, low-frequency scene representations rather than accurate future frame synthesis.
No evaluated model achieves the combined requirements of low MAD, stable rollout error, and real-time inference at the 15 FPS frame rate (66.7 ms/frame). Best-performing models remain over 20x slower than the frame budget per generated frame.
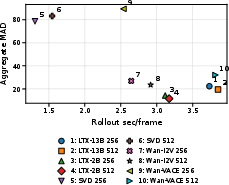
Figure 1: Tradeoff between prediction accuracy (MAD) and inference time across models and resolutions; no configuration achieves both low error and real-time performance.
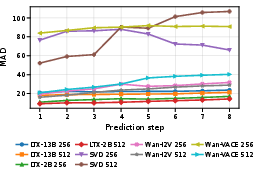
Figure 2: Temporal rollout error across prediction steps, highlighting stability of LTX models and divergent error patterns in diffusion-based architectures.
Qualitative Results and Temporal Consistency
Qualitative inspection further reinforces the lag between general-purpose generative models and predictive display requirements. LTX variants maintain scene layout and object structure over 8-step rollouts, with mild blur but temporal coherence. SVD deviates quickly, particularly in dynamic regions and at higher resolutions, showing fragmented, unrealistic patterns. Wan I2V achieves intermediate structural fidelity but demonstrates steady drift as prediction horizon increases. Wan VACE shows strong artifacts and unstable predictions, revealing persistent challenges for multi-frame conditioning in predictive contexts.

Figure 3: Qualitative comparison for a representative urban driving clip; LTX models preserve scene structure while diffusion models manifest rapid degradation.

Figure 4: Qualitative comparison in dynamic scenes; spatial and temporal inconsistencies are pronounced in diffusion-based predictions.
Discussion, Implications, and Limitations
The empirical evidence establishes a gap between generative video modeling and practical predictive display for teleoperation. Visual realism is insufficient—models must exhibit temporal accuracy and operate within stringent compute constraints. The reversal in LTX model performance as a function of scale, and the failure of diffusion models to maintain temporal consistency, indicate that architectural decisions for general video synthesis do not necessarily serve predictive display. Per-step analysis is essential; aggregate MAD can mask temporal drift and mode collapse, as seen in SVD’s low-resolution convergence.
For deployment, practical use will require in-domain adaptation through fine-tuning or distillation, aggressive inference optimization (quantization, custom samplers, or TensorRT), and potentially bespoke architectures that prioritize low-latency, temporally coherent rollout generation. Classical next-frame predictors or lightweight warping baselines should be re-visited in comprehensive teleoperation studies.
Domain limitations include zero-shot evaluation, pixel-level MAD metrics only, simulator environments, and bundled conditioning vs. architecture effects. Real-world video and closed-loop teleoperation studies are needed to align intrinsic metrics with operator outcomes and to validate predictive display utility.
Conclusion
Off-the-shelf generative video models, in their zero-shot configurations, do not satisfy the combined requirements of low short-horizon error, temporal consistency, and real-time inference for vision-based teleoperation predictive display. Scaling models or increasing resolution does not guarantee improvement and can exacerbate instability; temporal error analysis reveals model failure modes masked by aggregate error. Bridging this gap will require targeted architectural and deployment adaptations, in-domain temporal supervision, and more rigorous evaluation protocols aligned with teleoperation operator needs. These findings motivate future research in fast, temporally stable, and domain-adapted generative video modeling for predictive display applications.

