Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Abstract: Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: can modern video-generating AI models do real problem‑solving just by “thinking” through a video, without extra training? The authors focus on a powerful video model called Veo‑3 and test whether it can reason step‑by‑step across frames, a process they call “Chain‑of‑Frame (CoF)” reasoning. They build a new test set, called MME‑CoF, to check different kinds of visual reasoning, like understanding space, geometry, physics, and more.
Key Questions
The study looks at questions like:
- Can video models solve visual puzzles or tasks without being specially trained for them (“zero-shot”)?
- Do they keep track of cause and effect over time in a video, not just make things look realistic?
- Which kinds of reasoning do they handle well, and where do they break down?
How Did They Study It?
To answer these questions, the researchers created a compact benchmark (a standardized test set) named MME‑CoF and ran controlled experiments. Here’s how it worked:
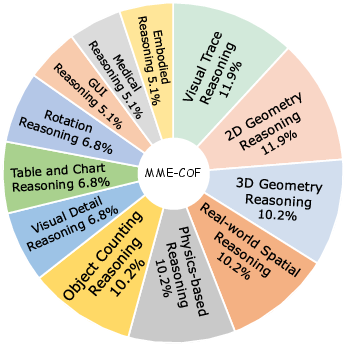
- They chose 12 types of visual reasoning to test, such as: noticing tiny details, following paths (like mazes), real‑world spatial layouts, 2D/3D geometry (drawing shapes or folding nets), physics (collisions and motion), rotation, charts/tables, counting objects, GUI clicking, and more.
- For each task, they carefully wrote clear video prompts that:
- Keep the camera steady unless movement is needed.
- State exactly what should change (or not) in the scene.
- Avoid giving away the answer using text; the solution must be shown visually.
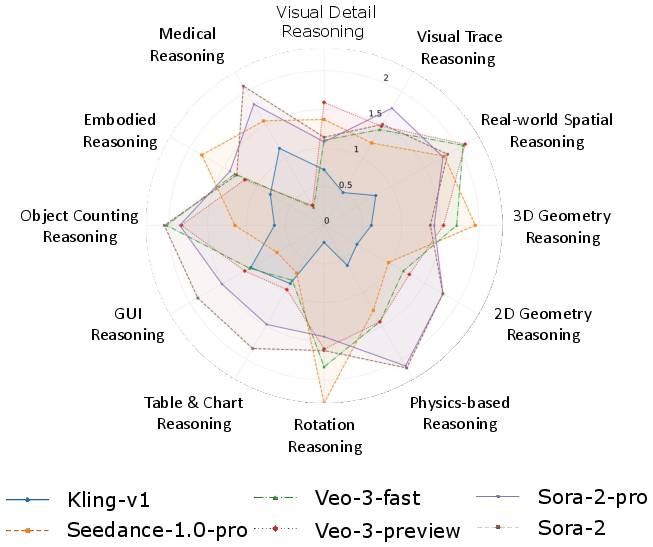
- They asked video models (mainly Veo‑3, plus others like Sora‑2, Kling, and Seedance) to generate short videos in a “zero-shot” way—meaning no extra training for the specific tasks.
- They judged the outputs in three simple levels:
- Good: clear, correct, and stable over time.
- Moderate: roughly correct but with small mistakes or instability.
- Bad: wrong or too messy to understand.
- They also measured a “success rate,” meaning how often the model gets a task right across multiple tries.
Think of CoF reasoning like a comic strip: each frame builds on the previous one. The model “reasons” by changing the scene step‑by‑step over time.
Main Findings
Big picture: today’s video models are strong at making realistic, smooth videos and show some early signs of reasoning—but they’re not yet reliable problem‑solvers on their own. More detail:
- What they do well:
- Short‑term spatial consistency: they keep objects and layouts steady over a few seconds and can focus on clear, big targets.
- Fine‑grained grounding (sometimes): they can highlight the right area when the scene is simple and the target is obvious.
- Locally consistent motion: they make motions look smooth and believable in the short term (like a ball bouncing or a small rotation).
- Where they struggle:
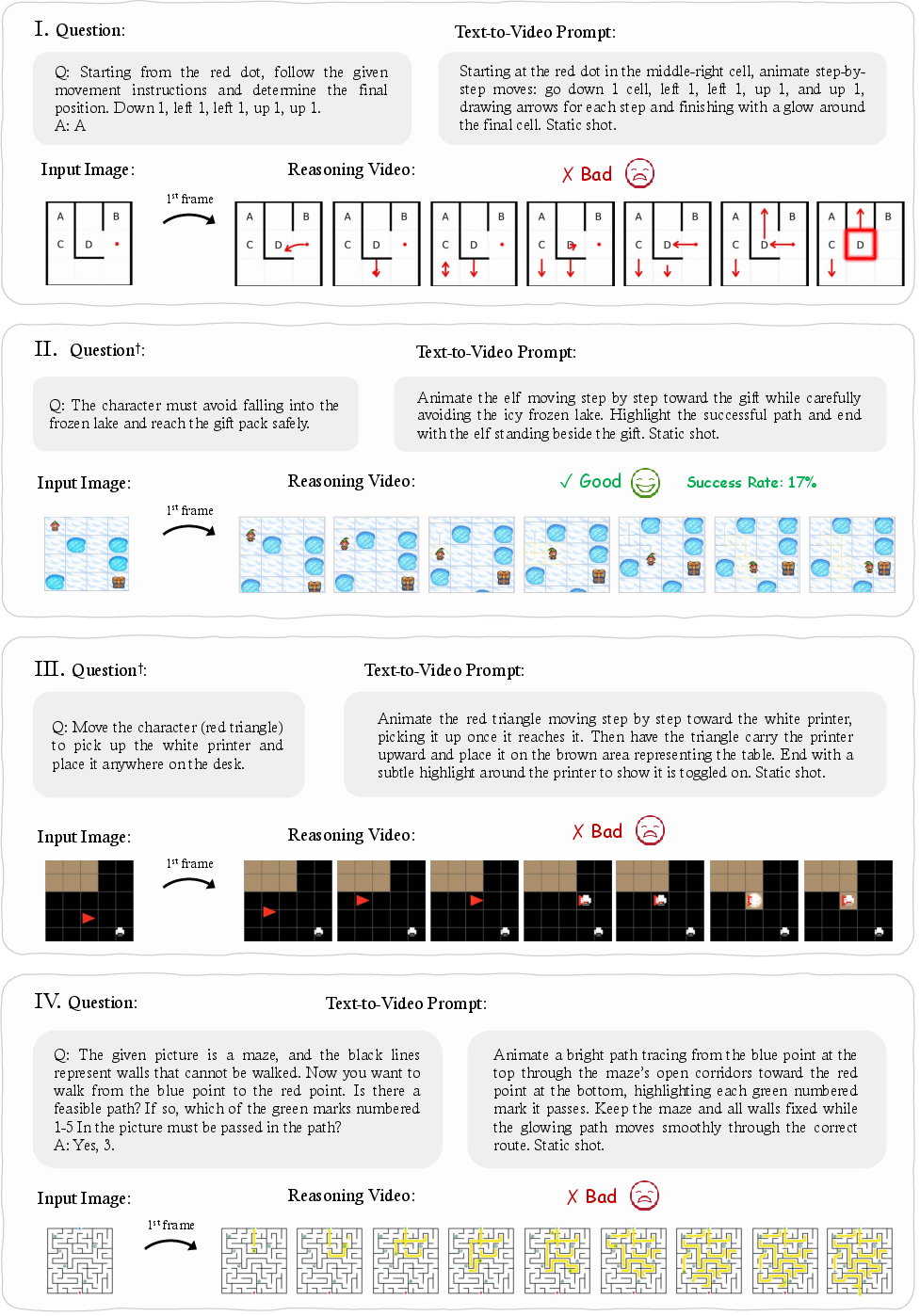
- Long‑term planning: they often fail multi-step tasks like maze navigation or sequences that require careful order.
- Strict geometry: they misdraw shapes, fold 3D nets incorrectly, or create impossible structures (like parts intersecting).
- Physics and causality: they make motion look good but break rules (wrong speeds, energy conservation, or cause-and-effect).
- Abstract logic: tasks that require following rules (like exact rotations on a flat plane, or connecting points in a specific order) often go wrong.
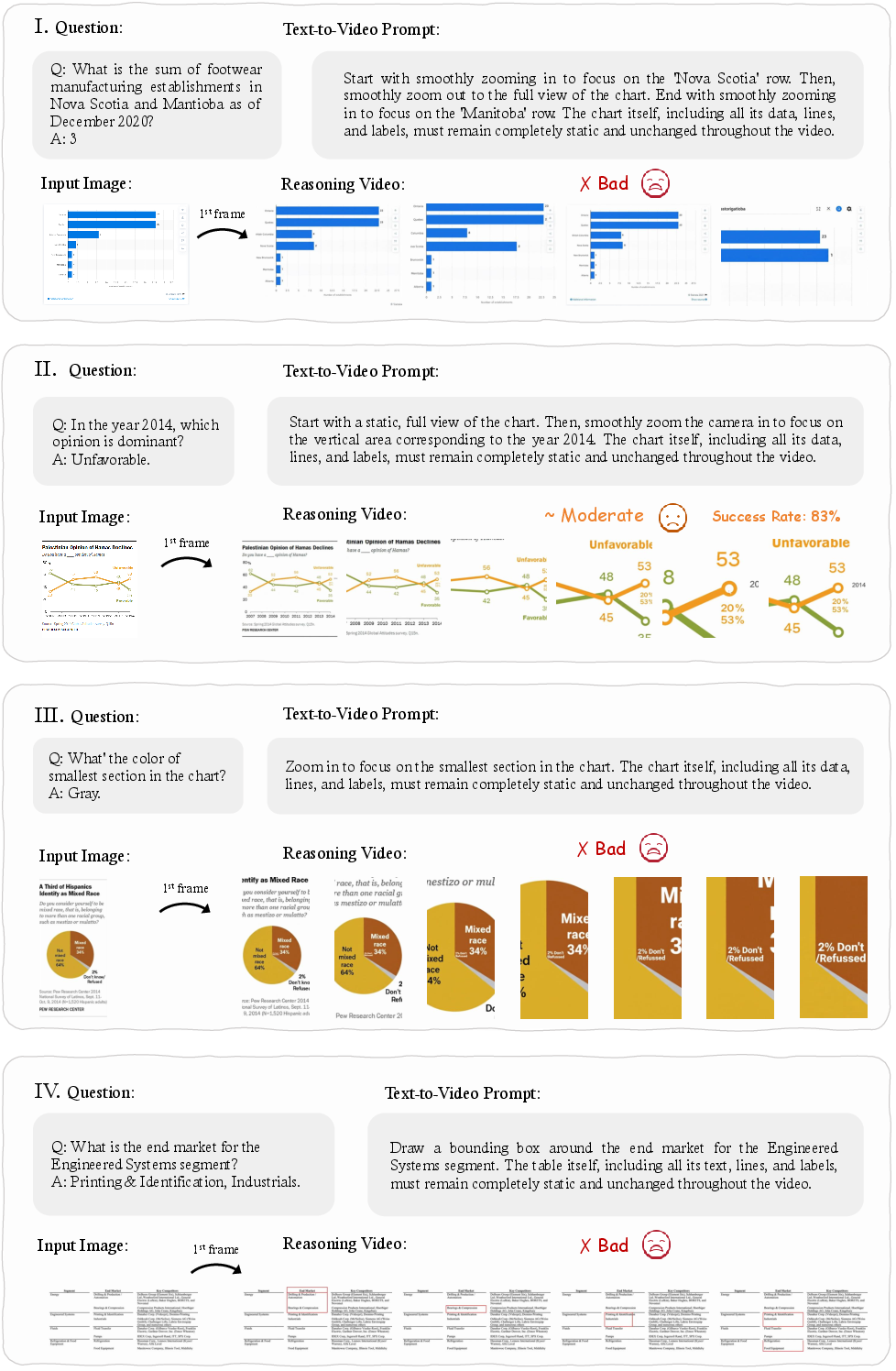
- Structured data: with charts and tables, they zoom roughly to the right spot but miss exact numbers or distort elements.
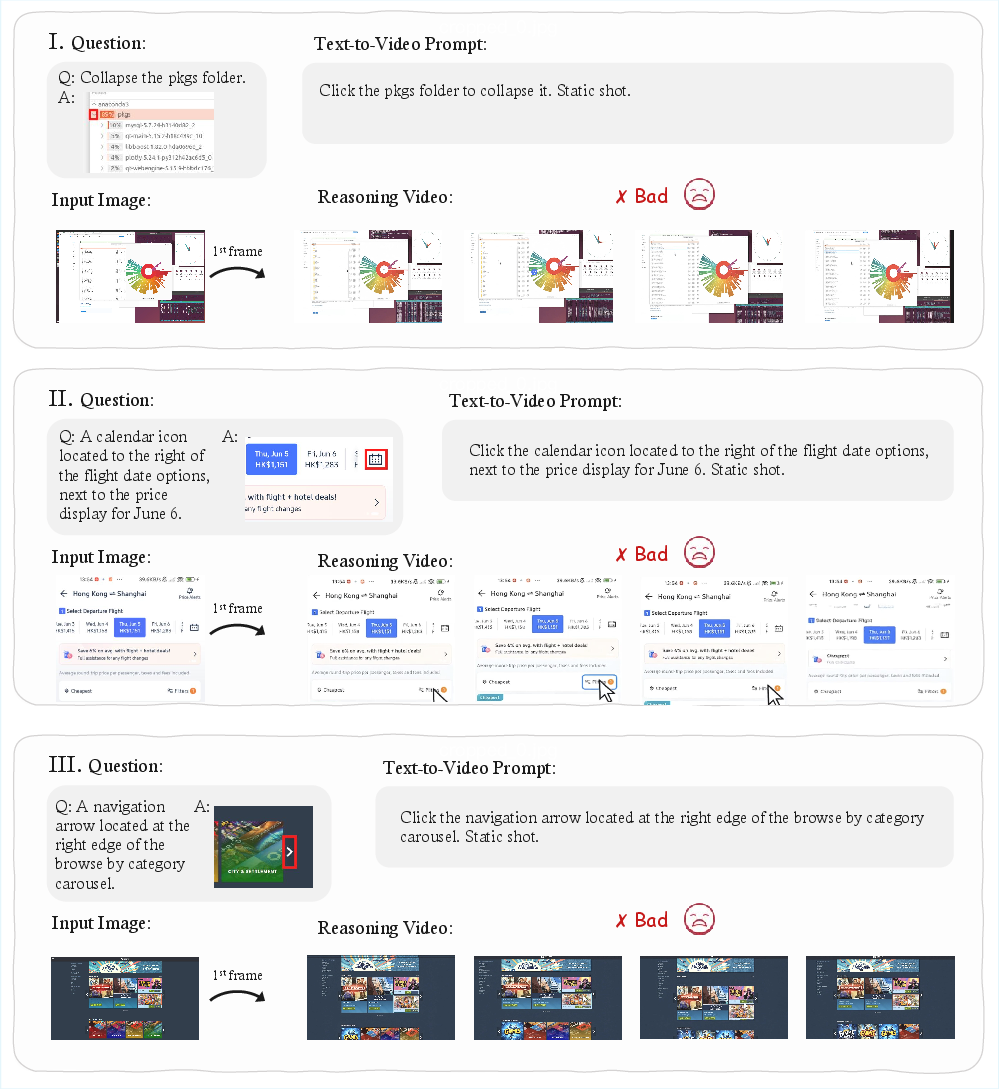
- Counting and GUIs: camera drift, object changes, or random clicks reduce accuracy and reliability.
In short, they can mimic patterns and produce visually pleasing videos, but that doesn’t mean they truly “understand” what’s happening over time or obey strict rules.
Why This Matters
- Video models aren’t ready to be standalone “zero-shot reasoners” yet. If you need accurate problem‑solving—like reliable geometry, physics, or multi-step logic—they still miss too often.
- However, they show promise as “visual engines.” Paired with dedicated reasoning models (like LLMs trained to think logically), they could become more powerful: the video model handles realistic visuals; the reasoning model checks rules, logic, and steps.
- The MME‑CoF benchmark gives researchers a standard way to test and improve these skills. With better training, clearer prompts, or combined systems, future video models might handle longer, smarter sequences and stronger rule‑based tasks.
Overall, the study shines a light on what video models can and cannot do today, helping guide the next steps toward AI that not only looks real but also reasons reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and its MME-CoF study:
- Reproducibility and transparency: lack of detailed release of prompts, seeds, sampling parameters (e.g., temperature, guidance), and post-processing scripts needed to exactly reproduce results across models and trials.
- Inter-rater reliability: no report of annotator agreement, calibration, or adjudication protocol for the green/orange/red ratings across categories.
- Statistical rigor: small sample size per case (6 videos) with no confidence intervals, significance testing, or power analysis; unclear robustness of reported success rates.
- Automatic metrics: heavy reliance on qualitative judgments; missing quantitative, task-specific metrics (e.g., IoU for localization, angle/length error for geometry, kinematic error for physics, click accuracy for GUI).
- Ground truth specification: unclear availability of explicit, machine-checkable ground truths for each case after conversion from image/QA datasets to video-generation tasks.
- Data leakage risk: no analysis of potential training exposure of closed models (e.g., Veo-3, Sora-2) to benchmark content or near-duplicates; no preventative auditing.
- Model comparability: most deep-dive analyses emphasize Veo-3; limited head-to-head, controlled comparisons across architectures and decoding regimes (diffusion vs autoregressive; CFG scales; sampler choices).
- Prompt sensitivity: no ablations on paraphrasing, negative prompts, instruction structure, or language variants to measure prompt-induced variance in “reasoning.”
- Camera-control confound: evaluation expects static shots but models often violate this; relaxing criteria may conflate camera-following skill with reasoning ability; no controlled tests that isolate this factor.
- Duration and horizon limits: all videos are short (8 s, 24 FPS); no systematic study of longer horizons, variable frame rates, or curricula that stress long-term causal consistency.
- CoF mechanism opacity: “Chain-of-Frame” is hypothesized but not operationalized; no attempt to extract, quantify, or causally test intermediate visual “reasoning steps” within the generative process.
- Causal diagnostics: no counterfactual or intervention-based tests (e.g., small perturbations in initial frames or environment) to discern pattern replay from genuine causal reasoning.
- Task coverage gaps: limited treatment of social/common-sense reasoning, multi-agent interactions, math word problems with visual constraints, or embodied tasks that require tool use and memory.
- Multilingual and modality breadth: prompts are English-only; no tests on multilingual instructions or audio-conditioned reasoning (e.g., narration-guided CoF).
- Physics evaluation: qualitative judgments dominate; missing quantitative checks of conservation (energy/momentum), force/torque consistency, contact/friction models, and trajectory deviation metrics.
- Geometry evaluation: no geometric error computation (e.g., angle, parallelism, planarity, self-intersection counts, topological consistency) to precisely diagnose failure modes.
- Chart/table rigor: lack of OCR fidelity checks, text-edit distance, cell/region IoU, and value extraction accuracy; frequent chart/table distortion remains unmeasured.
- Counting metrics: no standardized counting precision/recall, occlusion robustness tests, or protocols for handling motion-induced duplicates/misses.
- GUI interaction validity: no state-transition verification (pre/post conditions), temporal alignment checks, or task success criteria beyond a bounding-box click notion.
- Generalization and OOD: no tests for out-of-distribution prompts/scenes, compositional generalization, or transfer from synthetic to real-world footage.
- Ablations on training signals: no exploration of whether adding structural priors (3D inductive biases), physics-informed training, or supervised intermediate states improves CoF reasoning.
- Planner-controller integration: the paper posits video models as “visual engines” but does not evaluate pipelines that combine planners (MLLMs) with video generators for closed-loop reasoning.
- Memory and persistence: no experiments on memory-augmented generation (e.g., key-frame anchoring, scene graphs) to mitigate long-horizon drift and object identity swaps.
- Safety and bias: no assessment of demographic or content biases, harmful failure modes (e.g., unsafe GUI actions), or hallucinations with safety implications.
- Compute and efficiency: no profiling of inference cost vs. reasoning quality (e.g., sampling steps, resolution), or guidelines for practical deployment trade-offs.
- Benchmark validity after reformulation: many source datasets are repurposed from static QA to generative video; no human-baseline validation that the converted tasks preserve original difficulty and intent.
- Uncertainty calibration: no method for the model to signal confidence or abstain when reasoning is fragile; no correlation between variability across 6 samples and epistemic uncertainty.
- Invariance tests: absent evaluations of robustness to irrelevant changes (lighting, textures, distractors) or camera perturbations under the same reasoning specification.
- Open-sourcing of MME-CoF: unclear extent of public availability and licensing of the benchmark, evaluation code, and assets needed for community-wide, standardized testing.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s findings and resources while respecting current limitations.
- MME-CoF–based evaluation and procurement workflows (software/AI industry, academia, policy)
- Use the MME-CoF benchmark to standardize QA, regression testing, and vendor selection for video generation systems.
- Tools/products: test harness for 12 reasoning categories, success-rate dashboards, qualitative failure mode catalogs.
- Assumptions/dependencies: access to target models (e.g., Veo-3 or equivalents), reproducible generation settings, human-in-the-loop review for qualitative judgments, agreement on scoring rubrics.
- Production prompt templates and “prompt linter” for video generation stability (media/advertising, education, product marketing)
- Adopt the paper’s standardized prompt style (static camera, explicit constraints, imperative phrasing) to improve temporal consistency and reduce ambiguity.
- Tools/products: prompt template libraries, CI “prompt linter” that flags camera motion/ambiguity, internal style guides.
- Assumptions/dependencies: model adherence to camera/scene constraints varies; benefits strongest in short-horizon tasks.
- “Visual engine + reasoner” hybrid pipelines (education, enterprise training, customer support content)
- Pair LLM/MLLM planners with video models to render short, stepwise visuals for simple spatial layouts, fine-grained grounding, and locally consistent dynamics.
- Workflow: LLM plans steps → storyboard generator → video model renders CoF → human validation → publish.
- Assumptions/dependencies: LLM provides reliable CoT; video model handles short-horizon coherence; human oversight is essential for correctness.
- Micro-simulation and visual illustration for short-horizon phenomena (education, internal training)
- Generate qualitative demonstrations of local dynamics (e.g., reflections, simple rotations, basic spatial relations) for concept teaching and quick visual explainers.
- Tools/products: classroom micro-sim generators, LMS plug-ins that embed short CoF clips.
- Assumptions/dependencies: clips are not quantitatively accurate; instructors must add caveats on physical fidelity.
- Presentation aids for charts/tables with external validation (finance, business analytics, marketing)
- Use video models to produce focus/zoom animations on chart/table regions; pair with OCR/analytics backends to supply correct values.
- Workflow: external parser extracts data → video focuses/highlights region → overlay verified values.
- Assumptions/dependencies: model’s localization precision is limited; must rely on external data extraction and human checks to avoid misreadings.
- Simple object counting in controlled scenes (retail visual audits, warehouse demos)
- Produce counting visuals where objects are large, static, and uncluttered; use overlays or bounding boxes guided by external detection.
- Tools/products: “count-as-you-pan” demo generator; semi-automated counting with object detectors feeding the video model.
- Assumptions/dependencies: static scenes and clear salience; external detectors mitigate grounding errors; human spot checks for accuracy.
- UI/UX mockup animations (software design, product pitches)
- Create visual click-throughs and interface highlight flows to communicate intended interactions and journeys (not automation).
- Tools/products: Figma/Adobe plug-ins that convert wireframes into animated CoF demos.
- Assumptions/dependencies: model may introduce visual artifacts; keep scenarios simple and scripted; not suitable for functional RPA.
- Academic baselines and curriculum for CoF reasoning research (academia)
- Use MME-CoF to study failure modes, emergent capabilities, and to design training/evaluation curricula for visual reasoning.
- Tools/products: open benchmark splits, reproducible experiment configs, qualitative error taxonomies.
- Assumptions/dependencies: continued access to leading video models/APIs; institutional review for data curation.
- Risk labeling and governance checklists for generative video (policy, enterprise compliance)
- Incorporate the 12-category taxonomy in internal compliance to disclose limits (e.g., long-horizon causal, geometry, abstract logic).
- Tools/products: risk labels on generative videos; deployment readiness scorecards per category.
- Assumptions/dependencies: organizational buy-in; harmonization with emerging AI policy frameworks.
Long-Term Applications
The following use cases require advances in long-horizon causal reasoning, strict geometric/physical consistency, or integration with specialized modules. They are feasible with further research, scaling, and system design.
- Embodied agents and robotics with CoF–CoT synergy (robotics, logistics, manufacturing)
- Video models act as visual engines, while planners/controllers ensure task-level reasoning and manipulation, enabling long-horizon planning and execution.
- Tools/products: perception-grounded CoF renderers; policy-learning frameworks combining video generation with control.
- Assumptions/dependencies: robust causal consistency, object persistence, sim-to-real transfer; safety certification for physical interaction.
- Physics-consistent simulation and training content (engineering, education, gaming)
- Quantitative accurate dynamics for teaching, design validation, and simulation-based training.
- Tools/products: physics constraint modules (energy/momentum), hybrid sim–gen pipelines, “physics consistency checker.”
- Assumptions/dependencies: coupling generative video with numerical simulators; validated physical models; precise timing/trajectory control.
- CAD/geometry assistants for folding, assembly, and design (manufacturing, architecture, product design)
- Video-guided multi-step 2D/3D geometric reasoning to illustrate assembly or transformations with strict constraints.
- Tools/products: “geometry validator” enforcing non-intersection, alignment; CAD plug-ins generating instructional CoF videos.
- Assumptions/dependencies: accurate geometric primitives, coordinate-frame stability, constraint solvers; domain-specific training data.
- GUI automation agents (software automation/RPA)
- Reliable video-grounded interaction understanding translates to robust UI agents that execute tasks across OSes and web.
- Tools/products: UI grounding modules, event consistency trackers, OS/browser APIs for actuation.
- Assumptions/dependencies: precise UI localization and state tracking; auditability and rollback; security safeguards.
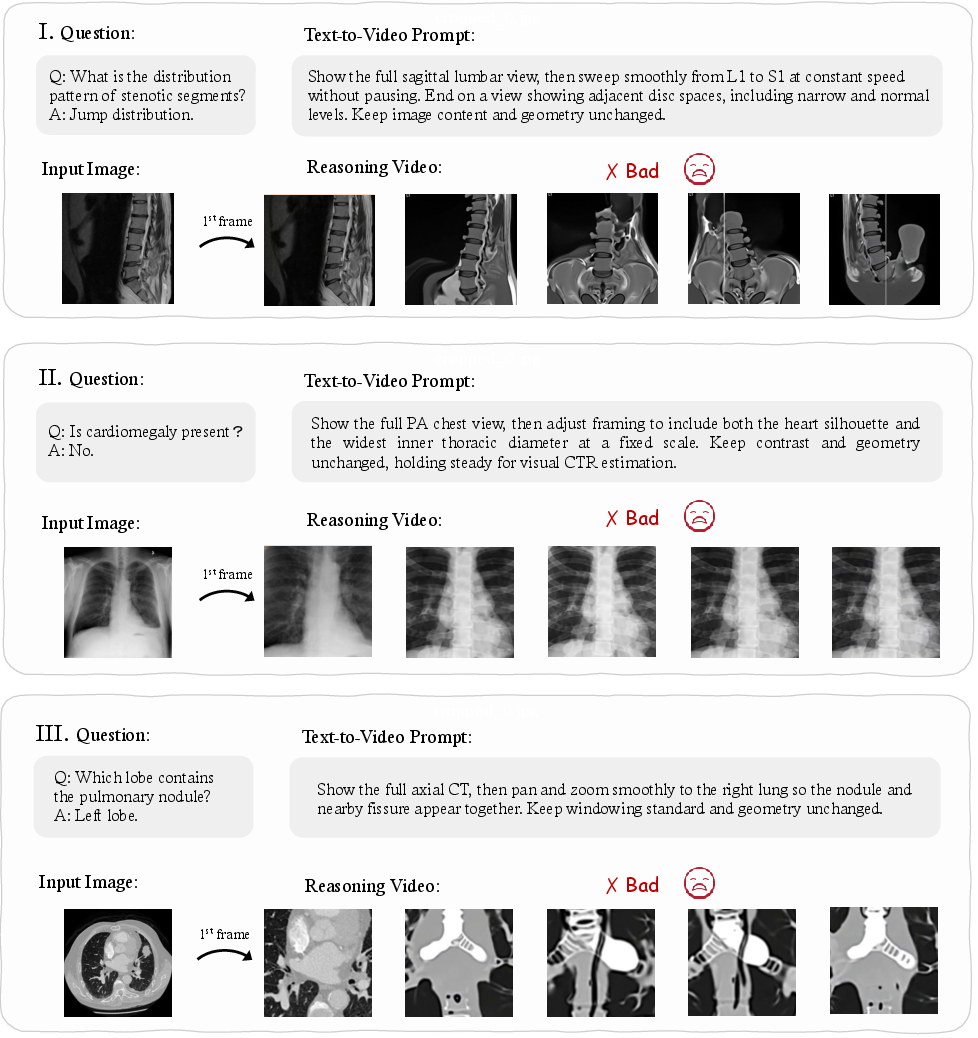
- Medical visual reasoning for training and clinical decision support (healthcare)
- Procedure planning, spatial orientation, and stepwise visual tutoring for clinical workflows.
- Tools/products: medically curated CoF datasets, compliance-aware renderers, integration with medical imaging/EMR systems.
- Assumptions/dependencies: domain-specific data, regulatory clearance (e.g., FDA/CE); rigorous validation and bias controls.
- Financial reporting with trustworthy chart/table reasoning (finance)
- Automated video narratives of financials with verified data overlays and accurate region focus.
- Tools/products: audit trails, cross-checkers for parsed values, explainability dashboards.
- Assumptions/dependencies: robust data parsing and validation; regulatory compliance (SOX/GDPR); human supervision.
- Real-time surveillance/inspection and anomaly reasoning (security, energy, industrial QA)
- Visual engines support anomaly explanation and stepwise incident reconstruction.
- Tools/products: stream-aware CoF generators, causal reasoning backends, incident timelines.
- Assumptions/dependencies: long-horizon temporal consistency, fairness and bias mitigation, reliable object persistence.
- Advanced visual tutors for STEM (education)
- Step-by-step derivations and manipulations in geometry/physics with correctness guarantees.
- Tools/products: tutor orchestration engines combining LLM reasoning, video generation, and validation modules.
- Assumptions/dependencies: formal verification hooks; curriculum-aligned datasets; guardrails against hallucination.
- Cross-industry evaluation standards (policy, procurement, SDOs)
- Evolve MME-CoF into an industry-wide standard for generative video reasoning capability, informing certification and disclosures.
- Tools/products: conformance tests, public scorecards, certification pipelines.
- Assumptions/dependencies: multi-stakeholder consortium; transparent benchmarks; periodic updates.
- AI tooling ecosystem around CoF (software/AI tooling)
- Frame-level constraint validators, trajectory planners, and post-processors that enforce static camera, geometric/physical rules.
- Tools/products: “CoF-Orchestrator” for pipeline assembly; “Constraint Enforcer” SDKs; visual QA dashboards.
- Assumptions/dependencies: mature APIs, model hooks for guidance/control, community adoption of open tooling.
Glossary
- Abstract logic: High-level, symbolic reasoning not tied to concrete visual details or specific instances. "abstract logic"
- Autoregressive architectures: Generative models that produce outputs sequentially by conditioning each step on previous ones (e.g., next-token or next-frame prediction). "autoregressive architectures"
- Causal consistency: Maintaining correct cause-and-effect relationships over time within generated sequences. "long-horizon causal consistency"
- Chain-of-Frame (CoF) reasoning: A step-by-step visual reasoning process unfolding across successive generated frames, analogous to textual chain-of-thought. "Chain-of-Frame (CoF) reasoning"
- Chain-of-thought (CoT): A prompting/decoding paradigm where models produce intermediate reasoning steps en route to an answer. "chain-of-thought (CoT)"
- Contact mechanics: The physics governing interactions at contacting surfaces, including constraints and forces during contact. "contact mechanics in frictional, force-driven, or mechanically constrained scenarios."
- Cube net: A 2D arrangement of six connected squares that fold into a 3D cube. "cube net"
- Diffusion models: Generative models that iteratively denoise samples from noise to data, learning the reverse of a diffusion process. "diffusion"
- Dolly (camera movement): A cinematography move where the camera physically moves toward or away from the subject (not a zoom). "no zoom, no pan, no dolly"
- Embodied reasoning: Reasoning that involves actions, interactions, and sensorimotor processes within an environment. "Embodied Reasoning"
- Emergent capabilities: Abilities that arise in large models without explicit task-specific training as scale and data increase. "These emergent capabilities"
- Fine-grained grounding: Precisely linking instructions or concepts to specific, detailed regions and attributes in the visual scene. "fine-grained grounding"
- Foundation models: Large, pretrained models that serve as general-purpose bases for a wide range of tasks. "foundation models for natural language."
- Hallucination (model): Generating content that is not supported by the input, task, or physical plausibility. "hallucinating its appearance"
- Long-horizon planning: Planning and maintaining coherent behavior over many steps or extended temporal spans. "long-horizon planning breakdowns"
- Meshing: Constructing or handling polygonal mesh representations of geometry; errors cause structural artifacts. "incorrect meshing"
- MLLMs (multimodal LLMs): Large models that jointly process and reason over multiple modalities, such as text and images/video. "multi-modal variants (MLLMs)"
- OCR (Optical Character Recognition): Automatically reading and converting text within images or video frames into machine-encoded text. "OCR"
- Perceptual grounding: Mapping abstract concepts or instructions onto perceptual features so the model can locate and manipulate them visually. "perceptual grounding"
- Priors (video priors): Learned statistical regularities or biases a model relies on when generating or interpreting video. "video priors"
- Reference-frame alignment: Keeping a consistent coordinate/reference frame so spatial relations remain coherent across views. "reference-frame alignment"
- Self-intersecting structures: Geometric configurations where parts of an object improperly intersect themselves, violating physical plausibility. "self-intersecting structures"
- Spatial coherence: Consistent spatial relations, layout, and object positioning across frames. "short-horizon spatial coherence"
- Temporal coherence: Smooth, consistent evolution of appearance and motion over time without abrupt artifacts. "temporally coherent videos"
- Text-to-video (and video-to-text): Models that synthesize videos from text prompts or generate text from videos. "text-to-video and video-to-text"
- Zero-shot reasoners: Models that can perform reasoning tasks without any task-specific training or examples. "zero-shot reasoners"
- Zero-shot setup: An evaluation setting where models are tested without fine-tuning, additional supervision, or auxiliary tools. "a unified zero-shot setup"
Collections
Sign up for free to add this paper to one or more collections.

