- The paper presents a novel real-time, action-conditioned video diffusion model for AV simulation that integrates with NVIDIA's AV ecosystem.
- It employs a causal transformer-based architecture with a streaming KV-cache, achieving high FPS and multi-view spatiotemporal consistency.
- The system supports closed-loop evaluation and policy deployment, demonstrating superior performance versus reconstruction-based simulators.
NVIDIA OmniDreams: Real-Time Generative World Model for Autonomous Vehicle Simulation
Introduction
NVIDIA OmniDreams introduces a generative world model for autonomous vehicle (AV) simulation, designed as an action-conditioned video diffusion model that operates in real-time and supports closed-loop policy evaluation. Unlike reconstruction-based neural simulators, which are constrained by captured data and inherently limited in out-of-distribution generalization and scene synthesis, OmniDreams leverages foundation-model architectures to synthesize sensor observations that are both photorealistic and interactive. It integrates deeply with the NVIDIA AV ecosystem, functioning as a drop-in sensor simulator within the AlpaSim orchestrator and the Alpamayo 1 policy stack, and facilitates the creation, evaluation, and control of complex, counterfactual, and long-tail AV scenarios.
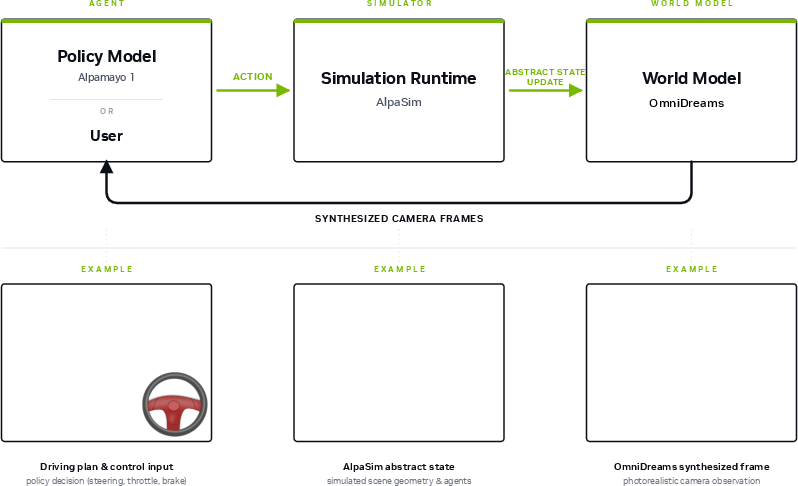
Figure 1: Closed-loop simulation workflow for AV policies interacting dynamically with the OmniDreams generative simulator.
Data Pipeline and Conditioning Mechanisms
OmniDreams is mid- and post-trained from Cosmos-Predict 2.5 on large-scale, real-world driving datasets (21k hours; ∼4M clips) covering 15 countries and seven camera viewpoints. The datasets are curated to ensure broad coverage across weather, geography, traffic density, and time-of-day, and are meticulously filtered for annotation and sensor quality.
Sensor generation by OmniDreams is conditioned on three core modalities:
- (i) Abstract world-scenario map (including HD map annotations and temporally-accurate dynamic agent trajectories),
- (ii) Text prompt (environment descriptions such as weather, lighting, and event context),
- (iii) Past visual history (via a memory/Key-Value (KV) cache of previously synthesized frames).
These signals together enable controlled, interactive, and temporally consistent simulation rollouts.
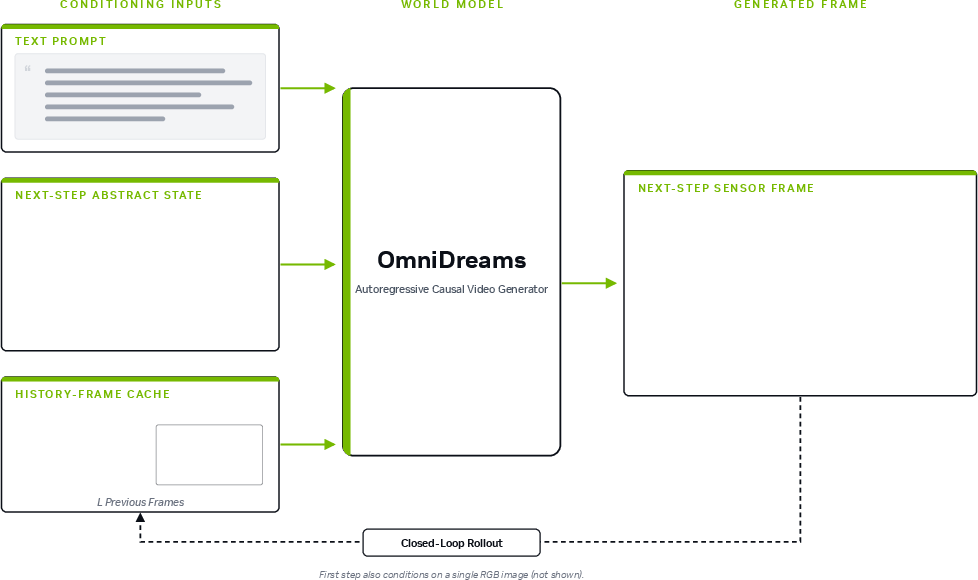
Figure 2: OmniDreams jointly conditions on text, abstract state, and temporal history to generate sensory frames in simulation.
Model Architecture
OmniDreams adopts a causal transformer-based Diffusion Transformer (DiT) backbone with autoregressive rollout for real-time, action-conditioned video synthesis. It supports both single-view (OmniDreams-SV) and factorized cross-view multi-camera (OmniDreams-MV) models. Multi-view deployment incorporates view embeddings and cross-view attention layers, ensuring spatial and temporal consistency across synchronized cameras while maintaining computational feasibility at scale.
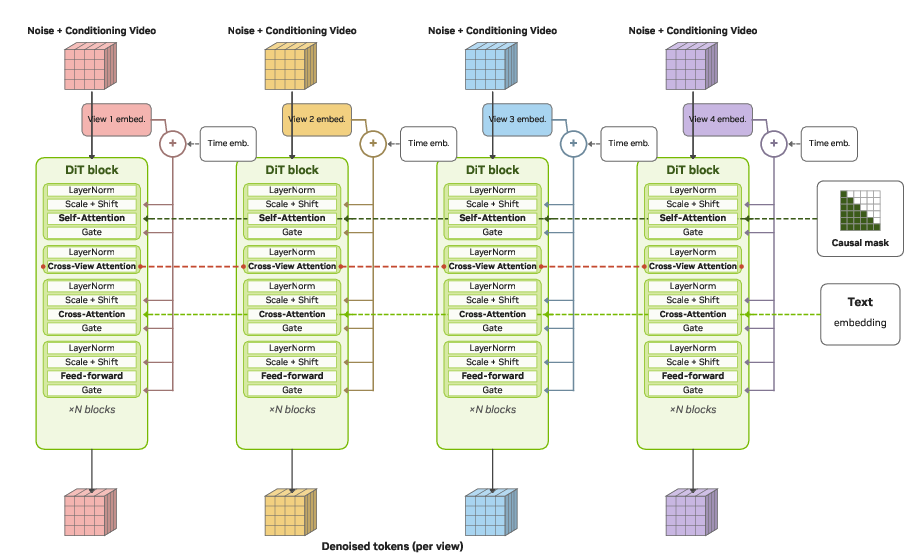
Figure 3: Multi-view DiT architecture with per-view embeddings and cross-view attention for consistent multi-camera generation.
Temporal consistency is enforced via a streaming KV-cache mechanism, and a lightweight world-scenario control branch injects compact structured state tokens into the generative model. This design sustains real-time performance: the 2B parameter single-camera model operates at 68 FPS on a single GB300 GPU for 720p output; the 4-camera instantiation achieves 105 FPS on 16 GB300s.
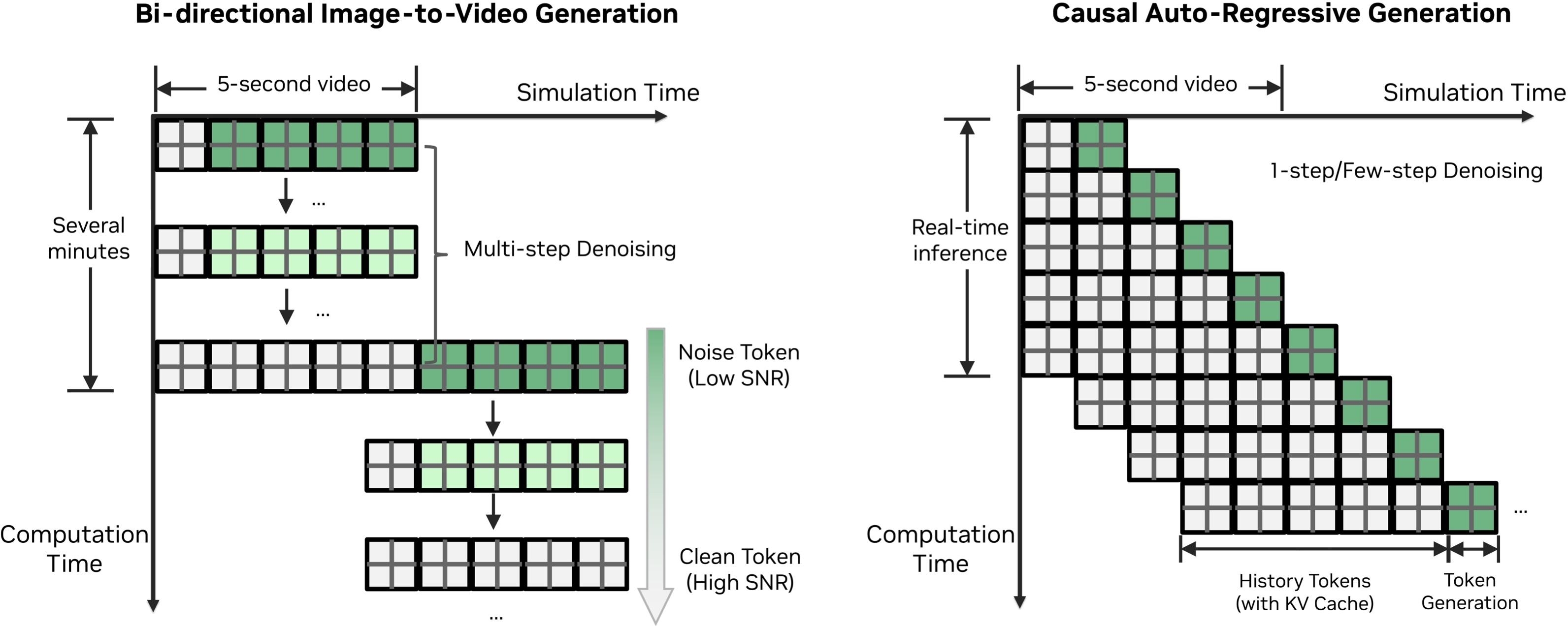
Figure 4: Causal, chunk-based video generation using streaming KV-caches for temporally consistent long-horizon rollouts.
Training Paradigm
OmniDreams is derived from bidirectional Cosmos models and subjected to a multi-stage regimen:
Distribution Matching Distillation (DMD) replaces traditional reconstruction loss, directly minimizing the KL divergence between generated and real-data video distributions.
Closed-Loop Simulation, Orchestration, and Serving
The OmniDreams simulation pipeline is fully integrated with the AlpaSim orchestrator and exposed as a stateful, chunk-based microservice over gRPC, supporting both single and distributed multi-GPU deployments. KV-cache maintenance and inference graphs are decoupled and optimized with CUDA Graphs and static-tensor shapes for minimum latency. In production, the simulator maintains session-based state, supports pre-fetch chunking, and synchronizes across policy (Alpamayo 1), traffic, and rendering layers.
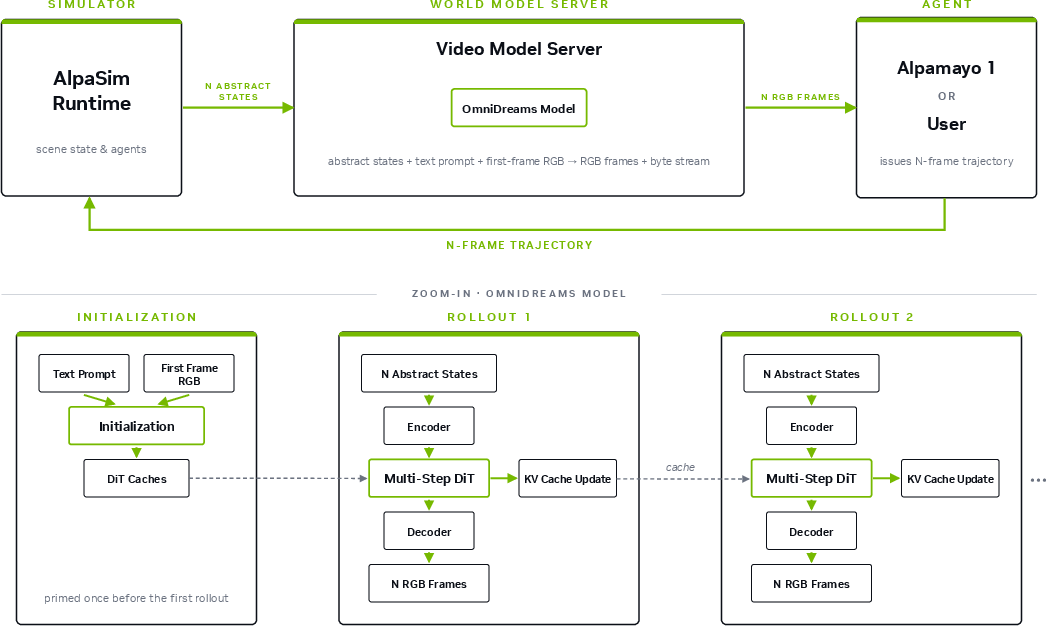
Figure 6: End-to-end pipeline: policy actions and world-state are streamed to OmniDreams, which returns photorealistic frame chunks.
Applications: World Model as Policy Backbone and Fixer
World-Action Model (WAM) Policy
Fine-tuning the OmniDreams backbone for trajectory prediction yields a competitive World-Action Model (WAM) policy. When compared on the Physical AI Autonomous Vehicles NuRec dataset (20s rollouts, 501 scenes), OmniDreams WAM achieves lower All Incidents and Collision rates than the Alpamayo 1.5 VLA model, using only 20% of the parameter count. This demonstrates that the generative model’s internal representations encode sufficient scene and agent semantics for direct policy deployment—a critical observation aligning with emerging trends in world-model-based robotics policies.
Diffusion-Based Artifact Correction
OmniDreams can be used as a post-trained diffusion fixer for neural reconstruction engines. Applied to 3DGS/NeRF-based renderings with view-dependent artifacts, the model effectively denoises and harmonizes reconstructed frames while preserving physical layout and actionable cues, demonstrated both qualitatively and quantitatively in artifact correction tasks.

Figure 7: Top: neural reconstruction frames (with artifacts); bottom: OmniDreams-corrected outputs.
Empirical Evaluation: Quality, Stability, and Controllability
Generation Fidelity
On held-out RDS-HQ-1M evaluation splits, OmniDreams achieves state-of-the-art FVD, temporal consistency, and strong 3D detection and lane-line regression scores. Distilled autoregressive variants close the gap with bidirectional backbones while enabling real-time simulation.
Long-Horizon Rollout
Longitudinal evaluation (20s, 597-frame rollouts) shows that progressive distillation from a long-context teacher is essential to suppress temporal artifacts and drift. Rolled-out FVDs remain low and appearance identity is preserved for minute-scale horizons.
Multi-View Consistency
Joint multi-camera generation maintains cross-view geometric and appearance consistency, critical for surround-view policy stacks in AV.

Figure 8: OmniDreams sustains spatiotemporal coherence across synchronized multi-camera AV rigs.
Closed-Loop Policy Evaluation
OmniDreams is validated as a closed-loop evaluation environment for several policies in comparison with NuRec. Policy rankings on All Incidents, Collision, and Offroad metrics are preserved, demonstrating that generative simulation is a reliable proxy for real-world deployment performance. As ego trajectories deviate from original log data, NuRec’s visual fidelity rapidly degrades, whereas OmniDreams maintains plausible sensor observations.
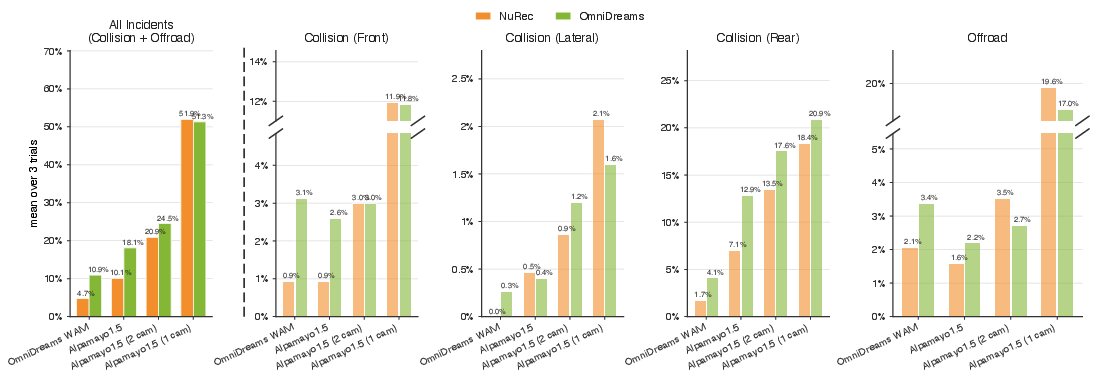
Figure 9: Side-by-side closed-loop evaluation: NuRec vs. OmniDreams sensor simulation for multiple policies (lower is better).
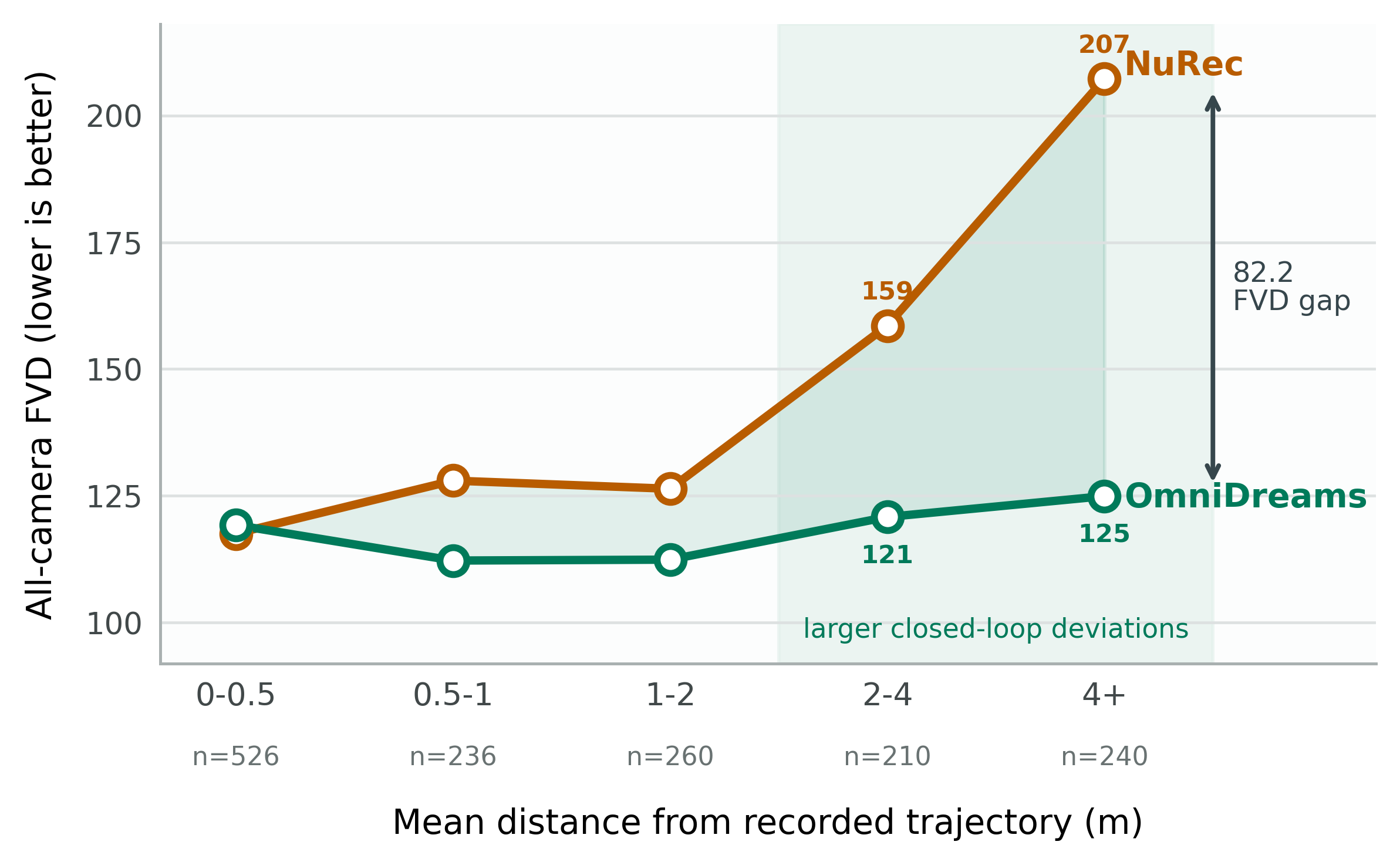
Figure 10: FVD for four-camera video distributions: OmniDreams maintains quality under trajectory deviations; NuRec degrades.
Scenario Editing and Out-of-Distribution Generalization
Counterfactuals are realized via editable conditioning (text prompt, world-scenario map, first frame), covering rare weather, agent configuration, and synthesized OOD events (e.g., inserted objects without explicit trajectories). Additional post-training with cuboid dropout generalizes handling to OOD object insertions and naturalistic persistence.

Figure 11: Scenario editing: Targeted changes to appearance, weather, and ego action while holding structure constant.

Figure 12: OOD object modeling: Inserted entities exhibit plausible, temporally-consistent dynamics.
Practical and Theoretical Implications
OmniDreams provides a blueprint for next-generation, data-driven simulation systems. Its integration of structured scene control, KV-cache temporal memory, causal diffusion transformers, and high-throughput serving removes the conventional barriers to scalable, interactive, and controllable AV testing. The strong empirical benchmarks for both simulation fidelity and downstream policy efficacy support the claim that generative world models can subsume both photorealistic sensor simulation and policy inference tasks, reducing reliance on modular, hand-engineered pipelines.
On the theoretical plane, these results provide further evidence that foundation world models can internalize both state estimation and action prediction, echoing recent findings in foundation robotics. The emergence of the WAM paradigm, with compact parameterization outperforming larger VLA models, has implications for the construction of unified, multitask AV backbones.
Future Directions
- Extension to additional modalities (LiDAR, audio, BEV),
- Tighter coupling of joint world-policy training for lifelong learning,
- More aggressive scalability in camera count and scene diversity,
- Streaming super-resolution and sparse attention for real-time resource optimization,
- Community integration via FlashDreams for plug-and-play deployment.
Conclusion
The OmniDreams system fundamentally advances closed-loop, generative simulation for autonomous vehicles. By fusing foundation model architectures with scalable infrastructure and policy integration, it sets the current standard for AV policy development, validation, and evaluation in highly unconstrained and long-tail scenarios. Its empirical results and architectural innovations will likely influence how future autonomous systems are trained, deployed, and tested through data-driven simulation.
