- The paper introduces Dream.exe, a scalable framework that converts manipulation videos into executable robot trajectories in physics simulators.
- It employs a four-stage pipeline including video generation, visual evaluation, trajectory extraction with depth estimation, and closed-loop physics execution.
- Key results reveal a decoupling between visual quality and execution success, highlighting the need for 3D-aware models and improved physical grounding.
Evaluating Physical Executability in Video Generation: An Analysis of Dream.exe
Introduction
"Dream.exe: Can Video Generation Models Dream Executable Robot Manipulation?" (2606.04811) presents a rigorous evaluation framework and empirical study aimed at directly probing the alleged physical world modeling abilities of contemporary video generation architectures. Rather than relying solely on conventional visual inspection metrics, the work operationalizes the world model hypothesis by introducing a pipeline that transforms synthesized manipulation videos into physical robot trajectories, which are then executed in a physics simulator. The central contribution is a unified, scalable evaluation framework—Dream.exe—that assesses video-to-robot translation not just for visual plausibility, but for actionable, executable manipulation in diverse and challenging simulation environments.
Benchmark and Task Suite
The Dream.exe task suite is constructed to probe executability and generalization over a broad manipulation task distribution. Based on RoboCasa365, 101 benchmarked tasks are selected following extensive curation, ensuring sufficient coverage in both atomic and complex manipulation regimes and robust camera viewpoint diversity to avoid overfitting and to stress generalization.
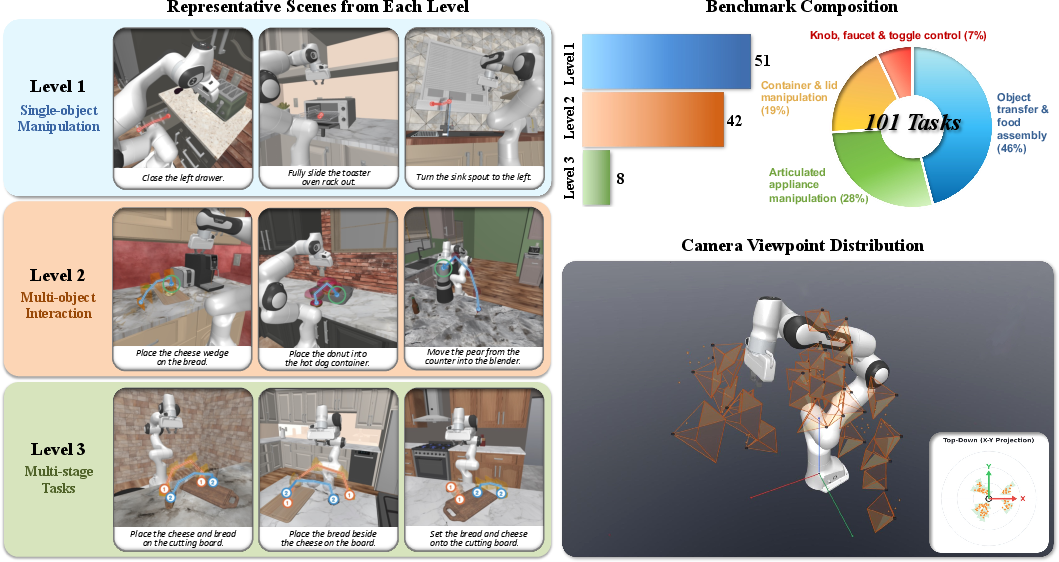
Figure 1: Overview of the Dream.exe task suite, displaying task prompt diversity, curated episodic scene variety, and stratified task complexity with viewpoint diversity.
Tasks are stratified into three difficulty levels:
- Level 1: Atomic single-object skills (e.g., pick-and-place, button pressing)
- Level 2: Multi-object scenarios requiring interaction and sequential dependencies
- Level 3: Compositional, multi-stage procedures demanding temporally coherent and physically grounded action execution
This ensures the benchmark diagnoses both core, short-horizon kinematic reasoning and long-horizon temporal consistency, both known weak points for generative temporal models.
Evaluation Pipeline
Dream.exe employs a four-stage pipeline to quantify physical executability:
- Video Generation: Models generate manipulation videos conditioned on a scene image and task prompt.
- Visual Quality Evaluation: Videos are rated by VLMs (Gemini 3 Pro, Qwen3-VL-Plus) for robot-subject consistency, plausibility, and task adherence; human studies complement these metrics.
- Video-to-Trajectory Extraction: Using mask initialization (simulator segmentations or open-vocabulary detection), 2D tracklets, robot-adapted monocular depth estimation, and kinematic/interaction recognition, videos are converted to robot end-effector and gripper trajectories.
- Physics Execution: Extracted action streams are replayed using a closed-loop robot controller in the RoboCasa/robosuite MuJoCo stack; explicit task success is the arbiter metric.
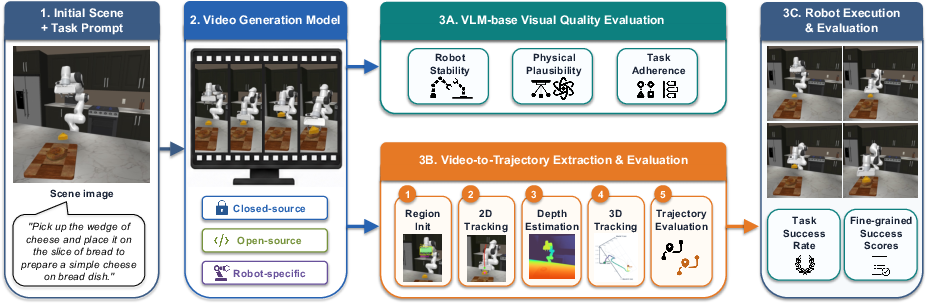
Figure 2: The Dream.exe pipeline, showing the transition from prompt and initial frames through generation, trajectory extraction, and closed-loop physics execution for grounded evaluation.
Trajectory extraction's robustness is vital, with the use of customized depth estimation models (DVD + LoRA), region tracking, and gripper event inference via contact/motion cues being critical to bridging pixel-space video and world-frame action sequences.
Model Selection and Experimental Design
Eight models are tested, representing three major classes:
- Frontier Closed-Source Video Generators: Hailuo~2.3, Kling~3.0, Wan~2.7, SeedDance~2.0, Veo~3.1
- Community Open-Source Generators: Wan~2.2 (and both LoRA-finetuned variants), LTX-2.3
- Robot-Specific Policy Models: CosmosPolicy (benchmark vs. default camera protocols; action-output baseline)
All models are evaluated with identical task prompts under both 'verbatim' and LLM-enhanced paraphrase instruction variants, ruling out context or conditional alignment artifacts.
Results and Failure Mode Taxonomy
Visual Quality vs. Physical Executability
Aggregate results reveal a pronounced decoupling between visual quality and downstream execution success. Krylov-rankings indicate that LTX-Video and Veo~3.1 achieve superior visual/semantic scores in robot-subject stability and task adherence, yet show consistently inferior executable trajectory fidelity and task completion rates compared to SeedDance~2.0 and Kling~3.0, which lead on task success despite modest visual ratings. Human annotation corroborates these findings.
Trajectory and Execution Analysis
Trajectory evaluation using modified Hausdorff/Wasserstein/DTW similarity to ground truth confirms that high visual realism does not entail kinematically feasible or temporally coherent robot motions. CosmosPolicy leads on geometric precision (tool-point trajectory similarity, checkpoint executability), but general-purpose video models (notably Wan~2.7 and Kling~3.0) frequently deliver higher aggregate task completion, especially in multi-object regimes. Robot-specific priors offer improved local geometry but lower generalization and task adherence, especially with out-of-domain viewpoints.
Task completion (SR-B binary, SR-P continuous metrics) is highly sensitive to task horizon: at Level 1 and Level 2, general-purpose models—SeedDance~2.0 and Wan~2.7 in particular—produce partial or total success rates up to 21%, with complex Level 3 tasks remaining intractable for nearly all models.
Failure Analysis
Systematic error analysis identifies object levitation, phantom grasp, and kinematic breakdown as dominant video-to-execution failure sources. The propagation of generation artifacts—non-contact attachment, inconsistent object states, and robot geometry hallucinations—results in unrecoverable execution errors even when the video generates visually plausible motion.
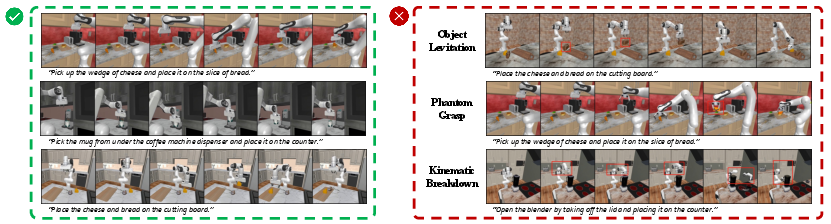
Figure 3: Taxonomy and representative examples of failure modes: object levitation, phantom grasp, kinematic breakdown.

Figure 4: Qualitative outcomes for trajectory extraction: left—successful video/rollout alignment; right—propagation of visual artifacts resulting in execution failure.
Video-to-Trajectory Technical Details
The trajectory extraction system employs adaptive region segmentation, temporally consistent monocular depth (robot-adapted DVD with LoRA), 2D point tracking (CoTracker), and kinematic calibration to deduce tool point and object frame movement. Sequential segmentation and geometric reasoning deliver end-effector orientation and gripper schedule detection.
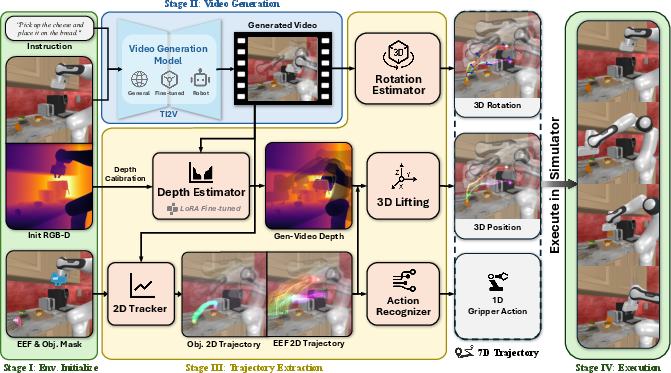
Figure 5: Detailed block diagram of video-to-execution pipeline, illustrating region detection, depth alignment, 3D lifting, and controller alignment.
The pipeline—when run on ground-truth rollout videos—substantially improves execution results, highlighting that shortcomings are largely an artifact of generative model limitations or depth estimation errors, rather than the action extraction method itself.
Implications and Future Outlook
Practical Significance: The data indicate that standard perceptual and temporal metrics (e.g., FVD, CLIP- or VLM-based plausibility) are inadequate proxies for actionable physical modeling. Dream.exe offers a scalable, differentiable benchmark that forces generative world models to be evaluated on the physically executable content of their outputs.
Model Development: The findings motivate future video generative architectures that incorporate explicit physical grounding—via 3D-aware priors, contact prediction, and simulated embodied training signals—to better align visual realism with downstream task readiness. The decoupling between visual quality and task executability also suggests the need for new model selection, evaluation, and fine-tuning paradigms, as in-domain visual imitation alone (as shown by LoRA experiments) only modestly improves physical adherence.
Evaluation Standards: By integrating video-to-trajectory evaluation, Dream.exe bridges the gap between compositional generalization benchmarks (VBench, EvalCrafter) and manipulation-specific embodied policy evaluations. This methodology is critical for robotics/embodied AI, where world model accuracy must propagate to action-level verification.
Conclusion
Dream.exe establishes the first rigorous connection between video generation and physical robot action executability. While state-of-the-art video generation models do encode transferable kinematic and some physical priors—enabling nontrivial manipulation task completion even without explicit robot data—these abilities are unsystematic, breakdown under compositional/long-horizon regimes, and are largely uncoupled from perceptual quality metrics. The Dream.exe protocol and data release define new targets for video world models, and highlight the urgent need for physically grounded auxiliary objectives and architectures that minimize the visual/physical reality gap.