- The paper introduces PDI-Bench, a novel quantitative framework that evaluates 3D geometric consistency in video models.
- It leverages a multi-stage Target-Uplift-Anchor pipeline and physical metrics such as scale-depth alignment and 3D motion consistency.
- The approach reveals a persistent physics gap in generative models, exposing failure modes like scale hallucination and kinematic artifacts.
Quantitative Evaluation of Geometric Consistency in Generative World Models: An Analysis of PDI-Bench
Introduction
The evaluation of generative video models as implicit world models necessitates moving beyond 2D perceptual realism into the domain of verifiable 3D physical coherence. The paper "Quantitative Video World Model Evaluation for Geometric-Consistency" (2605.15185) provides a rigorous, quantitative framework—PDI-Bench (Perspective Distortion Index Benchmark)—for auditing the geometric integrity of video synthesis models. While visual metrics such as FVD and CLIP-based scores are widely adopted, they remain fundamentally insensitive to underlying 3D spatial violations. PDI-Bench addresses this evaluative gap by introducing geometric diagnostics founded on hard physical laws applied at scale to state-of-the-art video generation architectures.
Methodology: The PDI-Bench Framework
PDI-Bench is operationalized through a multi-stage Target-Uplift-Anchor pipeline integrating top-tier vision models for robust evidence extraction.
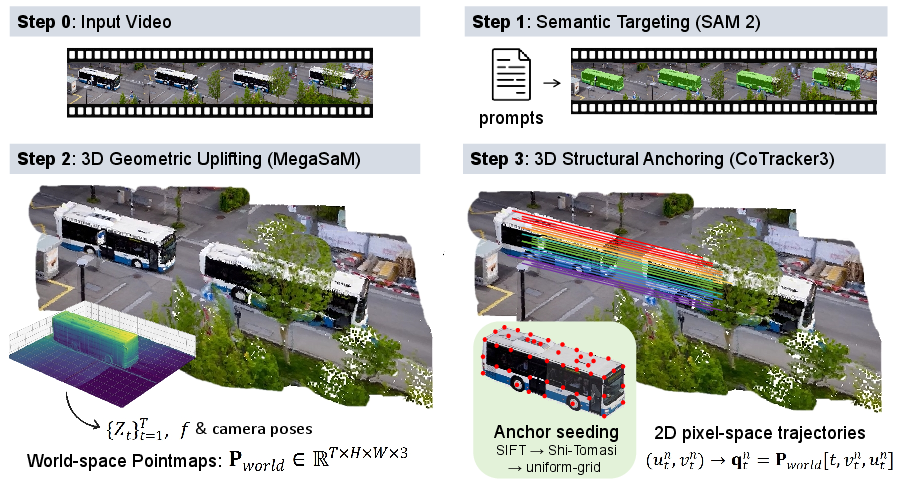
Figure 2: Schematic of the PDI-Bench pipeline, which systematically extracts object, motion, and structure information for geometric auditing.
Target-Uplift-Anchor Pipeline
- Semantic Targeting (SAM 2): The pipeline begins with automated object segmentation using Florence-2 and SAM 2, establishing a high-fidelity spatial mask and extracting frame-wise projected heights.
- 3D Geometric Uplifting (MegaSaM): MegaSaM reconstructs a temporally consistent 3D world space from monocular video, yielding pointmaps and camera poses, fully disentangling ego-motion from object kinematics.
- 3D Structural Anchoring (CoTracker3): CoTracker3 establishes high-confidence anchor trajectories within the mask, which are then lifted to 3D, enabling the computation of dynamic and structural consistency metrics in an object-centric frame.
Geometric Auditing Metrics
The Perspective Distortion Index (PDI) is defined as a weighted sum of three orthogonal, physically interpretable residuals:
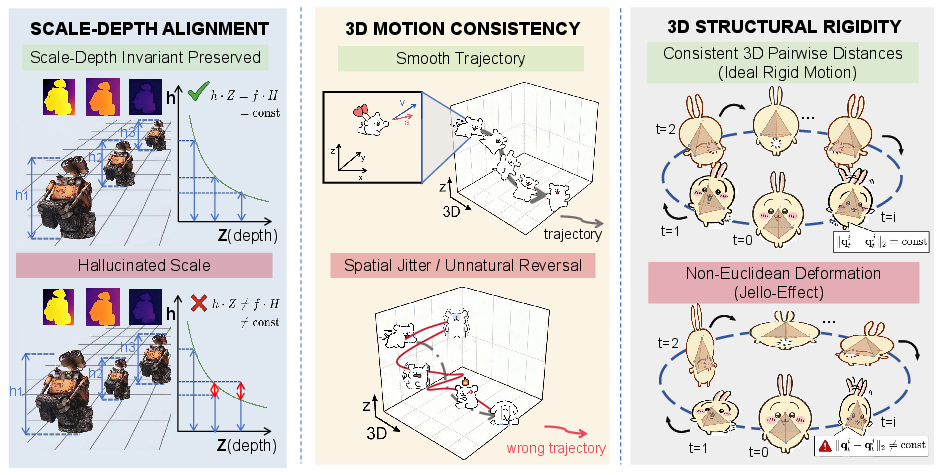
Figure 3: PDI-Bench's geometric auditing axes—scale-depth alignment, 3D motion consistency, and spatial rigidity.
- Scale-Depth Alignment (ϵscale): Enforces the pinhole camera invariant htZt=const for a rigid body, penalizing "volume breathing" induced by perspective hallucination.
- 3D Motion Consistency (ϵtraj): Quantifies deviation in centroid acceleration and abrupt velocity direction changes, explicitly penalizing unnatural kinematic discontinuities in world coordinates, normalized against stable speed references.
- Structural Rigidity (ϵrigidity): Measures the temporal stability of internal 3D anchor pairwise distances, providing a physicality prior essential for distinguishing rigid from non-rigid deformation artifacts.
PDI-Dataset and Evaluation Protocol
The PDI-Dataset comprises 183 video sequences sampled from 28 high-level prompt scenarios, spanning real-world (15 GT) and synthetic outputs from six leading models: Seedance 2.0, CogVideoX-3, Veo 3.1, Sora, HunyuanVideo, and Wan 2.2.
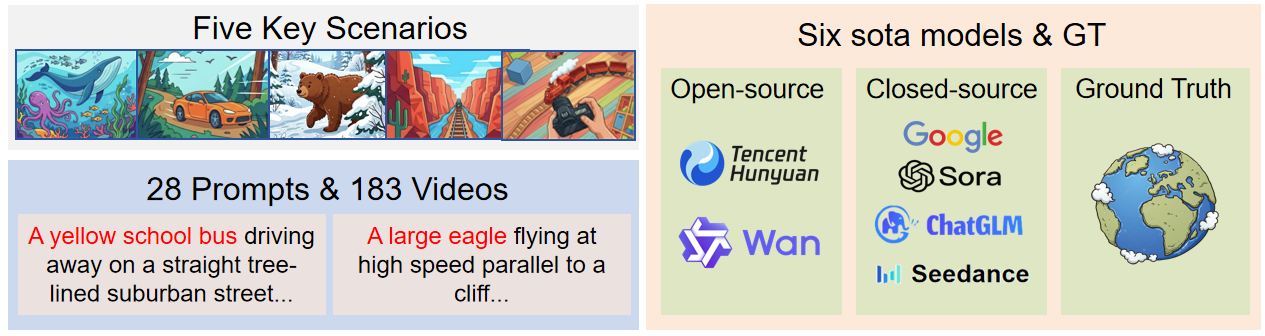
Figure 1: The benchmark setup and PDI-Dataset scope, stress-testing models across five critical geometric scenarios.
Every scenario is designed to stress the models’ spatial understanding: longitudinal convergence, dynamic tracking, biological motion, curved motion, and partial occlusion.
Experimental Results and Failure Mode Analysis
Global Ranking and Physics Gap
Quantitative results (Table 1 in the paper) indicate a persistent "physics gap" between real-world reference and synthetic outputs. While real data anchor a PDI score of 0.1206, the top-performing generative models like Seedance 2.0 (0.2422) and CogVideoX-3 (0.2480) can approach but not match this baseline; models renowned for visual quality such as Sora (0.8255) and HunyuanVideo (0.8825) radically underperform on 3D consistency, particularly in scale invariance (ϵscale>1.67).
Key findings:
- Persistent scale hallucination: A majority of models suffer from high-magnitude violations of the perspective invariant, especially during axial and occlusion scenarios.
- Kinematic artifacts: While some models maintain smooth centroid trajectories, structural rigidity remains susceptible to transient failure modes, notably during rapid soft-body motion or occlusion-induced "object forgetting".


Figure 5: Biological motion scenario displaying articulated dynamics and revealing temporal inconsistency in model predictions.
Scenario-Conditioned Dissection
Qualitative Pipeline Visualization
Pipeline visualizations elucidate the interpretability of the PDI metric. Intermediate masks, tracking overlays, and 3D point clouds provide transparency for diagnosing multi-modal inconsistency.



Figure 6: Multi-view visualization of temporally consistent 3D structures as output by MegaSaM.
Human Perceptual Alignment
A structured expert study demonstrates perfect rank correlation (ρ=1.0) between PDI and human intuition of physical realism, validating the metric's sensitivity to perceptible physics violations without requiring subjective annotation.
Stress Testing: AR Long-Range Generation
Autoregressive extrapolation analyses on Wan2.1 (Self-Forcing) reveal a dichotomy: even as trajectory smoothness is preserved (low ϵtraj), scale drift becomes catastrophic when AR mechanisms lose spatial anchors, especially under occlusion and extended horizon, thereby revealing the limitations of context-truncated generative memory.
Limitations
The framework's depth precision relies on the robustness of off-the-shelf segmentation, tracking, and monocular 3D vision backbones. Highly non-rigid, thin-structure, or amorphous entities are not fully captured by the rigidity prior, and monocular systems remain fundamentally ambiguous in severe rotation or low-parallax configurations.
Implications and Future Perspectives
PDI-Bench sets a new standard for evaluating physically plausible video generation. The explicit coding of geometric constraints exposes, in quantitative and interpretable terms, the limitations of current foundational models in emulating consistent world dynamics. This framework provides actionable diagnostic signals for developing next-generation, physically grounded generative architectures and highlights essential research directions: improved spatial memory, multi-modal sensor fusion, and the introduction of learned geometric priors for metrics distillation.
Conclusion
"Quantitative Video World Model Evaluation for Geometric-Consistency" (2605.15185) provides an authoritative protocol for geometric auditing of video synthesis models. PDI-Bench is shown to capture a domain of physical failures invisible to conventional perceptual or semantic metrics and is tightly aligned with expert judgment. Its adoption should catalyze a shift toward models genuinely constrained by 3D spatial laws, underpinning progress in vision, robotics, and embodied AI.


