LongVie 2: Multimodal Controllable Ultra-Long Video World Model
Abstract: Building video world models upon pretrained video generation systems represents an important yet challenging step toward general spatiotemporal intelligence. A world model should possess three essential properties: controllability, long-term visual quality, and temporal consistency. To this end, we take a progressive approach-first enhancing controllability and then extending toward long-term, high-quality generation. We present LongVie 2, an end-to-end autoregressive framework trained in three stages: (1) Multi-modal guidance, which integrates dense and sparse control signals to provide implicit world-level supervision and improve controllability; (2) Degradation-aware training on the input frame, bridging the gap between training and long-term inference to maintain high visual quality; and (3) History-context guidance, which aligns contextual information across adjacent clips to ensure temporal consistency. We further introduce LongVGenBench, a comprehensive benchmark comprising 100 high-resolution one-minute videos covering diverse real-world and synthetic environments. Extensive experiments demonstrate that LongVie 2 achieves state-of-the-art performance in long-range controllability, temporal coherence, and visual fidelity, and supports continuous video generation lasting up to five minutes, marking a significant step toward unified video world modeling.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “LongVie 2: Multimodal Controllable Ultra-Long Video World Model”
Overview
This paper introduces LongVie 2, a smart system that can create long, realistic videos (up to 3–5 minutes) that follow clear instructions. Think of it like a “video world model”: it doesn’t just make pretty clips; it tries to understand how the world changes over time, and then uses that understanding to generate videos that stay believable from start to finish.
Key Objectives
The researchers set out to answer three simple questions:
- How can we control what happens in a video in a precise, meaningful way (not just small tweaks)?
- How can we keep the video looking good for a long time, not just the first few seconds?
- How can we make the video stay consistent over time, so things don’t drift, glitch, or flip around?
How LongVie 2 Works
At a high level, LongVie 2 makes videos piece by piece and uses what it already generated to guide the next part. Here’s the approach, explained simply:
Diffusion models (in everyday language)
A diffusion model is like a “noise-cleaner.” Imagine starting with a blurry, noisy picture and cleaning it step by step until a clear image appears. For videos, it does this over many frames. To make it faster, the system works in a “compressed space” (like a smaller version of the video) and then decodes it back to full size.
Autoregressive generation
“Autoregressive” means it generates videos in short chunks (clips), and each new chunk looks at the previous one to keep the story and motion smooth, like writing a novel chapter by chapter and re-reading the last page before you continue.
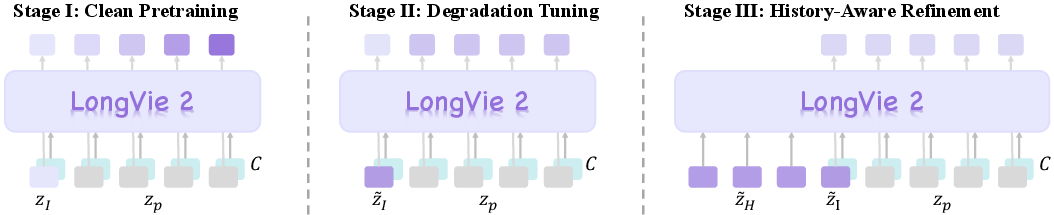
Three training stages
The system improves through three stages. Here’s what each stage does, with everyday analogies:
- Stage 1: Multi-modal guidance (controllability)
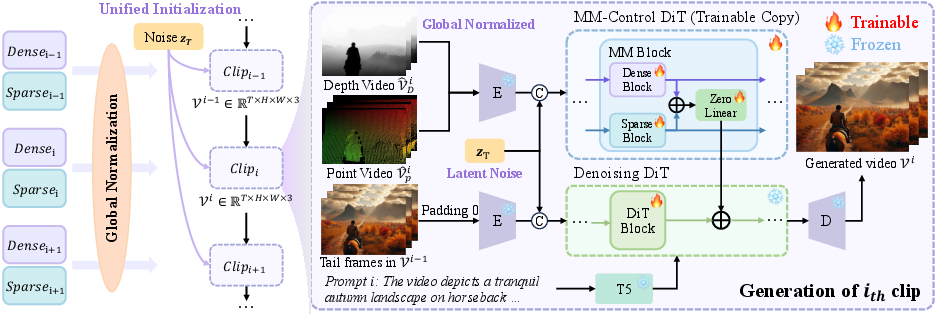
- Dense control signals: These are like a detailed 3D map of the scene (called depth maps). They tell the model where things are and how far they are.
- Sparse control signals: These are like colored sticky notes placed on important moving points (keypoints tracked over time). They give high-level hints about motion and what matters.
- Together, they act as “world-level guidance” so you can control not just small things, but the whole scene.
- Problem: The detailed 3D map can be too strong and drown out the sticky-note hints. Solution: Slightly “weaken” (degrade) the dense signals during training so the model learns to use both kinds of guidance fairly. This balancing helps control the video better over time.
- Stage 2: Degradation-aware training (long-term quality)
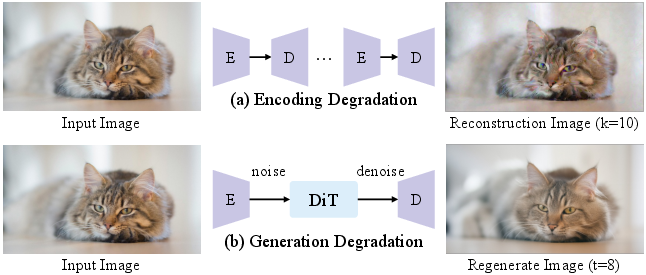
- In long videos, the first frame of each clip isn’t perfect—it’s generated by the model and slowly gets worse if the system isn’t trained for that.
- Solution: Practice with imperfect inputs. During training, the model is deliberately given a “messy” first frame (by adding noise or passing it through the compressor/decompressor multiple times). This teaches the model to handle and fix small errors so quality doesn’t collapse over minutes.
- Stage 3: History context guidance (temporal consistency)
- The model looks back at the end of the previous clip while generating the next one, so the motion and appearance stay consistent.
- The first few frames of a new clip get extra care: they’re gently adjusted to match the last frames of the previous clip, smoothing transitions.
- The system also applies simple “rules” that focus on large shapes (low-frequency details) for stability and sharp edges and textures (high-frequency details) for realism.
Training-free stability tricks
Without extra training, two small fixes improve smoothness:
- Unified noise initialization: Use the same starting noise for all clips, which helps the whole video feel connected.
- Global normalization: Keep the “depth” scale consistent across the entire video, not clip by clip, so the scene doesn’t jump or rescale unexpectedly.
Main Findings and Why They Matter
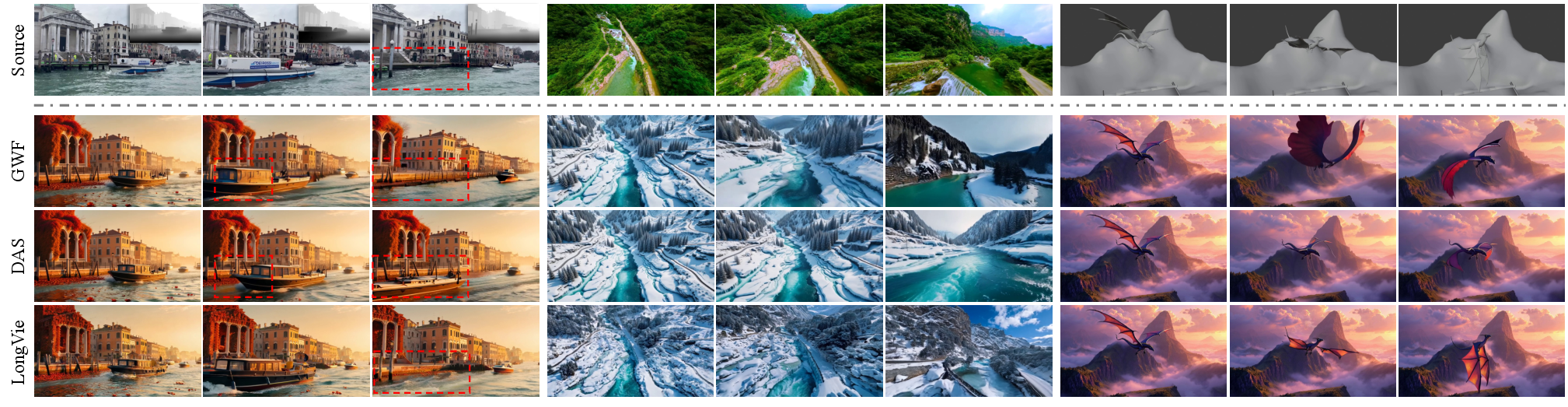
- LongVie 2 makes long videos (3–5 minutes) that stay clear, stable, and controllable throughout.
- It outperforms other strong systems on a new test set called LongVGenBench: 100 one-minute, high-resolution videos in many settings (day/night, indoors/outdoors, real and game-like).
- It keeps backgrounds steady, maintains the subject’s look, and follows instructions more closely than competing methods.
- In human ratings, people consistently preferred LongVie 2’s videos for quality, consistency, and how well they matched the prompt and controls.
This matters because making long, controllable, realistic videos is hard. Most models start strong but drift or blur over time. LongVie 2 shows a practical recipe to keep videos both controllable and stable.
Implications and Impact
- Better simulations and storytelling: You can “direct” a long video with maps and motion hints, and the system will keep it consistent.
- Games and virtual worlds: It can simulate believable environments and physical changes over time (like water flowing after turning a faucet on).
- Training agents and robots: Stable, controllable videos can act as virtual practice spaces.
- Research progress: LongVGenBench gives the community a standard way to test long video generation, pushing the field toward reliable “video world models.”
In short, LongVie 2 is a step toward video systems that understand and simulate the world over time, under your control, without falling apart as minutes go by.
Knowledge Gaps
Below is a concise list of the paper’s unresolved knowledge gaps, limitations, and open questions. Each item is written to be concrete and actionable for future research.
- The “world model” is purely conditional and non-interactive: there is no action-conditioned or policy-driven control (e.g., agent actions, camera trajectories, or closed-loop interaction), limiting the framework’s use for planning and simulation tasks inherent to world models.
- Control modalities are limited to dense depth and sparse point trajectories; the paper does not explore or ablate alternative controls (semantic maps, optical flow, object/instance tracks, text-edit commands, camera intrinsics/extrinsics), nor their fusion strategies.
- Sensitivity to control-signal quality is unquantified: no robustness analysis to noisy, biased, or missing depth/point-map inputs (e.g., low-light, fast motion, textureless surfaces), nor uncertainty-aware weighting of control branches.
- The multi-modal balance scheme (feature- and data-level degradation) is heuristic; the paper omits systematic tuning and sensitivity studies for
α,β, scale sets, blur kernels, andλdistributions, and does not test adaptive weighting at inference. - The history-context window is short (
N_H ∈ [0,16]) relative to minute-long sequences; there is no analysis of how larger memory windows, temporal transformers, or external memory modules affect long-horizon coherence and compute. - First-frame-only degradation may not match the real autoregressive error distribution; there is no comparison to self-forcing/error recycling, scheduled sampling, or video-level distribution matching (e.g., SVI, Self-Forcing) to better align train–test distributions.
- Global normalization of depth uses percentiles computed over the entire sequence, which assumes access to future frames; the paper does not provide an online/streaming alternative (e.g., rolling windows or robust online estimators) for real-time generation.
- Unified noise initialization across clips improves continuity but is not feasible if clips are generated independently or in streaming; the paper does not provide a strategy for consistent stochastic priors without global coordination.
- The approach relies on Wan2.1’s backbone and VAE; generalization to other backbones/VAEs (e.g., CogVideoX, HunyuanVideo) is untested, as are the trade-offs of freezing vs. fine-tuning different submodules.
- The training resolution and frame rate are limited (352×640 at 16 fps); scalability to 1080p/4K and higher frame rates (e.g., 60 fps), including memory/latency and quality stability, remains unaddressed.
- The paper reports 3–5 minute generation but evaluates primarily on one-minute LongVGenBench; long-duration (>5–10 min) behavior, degradation modes, and failure recovery are not studied.
- Clip boundary smoothing uses fixed, exponentially increasing weights for the first 3 frames; there is no principled analysis of boundary optimization, adaptive weighting, or alternative boundary-aware objectives (e.g., continuity constraints).
- The temporal regularization losses (low-/high-frequency consistency, history alignment) are introduced without ablations that isolate each term’s contribution or explore frequency operators’ design choices and hyperparameters.
- The control-first-then-long training strategy is justified empirically but not theoretically; the paper does not test alternative orderings (long-first, joint, curriculum variants) or meta-schedules for better stability.
- There is no explicit modeling or evaluation of physics plausibility, causal consistency, or conservation laws (e.g., fluid dynamics, rigid-body motion); the faucet example is anecdotal without quantitative physical metrics.
- Controllability evaluation with SSIM/LPIPS presumes reference videos; the paper does not address measuring controllability when no ground truth exists (e.g., text-only prompts) or disentangling alignment to controls vs. aesthetic similarity.
- LongVGenBench’s composition and licenses are not detailed; potential domain biases (game vs. real), overlap with training sets, and the benchmark’s representativeness and reproducibility (public release, annotations, splits) remain unclear.
- Prompt quality is auto-generated (Qwen2.5-VL-7B) and not controlled; the impact of prompt noise, specificity, and multi-instruction prompts on controllability and temporal coherence is not evaluated.
- The method assumes precomputed control signals from video; it does not provide a generative controller/planner to synthesize controls from text goals or actions, limiting autonomous long-range content generation.
- Failure modes with missing or corrupted controls (e.g., dropped frames, tracker failures, depth discontinuities) and fallback strategies (control dropout, masked conditioning, learned priors) are not addressed.
- Sparse control density (4,900 points/clip) is fixed; there is no ablation on point count, spatial distribution, or selection strategy (importance sampling, semantic regions), nor scene-dependent adaptivity.
- Compute and latency at inference are not quantified (minutes per minute, GPU memory), nor are practical optimizations (streaming attention, KV-caching, tiling) for real-time or near-real-time generation.
- The human evaluation lacks statistical rigor (e.g., confidence intervals, inter-rater reliability, significance testing) and does not report protocol details (pairing, randomization, content balance) or potential biases.
- The model’s ability to maintain identity consistency across occlusions, fast motions, or re-entries is not explicitly measured (e.g., ID tracking metrics) beyond VBench proxies.
- Safety and ethical considerations (privacy, bias, misuse, licensing of training data) are not discussed; guidelines for controlled content generation in sensitive settings are absent.
- Reproducibility gaps: several hyperparameters (e.g.,
α,β,K, precise training schedules), data preprocessing details, and code/model availability status are not fully specified for exact replication. - Extensibility to object-level editing (insert/remove/move entities) and scene graph conditioning is unexplored, limiting semantic-level world manipulation.
- The approach does not explore integrating 3D scene representations (NeRF, Gaussian Splatting, meshes) for geometrically consistent long-range control beyond 2D depth/points.
- There is no analysis of color drift or exposure/white balance consistency across multi-minute sequences, nor mechanisms (color constancy, histogram matching) to stabilize appearance over time.
- Robustness to domain shifts (e.g., underwater, medical, aerial, cartoon) and cross-dataset generalization are not evaluated; the model’s limits in out-of-distribution content remain unknown.
Practical Applications
Immediate Applications
Below are actionable, deployable use cases that leverage LongVie 2’s multimodal guidance (dense depth + sparse keypoints), degradation-aware training, history-context guidance, and training-free consistency strategies. Each item notes the sector, a concrete workflow or product idea, and assumptions/dependencies that may affect feasibility.
- Film/VFX previsualization and shot extension (Media/Entertainment)
- Use LongVie 2 to turn text prompts plus exported depth maps and tracked keypoints from previz tools into 3–5 minute, style-consistent sequences for directors and editors.
- Tools/workflows: NLE/DAW plugins (Premiere/Resolve/Nuke) that export/import depth maps; keypoint trackers (SpatialTracker); depth extraction (Video Depth Anything); unified noise initialization for multi-clip continuity.
- Assumptions/dependencies: Access to high-end GPUs or cloud inference; licensing for pretrained backbones; content safety filters; reliable control-signal extraction from on-set cameras.
- Game cutscene prototyping from engine captures (Gaming)
- Generate long, consistent cinematic cutscenes using Unreal/Unity exports (depth buffers + point trajectories) and text prompts for narrative guidance.
- Tools/workflows: Engine connector to export control modalities; LongVie 2 module inside pipeline; global normalization for depth across clips.
- Assumptions/dependencies: Engine integration, asset rights, compute; developers fluent with ControlNet-like adapters.
- Virtual production camera-planning and continuity checks (Media/Entertainment)
- Simulate minute-long camera moves to validate set design and lighting continuity before recording.
- Tools/workflows: On-set depth sensors; keypoint annotation of actor/blocking; history-context conditioning for cross-clip coherence.
- Assumptions/dependencies: Sensor calibration; scene metadata; stable multi-modal inputs.
- Social media and marketing content generation at scale (Advertising/Creator Economy)
- Produce consistent multi-minute reels with motion/style transfer (e.g., brand avatars) guided by sparse keypoints and depth for structural fidelity.
- Tools/workflows: Web/app front-ends; cloud inference APIs; preset “brand styles” via LoRA adapters.
- Assumptions/dependencies: Cloud costs; moderation and watermarking; latency constraints for batch vs near-real-time.
- Technical demonstrations and product walkthroughs (Software/Consumer Tech)
- Create long product demos (UI flows, device usage) with world-level guidance ensuring stable backgrounds and subjects over minutes.
- Tools/workflows: UI keypoint tracks; scripted prompts; degradation-aware training prevents visual collapse in extended walkthroughs.
- Assumptions/dependencies: Accurate control labeling; internal guidelines on synthetic disclosure.
- Educational animation for lectures and MOOCs (Education)
- Generate long, consistent explanatory videos (physics, biology, engineering) with sparse trajectories that encode conceptual motion and depth for structure.
- Tools/workflows: Instructor tools to draw/record keypoint paths; template prompts; history-context modules for lesson continuity.
- Assumptions/dependencies: Domain-accurate visuals; content review; compute budgets for campuses.
- Scientific visualization from simulation outputs (Research/Engineering)
- Convert CFD/FEA or agent-based simulation fields to long-form, stylized visualizations while maintaining temporal coherence.
- Tools/workflows: Mapping simulation fields to depth/point maps; global normalization across experiment runs; unified noise seeds for reproducibility.
- Assumptions/dependencies: Valid control-signal transformation; scientific fidelity vs stylization trade-offs.
- Robot task documentation and training data augmentation (Robotics/Manufacturing)
- Generate long, coherent video sequences of pick-and-place or assembly tasks using motion traces and scene depth to augment training datasets.
- Tools/workflows: Motion capture to sparse control; domain prompts; degradation-aware training reduces compound error across extended sequences.
- Assumptions/dependencies: Domain adaptation for industrial scenes; safety reviews; simulator-to-real gap.
- Autonomous driving scenario replay and edge-case visualization (Automotive)
- Create long replays of complex traffic scenarios with controllable motion/style to support scenario libraries, QA, and communication.
- Tools/workflows: Depth estimation from logged camera feeds; sparse object trajectories (keypoints) for controllability; percentiles-based depth normalization across clips.
- Assumptions/dependencies: Privacy controls; alignment with ground-truth sensor data; regulatory compliance.
- Broadcast continuity and “gap fill” in post-production (Media/Entertainment)
- Extend or inpaint long shots (e.g., B-roll) with high temporal stability using history-context guidance across clips.
- Tools/workflows: Post-production plug-in; first-frame degradation alignment to match noisy sources; consistent noise seeds across segments.
- Assumptions/dependencies: Editorial policy for synthetic content; frame-rate/resolution matching; compute at scale.
- Benchmarking and evaluation of long video models (Academia/ML Ops)
- Adopt LongVGenBench (100 x ≥1-minute videos) for standardized evaluation of controllability, consistency, and visual quality.
- Tools/workflows: Automated metrics (SSIM, LPIPS, VBench); protocol scripts; leaderboard hosting.
- Assumptions/dependencies: Dataset licensing; prompt/control-signal generation reproducibility.
- Rapid public-information PSAs (Policy/Communications)
- Create multi-minute, coherent PSAs (evacuation procedures, health advisories) with precise motion trajectories to demonstrate steps.
- Tools/workflows: Government templates with keypoint sequences; watermarking and provenance metadata.
- Assumptions/dependencies: Disclosure policies for synthetic video; accessibility standards; multilingual prompt support.
Long-Term Applications
These use cases require further research, scaling, or development—e.g., stronger physical grounding, interactive control, lower-latency inference, domain fine-tuning, or regulatory frameworks.
- Interactive video world models for digital twins (Smart Cities/Industrial IoT)
- Move from passive generation to agent-conditioned control (camera, objects, actions) for planning and “what-if” analyses in factories, power plants, or urban governance.
- Potential products: Action-conditioned LongVie 2 variants; twin orchestration APIs; compliance dashboards.
- Assumptions/dependencies: Realistic dynamics beyond keypoints/depth; closed-loop simulators; safety and auditability.
- RL training in video simulators with long-horizon tasks (AI/Robotics)
- Use controllable long videos as visual simulators for policy learning (assembly, inspection), leveraging multi-modal controls and history-context for stable rollouts.
- Potential products: Vision-based RL gym for minutes-long episodes; curriculum generators.
- Assumptions/dependencies: Action semantics bridge; reward modeling from visuals; sim-to-real transfer.
- Clinical procedure rehearsal and telemedicine training (Healthcare)
- Simulate minute-scale procedures (endoscopy, ultrasound) with controllable trajectories for clinician training and patient education.
- Potential products: Medical world-model trainer; scenario authoring tools; accreditation modules.
- Assumptions/dependencies: Access to medical-grade datasets; clinical validation; regulatory approvals (FDA/EMA).
- Emergency response and safety drills (Public Safety)
- Generate long, consistent, scenario videos (fire exits, earthquake protocols) for training, planning, and public dissemination.
- Potential products: Municipal scenario libraries; adaptive scenario generators; policy-integrated watermarks.
- Assumptions/dependencies: Multi-agency coordination; legal frameworks for synthetic media; accessibility compliance.
- Autonomous driving closed-loop evaluation (Automotive)
- Transition from replay visualization to interactive, agent-in-the-loop world models for minute-long drives with controllable behaviors and environment changes.
- Potential products: Evaluation harnesses; scenario stress-test suites; risk dashboards.
- Assumptions/dependencies: Physics grounding; sensor realism; liability and standards alignment (UNECE/ISO).
- Human–AI co-creation tools for long-form storytelling (Media/Entertainment)
- Interactive direction of scenes via sparse trajectories, mesh-to-video, and style transfer, with in-editor history-aware timelines.
- Potential products: LongVie 2 Studio; keypoint/mesh authoring UI; collaborative editing platforms.
- Assumptions/dependencies: Real-time constraints; rights management; creator safety features.
- CAD-to-video for design reviews and stakeholder communication (Engineering/Construction)
- Render long, consistent visual narratives of design alternatives from meshes and structural cues to support procurement and stakeholder engagement.
- Potential products: BIM/PLM connectors; scene consistency validators; change-tracking overlays.
- Assumptions/dependencies: Accurate mesh-to-video mapping; domain fine-tuning; versioning and provenance.
- Energy operations training and incident replay (Energy/Utilities)
- Long-form, controllable videos (valve operations, grid switching) to rehearse procedures and analyze incidents with consistent temporal fidelity.
- Potential products: Training simulators; incident reconstruction tools; QA checklists.
- Assumptions/dependencies: Access to operational data; safety certifications; cyber-security constraints.
- Personalized long-form education companions (Education)
- Curriculum-aligned minute-scale explainers with controllable motion to illustrate complex phenomena (e.g., fluid dynamics, orbital mechanics).
- Potential products: Tutor integrations; concept-to-trajectory authoring; classroom orchestration APIs.
- Assumptions/dependencies: Pedagogical validation; localization; equity in access (compute costs).
- Telepresence and holographic continuity (Communication/AR/VR)
- Maintain perceptual continuity in extended telepresence sessions, blending real depth/keypoints with generative consistency.
- Potential products: AR meeting services; temporal-coherence enhancement modules; bandwidth-optimized renderers.
- Assumptions/dependencies: Sensor fusion; latency budgets; privacy and biometric data protections.
- Compliance, watermarking, and provenance standards (Policy/Regulation)
- Embed robust provenance and disclosure metadata for synthetic long videos; support policy-aligned watermarking informed by degradation-aware and history-context strategies.
- Potential products: Regulatory SDKs; audit logs; content authenticity APIs (C2PA-like).
- Assumptions/dependencies: International standardization; interoperability; public trust frameworks.
- Efficiency-focused distillation and on-device deployment (Software/Edge AI)
- Compress LongVie 2 into lighter models (distilled/backbone-agnostic variants) enabling mobile or edge generation of multi-minute videos.
- Potential products: Edge inference kits; LoRA packs per domain; workload schedulers.
- Assumptions/dependencies: Distillation research; quality/latency trade-offs; hardware heterogeneity.
Common assumptions and dependencies across applications
- Control-signal availability: Reliable depth estimation and keypoint/point-track extraction (e.g., Video Depth Anything, SpatialTracker) are essential; sensor calibration affects quality.
- Compute and latency: Current 3–5 minute generation often needs powerful GPUs or cloud; real-time and interactive use cases may require distillation or specialized accelerators.
- Domain adaptation: Visual fidelity and physics plausibility depend on fine-tuning to the target domain; sparse/dense control balance may need reweighting.
- Legal, ethical, and safety: Watermarking/provenance, privacy for recorded data, rights to source assets, and clear synthetic disclosure policies are necessary.
- Content policies: Industry/government guidelines on synthetic long-form media (misinformation, deepfakes) should be integrated before deployment.
- Toolchain integration: Stable APIs/SDKs, connectors for engines (Unreal/Unity), NLEs, BIM/PLM, RL frameworks; versioning and reproducibility via unified noise seeds and depth normalization.
Glossary
- Ablation study: A controlled analysis where components of a system are systematically removed or altered to assess their impact. "We conduct ablation studies to verify the effectiveness of each component and training strategy adopted in our method."
- AdamW: An optimizer that decouples weight decay from the gradient-based update, often used for training large neural networks. "LongVie~2 is optimized with AdamW at a learning rate of "
- Adaptive Blur Augmentation: A data augmentation technique that applies randomized blurring to reduce dependence on sharp local details. "Adaptive Blur Augmentation:"
- Aesthetic Quality (A.Q.): A metric assessing the visual appeal of generated videos. "Aesthetic Quality (A.Q.)"
- Autoregressive paradigm: A generation approach that conditions each output segment on previously generated content to extend sequences. "built upon an autoregressive paradigm."
- Background Consistency (B.C.): A metric evaluating how stable the background remains across video frames. "Background Consistency (B.C.)"
- ControlNet: An architectural paradigm that adds trainable control branches to a frozen diffusion backbone to inject conditioning signals. "following the standard ControlNet paradigm"
- Data-level degradation: A training strategy that perturbs input data directly (e.g., via multi-scale fusion or blur) to improve robustness. "2) Data-level degradation:"
- Degradation-aware training: Training that exposes the model to degraded inputs to better handle long-horizon quality decay at inference. "degradation-aware training on the input frame"
- Degradation consistency: A loss component encouraging structural alignment with degraded inputs to stabilize transitions. "(2) Degradation consistency."
- Degradation operator: A formal operator that applies specified corruption procedures to inputs during training. "that together define the degradation operator :"
- Dense control signals: Spatially rich conditioning inputs that provide detailed structural guidance (e.g., depth). "integrates dense (e.g., depth maps) and sparse (e.g., keypoints) control signals"
- Depth maps: Per-pixel distance fields used as dense structural guidance for controllable generation. "we adopt depth maps as dense control signals"
- DiT (Diffusion Transformer): A transformer-based backbone for diffusion models used in image/video generation. "pre-trained Wan DiT"
- Diffusion models: Generative models that synthesize data by iteratively denoising from noise. "Diffusion models are powerful video world learners that synthesize realistic videos by progressively removing noise."
- Denoising: The process of reversing added noise within diffusion modeling to reconstruct clean data. "followed by denoising through the diffusion model"
- Dynamic Degree (D.D.): A metric assessing the extent of motion or dynamism in generated videos. "Dynamic Degree (D.D.)"
- Feature-level degradation: A training technique that scales or perturbs latent features to reduce over-reliance on certain controls. "1) Feature-level degradation:"
- Global Normalization: A consistency technique that normalizes control inputs (e.g., depth) across the entire sequence to a global scale. "we employ a global normalization strategy applied to the entire depth sequence."
- Ground-truth high-frequency alignment: A loss that aligns fine details of generated outputs with ground-truth high-frequency components. "(3) Ground-truth high-frequency alignment."
- High-frequency operator: A transform extracting fine-detail components of signals for loss computation. "denotes a high-frequency operator."
- History Context Guidance: Conditioning on preceding frames to enforce temporal coherence across clips. "we propose History Context Guidance."
- History context consistency: A loss enforcing alignment between the first latent of a new clip and the last latent of the history. "(1) History context consistency."
- Imaging Quality (I.Q.): A metric evaluating the technical fidelity and clarity of generated frames. "Imaging Quality (I.Q.)"
- Keypoints: Sparse, trackable image landmarks used as motion/structure cues for control. "a set of keypoints is tracked across frames"
- Latent Diffusion Models: Diffusion models operating in a compressed latent space via an autoencoder. "Latent Diffusion Models~\cite{rombach2021highresolution} work in a smaller, compressed space."
- LoRA: Low-rank adaptation technique that adds lightweight, trainable matrices to large frozen models for efficient fine-tuning. "components such as LoRA~\cite{hu2021loralowrankadaptationlarge}, ControlNet~\cite{controlnet}, or similar plug-in adapters."
- LPIPS: A learned perceptual image similarity metric used to evaluate visual similarity. "We also report similarity-based metrics, including SSIM and LPIPS"
- Low-frequency extraction operator: A transform isolating coarse, low-frequency components for stability constraints. "denotes a low-frequency extraction operator."
- Masking mechanism: A conditioning scheme that controls which inputs the model must attend to during training. "Following the masking mechanism in Wan"
- Percentile-based normalization: Scaling method using robust percentile bounds to mitigate outliers in control signals. "This percentile-based normalization is robust to outliers"
- Point maps: Sparse spatial control representations derived from tracked points or trajectories. "we adopt depth maps as dense control signals and point maps as sparse control signals"
- Random Scale Fusion: A multi-scale degradation technique that blends differently scaled versions of a control input. "Random Scale Fusion:"
- Self-attention layers: Transformer components enabling token-to-token interactions over space and time. "we additionally update all parameters in the self-attention layers of the base model."
- Sparse control signals: Compact conditioning inputs (e.g., keypoints) conveying semantic/motion cues with few elements. "integrates dense (e.g., depth maps) and sparse (e.g., keypoints) control signals"
- SSIM: Structural similarity index; a perceptual similarity metric for images/videos. "We also report similarity-based metrics, including SSIM and LPIPS"
- Subject Consistency (S.C.): A metric evaluating the stability of the main subject across frames. "Subject Consistency (S.C.)"
- Temporal drift: Gradual deviation in appearance or motion over long sequences, harming consistency. "these models often exhibit visual degradation and temporal drift"
- Unified Noise Initialization: Using a single noise seed across clips to enhance temporal coherence. "we adopt a unified noise initialization across all video clips."
- VAE (Variational Autoencoder): A probabilistic autoencoder used to encode/decode images into a latent space, introducing reconstruction artifacts. "due to the non-lossless encoding and decoding process of the VAE, repeated reconstruction further amplifies this decline in quality."
- VBench: A benchmarking protocol for evaluating video generation across multiple quality and consistency dimensions. "Following the widely adopted VBench protocol~\cite{vbench}, we evaluate performance"
- World model: A generative model that learns and simulates environment dynamics for coherent, controllable video synthesis. "a controllable video world model"
- Zero-initialized linear layers: Layers initialized to zero to inject controls without altering initial backbone behavior. "we adopt zero-initialized linear layers ."
Collections
Sign up for free to add this paper to one or more collections.

